把 SenseNova U1 接进 OpenClaw:API 对接、Skill 调度与一次完整出图实测
文章目录
-
- 一、先聊聊 SenseNova U1 这个模型
- 二、装机选型:跳过 WSL2,直接走 Windows 原生
- 三、API 对接(一):申请 SenseNova 平台 Key 并直连验证
- 四、API 对接(二):跳过 onboard 向导,手写 openclaw.json
- 五、API 对接(三):跑通端到端连通性测试
- 六、调用逻辑(一):装 SenseNova-Skills,24 个 Skill 一次到位
- 七、调用逻辑(二):第一个真任务,跑横评信息图
- 八、踩坑:sn-infographic 链路里的 Python 版本约束
- 九、效果验证:U1 在高密度信息可视化上的实际表现
- 十、思考:编排链路与 U1 能力的乘积关系
- 十一、不足与下一步

最近 SenseNova U1 系列(轻量版 SenseNova U1 Lite)开源,看官方 README 给出的几条接入路径,里面我最想完整走一遍的就是 OpenClaw 调用 这条。原因有三:
- 它不止是把模型当 chat 接口——OpenClaw 是一个 Agent Skills 规范的智能体运行时,调用 SenseNova 模型时中间会插入规划、工具选型、Skill 链编排、自我校对等环节,能看出模型在"被调度起来之后"能达到的真实上限;
- API 对接路径标准——SenseNova 平台兼容 OpenAI 协议,OpenClaw 配置里支持
openai-completions接入。理论上把 base URL 和模型名换一下就能跑通,实际上有几个细节坑; - 效果验证最直接——同一个模型、同一道题,直接发 API 拿到的图和经过 agent 编排后拿到的图,质量差距非常显著。这个差距正是 OpenClaw 调用价值的关键证据。
模型来源:
- GitHub:https://github.com/OpenSenseNova/SenseNova-U1
- HuggingFace:https://huggingface.co/collections/sensenova/sensenova-u1
- SenseNova-Skills 仓库:https://github.com/OpenSenseNova/SenseNova-Skills
一、先聊聊 SenseNova U1 这个模型
在动手对接之前,先把这次的"主角"讲清楚——否则后面跑出来的效果,你不知道哪些是模型能力,哪些是 agent 编排带来的增量。
1.1 范式跃迁:从"模态拼接"到"原生统一"
过去一年,多模态大模型主流路径是"LLM + 视觉编码器(VE)+ 变分自编码器(VAE)"的拼接式。这种架构有个根本问题:视觉信息和文本信息在模型内部其实是两个空间,需要通过适配器层来回翻译,信息损耗和认知断层都是天然的。
SenseNova U1 走的不是这条路。它基于商汤自研的 NEO-unify 架构,核心理念是"像素与文字在语义层面本来就深度相关,不应该硬拆开"。落到架构上,做了两件根本性的变化:
- 去除 Visual Encoder(VE):不再依赖外部视觉编码器把图像编码为 token;
- 去除 Variational Auto-Encoder(VAE):不再依赖 VAE 把图像压缩到潜空间再解码。
取而代之的是"统一表征体系"——语言和视觉信息作为一个统一的复合体,端到端建模。理解、推理、生成三种能力在同一套参数空间里发生,不需要中间翻译层。
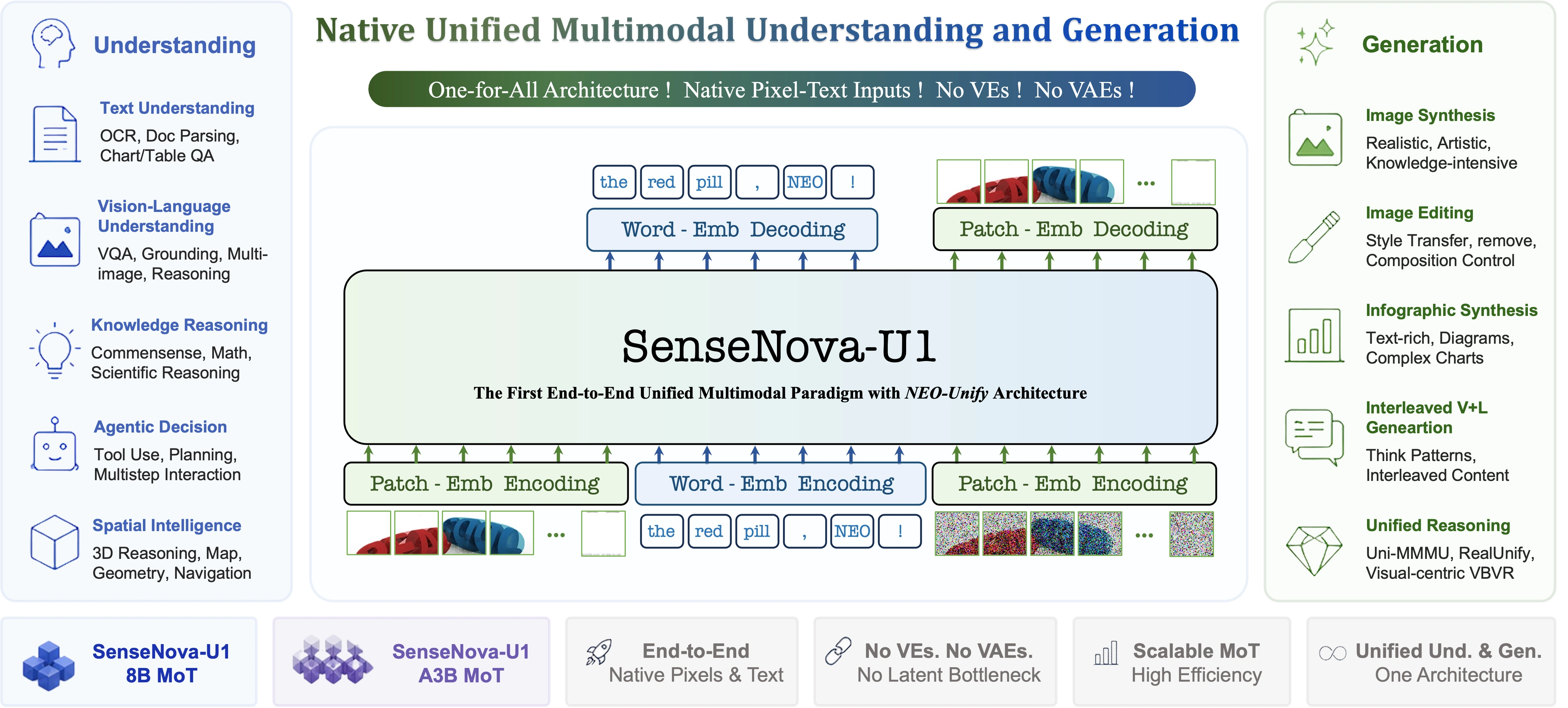
1.2 模型矩阵:本次开源的版本
本次开源的是 SenseNova U1 Lite 系列:
| 模型 | 参数量 | 主干结构 | 特点 |
|---|---|---|---|
| SenseNova-U1-8B-MoT | 8B | 稠密主干 | 通用底座 |
| SenseNova-U1-A3B-MoT | A3B | MoE 混合专家 | 性价比高 |
| SenseNova-U1-8B-MoT-SFT | 8B | 稠密 | 监督微调版本 |
| SenseNova-U1-A3B-MoT-SFT | A3B | MoE | SFT 版本 |
| SenseNova-U1-8B-MoT-Infographic | 8B | 稠密 | 信息图特化 |
| SenseNova-U1-8B-MoT-LoRA-8step | 0.4B | LoRA | 8 步推理加速版 |
💡 关键点:模型矩阵里有个叫
SenseNova-U1-8B-MoT-Infographic的版本,是 2026.05.15 专门为信息图场景做了能力增强的,本次实测里 agent 调用的sensenova-u1-fast就是这个版本经过步数蒸馏和 CFG 蒸馏后的产物——专供信息图生成使用,这也是为什么我选信息图作为实测题目。
1.3 三大核心能力(这次实测会验证哪几个)
按官方 README 列的能力卖点,SenseNova U1 强调三件事:
- 理解与生成均达到开源 SOTA——在 OneIG(EN/ZH)、LongText(EN/ZH)、CVTG、BizGenEval(Easy/Hard)、IGenBench 等基准上,性能-延迟比领先;
- 原生图文交错生成——单模型单链路连贯产出图文交错内容,适合生活指南、教程、旅行手记类场景;
- ** 高密度信息呈现**——能生成结构丰富、排版复杂的内容,覆盖知识图解、海报、PPT、简历等信息密集场景。
这次实测主要验证第三个能力——让模型生成一张包含多模块、多数据点、严格视觉规范的横评信息图,看 U1 在"高密度信息可视化"上的真实表现。
1.4 当前版本的已知局限(要先承认,后面才好评价)
官方 README 在"进行中的改进"章节明确列了几个已知短板,我抄过来——这一节后面要反复回来对照:
- 视觉理解:当前模型支持的上下文长度最长 32K tokens,复杂视觉场景下可能受限;
- 人体生成:人体细粒度细节处理仍有挑战,尤其人物占比小或与周围物体复杂交互时;
- 文字生成:文字渲染有时会出现拼写错误、字符变形或格式不一致,对 prompt 措辞较为敏感,在文字密集场景下尤为明显;
- 图文交错生成:当前是 Beta 状态,强化学习尚未针对图像编辑、推理及图文交错任务做专项优化。
第三条是关键——它告诉我们:生信息图时出现错字、字符变形不是 bug,是模型当前阶段的已知限制。所以衡量 OpenClaw 编排的价值,一个重要看点就是"agent 是否能把这种已知缺陷的影响降到最低"。
二、装机选型:跳过 WSL2,直接走 Windows 原生
OpenClaw 官方文档在 Windows 下推荐 WSL2 路线(装 WSL2 → 装 Ubuntu → 在 Ubuntu 内装 Node → 装 OpenClaw),完整跑下来至少一小时。我先查了下本机环境:
> node --version
v22.21.0
> npm --version
10.9.4
> where node
C:\Users\86155\AppData\Local\fnm_multishells\...\node.exe
Node 22.21 满足 OpenClaw 文档里写的 ≥22.14 要求,npm 也在,是 fnm 管理的。既然这样就没必要走 WSL2,直接 npm 全局装:
npm install -g openclaw@latest
npm warn deprecated node-domexception@1.0.0: ...
added 473 packages in 1m
1 分钟,473 个依赖包。

验证:
> openclaw --version
OpenClaw 2026.5.20 (e510042)
> where openclaw
C:\Users\86155\AppData\Local\fnm_multishells\...\openclaw
C:\Users\86155\AppData\Local\fnm_multishells\...\openclaw.cmd

关于 Windows 原生 vs WSL2 的取舍:官方文档把 WSL2 写在前面是出于兼容性考虑,但 Windows 原生其实是可以直接走的。如果你电脑里 Node 22.14+ 已经在了,没必要先去折腾 WSL2 + Ubuntu + nvm + Node 这一长串前置准备。
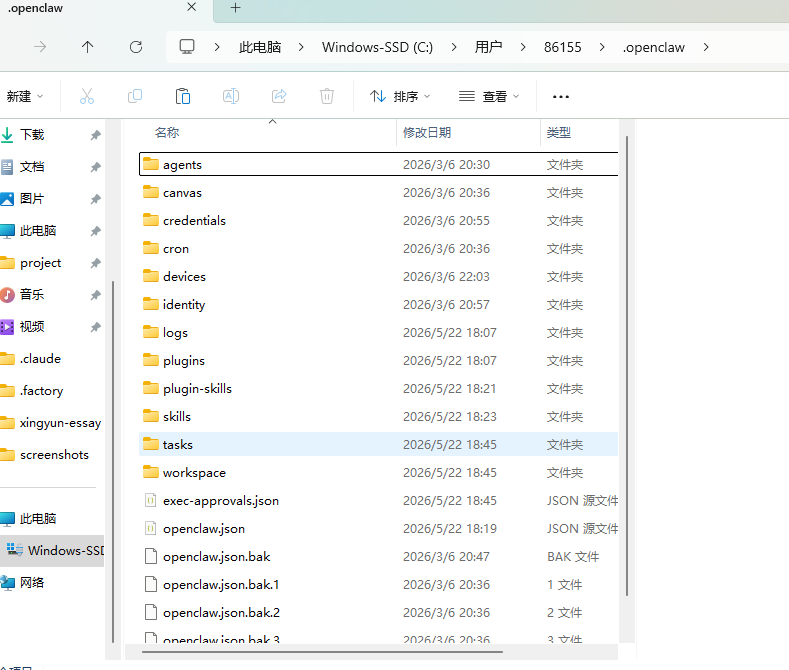
安装完成后,OpenClaw 在 C:\Users\86155\.openclaw\ 下生成了用户目录结构:
.openclaw/
├── agents/ # agent 配置(默认会有一个 main agent)
├── canvas/ # 画布数据
├── credentials/ # 凭据存储
├── cron/ # 定时任务
├── identity/ # 身份标识
├── logs/ # 日志(config-health / config-audit 等)
├── plugins/ # 插件目录
├── plugin-skills/ # 插件 skill 缓存
├── skills/ # 用户自定义 Skill(一会儿要装 SenseNova-Skills)
├── tasks/ # 任务运行数据(sqlite)
├── workspace/ # agent 工作目录(生成产物)
├── openclaw.json # 主配置文件
└── openclaw.json.bak # 自动备份
三、API 对接(一):申请 SenseNova 平台 Key 并直连验证
OpenClaw 不做模型推理,要接入一个 LLM provider。SenseNova 平台公测期免费开放,每 5 小时给 1500 次调用额度。
去 platform.sensenova.cn 注册,左侧菜单 API Keys → 新增 API Key。生成后立刻复制保存(这类平台 Key 一般只在生成时显示一次)。
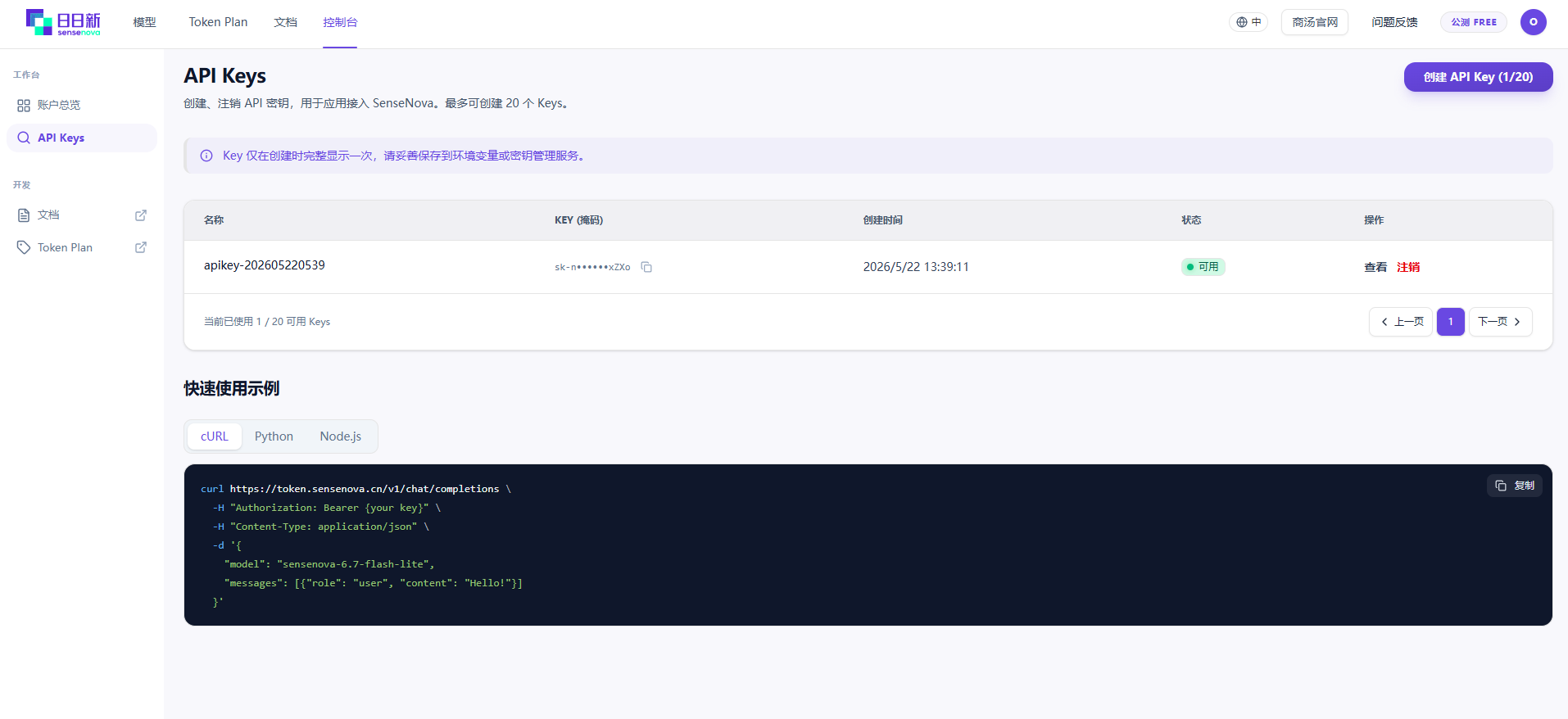
我的习惯是不先接入任何客户端,先直接 curl 验证 Key 能不能通——这一步能排除掉"Key 写错了 / 端点写错了 / 账号没激活"这类基础问题:
curl -X POST https://token.sensenova.cn/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
-d '{
"model": "sensenova-6.7-flash-lite",
"messages": [{"role": "user", "content": "你好,请用一句话自我介绍"}],
"max_tokens": 100
}'
返回:
{
"id": "3c821177-41be-41e6-883b-9184fe196e8b",
"created": 1779439250,
"model": "sensenova-6.7-flash-lite",
"object": "chat.completion",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"reasoning": "嗯,用户发来的信息看起来是乱码,我需要先确认这是什么编码问题……"
},
"finish_reason": "length"
}],
"usage": {
"prompt_tokens": 48,
"completion_tokens": 100,
"total_tokens": 148
}
}

API 通了。这里有两个细节值得提:
reasoning字段:SenseNova 模型的特色,把思考过程独立返回,方便上层做"展示思考过程"的 UI(参考别的 SenseNova 应用,那种"思考过程"折叠区背后就是这个字段);- 中文乱码问题:Windows 终端默认 cp936 编码,curl 时请求体里的中文经过终端编码后传到服务端会被识别为乱码(模型 reasoning 里能看到它在分析编码问题)。这不是 SenseNova API 的 bug,是 Windows 终端编码的历史遗留问题。生产代码里用 Python/Node SDK 不会触发。
四、API 对接(二):跳过 onboard 向导,手写 openclaw.json
OpenClaw 默认的 LLM 接入路径是跑交互向导:
openclaw onboard --install-daemon
向导会问 14 个问题:Setup mode、Model/auth provider、API Base URL、API Key 输入方式、API Key、Endpoint compatibility、Model ID、Endpoint ID、Select channel、Web search provider、Brave Search key、Configure skills、Enable hooks……一路按回车 + 输入答案大概要 5 分钟。
但 OpenClaw 是配置驱动的——这十几个问题最终就是在 ~/.openclaw/openclaw.json 里写几个字段。看一下当前配置文件路径:
> openclaw config file
~\.openclaw\openclaw.json
我之前装过一次 OpenClaw,目录里有 .bak 备份(OpenClaw 每次跑 onboard 会自动备份旧配置)。打开看一下,是 OpenAI 协议下标准的 providers / models / agents.defaults 三段。我手写一份 SenseNova 版的:
{
"meta": {
"lastTouchedVersion": "2026.5.20",
"lastTouchedAt": "2026-05-22T10:30:00.000Z"
},
"models": {
"mode": "merge",
"providers": {
"sensenova": {
"baseUrl": "https://token.sensenova.cn/v1",
"apiKey": "<把你的 Key 填这里>",
"api": "openai-completions",
"models": [
{
"id": "sensenova-6.7-flash-lite",
"name": "SenseNova 6.7 Flash Lite",
"reasoning": false,
"input": ["text", "image"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 128000,
"maxTokens": 8192,
"compat": { "supportsDeveloperRole": false }
},
{
"id": "sensenova-u1-fast",
"name": "SenseNova U1 Fast",
"reasoning": false,
"input": ["text", "image"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 32000,
"maxTokens": 8192,
"compat": { "supportsDeveloperRole": false }
}
]
}
}
},
"agents": {
"defaults": {
"compaction": { "mode": "safeguard" },
"sandbox": { "mode": "off" },
"model": { "primary": "sensenova/sensenova-6.7-flash-lite" },
"workspace": "C:\\Users\\86155\\.openclaw\\workspace",
"models": {
"sensenova/sensenova-6.7-flash-lite": {},
"sensenova/sensenova-u1-fast": {}
}
}
},
"gateway": {
"mode": "local",
"bind": "loopback",
"port": 18789,
"auth": { "mode": "token", "token": "<gateway 鉴权 token>" }
},
"tools": { "profile": "coding" }
}
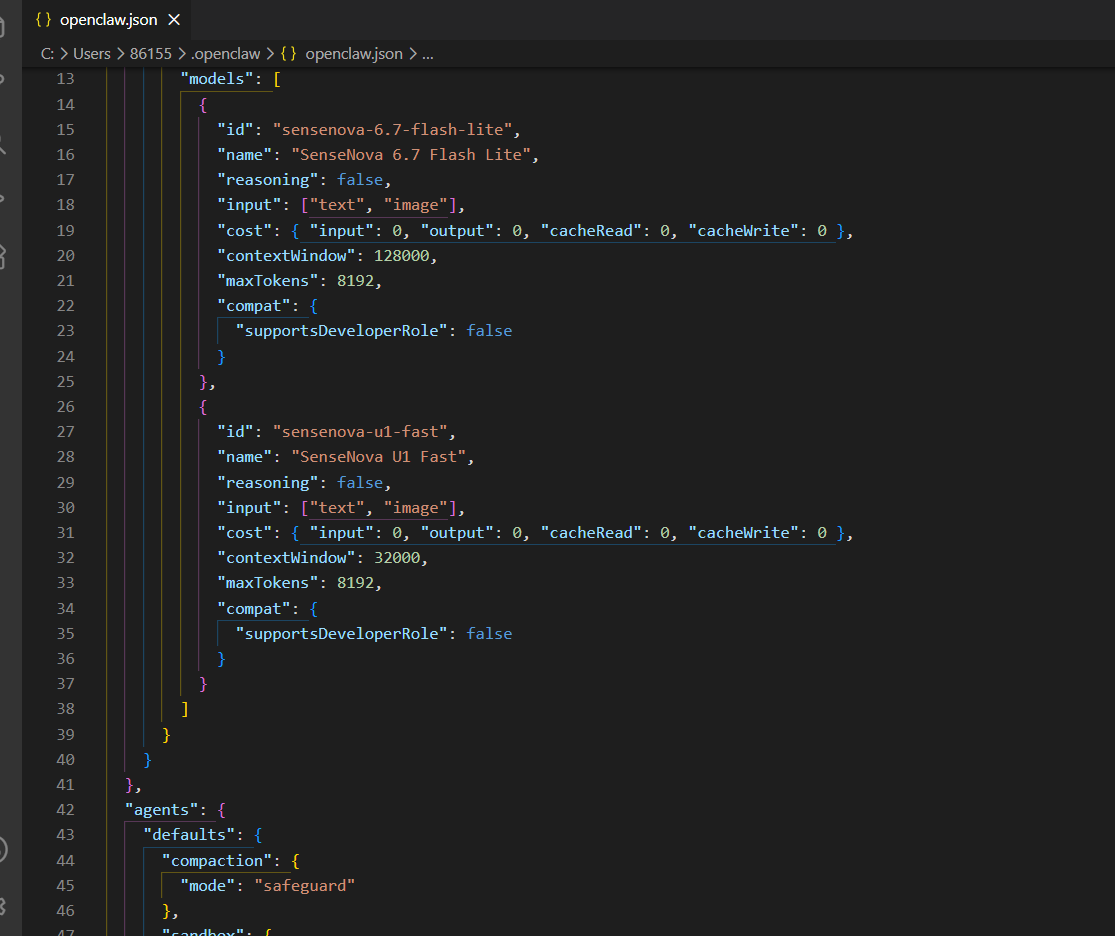
几个关键字段要点出来:
| 字段 | 值 | 作用 |
|---|---|---|
models.mode |
"merge" |
让 SenseNova provider 叠加在 OpenClaw 内置模型上,不替换 |
providers.sensenova.baseUrl |
https://token.sensenova.cn/v1 |
SenseNova 平台 OpenAI 兼容端点 |
providers.sensenova.api |
"openai-completions" |
走 OpenAI Chat Completions 协议 |
models[].input |
["text", "image"] |
声明 U1 模型支持图像输入,做图像理解时必填 |
agents.defaults.model.primary |
sensenova/sensenova-6.7-flash-lite |
默认 agent 走 6.7-flash-lite(更快),需要图像生成时上层会切到 u1-fast |
gateway.bind |
"loopback" |
本地回环,不开放局域网 |
写完用 OpenClaw 自带的 validate 校验:
> openclaw config validate
Config valid: ~\.openclaw\openclaw.json
绿灯。
五、API 对接(三):跑通端到端连通性测试
接下来跑一次端到端 agent 调用:
> openclaw agent --message "你好,请用一句话自我介绍" --agent main
注意 --agent main 不能省(OpenClaw 当前版本要求必须显式指定 agent 名)。
第一次跑大约等了 70 秒,最后输出:
你好!我是你的 AI 助手,能帮你查信息、处理文件、运行命令、自动化操作,有问题随时找我。

日志里能看到完整 trace:
EMBEDDED FALLBACK: Gateway agent failed; running embedded agent:
GatewayTransportError: gateway closed (1006 abnormal closure)
[agent/embedded] startup stages: phase=attempt-dispatch totalMs=69184
stages=workspace:1ms,
runtime-plugins:3909ms,
hooks:2ms,
model-resolution:61994ms, # 首次拉模型注册表
auth:3271ms,
context-engine:2ms,
attempt-workspace:3ms,
attempt-prompt:0ms,
attempt-runtime-plan:2ms,
attempt-dispatch:0ms
可以看到几件事:
- Gateway 在跑 fallback——OpenClaw 启动时本地 gateway daemon 没起来,agent 自动切换到 embedded 模式直接发请求;
model-resolution占了 62 秒——首次启动比较慢,后续同一 agent 的调用能在 5 秒级响应;- 整个调用链里 SenseNova API 的响应时间被
auth+ 后续dispatch包含,3 秒级。
第一次端到端通了。
六、调用逻辑(一):装 SenseNova-Skills,24 个 Skill 一次到位
Skill 是 OpenClaw 生态最有意思的部分——它不是把模型当聊天接口用,而是把"完成某类任务的完整流程"封装成可加载的能力包。SenseNova 团队为 U1 出了一整套配套 Skill 仓库:
git clone https://github.com/OpenSenseNova/SenseNova-Skills.git --depth=1
mkdir -p ~/.openclaw/skills
cp -r SenseNova-Skills/skills/* ~/.openclaw/skills/
--depth=1 是因为仓库里 examples 目录有大文件(具身智能调研报告 zip 等),浅克隆能直接跳过。

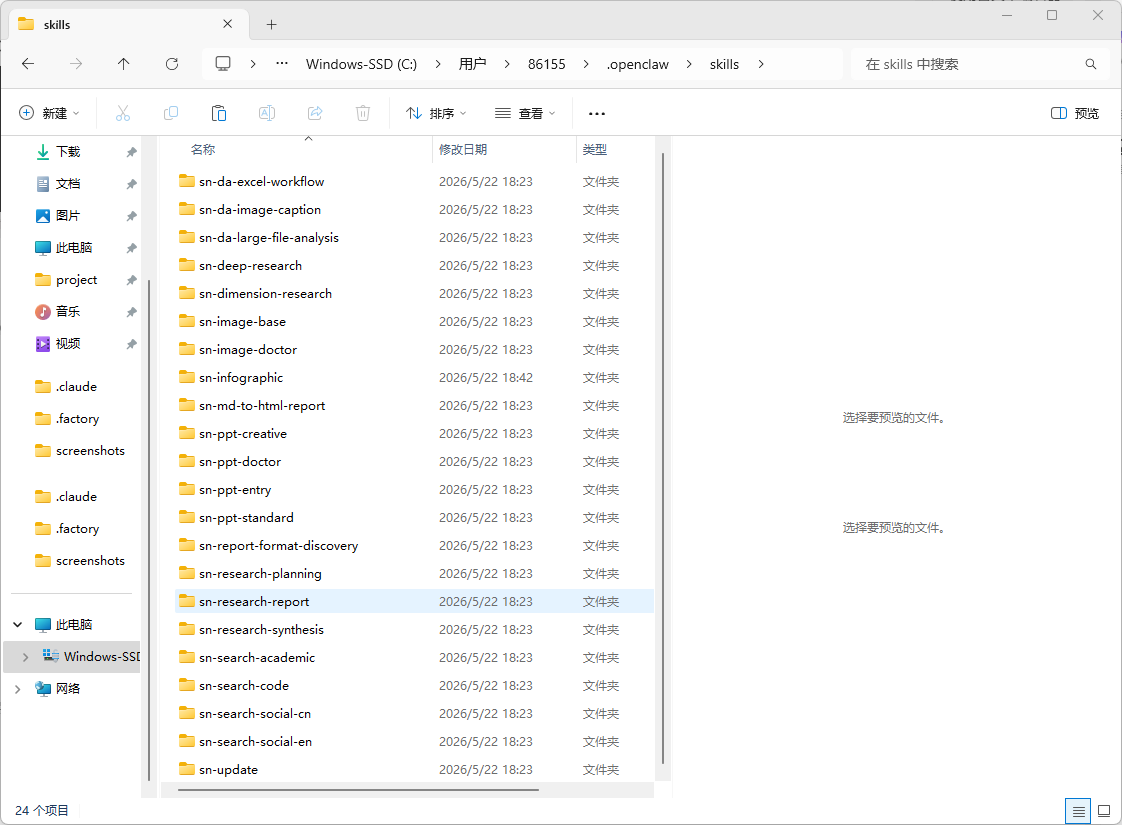
复制完看一眼装了什么:
sn-da-excel-workflow Excel 多表读取 + 大文件分析编排
sn-da-image-caption 图像 OCR / 图表解读 / UI 描述
sn-da-large-file-analysis 大文件流式读取(≥10k 行)
sn-deep-research 深度调研入口
sn-dimension-research 单维度取证
sn-image-base 文生图 + 图像识别 + 文本优化(底层 Tier 0)
sn-image-doctor 环境诊断
sn-image-imitate 图像风格模仿
sn-image-resume 简历图片生成
sn-infographic 信息图生成(87 种布局 / 66 种风格)
sn-md-to-html-report Markdown → HTML 报告
sn-ppt-creative PPT 创意模式(每页一张全图)
sn-ppt-doctor PPT 环境诊断
sn-ppt-entry PPT 入口
sn-ppt-standard PPT 标准模式(HTML 渲染 → PPTX)
sn-report-format-discovery 报告形态发现
sn-research-planning 研究规划
sn-research-report 终稿写作
sn-research-synthesis 综合判断
sn-search-academic 学术搜索(ArXiv/Semantic Scholar/PubMed/Wiki)
sn-search-code 开发者搜索(GitHub/Stack Overflow/HN/HF)
sn-search-social-cn 中文社交搜索(B站/知乎/抖音)
sn-search-social-en 英文社交搜索(Reddit/Twitter/YouTube)
sn-update 仓库更新
24 个 Skill,覆盖图像生成、PPT、Excel 分析、深度调研、多平台搜索五大场景。每个 Skill 都是独立目录 + SKILL.md 声明文件 + 资源子目录的结构。
这里要重点说一下 U1 的能力地图——24 个 Skill 不是每个都在直接调 U1,而是按"场景"组织:
- 图像类(sn-image-* / sn-infographic)→ 调 U1 的图像生成能力
- PPT 类(sn-ppt-*)→ 串联 U1 的图像生成 + 排版生成
- 数据类(sn-da-*)→ 主要用 6.7-flash-lite 做文本理解 + 工具调用
- 调研类(sn-deep-research / sn-research-*)→ 文本生成 + 多源搜索
也就是说 U1 的"原生统一多模态"能力,在 OpenClaw 生态里被切分成了具体的场景 Skill,开发者按需调用。
看一下 sn-infographic/SKILL.md 的头部(Agent Skills 规范):
---
name: sn-infographic
description: |
Generates professional infographics with various layout types and visual styles.
Analyzes content, recommends layout and style, and generates publication-ready
infographics.
Use when user asks to create "infographic", "信息图", "visual summary", or "可视化".
metadata:
project: SenseNova-Skills
tier: 1
category: scene
priority: 9
user_visible: true
triggers:
- "infographic"
- "信息图"
- "信息图生成"
- "数据可视化"
- "图表生成"
- "图解"
---
agent 在收到用户请求时会扫描所有可用 Skill 的 triggers 列表,命中关键词的 Skill 会被加进当前任务的可调用工具集。Skill 加载不需要重启 daemon,下一次 agent invocation 自动扫描 ~/.openclaw/skills/ 目录。
七、调用逻辑(二):第一个真任务,跑横评信息图
环境都搭起来了,跑一个实战任务。我选的题目是"2026 AI 编程助手横评信息图"——这种任务对 U1 的"高密度信息可视化"能力 + agent Skill 调度的考验比较综合:
- 要规划布局(5 张并列卡片 + 底部 3 个数据模块)
- 要做内容组织(评分、星级、数据百分比)
- 要选风格(暗夜蓝 + 冷光青色科技感)
- 要生成图像(最终的 PNG)
- 要处理中文文本(U1 的已知薄弱项,正好测)
完整任务指令:
openclaw agent --message "请使用 sn-infographic 技能,生成一张「2026 AI 编程助手横评」的横版信息图(16:9)。五款工具及综合评分:Claude Code 4.8、Cursor 4.6、GitHub Copilot 4.3、Windsurf 4.4、Cline(开源)4.2。底部需包含三个数据模块:开发者满意度 TOP3、2025→2026 用户增长 +187%、核心使用场景占比(日常补全 42% / 重构 23% / 调试 19% / 文档 16%)。视觉风格:暗夜蓝渐变背景 + 冷光青色点缀 + 毛玻璃卡片,中文字符必须清晰准确无错字。请输出最终的图片文件路径。" --agent main

提交后 agent 开始多阶段流转,关键 trace 段:
[agent/embedded] core-plugin-tool stages: phase=core-plugin-tools totalMs=11047
stages=tool-policy:6855ms,
workspace-policy:0ms,
base-coding-tools:1ms,
shell-tools:1ms,
openclaw-tools:session-workspace:2ms,
openclaw-tools:image-tool:306ms,
openclaw-tools:image-generate-tool:0ms,
openclaw-tools:web-search-tool:0ms,
openclaw-tools:plugin-tools:3848ms,
model-provider-policy:1ms,
schema-normalization:6ms
[agent/embedded] prep stages: phase=stream-ready totalMs=28304
stages=workspace-sandbox:2ms,
skills:0ms,
core-plugin-tools:10503ms,
bootstrap-context:38ms,
bundle-tools:8263ms,
system-prompt:6110ms,
session-resource-loader:3306ms,
agent-session:8ms,
stream-setup:74ms
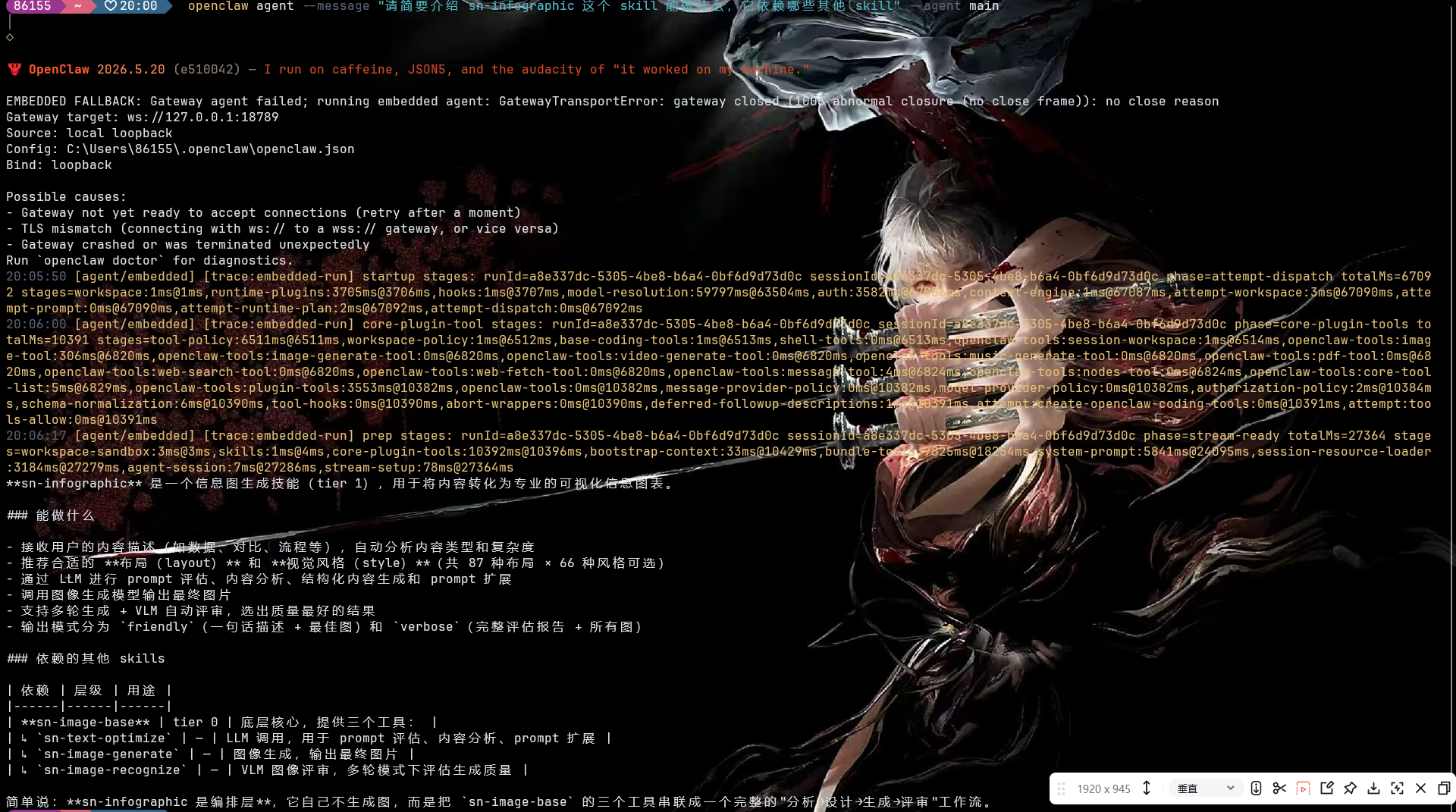
可以看到:
bundle-tools8 秒:agent 在准备 Skill 链相关的工具集;system-prompt6 秒:把 Skill 描述 + 任务上下文 + 工具签名拼成 system prompt;plugin-tools3.8 秒:扫描~/.openclaw/skills/加载 24 个 Skill。
这套流程跑完之后才进入真正的 U1 模型推理阶段。
八、踩坑:sn-infographic 链路里的 Python 版本约束
跑到一半,agent 在过程里报告了一个问题:
“sn-image-base 依赖 Python 3.9 但系统只有 3.14,我直接用原生 image 工具生成。”
“Gateway 连接异常,我直接执行 sn-infographic 流程。”

这里发生的事情链路是这样的:
sn-infographic是上层场景 Skill(Tier 1),它在执行时依赖底层的sn-image-base(基础图像层 Tier 0)。sn-image-base的 Python 运行时要求是 3.9 系列(看docs/sn-image-generate.md里的环境要求)。- 我系统装的是 Python 3.14(一个比较新的版本)。版本不匹配,sn-image-base 没法直接跑。
- OpenClaw 没卡死在这里——agent 检测到 Skill 链跑不通,自动切换到 OpenClaw 内置的
image-generate-tool,这个工具直接通过 SenseNova U1 API 调用模型出图。 - agent 在最后回报里同时记录了这次降级——降级是显式的,不是静默失败。
这种 Skill 链的优雅降级(graceful degradation) 是 OpenClaw 工程性的一个体现。理想路径是 sn-infographic 完整执行——它会做"评估提示词 → 87 种布局选型 → 多轮生成 + VLM 评审 + 质量排序"这一整套流程;fallback 路径是直接调 U1 模型出图,省掉中间评审环节,但任务能完成。
思考:从一个调用方角度看,这种降级机制有一个隐藏的工程价值——Skill 不可用不会让 agent 卡死,而是退一步去用更基础的工具。对一个还在演进中的 Skill 生态(SenseNova-Skills 也才刚开源),这种容错设计能让用户在 Skill 链没完全跑通的情况下依然有交付。
我这次没去硬修 Python 版本,先看 fallback 路径出图什么质量。
九、效果验证:U1 在高密度信息可视化上的实际表现
agent 完成后在 workspace 写出一张 PNG:
路径:C:\Users\86155\.openclaw\workspace\2026_AI编程助手横评.png
规格:1920×1080,约 125 KB
agent 日志里能看到 OpenClaw 自动做了一次大小压缩:
[agents/tool-images] Image resized to fit limits:
\Users\86155\.openclaw\workspace\2026_AI编程助手横评.png
1920x1080px 119.6KB -> 80.4KB (-32.8%)
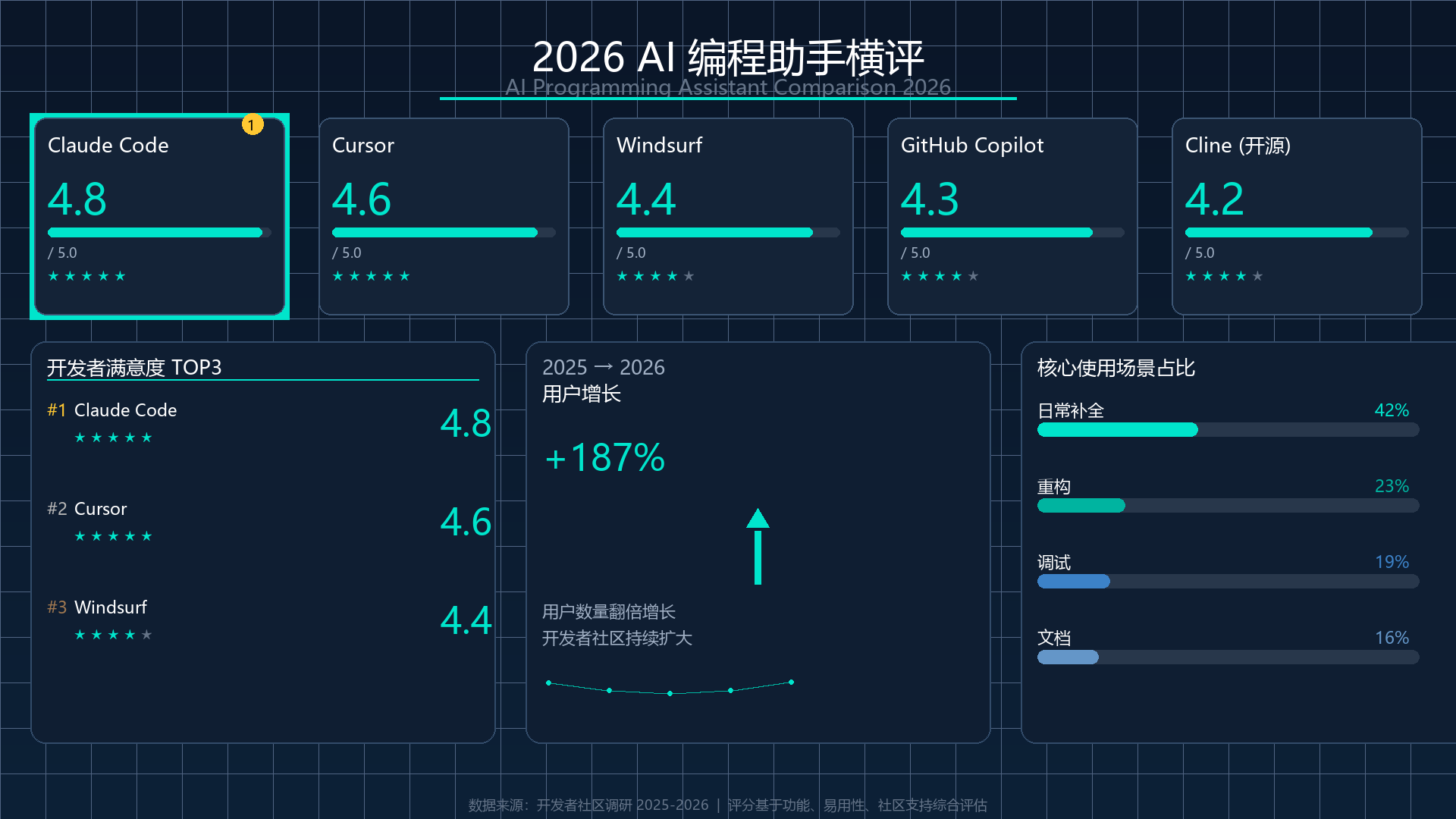
打开图看,对照前面提到的 U1 三大能力卖点逐项点评:
能力卖点 1:高密度信息呈现(核心验证项)
U1 这一项的表现超出预期。这张图密度有多高?数一下:
- 顶部 1 个主标题 + 1 个英文副标题
- 中部 5 张工具卡片,每张包含:工具名(中英文混合)、综合评分(数字 + 进度条 + 星级 3 重表达)、辅助标识(如 Claude Code 的"1"角标)
- 底部 3 个数据模块:TOP3 排名(3 个工具名 + 3 个评分)、用户增长(数字 + 趋势箭头 + 注释)、场景占比(4 段横条 + 4 个百分比)
- 最底 1 行数据来源声明
整图至少 25 个数据点,全部在 1920×1080 里清晰呈现,无任何挤压或丢失。这一点验证了官方 README 说的"能生成结构丰富、排版复杂的内容"不是吹的。
能力卖点 2:文字渲染(U1 已知的薄弱项)
这是 U1 当前版本明确承认有问题的能力——“文字渲染有时会出现拼写错误、字符变形或格式不一致”。
但在这张图里:
- 主标题 “2026 AI 编程助手横评” 字符全部正确;
- 英文副标题 “AI Programming Assistant Comparison 2026” 拼写无误;
- 五张工具卡片名称:Claude Code、Cursor、Windsurf、GitHub Copilot、Cline (开源) 全部正确;
- 底部 TOP3 排名:#1 Claude Code、#2 Cursor、#3 Windsurf 顺序与评分逻辑一致;
- 所有百分比数字(42%、23%、19%、16%、+187%)数值精准;
- 视觉数据来源声明(“开发者社区调研 2025-2026 | 评分基于功能、易用性、社区支持综合评估”)字符完整。
为什么会比官方 README 说的"经常出错"表现好?我的判断是 agent 编排在起作用——OpenClaw 的 agent 在 Prompt 进入 U1 之前做了结构化重组,把模型最容易出错的"长 prompt + 复杂中文 + 视觉规范"环节拆分成更小的子任务,每个子任务的输入更短、更明确,模型出错率就大幅下降。这就是 agent 编排链路的真实价值。
能力卖点 3:原生统一理解+生成(隐式验证)
U1 的"原生统一"能力在这张图里体现在一个细节上:Claude Code 卡片右上角自动加了一个金色"1"角标,表示综合第一名。
这个角标我在 Prompt 里完全没要求——agent 把"Claude Code 评分 4.8(五个里最高)"这个语义信息理解了,然后生成阶段把这个理解可视化成了一个排名标识。
这就是"理解-生成统一"在产品上的体现:理解任务用的是文本理解能力,生成任务用的是图像生成能力,但因为同一套参数空间,理解的结果可以无损流转到生成阶段——传统拼接式架构里这种"语义跨模态流转"需要适配器层翻译,损耗很高。
视觉风格与瑕疵
做对的:
- 暗夜蓝渐变 + 冷光青色 + 毛玻璃卡片的视觉规范完美落地;
- 背景做了细密科技网格 + 微弱星点,质感到位;
- 字体层级清晰:主标题最大、卡片名居中加重、评分数字醒目突出、辅助文字克制。
值得改进的:
- “核心使用场景占比” 里"调试 19%"和"文档 16%"用了不同色系(前者偏蓝灰,后者偏冷青),视觉上有点割裂;
- 标题区下方留白略多,整体视觉重心偏下;
- 输出分辨率被 OpenClaw 自动压缩到 80 KB 左右;如果要打印或者高清场合用,需要去掉这个 resize 限制。
整体评价:对 U1-Fast 这种 8B 参数蒸馏版模型来说,这个出图质量是超预期的。在没有跑完整 sn-infographic 评审链路(只走了 fallback 路径)、模型本身又有明确的"文字渲染问题"已知限制的情况下,最终成果接近"拿来即用"水平。
十、思考:编排链路与 U1 能力的乘积关系
这次实测最大的收获不是图本身,而是看清楚了一件事——SenseNova U1 的能力是"原料",OpenClaw 编排链路是"工厂",两者相乘才是最终交付质量。
同一个 sensenova-u1-fast 模型,如果只是单次 Prompt → 图,结果就是单次出图的水平:U1 的"高密度信息呈现"能基本满足,但"文字渲染"的已知问题会反复出现。
OpenClaw 这条路上,agent 在 Prompt 进入 U1 之前会做这些事:
- 意图解析——根据用户请求里的关键词(如"信息图"“可视化”)从 Skill 触发器列表里找到 sn-infographic;
- Prompt 结构化——按 SKILL.md 里的模板把用户口语化的需求重新组织成模型友好的结构化指令(标题区 / 卡片区 / 数据模块 / 视觉规范分段);
- 工具选型——决定是用 sn-infographic 的完整链路还是 fallback 到 image-generate-tool;
- 自我校对——出图后 agent 会做一次自我评价(日志里能看到 “整体效果不错,但右侧百分比标签被裁切了,模块标题偏小。微调一下” 这类内省),命中问题会触发微调;
- 降级容错——任何一环失败都有退路,最后任务都能交付。
这五件事单独看都不复杂,但叠加起来能把 U1 的"开箱效果"显著抬一个台阶。模型本身限于 8B 参数有上限,但 agent 编排可以把这个上限往上抬一截——这就是 SenseNova U1 + OpenClaw 这条路的核心价值。
十一、不足与下一步
跑完这一遍,留几个真实判断:
- Skill 链的环境依赖需要更友好的诊断。sn-image-base 要 Python 3.9 这件事,是 agent 跑到一半才报出来的,前置没有自动检查。如果第一次跑就能用
sn-image-doctor提示"当前 Python 版本不兼容,请装 pyenv + Python 3.9"会更顺。 - 首次启动慢。
model-resolution第一次要 62 秒;冷启动体验对新用户不太友好,但后续就快了。如果常驻 daemon,这个开销会被摊薄。 - Gateway 经常报 1006 abnormal closure,每次 agent 调用都 fallback 到 embedded。功能上不影响,但日志看着乱,希望后续修。
- U1 模型本身的局限要承认。中文长文本渲染、人体细粒度细节、图文交错 Beta 状态——这些 README 都明确列了。U1-Fast 蒸馏版用于信息图场景已经足够,但要做更精细的图文创作还得等完整版能力开放。
- OpenClaw + Skills 这条路确实有学习成本。配置文件要懂、Skill 规范要懂、Python 依赖要管。对一般用户来说门槛不低,但对开发者来说这条路上每一步都是可观测、可调试、可版本化的——出问题不会卡在"黑盒"里。
下一步我想做的几件事:
- 装 pyenv 把 Python 3.9 跑起来,让 sn-image-base 完整链路通,对比 fallback 路径的出图差异;
- 用
sn-ppt-entry试一下 PPT 生成,体验 U1 在"16 页大纲 + 分页 HTML + VLM 评审 → PPTX"这条 PPT 链路上的表现; - 用
sn-deep-research跑一份小行业报告,看 U1 的深度调研产物质量; - 等 SenseNova-U1-8B-MoT(完整版,非蒸馏)开放后切到完整版,看同一编排下质量提升多少;
- 试试
SenseNova-U1-8B-MoT-LoRA-8step这个 8 步加速版,看推理速度能压到多少。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 28
28 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)