小米自动驾驶大模型 OneVL 全面开源,推理延迟低至 0.24 秒!

「让大模型推理“又快又准”」
Xiaomi OneVL自动驾驶模型是小米公司于2026年5月13日正式发布并全面开源的自动驾驶技术框架。
该模型在行业内首次实现了VLA(视觉语言动作)、世界模型和潜空间推理三大技术路线的统一,通过潜空间推理技术大幅提升决策速度和精度,推理延迟最低达0.24秒,性能超越传统方案。
雷军在社交媒体宣布开源后,全球开发者可通过GitHub获取模型权重及代码,共同推进自动驾驶技术发展。该模型在NAVSIM基准测试中获得88.84分,成为首个在潜空间推理中超越显式CoT(Explicit CoT)的方法。
01 基本原理和框架
OneVL以开源预训练视觉语言大模型(Qwen3-VL-4B-Instruct)作为基础底座,模型整体沿用大模型的基础结构,在此之上增设专属的潜在令牌交互结构与辅助监督模块,整体采用训练阶段多模块协同、推理阶段精简结构运行的设计模式,整体架构与训练范式均可参考项目开源文档与论文原文。
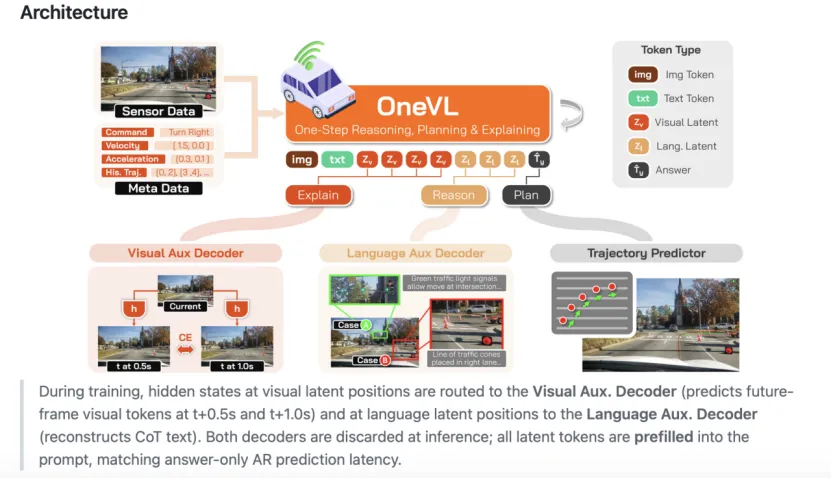
潜在令牌是模型设置的一组可学习特征向量,这类向量不生成可读文本,只用来承载驾驶场景的空间特征、运动关联与推理逻辑信息,就像程序的二进制代码,不是给人读的信息。
框架在模型前向传播的固定位置插入一定数量的视觉潜在令牌与语言潜在令牌,视觉潜在令牌用来编码道路场景、障碍物形态、车辆姿态等视觉维度信息,语言潜在令牌用来编码交通规则、场景语义、决策逻辑等语言维度信息。所有潜在令牌构成信息筛选的中间瓶颈,模型只会保留和驾驶因果关联度较高的特征内容,减少无关冗余信息对轨迹预测的干扰。
框架搭配双路辅助解码器结构,两路解码器只参与模型训练过程,正式推理运行时不会保留,不会给模型带来额外时延开销。语言辅助解码器依托语言潜在令牌做内容还原,把压缩在特征向量里的推理逻辑转化为可读的自然语言描述,让模型在特征学习过程中对齐语义推理逻辑,也让模型决策过程具备可追溯的语言解释依据。
视觉世界模型解码器依托视觉潜在令牌做未来场景推演,世界模型是能够依据当前环境状态预判后续环境变化的模块,该解码器可以预测短时间内的道路画面变化,让视觉潜在令牌学习真实场景的物理运动规律与时空关联关系,补足单纯语言语义无法覆盖的空间动态细节。
模型整体采用分阶段渐进式训练方式,用来规避多模块同时优化带来的训练不稳定问题。
- 第一阶段为基础模型预热,保持辅助解码器处于冻结状态,只对基础视觉语言模型与潜在令牌做联合训练,让模型初步建立潜在令牌特征和轨迹预测任务之间的关联关系。
- 第二阶段为辅助解码器预热,保持基础主模型参数固定,分别训练语言辅助解码器与视觉世界模型解码器,让两路解码器具备从固定潜在令牌中还原文本、推演场景图像的能力,完成辅助模块的基础适配。
- 第三阶段为全模块联合微调,开放所有模块的参数更新通道,各模块之间双向传递梯度信息,进一步收紧潜在令牌的信息瓶颈,强化模型对驾驶场景因果动态特征的学习能力,整套训练流程的细节配置在开源代码仓库中可查阅复现。
在实际推理运行阶段,框架不再启用两路辅助解码器,所有视觉与语言潜在令牌以并行方式一次性完成信息填充,不需要按照步骤逐一生成推理内容,仅保留轨迹预测分支做自回归输出。这样的运行方式可以把推理时延控制在较低水平,整体运行耗时和只做轨迹输出、无额外推理环节的模型保持相近水准,相关时延与推理机制的实验数据均来自论文公开实验结果。
02 主要优点及与同类方案对比
OneVL在自身架构设计之外,在实际任务表现、运行时延、可解释维度与部署适配层面都具备相应优点。在公开的自动驾驶评测基准当中,OneVL在轨迹预测相关评价指标上的表现,能够达到显式思维链模型的水准,同时超过同类型多数潜在推理框架的表现,所有基准实验结果均来源于论文官方测试统计。
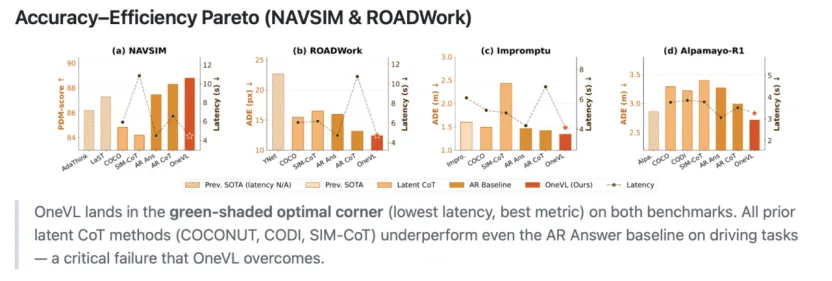
上面这张“Accuracy–Efficiency Pareto (NAVSIM & ROADWork)”对比图,展示了OneVL在NAVSIM、ROADWork、Impromptu、Alpamayo-R1四个自动驾驶轨迹预测基准上的表现,每个基准对应不同的真实驾驶场景与评价逻辑:
NAVSIM是面向城市场景的大规模自动驾驶仿真基准,以PDM-score作为评价指标,衡量轨迹预测与真实驾驶行为的匹配度;ROADWork聚焦复杂道路与路口交互场景,Impromptu关注突发交通参与者的动态变化场景,Alpamayo-R1则覆盖多样化的跨城驾驶环境,后三者均以ADE(平均位移误差)作为精度指标,数值越低代表预测轨迹与真实轨迹的偏差越小。
图中每个基准下,柱状条表示不同模型的精度表现,虚线点线表示对应模型的推理延迟(单位:秒,数值越低代表效率越高),其中浅纹柱形代表过往最优方案,浅橙柱形代表无推理的基线模型,中橙柱形代表潜在思维链(Latent CoT)模型,深橙柱形代表无额外推理的自回归基线模型,红色柱形为OneVL的表现。
可以看到,在所有四个基准中,OneVL的精度指标均处于对比模型的前列,同时推理延迟保持在接近基线模型的低位水平,处于“低延迟+高精度”的优势区域;而过往的潜在思维链模型,要么精度不及无推理基线模型,要么延迟偏高,OneVL在兼顾实时性的同时实现了性能反超,解决了传统潜在推理方案在驾驶任务中的适配问题。
框架采用潜在令牌并行填充的推理机制,运行过程省去分步生成推理文本的耗时,整体时延相比显式思维链模型有明显缩减,和不搭载推理结构的基础轨迹模型时延差距较小,更适配自动驾驶车载设备对实时性的运行要求。
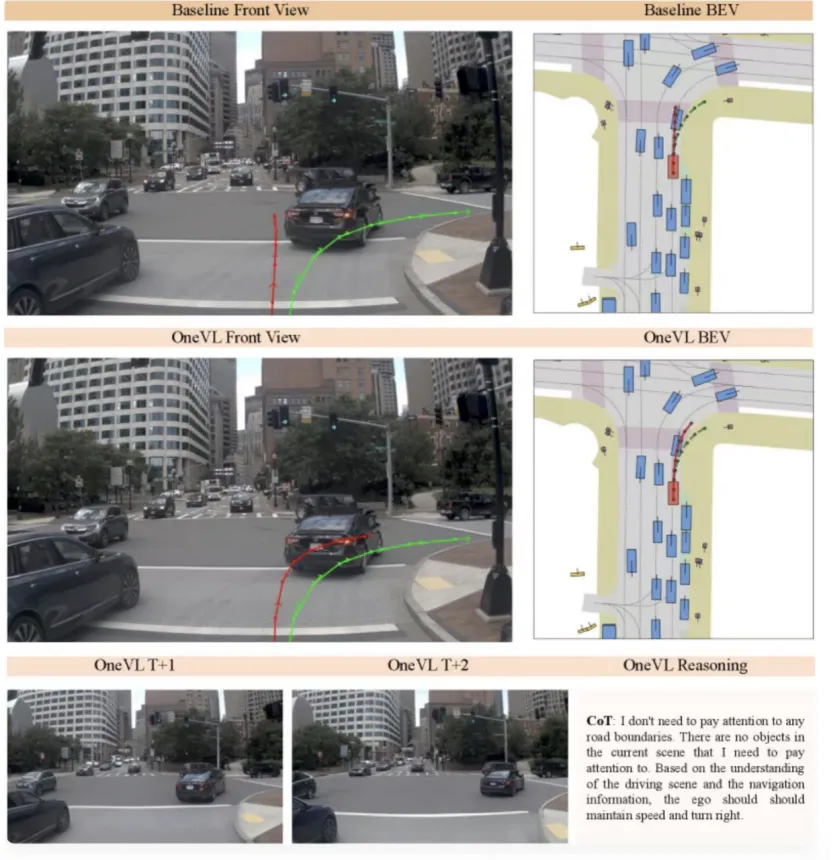
框架同时具备语言维度与视觉维度的解释能力,既可以输出自然语言形式的决策推理描述,也可以生成未来短时场景的推演画面,相比只提供单一语言解释的模型,可参考的信息维度更为丰富,便于研发人员做场景调试、问题定位与效果验证,双模态可解释能力的实现逻辑在项目主页技术介绍中有完整说明。
模型依托中等参数量的基础视觉语言模型完成架构搭建,在达到较高轨迹预测表现的前提下,模型整体体量更为精简,对车载边缘硬件的资源占用更为友好,适配轻量化设备的部署条件。
为了让 AI思考有可解释性和更类似人,行业常规做法是引入显式思维链。这种方式决策确实准,但其逐字生成的自回归特性带来极高延迟。在自动驾驶中,慢是不可忍受的。
如果跳过推理过程,直接让模型输出轨迹,速度虽然快了,但系统又退化成了黑盒。
和显式思维链类方案相比,显式思维链依靠逐一生成推理文本辅助决策,推理步骤较多,运行时延偏高,在实时性要求较强的车载场景适配度有限;OneVL采用潜在特征并行推理的模式,不用逐一生成文本推理内容,时延可以得到有效控制,同时轨迹预测指标能够达到更高水准,还能同时提供语言与视觉两类解释信息。

和过往传统潜在思维链方案相比,传统潜在推理框架大多只依靠语言语义做特征监督,很难完整学习驾驶场景的物理时空规律,整体任务表现常常达不到显式思维链的水准;OneVL增加视觉世界模型解码器做同步监督,让潜在特征同时学习语义逻辑与场景动态规律,任务表现可以实现提升,同时补充了视觉推演的解释维度。
和主流同领域视觉语言行动模型相比,部分同类方案依赖更大参数量的基础模型支撑效果,硬件部署门槛偏高;OneVL以中等参数量模型为底座,依靠架构创新与多模块监督策略提升表现,在控制模型体量的同时,保持轨迹预测与实时运行的综合能力,在落地部署层面拥有更好的适配空间。
相关消融实验可以体现框架各模块的作用,取消视觉世界模型解码器后,轨迹预测评价指标会出现回落;取消语言辅助解码器,指标也会产生小幅波动;跳过分阶段渐进式训练流程,直接做全模块联合训练,模型整体表现会出现明显下滑,能够看出双路辅助解码器与分阶段训练流程,对OneVL的整体表现有着重要支撑作用,消融实验的完整数据可查阅论文附录部分。
03 总结
OneVL是小米具身智能团队围绕自动驾驶轨迹预测场景,针对传统视觉语言行动模型推理时延与任务表现难以兼顾的现状打造的技术框架。框架以潜在令牌作为信息承载与特征筛选的载体,搭配语言与视觉双路辅助解码器做训练监督,借助分阶段渐进式训练完成多模块协同优化,推理阶段精简结构实现低时延运行。
框架的设计形态,让潜在推理模式不再需要牺牲任务表现换取低时延,拉近了潜在推理与显式推理的效果差距,同时增添视觉场景推演的解释维度,丰富了模型决策的可追溯性。相比同类型各类方案,OneVL在任务表现、实时时延、可解释能力与轻量化部署适配层面都有自身适配特点,中等参数量底座的架构设计,也降低了自动驾驶车载端的落地门槛。
OneVL完成代码与项目资料的开源开放,可为自动驾驶视觉语言行动领域的算法研究、模型迭代与工程落地提供参考范式[1][2][3]。后续还可在多类传感器信息融合、复杂极端交通场景泛化、多任务拓展适配等方向继续完善,让框架在真实道路自动驾驶应用场景中拥有更广的适用范围。
参考文献
[1] arXiv论文:https://arxiv.org/abs/2604.18486
[2] OneVL项目主页:https://xiaomi-embodied-intelligence.github.io/OneVL
[3] GitHub开源仓库:https://github.com/xiaomi-research/onevl

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)