别再把 Cursor 当“自动补全插件”了:从安装到真正用起来,一篇讲透 AI 编程神器
写在前面:这篇文章不是“Cursor 功能列表”,而是给技术人准备的一套上手路径。你照着做,基本可以从第一天会安装,第二天会改代码,一周后能把它接入真实项目流程。
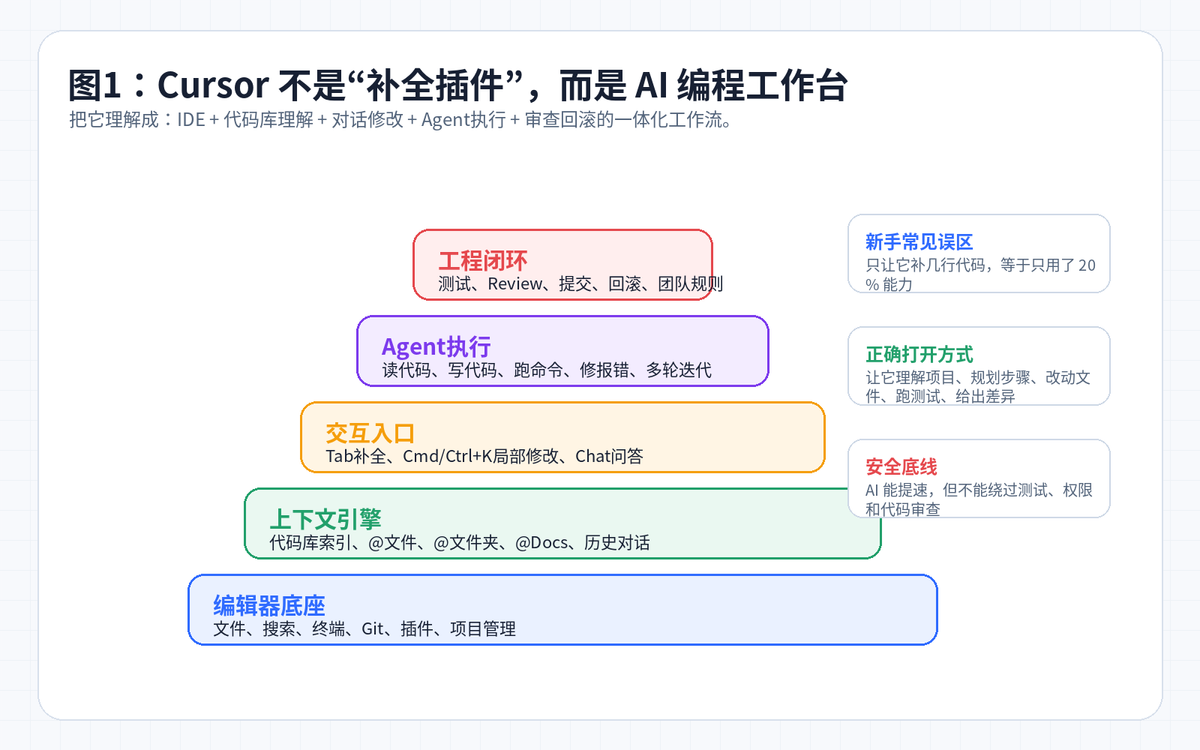
一、先说结论:Cursor 到底解决了什么问题?
如果只把 Cursor 当成“比 VS Code 多了一个 AI 聊天窗口”的编辑器,那就低估它了。Cursor 的真正价值,是把开发过程里最耗时间的几个环节串起来:读代码、找上下文、写改动、跑命令、修报错、做审查。
过去我们写代码,流程往往是:打开 IDE,看代码,看文档,问 ChatGPT,复制粘贴,跑测试,报错,再来一轮。Cursor 想做的事情,是把这些动作尽量压缩在一个工作台里。你不用频繁切窗口,AI 也不再只看到你复制过去的一小段代码,而是能围绕整个项目协助。
新手最容易用错:只用 Tab 补全,感觉“还行”,但没有形成工作流。
真正提效的用法:给它明确任务,让它读项目、列计划、改代码、跑测试、输出 Diff。
团队落地的关键:不是让每个人自由发挥,而是用 Rules、测试、审查和权限边界把 AI 关进流程里。
二、安装前先准备:别上来就点下载
安装 Cursor 很简单,但为了后面少踩坑,建议先准备 4 件事:
确认系统:Cursor Desktop 官方下载页提供 macOS、Windows、Linux 版本。Windows 还会区分 System/User,Linux 常见有 deb、rpm、AppImage 等包。
准备账号:建议用 GitHub 或 Google 登录,后续连接仓库、团队空间、Agent 工作流更顺。
准备一个真实项目:不要只打开空文件练习,Cursor 的优势在于理解项目上下文。
准备网络与权限:企业内网、代理、终端权限、Git 权限都可能影响 Agent 能不能正常运行命令。

三、下载安装:Windows、macOS、Linux 怎么选?
进入 Cursor 官网下载页后,通常网站会自动识别你的系统。实际选择时可以按下面思路判断:
|
系统 |
推荐下载 |
怎么判断 |
注意事项 |
|
Windows |
x64 User 或 System |
个人电脑一般用 User;公司统一装可用 System |
如果安全软件拦截,要确认来源是官方安装包 |
|
macOS |
ARM64 / x64 / Universal |
M 系列芯片选 ARM64;Intel 芯片选 x64;不确定选 Universal |
安装后拖入 Applications,首次打开可能需要允许 |
|
Linux |
deb / rpm / AppImage |
Ubuntu/Debian 用 deb;Fedora/RHEL 用 rpm;通用可用 AppImage |
注意执行权限、桌面入口、系统依赖 |
安装完成后,第一次打开 Cursor,建议不要直接让 AI 写代码。先完成初始化配置,后面效率会高很多。

四、第一次打开:把 Cursor 调成“顺手的开发环境”
1. 先导入熟悉的操作习惯
如果你之前用 VS Code,最重要的是把主题、快捷键、扩展、常用设置迁移过来。原因很简单:AI 工具再强,也不能让你每天为快捷键和插件分心。Cursor 的上手成本之所以低,关键就在于它保留了很多熟悉的编辑器习惯。
2. 选择模型:不要所有任务都用最强模型
复杂架构设计、跨文件重构、疑难 Bug,可以用更强的模型;简单补全、解释一段代码、写小函数,自动模式或低成本模型就够了。真正会用 AI 编程的人,会把“模型”当成计算资源,而不是永远一把梭。
3. 隐私与索引:团队项目要特别谨慎
Cursor 能理解代码库,依赖项目索引与上下文收集。个人练习问题不大,但公司项目一定要确认团队政策:代码是否允许被索引、日志是否保留、是否有合规限制、是否需要企业版管理。
五、主界面导览:5 个区域必须认识
Cursor 的界面并不难,核心区域可以拆成:活动栏、资源管理器、代码编辑区、AI 面板、终端/Git 区域。你每天的动作基本都在这几个地方来回流动。

图4:Cursor 主界面区域说明
这里有一个关键意识:你不是“在编辑器旁边打开一个聊天机器人”,而是在一个工程工作台里调度 AI。你选中的文件、打开的目录、当前报错、终端日志、项目规则,都会影响 AI 的回答质量。
六、核心功能:从轻到重,四种用法一次讲清楚
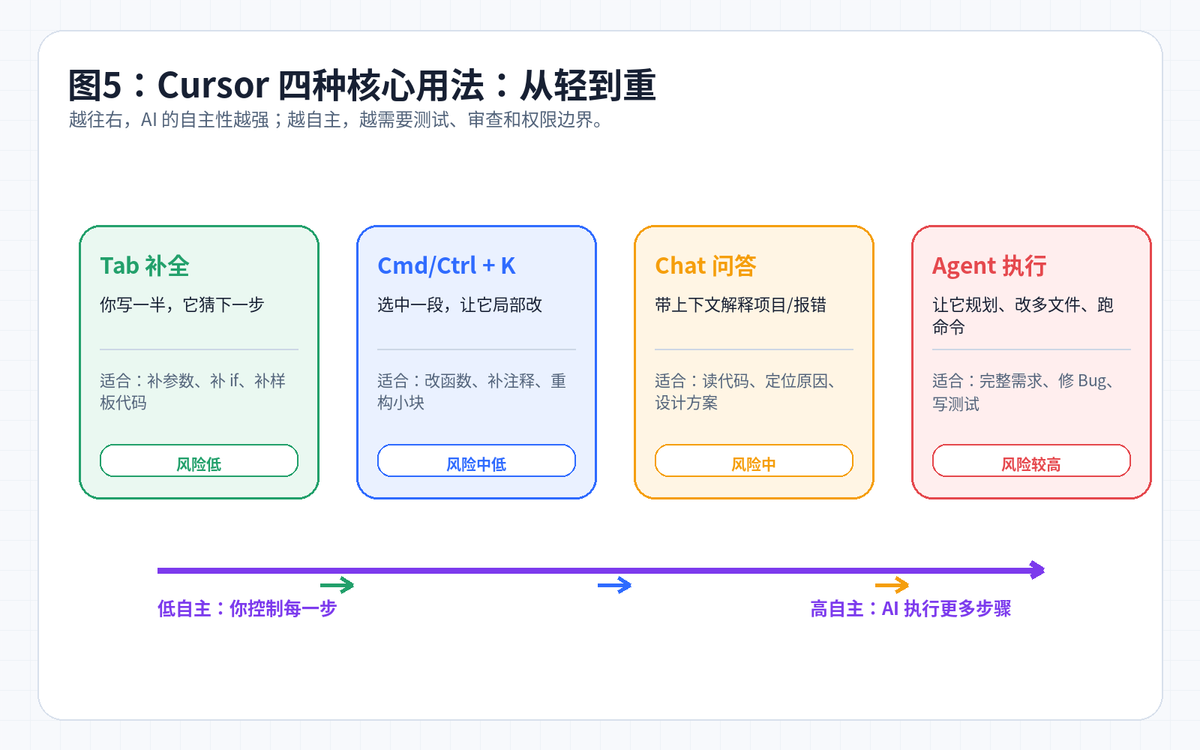
图5:Cursor 四种核心交互方式
1. Tab 补全:写代码时的“副驾驶”
Tab 补全适合连续写代码时使用。比如你正在写 DTO、Mapper、Controller、单元测试,Cursor 会根据前后文预测下一段代码。它的价值不是替你做架构,而是减少重复输入。
适合:补参数、补样板代码、补测试断言、补异常处理。
不适合:复杂业务决策、跨模块重构、生产级安全设计。
2. Cmd/Ctrl + K:局部修改最舒服
当你已经知道要改哪一段代码,可以选中代码后让 Cursor 修改。例如:“把这段同步逻辑改成异步”“补充空指针保护”“把硬编码提到配置里”。这种方式比直接问 Chat 更可控,因为上下文范围更小,输出更容易审查。
3. Chat:读项目、解释报错、做方案
Chat 适合问“为什么”和“怎么做”。例如:“这个项目的登录流程在哪里?”“为什么这个接口返回 403?”“如果我要加一个优惠券平台适配层,应该改哪些文件?”这类问题需要 AI 读上下文、找关联文件、给出解释。
4. Agent:让它执行一段完整任务
Agent 模式适合更完整的任务,比如修一个 Bug、加一个小功能、补测试、整理文档。它会尝试读文件、计划步骤、修改文件、运行命令。自主性更强,也意味着你必须更重视测试与审查。
七、上下文工程:Cursor 好不好用,80% 取决于你给不给对上下文
很多人抱怨 AI 写代码不靠谱,根因并不是模型太差,而是上下文给错了。你让它改一个接口,却不给 Controller、Service、DTO、配置、错误日志,它只能猜。
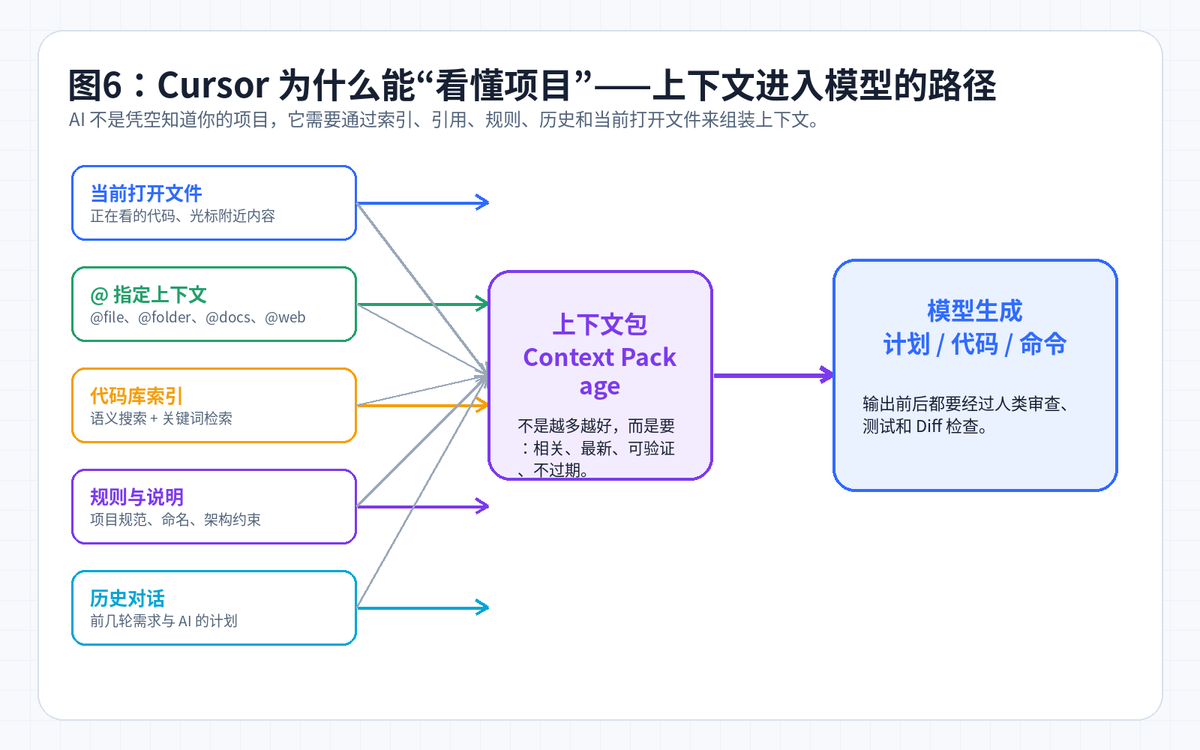
1. @ 文件:精确告诉它看哪里
当你知道相关文件时,直接 @ 文件最稳。比如让它修改一个支付回调,就把 Controller、Service、配置类、相关测试一起带上。上下文越精确,幻觉越少。
2. @ 文件夹:让它理解一个模块
当你不知道具体文件,但知道模块位置,可以 @ 文件夹。比如 @coupon、@order、@auth。它会在这个范围里寻找线索,比让它全项目乱找更稳。
3. @ Docs:把外部文档变成上下文
如果你在接第三方 API,比如拼多多、京东联盟、支付平台、短信平台,最好把官方文档、接口字段说明、错误码说明引入上下文。否则 AI 很容易凭经验编字段。
4. 代码库索引:先等它理解项目,再提复杂需求
第一次打开大项目时,建议等待索引完成再问复杂问题。否则你会遇到“AI 看不全项目”的情况。对于大型仓库,问题要分阶段问:先让它找入口,再让它画流程,再让它改代码。
八、Agent 工作流:不要让它一口气乱改
真正稳定的 Agent 使用方式,是“小步计划、小步执行、小步验证”。不要直接说“帮我把整个项目改成微服务”,这种任务不仅容易跑偏,还很难审查。
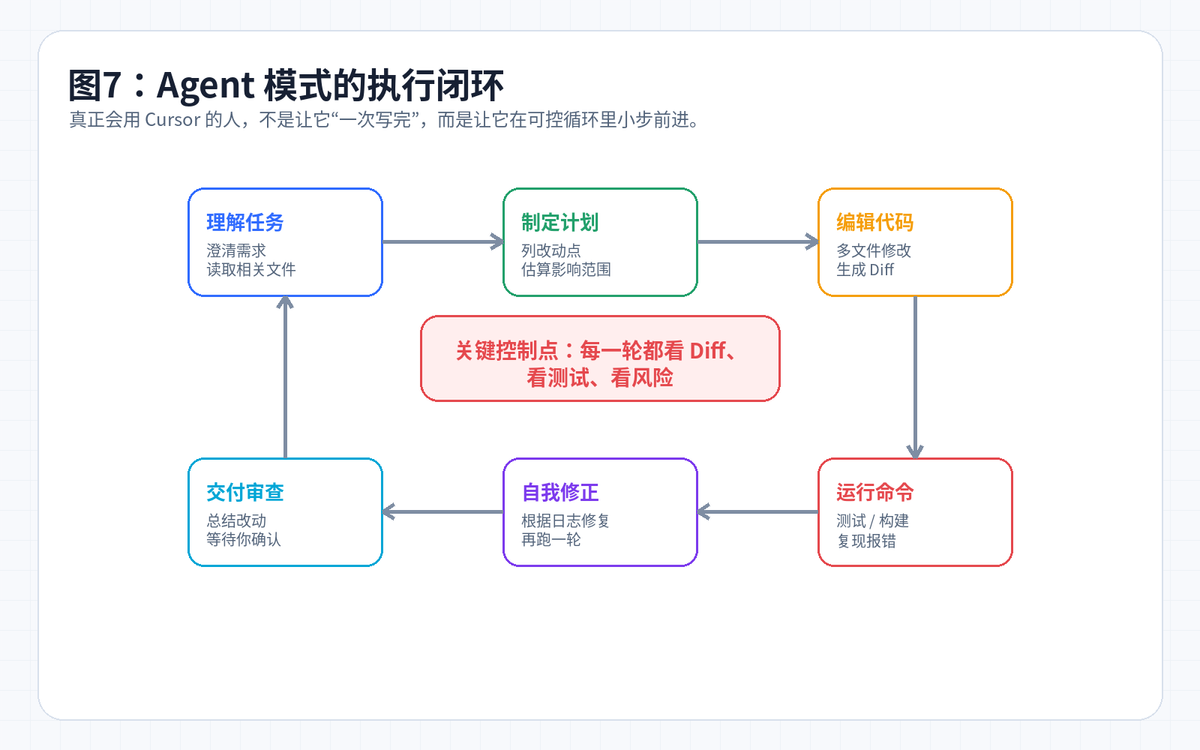
推荐指令模板
你可以直接复制下面这段作为 Cursor Agent 的任务提示:
请先不要改代码,先做 4 件事:
1. 阅读相关文件,找出这个需求会影响哪些模块;
2. 输出一份改动计划,按文件列出要改什么;
3. 标记风险点,比如权限、兼容性、数据一致性;
4. 等我确认后,再开始修改。
这段提示的价值在于:先把 AI 从“执行者”变成“方案设计者”,你确认边界后再让它动手。这样即使模型理解错了,也是在计划阶段暴露问题,不会直接改坏代码。
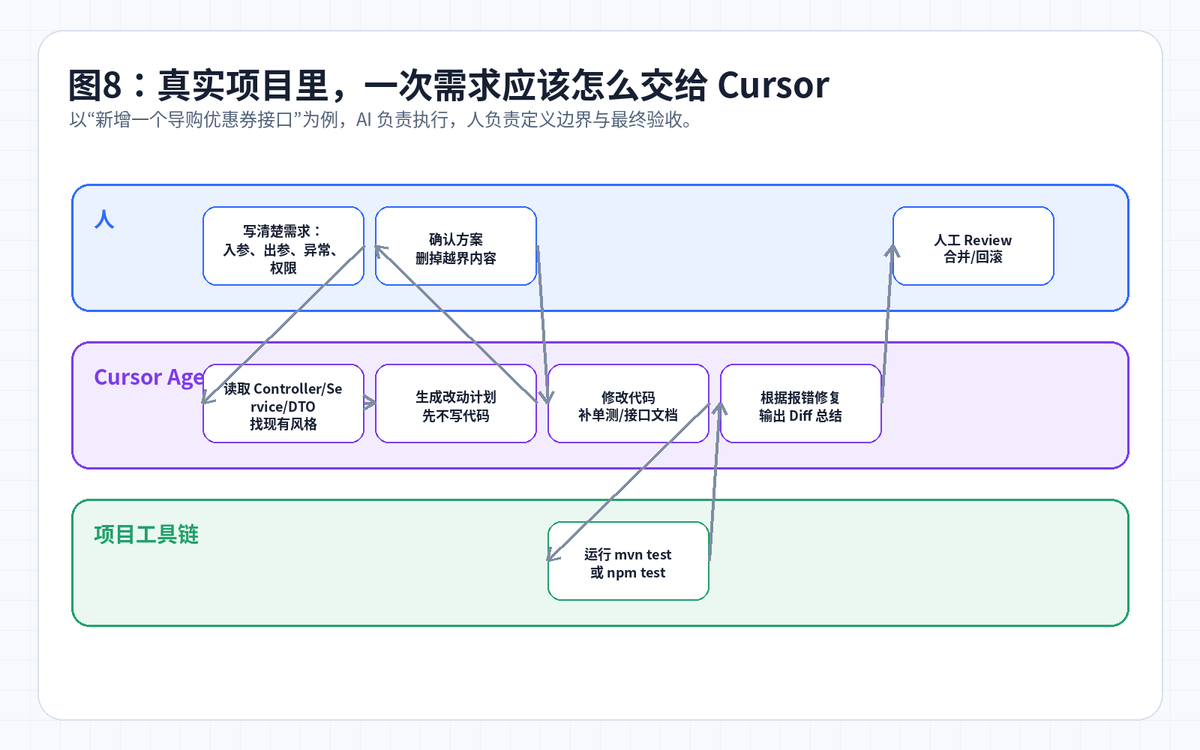
九、真实项目示例:新增一个导购优惠券接口
假设你要做一个优惠券网站,后端需要新增“查询商品优惠券”的接口。不要只对 Cursor 说“帮我写一个接口”,这太模糊。正确做法是给它业务边界、项目上下文、验收标准。
可以这样给任务
需求:新增 /api/coupon/search 接口。
背景:项目已有商品查询、转链、用户点击记录模块。
要求:
- 入参:keyword、platform、page、size;
- 出参:商品标题、原价、券后价、佣金比例、跳转链接;
- 先复用现有 Result<T> 响应结构;
- 不要直接连真实联盟 API,先用 mock 数据;
- 补充单元测试和接口示例;
- 修改前先输出改动计划。
注意,这个任务没有让 AI “自由发挥”。你明确了接口、字段、复用结构、是否接真实 API、测试要求、先计划后修改。这样的提示词才像工程需求,而不是一句愿望。
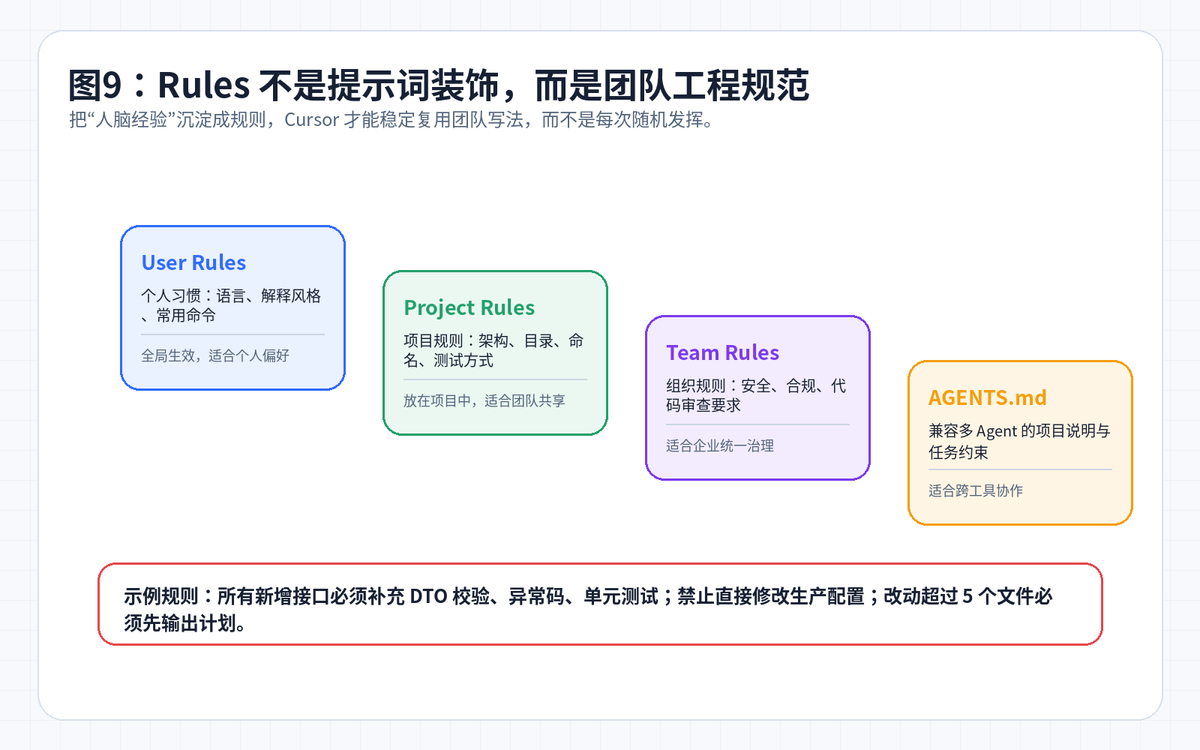
十、Rules:把团队经验沉淀下来
Cursor 的 Rules 可以理解成“长期有效的项目提示词”。它不是用来写漂亮话,而是用来固化团队工程规范。比如:项目分层怎么写、接口返回格式是什么、异常码怎么定义、测试怎么跑、哪些文件不能改。
推荐写进 Rules 的内容
技术栈:Java 版本、Spring Boot 版本、ORM、测试框架、前端框架。
分层规范:Controller 不写业务逻辑,Service 负责编排,Repository 只做数据访问。
命名规范:DTO、VO、Request、Response、Mapper 的命名方式。
安全规范:禁止输出密钥、禁止修改生产配置、禁止执行破坏性命令。
测试规范:新增接口必须补单测或最小可验证用例。
提交规范:每次改动输出影响范围、测试结果、风险点。
一个可直接用的 Rules 模板
你是本项目的 AI 编程助手,请遵守:
1. 修改前先阅读相关文件,并输出计划;
2. Controller 层只做参数校验和响应包装,不写业务逻辑;
3. Service 层必须处理异常与边界条件;
4. 新增接口必须补充单元测试或最小验证脚本;
5. 禁止修改生产配置、密钥、部署脚本;
6. 涉及数据库结构变更时,必须先说明风险并等待确认;
7. 输出结果必须包含:改了哪些文件、为什么改、如何验证。
十一、MCP:让 Cursor 不只看代码,还能连接工具
MCP(Model Context Protocol)可以理解成 AI 与外部工具/数据源之间的标准接口。它的价值是:让 Cursor 不只看本地代码,还能按权限访问文档、接口、数据库、GitHub、监控日志等。
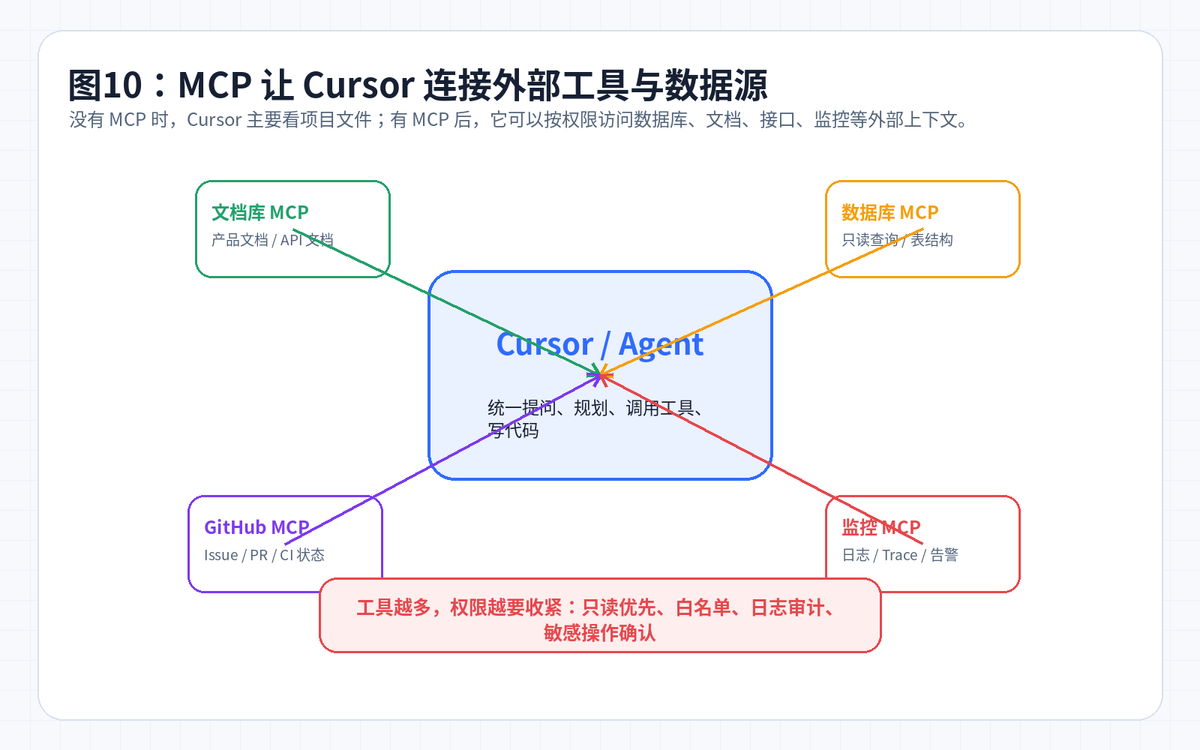
但 MCP 不是越多越好。每接一个外部工具,AI 的能力会变强,风险也会变高。推荐原则是:先只读、再白名单、再审计、最后才考虑写操作。
文档 MCP:让 AI 查产品文档、接口文档、组件库文档。
GitHub MCP:让 AI 读 Issue、PR、CI 状态,辅助修复问题。
数据库 MCP:初期只给只读权限,用于理解表结构和排查数据问题。
监控 MCP:连接日志、Trace、告警,帮助定位线上问题,但不能直接放开生产操作。
十二、安全边界:Cursor 可以提速,但不能替你负责
AI 编程最危险的地方,不是它不会写代码,而是它写得很像对的。你必须给它建立边界:哪些能改,哪些不能改;哪些命令能跑,哪些必须人工确认;哪些结果必须测试验证。
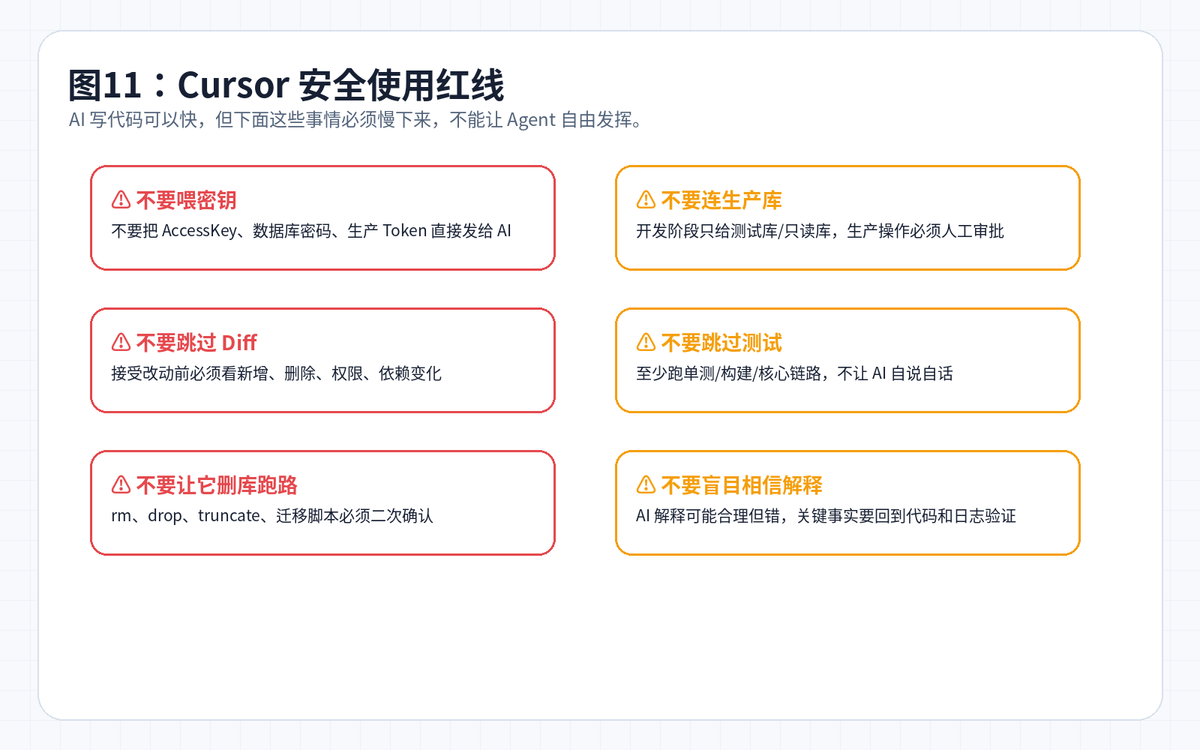
图11:Cursor 安全使用红线
建议建立 5 道门禁
计划门禁:复杂任务先让它输出计划,不允许直接改。
Diff 门禁:每次接受改动前,必须看新增、删除、依赖、配置变化。
测试门禁:单测、构建、接口调用,至少跑一个可验证闭环。
权限门禁:生产密钥、生产数据库、部署脚本不能交给 AI 自由操作。
回滚门禁:Git 分支、提交粒度、变更记录要清楚,随时能撤回。
十三、新手最容易踩的 10 个坑
|
坑 |
表现 |
正确做法 |
|
只给一句话需求 |
AI 改出来一堆不相关文件 |
补充背景、范围、验收标准 |
|
不指定上下文 |
AI 猜错框架和字段 |
@ 相关文件/文件夹/文档 |
|
一次让它改太大 |
Diff 看不懂,测试也难跑 |
拆成小任务,每次闭环 |
|
不看 Diff 直接接受 |
引入隐藏 Bug 或删除逻辑 |
接受前逐块审查 |
|
不写 Rules |
每次输出风格都变 |
把项目规范沉淀成规则 |
|
让它连生产环境 |
误操作风险巨大 |
只读优先,生产人工审批 |
|
报错只截图 |
上下文不完整 |
给错误日志、命令、相关文件 |
|
盲信解释 |
听起来合理但事实错误 |
回到代码、日志、测试验证 |
|
忽视成本 |
复杂模型被滥用 |
按任务选择模型 |
|
不保留回滚点 |
改坏后难恢复 |
小步提交,随时 git diff |
十四、30 天上手路线:从会用到用顺

很多人学 Cursor 的问题是:第一天很兴奋,第二天让它写大项目,第三天发现一堆 Bug,然后放弃。正确节奏应该是逐步放权。先让它解释,再让它局部改,再让它跑小任务,最后才接入 Agent、MCP、团队规则。
十五、给技术人的一句话总结
Cursor 的核心价值,不是“让不会写代码的人变成高级工程师”,而是让已经懂工程的人,把重复劳动、上下文搜索、样板代码、测试修复、文档整理交给 AI。
你越懂项目,越会给上下文,越会拆任务,越会审查结果,Cursor 就越强;你越想让它一步到位、替你负责,它就越危险。
所以最好的使用姿势是:人定方向,AI 做执行;人控边界,AI 提效率;人做审查,AI 给候选方案。把这套流程跑顺,Cursor 才真正从一个“AI 编辑器”变成你的“软件开发加速器”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 21
21 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)