从通用到垂直:OpenCSG 发布 CIMD 跨来源文档智能语料库,重新定义行业数据集标准

当 Chinese FineWeb 系列数据集在通用中文 AI 领域持续发光发热时,OpenCSG 悄然完成了一次战略转身——从通用语料走向垂直场景,从单一来源走向跨来源整合,从语言模型基座延伸到文档智能底座。
2026 年 3 月,OpenCSG 正式开源 CIMD(Cross-Source Multilingual Document Corpus),一个面向文档智能任务的跨来源、多语言 JSONL 语料库。这不仅是 OpenCSG 数据战略的重要升级,更是从“能读懂文字”到“真正理解文档”的关键一步。
为什么需要 CIMD?文档智能的数据困境
在大模型时代,一个容易被忽视的现实正在浮现:通用语料虽然让模型能够流畅对话,但面对真实世界的文档智能任务时,往往力不从心。
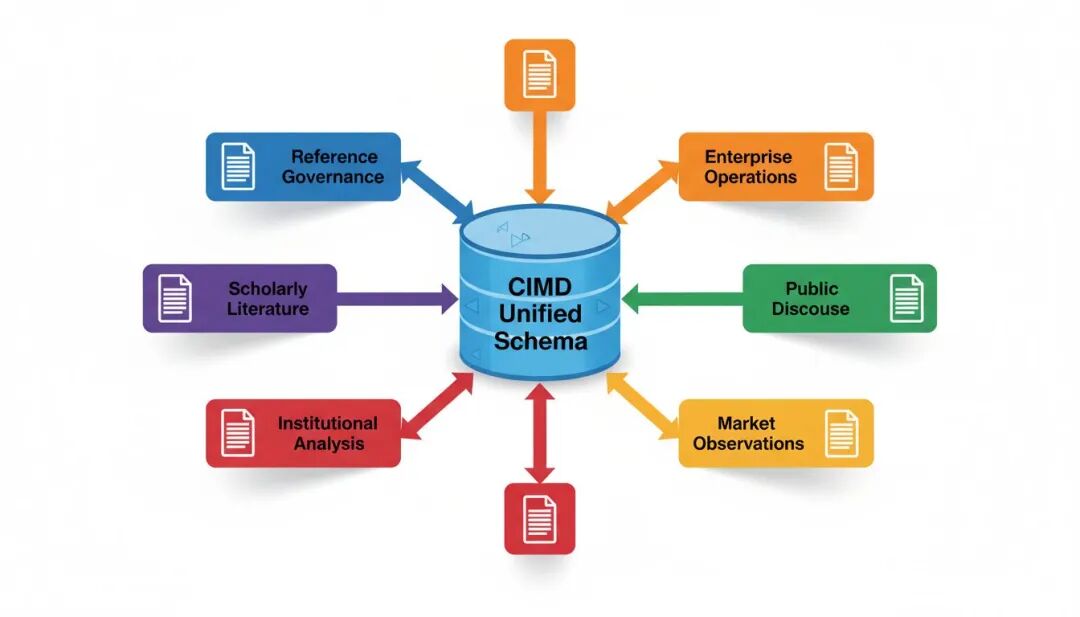
以企业知识库问答为例,一个看似简单的问题“某项政策对我们的业务有什么影响”,实际上需要同时调用制度参考层面的法律法规、政策文件和行业标准,学术研究层面的专业论文、学位论文和会议记录,机构分析层面的研究报告、协会材料和咨询分析,企业运营层面的产能数据、融资材料和项目更新,以及公共讨论层面的媒体报道、观点记录和舆情分析。
传统的单一来源数据集只能回答局部问题——政策库侧重制度依据,论文库侧重技术原理,企业库侧重运营数据。而真实的文档智能任务往往需要跨来源的连续证据链,需要在不同类型的文档之间建立关联,需要追溯每一条证据的来源和时间。
更关键的是,现有的文档数据集普遍存在三大痛点:元数据缺失(只有正文,没有来源、时间、语言等关键信息)、格式混乱(PDF、DOCX、HTML 混杂,难以统一处理)、可追溯性差(无法回溯到原始文档,难以做审计和归因)。
这正是 CIMD 的核心价值所在:将制度文本、学术文献、机构分析、企业资料、公共讨论和市场材料放入同一套记录体系,每条记录都保留完整的元数据,让 AI 能够像文档分析师一样进行“跨来源检索 + 证据归因 + 时间追溯”的联合推理。
CIMD 核心特性:不只是文档堆砌,而是智能就绪的数据资产
跨来源整合:打破文档孤岛
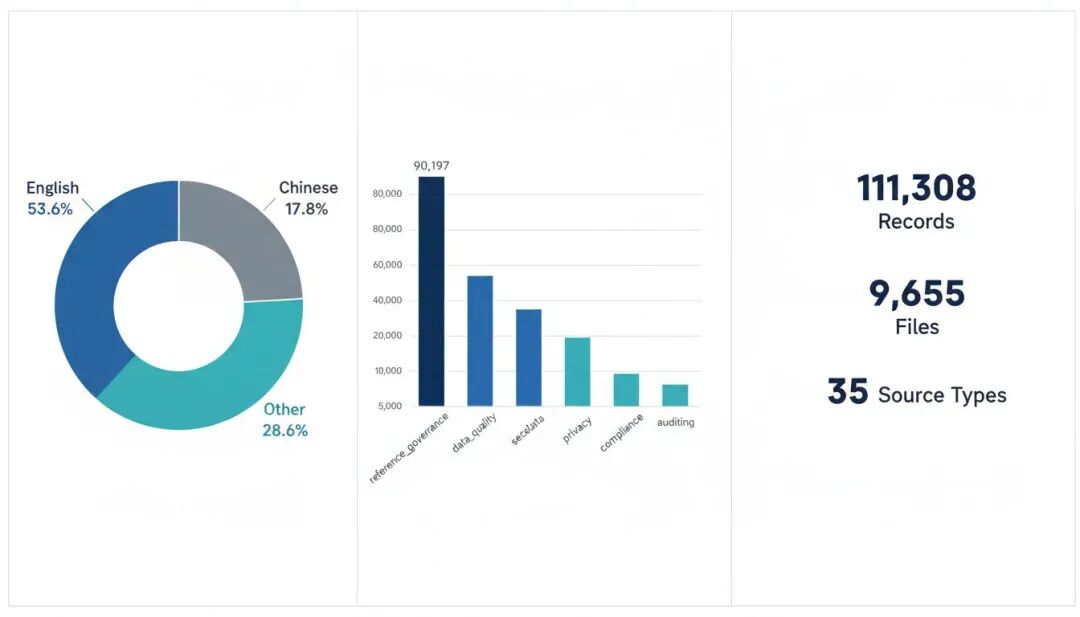
CIMD 最大的创新在于来源家族清晰的跨来源整合。当前公开快照包含 111,308 条 JSONL 记录,覆盖 9,655 个去重文件,保留 35 类来源类型,按 7 个来源家族组织:
-
制度参考(reference_governance):90,197 条记录,涵盖法规、政策、标准和合规参考材料
-
学术文献(scholarly_literature):17,569 条记录,包含学术出版物、长文档资料、学位论文和会议记录
-
企业运营(enterprise_operations):1,744 条记录,整合企业资料、运营信息、产能记录、融资材料和项目更新
-
公共讨论(public_discourse):1,286 条记录,汇集公共讨论、媒体材料和观点记录
-
机构分析(institutional_analysis):484 条记录,涵盖研究机构、协会、咨询机构和金融机构分析材料
-
市场观察(market_observations):20 条记录,包含市场、交易和价格相关记录
-
其他记录(miscellaneous_records):8 条记录,未归入主要来源家族的材料
这种跨来源结构使得同一主题可以在多种来源之间形成连续证据链,减少跨库拼接带来的语义割裂和上下文缺口。
元数据完整:从“能用”到“好用”的关键
CIMD 和通用网页语料的核心差别在于记录级元数据。每条记录都保留了完整的元数据字段:
-
标识字段:file_id(文件标识)、data_id(记录标识)、file_name(原始文件名)
-
来源字段:source_type(来源类型)、author(作者/机构)、source_details(来源链接或说明)
-
时间字段:original_time(原始发布时间)、content_time(内容时间)
-
分类字段:language(语言标签)、country(国家标签)、keywords(关键词)
-
授权字段:license_type(记录级授权类型)、data_version(数据版本)
使用者可以按来源筛选只使用制度参考或只使用学术文献,按时间过滤获取特定时间段的政策变化,按语言分类进行中英文分离或混合使用,还可以将检索到的文本片段回溯到原始文件。对于长文档检索、来源归因、审计留痕、授权控制、质量抽检和数据资产管理,这类记录级元数据比单纯正文更有操作价值。
长文档就绪:为文档智能优化的数据结构
CIMD 专门为长文档工作流设计。公开数据主要来自 PDF、DOCX、JSONL 等载体,发布时统一整理为按行读取的 JSONL。raw_chunk 保存解析后的文本块,单个源文件可以对应多条记录。
当前块长不是固定 token 长度,公开快照的 raw_chunk 中位数字符数约为 3,951,P95 约为 4,091。这个长度设计考虑了:
-
向量库索引的效率(不会太长导致检索粒度过粗)
-
长上下文模型的输入需求(可以直接作为上下文块)
-
人工审核的可读性(一个 chunk 对应一个完整的语义单元)
进入向量库或长上下文模型前,用户可按窗口长度重新切分,保持了最大的灵活性。
多语言覆盖:支持跨语种文档智能
当前快照包含 en(英文)、zh(中文)和 other(其他语言) 三类语言标签:
-
英文(en):59,625 条(53.6%)
-
中文(zh):19,856 条(17.8%)
-
其他语言:31,827 条(28.6%)
这种多语言覆盖可用于构建跨语种检索样本、多语言文档分类语料和双语知识库。需要精确到具体小语种的任务,可以先检查或重新标注 other 类记录。
子集可独立使用:灵活的数据组织方式
CIMD 按来源家族组织,每个子集都可以单独加载:
# 只加载制度参考材料
dataset = load_dataset("opencsg/CIMD", "reference_governance", split="train")
# 只加载学术文献
dataset = load_dataset("opencsg/CIMD", "scholarly_literature", split="train")
# 合并多个子集构建完整语料
from datasets import concatenate_datasets
ref_data = load_dataset("opencsg/CIMD", "reference_governance", split="train")
scholar_data = load_dataset("opencsg/CIMD", "scholarly_literature", split="train")
full_data = concatenate_datasets([ref_data, scholar_data])
这个结构适合做分组实验、增量验证和权限分层。如果要发布标准 benchmark,需要另行构造查询、标注和评价集。
质量保障:公开版本经过发布前筛选
当前公开快照经过严格的发布前筛选:
-
过滤前记录条数:379,648
-
过滤排除记录条数:268,340
-
公开 JSONL 记录条数:111,308
-
去重 file_id 数:9,655
-
source_type 类别数:35
筛选范围包括元数据完整性、来源可追溯性、授权标记和解析质量。用户在训练、分发或商用前仍需结合具体来源核验授权范围。
数据资产盘点:完整的 Manifest
dataset_manifest.json 保留了公开快照的总体规模、子集规模、语言分布、格式分布和来源类型分布。使用者可以把它作为数据清单,也可以用来做后续版本对比、质量抽检和数据目录登记。
格式分布:
-
PDF:109,069 条(98.0%)
-
JSONL:704 条(0.6%)
-
DOCX:1,528 条(1.4%)
-
DOC:7 条(0.0%)
应用场景:从检索到 Agent 的全链路支撑
CIMD 的设计目标是直接可用于模型与应用。当前公开版本以统一 JSONL 记录格式发布,不是单纯的原始 PDF 堆积。解析后的记录可直接进入检索、切分、标注、训练、评测和服务流程。
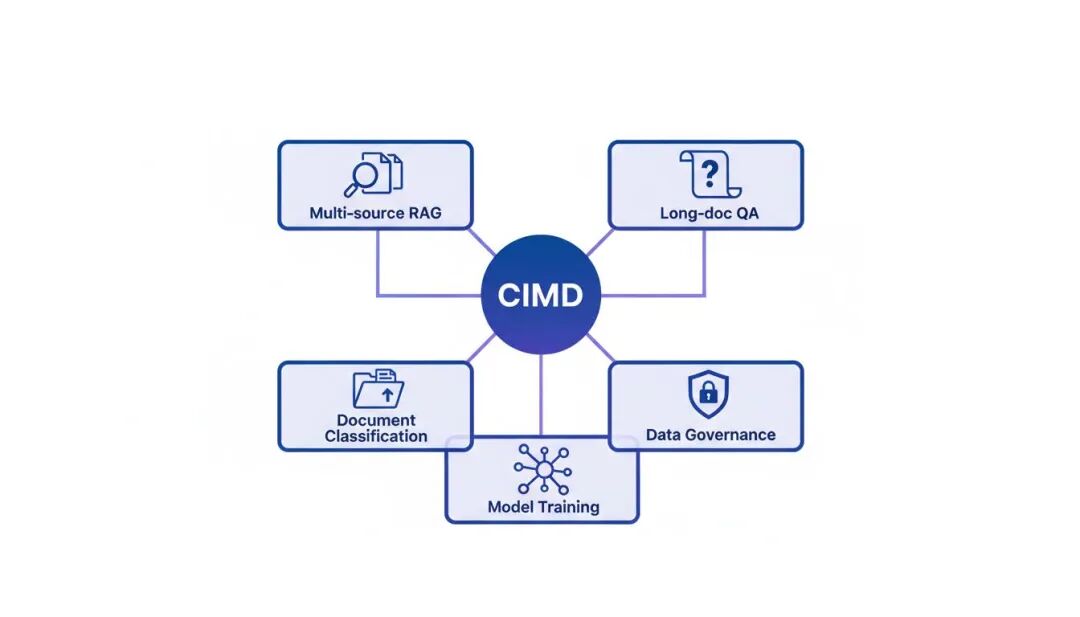
场景一:多来源文档检索与 RAG
以企业合规问答助手为例,当用户询问“最新的数据安全法规对我们的业务有什么影响”时,系统可以:
-
跨来源检索:同时在 reference_governance(法规政策)、scholarly_literature(学术研究)和 institutional_analysis(机构分析)中检索
-
时间过滤:通过 original_time 和 content_time 字段筛选最近 6 个月的材料
-
证据归因:在生成回答时,通过 source_type、author 和 source_details 字段标注每条证据的来源
-
可追溯性:通过 file_id 和 data_id 回溯到原始文档,支持审计和复核
统一的 JSONL 格式可以直接接入向量数据库,完整的元数据支持精确过滤和来源归因,跨来源结构天然适配多跳推理。
场景二:长文档问答与证据归因
在学术文献分析场景中,研究人员需要从大量论文中提取关键信息并追溯来源。CIMD 的长文档结构支持:
-
完整上下文:raw_chunk 保留足够长的文本块,保证语义完整性
-
文档级关联:通过 file_id 将同一文档的多个 chunk 关联起来
-
时间序列分析:通过 content_time 字段构建研究主题的时间演进图谱
-
跨语言检索:通过 language 字段支持中英文混合检索
场景三:文档分类与主题标注
在构建企业知识库时,需要对大量文档进行自动分类和主题标注。CIMD 提供:
-
来源类型标签:35 类 source_type 可以作为分类的先验知识
-
关键词辅助:keywords 字段提供主题标注的候选词
-
作者/机构信息:author 字段帮助识别权威来源
-
多语言支持:language 字段支持构建多语言分类模型
场景四:数据目录与授权审计
在企业数据治理场景中,需要对数据资产进行盘点和授权管理。CIMD 的元数据结构支持:
-
数据清单:通过 dataset_manifest.json 快速了解数据规模和分布
-
授权追踪:license_type 字段记录每条记录的授权类型
-
来源追溯:source_details 字段提供原始来源链接
-
版本管理:data_version 字段支持数据版本对比
场景五:继续训练语料筛选与评测集构建
在构建垂直领域大模型时,CIMD 可以作为:
-
预训练语料筛选:按 source_type 和 language 筛选高质量训练样本
-
SFT 数据构建:基于制度参考、学术文献等构建指令数据
-
评测集构建:按来源家族和时间分层抽样,构建多维度评测集
-
数据质量控制:通过元数据字段做质量抽检和异常检测
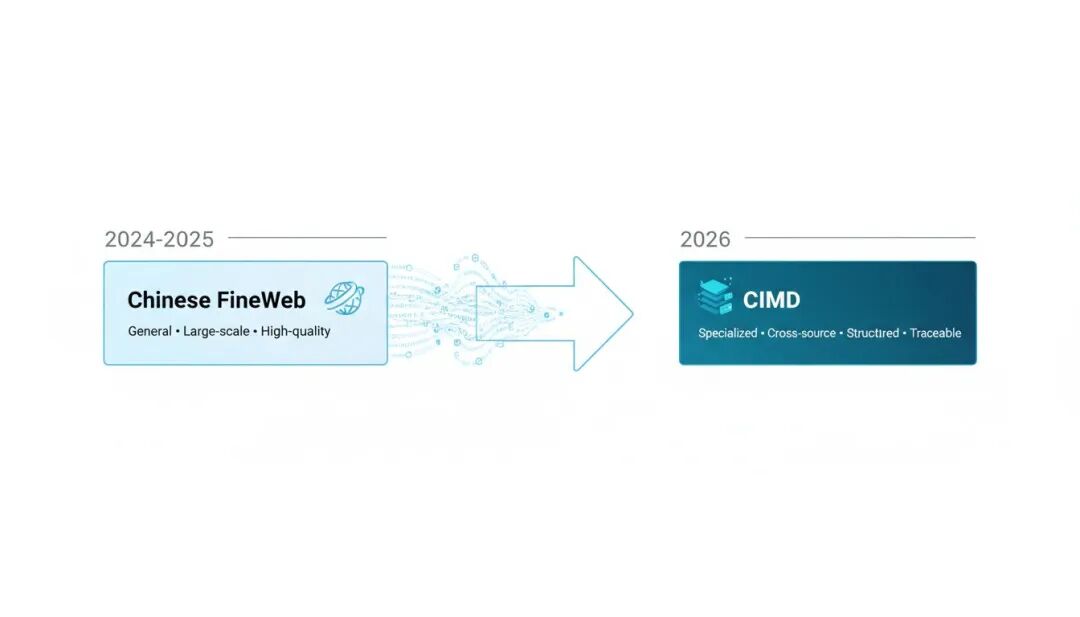
从 Chinese FineWeb 到 CIMD: OpenCSG 的数据战略演进
如果我们回顾 OpenCSG 的数据开源历程,会发现一条清晰的战略演进路径:
第一阶段:通用中文语料(Chinese FineWeb 系列)
这一阶段的目标是为中文大模型提供高质量预训练语料。Chinese FineWeb 被清华大学论文选为 L1 层基础数据,支撑了 CMU H-Net、MiniCPM4 等多个前沿模型,成为中文 AI 研发的必备资源。这一阶段的特点是通用、大规模、高质量。
第二阶段:垂直场景语料(CIMD)
这一阶段的目标是为文档智能任务提供专业数据底座。CIMD 实现了从通用走向垂直、从单一来源走向跨来源整合、从语料库走向知识体系、从研究数据集走向数据资产的创新。这一阶段的特点是专业、跨源、体系化、可信。
这种演进反映了 OpenCSG 对 AI 发展趋势的深刻洞察:通用大模型是基础,垂直场景 AI 是未来。
开源承诺:商业友好,推动文档智能化
CIMD 采用 OpenCSG 数据集许可协议(OpenCSG Dataset License Agreement)。在 Hugging Face 和 OpenCSG 平台的仓库 metadata 中,license 字段标注为 other,表示本数据集采用平台预设列表之外的自定义许可协议;数据集的实际许可条款以 OpenCSG 数据集许可协议为准。
该协议明确支持商业用途。使用者可以将数据集用于研究、评测、验证、内部开发、模型训练、模型微调、检索增强、质量分析和合规审查等场景。如果计划将本数据集、基于本数据集训练或增强的模型、系统、Agent、API 服务或商业产品用于商业场景,需要遵循该协议的相关条款,并发送邮件至 lorraineg@opencsg.com 获取商业许可。
重要说明:当前公开快照中的 license_type: 商业授权 是记录级授权来源标记,不替代仓库级许可协议。
这种开源策略体现了 OpenCSG 的核心理念:既要保护数据来源方的合法权益和知识产权,又要为文档智能发展提供必要的数据支撑。通过清晰的授权边界、完善的合规要求和灵活的商业许可机制,CIMD 为企业合规使用文档数据、构建垂直 AI 能力提供了可信路径。
数据获取与使用指南
通过 Git 获取(推荐)
git lfs install
git clone https://opencsg.com/datasets/OpenCSG/CIMD.git
cd CIMD
git lfs pull
7 个子集说明
1. reference_governance(制度参考)
-
记录数:90,197 条 | 文件数:6,919 个
-
内容:法规、政策、标准和合规参考材料
2. scholarly_literature(学术文献)
-
记录数:17,569 条 | 文件数:2,053 个
-
内容:学术出版物、长文档资料、学位论文和会议记录
3. enterprise_operations(企业运营)
-
记录数:1,744 条 | 文件数:64 个
-
内容:企业资料、运营信息、产能记录、融资材料和项目更新
4. public_discourse(公共讨论)
-
记录数:1,286 条 | 文件数:545 个
-
内容:公共讨论、媒体材料和观点记录
5. institutional_analysis(机构分析)
-
记录数:484 条 | 文件数:68 个
-
内容:研究机构、协会、咨询机构和金融机构分析材料
6. market_observations(市场观察)
-
记录数:20 条 | 文件数:2 个
-
内容:市场、交易和价格相关记录
7. miscellaneous_records(其他记录)
-
记录数:8 条 | 文件数:4 个
-
内容:未归入主要来源家族的记录
使用注意事项
-
计数单位:当前统计为解析记录数,不等同于去重后的原始文档数。单个源文件可以对应多条记录。
-
Git LFS:公开子集通过 Git LFS 管理,clone 后需执行
git lfs pull。 -
数据质量:不同来源之间可能存在重复、近重复或解析噪声。
-
时间字段:时间字段可能表示发布时间、内容时间或抽取时间,需结合具体记录判断。
-
授权核验:用于训练、分发或商用前,需结合来源信息核验实际授权范围。
展望:从文档智能到更多场景
CIMD 的发布只是 OpenCSG 垂直场景数据战略的第一步。从数据体系的设计来看,这套方法论具有很强的可复制性和可扩展性:
横向扩展:可以复制到更多垂直领域(金融、医疗、法律、教育等),构建领域专属的文档智能语料库。
纵向深化:可以在时间维度上持续更新构建时序数据集,在深度维度上增加更多细分来源和专题,在质量维度上引入更精细的质量分层。
能力升级:可以从单纯的文本语料扩展到多模态文档(包含图表、公式、表格的复杂文档),从静态快照升级到动态更新的知识库。
OpenCSG 正在探索的,是一条从通用 AI 到场景 AI、从语料库到知识体系、从研究数据集到数据资产的完整路径。
行业标杆地位的验证
OpenCSG发布的FineWeb-Edu-Chinese作为全球下载量排名前三的中文预训练数据集,累计下载超百万次,其价值已经得到业界广泛认可:
-
学术领域:被斯坦福大学、清华大学、中国人民大学高瓴人工智能学院、上海人工智能实验室、北京智源研究院等 20 余家顶尖机构的论文引用。旗下 Chinese Fineweb Edu 已成为中文 NLP 研究的核心数据资源,被 100 + 篇学术论文引用,在 NeurIPS、ACL、EMNLP、ICLR 等国际顶会及 Nature 子刊、JMLR 等权威期刊中作为核心实验数据集,支撑大模型预训练、指令微调等前沿研究,合作机构还包括鹏城实验室、西南电子技术研究所、西班牙国家级超算中心(Barcelona Supercomputing Center)及 Mozilla Data Collective 等全球顶尖科研单位。
-
产业应用:支撑 Llama3-Chinese、DeepSeek 等知名模型训练,并被中国移动、中国联通、英伟达(NVIDIA)、苹果公司(Apple Inc.)、OPPO、美团、阿里巴巴、蚂蚁集团、面壁智能(ModelBest)、Krafton等领军企业采用。Chinese Fineweb Edu 已从实验室走向产业场景,为创业公司到头部企业的研发团队提供可靠支撑,切实推动中文 NLP 应用从理论落地到生产实践。
-
生态影响:下载数量累计超百万次,数据体量达 2.42TB,覆盖 9.57 亿条高质量文本,已孵化出 10 余个垂直领域微调模型。同时,OpenCSG 通过开源打分模型和完整工具链,输出数据治理方法论,带动行业从 “模型参数内卷” 转向 “数据基建完善”,显著降低中小开发者与研究机构的入门门槛。
-
开源生态:OpenCSG 坚持“开源即文化”的理念,通过透明、共创、共享的社区文化,与全球开发者、工程师和 AI 原生企业共同构建智能体生态。
结语:文档智能的基础设施,从数据开始
当我们谈论 AI 在企业中的落地时,往往聚焦于模型架构、算法优化、算力投入,却容易忽视一个更基础的问题:文档智能需要什么样的数据?
CIMD 给出了一个清晰的答案:文档智能需要的不是简单的网页爬虫数据,而是跨来源整合的专业语料;不是只有正文的纯文本,而是带有完整元数据的数据资产;不是混乱的文件堆积,而是统一格式、可追溯、可审计的记录体系;不是封闭的研究数据集,而是商业友好的开源资源。
OpenCSG 通过 CIMD 的开源,正在做一件具有战略意义的事情:为文档智能构建数据基础设施。
这不是终点,而是起点。当越来越多的垂直场景拥有像 CIMD 这样的高质量数据集,当数据的组织方式从“文件堆积”升级为“知识体系”,当数据资产的流通从“封闭私有”转向“可信开放”,我们才能真正实现 AI 技术从实验室到产业的跨越。
CIMD 的开源,是文档智能从“能读懂文字”到“真正理解文档”的关键一步。
了解更多:访问 OpenCSG 官网 https://opencsg.com 或关注 OpenCSG 开源社区
商业授权咨询:lorraineg@opencsg.com
引用格式:
@dataset{opencsg_cimd_2026,
title = {CIMD: A Cross-Source Multilingual Document Corpus},
author = {OpenCSG},
year = {2026},
url = {https://opencsg.com/datasets/OpenCSG/CIMD},
note = {OpenCSG dataset repository}
}
社区地址
OpenCSG社区:https://opencsg.com/datasets/OpenCSG/CIMD
hf社区:https://huggingface.co/datasets/opencsg/CIMD
魔搭社区:https://modelscope.cn/datasets/opencsg/CIMD
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)