大模型入门-GSPO 分组序列策略优化
2.10 GSPO 分组序列策略优化 (Group Sequence Policy Optimization)
论文地址: https://arxiv.org/pdf/2507.18071
论文中提到,传统的 GRPO 对 next-token 的重要性采样容易引入高方差,导致训练不稳定甚至崩溃。GSPO 针对此问题调整了优化目标的颗粒度,将其从 token-level(词级)变为了 sequence-level(序列级)。 在优化奖励时,模型不再依赖逐个 token 的概率比值,而是关注整个生成序列的综合表现,从而有效降低噪声并提升训练的稳定性。
一、 PPO 与 GRPO 的 Token 级别优化困境
在实际应用中,我们通常会用回复的“完整内容(整句话)”来评价模型的表现,但 PPO 与 GRPO 底层却是用“逐词(Token)”的方法来计算权重并训练的。
PPO 和 GRPO 对模型输出的 token 逐个进行优化,这种做法的本意是为了实现更精细的更新。但论文指出,在大模型长文本生成的场景下,这种逐词计算极易引入严重的噪声和奖励偏差,导致模型训练迷失方向。
GSPO 的核心思路就是把“奖励”和“优化目标”重新对齐:从给每个 token 独立计算权重,改为直接对整个句子计算重要性权重。 这种切换带来的好处主要有两点:
- 更稳定: 直接对整句进行训练,大幅减少了词级剧烈波动带来的训练噪声。
- 更高效: 根据句子的整体得分筛选样本,仅保留高质量、纯净的样本参与优化,让模型更快收敛,效果更好。
二、 为什么 Token 级别的优化难以收敛?
我们用一个简单的文本生成场景来具体说明。假设我们要训练一个语言模型生成序列“猫喜欢鱼”,这个序列包含 3 个 token: t 1 = “猫” t1=\text{“猫”} t1=“猫”、 t 2 = “喜欢” t2=\text{“喜欢”} t2=“喜欢”、 t 3 = “鱼” t3=\text{“鱼”} t3=“鱼”。
目标策略 P P P(我们最终想优化的完美模型),它对每个 token 的条件概率假设如下:
- P ( t 1 = “猫” ∣ 空 ) = 0.8 P(t1=\text{“猫”}|\text{空}) = 0.8 P(t1=“猫”∣空)=0.8 (在句首更可能生成“猫”)
- P ( t 2 = “喜欢” ∣ “猫” ) = 0.7 P(t2=\text{“喜欢”}|\text{“猫”}) = 0.7 P(t2=“喜欢”∣“猫”)=0.7 (“猫”后面更可能接“喜欢”)
- P ( t 3 = “鱼” ∣ “猫喜欢” ) = 0.9 P(t3=\text{“鱼”}|\text{“猫喜欢”}) = 0.9 P(t3=“鱼”∣“猫喜欢”)=0.9 (“猫喜欢”后面更可能接“鱼”)
行为策略 Q Q Q(我们实际采样用的旧模型),它的条件概率假设如下:
- Q ( t 1 = “猫” ∣ 空 ) = 0.5 Q(t1=\text{“猫”}|\text{空}) = 0.5 Q(t1=“猫”∣空)=0.5
- Q ( t 2 = “喜欢” ∣ “猫” ) = 0.2 Q(t2=\text{“喜欢”}|\text{“猫”}) = 0.2 Q(t2=“喜欢”∣“猫”)=0.2
- Q ( t 3 = “鱼” ∣ “猫喜欢” ) = 0.3 Q(t3=\text{“鱼”}|\text{“猫喜欢”}) = 0.3 Q(t3=“鱼”∣“猫喜欢”)=0.3
重要性采样的核心,是用行为策略 Q Q Q 的样本来估计目标策略 P P P 的期望。对于整个序列“猫喜欢鱼”,其联合概率为各条件概率的乘积,因此序列级的重要性权重应为:
序列权重 = P ( t 1 ) ⋅ P ( t 2 ∣ t 1 ) ⋅ P ( t 3 ∣ t 1 , t 2 ) Q ( t 1 ) ⋅ Q ( t 2 ∣ t 1 ) ⋅ Q ( t 3 ∣ t 1 , t 2 ) 序列权重=\frac{P(t1)\cdot P(t2|t1)\cdot P(t3|t1,t2)}{Q(t1)\cdot Q(t2|t1)\cdot Q(t3|t1,t2)} 序列权重=Q(t1)⋅Q(t2∣t1)⋅Q(t3∣t1,t2)P(t1)⋅P(t2∣t1)⋅P(t3∣t1,t2)
代入数值:
序列权重 = 0.8 × 0.7 × 0.9 0.5 × 0.2 × 0.3 = 0.504 0.03 = 16.8 序列权重=\frac{0.8\times 0.7\times 0.9}{0.5\times 0.2\times 0.3}=\frac{0.504}{0.03}=16.8 序列权重=0.5×0.2×0.30.8×0.7×0.9=0.030.504=16.8
这个权重的含义是:旧模型 Q Q Q 生成这整句话的概率比目标模型 P P P 低了 16.8 倍。因此在更新时,需要给这个样本“放大 16.8 倍”的权重。
但如果使用 PPO 或 GRPO 的逐 token 计算,每个 token 的单独权重为:
- t 1 t1 t1 权重: 0.8 0.5 = 1.6 \frac{0.8}{0.5}=1.6 0.50.8=1.6
- t 2 t2 t2 权重: 0.7 0.2 = 3.5 \frac{0.7}{0.2}=3.5 0.20.7=3.5
- t 3 t3 t3 权重: 0.9 0.3 = 3 \frac{0.9}{0.3}=3 0.30.9=3
致命缺陷:
整个序列的分布偏差是 16.8 倍,但单个 token 的权重(1.6、3.5、3)都远小于 16.8。如果用单个 token 的权重来矫正,会严重低估需要放大的程度,导致分布矫正不足。同时,逐 token 的权重会把每个词局部的波动直接带入训练(例如 t 2 t2 t2 的权重 3.5 远高于 t 1 t1 t1 的 1.6,模型会误以为 t 2 t2 t2 的偏差最严重),这会使得单次采样的方差被无限放大,模型过度关注局部而忽略整体合理性。
补充:什么是重要性采样?
重要性采样是在无法直接从“目标分布 P P P”采样时,通过从一个更容易获取的“行为分布 Q Q Q”中采样,再用重要性权重 P ( x ) Q ( x ) \frac{P(x)}{Q(x)} Q(x)P(x) 矫正偏差,从而估计目标期望的技术。其核心公式为:
E P [ f ( x ) ] = 1 n ∑ i = 1 n ( P ( x i ) Q ( x i ) ) ⋅ f ( x i ) \mathbb{E}_{P}[f(x)]=\frac{1}{n}\sum_{i=1}^{n}\left(\frac{P(x_{i})}{Q(x_{i})}\right)\cdot f(x_{i}) EP[f(x)]=n1i=1∑n(Q(xi)P(xi))⋅f(xi)
利用离线数据(来自旧策略)来评估新策略的期望,避免了每次更新都要重新采样,大幅降低了成本。
三、 GRPO 为什么在 MoE 架构上难以收敛?
MoE (混合专家模型) 每次推理只激活少数几个专家模块。在强化学习更新参数时,新旧策略的 Router(路由)极易发生变化,导致新旧策略针对同一个词激活了完全不同的专家。
- 旧策略下: Router 激活了【专家A】和【专家C】。
- 新策略下: Router 激活了【专家B】和【专家D】。
这导致计算重要性比率 π n e w π o l d \frac{\pi_{new}}{\pi_{old}} πoldπnew 时,两个概率的生成基础存在底层结构差异。这种差异会让重要性比率急剧失真,引发 Clip 机制被频繁触发,进而导致梯度严重损坏。高方差噪声渗入训练后,往往会造成模型不可逆的崩溃。传统算法通常需要引入成本高昂的 Routing Replay(路由回放) 机制来强行绑定前后一致性,严重制约了训练效率。
四、 回顾 GRPO 的损失函数
GRPO 采用的是词级 (Token-level) 重要性权重:
r i , t ( θ ) = π θ ( y i , t ∣ x , y i : < t ) π θ o l d ( y i , t ∣ x , y i : < t ) r_{i,t}(\theta) = \frac{\pi_{\theta}(y_{i,t}|x,y_{i:<t})}{\pi_{\theta_{old}}(y_{i,t}|x,y_{i:<t})} ri,t(θ)=πθold(yi,t∣x,yi:<t)πθ(yi,t∣x,yi:<t)
其损失函数为:
J G R P O ( θ ) = E x ∼ D , { y i } i = 1 G ∼ π θ o l d [ 1 G ∑ i = 1 G 1 ∣ y i ∣ ∑ t = 1 ∣ y i ∣ min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) ] \mathcal{J}_{GRPO}(\theta)=\mathbb{E}_{x\sim\mathcal{D}, \{y_i\}_{i=1}^G \sim \pi_{\theta_{old}}}\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|y_{i}|}\sum_{t=1}^{|y_{i}|}\min(r_{i,t}(\theta)\hat{A}_{i,t}, clip(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_{i,t})\right] JGRPO(θ)=Ex∼D,{yi}i=1G∼πθold G1i=1∑G∣yi∣1t=1∑∣yi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t)
其中优势值 A ^ i , t \hat{A}_{i,t} A^i,t 均为共享的组内标准化优势:
A ^ i = r ( x , y i ) − m e a n ( { r ( x , y i ) } i = 1 G ) s t d ( { r ( x , y i ) } i = 1 G ) \hat{A}_{i}=\frac{r(x,y_{i})-mean(\{r(x,y_{i})\}_{i=1}^{G})}{std(\{r(x,y_{i})\}_{i=1}^{G})} A^i=std({r(x,yi)}i=1G)r(x,yi)−mean({r(x,yi)}i=1G)
由于 GRPO 对每个 token 进行重要性采样修正的分布并不一致,用同一个 Clip 标准进行裁剪在长文本和 MoE 场景下显得极不合理。
五、 GSPO 的损失函数:分组序列策略优化
基于上述问题,通义千问团队提出了 GSPO。GSPO 将重要性采样权重升级为了 Sequence 级别 (序列级别):
J G S P O ( θ ) = E x ∼ D , { y i } i = 1 G ∼ π θ o l d [ 1 G ∑ i = 1 G min ( s i ( θ ) A ^ i , c l i p ( s i ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i ) ] \mathcal{J}_{GSPO}(\theta)=\mathbb{E}_{x\sim\mathcal{D}, \{y_i\}_{i=1}^G \sim \pi_{\theta_{old}}}\left[\frac{1}{G}\sum_{i=1}^{G}\min(s_{i}(\theta)\hat{A}_{i}, clip(s_{i}(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_{i})\right] JGSPO(θ)=Ex∼D,{yi}i=1G∼πθold[G1i=1∑Gmin(si(θ)A^i,clip(si(θ),1−ϵ,1+ϵ)A^i)]
GSPO 同样采用基于分组的优势估计 A ^ i \hat{A}_{i} A^i,但它基于一句完整的话来定义重要性权重 s i ( θ ) s_{i}(\theta) si(θ),并引入了长度归一化以控制数值溢出:
s i ( θ ) = ( π θ ( y i ∣ x ) π θ o l d ( y i ∣ x ) ) 1 ∣ y i ∣ = exp ( 1 ∣ y i ∣ ∑ t = 1 ∣ y i ∣ log π θ ( y i , t ∣ x , y i : < t ) π θ o l d ( y i , t ∣ x , y i : < t ) ) s_{i}(\theta)=\left(\frac{\pi_{\theta}(y_{i}|x)}{\pi_{\theta_{old}}(y_{i}|x)}\right)^{\frac{1}{|y_{i}|}} = \exp\left(\frac{1}{|y_{i}|}\sum_{t=1}^{|y_{i}|}\log\frac{\pi_{\theta}(y_{i,t}|x,y_{i:<t})}{\pi_{\theta_{old}}(y_{i,t}|x,y_{i:<t})}\right) si(θ)=(πθold(yi∣x)πθ(yi∣x))∣yi∣1=exp ∣yi∣1t=1∑∣yi∣logπθold(yi,t∣x,yi:<t)πθ(yi,t∣x,yi:<t)
核心优势:
GSPO 是对整句话的综合概率比进行裁剪,这既完美契合了序列级的奖励机制,也与最终的优化目标一致。引入长度归一化 1 ∣ y i ∣ \frac{1}{|y_i|} ∣yi∣1 有效降低了长文本带来的方差,将 s i ( θ ) s_i(\theta) si(θ) 约束在了一个稳定、统一的数值范围内。
六、 实验效果
论文基于 Qwen3-30B-A3B-Base 模型开展了冷启动微调实验。在相同算力下进行对比,GSPO 展现出了更优的训练效率,其训练奖励曲线不仅攀升更快、更平稳,最终在各项基准测试(如 AIME 24、LiveCodeBench)中的精度也显著超越了带有 Routing Replay 的传统 GRPO 模型。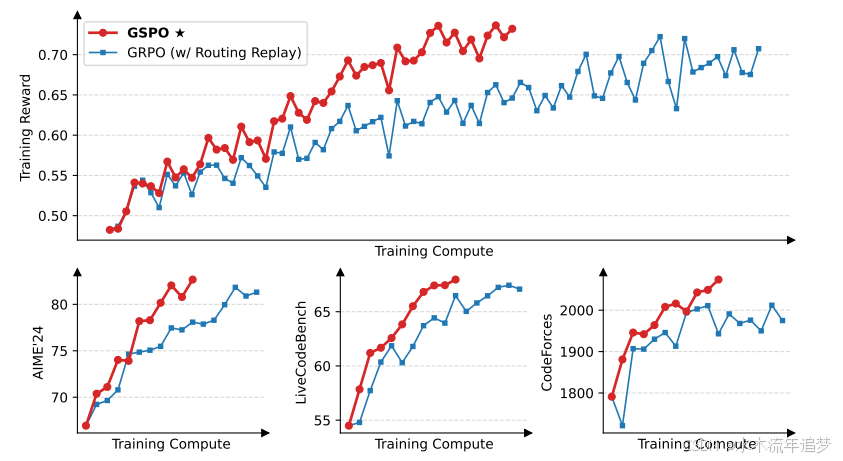
七、 附:GSPO 核心 Loss 代码实现
以下是 GSPO 算法中计算序列级重要性比率并进行更新的 Python 参考代码:
import torch
def gspo_update(policy, ref_policy, optimizer, prompts, responses, rewards, response_mask, epsilon_low=0.2, epsilon_high=0.2):
# 1. 计算 token 级 log 概率 [batch, seq_len]
log_probs = policy.log_prob_per_token(prompts, responses)
ref_log_probs = ref_policy.log_prob_per_token(prompts, responses)
# 2. 计算群组归一化优势 (与 GRPO 相同)
group_mean = rewards.mean()
group_std = rewards.std() + 1e-8
advantages = (rewards - group_mean) / group_std # [batch]
# 3. GSPO关键: 计算序列级重要性比率
negative_approx_kl = log_probs - ref_log_probs # [batch, seq_len]
seq_lengths = response_mask.sum(dim=1).clamp(min=1) # [batch]
# 序列级重要性比率指数部分: (1/|y_i|) * Σ_t log(π_θ/π_old)
negative_approx_kl_seq = (negative_approx_kl * response_mask).sum(dim=1) / seq_lengths # [batch]
# 构造 token 级序列重要性比率 (通过 detach 技巧保留梯度)
log_seq_ratio = (log_probs - log_probs.detach() + negative_approx_kl_seq.detach().unsqueeze(-1))
seq_importance_ratio = torch.exp(log_seq_ratio) # [batch, seq_len]
# 4. PPO 裁剪损失计算
clipped_ratio = torch.clamp(seq_importance_ratio, 1 - epsilon_low, 1 + epsilon_high)
loss1 = -advantages.unsqueeze(-1) * seq_importance_ratio
loss2 = -advantages.unsqueeze(-1) * clipped_ratio
# 序列级聚合损失 (注意这里是用 maximum 因为前面加了负号,等价于原公式的 min 外面套负号)
pg_losses = torch.maximum(loss1, loss2)
policy_loss = (pg_losses * response_mask).sum() / response_mask.sum()
# 5. 更新策略参数
optimizer.zero_grad()
policy_loss.backward()
optimizer.step()
return policy_loss.item()


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)