基于C++ 11的线程池实现
线程池实现
线程池源码可在采用C++11实现的线程池功能资源-CSDN下载。
目的使用C++ 11 实现简易的线程池功能。在这之前需要了解下C++ 信号量知识,信号量 std::condition_variable 是实现线程同步的方法。其相当于线程的“闹钟 + 休息室”。可避免循环浪费CPU资源,实现线程间精准等待/环形,同时可用于生产者-消费者模型:
- 一个线程往队列放数据(生产者)
- 一个线程从队列取数据(消费者)
- 没数据时,消费者不能死循环疯狂检查,要睡觉等通知
- 有数据时,生产者叫醒消费者
std::condition_variable实现通知线程,有如下方法可实现:
notify_one:实现通知一个线程
#include <mutex>
#include <vector>
#include <iostream>
#include <thread>
std::mutex m_mutex;
std::condition_variable my_cond;
std::vector<int> m_msgRecvQueue;
void outMsgRecvQueue() {
int command = 0;
while (true)
{
std::unique_lock<std::mutex> lock(m_mutex);
my_cond.wait(lock, [&]() {
if (!m_msgRecvQueue.empty())//解决虚假唤醒问题
return true;
return false;
});
command = m_msgRecvQueue.back();
m_msgRecvQueue.pop_back();
lock.unlock();
std::cout << "outMsgRecvQueue()执行,取出一个元素 " << command<<"=====" << std::endl;
}
}
void inMsgRecvQueue() {
for (int i = 0; i < 10; i++)
{
std::cout << "inMsgRecvQueue()执行,插入一个元素 " << i << "=====" << std::endl;
std::unique_lock<std::mutex> lock(m_mutex);
m_msgRecvQueue.emplace_back(i);
my_cond.notify_one();
}
}
int main() {
std::thread t1(outMsgRecvQueue);
std::thread t2(inMsgRecvQueue);
std::thread t3(outMsgRecvQueue);
std::thread t4(inMsgRecvQueue);
t1.join();
t2.join();
t3.join();
t4.join();
return 0;
}
上述代码中实现的是:
1、线程启动后outMsgRecvQueue函数执行,此时进入while循环,while循环内部先加锁,接着执行到my_cond.wait,这个根据wait有不同的参数存在不同的执行方法:
- 如果wait第二个参数的lambda表达式返回的是true,wait直接返回;
- 如果wait第二个参数的lambda表达式返回的是false,那么wait将解锁互斥量并堵塞这行,堵塞的截止由另外一个线程调用notify_one()通知为止;
- 如果wait()不用第二个参数,那跟第二个参数为lambda表达式并且返回false效果一样(等待另外一个线程调用notify_one()通知结束堵塞)。
2、inMsgRecvQueue执行往m_msgRecvQueue集合添加数据,为了线程安全,添加了互斥量,在添加完了元素后, 执行 my_cond.notify_one() 唤醒沉睡的线程。
notify_all:实现通知所有等待线程
demo与notify_once一样,只是在inMsgRecvQueue函数中,把my_cond.notify_one()改成my_cond.notify_all();即可。他的执行其实与notify_once一样,每次也只是一个线程获取得到锁。
std::packaged_task:
把函数/可调用对象打包成任务,自动分配好std::future,通过返回的future得到任务的结果。
int mythread(int i){};
std::packaged_task<int(int)> mypt(mythread);
std::thread t1(std::ref(mypt),1);
t1.join();
std::future<int> result = mypt.get_future();
std::cout<<result.get()<<std::endl;
std::unique_lock
unique_lock是一个类模板,它的功能与lock_guard类似,但是比 lock_guard 更 灵 活 。他有unlock方法,意味着可以随时解锁。降低锁的颗粒度。
atomic
为原子操作,是个模板类,支持基本数据类型,实现无锁操作的同时实现线程同步。
std::enable_if<条件,返回值类型>
std::enable_if目的是控制函数是否生效,实现模板函数重载。其原理是若条件为true,那么生成合法的类型,否则,直接让这个函数不参与编译。在实现的线程池中,使用了std::enable_if,目的是根据传入函数不同类型,让编译器选择不同的类型的函数,具体实现代码如下:
//有参数且有std::future返回值走这个方法
template<typename F, typename... Arg>
typename std::enable_if<(sizeof...(Arg) > 0), std::future<decltype(declval<F>()(declval<Arg>()...))>>::type
Commit(F&& f, Arg&&...args)
{
if (!m_run)
throw runtime_error("commit on ThreadPool is stopped.");
using RetType = decltype(f(args...));
auto task = std::make_shared<std::packaged_task<RetType()>>(
std::bind(std::forward<F>(f), std::forward<Arg>(args)...)
);
std::future<RetType> future = task->get_future();
std::lock_guard<std::mutex> lock(m_mutex);
m_taskList.emplace([task]() {
(*task)();
});
m_task_cv.notify_one();
return future;
};
//无参且有std::future返回值走这个方法
template<typename F, typename... Arg>
typename std::enable_if<(sizeof...(Arg) <= 0)&&!(std::is_void<decltype(std::declval<F>()())>::value),
std::future<decltype(declval<F>()(declval<Arg>()...))>>::type
Commit( F&& f, Arg&&...args)
{
if (!m_run)
throw runtime_error("commit on ThreadPool is stopped.");
using RetType = decltype(f());
auto task = std::make_shared<
std::packaged_task<decltype(f())()>
>(std::forward<F>(f));
std::future<RetType> future = task->get_future();
std::lock_guard<std::mutex> lock(m_mutex);
m_taskList.emplace([task]() {
(*task)();
});
m_task_cv.notify_one();
return future;
}
////无参且无返回值走这个方法
template<typename F, typename... Arg>
typename std::enable_if<
std::is_void<decltype(std::declval<F>()())>::value
>::type
Commit( F&& f, Arg&&... args) {
if (!m_run)
throw runtime_error("commit on ThreadPool is stopped.");
auto task = std::make_shared<packaged_task<void()>>(std::bind(std::forward<F>(f), std::forward<Arg>(args)...));
m_taskList.emplace(task);
m_task_cv.notify_one();
}
有了上述基础后,我们来实现线程池就相对简单了。在这里先阐述下线程池实现原理:
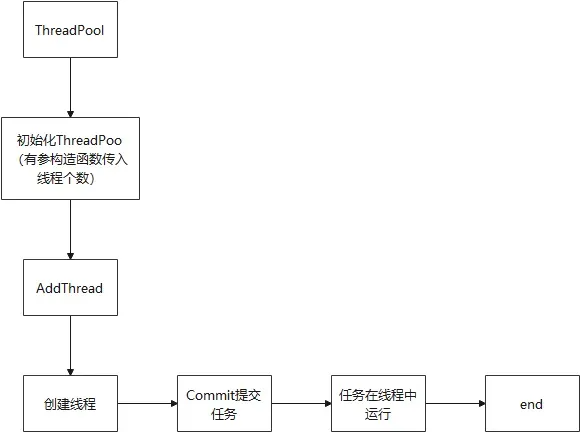
首先创建ThreadPool类,在类中设置默认最大线程池大小,防止线程数量过大,导致系统资源开发过渡导致线程池效率降低问题。
#define THREADPOOL_MAX_NUM 16//设置默认最大线程池大小
接着创建构造函数,采用的是有参数构造函数,设置默认线程个数4个,同时初始化m_avilable_thread_num。接着在构造函数内部调用AddThread方法,实现线程池的初始化。接下来,详细介绍AddThread方法的实现。
class ThreadPool {
private:
unsigned int m_size;
std::mutex m_mutex;
std::vector<std::thread> m_pool;//线程池
using Task = std::function<void()>;
std::queue<Task> m_taskList;//存储任务
atomic<bool> m_run{ true };//通知线程停止
std::condition_variable m_task_cv;//信号量
atomic<int> m_avilable_thread_num;//可用线程数量
public:
int GetAvilableThreadNum() const {
return m_avilable_thread_num;
};
public:
ThreadPool(unsigned int size = 4) :m_size(size), m_avilable_thread_num(0) {
AddThread(size);
};
~ThreadPool() {
m_run = false;
m_task_cv.notify_all();
for (thread& thread : m_pool) {
if (thread.joinable())
thread.join();
}
}
AddThread实现如下:
void AddThread(unsigned int size) {
for (; size > 0&&(m_pool.size() < THREADPOOL_MAX_NUM); size--) {
m_pool.emplace_back([&]() {
while (true)
{
std::unique_lock<std::mutex> lock(m_mutex);
Task task;
{
m_task_cv.wait(lock, [&] {
return !m_run || !m_taskList.empty();
});
if (!m_run || m_taskList.empty())
break;
m_avilable_thread_num--;
task = std::move(m_taskList.front());
m_taskList.pop();
}
lock.unlock();
task();
m_avilable_thread_num++;
}
});
m_avilable_thread_num++;//创建线程的时候,任务为空,此时可用线程数量自增
}
};
工作原理:其入口参数为线程数量,方法体是为了实现创建线程,同时在存在任务的情况下,从m_taskList任务列表里面提取任务,执行任务。
详解:
1、for (; size > 0&&(m_pool.size() < THREADPOOL_MAX_NUM); size--) 根据传入的线程数量循环创建线程,同时限制线程数量,保证线程数量不超过THREADPOOL_MAX_NUM。m_pool字段,其声明类型为 std::vector<std::thread>,其emplace_back为将创建的线程句柄存入m_pool内,同时创建的线程交由cpu选择时机执行。
2、while循环内部,首先通过std::unique_lock<std::mutex> lock(m_mutex);上锁,当获取到锁后执行后续代码,否则将在此等待,直至获取到锁,目的是实现后从m_taskList提取任务,防止线程冲突。
3、m_task_cv.wait有两个参数,传入一个lock,第二个参数为lambda表达式,当lambda表达式返回true时,同时获得锁后,程序立马返回,但若lambda返回false,则m_task_cv将释放锁,等待其他线程触发notify_one/notify_all。
4、 if (!m_run || m_taskList.empty()) ,这部分代码目的是为了若任务列表为空或者线程池被回收的时候,能从打断while循环,逐步释放线程。
5、 lock.unlock(); 这部分代码目的是为了解锁线程,使 task();能实现多线程并发,也就是不受线程同步影响。
Commit方法详解:
template<typename F, typename... Arg>
typename std::enable_if<(sizeof...(Arg) > 0),
std::future<decltype(declval<F>()(declval<Arg>()...))>>::type
Commit(F&& f, Arg&&...args)//有参数且有std::future返回值走这个方法
{
if (!m_run)
throw runtime_error("commit on ThreadPool is stopped.");
using RetType = decltype(f(args...));
auto task = std::make_shared<std::packaged_task<RetType()>>(
std::bind(std::forward<F>(f), std::forward<Arg>(args)...)
);
std::future<RetType> future = task->get_future();
std::lock_guard<std::mutex> lock(m_mutex);
m_taskList.emplace([task]() {
(*task)();
});
m_task_cv.notify_one();
return future;
};
template<typename F, typename... Arg>
typename std::enable_if<(sizeof...(Arg) <= 0)&&!(std::is_void<decltype(std::declval<F>()())>::value),
std::future<decltype(declval<F>()(declval<Arg>()...))>>::type
Commit( F&& f, Arg&&...args)//无参且有std::future返回值走这个方法
{
if (!m_run)
throw runtime_error("commit on ThreadPool is stopped.");
using RetType = decltype(f());
auto task = std::make_shared<
std::packaged_task<decltype(f())()>
>(std::forward<F>(f));
std::future<RetType> future = task->get_future();
std::lock_guard<std::mutex> lock(m_mutex);
m_taskList.emplace([task]() {
(*task)();
});
m_task_cv.notify_one();
return future;
}
template<typename F, typename... Arg>
typename std::enable_if<
std::is_void<decltype(std::declval<F>()())>::value
>::type////无参且无返回值走这个方法
Commit( F&& f, Arg&&... args) {
if (!m_run)
throw runtime_error("commit on ThreadPool is stopped.");
auto task = std::make_shared<packaged_task<void()>>(std::bind(std::forward<F>(f), std::forward<Arg>(args)...));
m_taskList.emplace(task);
m_task_cv.notify_one();
}
上述代码为实现模板重载,当传入任务存在有参数且有std::future返回值时,编译器将选择方法1;当传入任务存在无参且有std::future返回值时,编译器将选择方法2;若传入任务无参且无返回值,编译器选择方法3。上述代码大同小异,就采用方法1的代码段详细介绍:
template<typename F, typename... Arg>
typename std::enable_if<(sizeof...(Arg) > 0),
std::future<decltype(declval<F>()(declval<Arg>()...))>>::type
Commit(F&& f, Arg&&...args)
1、首先针对std::enable_if部分代码介绍。std::enable_if<条件,返回值类型>,条件是(sizeof...(Arg) > 0),其表达的意思是获取参数的数量,若大于0,则编译器选择这个方法,同时返回值类型为 std::future<decltype(declval<F>()(declval<Arg>()...))>,decltype为获取f(args…)方法的返回值类型。std::declval<T>(),用于在编译期间创建T类型对象,但实际不会真的创建。declval<F>()为创建F函数对象,declval<Arg>()...为创建参数包对象,declval<F>()(declval<Arg>()...)相当于执行了f(args…)函数,decltype(declval<F>()(declval<Arg>()...))>则为获取执行的函数的返回值类型。
2、函数体内部, auto task = std::make_shared<std::packaged_task<RetType()>>( std::bind(std::forward<F>(f), std::forward<Arg>(args)...) ); 为包装一个函数体。
接下来,在main函数中测试线程池代码:
#include "ThreadPool.h"
#include <iostream>
void fun1(int slp)
{
printf(" hello, fun1 ! %d\n", std::this_thread::get_id());
if (slp > 0) {
printf(" ======= fun1 sleep %d ========= %d\n", slp, std::this_thread::get_id());
std::this_thread::sleep_for(std::chrono::milliseconds(slp));
//Sleep(slp );
}
}
struct gfun {
int operator()(int n) {
printf("%d hello, gfun ! %d\n", n, std::this_thread::get_id());
return 42;
}
};
class A {
public:
static int Afun(int n = 0) {
std::cout << n << " hello, Afun ! " << std::this_thread::get_id() << std::endl;
return n;
}
static std::string Bfun(int n, std::string str, char c) {
std::cout << n << " hello, Bfun ! " << str.c_str() << " " << (int)c << " " << std::this_thread::get_id() << std::endl;
return str;
}
};
int main()
try {
std::ThreadPool executor{ 50 };
A a;
std::future<void> ff = executor.Commit(fun1, 0);
std::future<int> gg = executor.Commit(a.Afun, 9999);
std::future<std::string> gh = executor.Commit(A::Bfun, 9998, "mult args", 123);
std::future<std::string> fh = executor.Commit(
[]()->
std::string {
std::cout << "hello, fh ! " << std::this_thread::get_id() << std::endl;
return "hello,fh ret !";
});
std::cout << " ======= sleep ========= " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::microseconds(900));
for (int i = 0; i < 50; i++) {
executor.Commit(fun1, i * 100);
}
std::cout << " ======= commit all ========= " << std::this_thread::get_id() << " idlsize=" << executor.GetAvilableThreadNum() << std::endl;
std::cout << " ======= sleep ========= " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << " ======= sleep ========= " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << " ======= fun1,55 ========= " << std::this_thread::get_id() << std::endl;
executor.Commit(fun1, 55).get(); //调用.get()获取返回值会等待线程执行完
std::cout << "end... " << std::this_thread::get_id() << std::endl;
std::ThreadPool pool(4);
std::vector< std::future<int> > results;
for (int i = 0; i < 8; ++i) {
results.emplace_back(
pool.Commit([i] {
std::cout << "hello " << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "world " << i << std::endl;
return i * i;
})
);
}
std::cout << " ======= commit all2 ========= " << std::this_thread::get_id() << std::endl;
for (auto&& result : results)
std::cout << result.get() << ' ';
std::cout << std::endl;
return 0;
}
catch (std::exception& e) {
std::cout << "some unhappy happened... " << std::this_thread::get_id() << e.what() << std::endl;
}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)