当 AI 开始真正走进 EDA 后端:它不只是会写脚本,而是在学着理解物理实现
导语
最近,人工智能和芯片设计结合得越来越紧。写代码、补测试、生成脚本,这些方向大家已经看得很多了。但如果把视角往后移,放到芯片实现流程里,就会发现真正难啃的地方其实还在后端。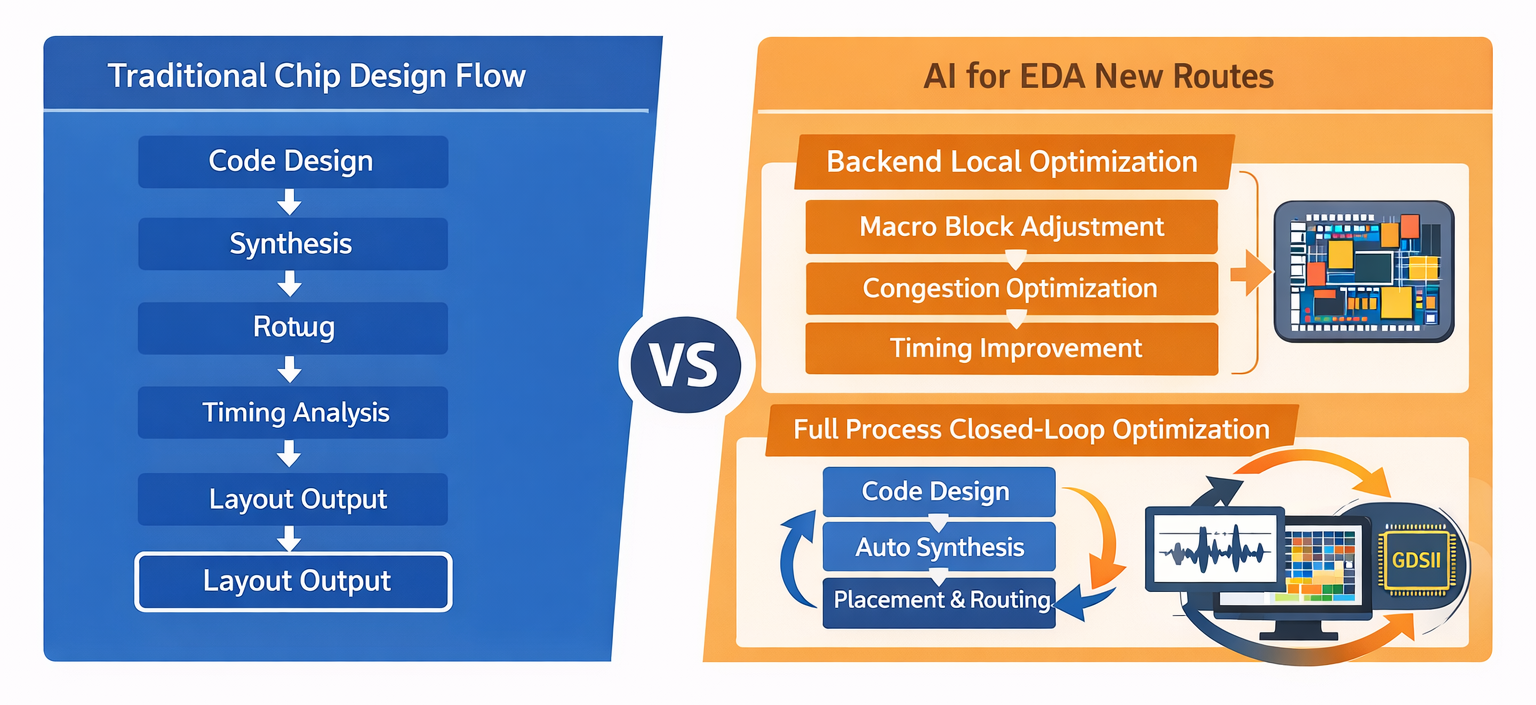
图1 传统与AI for EDA的对比
这里说的后端,不只是某一个工具,也不只是布局布线四个字,而是一整套会直接影响芯片最终质量的流程。模块怎么摆,线路怎么走,时序能不能收住,面积会不会继续膨胀,最后有没有大量违规点,这些都决定了一个设计能不能真正落地。
这篇文章想讲两篇最近很有代表性的论文。
第一篇是 《Reinforcement Learning Policy as Macro Regulator Rather than Macro Placer》。这篇论文关注的是后端里一个非常核心的问题,也就是大模块布局。它的关键想法是,不要让强化学习从零开始摆放大模块,而是让它在已有布局基础上做进一步调整。
第二篇是 《MCP4EDA: LLM-Powered Model Context Protocol RTL-to-GDSII Automation with Backend Aware Synthesis Optimization》。这篇论文关注的是更长的一条链路,也就是从代码到版图的自动化设计流程。它的关键想法是,把综合、仿真、布局布线和结果分析串成一个闭环,让大模型根据后端真实结果,继续反过来优化前面的综合过程。
一篇聚焦后端中的单点难题,一篇聚焦从前到后的整条流程。看起来方向不同,但其实都在回答同一个问题:人工智能怎样才能真正进入芯片后端,而不只是停留在表面辅助。
正文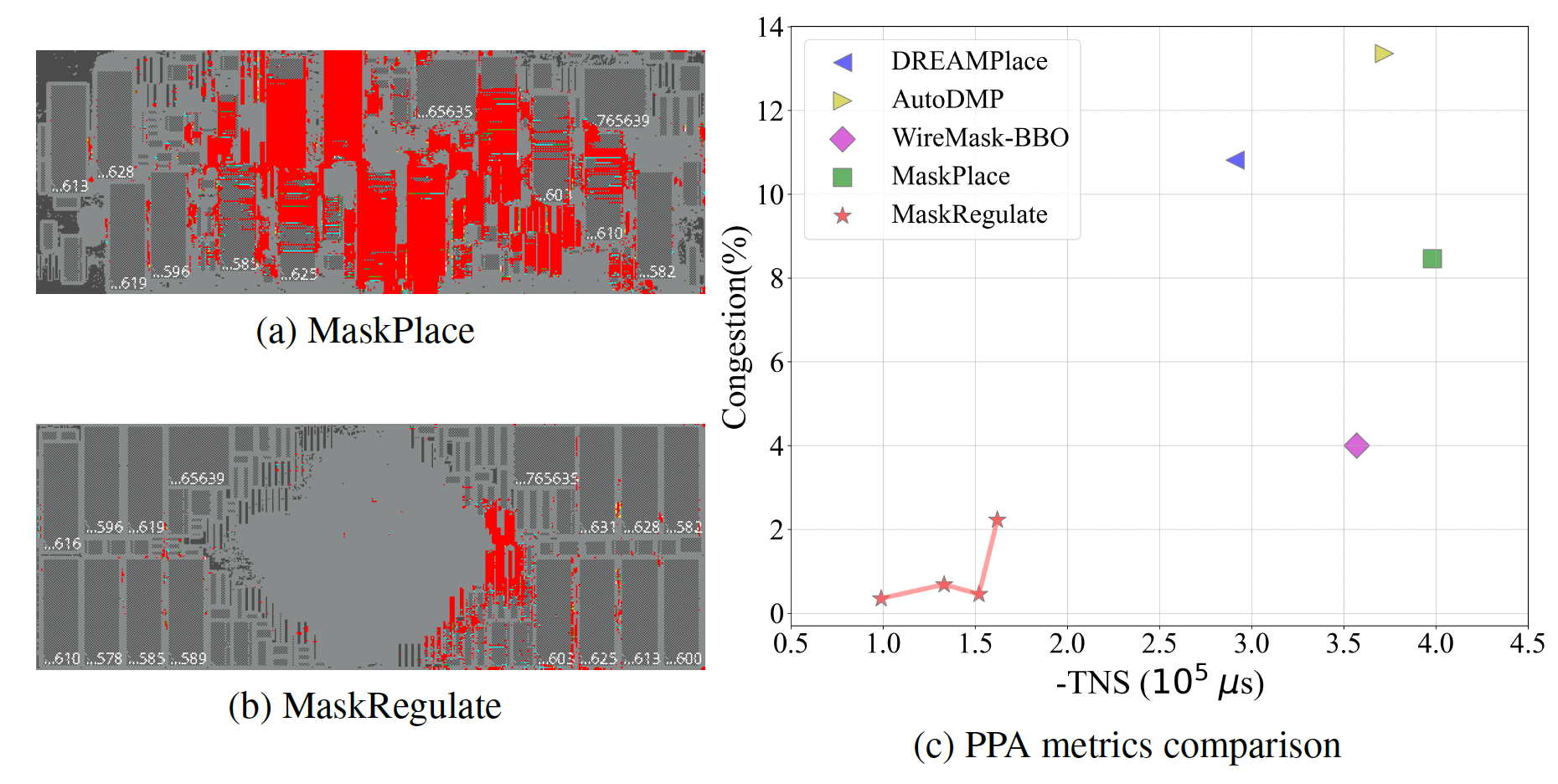
图2 a)原方法的布局与拥塞图;b)改进方法的布局与拥塞图;c)关键指标对比图
先说第一篇,《Reinforcement Learning Policy as Macro Regulator Rather than Macro Placer》。光看题目就能看出,这篇论文最想强调的是一个身份转变。
过去很多用强化学习做芯片布局的工作,默认思路都是让算法从空白画布开始,一个一个去摆放大模块。也就是说,算法既负责开局,也负责全过程。可这篇论文认为,问题恰恰可能就出在这里。
因为从零开始摆放时,前期信息太少。算法一开始几乎看不到完整局面,也拿不到足够准确的反馈。它只能根据很有限的中间状态去猜,最后这种训练方式往往会带来几个问题:训练时间长,学到的策略不够稳定,换一个设计之后泛化能力也不强。论文里明确指出,现有强化学习布局方法存在训练时间长、泛化能力弱、难以保证最终功耗性能面积结果改善等问题,而其中一个重要原因,就是问题定义本身不够合理。
所以作者换了一个思路。他们不再让强化学习扮演“从头摆放者”,而是让它扮演“布局调节者”。也就是说,先有一个初始布局结果,再由强化学习去做局部修正和进一步优化。论文把这个角色叫作 regulator,而不是 placer。这个区分非常重要,因为它意味着算法不再负责从零造一个结果,而是负责把已有结果调得更好。
从读者视角理解,这件事其实不难。你可以把它想象成整理房间。如果让一个人面对空房间,从零规划所有家具摆放,难度非常大,因为他还不知道哪些地方会拥挤、哪些动线会不顺、哪些区域会显得压抑。但如果房间里已经有了一个初步布置,再让他根据实际使用体验去调整沙发、桌子和柜子的位置,事情就会容易很多,也更接近真实生活中的优化过程。
芯片大模块布局也是类似的道理。已有布局一旦存在,算法就能看见更多真实信息。哪些区域已经过于密集,哪些模块形成了堵塞,哪些位置虽然看起来连线不长,但会给后续布线和时序带来麻烦。相比从零开始,这种调整式优化能得到更完整的状态信息,也更容易拿到更准确的反馈。
这篇论文还有一个很重要的点,就是它没有只盯着“线长”这一个指标。
很多布局研究会把总线长当成判断好坏的核心标准,因为线短通常意味着更紧凑、更省资源。但现实中的后端设计远比这复杂。一个线长不算差的布局,可能依旧会把大模块堆在一起,导致局部区域非常拥堵,也可能破坏版图的整体规整性,让后面标准单元难放、线路难走、时序难收。
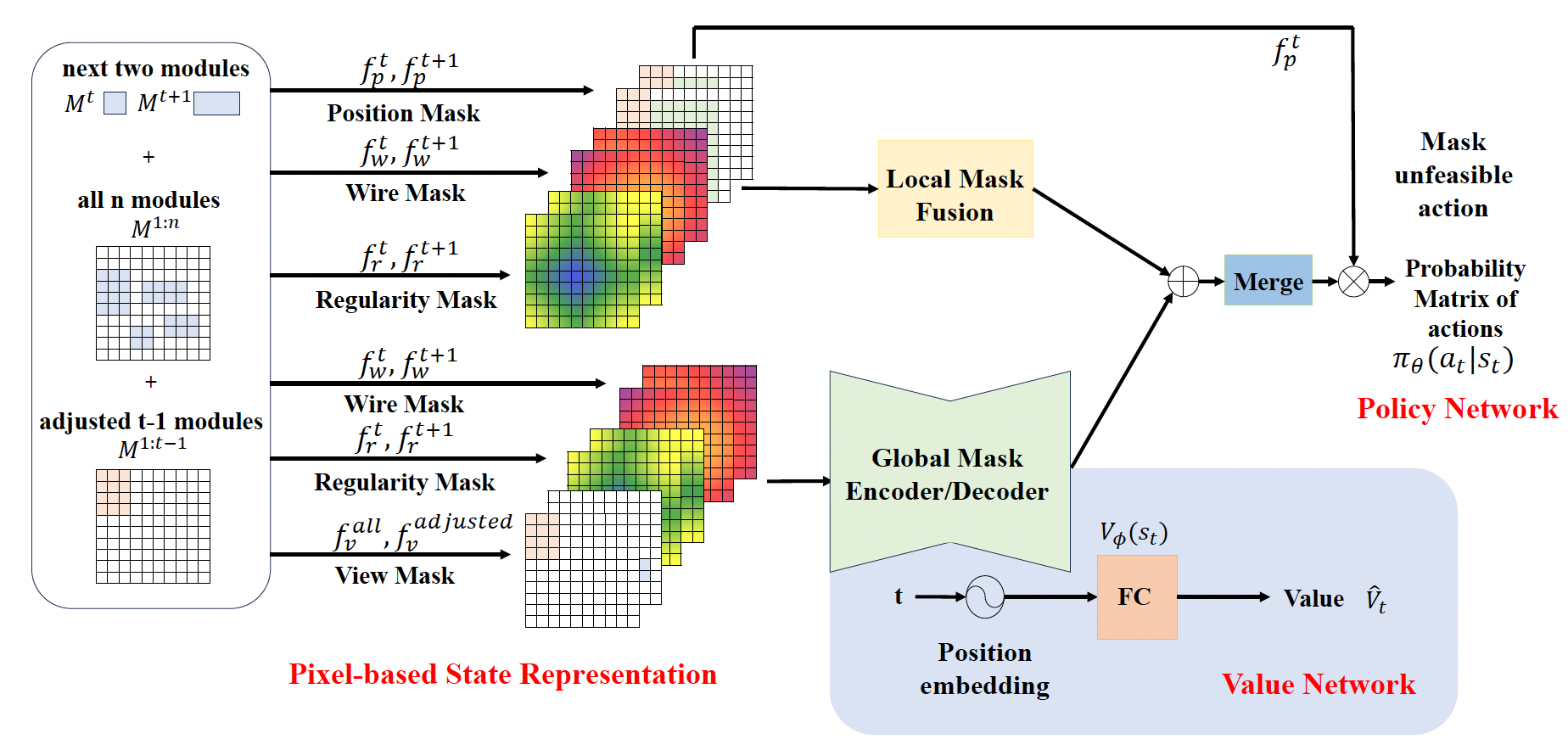
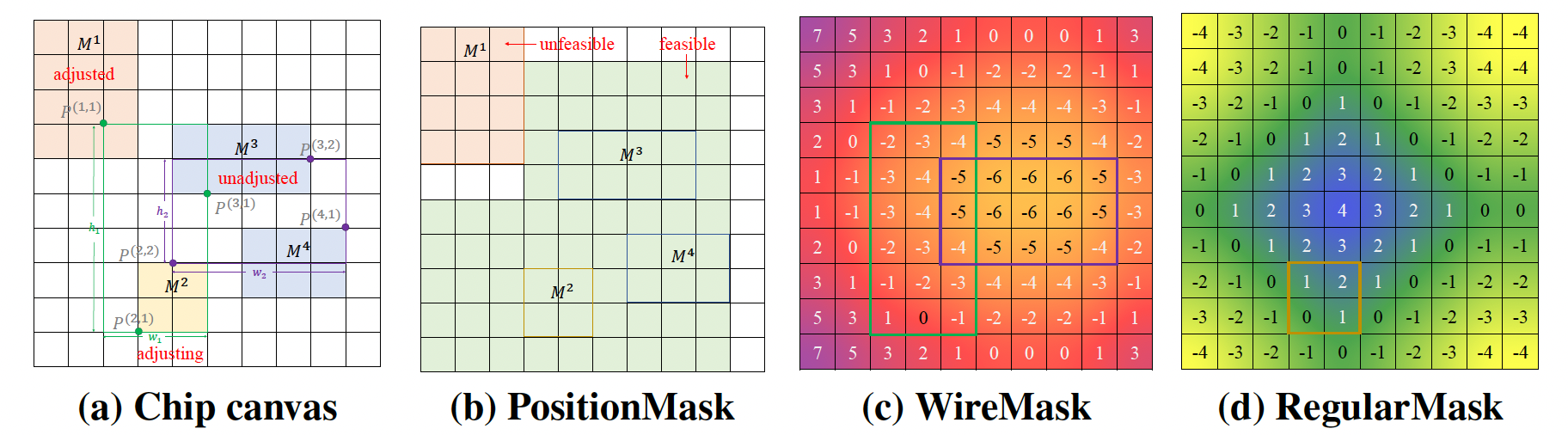
图3 方法框架图及布局位置信息处理策略
所以这篇论文特别引入了一个概念,叫作布局规整性。简单理解,就是布局不能只追求把模块塞进去,还要看它是不是分布合理,是不是留出了更均衡的后续实现空间。论文认为,这是工业界很重视、但很多强化学习布局工作没有充分考虑的因素。更重要的是,它不是把这个因素放到最后评估,而是直接纳入训练过程,让算法在优化时就开始兼顾这个目标。
这件事为什么值得强调?
因为它说明作者并不是在做一个只会追求单一数字变好的算法,而是在努力让方法更接近真实后端设计的判断标准。后端设计从来都不是把某一个指标拉到最好就算成功,而是在多个目标之间找平衡。布局规整、布线拥堵、时序表现、违规情况,这些往往是一起发生作用的。
它不是只看中间过程里的代理指标,而是用商业后端工具去看最终结果。论文在 ICCAD 2015 基准上做了评估,并使用商业设计工具进一步验证后端表现。结果显示,在 superblue1 这个测试电路上,相比已有的强化学习布局方法,新的方法在布线线长、横向和纵向拥堵、最差负时序裕量、总负时序裕量以及违规点数量等指标上都有明显改善。其中,横向拥堵改善超过七成,总负时序裕量改善接近四成,违规点数量减少接近一半。

图4 布局优化效果
这组结果的意义不只是数字好看。真正重要的是,它说明这种“先有初始布局,再由强化学习做细调”的思路,确实更容易把优化效果落到后端真正关心的指标上,而不只是停留在线长这种单一代理指标上。对于实际工程来说,这类方法也更容易接入已有流程,因为它不是要求设计团队把原有方法全部推翻,而是可以作为现有布局流程后的增强步骤来使用。
再看第二篇,《MCP4EDA: LLM-Powered Model Context Protocol RTL-to-GDSII Automation with Backend Aware Synthesis Optimization》。
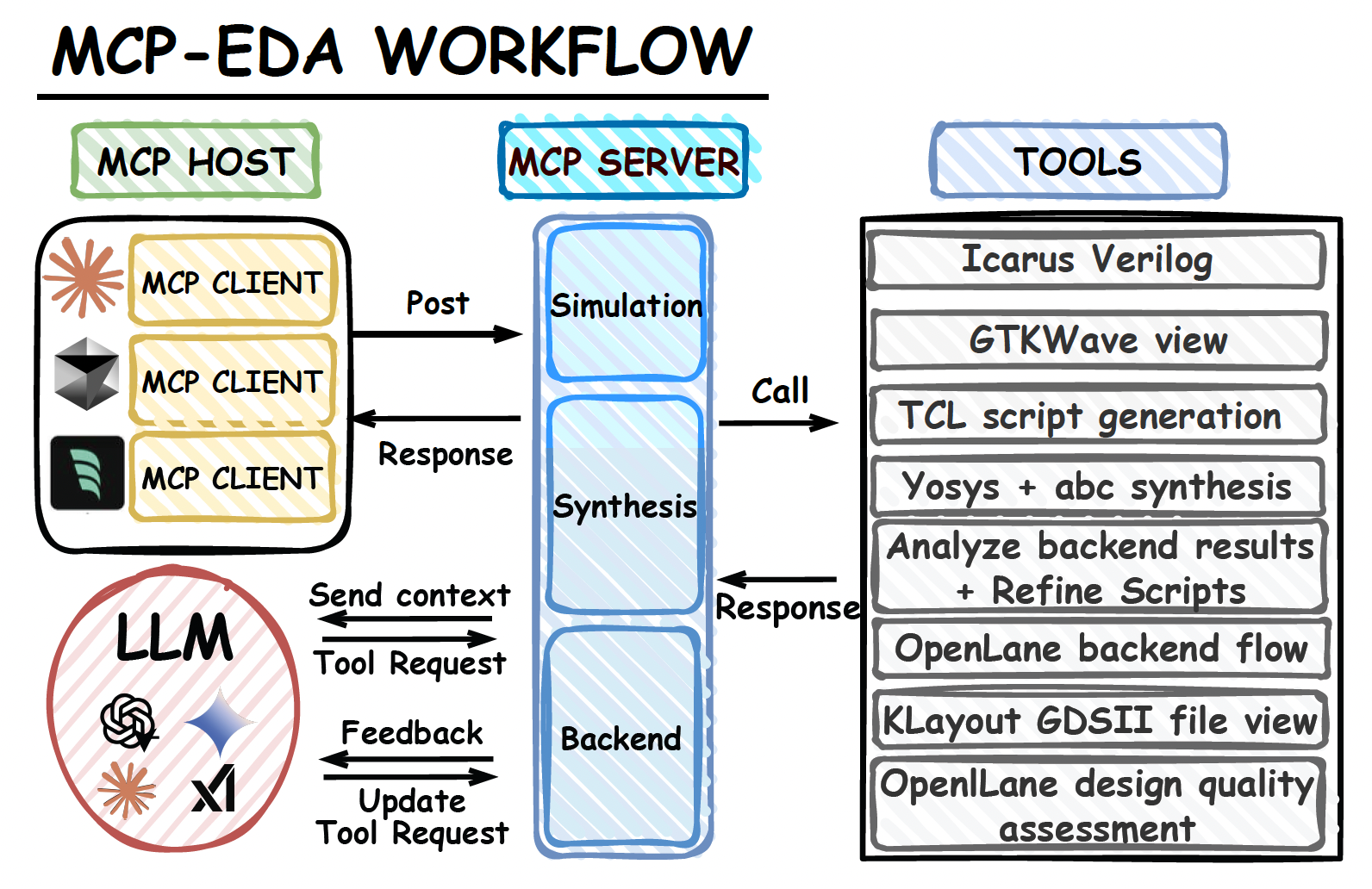
图5 MCP-EDA架构
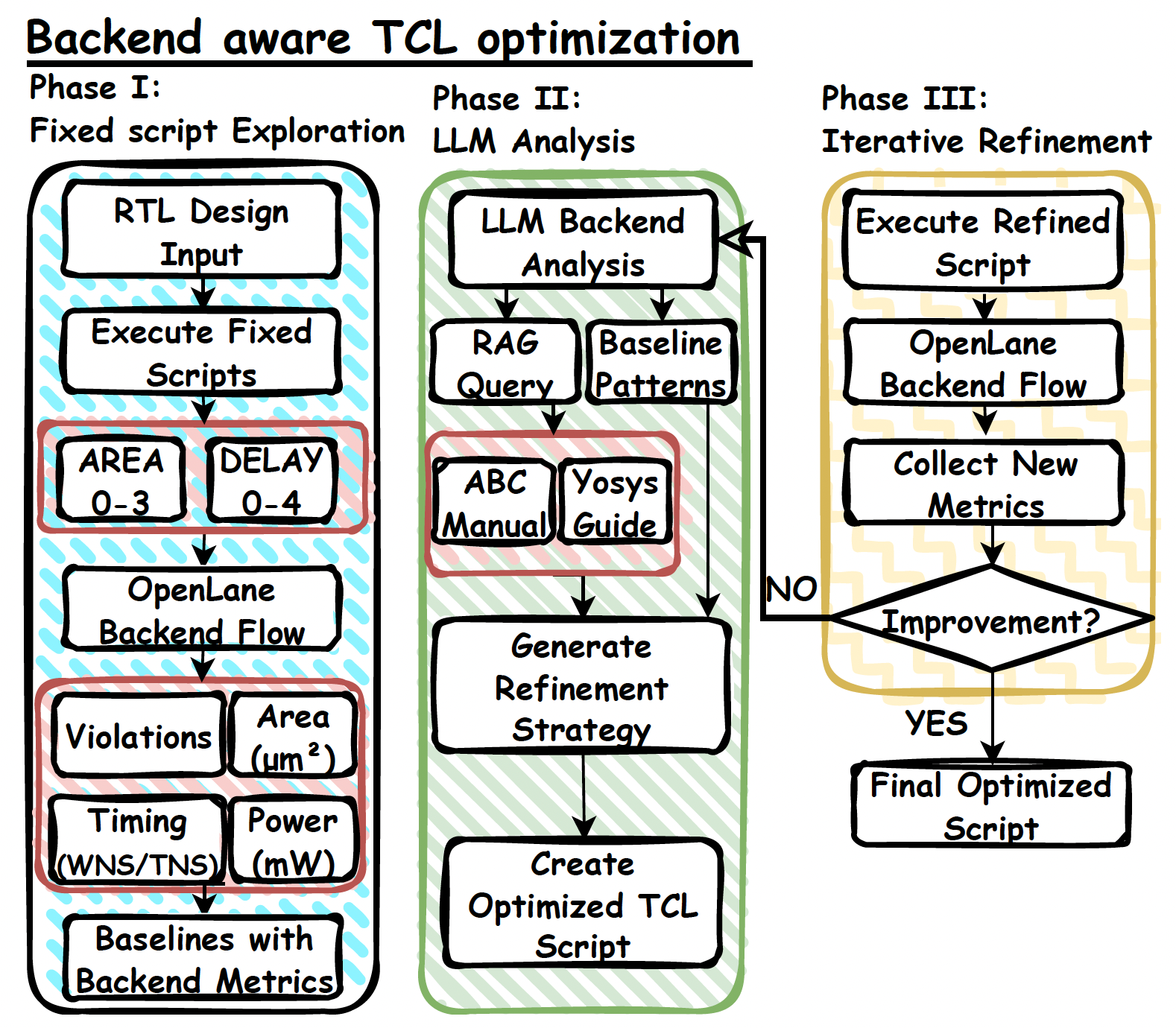
图6 后端感知的TCL优化
如果说第一篇是在解决后端中的一个关键局部问题,那么第二篇面对的是更大的问题:从代码到版图这条流程,能不能让大模型真正参与进来,而且不是只写脚本,而是能根据后端结果不断修正前面的决策。
这篇论文的出发点很现实。今天很多所谓“大模型做芯片设计”的展示,停留在生成代码、补测试平台、写综合脚本这些层面。这些都能帮忙,但距离真正的后端自动化还有一段距离。因为真正的设计流程不是写完一段脚本就结束,而是要看这段脚本最后带来了什么结果。综合之后时序如何,布局布线之后面积怎样,有没有新的瓶颈,这些才是工程师真正关心的事情。
而传统流程恰恰容易在这里断开。综合阶段通常依赖比较粗略的估计来做判断,可真正到了布局布线之后,物理实现带来的影响才会完整暴露出来。也就是说,前面看起来合理的选择,后面不一定真的有效。论文里专门指出,传统综合优化往往依赖较粗略的延迟估计,而这些估计和后端真实结果之间存在明显偏差,特别是在更复杂的设计条件下,这种差距会更加明显。

图7 三阶段LLM闭环流程
MCP4EDA 想做的,就是把这段断开的反馈重新接起来。论文把综合工具、仿真工具、布局布线工具、波形查看工具和版图查看工具统一到一个接口框架中,让大模型不仅能调用这些工具,还能连续地保留设计上下文。更关键的是,它提出一种面向后端真实结果的综合优化方式。简单说,就是先跑出后端结果,再把真实的时序、面积、功耗等信息拿回来,作为下一轮修改综合脚本和优化流程的依据。
从读者角度理解,可以把它想成一个会复盘的工程助手。它不是帮你写完一段脚本就退出,而是会继续看结果。发现时序没收住,它会回去调整综合策略。发现面积过大,它会尝试新的优化顺序。发现后端结果和预期不符,它会根据已有上下文再做一轮修正。论文希望实现的,其实就是这样一种带反馈、会迭代的自动化流程。
这篇论文的另一个特点,是它强调“动态调用工具”,而不是走固定模板流程。传统自动化流程很多时候是一条预设好的路径,按顺序把工具跑完。可真实工程往往不是这样。工程师会根据中间结果决定下一步做什么,是先回头改脚本,还是继续跑后端,是看波形,还是看版图。论文认为,大模型的价值不只是生成命令,而是在于可以基于当前结果决定下一步动作,从而让整个设计流程更有弹性。
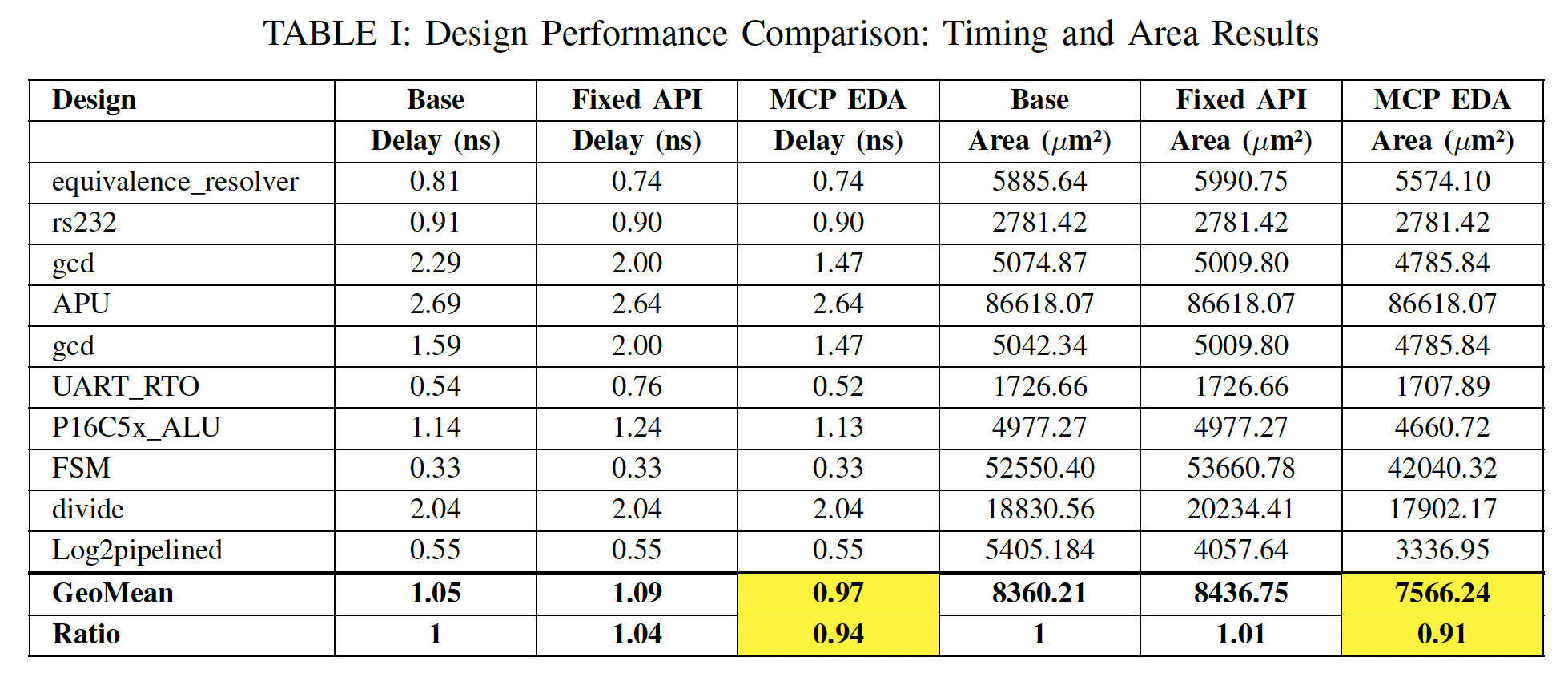
图8 优化结果面积对比
论文在一组开源数字设计上进行测试,给出的结果是,相比默认综合流程,这种带后端反馈的优化方式在关键路径和面积上都有一定改善。摘要中给出的范围是,时序收敛改善大约百分之十五到百分之三十,面积下降大约百分之十到百分之二十;在更详细的实验总结中,作者也给出了更保守的整体统计,说明不同设计上的提升幅度会有波动,但总体趋势是正向的。
当然,这篇论文也没有把事情说得太轻松。它明确提到,目前验证的主要还是中小规模开源设计,而且每一轮优化都需要重新跑综合和后端流程,所以会带来额外时间开销。通常一个设计需要三到五轮迭代才能逐步收敛,小设计每轮大约一分钟,大一些的设计每轮大约三分钟,大模型本身的推理还会进一步增加总时间。也就是说,这不是一个“立刻让流程飞起来”的工具,而是一个用更多计算和更好的反馈,换取更优结果的系统。
这两篇论文为什么值得放在一起讲
到这里,读者可能会问,这两篇论文一个讲大模块布局,一个讲整条自动化流程,为什么要放在一起?
原因就在于,它们虽然切入点不同,但都代表了人工智能进入芯片后端的两条重要路线。
第一条路线,是先解决后端中的关键局部问题。第一篇论文就是典型例子。它没有贪心到想让强化学习一口气接管全部布局,而是找到一个更合理、更接近工程实际的位置,让算法去做已有布局上的细调。这样的方法更现实,也更容易在真实流程中落地。
第二条路线,是打通整条流程中的反馈闭环。第二篇论文代表的就是这个方向。它不是只让大模型参与前端生成,而是努力把它放到一个连续、可迭代、可复盘的流程中,让它能够看到后端真实结果,并继续影响前面的优化决策。
从工程现实来看,这两篇论文最大的价值是什么
如果只看表面,这两篇论文一个像是在做算法改进,一个像是在做系统整合。但从工程角度看,它们最有价值的地方其实很一致,那就是都没有脱离后端设计的真实规律。
第一篇论文没有把强化学习放到最理想化的位置,而是承认从零开始做布局太难、信息太少、反馈太弱,于是把它放到已有结果的优化阶段。第二篇论文也没有把大模型当作一个会写脚本的展示工具,而是承认前后端之间存在信息断层,于是努力用真实后端结果把综合和实现重新连起来。
人工智能进入芯片后端,不一定是一下子替代工程师,也不一定是一上来就接管整条流程。更现实的方向,可能是先在最痛、最关键、最有反馈价值的地方嵌进去,然后一步一步往更深处走。能不能改善拥堵,能不能减轻时序压力,能不能减少违规点,能不能让综合和后端之间少走几轮弯路,这些问题比“模型用了什么名字”更重要。
论文引用:[1] K. Xue et al., “Reinforcement Learning Policy as Macro Regulator Rather than Macro Placer,” Dec. 10, 2024, arXiv: arXiv:2412.07167. doi: 10.48550/arXiv.2412.07167.
[2] Y. Wang, W. Ye, Y. He, Y. Chen, G. Qu, and A. Li, “MCP4EDA: LLM-Powered Model Context Protocol RTL-to-GDSII Automation with Backend Aware Synthesis Optimization,” Jul. 25, 2025, arXiv: arXiv:2507.19570. doi: 10.48550/arXiv.2507.19570.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)