【重磅】SceneEngine V3.5 场景驱动的AI编程范式
从对话到构建的深度揭秘——当AI编程助手不再只是"问答机器",而是拥有场景感知、知识分层和Agent协作能力的"架构师",软件开发的范式将发生根本性变革。
OODER A2UI · 深度技术揭秘 · 2026
1 问题:为什么当前的AI编程不够"聪明"?
你有没有遇到过这样的场景:
// 第一轮对话——一切看起来很美好
用户: "我需要建立一个部门管理"
AI: 生成一个 NavTree 组件 ✅
// 第二轮对话——AI"失忆"了
用户: "加一个搜索功能"
AI: ???——搜索什么?在哪个组件上加?和之前的部门管理有什么关系?
⚠️ 根本原因:三个核心断层
1. 对话历史与场景脱钩:每次对话都是"失忆"的,AI不知道你在哪个业务场景中
2. 知识库无场景隔离:部门管理的知识和角色管理的知识混在一起,AI无法精准获取
3. Agent链路缺少知识路由:AI不知道该找哪个Agent、用什么知识来回答
这三个断层不是孤立的bug,而是系统性架构缺陷。传统AI编程系统把所有对话当作一个"大锅饭",所有知识混在一个"大仓库",所有Agent排成一条"大长队"——这在简单场景下勉强可用,一旦进入复杂业务系统构建,就会暴露出严重的上下文丢失、知识混淆和Agent误路由问题。
2 破局:场景驱动的三层架构
我们提出场景驱动的三层架构,将AI编程从"无状态问答"升级为"有状态场景协作":

图1:场景驱动的三层架构——对话层驱动知识层,知识层驱动Agent层,形成闭环
💡 架构核心思想
三层不是简单的分层,而是闭环驱动:场景对话积累上下文 → 上下文驱动知识路由 → 知识路由选择Agent → Agent执行结果更新上下文。每一层都是上一层的"感知器",也是下一层的"决策源"。
3 Layer 3:场景对话层——让AI拥有"记忆"
3.1 核心设计
每个场景拥有独立的对话历史,AI在场景内是"有记忆"的:
Turn 1:用户 → “我需要建立一个部门管理”
AI → NavTree组件(自包含树形)
intent=CREATE type=NavTree
Turn 2:用户 → “加一个搜索功能”
AI → 增量修改: Block中添加SearchInput
intent=MODIFY type=NavTree ESSENTIAL→COMPLETE
Turn 3:用户 → “搜索要支持按部门名称筛选”
AI → SearchInput添加filterBy属性
intent=MODIFY type=NavTree COMPLETE→POLISHED
3.2 SceneContextWindow——场景的"工作记忆"
public classSceneContextWindow {
private String sceneGroupId; // 场景标识
private String currentIntent; // 当前意图: CREATE / MODIFY_UI
private String currentComponentType;// 当前组件: NavTree / NavGroup
private String currentModuleName; // 当前模块: DepartmentManagement
private List<String> accumulatedFields; // 累积字段: [deptName, deptCode, parentId]
privateint turnCount; // 对话轮次
privateDisclosureLevel currentLevel; // SKELETON→ESSENTIAL→COMPLETE→POLISHED
}Java
🔧 关键改造
NlpDesignService中sceneId从硬编码"rad"改为sceneGroupId(projectName),让Pipeline知道自己在哪个场景中工作。这个看似简单的改动,解决了"所有场景共享同一个对话历史"的根本问题。
4 Layer 2:场景知识层——让AI拥有"专业领域知识"
4.1 三层知识架构
这是整个范式最核心的创新——知识不再是一锅粥,而是按场景分层组织:
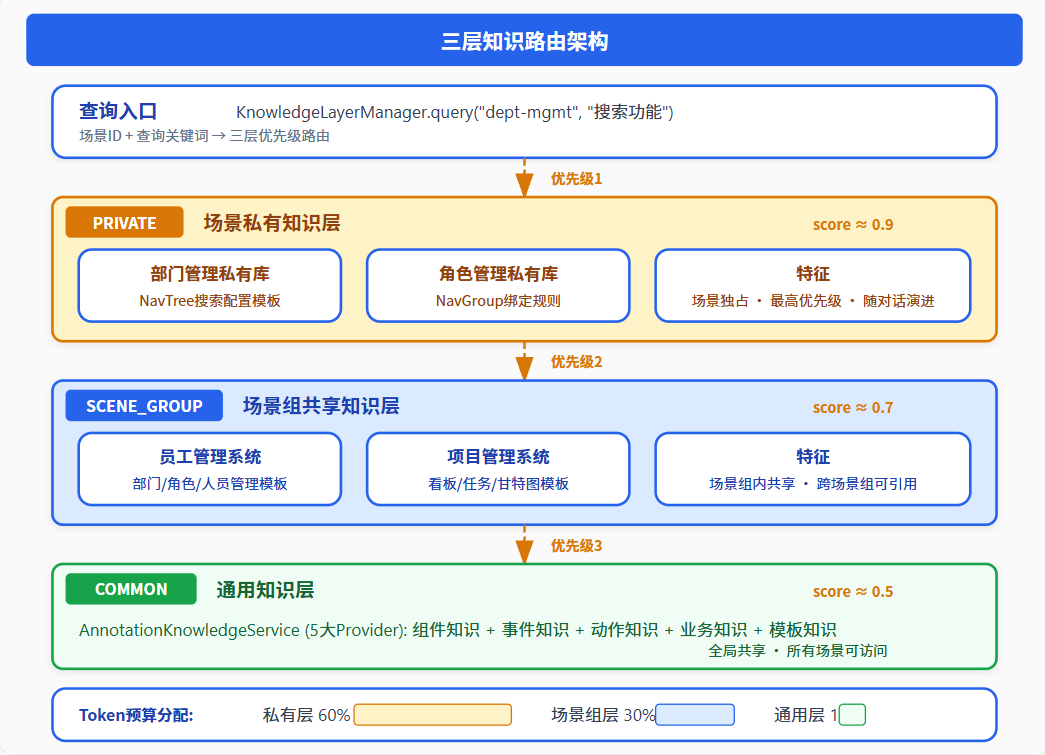
图2:三层知识路由架构——PRIVATE(私有)→SCENE_GROUP(场景组)→COMMON(通用),优先级递减
4.2 知识路由——三层优先级查询
当用户在"部门管理"场景中说"加一个搜索功能":
PRIVATE层: NavTree搜索配置模板 score=0.95 ← 命中!
SCENE_GROUP层: 员工管理系统搜索模式 score=0.80 ← 补充
COMMON层: SearchInput组件知识 score=0.60 ← 兜底
📊 Token预算分配
私有层 60% + 场景组层 30% + 通用层 10%
越靠近场景的知识越精准,分配的Token预算越多——这确保了AI优先使用最相关的领域知识。
4.3 场景感知的渐进式披露
传统渐进式披露基于全局置信度,我们改为知识层完整度 + 对话轮次双因素驱动:
| 知识层状态 | 披露级别 | 输出内容 |
|---|---|---|
| 私有层有完整模板 | COMPLETE | 完整组件+事件+数据绑定 |
| 私有层有部分知识 | ESSENTIAL | 核心字段+基础事件 |
| 仅场景组层知识 | SKELETON | 组件框架结构 |
| 仅通用层知识 | SKELETON + 澄清 | 骨架+请求用户确认 |
❌ 升级策略(旧)
基于全局置信度,无场景感知,容易过早或过晚升级
✅ 升级策略(新)
每2轮对话自动升级一级:SKELETON→ESSENTIAL→COMPLETE→POLISHED
降级策略:混合编辑冲突→降一级;编译前检验失败→降一级。降级不是失败,而是自适应调整——确保输出质量始终可控。
5 Layer 1:场景Agent层——让AI拥有"协作能力"
5.1 知识感知Agent路由
传统Agent路由只做命令转发,我们让Agent路由感知知识:
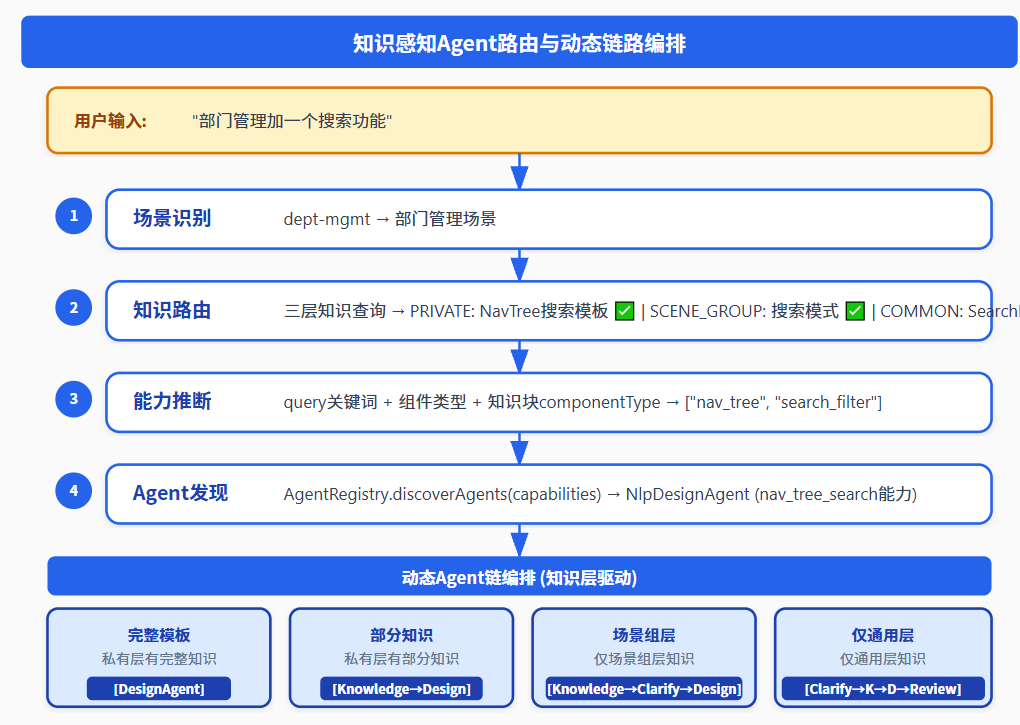
图3:知识感知Agent路由——4步从用户输入到Agent发现,每一步都有知识层参与决策
5.2 动态Agent链编排
根据知识层查询结果,动态编排Agent调用链——不是固定流程,而是自适应的:
| 知识层状态 | Agent链路 | 说明 |
|---|---|---|
| 私有层有完整模板 | DesignAgent | 单Agent足够,知识充分 |
| 私有层有部分知识 | KnowledgeAgent → DesignAgent | 先检索再设计 |
| 仅场景组层 | KnowledgeAgent → ClarifyAgent → DesignAgent | 检索+澄清+设计 |
| 仅通用层 | ClarifyAgent → KnowledgeAgent → DesignAgent → ReviewAgent | 完整链路 |
⏱️ 超时控制
每步 30秒,总链路 120秒,超时自动终止。动态链路不是无限等待,而是在可控时间内给出最优结果。
6 完整流程推导:以"员工管理系统"为例
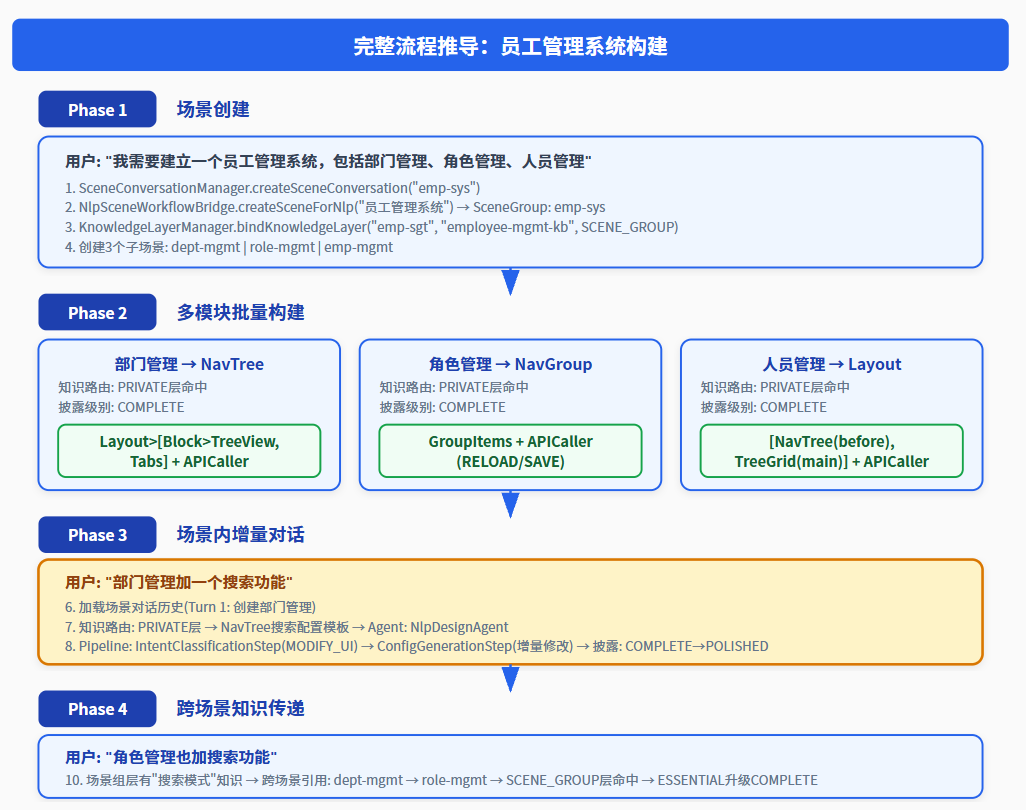
图4:员工管理系统完整构建流程——从场景创建到跨场景知识传递的4个Phase
Phase 1: 场景创建
用户: "我需要建立一个员工管理系统,包括部门管理、角色管理、人员管理"
1. SceneConversationManager.createSceneConversation("emp-sys")
2. NlpSceneWorkflowBridge.createSceneForNlp("员工管理系统")
→ SceneGroup: emp-sys (ACTIVE)
3. KnowledgeLayerManager.bindKnowledgeLayer("emp-sys", "employee-mgmt-kb", SCENE_GROUP)
4. 创建3个子场景:
├── dept-mgmt → 绑定NavTree私有知识
├── role-mgmt → 绑定NavGroup私有知识
└── emp-mgmt → 绑定TreeGrid私有知识
Phase 2: 多模块批量构建
部门管理 → NavTree
知识路由: PRIVATE层命中NavTree配置模板
披露级别: COMPLETE
生成: Layout>Block>TreeView, Tabs + APICaller
角色管理 → NavGroup
知识路由: PRIVATE层命中NavGroup配置模板
披露级别: COMPLETE
生成: GroupItems + APICaller(RELOAD/SAVE)
人员管理 → Layout
知识路由: PRIVATE层命中TreeGrid/Layout模板
披露级别: COMPLETE
生成: NavTree(before), TreeGrid(main) + APICaller
Phase 3: 场景内增量对话
用户: "部门管理加一个搜索功能"
6. SceneConversationManager.getSceneMemory("dept-mgmt")
→ 加载场景对话历史(Turn 1: 创建部门管理)
7. SceneAgentRouter.route("dept-mgmt", "搜索功能")
→ 知识路由: PRIVATE层 → NavTree搜索配置模板
→ Agent发现: NlpDesignAgent(nav_tree_search能力)
8. NlpPipelineContext:
├── sceneId = "dept-mgmt"// 不再硬编码
├── conversationHistory = 场景对话历史
└── previousResult = 场景上下文窗口
9. Pipeline执行:
→ IntentClassificationStep: MODIFY_UI意图
→ ConfigGenerationStep: 增量修改NavTree
→ 披露级别: COMPLETE → POLISHED
Phase 4: 跨场景知识传递
用户: "角色管理也加搜索功能"
10. 场景组层有"员工管理系统搜索模式"知识
11. 跨场景引用: dept-mgmt → role-mgmt (search-pattern)
12. KnowledgeLayerManager.query("role-mgmt", "搜索功能")
├── PRIVATE: NavGroup配置模板(无搜索相关)
├── SCENE_GROUP: 搜索模式(来自dept-mgmt的积累) ✅
└── COMMON: SearchInput组件知识
13. 披露级别: SCENE_GROUP有搜索模式 → ESSENTIAL
→ 跨场景引用有完整搜索实现 → 升级到COMPLETE
💡 跨场景知识传递的妙处
在"部门管理"场景中积累的搜索功能知识,通过场景组层自动传递到"角色管理"场景——无需重复描述,AI自动复用。这就是场景组层的核心价值:一次积累,组内共享。
7 Pipeline→SceneWorkflow:让构建过程可追溯
传统Pipeline是串行黑盒,我们通过SceneWorkflowPipelineAdapter将12步骤映射到SceneWorkflow:
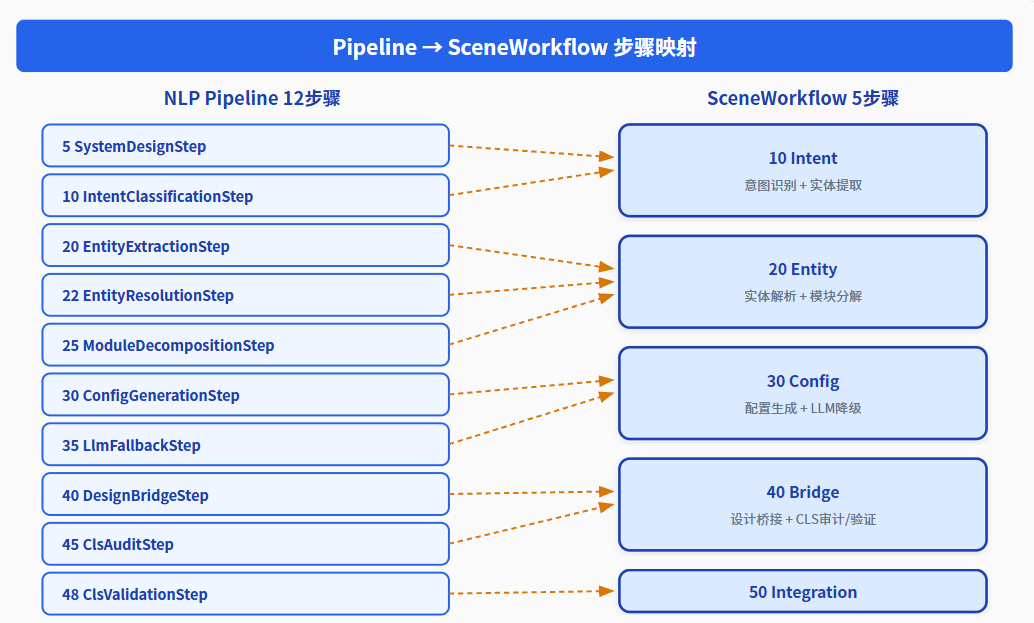
图5:Pipeline 12步骤 → SceneWorkflow 5步骤映射,每一步可追踪可回溯
每一步的完成状态、执行时长、结果摘要都被SceneWorkflow记录,支持:
工作流状态查询:getWorkflowStatus(sceneGroupId)——随时查看当前构建进度
步骤级追踪:recordStepCompletion(sceneGroupId, stepName, ...)——精确到每一步
与Undo/Redo联动:基于SceneSnapshot的快照恢复——构建过程可回退
8 编译前检验:5道防线确保生成质量
在代码写入VFS之前,5个检测器自动执行:
| 检测器 | 检测码 | 核心功能 |
|---|---|---|
| §6.1 DataMeta一致性 | DM-001~DM-005 | @CustomClass注解与NlpMetaBuilder映射校验 |
| §6.2 .cls结构完整性 | CS-001~CS-031 | 空壳检测/组件结构/字段结构/APICaller事件 |
| §6.3 URL配置 | UC-001~UC-011 | moduleName/componentType + APICaller queryURL |
| §6.4 工作流前置 | WP-001~WP-015 | intent/confidence/componentType/entities/验证状态 |
| §6.5 快照一致性 | SC-001~SC-032 | SnapshotManager/UndoRedoManager/VfsBridge可用性 |
🔬 关键创新
检测器不是简单的规则校验,而是反射级类型兼容性检查——自动检测@CustomClass注解与NlpMetaBuilder使用的UIComponent类型是否一致,从根源上杜绝了".cls空壳"问题。
这个创新源于一次真实的Bug追踪:DataMeta类型不匹配导致ClassCastException→组件构建失败→降级为空壳.cls文件。5道防线确保此类问题在写入VFS之前就被拦截。
9 技术实现清单
| 模块 | 核心文件 | 核心能力 |
|---|---|---|
| 场景对话 | SceneConversationManager | 场景级对话历史+上下文窗口+跨场景引用 |
| 场景上下文 | SceneContextWindow | 意图/组件/模块/字段/轮次/披露级别 |
| 三层知识 | KnowledgeLayerManager | PRIVATE/SCENE_GROUP/COMMON三层路由+SDK联动 |
| 知识类型 | KnowledgeLayerType | 三层优先级枚举 |
| 知识查询 | KnowledgeQueryResult | 三层分块+路由追踪+模板检测 |
| 渐进披露 | SceneDisclosureStrategy | 知识层+对话轮次双因素驱动+升级/降级 |
| Agent路由 | SceneAgentRouter | 知识感知路由+中英文能力推断+Agent发现 |
| Agent编排 | AgentChainOrchestrator | 动态链路+知识层驱动+超时控制 |
| 技能关联 | SceneSkillRelationManager | 场景↔技能绑定+知识范围+优先级 |
| Pipeline适配 | SceneWorkflowPipelineAdapter | Pipeline→SceneWorkflow步骤映射+状态追踪 |
| 编译前检验 | NlpPreBuildValidator | 5个检测器+检测码体系+Pipeline集成 |
10 总结:从"问答"到"协作"的范式跃迁
场景驱动的AI编程范式,本质上是三个转变:
❌ 旧范式:无状态问答
对话无记忆,每次都是"从零开始"
知识一锅粥,精准度无法保证
Agent固定链路,无法自适应
✅ 新范式:有状态协作
从无状态到有状态:每个场景拥有独立的对话历史和上下文窗口,AI不再"失忆"
从通用知识到分层知识:私有→场景组→通用三层知识路由,AI获得精准的领域知识
从单Agent到协作链:知识感知的Agent路由和动态链路编排,AI拥有了协作能力
🔄 闭环驱动
这三个转变共同构成了一个闭环:
场景对话积累上下文 → 上下文驱动知识路由 → 知识路由选择Agent → Agent执行结果更新上下文
这不是简单的功能叠加,而是编程范式的根本性变革——AI从"代码生成器"进化为"场景架构师"。
本文基于OODER A2UI平台实际代码实现,所有架构设计均已在代码库中落地。场景驱动不是概念,而是已经在生产环境中运行的编程范式。
OODER A2UI · 场景驱动的AI编程范式
基于实际代码实现的技术深度揭秘 | 2026

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)