基于 LangGraph 实现长文本总结的多阶段工作流
基于 LangGraph 实现长文本总结的多阶段工作流
前言
大语言模型(LLM)在短文本处理上表现出色,但面对长文本总结(如文章摘要、报告提炼)时,往往受限于上下文窗口和输出长度,难以一次性完成高质量的压缩与重构。
解决思路并非等待更强的模型,而是改变架构:将长文本拆解为可处理的小单元,通过「分块 → 摘要 → 规划 → 重写」四阶段工作流,让 LLM 在每个环节只处理它擅长的粒度,最终由状态机编排完成全局协同。
1. 整体架构
1.1 工作流流程
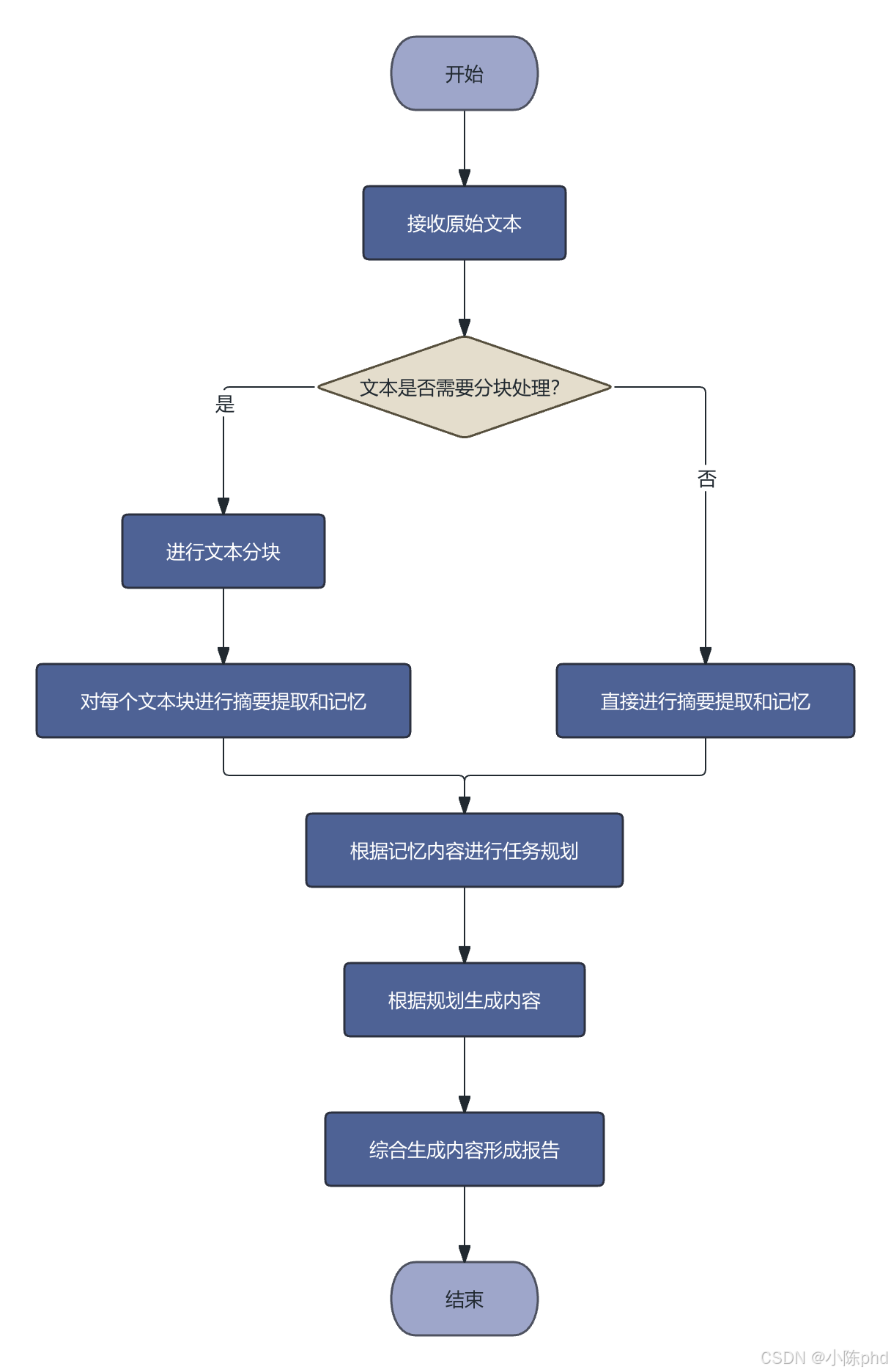
四个阶段各司其职:
| 阶段 | 输入 | 输出 | 核心作用 |
|---|---|---|---|
| 分块 | 原始文本 | 文本块列表 | 将长文拆为可处理的小单元 |
| 摘要+记忆 | 文本块 | 摘要列表 + 向量库 | 压缩信息,构建可检索的记忆 |
| 规划 | 摘要列表 | 文章结构树 | 确定报告的章节框架 |
| 生成 | 结构树 + 向量库 | 最终报告 | 逐章节生成内容 |
1.2 技术栈
- LangGraph:状态机工作流框架
- FAISS:向量数据库,用于语义检索
- DashScope(通义千问):LLM 和 Embedding 接口
- OpenAI SDK:统一调用接口
2. 环境准备
2.1 依赖安装
pip install langgraph langchain-community faiss-cpu openai python-dotenv
注意:macOS 用户请安装
faiss-cpu,不要安装faiss-gpu(不支持)。
2.2 环境变量
在项目根目录创建 .env 文件:
DASHCOPE_KEY=sk-your-api-key
BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
2.3 初始化客户端
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url=os.getenv('BASE_URL'),
api_key=os.getenv('DASHCOPE_KEY')
)
DashScope 兼容 OpenAI 接口协议,因此可以直接使用 OpenAI SDK 调用。
3. 状态定义:工作流的“数据总线”
LangGraph 的核心思想是基于状态的工作流。所有节点(函数)通过一个共享的 State 对象传递数据。
from typing import Dict, List, TypedDict
class GenerationState(TypedDict):
original_text: str # 原始输入文本
chunks: List[str] # 切分后的文本块
summaries: List[str] # 每个文本块的摘要
planning_tree: Dict # 文章结构树(JSON)
final_output: str # 最终生成的报告
vectorstore: FAISS # 向量数据库
为什么需要状态定义?
- 每个节点只读取自己需要的字段,写入自己产出的字段
- 类型安全:
TypedDict提供了编译期检查 - 数据流向清晰:从字段定义就能看出整个流程的数据变换
4. 文本分块:化整为零
4.1 为什么要分块?
长文本直接喂给 LLM 会面临:
- 超出上下文窗口限制
- 信息密度不均,关键内容被稀释
- 摘要质量随长度下降
分块的目的是将长文拆为语义完整的小单元,便于后续逐块处理。
4.2 分块策略
def split_text(text: str) -> List[str]:
"""语义化文本分块,目标2-10块"""
# 按双换行符(段落)分割
paragraphs = [p.strip() for p in text.split("\n\n") if p.strip()]
# 情况1:段落数在目标范围内,直接返回
if 2 <= len(paragraphs) <= 10:
return paragraphs
# 情况2:段落太少(<2),按句子进一步拆分
if len(paragraphs) < 2:
sentences = []
for para in paragraphs:
sent_list = re.split(r'[。!?]', para)
sentences.extend([s.strip() for s in sent_list if s.strip()])
# 将句子重新组合成块
...
# 情况3:段落太多(>10),合并相邻段落
if len(paragraphs) > 10:
chunk_size = len(paragraphs) // 8 # 目标8块左右
chunks = []
for i in range(0, len(paragraphs), chunk_size):
chunk_paras = paragraphs[i:i+chunk_size]
chunks.append("\n\n".join(chunk_paras))
return chunks
设计思路:
- 先按段落自然分割
- 根据段落数量决定策略:合适则直接返回,太少则按句子拆分,太多则合并
- 最终控制在 2-10 块的范围内
4.3 实际效果
以《老人与海》读后感(2678 字符)为例,分块结果:
切分块数: 15 块
平均块长度: 176 字符
最大块: 237 字符
最小块: 24 字符
5. 摘要与记忆:信息压缩
5.1 LLM 摘要生成
对每个文本块调用 LLM 生成精简摘要,目标压缩到原文的 30%:
def generate_summary(chunk: str) -> str:
target_length = int(len(chunk) * 0.3)
response = client.chat.completions.create(
model="qwen-plus",
messages=[{
"role": "system",
"content": f"请对以下内容进行高度精简的摘要。要求:\n"
f"1. 摘要长度不超过{target_length}字符\n"
f"2. 只保留最核心的观点和关键信息"
}, {
"role": "user",
"content": chunk
}],
temperature=0
)
return response.choices[0].message.content
二次压缩机制:如果首次摘要仍然超长,会再调用一次 LLM 进行压缩:
if len(summary) > target_length:
# 再次调用 LLM 压缩
...
5.2 向量数据库:构建可检索记忆
摘要生成后,将其存入 FAISS 向量数据库:
state["vectorstore"] = FAISS.from_texts(summaries, embedding=embeddings)
Embedding 模型使用 DashScope 的 text-embedding-v4:
class OpenAIEmbeddings(Embeddings):
def __init__(self, model: str = "text-embedding-v4"):
self.model = model
self.client = client
def embed_documents(self, texts: List[str]) -> List[List[float]]:
# DashScope 限制单次最多 10 条,分批处理
batch_size = 10
all_embeddings = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
response = self.client.embeddings.create(model=self.model, input=batch)
all_embeddings.extend([data.embedding for data in response.data])
return all_embeddings
踩坑记录:DashScope 的 Embedding 接口限制单次最多 10 条文本,超过会报 400 错误。必须实现分批处理逻辑。
6. 规划阶段:结构设计
6.1 从摘要到结构树
将所有摘要汇总,让 LLM 生成文章结构大纲:
def build_planning_tree(summaries: List[str]) -> Dict:
combined = "\n\n".join(f"Block {i+1}: {s}" for i, s in enumerate(summaries))
prompt = f"""
请根据以下文本块摘要,生成一份精简的综合报告结构大纲。
要求:
- 总共只生成3-4个主要章节
- 输出为严格JSON格式
摘要汇总:
{combined}
"""
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
return json.loads(response.choices[0].message.content)
6.2 输出格式
结构树是一个 JSON 对象:
{
"title": "《老人与海》精神内核综合报告",
"sections": [
{"title": "核心人物与精神象征", "subsections": []},
{"title": "主题哲思与存在叩问", "subsections": []},
{"title": "叙事美学与生命启示", "subsections": []}
]
}
subsections 为空数组,表示每个章节作为一个完整段落输出,避免过度碎片化。
7. 生成阶段:逐章撰写
7.1 语义检索 + 内容生成
对每个章节,先从向量库中检索相关内容,再交给 LLM 撰写:
def generate_node(state: GenerationState) -> GenerationState:
tree = state["planning_tree"]
content_parts = []
for section in tree["sections"]:
sec_title = section["title"]
# 从向量库检索相关上下文
context = retrieve_relevant_memory(sec_title, state["vectorstore"])
# LLM 生成章节内容
content = generate_section_content(sec_title, context)
content_parts.append(content)
# 将生成内容回写向量库(增量记忆)
state["vectorstore"].add_texts([content])
state["final_output"] = "\n\n".join(content_parts)
return state
关键设计:生成的内容会回写到向量库,后续章节可以检索到前面已生成的内容,实现上下文连贯。
7.2 语义检索
def retrieve_relevant_memory(query: str, vectorstore: FAISS, k: int = 3) -> str:
docs = vectorstore.similarity_search(query, k=k)
return "\n".join(d.page_content for d in docs)
用章节标题作为 query,检索最相关的 k 条摘要/内容,为 LLM 提供写作素材。
8. 工作流编排:LangGraph 状态图
8.1 定义节点和边
from langgraph.graph import StateGraph, END
def create_generation_workflow():
workflow = StateGraph(GenerationState)
# 添加节点
workflow.add_node("split", split_node)
workflow.add_node("summarize_and_memorize", summarize_and_memorize_node)
workflow.add_node("plan", planning_node)
workflow.add_node("generate", generate_node)
# 定义执行顺序(线性流水线)
workflow.set_entry_point("split")
workflow.add_edge("split", "summarize_and_memorize")
workflow.add_edge("summarize_and_memorize", "plan")
workflow.add_edge("plan", "generate")
workflow.add_edge("generate", END)
return workflow.compile()
8.2 执行工作流
app = create_generation_workflow()
result = app.invoke({"original_text": sample_text})
print(result["final_output"])
8.3 数据流示意
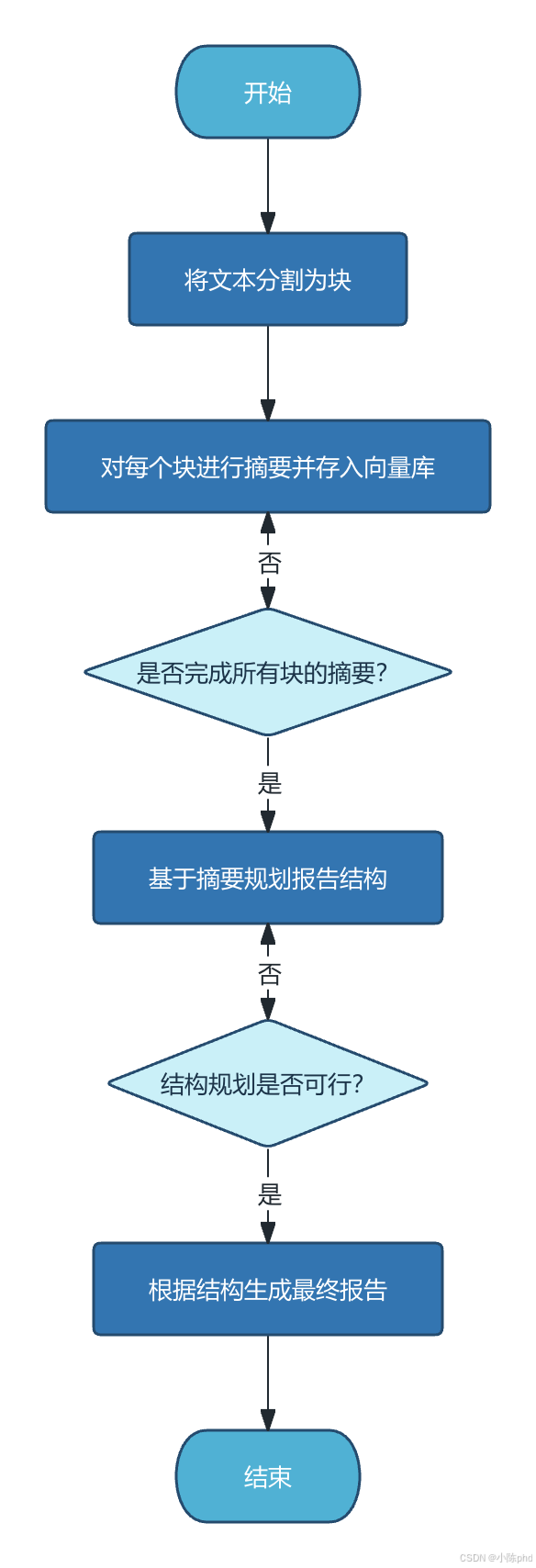
9. 运行效果
以《老人与海》读后感(2678 字符)为输入:
分块阶段:15 个文本块,平均 176 字符/块
摘要阶段:15 条摘要,平均压缩率约 16%
规划阶段:生成 3-4 章节结构
生成阶段:输出约 1400-1800 字符的综合报告





10. 总结与扩展
核心设计要点
- 分而治之:长文先拆块,逐块处理,避免超出 LLM 能力边界
- 记忆机制:向量数据库作为"外部记忆",让生成过程可以检索和引用
- 结构先行:先规划文章结构,再逐章填充,保证输出有条理
- 增量更新:生成的内容回写向量库,后续章节可以感知前文
可扩展方向
- 并行分块处理:利用 LangGraph 的 Send API 并行生成摘要
- 质量评估节点:在生成后加入评估-反思节点,自动修正
- 多轮迭代:对生成结果再次摘要、对比,检查信息丢失
- 流式输出:结合 LangGraph 的 stream 模式,实时展示进度

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)