凭什么封神?GPT-5.5 深度横评:当“大模型”进化成“全自动流水线
2026年4月23日,OpenAI悄然发布了GPT-5.5。这不是又一次的“小升级”,而是AI发展史上的一个重要节点。标题中的“封神”二字,听起来夸张,但当你亲身测试后,会发现它确实配得上这个词——至少在“agentic”(智能体化)工作流领域,它把“大模型”从一个聪明的对话者,真正进化成了能独立运转的“全自动流水线”。
过去,我们用GPT-4o、GPT-5系列时,还需要大量提示工程(prompt engineering)、反复迭代、人工干预。现在,GPT-5.5能理解复杂目标、使用工具、自检工作、持续推进直到完成任务。它标志着AI从“辅助工具”向“自主工作者”的转变。
这篇文章将从基准测试、实际用例、与其他模型的横评、底层机制、优缺点、行业影响,到未来展望,进行全面拆解。希望帮助你判断:GPT-5.5是否值得“封神”,以及如何在实际工作中部署它。
第一章:GPT-5.5核心技术亮点与演进路径
1.1 从GPT-5到GPT-5.5的迭代
GPT-5系列从2025年8月发布起,就强调“统一系统”:一个高效基础模型+深度推理路径+智能路由。GPT-5.5在此基础上进行了“完全重训”(full retrain),重点强化agentic能力。
关键升级:
- 1M+上下文窗口(约922K输入+128K输出),支持超大规模代码库、文档集分析。
- 原生工具使用与计算机操控:能直接操作终端、浏览器、桌面应用。
- 自反思与自我验证:生成输出前自动检查,减少幻觉。
- 多步长时序行动:能执行上千步工具调用而无需人工干预。
- 效率优化:相同质量下,token消耗更低,实际成本下降。
与GPT-5.4相比,GPT-5.5在ARC-AGI-2等抽象推理基准上从73.3%跃升至85.0%,Terminal-Bench 2.0达82.7%。
1.2 “全自动流水线”的技术基石
“大模型进化成流水线”的核心是Agentic Workflow。传统LLM是单次生成,Agentic则形成闭环:感知(Observe)→规划(Plan)→行动(Act)→反思(Reflect)。
GPT-5.5内置了更强的规划器、记忆模块和工具编排引擎。它不再是“听指令做事”,而是“理解目标后自主拆解并执行”。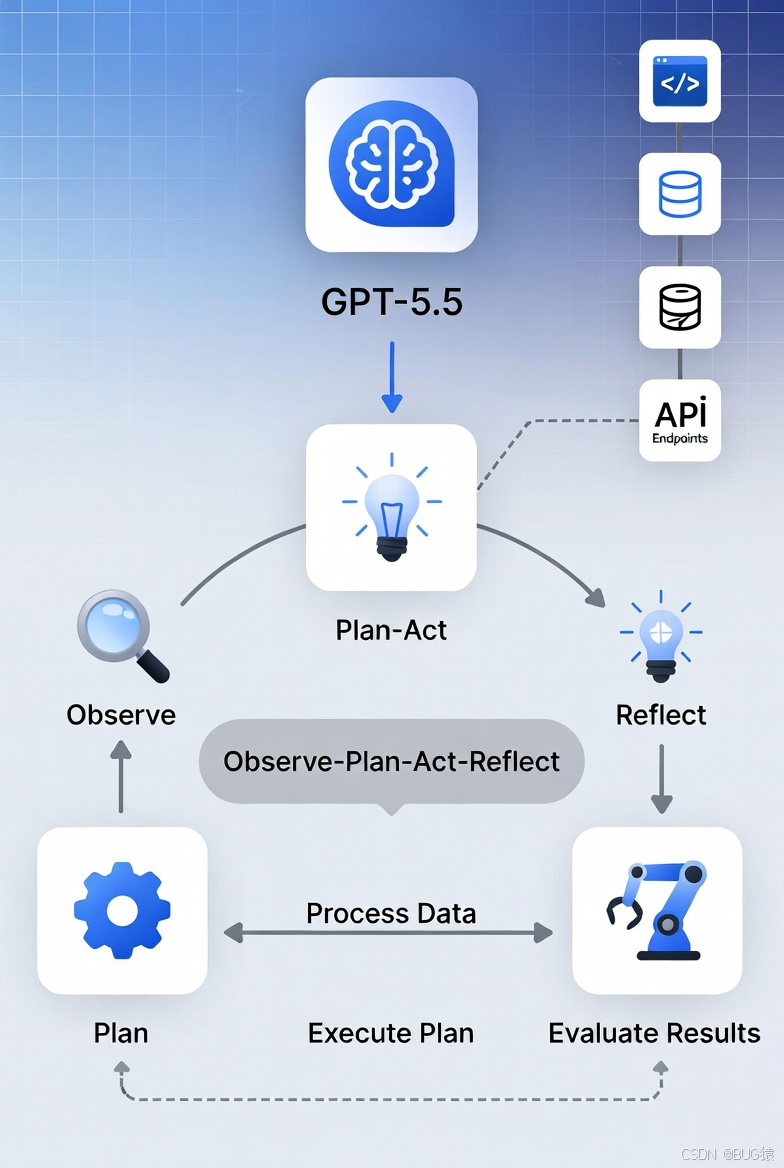
(Workflow循环示意图)
第二章:基准测试深度横评
2.1 综合智能基准
GPT-5.5在多个前沿基准上领跑或并跑:
- GPQA Diamond(研究生级科学):接近或超过93%,领先多数竞品。
- MMLU-Pro / Humanity’s Last Exam:高分,体现广度与深度。
- ARC-AGI-2:85%,抽象推理重大突破。
2.2 编程与Agentic Coding能力
这是GPT-5.5最闪耀的领域。
- Terminal-Bench 2.0(命令行复杂工作流):82.7%,大幅领先Claude Opus 4.7的69.4%和Gemini 3.1 Pro的68.5%。
- SWE-Bench Pro(真实GitHub问题解决):58.6%,Claude Opus 4.7以64.3%略胜,但GPT-5.5在端到端单次通过率和长时序任务上更强。
- SWE-Bench Verified:据多个来源,GPT-5.5可达82%以上高位。
- OSWorld-Verified(计算机使用):78.7%,展现桌面级自主操作能力。
- Expert-SWE(内部长时程编码,模拟20小时人类工作):显著优于前代。
实际测试洞察:在真实代码库重构中,GPT-5.5倾向于生成更小、更可审查的补丁,验证步骤更严谨。Claude在某些多文件推理上仍有优势,但GPT-5.5的工具协调和持久性更胜一筹。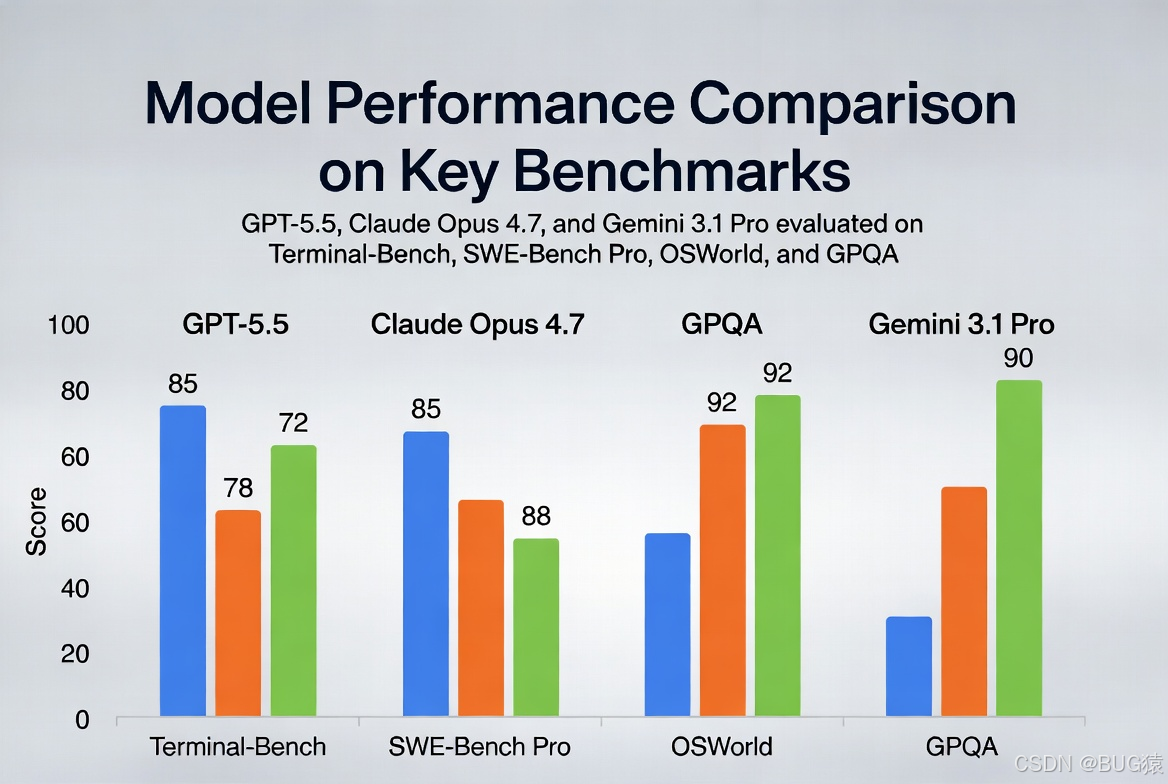
(配图3:SWE-Bench等基准柱状图对比)
2.3 其他领域表现
- 知识工作(GDPval):84.9%,领先。
- 浏览与研究(BrowseComp):84.4%。
- 多模态与视觉推理:强劲,支持图像输入。
- 数学与科学:HMMT、FrontierMath等高分,尤其带工具时接近完美。
与Claude Opus 4.7相比,GPT-5.5更“流水线化”——适合长时间自主运行;Claude在创意写作和精细风格控制上仍有一席之地。Gemini在搜索集成和某些多语言任务上有优势,但整体agentic能力稍弱。
第三章:真实世界用例详解
3.1 软件开发流水线
场景:一个中型SaaS产品的功能迭代。
传统方式:产品经理写需求→开发者编码→测试→部署,来回多次。
GPT-5.5+Codex模式:
- 输入高层目标(如“实现用户权限系统,支持RBAC和审计日志”)。
- 模型自动规划:分析现有代码库、设计schema、生成迁移脚本、编写后端API、前端组件、单元测试、集成测试。
- 使用工具:浏览文档、执行终端命令、运行测试、修复bug。
- 自检并迭代,直到通过CI/CD。
开发者反馈:在Codex中,GPT-5.5能处理完整特性开发,减少80%以上重复劳动。
(配图4:AI编码代理工作流示例)
3.2 研究与情报分析流水线
输入:“针对2026年AI监管政策,进行全面竞品分析并生成报告。”
GPT-5.5会:
- 自主网页浏览与搜索。
- 提取、交叉验证信息。
- 构建知识图谱。
- 生成结构化报告(含图表、引用)。
- 如果发现矛盾,主动提问或深入挖掘。
适用于咨询、学术、投资研究。效率提升5-10倍。
3.3 企业自动化:数据处理、客服、运营
- 文档处理:批量PDF/邮件分类、提取、异常检测。
- 客服:复杂工单全流程处理(查历史、应用政策、起草回复、升级)。
- DevOps:监控告警→诊断→修复脚本生成→部署验证。
Tau2-bench Telecom等基准显示其多轮工具准确率高达98%。
3.4 个人生产力革命
普通用户在ChatGPT Pro中使用GPT-5.5 Instant或Pro版本,能让AI像“私人全能助理”:规划旅行(含实时预订逻辑)、写作长文并迭代、学习复杂主题并出测试题等。
第四章:与其他前沿模型深度横评
4.1 vs Claude Opus 4.7
- 优势互补:Claude在SWE-Bench Pro和创意任务上略胜,风格更谨慎优雅。GPT-5.5在agentic、终端操作、知识工作上领先。
- 定价与效率:GPT-5.5 token效率更高,长期运行成本可能更优。
- 适用:复杂自主项目选GPT-5.5;需要极致代码审美或长上下文精细推理可选Claude。
4.2 vs Gemini 3.1 Pro
Gemini搜索与多模态集成强,但agentic持久性和编码深度稍逊。GPT-5.5更适合“闭环完成任务”。
4.3 vs 开源/其他
DeepSeek等在性价比上有优势,但前沿agentic能力仍落后封闭模型一代。
总结表格(文字描述):
| 维度 | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Agentic Coding | 优秀 | 良好 | 中等 |
| 自主持久性 | 顶尖 | 良好 | 良好 |
| 创意写作 | 良好 | 顶尖 | 良好 |
| 成本效率 | 高 | 中等 | 高 |
| 计算机使用 | 顶尖 | 良好 | 中等 |
第五章:定价、访问与部署建议
- ChatGPT:Plus/Pro/Enterprise用户可用GPT-5.5及Pro版本。
- API:输入$5/百万tokens,输出$30/百万(大致),1M上下文。
- Codex:专为开发者优化。
部署Tips:
- 用“高推理努力”(high reasoning effort)处理复杂任务。
- 结合自定义GPTs或外部工具链构建专属流水线。
- 注意安全:OpenAI加强了防护,但高能力模型仍需谨慎使用敏感场景。
第六章:潜在风险、局限性与伦理讨论
局限:
- 仍可能在极端边缘案例幻觉或卡住。
- 高阶任务需良好提示引导。
- 计算成本对个人用户仍较高。
- 安全边界:尽管有最强防护,agentic能力提升了滥用潜力。
伦理:AI流水线化将重塑就业。程序员从“码农”变“架构师+监督者”。社会需思考教育转型与UBI等议题。
OpenAI的系统卡显示他们在红队测试和生物/网络安全上做了大量工作。
第七章:行业影响与未来展望
GPT-5.5加速了“AI Native”企业的诞生。初创公司能用少量人力实现复杂产品开发;大企业能自动化海量中后台工作。
未来方向:
- 多代理协作系统(Multi-Agent)。
- 更强世界模型与具身智能。
- 与机器人、AR/VR深度集成。
- 2027年可能看到GPT-6级“通用代理”。
“大模型”已死,“智能体流水线”时代来临。
结语:值得封神吗?
是的,在agentic工作流这个维度,GPT-5.5配得上“封神”。它不是完美无缺,但它把AI的实用性推到了新高度——从“帮我写代码”到“替我把这个项目做完”。
对于开发者、研究者、企业决策者:现在就是拥抱并实验的最佳时机。不要只聊天,用它构建你的第一条“全自动流水线”。
行动号召:去ChatGPT或API试用GPT-5.5,输入一个你拖延已久的项目目标,看它如何拆解执行。然后告诉我你的体验。
参考来源:OpenAI官方公告、各类基准Leaderboard、开发者社区反馈等。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)