超越VGGT&VDA,全面SOTA!华科&酷睿程重磅开源3D几何感知框架 GemDepth(ICML2026)

「突破2D局限,探索视频深度估计的3D一致性」
目录
视频深度估计一直面临着一个绕不开的痛点:如何克服画面闪烁,实现完美的时间一致性?
不可否认, 如今的单帧深度估计大模型已经非常强大,无论是走判别式路线的 VideoDepthAnything,还是走生成式路线的 DepthCrafter,都在空间精度上交出了令人满意的答卷。
但是,这些方法普遍存在一个致命盲区——它们过度依赖2D帧上的隐式时序平滑,而忽略了真实的3D几何感知。这种“知其然而不知其所以然”的2D约束,在遇到剧烈的视角切换或复杂的相机旋转时就会原形毕露,无法保持严格的几何一致性。更糟糕的是,为了强行让画面看起来“平滑”,这些模型经常会抹杀掉高频的空间细节,导致物体边缘模糊、结构退化。
我们坚信,要想实现真正的时间一致性,就必须赋予模型显式的3D几何理解能力,包括让它感知到相机的运动轨迹和全局的3D结构。缺少了运动先验这块拼图,模型就无法建立起底层的点级对应关系,自然也就容易被混乱的时间线索带偏,产生空间模糊。
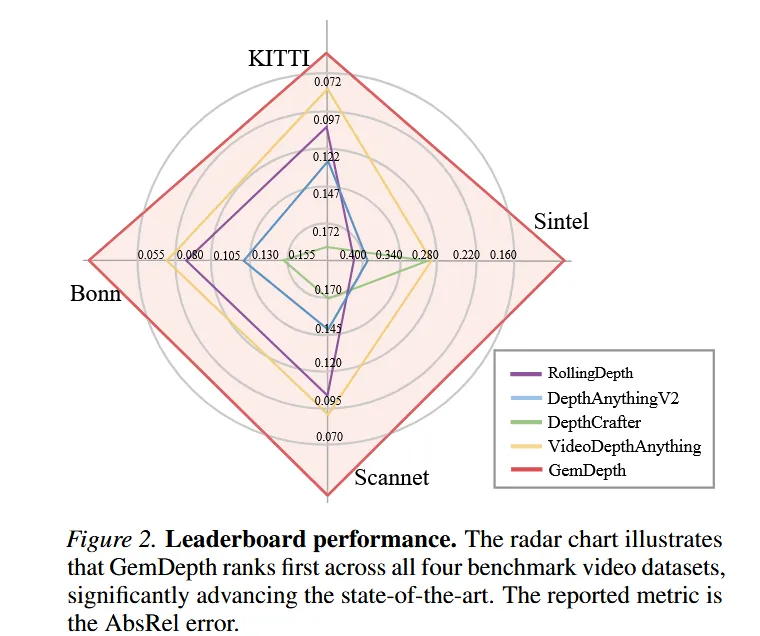
为了直观地展现这个问题,我们做了一个简单的实验:将连续10帧的点云全部投影到第一帧的坐标系中堆叠起来。如下图所示,之前的 SOTA 模型(VDA)因为没有3D几何的约束,投影结果出现了惨不忍睹的重影;而我们的 GemDepth 则精准切中了这一痛点,凭借优秀的3D几何感知能力,完美抑制了重影现象。

01 关键技术
华科&酷睿程团队提出基于几何参数自预测的视频深度估计框架 GemDepth,在视频深度估计领域中首次利用几何参数作为隐式嵌入,解决现有视频深度估计在视角剧烈变化时难以维持3D几何一致性、易导致空间模糊与时序不连续的问题。模型效果大幅刷新视频深度估计SOTA并在点云重建效果上优于DepthAnything3,VGGT等3D基础模型。
核心架构解析:当几何先验遇上时空交替
现有的方法往往陷入一个困境:它们本质上是在做 “2D 特征序列的盲目平滑”。GemDepth给出了截然不同的做法:通过显式预测相机位姿来注入运动先验,并在“时序对齐”与“空间细化”之间交替运行,协同聚合出3D几何一致的视频深度。
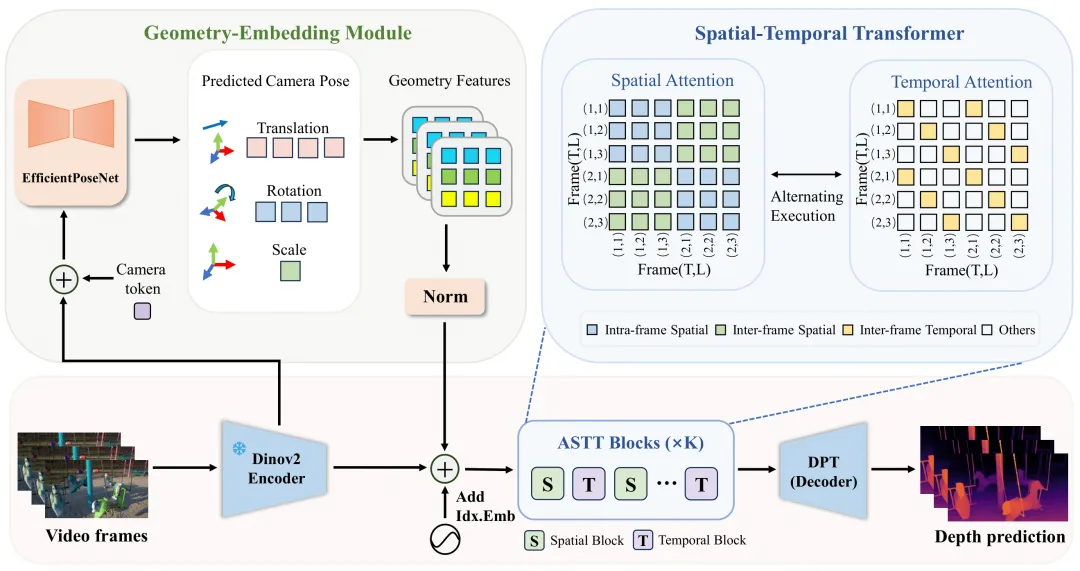
具体实施:几何先验与时空交替的协同作用
epth架构如上图所示,GemDepth的强大能力主要源自两大核心模块的默契配合:
一、几何嵌入模块(GEM)
GEM 模块站在 DinoV2 强大特征表示的“肩膀”上,内置了一个轻量级的 EfficientPoseNet,专门用来预测视频帧之间的 6-DoF 相机运动。这些位姿数据经过 MLP 编码后,会化身为带有物理度量信息的相机特征 ,为整个网络提供至关重要的几何指引。我们将一个可学习的相机 token
融入主特征图
中,交由四层交替注意力 Transformer 进行深度解析。为了让物理约束更严谨,GEM 会把所有计算出的位姿统一拉到一个标准的规范坐标系下。破解尺度魔咒:单目深度最怕“忽大忽小”的尺度问题。
为此,我们引入了全局尺度因子 来归一化平移量,并直接用真实的尺度数据对 GEM 进行监督训练。这就好比给模型上了一把“统一标尺”,彻底根除了初始的尺度不一致痼疾。最终,这份几何嵌入会与主特征图
完美交融。在显式物理约束的引导下,模型的深度优化彻底告别了依靠 2D 图像的“盲目平滑”,实现了真正的“物理对齐”。
二、交替时空 Transformer 模块 (ASTT) ASTT
采用了一种非常聪明的“分步走”策略,把复杂的时空建模拆解为两个动作:“时序对齐”和“空间细化”。两者交替进行,共同把几何一致性推向极致。
时序注意力(专攻几何对齐):我们先把特征图重新排布,专门剥离出时间维度上的联系。有了刚才 GEM 提供的 6-DoF 运动先验作为“导航”,模型就能在时间轴上精准建立起像素点级别的对应关系。这种 沿着运动轨迹提取特征的做法,能有效屏蔽掉杂乱背景的干扰,专心捕捉纯粹的运动信息,从而保证了画面结构的稳定,让闪烁问题无处遁形。
空间注意力(专攻结构细化):时间对齐搞定后,接下来就是提升画质。我们把这一步拆成了两块:“帧 内注意力”负责抠局部细节,“帧间注意力”负责处理跨帧的宏观联系。它能把相关的 3D 空间特征聚拢起来,让模糊的边缘变得锐利,让高频细节更加突出。
ASTT 就这样在“找准几何对齐”和“死磕画面细节”之间来回迭代,严格遵循“先对齐,后锐化”的原则,最终为我们端出了一盘极其逼真、连贯的高保真深度序列。
02 实验结果:视频深度与点云重建全面SOTA
Zero-shot Depth Estimation
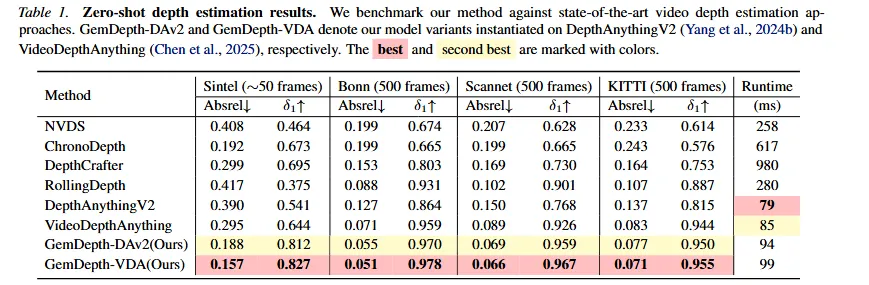
- 空间精度指标:无论在DepthAnythingV2还是VideoDepthAnything基础上接入GemDepth框架,我们在所有指标上都始终树立了新的先进水平。至关重要的是,GemDepth以卓越的数据效率取得了这些成果。

- 时间一致性指标:GemDepth始终能产生最稳定的深度估计。值得注意的是,GemDepth-DAv2和GemDepth-VDA均为时间稳定性树立了新的最先进标准,在TAE指标上分别比各自的基线高出56.14%和17.54%。
3D Geometric Accuracy
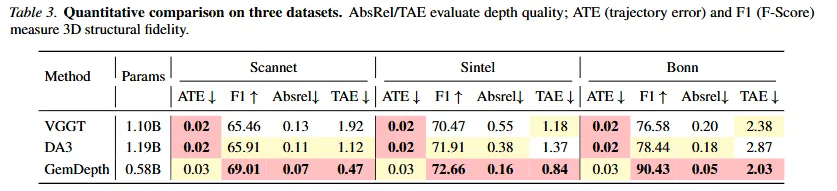
在 3D 几何精度方面,GemDepth性能实现了断层领先。面对拥有 1.19B 庞大参数量的 DepthAnything3 (DA3) 和 1.10B 的 VGGT,我们的模型仅仅使用了不到它们一半的参数(0.58B),却在核心指标上实现了全面碾压!
- 深度精度:降维打击般的时空一致性
在视频深度估计的赛道上,GemDepth 对标 DA3 实现了全面超越。数据不会撒谎:在 ScanNet 数据集上,最让人头疼的时间一致性指标(TAE)直接被我们砍掉了一半多(0.47 vs 1.12);在 Bonn 数据集上,绝对相对误差(AbsRel)更是暴降了 70%(0.05 vs 0.18)。能交出这么亮眼的成绩单,全靠模型自带的“3D 视野”——在几何线索的牵引下,时空特征在交替交互中死死咬住像素点的运动轨迹,让空间的高清画质和时间的丝滑流畅同时拉满。
- 点云重建:彻底告别重影与拉丝
除了视频看着爽,GemDepth 在 3D 空间的重构能力同样能打。如果我们把预测出来的深度序列投 影到 3D 空间,你会发现,相比于现有的主流 3D 基础模型,GemDepth 还原出的点云非常干净。 在极其考验模型抗干扰能力的高动态数据集 Bonn 上,点云重建的核心指标 F1 分数被我们硬生生从 78.44(DA3)拔高到了 90.43,提升幅度高达 15.3%!秘诀就在于我们将极其精准的相机位姿和锐利的深度边缘完美缝合,彻底消除以前那种模糊不清的“重影”。
- 位姿精度:用一半参数撬动极致几何
我们同样也没有放过对位姿预测指标的严格考核。量化分析显示,GemDepth 在所有测试集上的绝对轨迹误差(ATE)都极具杀伤力。在 Sintel 和 Bonn 这种复杂的室内场景中,ATE 稳稳控制在 0.03 量级,几乎咬住了那些巨无霸 3D 模型的尾巴。要知道,像 DA3 和 VGGT 可是靠着超过 1.10B 的庞大参数量在暴力拟合,而 GemDepth 只用了区区 0.58B 的参数就做到了平分秋色!
更绝的是,位姿在我们这儿根本不是为了输出而输出的“附属品”,而是作为一张底牌式的“物理先验”。GEM 模块吐出的这些自带统一尺度的精准位姿,就像是给后面的交替时空注意力模块装上了高精度 GPS,指引着每一帧画面严丝合缝地完美对齐。
Ablation Studies
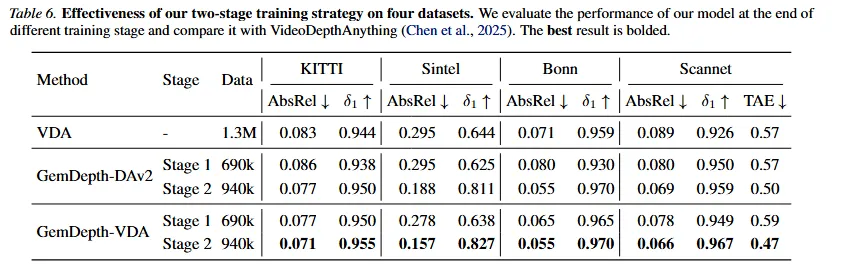
为了验证我们提出的两阶段训练策略的有效性,我们在四个基准测试集上评估了每个阶段完成后的模型性能。如上表所示。我们观察到GemDepth-DAv2和GemDepth-VDA都有一致的上升轨迹:从阶段1到阶段2,随着训练的推进性能单调提高。
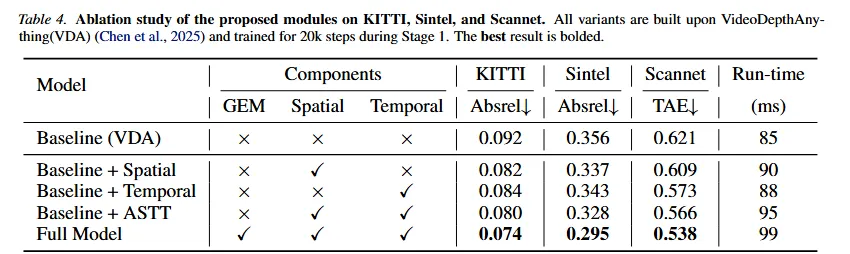
在消融实验中,我们系统性验证了模型关键组件的有效性。以VideoDepthAnything为baseline,通过比较加入GEM模块中的Spatial Attention、Temporal Attention和baseline的效果,以及在GEM基础上加 入ASTT模块后的效果,证明GEM模块和ASTT模块的有效性。这些模块展现出强大的协同效应,同时优化深度精度和时间一致性。
Visualization
- Qualitative comparison of spatial accuracy on diverse datasets
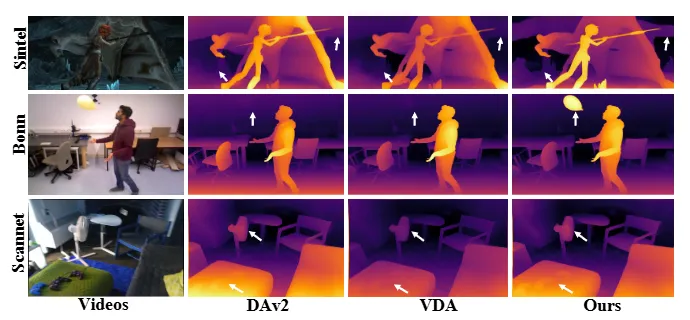
如白色箭头所示,GemDepth展现出卓越的空间精度和结构保真度,能有效恢复细粒度细节,同时减轻了其他方法中常见的过度平滑伪影。值得注意的是,第二行展示了我们的模型在动态物体上的优越性能,能有效还原出空中运动的气球。
- Qualitative results of temporal consistency on videos of varying lengths.

为了评估时间稳定性,我们通过沿固定空间轴(由红线表示)提取深度切片,GemDepth展示了卓越的时间连贯性。相比之下,DepthAnythingV2和VideoDepthAnything存在明显的闪烁和锯齿状的时间不连续性。
- Zero-Shot performance on KITTI
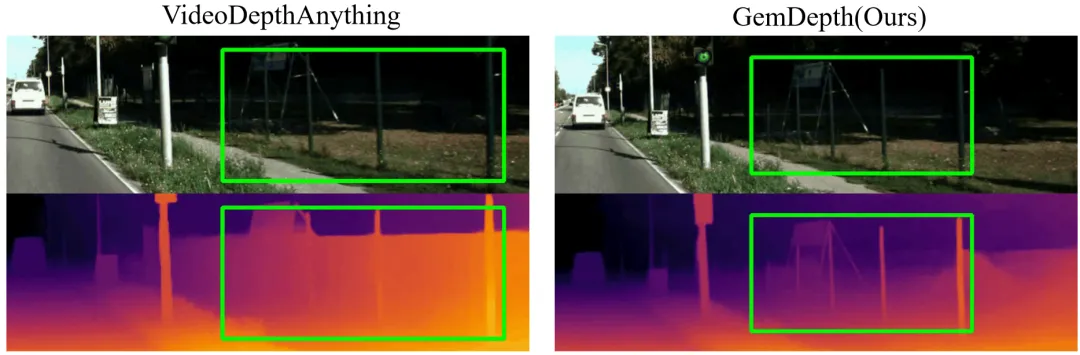
以下是我们的模型与之前的判别式视频深度估计SOTA方法VideoDepthAnything的比较。我们的方法GemDepth在具有挑战性的区域(远处的栅栏,墙壁)中有显著的改善。

- Pointcloud comparation
以下是GemDeth以及竞争方法预测depth的点云可视化效果,GemDepth能产生最干净高质量的点云。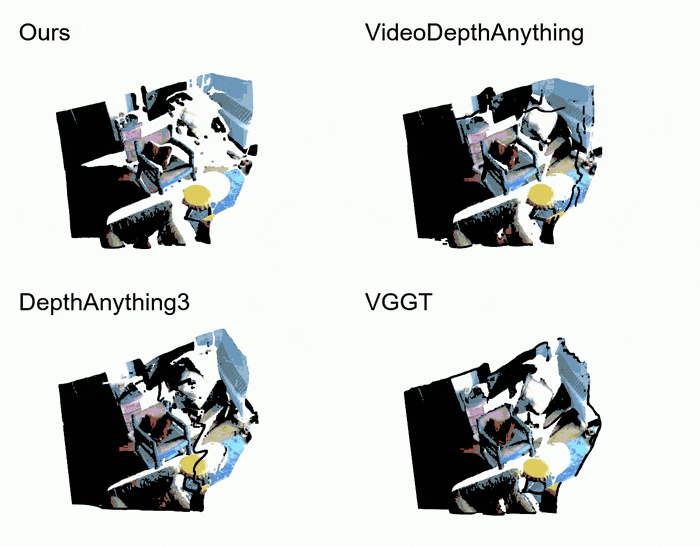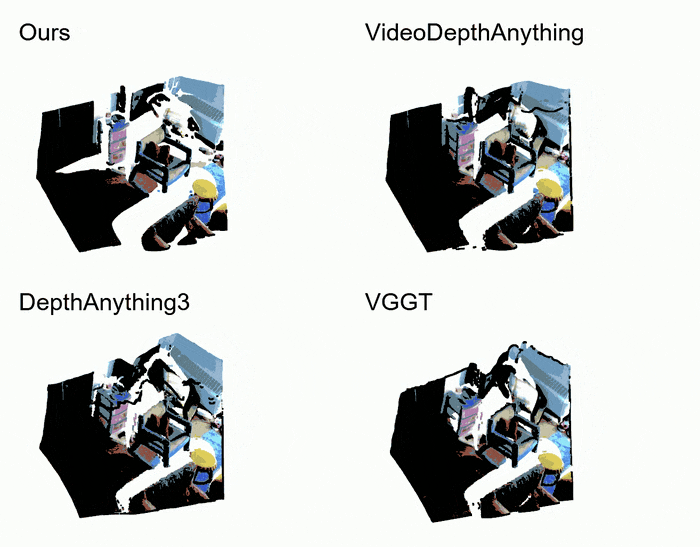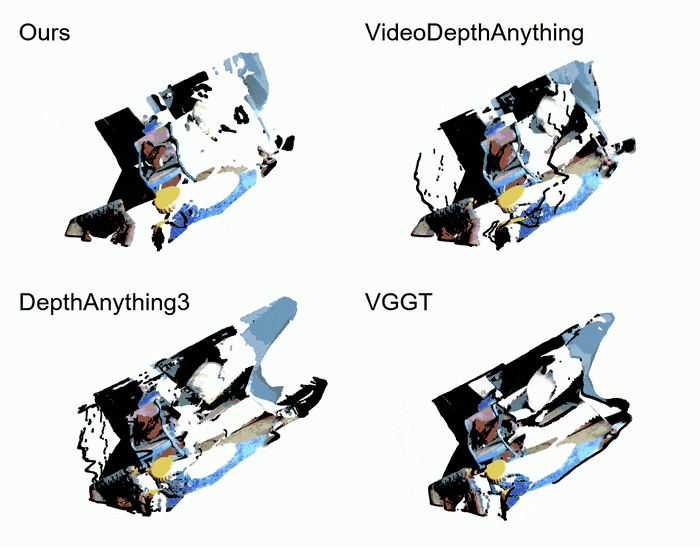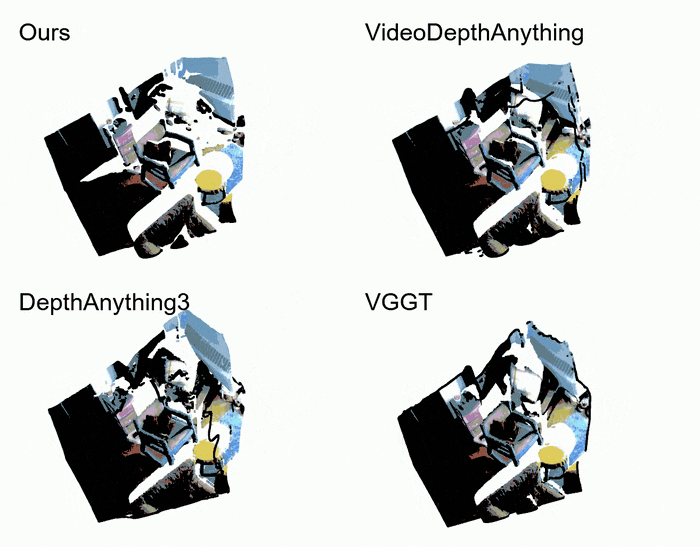
03 总结
本研究提出了一种全新的视频深度估计架构——GemDepth,旨在攻克传统方法在处理动态环境及长序 列视频时频发的时序抖动与尺度二义性瓶颈。
广泛的实验验证表明,GemDepth 不仅在四个主流基准数 据集上刷新了当前最优(SOTA)记录,同时在面对长度各异、极具挑战性的真实物理世界视频时,展现出了卓越的零样本(Zero-shot)泛化效能。
较之现阶段的视频深度估计算法,GemDepth 的核心技术优势体现在以下四个维度:
- 严苛的时空三维几何一致性:依托引入的全局几何先验知识,模型能够从容应对剧烈的摄像机视角偏移,有效抑制长序列视频中的帧间闪烁与结构畸变现象。
- 高频空间细节的高度保留:借助将“时序对齐”与“空间精调”相解耦的交替迭代机制,网络能够精确定位底层的点级映射关系,从而在深度预测中完整保留复杂目标物体的锐利物理边缘。
- 面向高动态场景的鲁棒感知力:该架构可高效调动几何线索以屏蔽非刚性运动带来的背景干扰,确保在包含大量动态元素的复杂序列中,依然能够维持高精度的深度推断。
- 全场景无损三维点云重建:基于跨帧的极致时序连贯性与单帧的高保真空间分辨率,由预测序列直接反投影生成的三维点云结构高度致密,从根本上消除了视觉可见的几何伪影。
论文出处:ICML 2026
论文标题:GemDepth: Geometry-Embedded Features for 3D-Consistent Video Depth
论文链接:https://arxiv.org/abs/2605.10525
代码链接:https://github.com/Yuecheng919/GemDepth
本文作者来自于华中科技大学杨欣团队和酷睿程团队,一作刘粤诚,通讯程俊达

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)