Lancet Digit Health(IF=24.1)牛津大学:基于Transformer的心血管病预防性治疗人群筛选
01
文献信息

本次分享的文献是由牛津大学Kazem Rahimi教授团队联合牛津大学多个系、哈佛大学、奥克兰大学、Memorial Sloan Kettering癌症中心等多家机构于2025年6月在柳叶刀子刊《The Lancet Digital Health》(中科院1区top,IF=24.1)上发表的研究“Refined selection of individuals for preventive cardiovascular disease treatment with a transformer-based risk model”即基于Transformer模型的心血管疾病预防性治疗人群精细化筛选研究,该研究旨在通过深度学习的Transformer架构开发一个新的风险预测模型TRisk,用于预测未来10年内心血管疾病(CVD)事件风险。研究基于英国近300万成年人的电子健康记录(EHR),比较了TRisk与现行主流模型(如QRISK3、DeepSurv)的性能。结果表明,TRisk在总体人群及糖尿病亚群中均表现出显著更高的区分度(C-index约0.91),并能减少约三分之一被推荐治疗的人数,而不降低事件预防效果。
02
研究背景
1.研究问题
现有心血管疾病风险预测模型存在两大核心问题:
过度推荐治疗:传统统计模型(如QRISK3、SCORE2、ASCVD)虽广泛用于临床,但会将大量低风险人群误判为“高风险”,导致过度治疗(如英国30-79岁成人中约1/3被推荐治疗,但多数不会发生CVD事件);
特殊人群模型缺失:对糖尿病等基础疾病人群,当前指南采用“全员治疗”策略,忽略个体风险差异(如部分糖尿病患者CVD风险较低,无需常规干预),模型在该类人群中适用性不足。
2.研究难点
数据处理局限:传统模型依赖专家驱动的特征工程,难以处理电子健康记录(EHR)中“多模态、变长时序”的数据(如诊断、药物、实验室检查的动态变化);
亚组性能不稳定:传统模型对年龄依赖性强,在窄年龄范围、不同性别或社会经济地位亚组中性能显著下降;
决策平衡难题:难以同时实现“减少过度治疗”(降低高风险人群分类)和“避免漏判”(降低假阴性),二者常存在trade-off。
3.解决思路
架构创新:采用Transformer(基于BEHRT模型改进),利用其自动提取时序特征的能力,处理EHR多模态数据,无需人工特征工程;
生存分析适配:将BEHRT从二分类模型转为生存分析模型,解决随访数据中的“截尾问题”(如患者失访、研究结束时未发生事件);
迁移学习优化:先在大样本一级预防人群训练模型,再在糖尿病患者中微调,适配高风险人群特征,避免单独建模的样本量不足问题。
03
研究目标
-
开发并验证TRisk模型,实现一级预防人群和糖尿病患者的10年CVD风险精准预测;
-
对比TRisk与现有基准模型(QRISK3、DeepSurv、SCORE2-Cox模型)的性能(鉴别能力、校准度、决策净获益);
-
评估TRisk在不同亚组(年龄、性别、社会经济地位)中的稳定性,验证其对“弱势群体”的预测公平性;
-
量化TRisk的临床价值:在减少过度治疗的同时,确保CVD事件预防效果不降低。
04
Trisk模型架构
TRisk基于双向电子健康记录Transformer(BEHRT)改进,核心架构如下:
1. 输入层
多模态特征:涵盖EHR中4类核心数据,共6366个特征单元:3858种诊断、390类药物、1439项实验室检查、679个操作代码;
时序标注:每个特征单元关联患者“年龄”和“医疗服务接触时间”,形成变长时序序列(如患者A的诊断记录按“2010年(50岁)-2012年(52岁)”排序);
无人工预处理:无需缺失值插补(直接保留缺失状态作为特征)、无需人口统计学特征(如性别、社会经济地位,模型通过时序数据自动捕捉相关信息)。
2. Transformer层
注意力机制:通过自注意力(Self-Attention)捕捉不同特征间的时序关联(如“高血压诊断+利尿剂使用”的组合对CVD风险的协同影响);
双向编码:采用双向Transformer结构,同时考虑“基线前历史”的正向和反向时序依赖(如“实验室检查异常后调整药物”的因果关系)。
3. 生存分析输出层
风险函数建模:在Transformer输出后接入生存分析模块,基于Cox比例风险模型框架,输出患者的10年CVD风险概率;
截尾处理:通过对数似然损失函数优化,纳入截尾数据(如失访患者)的信息,避免偏倚。
4. 迁移学习适配
预训练阶段:在222万一级预防人群中训练模型,学习通用CVD风险时序模式;
微调阶段:在4.5万糖尿病患者中微调模型参数,适配“糖尿病+其他并发症”的特殊风险模式,提升高风险人群预测精度。
05
数据和方法
研究数据
数据来源:英国临床实践研究数据链(CPRD),覆盖291家诊所(训练)和98家诊所(验证)。
样本量:一级预防人群约297万,糖尿病患者约5.9万。
随访时间:中位2.5年(IQR0.8–5.9)。
结局定义:复合心血管事件(冠心病、缺血性卒中、短暂性脑缺血发作)。
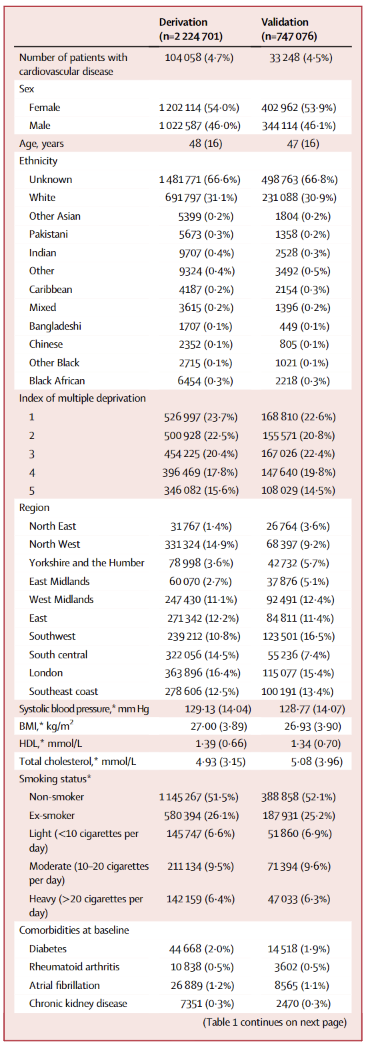
表 1:一级预防人群推导集与验证集的人口特征
研究方法
对比模型:QRISK3、DeepSurv、基于SCORE2的Cox模型。
评估指标:C指数、校准曲线、决策曲线分析、临床影响分析(高风险人数、真阳性、假阴性)。
统计方法:使用TRIPOD+AI指南报告模型性能。
06
结果与分析
1.一级预防人群核心结果
(1)鉴别能力:TRisk显著优于基准模型
|
模型 |
C 指数(95% CI) |
精确召回曲线下面积(AUC-PR) |
|
TRisk |
0.910 (0.906-0.913) |
0.892 |
|
QRISK3 |
0.831 (0.826-0.835) |
0.785 |
|
DeepSurv |
0.846 (0.841-0.850) |
0.801 |
(2)校准度:所有模型在临床阈值内表现良好
0-20%风险阈值(临床推荐治疗阈值范围)内,TRisk、QRISK3、DeepSurv的校准曲线均接近对角线;
仅QRISK3在高风险区间(>15%)略有高估(预测风险高于实际风险),TRisk校准最稳定。
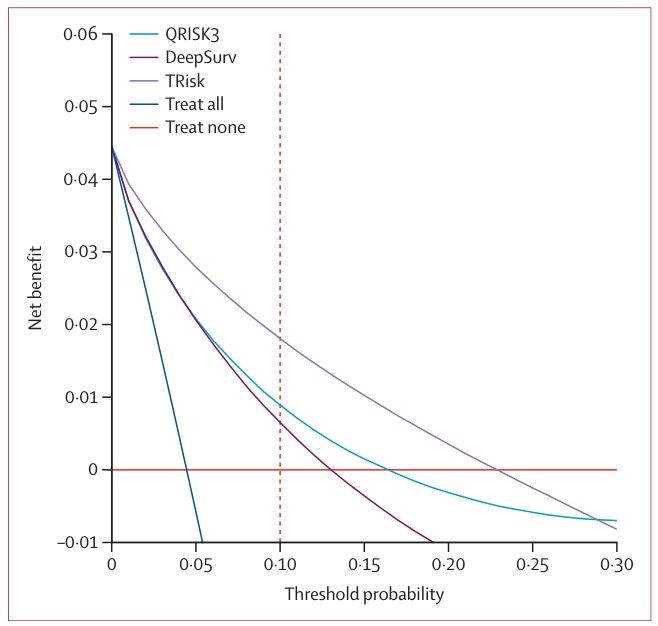
图 2:决策曲线分析(DCA)
(3)风险分布:TRisk分类更极端,减少“中间模糊人群”
TRisk将23.5%患者归为“极低风险(<5%)”或“极高风险(>20%)”,而QRISK3仅12.1%;
基准模型风险分布集中在8%-15%,导致大量“中间风险人群”难以决策,TRisk可减少此类模糊分类。
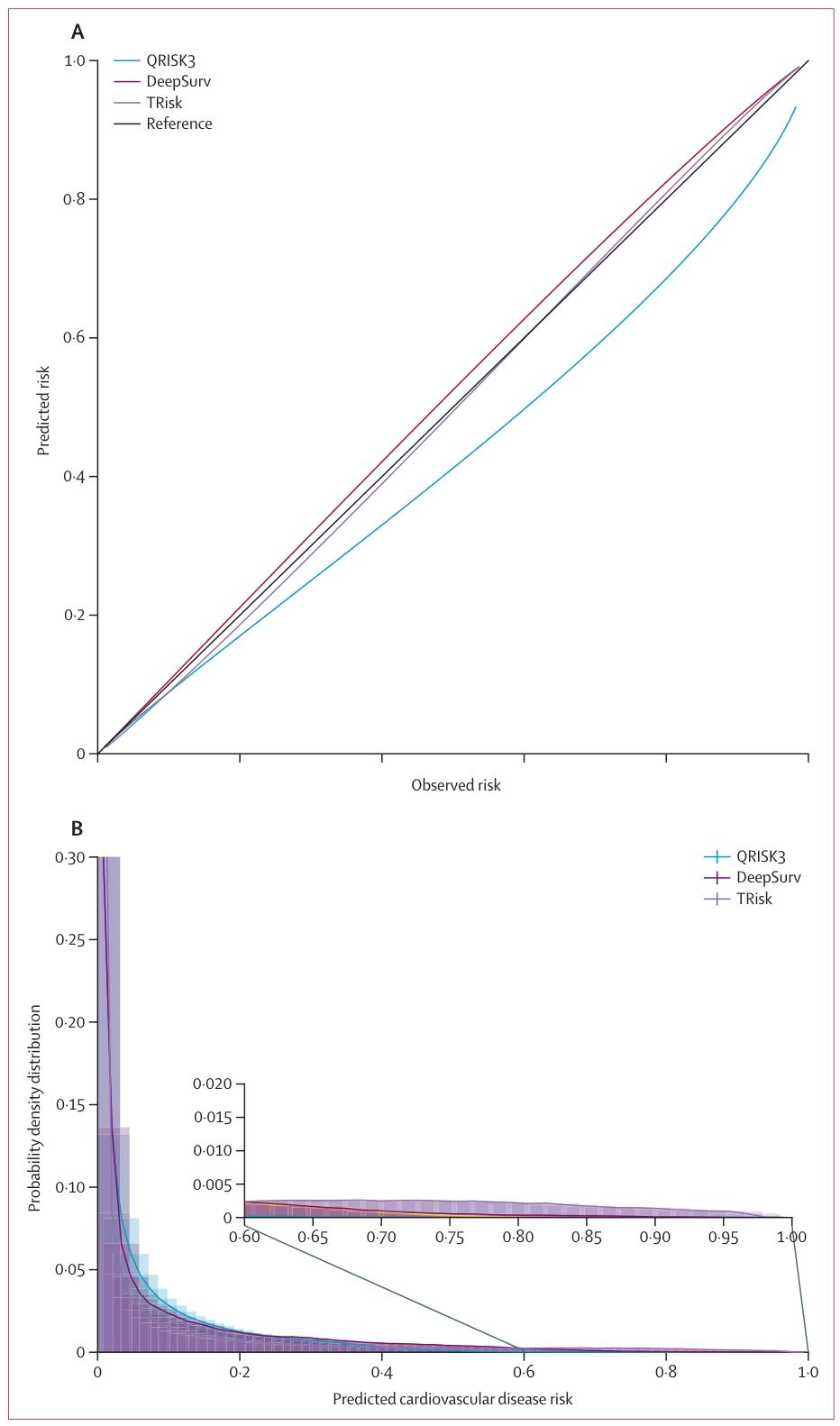
图 1:模型校准图与预测风险分布
(4)临床影响:减少过度治疗且降低漏判
以1000名一级预防人群为基准,不同阈值下的对比结果:
10%阈值下,QRISK3高风险272人(真阳36、假阴9),TRisk高风险216人(↓20.6%,真阳40、假阴5);
15%阈值下,QRISK3高风险187人(真阳29、假阴15),TRisk高风险178人(↓34.6%,真阳37、假阴8);
20%阈值下,QRISK3高风险131人(真阳24、假阴21),TRisk高风险152人(真阳35、假阴10)。
此外,全员治疗全归高风险(真阳45),不治疗无高风险(假阴45)。
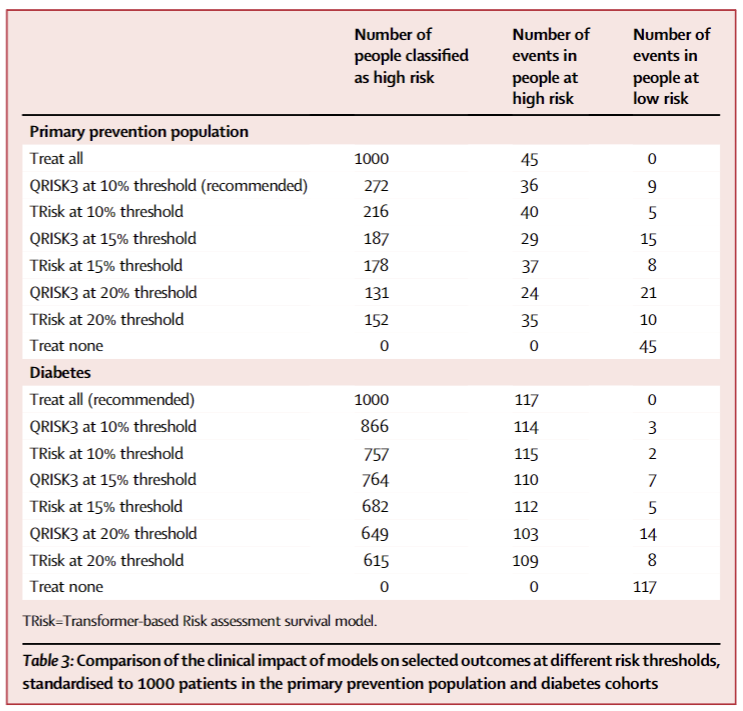
表 3:不同风险阈值下各模型的临床影响(标准化至 1000 人)
2.糖尿病患者核心结果
鉴别能力:TRisk的C指数(0.895,95%CI0.887-0.903)高于QRISK3(0.812)和DeepSurv(0.828);
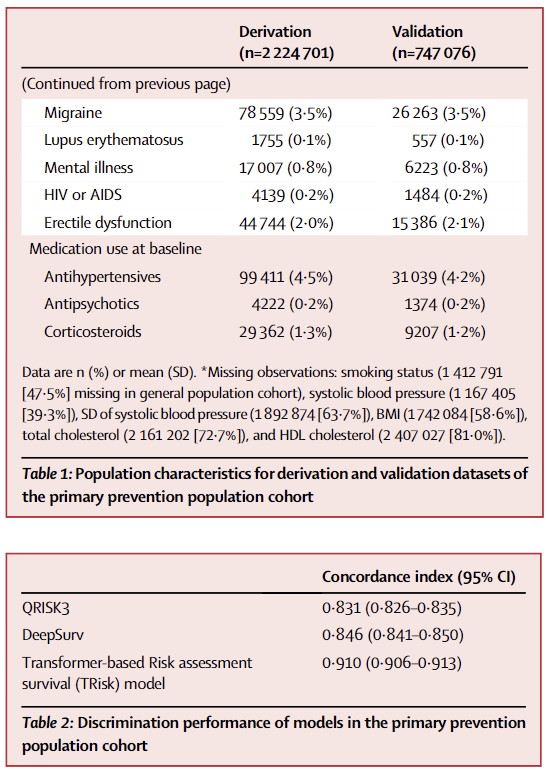
表 2:一级预防人群中各模型的鉴别性能(C 指数对比)
临床影响:
对比“全员治疗”策略:TRisk在10%阈值下减少24.3%治疗推荐(757/1000vs1000/1000),假阴性仅2例(0.2%);
对比QRISK3(10%阈值):TRisk减少12.6%高风险人群(757/1000vs866/1000),真阳性多1例(115vs114)。
3.亚组性能:TRisk稳定性更优
年龄亚组:在窄年龄范围(40-69岁)中,TRisk的C指数(0.902)较QRISK3(0.815)优势扩大(差值从0.079增至0.087);
性别与社会经济亚组:TRisk在男性/女性、不同IMD分层中C指数差异<0.02,而QRISK3在贫困人群(IMD1分)中C指数下降0.05(从0.831降至0.781)。
07
结论
性能优势:TRisk在一级预防人群和糖尿病患者中,10年CVD风险预测的鉴别能力、校准度和决策净获益均显著优于传统模型(QRISK3、DeepSurv等);
亚组稳定性:TRisk对年龄、性别、社会经济地位的依赖性低,在各亚组中性能一致,可减少健康不平等;
临床价值:TRisk可减少约1/3一级预防人群、1/4糖尿病患者的治疗推荐,同时降低假阴性率,实现“精准医疗+资源节约”双赢;
可及性:TRisk仅依赖常规EHR数据,无需额外检查(如基因检测、生物标志物),便于在基层医疗推广。
08
讨论
1.创新方向
技术创新:首次将Transformer架构用于CVD生存风险预测,突破传统模型“手工特征工程”的局限,自动挖掘EHR中的时序关联(如“药物调整后实验室指标变化”对风险的影响);
方法创新:通过迁移学习实现“通用人群→特殊人群”的模型适配,解决糖尿病队列样本量不足的问题,为其他基础疾病(如慢性肾病)的风险预测提供范式;
评估创新:结合“决策曲线分析”和“临床影响量化”,从“统计性能”到“实际临床价值”形成闭环评估,避免模型仅停留在理论层面。
2.临床价值
减少过度医疗:按英国人口估算,TRisk可减少约350万一级预防人群的他汀/降压药推荐,降低药物不良反应(如他汀相关肌肉疼痛)和医疗成本;
优化糖尿病管理:替代“全员治疗”策略,使24.3%低风险糖尿病患者避免不必要治疗,同时确保高风险者不被漏判;
推动基层医疗效率:基层医生无需掌握复杂风险评分规则,TRisk可基于EHR自动输出风险分层,辅助快速决策。
3.局限性
数据代表性:仅基于英国CPRD数据,需在其他国家/地区(如美国、中国)进行外部验证,确认模型跨人群适用性;
随访时间:中位随访2.5年,部分患者缺乏完整10年随访数据,虽与同类研究一致,但长期预测精度需进一步验证;
可解释性:Transformer模型存在“黑箱”问题,虽BEHRT既往研究已挖掘部分风险因素(如缺铁性贫血与心衰关联),但TRisk的具体预测机制仍需更深入的解释性分析;
部署挑战:TRisk依赖完整EHR数据和计算资源,无法简化为“纸质评分表”,需开发轻量化工具(如离线计算模块)适配基层医疗的低算力环境。
4.未来展望
外部验证:在北美、欧洲、亚洲等不同医疗体系中验证TRisk性能,优化模型适配性;
多组学融合:纳入基因组、代谢组数据,提升对“罕见高风险人群”的预测精度;
实时部署:开发临床决策支持系统(CDSS),将TRisk集成到电子病历系统,实现“患者就诊时自动生成风险报告”;
长期效果评估:开展随机对照试验,对比“TRisk指导治疗”与“传统模型指导治疗”的长期CVD事件发生率,验证其因果效应。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)