DiffCrack:复杂道路场景下的可控裂缝图像生成方法
1. 背景:为什么需要生成复杂场景裂缝图像?
道路裂缝检测是智慧交通、基础设施巡检和道路养护中的重要任务。近年来,基于深度学习的裂缝检测与分割方法取得了较大进展,但在真实道路场景中仍然面临明显的泛化问题。
真实道路图像往往存在阴影、反光、车道线、路面污渍、植被、建筑物遮挡等复杂干扰。同时,裂缝本身也具有形态细长、尺度变化大、纹理不稳定、对比度弱等特点。这使得模型在标准数据集上训练后,迁移到复杂场景时容易出现漏检、误检和边界不准确等问题。
因此,影响模型泛化能力的关键因素不仅是标注数据数量不足,更重要的是现有数据集中裂缝形态、背景纹理和成像条件的模式多样性不足。如何构建具有复杂场景多样性的裂缝数据,是提升道路裂缝检测鲁棒性的关键问题之一。
2. 工作简介:DiffCrack 解决什么问题?
为了解决复杂场景裂缝样本不足和数据模式单一的问题,我们提出了DiffCrack:一种面向复杂场景裂缝图像生成的语义–结构可控扩散框架。
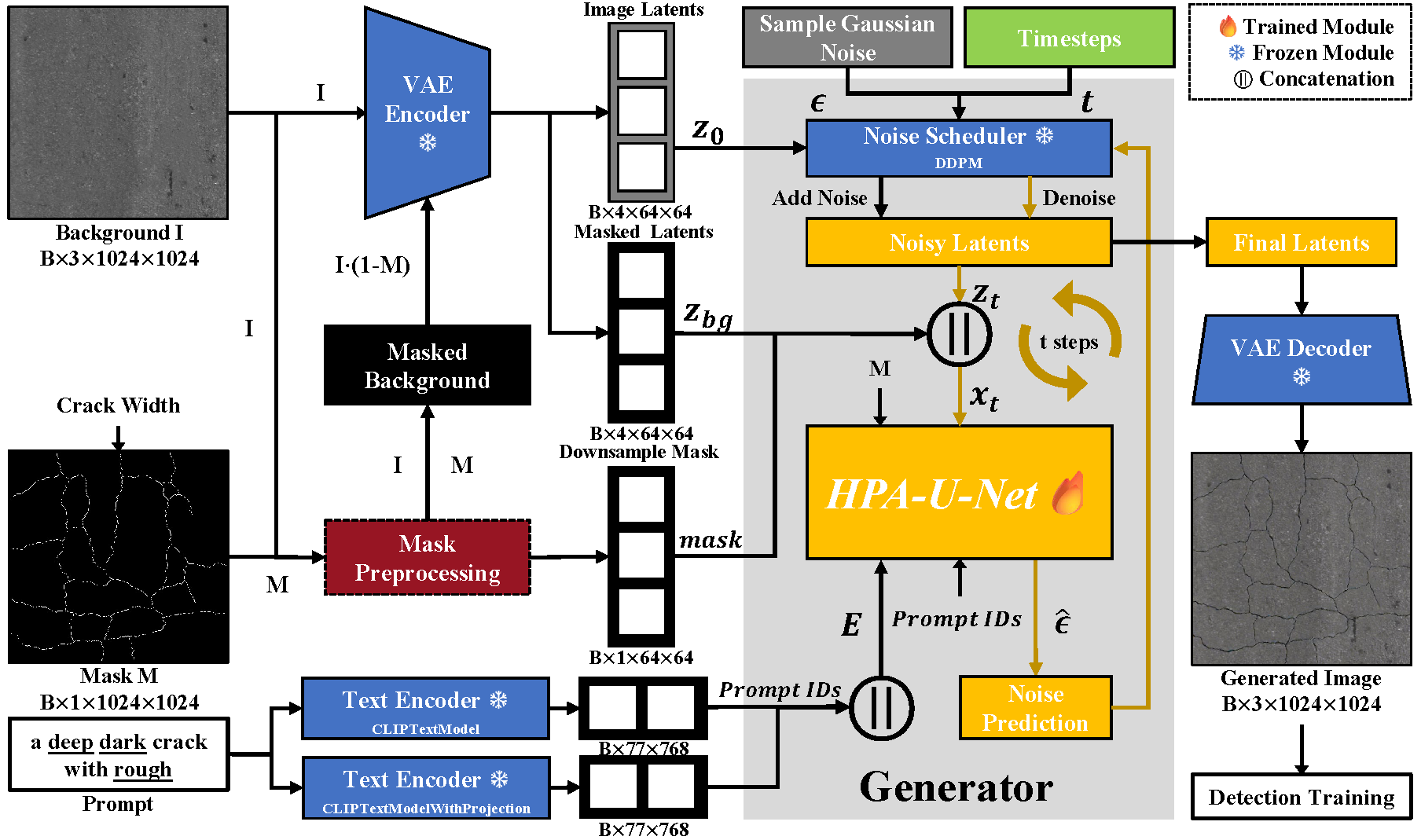
DiffCrack的目标不是简单生成“看起来像裂缝”的图像,而是希望实现三个方面的可控生成能力:
- 结构可控:通过裂缝 mask 控制裂缝的空间位置和几何形态;
- 语义可控:通过文本描述控制裂缝的宽度、深度、颜色、纹理等外观属性;
- 场景真实:在复杂道路背景中生成更加自然、真实且具有多样性的裂缝样本。
通过这种方式,可以用于构建更丰富的缺陷训练数据,从而提升下游裂缝检测和分割模型在复杂场景下的泛化能力。
3. 方法核心:语义控制与结构控制解耦
DiffCrack的核心思想是将裂缝生成过程中的“结构信息”和“外观语义信息”进行解耦。传统生成方法往往将裂缝的几何结构和视觉外观混合建模,容易出现裂缝位置不可控、形态不稳定、背景融合不自然等问题。DiffCrack 则将生成过程拆分为两个控制条件:
3.1 结构控制:利用掩码约束裂缝空间形态
DiffCrack 使用二值裂缝 mask 作为结构条件,用于控制裂缝在图像中的位置、走向和几何形态。这样可以保证生成裂缝与给定结构先验保持一致,避免生成结果出现明显的位置漂移或结构失真。
3.2 语义控制:利用HPA调控裂缝外观属性
在语义控制方面,DiffCrack设计了Hierarchical Prompt Attention, HPA 模块,用于对裂缝的宽度、深度、颜色和纹理等属性进行层级化控制。
 例如,同一张真实裂缝掩码可以通过不同的 prompt 生成不同外观的裂缝结果:
例如,同一张真实裂缝掩码可以通过不同的 prompt 生成不同外观的裂缝结果:
- thin / wide crack;
- shallow / deep crack;
- dark / light crack;
- rough / smooth texture。
这种设计使得模型不仅能够保持裂缝结构稳定,还能够生成具有丰富外观变化的裂缝样本。
4. 数据集:Normal 与 Complex Scene
为了验证方法在真实道路场景中的有效性,我们构建并整理了 Normal 和 Complex Scene 两类数据。

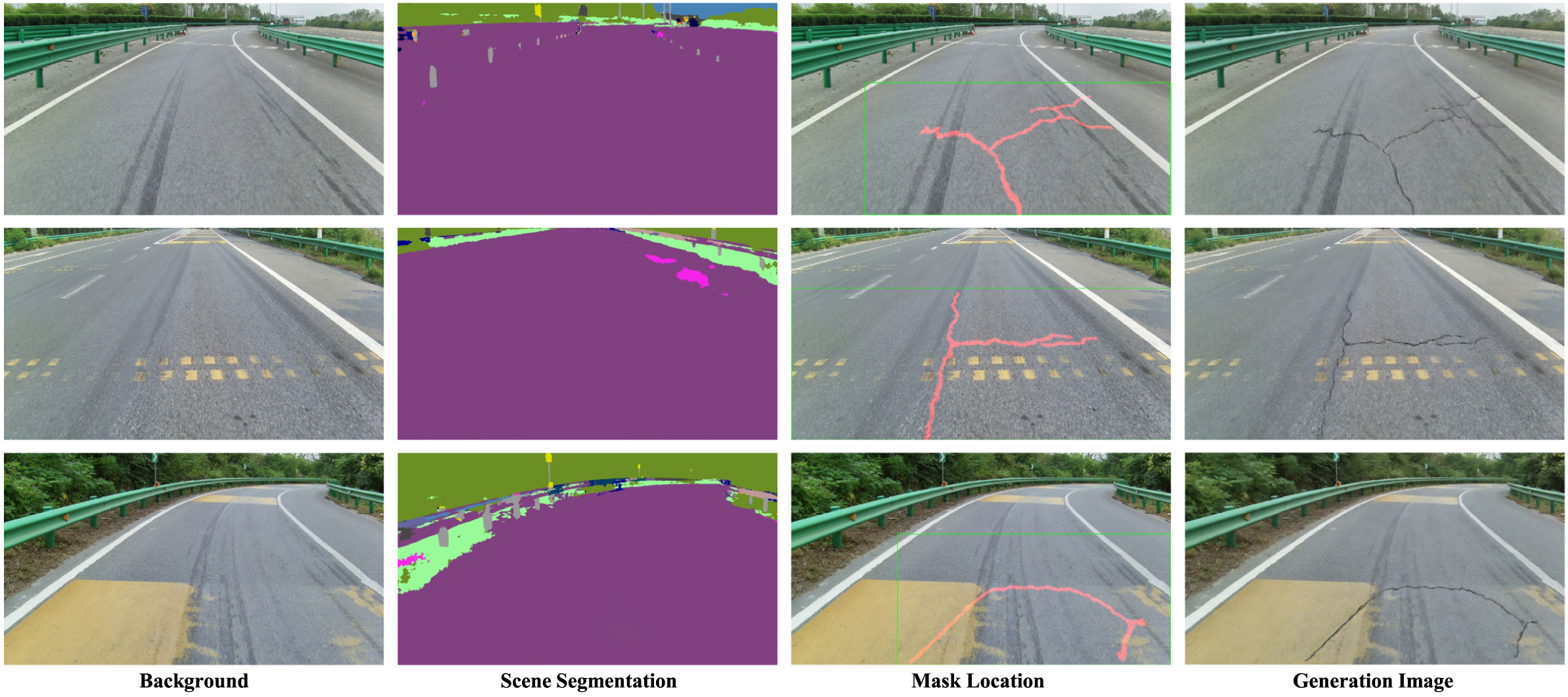
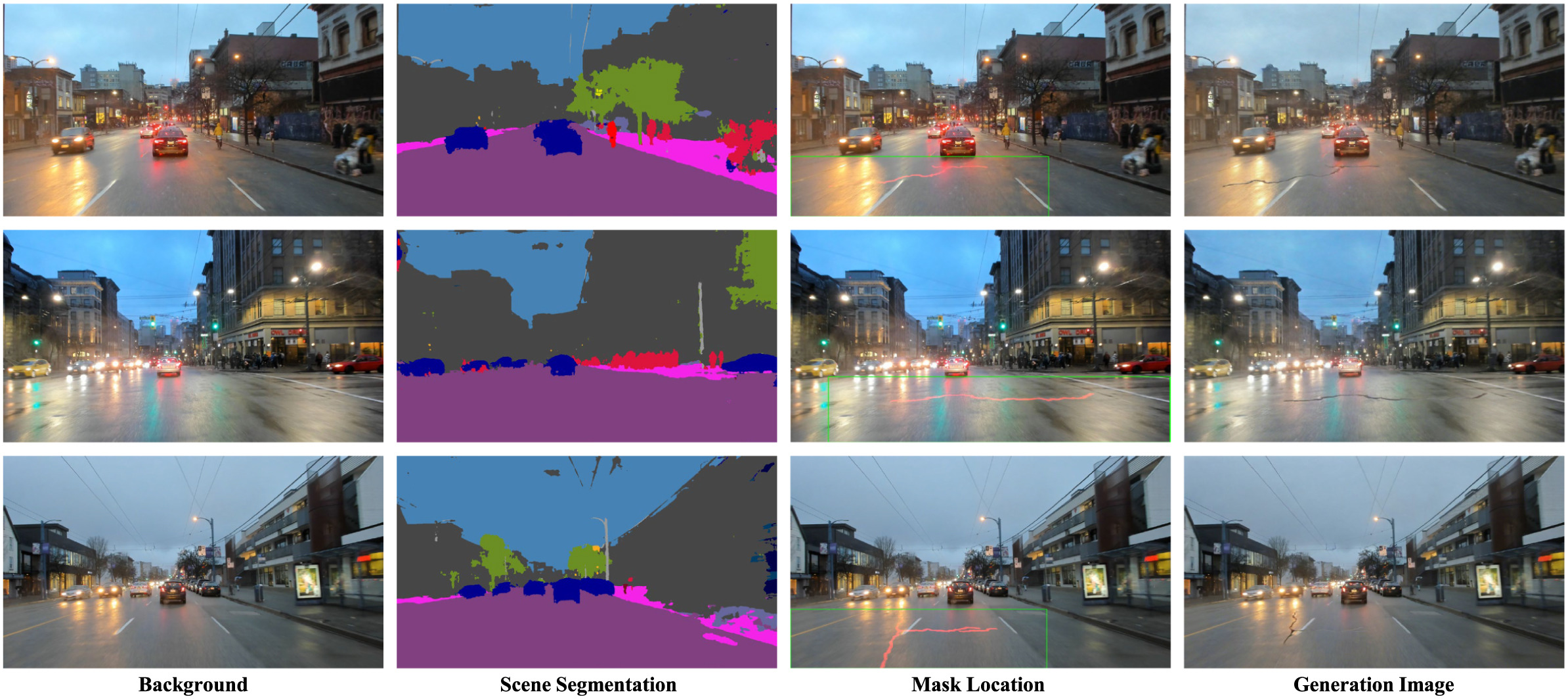
其中,Complex Scene 主要关注真实道路图像中的复杂干扰因素,包括:
| 类型 | 示例 |
|---|---|
| 光照相关干扰 | 阴影、反光、亮度不均 |
| 路面表面干扰 | 车道线磨损、标线重叠、路面纹理干扰 |
| 结构性背景干扰 | 路边标志、植被、建筑物等 |
这些复杂场景能够更真实地反映道路巡检任务中模型所面临的挑战,也更适合用于评估生成数据对下游检测模型鲁棒性的提升作用。
5. 代码仓库结构
目前我们已经开源了 DiffCrack 的官方实现,代码仓库包含模型源码、数据预处理脚本、训练脚本、推理示例和预训练权重说明。
项目结构如下:
DiffCrack/
├── assets/ # 方法示意图与展示图
├── configs/ # 训练和推理配置文件
├── data/ # 数据组织示例
├── scripts/ # 训练、推理、评估脚本
├── src/ # 核心模型代码
├── tools/ # 数据预处理、训练、推理、评估入口
├── requirements.txt
└── README.md6. 环境配置
首先克隆代码仓库:
git clone https://github.com/tq307/DiffCrack.git
cd DiffCrack创建并激活 conda 环境:
conda create -n diffcrack python=3.10 -y
conda activate diffcrack安装依赖:
pip install -r requirements.txt7. 数据格式
DiffCrack 使用 JSONL 格式组织训练、验证和测试数据。每一行对应一个样本,包含目标图像、结构 mask、背景图像和文本 prompt。
示例格式如下:
{"target":"targets/0001.png","source":"masks/0001.png","background":"backgrounds/0001.png","prompt":"A deep dark crack with rough texture"}其中:
- target:目标裂缝图像;
- source:裂缝结构 mask;
- background:背景道路图像;
- prompt:裂缝外观描述文本。
8. 数据预处理
可以使用项目中的预处理脚本生成训练所需的 JSON 文件:
python tools/preprocessing.py \
--background_folder ./data/backgrounds \
--crack_folder ./data/crack_templates \
--output_json ./data/train.json \
--mode training \
--random_mode如果不使用 --random_mode,则需要指定本地 Qwen2.5-VL 模型路径或模型名称,用于生成 prompt。
9. 模型训练
使用如下命令启动训练:
python tools/train.py --config configs/train.yaml也可以使用脚本启动:
bash scripts/train.sh多卡训练可以使用 accelerate:
NUM_PROCESSES=4 bash scripts/train.sh multi10. 模型推理
单图或批量推理可以使用:
python tools/infer.py --config configs/infer.yaml或者:
bash scripts/infer.sh当没有指定 --image_path 时,程序会根据配置文件中的测试数据进行批量推理。
11. 结果评估
推理完成后,可以使用如下命令进行评估:
python tools/evaluate.py --config configs/infer.yaml --pred_path outputs/predictions.json或者:
bash scripts/eval.sh12. 项目地址
GitHub 项目地址:
https://github.com/tq307/DiffCrack欢迎大家使用和交流。如果在数据集、代码运行或预训练权重方面有问题,也欢迎通过GitHub或论文中提供的联系方式进行讨论。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)