LEC 3 OS organization and system calls
Xv6 kernel source files.
| File | Description |
|---|---|
| bio.c | Disk block cache for the file system. |
| console.c | Connect to the user keyboard and screen. |
| entry.S | Very first boot instructions. |
| exec.c | exec() system call. |
| file.c | File descriptor support. |
| fs.c | File system. |
| kalloc.c | Physical page allocator. |
| kernelvec.S | Handle traps from kernel, and timer interrupts. |
| log.c | File system logging and crash recovery. |
| main.c | Control initialization of other modules during boot. |
| pipe.c | Pipes. |
| plic.c | RISC-V interrupt controller. |
| printf.c | Formatted output to the console. |
| proc.c | Processes and scheduling. |
| sleeplock.c | Locks that yield the CPU. |
| spinlock.c | Locks that don’t yield the CPU. |
| start.c | Early machine-mode boot code. |
| string.c | C string and byte-array library. |
| swtch.S | Thread switching. |
| syscall.c | Dispatch system calls to handling function. |
| sysfile.c | File-related system calls. |
| sysproc.c | Process-related system calls. |
| trampoline.S | Assembly code to switch between user and kernel. |
| trap.c | C code to handle and return from traps and interrupts. |
| uart.c | Serial-port console device driver. |
| virtio_disk.c | Disk device driver. |
| vm.c | Manage page tables and address spaces. |
当 RISC-V 计算机上电时,它会对自身进行初始化,并运行一个存储在只读存储器中的引导加载程序。该引导加载程序将 xv6 内核加载到内存中。随后,在机器模式(machine mode)下,CPU 从 _entry(kernel/entry.S:7)开始执行 xv6。RISC-V 启动时分页硬件处于禁用状态:虚拟地址直接映射到物理地址。 加载程序将 xv6 内核加载到物理地址 0x80000000 处的内存中。之所以将内核放置在 0x80000000 而不是 0x0,是因为地址范围 0x0:0x80000000 包含 I/O 设备。_entry 处的指令设置栈,使 xv6 能够运行 C 代码。Xv6 在文件 start.c(kernel/start.c:11)中为初始栈 stack0 声明空间。_entry 处的代码将栈指针寄存器 sp 加载为地址 stack0+4096,即栈顶,因为 RISC-V 上的栈向下增长。既然内核已经拥有栈,_entry 便调用 start(kernel/start.c:21)处的 C 代码。函数 start 执行一些仅允许在机器模式下进行的配置,然后切换到监督者模式(supervisor mode)。为进入监督者模式,RISC-V 提供了指令 mret。该指令最常用于之前从监督者模式进入了机器模式,现在从机器模式返回到之前的监督者模式。start 并不是从这样的调用返回,而是将相关状态设置得仿佛曾发生过这样一次调用:它在寄存器 mstatus 中将先前的特权模式设置为监督者模式;通过将 main 的地址写入寄存器 mepc,将返回地址设置为 main;通过向页表寄存器 satp 写入 0,在监督者模式下禁用虚拟地址转换;并将所有中断和异常委派给监督者模式。在跳转到监督者模式之前,start 还执行一项任务:对时钟芯片进行编程,使其生成定时器中断。在完成这些准备工作之后,start 通过调用 mret “返回”到监督者模式。这会使程序计数器变为 main(kernel/main.c:11)。在 main(kernel/main.c:11)初始化若干设备和子系统之后,它通过调用 userinit(kernel/proc.c:226)创建第一个进程。第一个进程执行一个用 RISC-V 汇编编写的小程序,并发起 xv6 中的第一次系统调用。initcode.S(user/initcode.S:3)将 exec 系统调用的编号 SYS_EXEC(kernel/syscall.h:8)加载到寄存器 a7 中,然后调用 ecall 以重新进入内核。内核在 syscall(kernel/syscall.c:133)中使用寄存器 a7 中的编号来调用所需的系统调用。系统调用表(kernel/syscall.c:108)将 SYS_EXEC 映射到 sys_exec,内核随后调用该函数。正如我们在第 1 章中所见,exec 会用一个新程序(在本例中为 /init)替换当前进程的内存和寄存器。一旦内核完成 exec,它便返回到 /init 进程的用户空间。Init(user/init.c:15)在需要时创建一个新的控制台设备文件,然后将其作为文件描述符 0、1 和 2 打开。随后,它在控制台上启动一个 shell。至此,系统已启动完毕。
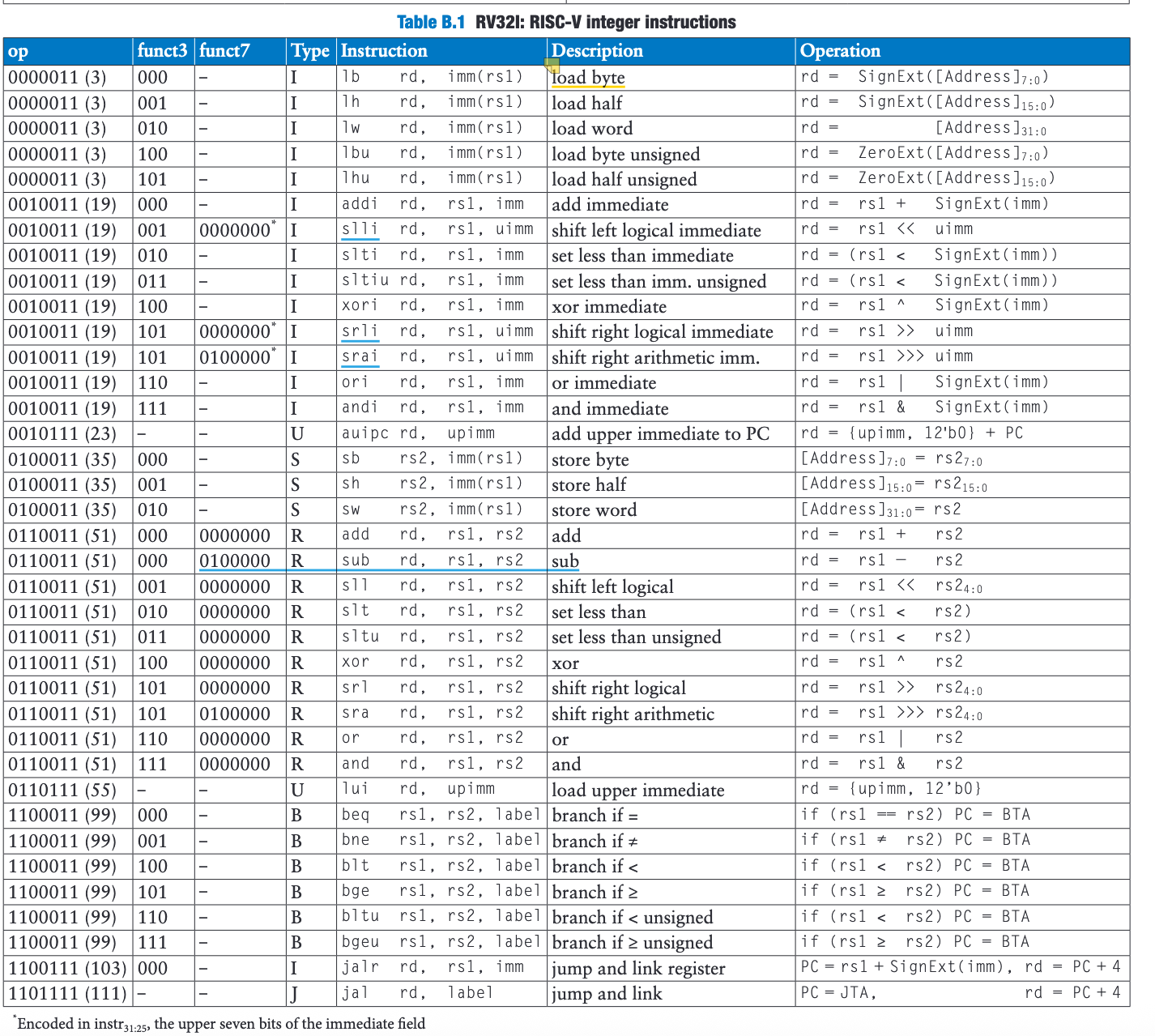
RISC-V 基础指令集
指令集
![![[6232c2d3-0890-4252-b923-09983ec2b1d7.png]]](https://i-blog.csdnimg.cn/direct/a09eeb9ea8ac4cdb95deedf7323245ab.png)
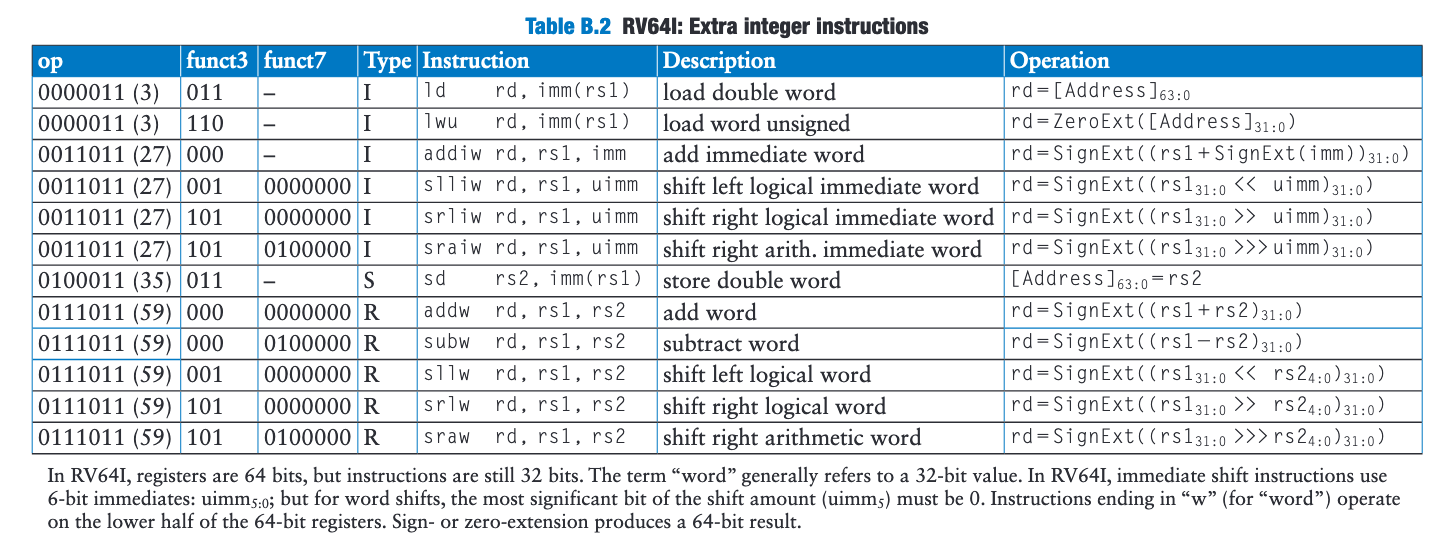
RV32 和 RV64 的区别
RV32 与 RV64 的核心区别是 XLEN 不同。XLEN 表示通用整数寄存器的位宽,也是多数整数运算的默认操作数宽度。
| 对比项 | RV32 | RV64 |
|---|---|---|
XLEN |
32 位 | 64 位 |
| 通用寄存器宽度 | x0-x31 各 32 位 |
x0-x31 各 64 位 |
| 地址空间 | 以 32 位地址空间为主 | 以 64 位地址空间为主 |
| 指针大小 | 通常为 4 字节 | 通常为 8 字节 |
long 类型大小 |
通常为 4 字节 | 通常为 8 字节 |
| 基础整数指令集 | RV32I |
RV64I |
| Load/Store | 支持到 lw/sw |
增加 ld/sd 等 64 位访存指令 |
| 32 位运算 | 默认整数运算即为 32 位 | 使用带 w 后缀的 word 指令 |
寄存器宽度
RV32 的通用寄存器宽度为 32 位,RV64 的通用寄存器宽度为 64 位。因此,同一条整数运算指令在两种架构中的默认操作数宽度不同。
add a0, a1, a2
在 RV32 中,该指令执行 32 位加法;在 RV64 中,该指令执行 64 位加法。
指针和地址宽度
RV32 通常使用 32 位地址空间,指针大小为 4 字节;RV64 通常使用 64 位地址空间,指针大小为 8 字节。该差异会影响 C 程序的数据结构布局。
struct node {
int value;
struct node *next;
};
在 RV32 中,next 指针通常占 4 字节;在 RV64 中,next 指针通常占 8 字节。因此,相同结构体在 RV64 上可能占用更多内存。
Load/Store 指令
RV64 在 RV32 的基础上增加了 64 位访存指令。
| 指令 | RV32 | RV64 | 含义 |
|---|---|---|---|
lb |
支持 | 支持 | 读取 8 位并符号扩展 |
lbu |
支持 | 支持 | 读取 8 位并零扩展 |
lh |
支持 | 支持 | 读取 16 位并符号扩展 |
lhu |
支持 | 支持 | 读取 16 位并零扩展 |
lw |
支持 | 支持 | 读取 32 位;在 RV64 中符号扩展到 64 位 |
lwu |
不支持 | 支持 | 读取 32 位并零扩展到 64 位 |
ld |
不支持 | 支持 | 读取 64 位 |
sb |
支持 | 支持 | 写入低 8 位 |
sh |
支持 | 支持 | 写入低 16 位 |
sw |
支持 | 支持 | 写入低 32 位 |
sd |
不支持 | 支持 | 写入 64 位 |
在 RV64 中,保存返回地址 ra 到栈上通常使用 sd:
sd ra, 8(sp)
在 RV32 中,保存返回地址通常使用 sw:
sw ra, 4(sp)
Word 指令
RV64 的普通整数运算默认处理 64 位数据。若需要执行 32 位整数运算,应使用带 w 后缀的 word 指令。w 表示 32 位 word。
| 指令 | 含义 |
|---|---|
addw rd, rs1, rs2 |
对低 32 位执行加法,结果符号扩展到 64 位 |
subw rd, rs1, rs2 |
对低 32 位执行减法,结果符号扩展到 64 位 |
addiw rd, rs1, imm |
对低 32 位执行立即数加法,结果符号扩展到 64 位 |
sllw rd, rs1, rs2 |
对低 32 位执行逻辑左移,结果符号扩展到 64 位 |
srlw rd, rs1, rs2 |
对低 32 位执行逻辑右移,结果符号扩展到 64 位 |
sraw rd, rs1, rs2 |
对低 32 位执行算术右移,结果符号扩展到 64 位 |
addw a0, a1, a2
该指令只对 a1 和 a2 的低 32 位执行加法,并将 32 位结果符号扩展到 64 位后写入 a0。这类指令主要用于支持 C 语言中的 32 位 int 运算。
指令编码
RV32I 与 RV64I 的基础指令编码格式基本一致,包括:
R-typeI-typeS-typeB-typeU-typeJ-type
差异主要体现在操作数位宽、部分新增指令以及移位量范围上。例如,ld、sd、lwu、addw 等指令只存在于 RV64I 中。
移位指令
由于寄存器宽度不同,移位量范围也不同。
| 指令类型 | RV32 | RV64 |
|---|---|---|
| 普通移位 | 移位量通常取低 5 位,范围为 0-31 | 移位量通常取低 6 位,范围为 0-63 |
| word 移位 | 默认即为 32 位移位 | 使用 sllw、srlw、sraw 等 word 指令 |
RV64 中的 64 位移位可以使用更大的移位量:
slli a0, a0, 63
对 xv6 的影响
xv6-riscv 使用 RV64,因此阅读 xv6 汇编代码时需要注意以下特征:
| 现象 | 原因 |
|---|---|
经常出现 ld/sd |
保存和恢复 64 位寄存器 |
| 栈上保存一个寄存器通常占 8 字节 | 通用寄存器宽度为 64 位 |
| 指针大小为 8 字节 | 内核运行在 64 位 RISC-V 上 |
页表项 PTE 为 64 位 |
xv6-riscv 使用 64 位地址相关机制 |
satp、sepc、stvec 等 CSR 保存地址或状态 |
与 64 位特权架构相关 |
RV64 中常见的函数序言:
addi sp, sp, -16
sd ra, 8(sp)
sd s0, 0(sp)
对应的 RV32 写法通常为:
addi sp, sp, -8
sw ra, 4(sp)
sw s0, 0(sp)
小结
RV32 是 32 位 RISC-V,寄存器、指针和默认整数运算以 32 位为主;RV64 是 64 位 RISC-V,寄存器、指针和默认整数运算以 64 位为主,并增加了 64 位访存指令和 32 位 word 运算指令。
阅读 xv6-riscv 时需要重点记住:
- xv6-riscv 使用
RV64; - 通用寄存器为 64 位;
- 指针大小为 8 字节;
- 保存和恢复寄存器通常使用
sd/ld; - 带
w后缀的指令表示在 64 位机器上执行 32 位运算。
RISC-V常见的伪指令
li a1, 1
la a0, .string
call printf
ret
mv t0, a0
j label
beqz rs, label
li rd, imm:li是 load immediate,把立即数装入寄存器rd。la rd, symbol:la是 load address,加载某个标签或全局符号的地址到寄存器rd。call printf: 会跳到printf,同时把返回地址保存到ra,等printf执行完后,它会通过ret回来,调用printf之前要先保存ra。ret:函数返回,展开成jalr zero, 0(ra),跳转到ra寄存器保存的值 + 0的位置,zero = PC+4(zero只读,这句无意义)。mv rd, rs:mv是 move,把一个寄存器的值复制到另一个寄存器。j label:无条件跳转,展开成jal zero, loop,jal本来会保存返回地址,但这里目标寄存器是zero,所以返回地址被丢弃,效果就是单纯跳转。beqz rs, label:如果 rs == 0,跳转到 label。
RISC-V 内联汇编
RISC-V 内联汇编指在 C 代码中直接嵌入汇编指令。xv6-riscv 中常用它访问普通 C 无法直接访问的硬件状态,例如 CSR、特权指令、栈指针、hart id 等。
内联汇编适合处理以下场景:
- 读写 CSR,例如
sstatus、satp、sepc、stvec; - 执行特权指令,例如
sfence.vma、wfi; - 访问特殊寄存器,例如
sp、tp; - 实现极短且必须精确控制指令的底层代码。
不适合使用内联汇编的场景:
- 普通算术、逻辑运算;
- 普通内存复制或循环优化;
- 可以由 C 编译器稳定生成的常规代码。
原因是内联汇编会限制编译器优化,并且需要手动告诉编译器哪些寄存器、内存或状态被修改。
基本语法
GNU C 风格的扩展内联汇编格式如下:
asm volatile (
"assembly template"
: output operands
: input operands
: clobbers
);
完整结构可以理解为:
asm volatile(
"汇编指令模板"
: 输出操作数
: 输入操作数
: 被破坏的寄存器或状态
);
各部分含义如下:
| 部分 | 作用 |
|---|---|
asm |
表示嵌入汇编代码 |
volatile |
告诉编译器该汇编有副作用,不能随意删除或合并 |
| 汇编模板 | 实际要生成的汇编指令 |
| 输出操作数 | 汇编代码写回到 C 变量的结果 |
| 输入操作数 | C 变量传入汇编代码的值 |
| clobbers | 告诉编译器汇编代码额外修改了哪些寄存器、内存或状态 |
其中 volatile 主要用于有副作用的指令,例如读写 CSR、执行 sfence.vma、wfi、ecall 等。如果汇编只是根据输入计算输出,且输出被 C 代码使用,则不一定需要 volatile。
操作数占位符
内联汇编模板中的 %0、%1、%2 表示操作数占位符。编号从输出操作数开始,然后继续编号输入操作数。
uint64 out;
uint64 a = 1;
uint64 b = 2;
asm volatile(
"add %0, %1, %2"
: "=r"(out)
: "r"(a), "r"(b)
);
操作数对应关系如下:
| 占位符 | 对应 C 表达式 | 含义 |
|---|---|---|
%0 |
out |
输出操作数 |
%1 |
a |
第一个输入操作数 |
%2 |
b |
第二个输入操作数 |
编译器会为这些操作数分配实际寄存器。最终生成的指令可能类似:
add a5, a0, a1
因此,内联汇编中通常不应手动固定使用 t0、t1 等寄存器,除非同时在 clobber list 中声明它们被修改。
常见约束
约束用于告诉编译器某个操作数应该放在哪里,以及该操作数是读、写还是读写。
| 约束 | 含义 |
|---|---|
"r"(x) |
将 x 放入通用寄存器,作为输入 |
"=r"(x) |
将结果写入通用寄存器,再写回 x;= 表示只写 |
"+r"(x) |
x 既作为输入又作为输出 |
"i"(imm) |
编译期立即数 |
"I"(imm) |
RISC-V I-type 12 位有符号立即数 |
"K"(imm) |
RISC-V CSR 指令使用的 5 位无符号立即数 |
"memory" |
告诉编译器该汇编可能读写未显式列出的内存,使编译器不能错误复用、合并或移动相关内存访问 |
示例:
asm volatile("addi %0, %1, 1" : "=r"(out) : "r"(in));
含义:
%0是输出寄存器;%1是输入寄存器;- 编译器负责选择具体寄存器;
- 汇编执行后,输出寄存器的值写回 C 变量
out。
volatile 与 memory 的区别
volatile 和 memory clobber 解决的问题不同。
| 写法 | 作用 |
|---|---|
asm volatile(...) |
防止该汇编语句被删除或与相同语句合并 |
::: "memory" |
告诉编译器该汇编可能读写某些未显式列在输入/输出操作数中的内存 |
"memory" 是给编译器看的约束,不是 RISC-V 指令。它不会生成硬件内存屏障,也不表示所有寄存器都会被保存或重新读取。
更准确地说,"memory" 会使编译器在该 asm 前后重新考虑内存状态:
- asm 前已经写入、且可能被 asm 观察到的内存,不能被错误移动到 asm 之后;
- asm 后需要读取、且可能被 asm 修改过的内存,不能简单复用 asm 之前缓存的旧值;
- 只保存在寄存器中的普通局部变量不受
"memory"影响,除非它对应的内存对象需要在 asm 前后保持一致; - 如果 asm 会修改某个寄存器,应使用 clobber list 显式声明该寄存器,而不是依赖
"memory"。
例如:
asm volatile("fence rw, rw" ::: "memory");
这里有两层含义:
fence rw, rw约束 CPU 层面的内存访问顺序;"memory"告诉编译器该 asm 可能影响内存,避免编译器错误地跨越该语句复用、合并或移动相关内存访问。
因此,volatile、"memory" 和 fence 分别处理不同层面的问题:
| 机制 | 作用层面 | 主要作用 |
|---|---|---|
volatile |
编译器 | 防止 asm 被删除或合并 |
"memory" |
编译器 | 告知 asm 可能读写未知内存,约束相关内存优化 |
fence |
CPU/硬件 | 约束硬件层面的内存访问顺序 |
读改写操作数
如果一个 C 变量既作为输入又作为输出,应使用 +r。
uint64 x;
asm volatile(
"addi %0, %0, 1"
: "+r"(x)
);
含义:
- 汇编执行前,
x的值被放入%0; - 汇编执行后,
%0的值写回x; +表示该操作数既读又写。
如果错误地写成 =r,编译器会认为该操作数只写不读,从而可能生成错误代码。
常见错误
| 错误 | 后果 |
|---|---|
有副作用的汇编不写 volatile |
可能被编译器删除或移动 |
asm 读写未显式列出的内存但不写 "memory" |
编译器可能错误复用、合并或移动相关内存访问 |
手动使用 t0、t1 等寄存器但不声明 clobber |
可能破坏编译器保存的 C 变量 |
把读写操作数写成只写约束 =r |
编译器可能认为原值无用,导致错误代码 |
在内联汇编中随意修改 sp、ra |
可能破坏函数调用栈或返回地址 |
| 在普通用户态代码中执行特权指令 | 可能触发非法指令异常或 trap |
在汇编中跳转到 C 标签但不用 asm goto |
编译器无法正确理解控制流 |
RISCV内嵌汇编代码与宏结合
内嵌汇编代码与C语言宏可以结合使用,让代码变得更简洁。我们可以巧妙地使用C语言宏中的#以及##符号:
- 若在宏的参数前面添加
#,预处理器会把这个参数转换为一个字符串。 ##用于连接参数和另一个标识符,形成新的标识符。
下面代码所示为ATOMIC_OP宏,它在Linux 5.15内核里实现,代码路径为arch/ riscv/include/asm/atomic.h。
通过调用ATOMIC_OP宏实现了多个函数,如atomic_add()函数、atomic_or()函数、atomic_xor()函数等。
使用##把atomic_与宏的参数op拼接在一起,构成函数名;使用#把参数asm_op转换成一个字符串。例如,假设asm_op参数为add,asm_tp参数为w那就变成amoadd.w zero, %1, %0\n。
#define ATOMIC_OP(op, asm_op, I, asm_type, c_type, prefix) \
static __always_inline \
void atomic##prefix##_##op(c_type i, atomic##prefix##_t *v) \
{ \
__asm__ __volatile__ ( \
"amo" #asm_op "." #asm_type " zero, %1, %0" \
: "+A" (v->counter) \
: "r" (I) \
: "memory"); \
} \
#define ATOMIC_OPS(op, asm_op, I) \
ATOMIC_OP (op, asm_op, I, w, int, ) \
ATOMIC_OPS(add, add, i)
ATOMIC_OPS(sub, add, -i)
ATOMIC_OPS(and, and, i)
ATOMIC_OPS( or, or, i)
ATOMIC_OPS(xor, xor, i)
ATOMIC_OPS(add, add, i) 展开后变成如下代码
static __always_inline
void atomic_add(int i, atomic_t *v)
{
__asm__ __volatile__ (
"amoadd.w zero, %1, %0"
: "+A" (v->counter)
: "r" (i)
: "memory");
}
trapframe
trapframe是用户态 → 内核态切换时的「寄存器快照」+「路径地图」,它的本质是一个 「用户↔内核边界的上下文缓存」:
- 保存区:用户态被中断时的完整 CPU 状态
- 路径地图:内核回来的路标(satp / sp / trap / hartid)
- 隔离边界:只存在于用户页表映射中,内核页表不可见,确保用户态无法直接读写内核内存
物理布局上,trapframe 独占一页内存,紧贴在 trampoline page 下面。这个地址通过 RISC-V 的 CSR 寄存器(系统控制和状态寄存器,Control and Status Register , CSR)sscratch 指向。
XV6 在进入用户态之前,会把当前进程的 trapframe 地址提前放进 RISC-V 的 sscratch 寄存器里。等用户程序发生系统调用、中断或异常时,trampoline.S 就能从 sscratch 里拿到 trapframe 地址,把用户寄存器保存进去。
trapframe 这页内存映射在用户页表里,但没有 PTE_U 权限,所以用户态代码不能访问;
内核页表中没有把它映射到 TRAPFRAME 这个虚拟地址;trampoline.S 在刚进入内核、还没切换到内核页表之前,借助用户页表中的 TRAPFRAME 映射来访问它。
用户态运行
↓ ecall / 中断
进入 supervisor mode
↓
仍然使用用户页表
↓
跳到 trampoline.S:uservec
↓
uservec 访问 TRAPFRAME,保存寄存器
↓
再切换到内核页表
源码来自xv6-labs-2021/kernel/proc.h
// per-process data for the trap handling code in trampoline.S.
// sits in a page by itself just under the trampoline page in the
// user page table. not specially mapped in the kernel page table.
// the sscratch register points here.
// uservec in trampoline.S saves user registers in the trapframe,
// then initializes registers from the trapframe's
// kernel_sp, kernel_hartid, kernel_satp, and jumps to kernel_trap.
// usertrapret() and userret in trampoline.S set up
// the trapframe's kernel_*, restore user registers from the
// trapframe, switch to the user page table, and enter user space.
// the trapframe includes callee-saved user registers like s0-s11 because the
// return-to-user path via usertrapret() doesn't return through
// the entire kernel call stack.
/*
trapframe 是每个进程独有的数据结构,主要供 trampoline.S 中的 trap 处理代码使用。它单独占用一个页面,位于用户页表中 trampoline 页面正下方,但并不会以特殊方式映射到内核页表中。在用户态运行时,RISC-V 的 sscratch 寄存器会指向当前进程的 trapframe。当用户进程发生系统调用、中断或异常并进入内核时,trampoline.S 中的 uservec 会先把用户态寄存器保存到 trapframe 中,然后从 trapframe 的 kernel_sp、kernel_hartid、kernel_satp 等字段中取出内核栈、CPU 编号和内核页表等信息,完成运行环境切换,并跳转到 kernel_trap,也就是内核中的 usertrap() 函数进行处理。内核处理完成后,usertrapret() 和 trampoline.S 中的 userret 会重新设置 trapframe 中的 kernel_* 字段,从 trapframe 恢复用户寄存器,切换回用户页表,并通过 sret 返回用户空间。普通 C 函数调用,s0-s11 由被调用者保存到栈上,调用链返回时自然恢复。但从用户态 trap 进内核再返回,不是沿着调用链一层层返回到用户态——而是usertrapret() 直接跳到 trampoline 的 userret,然后一个 sret 飞回用户态,所以即使是 s0-s11 这类通常由被调用者保存的寄存器,也必须保存在 trapframe 中。
*/
struct trapframe {
/* 0 */ uint64 kernel_satp; // kernel page table 内核页表根地址
/* 8 */ uint64 kernel_sp; // top of process's kernel stack 本进程内核栈栈顶
/* 16 */ uint64 kernel_trap; // usertrap() usertrap() 函数地址
/* 24 */ uint64 epc; // saved user program counter 被中断的用户指令地址
/* 32 */ uint64 kernel_hartid; // saved kernel tp 当前 CPU 核 ID
/* 40 */ uint64 ra; //x1 返回地址
/* 48 */ uint64 sp; //x2 栈指针
/* 56 */ uint64 gp; //x3 全局指针
/* 64 */ uint64 tp; //x4 线程指针
/* 72 */ uint64 t0; //t0-t2 x5-x7 临时寄存器(不需要被调用者保存)
/* 80 */ uint64 t1;
/* 88 */ uint64 t2;
/* 96 */ uint64 s0; //s0-s1 x8-x9 被调用者保存/帧指针
/* 104 */ uint64 s1;
/* 112 */ uint64 a0;//a0-a7 x10-x17 函数参数/返回值
/* 120 */ uint64 a1;
/* 128 */ uint64 a2;
/* 136 */ uint64 a3;
/* 144 */ uint64 a4;
/* 152 */ uint64 a5;
/* 160 */ uint64 a6;
/* 168 */ uint64 a7;
/* 176 */ uint64 s2;//s2-s11 x18-x27 被调用者(callee)保存
/* 184 */ uint64 s3;
/* 192 */ uint64 s4;
/* 200 */ uint64 s5;
/* 208 */ uint64 s6;
/* 216 */ uint64 s7;
/* 224 */ uint64 s8;
/* 232 */ uint64 s9;
/* 240 */ uint64 s10;
/* 248 */ uint64 s11;
/* 256 */ uint64 t3;//t3-t6 x28-x31 临时寄存器
/* 264 */ uint64 t4;
/* 272 */ uint64 t5;
/* 280 */ uint64 t6;
};
进程状态枚举
enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
| 状态 | 含义与理解 |
|---|---|
UNUSED |
槽位空闲。XV6 的进程数组 proc[NPROC] 大小固定,初始多数槽位处于此状态。allocproc() 从这里分配。 |
USED |
已分配、正在初始化。allocproc() 找到 UNUSED 槽位后置为 USED,此时尚不具备运行条件(页表、上下文等还在准备)。 |
SLEEPING |
睡眠/阻塞。进程因等待某事件主动放弃 CPU——磁盘 I/O、管道数据、子进程退出等。通过 sleep(chan) 挂到等待通道上,事件发生后 wakeup(chan) 唤醒,状态转为 RUNNABLE。 |
RUNNABLE |
就绪,具备运行条件但还未被调度。scheduler() 不断扫描进程表寻找此状态的进程——「排队等 CPU」。 |
RUNNING |
正在某个 CPU 上执行。scheduler() 选中 RUNNABLE 后置为 RUNNING,通过 swtch() 切入。每个核同时最多一个 RUNNING 进程。 |
ZOMBIE |
僵尸状态。进程已调用 exit() 退出,但父进程尚未 wait() 回收。内核保留其 pid 和退出状态供父进程查询。父进程 wait() 后释放槽位,状态回到 UNUSED。 |
系统调用的添加与执行
结合 SYS_trace,可以把 xv6 的系统调用流程分成两条线:
第一条线:编译时,怎么让用户程序能调用 trace()
第二条线:运行时,trace() 是怎么从用户态进入内核态并被执行的
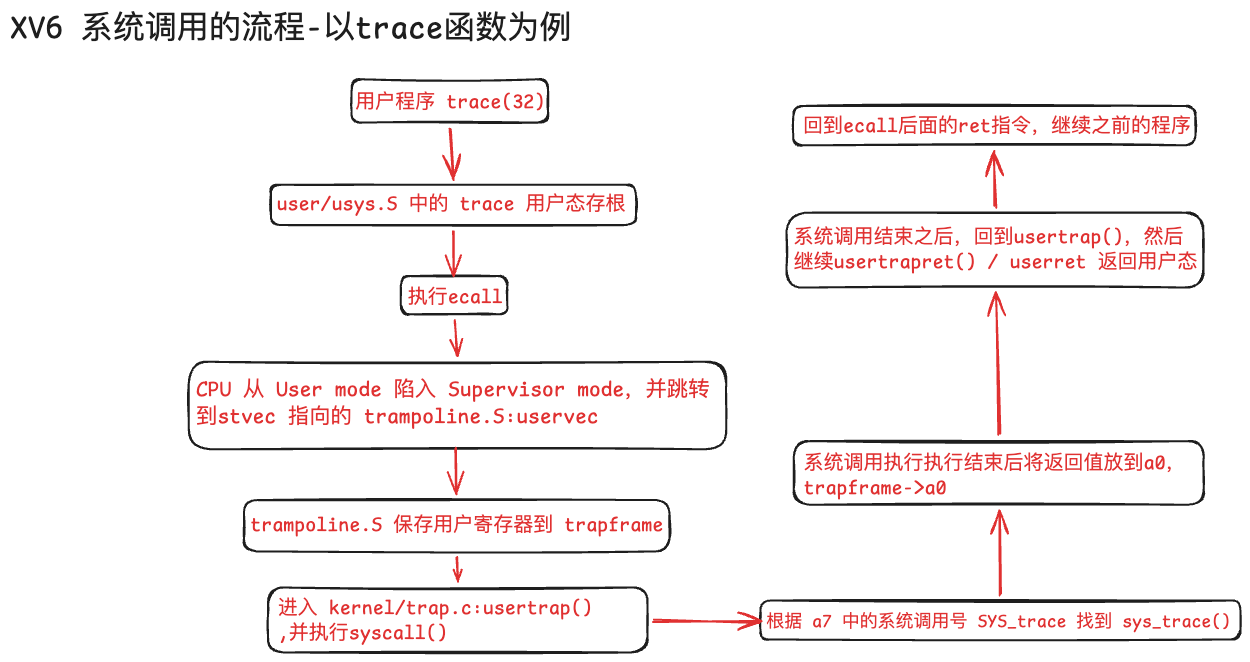
如上面的绘图文件所示,用户程序调用的是用户态的 trace() 存根,真正的内核实现是 sys_trace(),二者通过系统调用号 SYS_trace 和 ecall 连接起来。
具体流程如下:
第一步:在 kernel/syscall.h 里添加系统调用号,#define SYS_trace 22,给 trace 系统调用分配一个唯一编号。
第二步:在 user/user.h 里声明用户态函数添加:int trace(int);这一步是给用户程序看的。
第三步:在 user/usys.pl 里添加用户态存根
user/usys.pl 是一个 Perl 脚本,Makefile 会调用它生成 user/usys.S。用户程序调用:trace(32),实际上会跳到用户态汇编函数:
trace:
li a7, SYS_trace
ecall
ret
其中:li a7, SYS_trace,表示把系统调用号放入 a7 寄存器,在 xv6 RISC-V 里,系统调用约定是:
a0 ~ a5:系统调用参数
a7 :系统调用号
a0 :系统调用返回值
第四步:ecall 触发 trap
用户态执行 ecall 后,CPU 会发生 trap:
User mode
↓ ecall
Supervisor mode
但是 CPU 不会直接跳到 sys_trace(),它会先进入 xv6 的 trap 入口,也就是 trampoline.S 中的 uservec,uservec来自于stvec (Supervisor Trap Vector Base Address Register),在 xv6 中,用户态执行 ecall 后,硬件会做几件事情
1. 记录 trap 原因到 scause
2. 记录当前用户 PC 到 sepc
3. 记录当前特权级到 sstatus.SPP
4. 关闭中断
5. 把特权级从 User mode 切到 Supervisor mode
6. 把 PC 设置为 stvec 中保存的地址
这里提及的uservec就是stvec寄存器里保存的地址。
第五步:trampoline.S 保存用户态现场
发生系统调用时,用户程序的寄存器里有很多重要内容:
a0 = trace 的参数 32
a7 = 系统调用号 SYS_trace
sp = 用户栈指针
ra = 用户函数返回地址
其他寄存器 = 用户程序当前状态
内核不能直接覆盖这些寄存器,否则系统调用返回后用户程序就乱了。所以 trampoline.S:uservec 会把用户寄存器保存到当前进程的:p->trapframe里面。
其中很关键的是:
p->trapframe->a0 = 32;
p->trapframe->a7 = SYS_trace;
之后,uservec 会切换到内核页表、内核栈,然后跳转到:usertrap()。
第六步:进入 kernel/trap.c:usertrap()
usertrap() 是用户态 trap 进入内核后的 C 语言处理函数。它会判断这次 trap 是什么原因。
如果是系统调用,大致逻辑是:
if(r_scause() == 8){
// system call
if(killed(p))
exit(-1);
p->trapframe->epc += 4;
intr_on();
syscall();
}
这里有几个关键点。
1. r_scause() == 8
在 RISC-V 中,用户态执行 ecall 后,scause 会记录 trap 原因。8 表示:Environment call from U-mode 也就是用户态系统调用。
2. p->trapframe->epc += 4
epc 保存的是用户程序发生 trap 时的 PC,也就是 ecall 这条指令的位置。如果不加 4,系统调用返回用户态后会再次执行同一条 ecall,然后又进入内核,造成死循环。所以:p->trapframe->epc += 4;系统调用返回后,从 ecall 的下一条指令继续执行。
之后就是调用 syscall()。
第七步:kernel/syscall.c:syscall() 根据编号分发
syscall() 会先取出系统调用号:num = p->trapframe->a7;这里的 a7 是用户态存根设置的:li a7, SYS_trace,所以此时:num = SYS_trace,然后 syscall() 会查系统调用表:
//提前声明这个函数,不然会报错
extern uint64 sys_trace(void);
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
...
[SYS_trace] sys_trace,
};
//调用和系统调用号对应的系统调用函数
p->trapframe->a0 = syscalls[num]();
因此,要在这里添加和SYS_trace对应的系统调用函数sys_trace,使得。
第八步:实现 kernel/sysproc.c:sys_trace()
在 kernel/sysproc.c 中实现具体的函数:
uint64 sys_trace(void){
int mask;
argint(0, &mask);
myproc()->tracemask = mask;
return 0;
}
这个函数是真正的内核实现。
第九步:系统调用返回值放到 a0
在 xv6 中,系统调用返回值也是通过 a0 传回用户态的。所以 syscall() 会做:p->trapframe->a0 = syscalls[num]();
对于 trace 来说,sys_trace() 返回 0,所以:p->trapframe->a0 = 0;等返回用户态后,用户程序里的trace(32),就会得到返回值 0。
如果是 read(),那么 a0 里就是实际读取的字节数。
如果是 fork(),那么 a0 里就是子进程 pid 或 0。
第十步:回到用户态
syscall() 执行完后,会回到 usertrap(),然后走:usertrapret();
usertrapret() 会准备返回用户态所需的信息,例如:
设置 stvec 回到 trampoline中的uservec
设置 sepc 为 trapframe->epc
设置 sstatus,使 sret 返回 User mode
设置 trapframe 中的 kernel_satp、kernel_sp、kernel_trap 等
最后通过 trampoline.S:userret:
恢复用户寄存器
切换回用户页表
执行 sret
返回用户空间
用户程序继续从 ecall 后面的指令运行。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)