2026必懂!20个AI核心概念,小白也能看懂的底层逻辑与未来趋势
编者摘要:本文用无专业术语、通俗可视化的方式,讲解2026年必须掌握的20个AI****核心概念,按AI基础原理、LLM运行机制、模型优化方法、真实AI****系统构建四大模块展开,清晰说明神经网络、Transformer、LLM、RAG、AI智能体等核心技术的作用与逻辑,覆盖文本生成、图像生成、模型微调、部署优化等关键环节,帮助普通人快速理解AI 工作原理与实用价值。
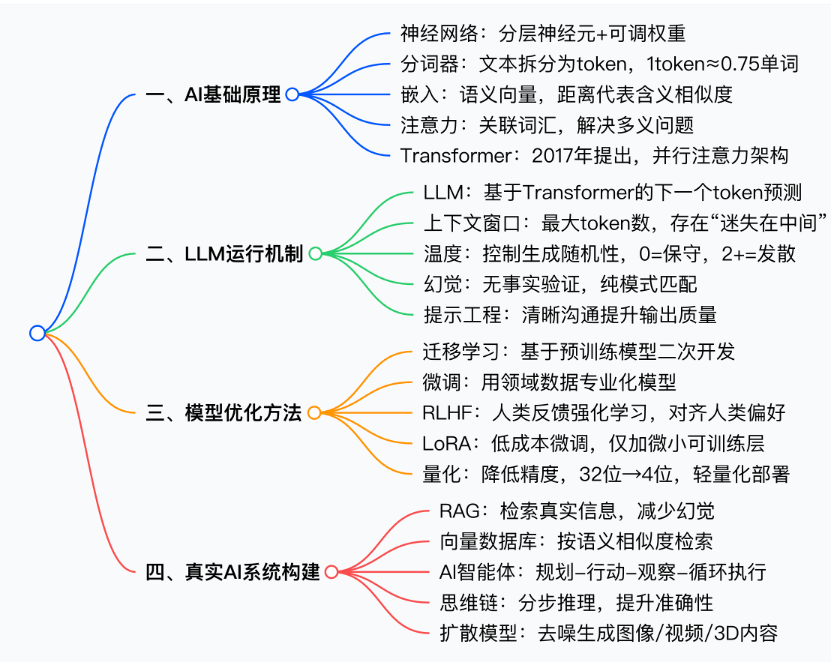
本文围绕20个AI****核心概念,分四大模块系统拆解AI 技术逻辑,关键信息与数字清晰明确,具体如下:
- AI 基础原理(架构与数据处理)
===================
-
神经网络:
AI 模型核心,由输入层、隐藏层、输出层组成,通过调整权重实现精准预测;GPT-4 约1.8****万亿参数,Claude 3 Opus 达数百亿参数。
-
分词器:
将文本拆分为token,非完整单词;1token≈0.75****个单词,适配新词、拼写错误等复杂语言场景。
-
嵌入:
将token 转为语义向量,向量距离代表含义相似度,支撑语义搜索、推荐、RAG。
-
注意力机制:
让词汇相互关联,解决多义问题,支持模型一次性处理整句文本。
-
Transformer:
2017 年谷歌提出,现代AI 主流架构,基于注意力并行处理,训练更快、输出更优。
- LLM 运行机制(对话AI 核心逻辑)
======================
-
LLM**(大型语言模型):**
基于Transformer,在万亿token 数据上训练,核心任务为预测下一个****token,参数规模达数千亿。
-
上下文窗口:
模型单次处理最大token 数,早期GPT 约4000token,GPT-4 为128000token,Claude 3.5 为200000token,Gemini 1.5 Pro 达1000000token;存在迷失在中间问题,首尾记忆更强。
-
温度:
生成随机性调节器;**0 =**保守精准,**1 =**自然创意,**2+=**混乱发散。
-
幻觉:
LLM 无事实验证,仅预测最可能token,易生成虚假信息,需RAG 修复。
-
提示工程:
通过背景、角色、示例、具体要求提升输出质量,是与模型沟通的核心方式。
- 模型优化方法(低成本高效迭代)
==================
| 优化技术 | 核心作用 | 关键优势 |
|---|---|---|
| 迁移学习 | 基于预训练模型开发,无需从零训练 | 节省成本与时间 |
| 微调 | 用领域数据让模型专业化 | 适配垂直场景(法律/ 医疗/ 代码) |
| RLHF | 人类反馈强化学习,让模型更有用、安全 | 对齐人类偏好 |
| LoRA | 冻结原模型,仅加微小可训练层 | 成本降低约100 倍,消费级GPU 可运行 |
| 量化 | 权重精度32 位→4 位,体积缩小8 倍 | 本地部署(手机/ 笔记本)可行 |
- 真实AI 系统构建(落地应用核心)
====================
-
RAG**(检索增强生成):**
先检索知识库再生成答案,减少幻觉,数据更新无需重训模型。
-
向量数据库:
存储文本嵌入,按语义相似度检索,优于关键词搜索。
-
AI****智能体:
具备思考- 行动- 观察- 循环能力,可调用工具执行任务,从应答转向执行。
-
思维链(CoT):
引导模型分步推理,提升数学、逻辑问题准确性。
-
扩散模型:
AI 图像/ 视频/ 3D 生成核心,通过逐步去噪从随机噪声生成内容。
5、惯例的三个问题Q&A
问题1:LLM产生幻觉的根本原因是什么?如何有效缓解?
答:根本原因是LLM 仅预测下一个最可能****token,无事实验证与检索环节,纯模式匹配易生成虚假信息;有效缓解方式是使用RAG****(检索增强生成),让模型先检索真实数据再作答。
问题2:LoRA与量化分别解决了AI模型应用的什么痛点?
答:LoRA解决传统微调成本高、需高端****GPU的痛点,仅添加微小可训练层,成本降低约100 倍,普通设备可微调;量化解决大模型体积大、无法本地部署的痛点,降低权重精度,让大模型可在笔记本、手机运行。
问题3:Transformer架构为何能成为现代AI的核心基础?
答:Transformer 于2017 年提出,核心突破是用注意力机制并行处理文本,替代传统逐字读取,大幅提升训练速度与输出效果;支持多层级理解(语法→词汇关系→复杂推理),是GPT、Claude、Gemini 等主流模型的统一架构。
附录: 2026年必须了解的20 个人工智能概念
Rahul

2026年你必须了解的20个人工智能概念
人人都在使用人工智能。
几乎没有人理解它是如何实际工作的。
人们随意使用像变换器、嵌入、RAG、智能体、RLHF……这样的词。
…仿佛每个人已经都知道了。
大多数人不会。
老实说?
人工智能并不复杂,一旦你理解了思维模型。
ChatGPT. Claude. Midjourney. Cursor. Coding agents.
一旦你理解下面的20个观点,它们就都能说得通。
无需博士学位。无需行话。只有简单的解释和视觉效果。
保存这个。你会再用到它。
第一部分:人工智能实际上是如何工作的(所有事物建立的基础)
- 神经网络
=======
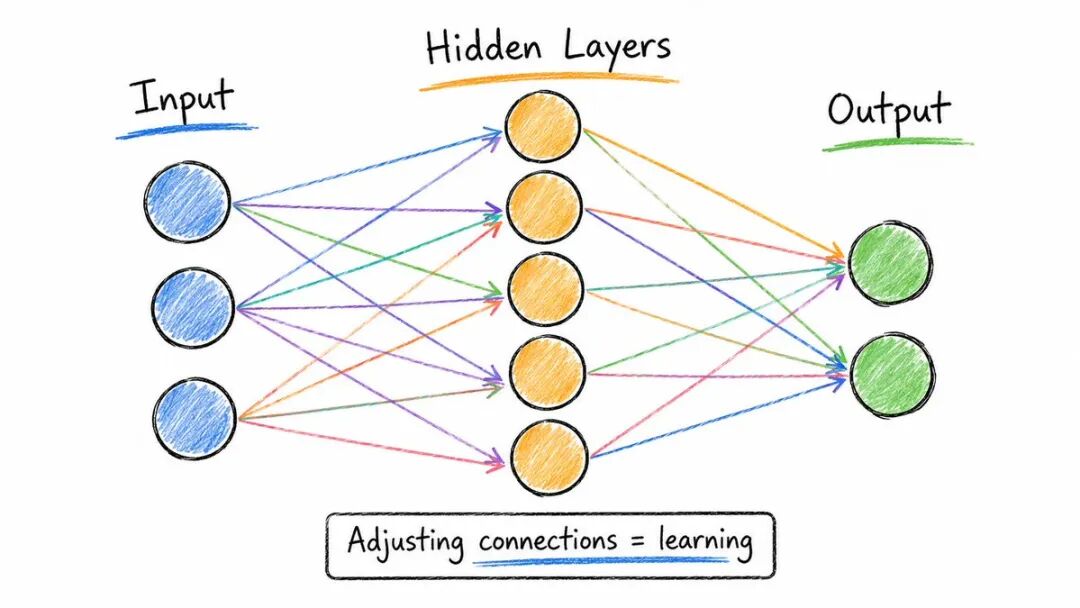
每个AI模型的核心。
神经网络是一个层的管道。
→数据进入输入层→ 经过隐藏层→ 以预测的形式输出
每个连接都有一个“权重”——一个微小的分数,它控制着一个神经元对下一个神经元的影响程度。
训练= 调整数十亿个这些权重,直到输出准确。
简单的想法。规模化时可能疯狂。
GPT-4拥有约1.8 万亿个参数。Claude 3 Opus 拥有数百亿个参数。
都源于同一个基本概念:可调连接的分层神经元。
- 分词器
======
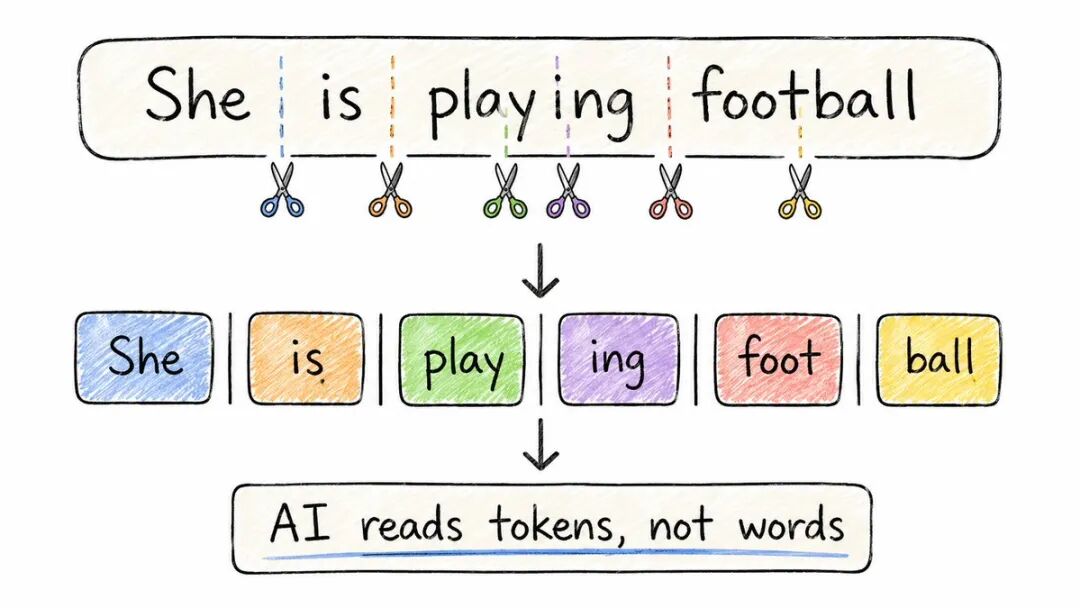
在AI读取您的文本之前,它将其分解为称为标记的片段。
并不总是完整的单词。
“玩” → “玩” + “ing” “ChatGPT” → “Chat” + “G” + “PT” “狗” → “狗” (保持不变)
为什么不直接使用完整的单词?
语言是混乱的。新词。打字错误。混合语言。固定的词汇量将是不可想象地庞大的。
Token是可重用的构建模块。
即使模型从未见过一个词,它也可以通过将其分解成熟悉的部分来理解它。
粗略规则:1个Token ≈ 0.75个单词。
1000 tokens ≈ 750 words.
- 嵌入
=====
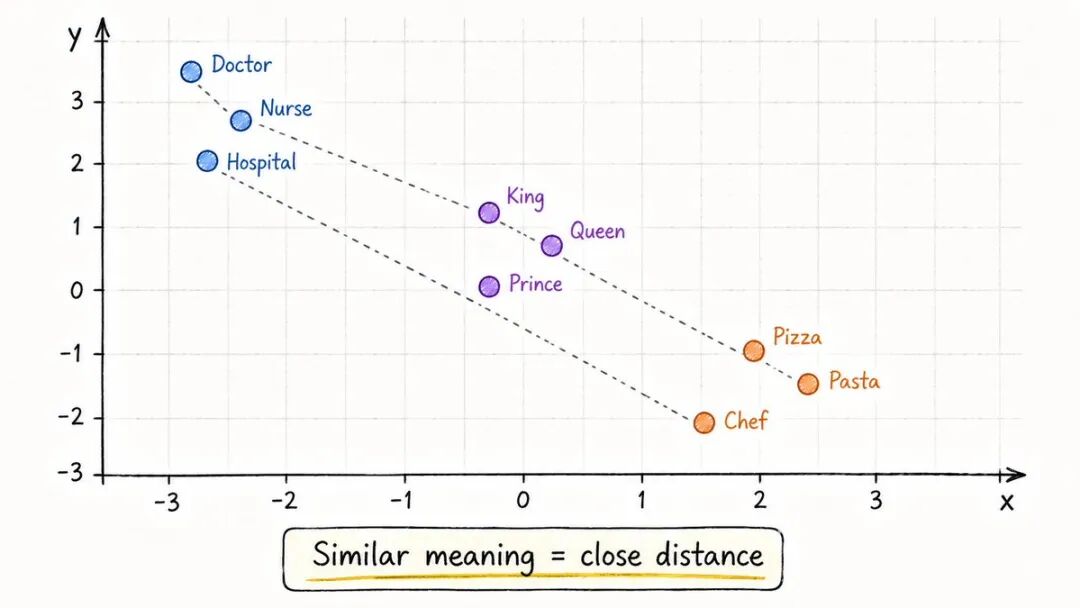
一旦文本被标记化,每个标记就变成一个数字。
该数字是一个嵌入——一个表示意义的向量。
把它看作是单词的谷歌地图。
→ “医生” 和"护士" 坐得很近→ “医生” 和"披萨" 坐得很远→ “国王” 减去"男人" 加上"女人" ≈ “女王”
该模型无法像你一样理解单词。
它理解距离和方向。
这就是驱动力:→语义搜索→ 推荐→ RAG 系统
所有“理解意图”的东西在底层都使用嵌入。
- 注意力机制
========
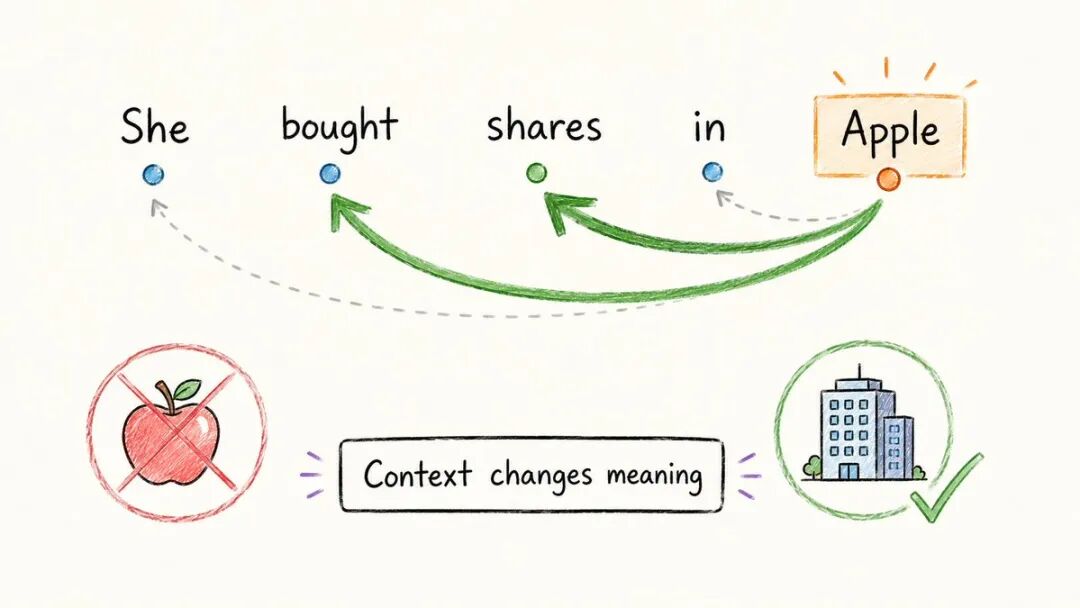
“苹果”这个词有不同的含义:
→ “我吃了一个苹果” → 水果→ “我买了苹果公司的股票” → 公司
仅仅依靠嵌入是无法解决这个问题的。
注意可以。
注意力使每个词与句子中的其他词相互关联并决定什么是重要的。
在“她购买了苹果公司的股票”:→ “苹果”高度关注“股票”和“购买”→ 模型得出结论:公司,而不是水果
Before attention, models read left-to-right. Slow. Limited.
经过注意力处理后,模型一次性看到整个句子。
这个单一的理念解锁了现代人工智能。
- Transformer
==============
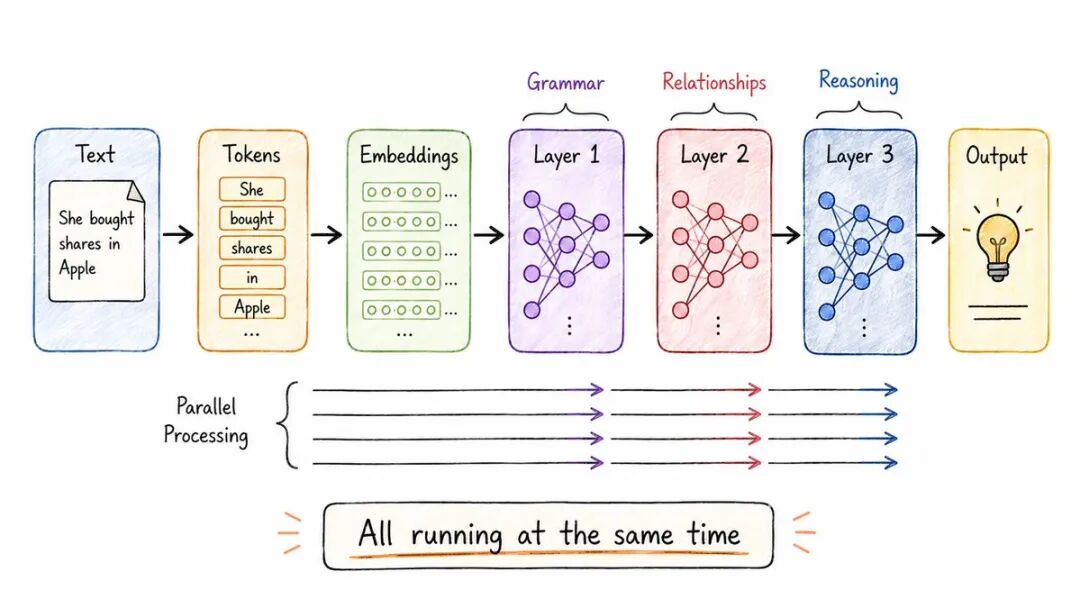
当今几乎所有AI模型背后的架构。
2017年在一篇名为“注意力机制是你所需要的”的论文中介绍。
突破:不是逐字阅读文本,而是使用注意力并行处理所有内容。
它是如何工作的:→文本→ 词元→ 嵌入→ 堆叠注意力层→ 输出
每个层次精炼理解:→初始层:语法,基本结构→ 中间层:词汇关系→ 深层:复杂推理
结果:训练速度大幅提升,输出效果明显改善。
GPT。Claude。Gemini。Llama。Mistral。
所有Transformer。
如果你理解这一种架构,你就理解现代人工智能。
第二部分:LLM是如何工作的(当你与AI聊天时实际上发生了什么)
- LLMs (大型语言模型)
================
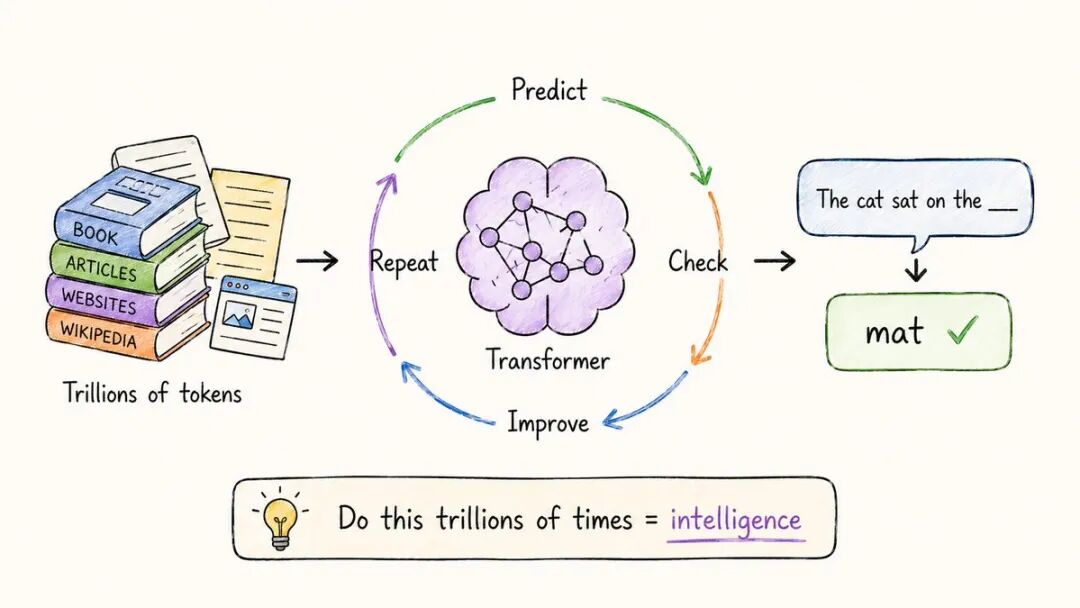
一个LLM是一个在大量文本上训练的变换器。
书籍。网站。代码。维基百科。Reddit。
万亿个标记。
训练任务听起来太简单了,无法发挥威力:
→预测下一个标记。
这就是。
但当你在数万亿个例子中重复这一点时,奇妙的事情发生了。
模型学习语法。然后是推理。再然后是如何编写代码、翻译语言、解决数学问题。
没有人告诉它做这些事情。
它是在大规模的下一个标记预测中产生的。
“Large” =数千亿参数。训练成本= 数百万美元。
ChatGPT, Claude, Gemini →所有的LLM。
- 上下文窗口
========
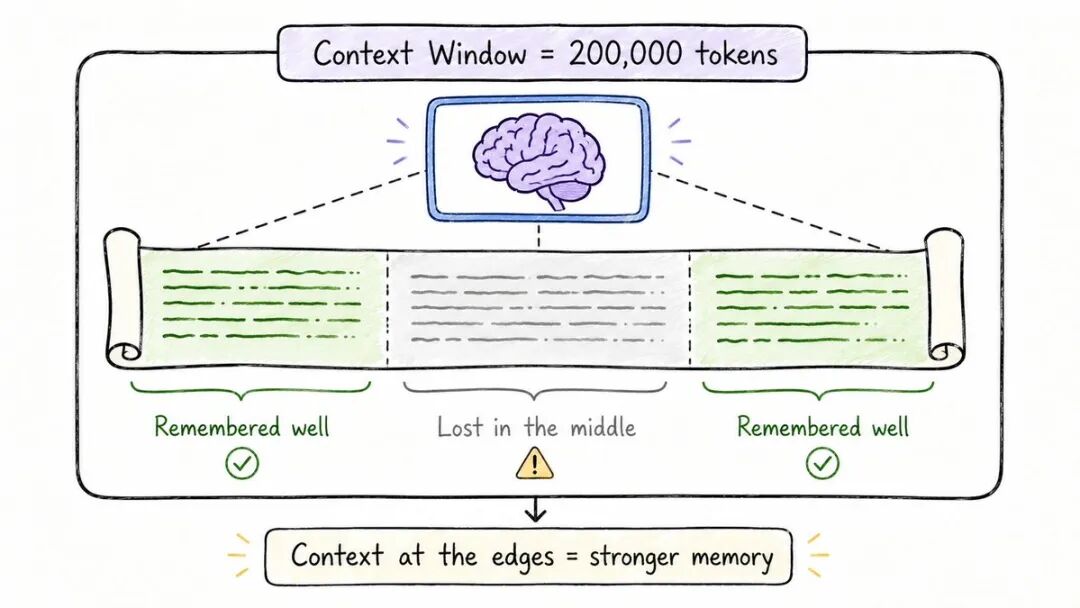
每个AI模型都有一个记忆限制。
它被称为上下文窗口。
这是模型一次可以“看到”的最大Token数——你的消息+ 其响应+ 对话历史。
早期GPT: ~4,000 个Token。GPT-4: 128,000 个Token。Claude 3.5: 200,000 个Token。Gemini 1.5 Pro: 1,000,000 个Token。
更大的窗口= 更多的上下文= 更好的答案。
模型对信息的读取不平等。
他们专注于上下文的开始和结束。
中间?常常被忽视。
这被称为“迷失在中间”问题。
大上下文窗口≠ 完美记忆。
理解这一点可以解释为什么人工智能有时会“忘记”你清楚提到的某些事情。
- 温度
=====
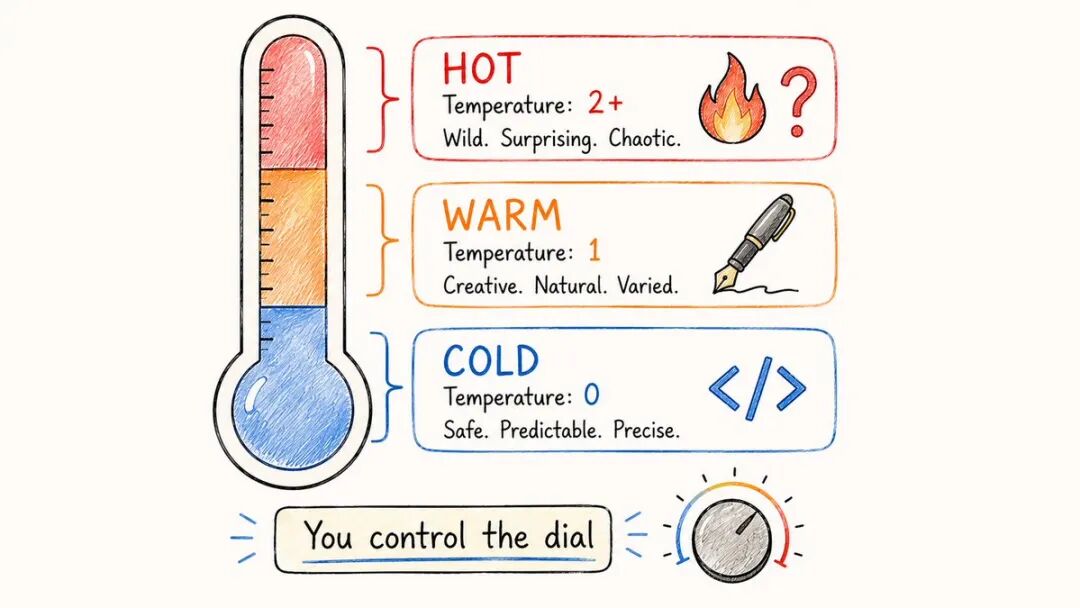
当AI生成文本时,它并不是每次都选择最可能的下一个单词。
它有一个叫做温度的表盘。
→温度= 0:总是选择最安全、最可预测的词→ 温度= 1:选择更具创意的词,更加多样化→ 温度= 2+:变得疯狂,有时难以理解
低温→ 用于:编码、事实、摘要 高温→ 用于:头脑风暴、创意写作、变体
大多数工具会为您自动设置这个。
但理解它可以解释为什么有时人工智能显得“无聊”,而有时又会让你感到惊喜。
- 幻觉
=====
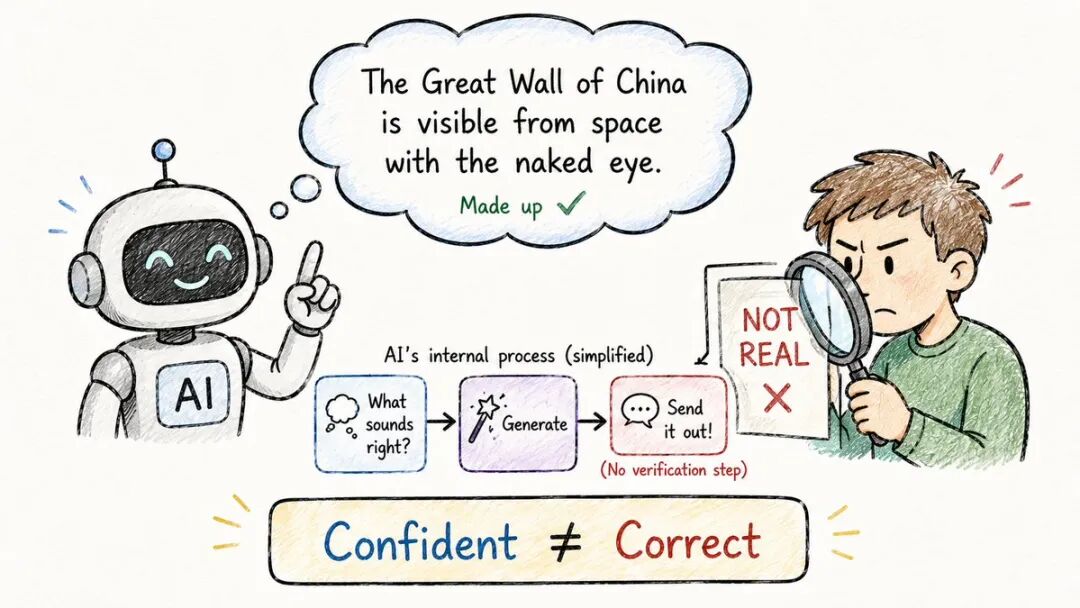
不是故意的。它真的无法自助。
这就是原因。
一个LLM并不寻找真理。
它预测下一个最可能的标记是什么。
如果虚假陈述看起来像是基于训练模式“应该接下来出现”的内容,它就会生成它。
无需验证。无需查找。纯模式匹配。
所以它会:→ 引用一篇不存在的研究论文→ 发明一个从未创建的API函数→ 以完全的信心陈述一个虚假的历史“事实”
这被称为幻觉。
修复方案:永远不要在未验证的情况下信任AI输出的事实。
使用RAG(概念16)将其与真实数据相结合。
- 提示工程
========
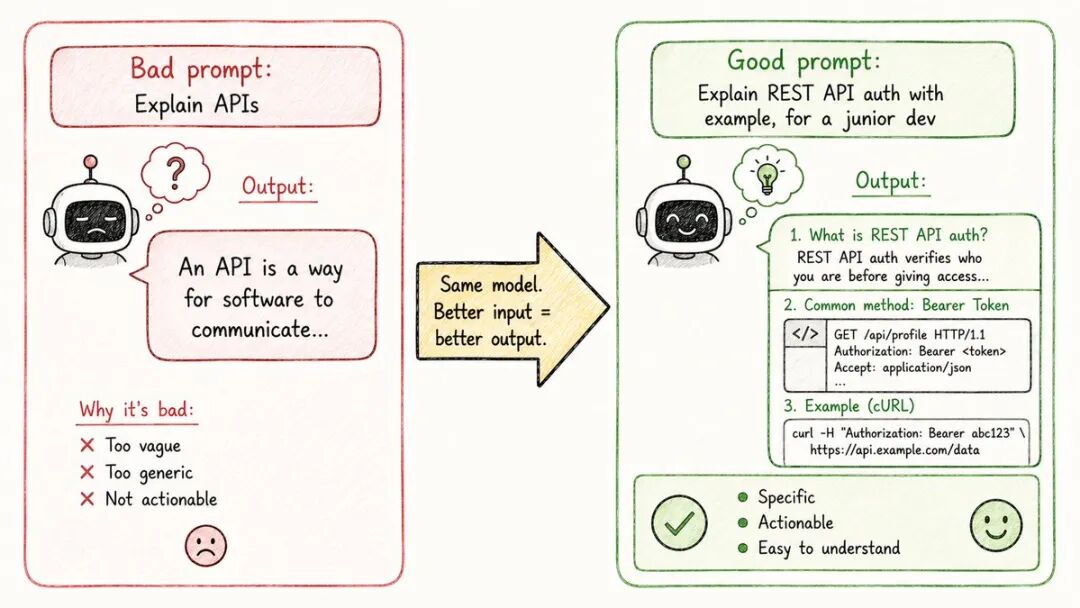
你问的方式改变了一切。
相同的模型。相同的问题。根据你的表述方式,结果截然不同。
不良提示:→ “解释API” →得到:模糊、肤浅的答案
好的提示: → “解释REST API 如何处理身份验证。给出一个带代码的实际示例。假设我是一名初级开发者。” → 得到: 具体、结构化、立即有用
提示工程只是清晰的沟通。
有效的技巧:→ 提供背景(“我正在为X构建一个SaaS”)→ 指定角色(“充当高级后端工程师”)→ 显示示例(“这是我喜欢的格式:___”)→ 对输出要求具体(“给我5个编号列表的选项”)→ 将复杂需求分解为步骤
提示工程不是一种技巧。
这是你与模型沟通的主要方式。
第三部分:人工智能模型如何改进(原始模型如何成为有用的产品)
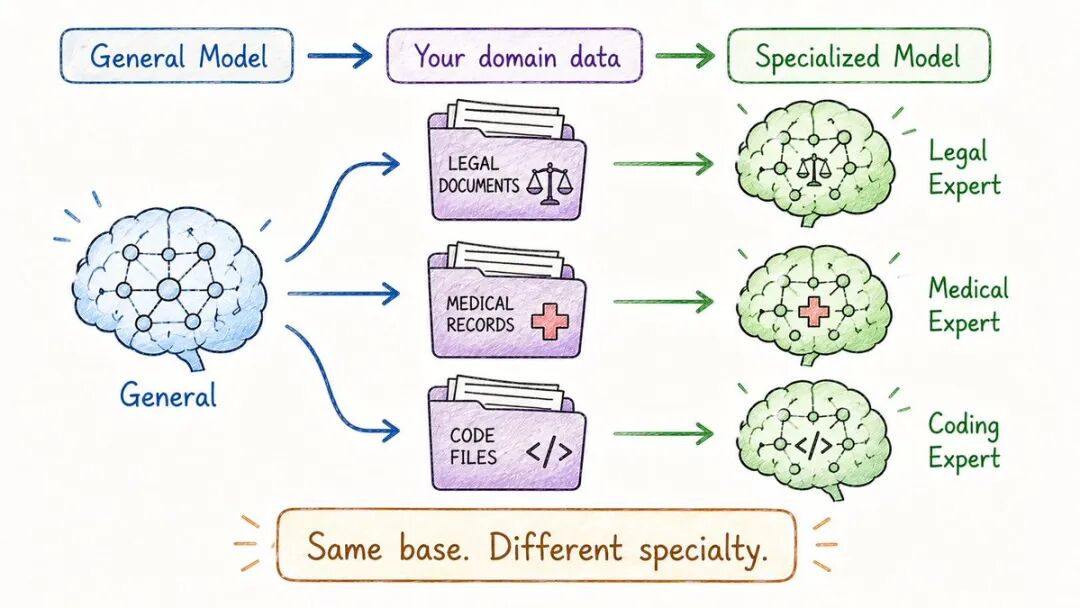
- 迁移学习
========
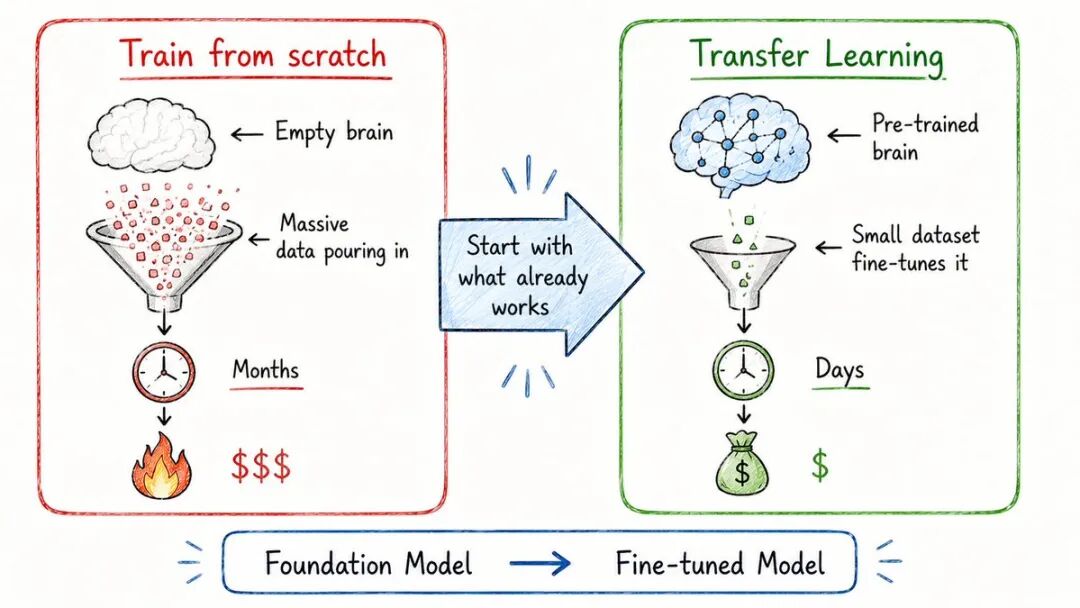
从零开始训练是昂贵的。
疯狂的数据量。巨大的计算能力。数周的训练。
迁移学习解决了这个问题。
您采用一个已在庞大的通用任务上训练的模型,并将其调整为更具体的任务。
你不是从零开始的。你是在此基础上进行建设。
想象成这样:
→你已经知道怎么骑自行车→ 学习摩托车会快得多,因为这样→ 你可以转移你已经知道的知识
这就是今天几乎所有AI产品的工作方式:
→ OpenAI训练大规模基础模型→ 公司针对其特定用例进行微调→ 节省数百万的计算成本和数月的训练时间
没有公司再从零开始训练了。
- 微调
======
迁移学习告诉你这个概念。
微调就是这样做的。
您使用一个预训练模型,并在一个较小、集中的数据集上继续训练它。
该模型已经会说“语言”。
现在你正在教授它你的特定领域。
示例:→基于临床记录微调的医学模型→ 基于合同微调的法律模型→ 基于GitHub 微调的编码模型
结果:一个能够完美响应您使用案例的模型。
成本:您需要更新数十亿个参数。
那需要强大的计算能力——多个GPU,严谨的基础设施。
(这就是为什么LoRA这个概念如此重要。)
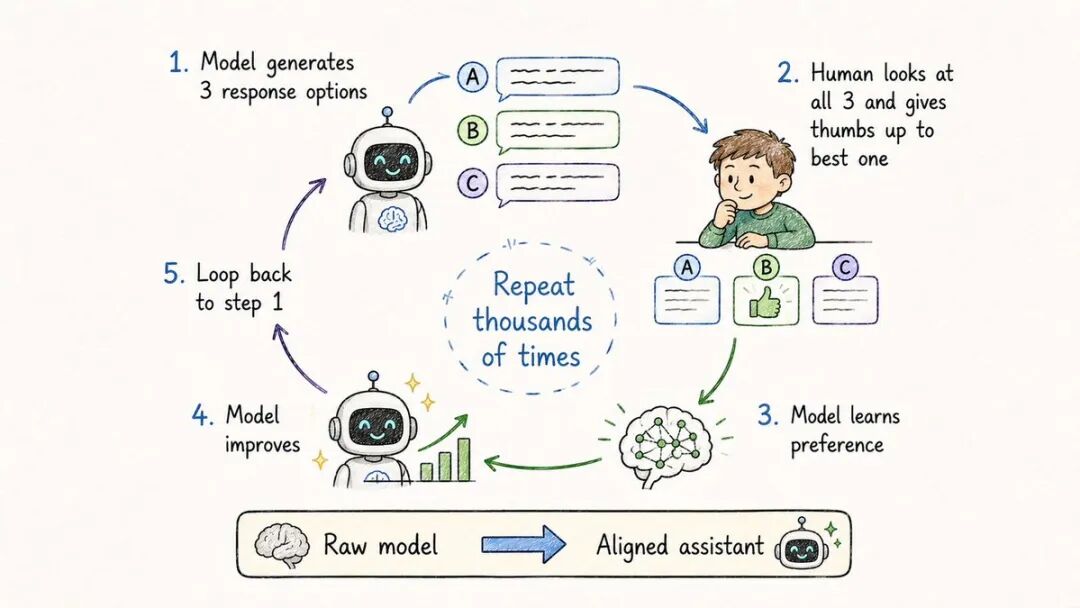
- RLHF(来自人类反馈的强化学习)
=====================
微调使模型变得专业化。
RLHF是让他们感到有帮助和安全的原因。
没有它:模型只会预测文本。流畅,但不一致。
通过它:模型学习人类实际的偏好。
这是它的工作原理:
→展示模型提示→ 模型生成多个响应→ 人类对响应进行排名→ 模型学习偏向人类的偏好
重复数千次。
该模型建立了“良好答案”的概念:→ 清晰→ 有帮助→ 诚实→ 安全
这就是为什么ChatGPT 和Claude 感觉像助手— 而不是随机文本生成器。
没有RLHF,它们仍然令人印象深刻。但实用性较差,可信度较低,且控制起来更困难。
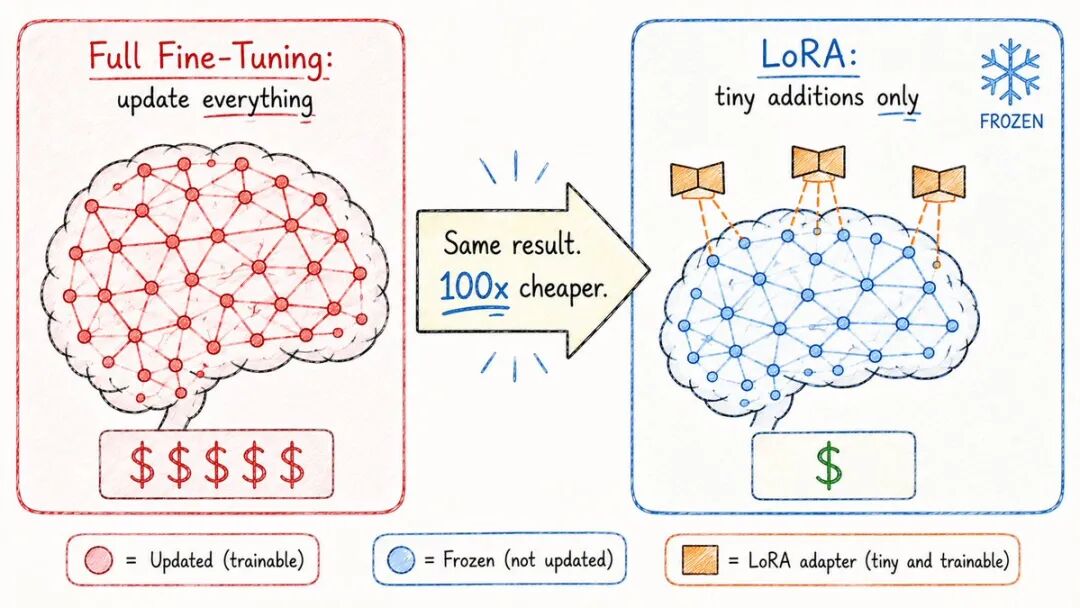
- LoRA(低秩适应)
==============
微调是强大的但代价高昂。
更新数十亿个参数需要多个GPU和严谨的基础设施。
LoRA解决了这个问题。
相较于改变整个模型,LoRA:
→保持原始模型不变→ 在其上添加微小的可训练层→ 这些层只是完整模型大小的一部分
洞察:大多数微调变化都很小。
您不需要重写整个模型。
你只需要进行小范围的针对性调整。
结果:→ 在单个消费级GPU上进行微调:可行→ 存储一个基础模型+ 更换不同的LoRA适配器:实用→ 多个专业化模型而不需要大量存储:完成
LoRA是开源人工智能爆炸式增长的原因。
突然间,任何人都可以在笔记本电脑上微调强大的模型。
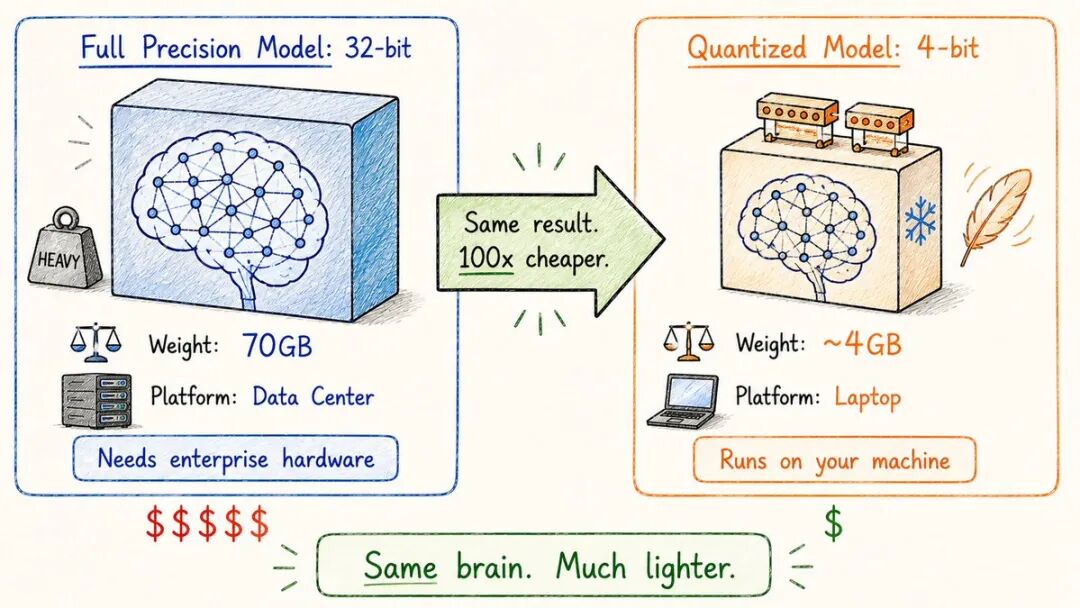
- 量化
======
模型变得庞大。
运行它们需要大量的内存和计算能力。
量化使它们更小且运行成本更低。
如何:降低每个权重的精度。
一个以全精度存储的权重使用32位。
量化为4位→ 小了8倍。
疯狂的事情是:质量下降往往出乎意料的微小。
这就是为什么你现在可以:→ 在MacBook上运行LLaMA → 在消费级GPU上本地运行Mistral → 在手机上使用强大的模型
没有量化,大型模型将会被锁定在数据中心。
通过量化,它们可以在你的机器上运行。
第四部分:真实AI系统是如何构建的(你实际使用的产品背后是什么)
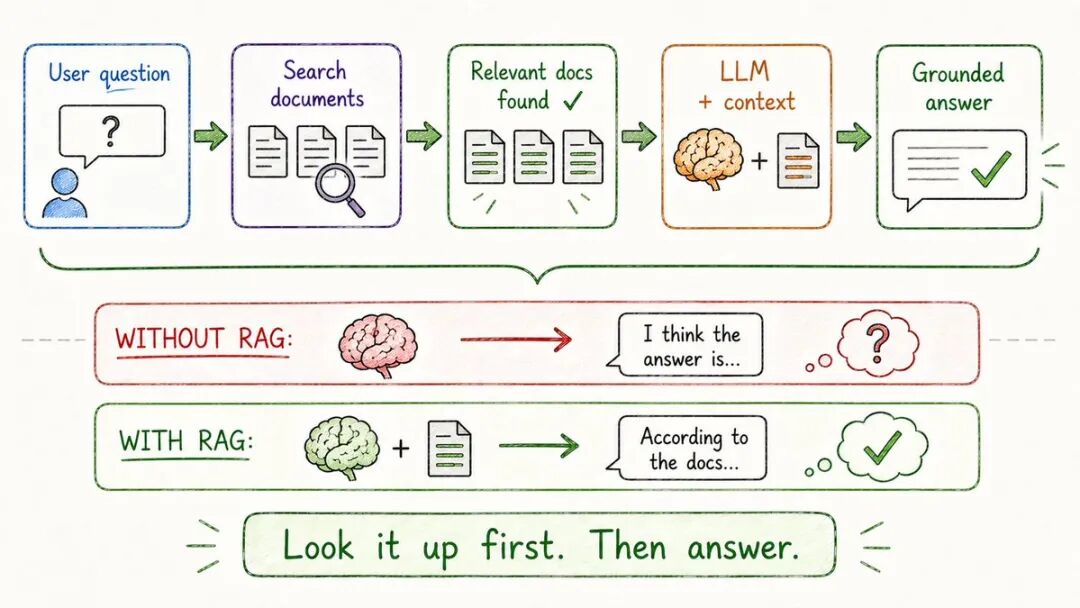
- RAG(检索增强生成)
===============
LLMs幻觉是因为它们通过记忆回答。
RAG通过让他们首先查找信息来解决这个问题。
如何运作:## 所需要的语言: 中文
用户提问。
系统在知识库中搜索相关文档
这些文档作为上下文传递给模型。
使用真实信息而非猜测的模型答案
想象成这样:
→闭卷考试(无RAG):凭记忆作答,往往错误→ 开卷考试(RAG):查阅资料,准确得多
为什么它很强大:→数据发生变化时无需重新训练— 只需更新文档→ 模型始终使用当前、准确的信息→ 大幅减少幻觉
每个严肃的人工智能产品都使用RAG。
客户支持机器人。法律工具。医疗助手。内部知识库。
- 向量数据库
=========
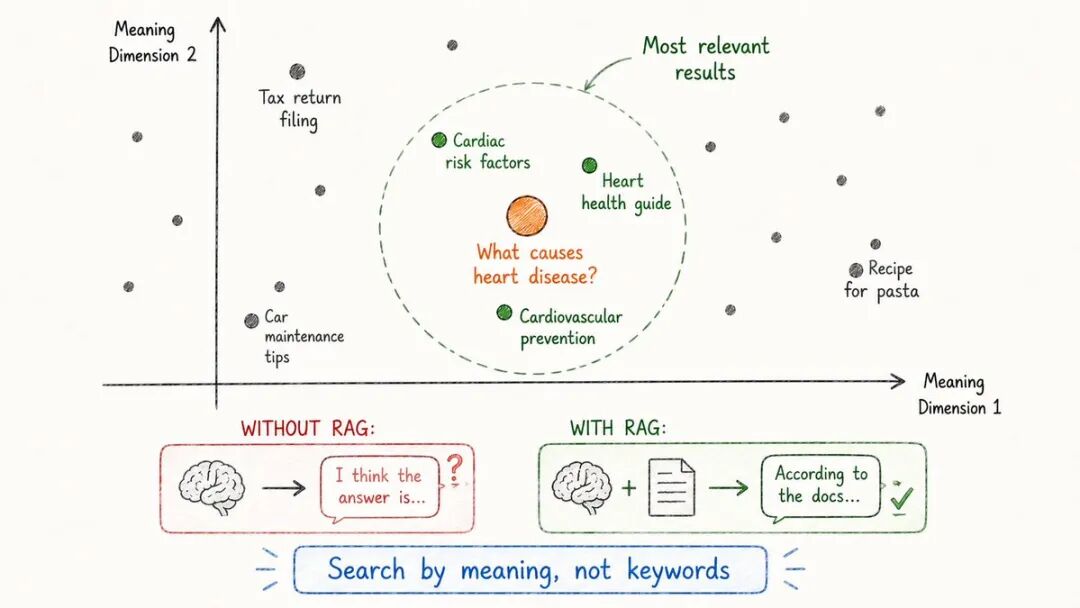
RAG需要快速找到正确的文档。
但你如何通过意义而不仅仅是关键词来搜索数百万份文档呢?
向量数据库。
它们是如何运作的:
每个文档都被转换为一个嵌入(一个数字向量)
这些向量被存储在数据库中
当用户提出问题时,该问题也成为一个向量。
数据库查找与问题向量最接近的向量
返回语义上最相似的文档
为什么这比关键词搜索更好:
→ “心脏疾病治疗” 找到有关"心脏护理协议" 的文档→ 尽管确切的词语不匹配,但意思是相同的
工具:Pinecone, Qdrant, Weaviate, pgvector
向量数据库是使AI系统“理解”的关键——而不仅仅是匹配字符串。
- AI智能体
=========
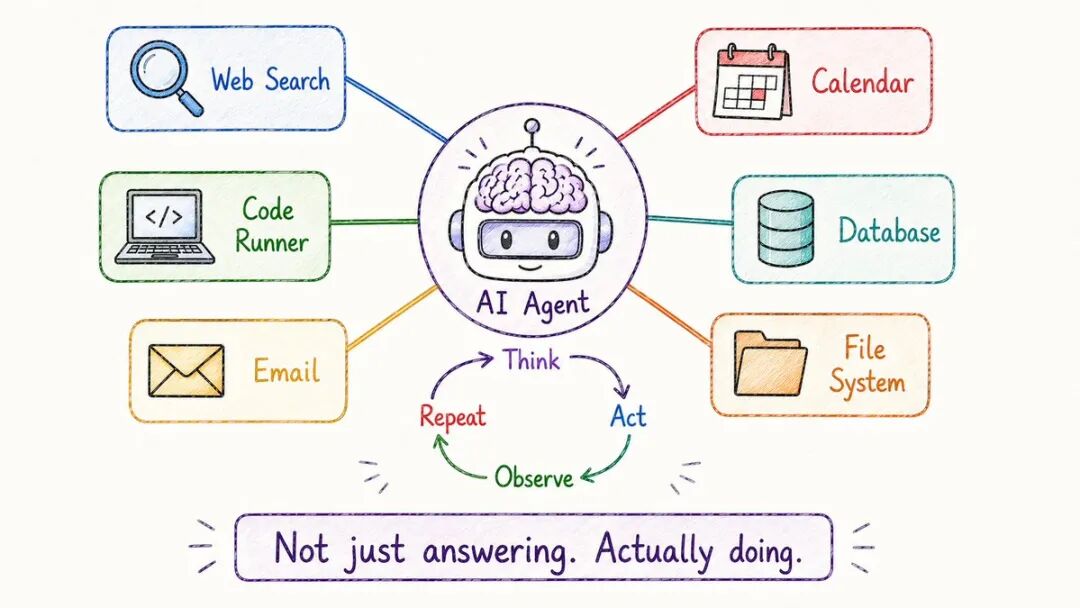
一个大型语言模型(LLM)对消息进行响应。
一个人工智能智能体实际上是做事情的。
差异:
→ LLM:你问,它回答,完成→ Agent: 你给出一个目标,它规划,采取行动,检查结果,调整,重复
智能体循环:
思考→ 行动→ 观察→ 重复
示例:编码智能体修复一个错误→ 阅读问题→ 探索代码库→ 识别问题→ 编写修复→ 运行测试→ 查看失败→ 调整修复→ 重复直到完成
模型是大脑。工具是手。
智能体可以使用哪些工具?→ 网络搜索→ 代码执行→ 文件系统→ 应用程序接口→ 电子邮件/ 日历→ 数据库
智能体将人工智能从聊天机器人转变为同事。
- 思维链(CoT)
============
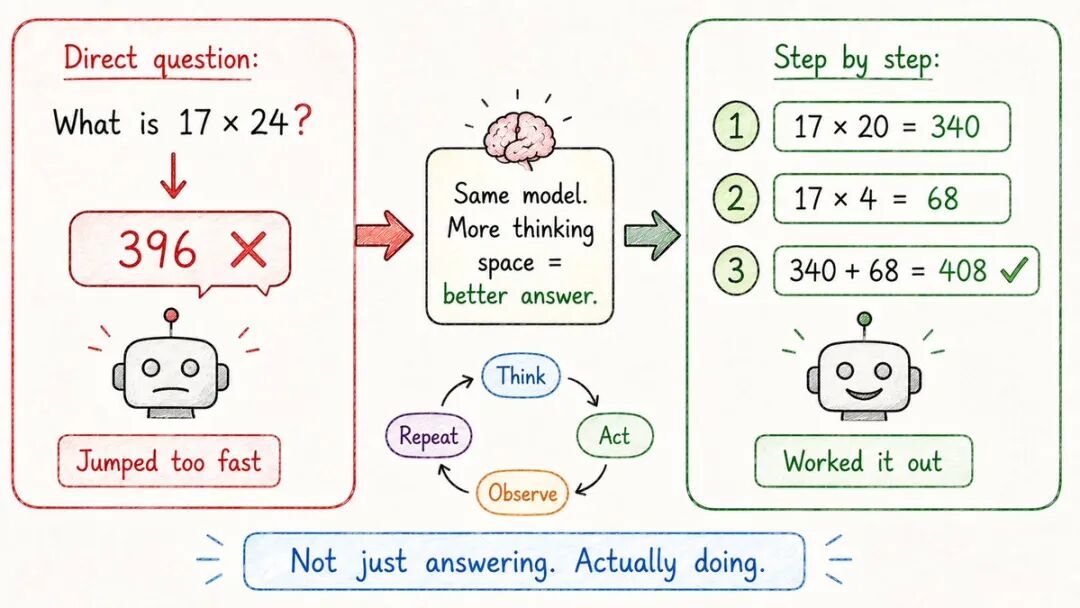
有时候,人工智能得出的答案不对并不是因为它愚蠢。
但因为它跳得太快了。
思维链解决了这个问题。
直接请求最终答案:
→ “求解:如果一列火车以60英里每小时的速度行驶2.5小时,走多远?”
你引导它一步一步思考:
→ “逐步解决:速度= 60英里每小时。时间= 2.5小时。距离= 速度× 时间= ?”
模型通过推理进行步骤演示:→第一步:识别公式→ 第二步:代入数字→ 第三步:计算
在数学、逻辑和多步骤问题上更可靠。
洞察:给模型留出思考空间,而不仅仅是反应。
这就是为什么像“逐步思考”或“仔细推理”这样的提示实际上有效的原因。
- 扩散模型
========
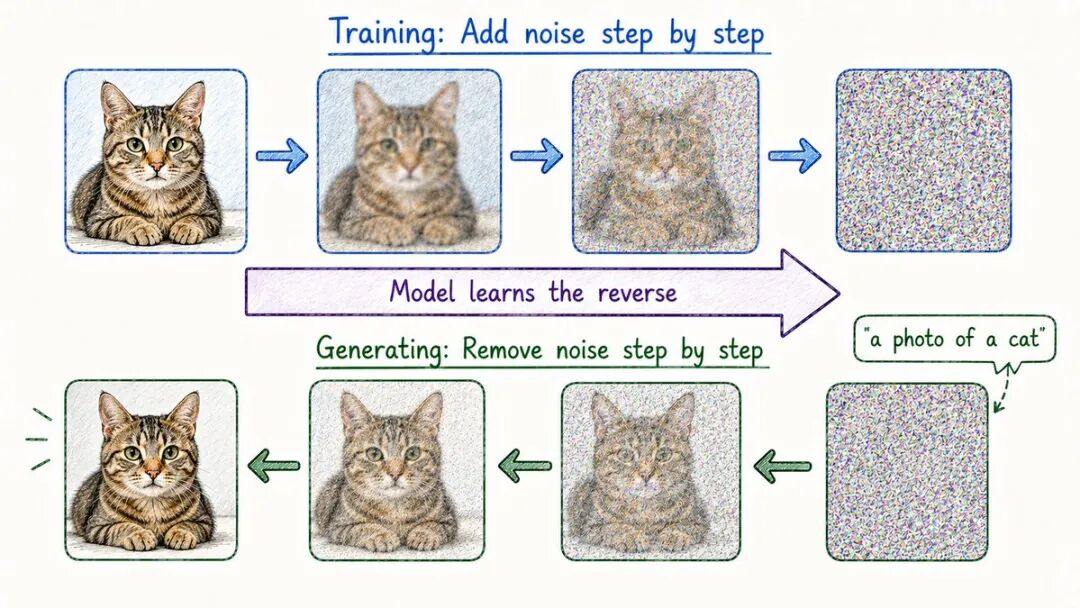
到目前为止,一切都与文本有关。
扩散模型解释了AI如何生成图像。
这个过程是违反直觉的。
模型并不会学习绘画。
它学会了摧毁图像。
训练:→从一幅真实的图像开始→ 逐步添加噪声直到变为纯静态→ 训练模型来逆转这个过程— 逐步去除噪声
生成:→从纯噪声开始→ 模型逐步去除噪声→ 在你的文本提示的指导下→ 图片从随机性中显现出来
这个名称来自物理学——粒子在介质中随机扩散,就像墨水在水中扩散一样。
在这里,模型学习逆转该扩散。
不仅仅是图像:→视频(Sora,Runway)→ 音频→ 3D 内容→ 药物分子
扩散模型是人工智能生成任何视觉内容的方式。
这就是全部20。
让我回顾一下:
AI是如何工作的:
→ 1.神经网络— 分层模式学习
→ 2.分词— 将文本拆分为片段
→ 3.嵌入— 作为数字的意义
→ 4.注意——情境改变意义
→ 5. Transformers —一切背后的架构
如何运作LLM:
→ 6.大型语言模型— 大规模的下一个标记预测
→ 7.上下文窗口— 记忆限制和中间问题
→ 8.温度— 创造力调节器
→ 9.幻觉— 自信而错误
→ 10.提示工程— 你如何沟通
模型如何改进:
11.迁移学习— 基于现有基础进行构建
→ 12.微调— 专门化一个模型
→ 13. RLHF —教它变得有帮助
- LoRA —无成本的微调
→ 15.量化— 在小型机器上运行大型模型
如何构建真实系统:
→ 16. RAG —先查一下,然后再回答
→ 17.向量数据库— 按意义搜索
→ 18. AI智能体— 从回答到执行
→ 19.思维链— 给它空间思考
→ 20.扩散模型— 从噪声到图像
你现在理解人工智能是如何实际运作的。
大多数每天使用人工智能的人并没有。
那个差距就是你的优势。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献158条内容
已为社区贡献158条内容

所有评论(0)