基于MLP神经网络的红酒品质回归预测
基于MLP神经网络的红酒品质回归预测
1.作者介绍
陈金顺,男,西安工程大学电子信息学院,2025级研究生
研究方向:情绪识别
电子邮件:1732179164@qq.com
胥乾信,西安工程大学电子信息学院,2025级研究生 张宏伟人工智能课题组
研究方向:机器视觉与人工智能
联系邮箱:2692797728@qq.com
2.MLP网络介绍
2.1 MLP神经网络概述
MLP(Multi-Layer Perceptron,多层感知机)是一种典型的前馈神经网络,由输入层、隐藏层和输出层构成。相邻层之间通常采用全连接方式传递信息,每一层先进行线性变换,再经过非线性激活函数,从而能够逼近复杂的非线性映射关系。
在回归任务中,MLP的目标是学习输入特征与连续数值标签之间的映射关系。本实验以红酒的11个理化指标作为输入,以品质评分作为输出,网络结构可设置为11->64->32->1,从而完成红酒品质分数预测。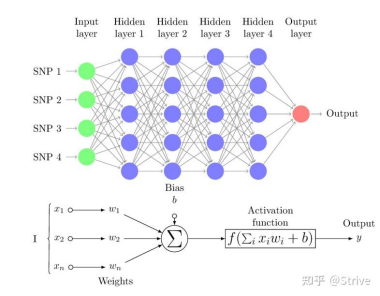
图 1 MLP神经网络结构示意图
2.2 前向传播与反向传播机制
前向传播阶段,第层的输出可写为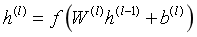
其中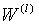 表示第
表示第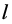 层权重矩阵,
层权重矩阵,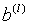 表示偏置项,
表示偏置项,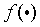 表示激活函数。输出层用于回归预测,通常不使用分类激活函数,最终输出为:
表示激活函数。输出层用于回归预测,通常不使用分类激活函数,最终输出为: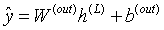
其中,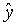 表示模型预测的红酒品质分数。
表示模型预测的红酒品质分数。
反向传播阶段,模型根据损失函数计算预测值与真实值之间的误差,并利用链式法则逐层求出各层参数的梯度,再由优化器按学习率对权重和偏置进行更新。本实验采用MSELoss作为损失函数,采用Adam优化器完成参数更新,并结合ReLU激活函数和Dropout抑制过拟合。
3.Wine Quality 数据集与实验环境
3.1 数据集介绍
本实验使用的Wine Quality数据集是UCI机器学习库中的经典多变量数据集,2009 年由葡萄牙波尔图大学团队发布,包含红、白葡萄酒样本,用于通过理化指标预测葡萄酒质量。其中红葡萄酒子集winequality-red.csv共1599条样本记录。每条样本包含11个理化指标和1个品质标签 quality,品质分数范围为0到10。下载地址:UCI Machine Learning Repository
11个输入特征分别如表1所示,这些指标能够从酸度、含盐量、密度、酒精含量等角度刻画红酒理化性质,为品质回归建模提供依据。
表1 11个输入特征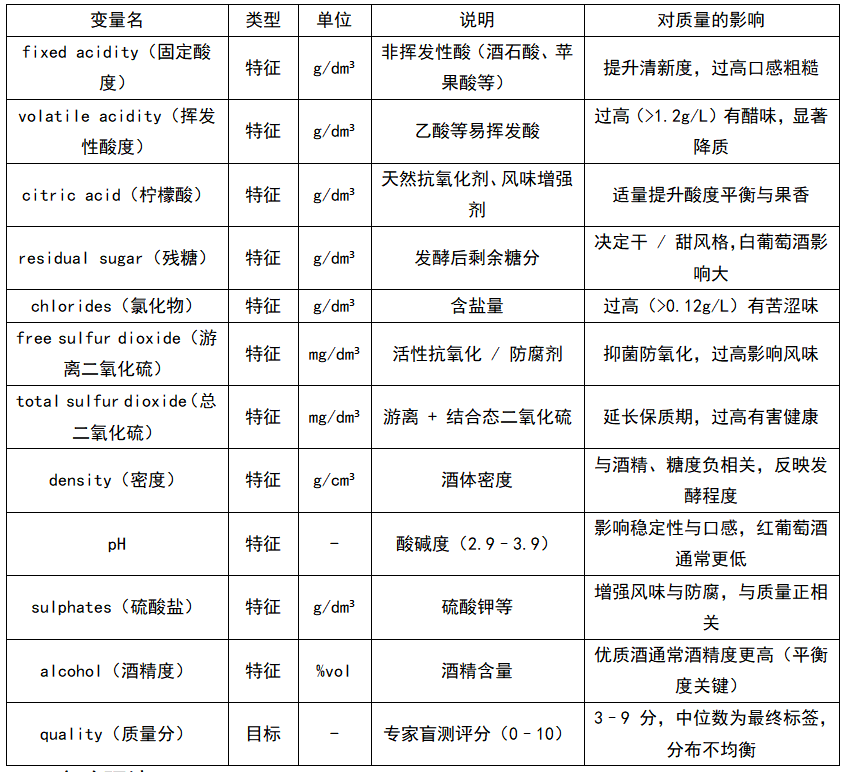
3.2 实验环境
实验准备阶段需要安装的主要软件包包括 pandas、numpy、scikit-learn 和 PyTorch。其中 pandas 用于数据读取与整理,numpy 用于数值运算,scikit-learn 用于数据划分、标准化与评价指标计算,PyTorch 用于搭建并训练 MLP 神经网络模型。
数据预处理时,先将quality列作为预测目标,其余11个字段作为输入特征,再按8:2划分训练集与测试集,并使用 StandardScaler 对特征进行标准化处理,以减小不同量纲对模型训练过程的影响。
3.3 实验流程与核心代码
实验整体流程包括数据读取、特征标准化、模型构建、损失函数与优化器设置、批量训练以及测试集评估六个步骤。
数据读取与标准化核心代码如下:
3.3.1数据读取
# 读取红酒数据集,并将 quality 作为回归目标
df = pd.read_csv(DATA_FILE, sep=";")
x = df.drop("quality", axis=1).values.astype(np.float32)
y = df["quality"].values.astype(np.float32).reshape(-1, 1)
# 划分训练集和测试集,并对特征做标准化
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=SEED
)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train).astype(np.float32)
x_test = scaler.transform(x_test).astype(np.float32)
3.3.2 MLP 神经网络模型
MLP 模型定义核心代码如下:
# 定义 11 -> 64 -> 32 -> 1 的 MLP 回归模型
class MLPRegressor(nn.Module):
def __init__(self, input_dim: int) -> None:
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64), # 输入层 → 第一层隐藏层(64个神经元)
nn.ReLU(), # 激活函数
nn.Dropout(0.2), # 随机失活,防止过拟合
nn.Linear(64, 32), # 第一层 → 第二层隐藏层(32神经元)
nn.ReLU(),
nn.Linear(32, 1), # 输出层 → 预测1个值(质量分数)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)3.3.3 模型训练与性能评估
模型训练与性能评估核心代码如下:
# 设置损失函数与优化器,并在训练循环中完成反向传播
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-4)
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
pred = model(batch_x)
loss = criterion(pred, batch_y)
loss.backward()
optimizer.step()
# 在测试集上计算 MAE、RMSE 和 R^2
test_loss, y_true, y_pred = evaluate(model, test_loader, criterion, device)
mae = mean_absolute_error(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
r2 = r2_score(y_true, y_pred)
训练过程中还可以从训练集中进一步划分验证集,并保存验证集表现最优的模型参数,以提高模型泛化能力并避免训练后期出现过拟合。
3.4 测试结果与问题分析
图 2 实验结果示意图
模型在测试集上的结果如图2所示,MAE = 0.4845,RMSE = 0.6153,R^2 = 0.4206。MAE 表明模型平均预测误差约为 0.48 分,整体预测较为稳定;RMSE 略高于 MAE,说明仍存在少量偏差较大的样本;R^2 达到 0.4206,说明模型能够解释约 42.06% 的品质波动,在课程实验场景下具有较好的参考价值。
从实验表现来看,MLP 能够有效学习红酒理化特征与品质评分之间的非线性关系,但受限于数据规模、品质标签的主观性以及网络超参数设置,模型仍有进一步优化空间。后续可通过调整隐藏层规模、训练轮数、学习率、批大小,或引入交叉验证等方式继续提升泛化能力。
实验过程中出现过“数据读取失败”的问题,其原因在于模型输入要求是数值型特征矩阵,但程序读取到的是由错误分隔符拼接成的一整行字符串,导致后续类型转换失败。对应的解决方法包括统一数据集格式,并在读取逻辑中兼容分号和逗号分隔符,从而提升程序的鲁棒性。
4.参考链接
[1] UCI Machine Learning Repository: Wine Quality Data Set. https://archive.ics.uci.edu/
[2] P. Cortez, A. Cerdeira, F. Almeida, T. Matos, J. Reis. Modeling wine preferences by data mining from physicochemical properties.
[3] PyTorch Documentation. https://pytorch.org/docs/stable/
[4] scikit-learn Documentation. https://scikit-learn.org/stable/
附录:
import copy
import json
from pathlib import Path
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import DataLoader, TensorDataset
SEED = 42
DATA_FILE = Path("winequality-red.csv")
OUTPUT_DIR = Path("mlp_wine_ppt_materials") / "outputs"
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
##为了保证实验结果具有可复现性,需要固定 NumPy 和 PyTorch 的随机种子。
def set_seed(seed: int = SEED) -> None:
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
##本项目使用两层隐藏层的 MLP 网络,隐藏层神经元数量分别为 64 和 32,并加入 Dropout 降低过拟合风险。
class MLPRegressor(nn.Module):
def __init__(self, input_dim: int) -> None:
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
##该函数读取红酒数据集,将除 quality 以外的 11 个字段作为输入特征,将 quality 作为回归预测目标。
def load_data() -> tuple[np.ndarray, np.ndarray, list[str]]:
df = pd.read_csv(DATA_FILE, sep=";")
feature_names = [col for col in df.columns if col != "quality"]
x = df[feature_names].values.astype(np.float32)
y = df["quality"].values.astype(np.float32).reshape(-1, 1)
return x, y, feature_names
##数据集被划分为训练集、验证集和测试集,并使用 StandardScaler 对输入特征进行标准化处理,使模型训练更加稳定。
def build_loaders(
x: np.ndarray, y: np.ndarray, batch_size: int = 32
) -> tuple[DataLoader, DataLoader, DataLoader, StandardScaler]:
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=SEED
)
x_train, x_val, y_train, y_val = train_test_split(
x_train, y_train, test_size=0.2, random_state=SEED
)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train).astype(np.float32)
x_val = scaler.transform(x_val).astype(np.float32)
x_test = scaler.transform(x_test).astype(np.float32)
train_loader = DataLoader(
TensorDataset(torch.tensor(x_train), torch.tensor(y_train)),
batch_size=batch_size,
shuffle=True,
)
val_loader = DataLoader(
TensorDataset(torch.tensor(x_val), torch.tensor(y_val)),
batch_size=batch_size,
shuffle=False,
)
test_loader = DataLoader(
TensorDataset(torch.tensor(x_test), torch.tensor(y_test)),
batch_size=batch_size,
shuffle=False,
)
return train_loader, val_loader, test_loader, scaler
##该函数用于计算模型在验证集或测试集上的平均损失,并返回真实值和预测值,方便后续计算 MAE、RMSE 和 R² 等指标。
def evaluate(
model: nn.Module, loader: DataLoader, criterion: nn.Module, device: torch.device
) -> tuple[float, np.ndarray, np.ndarray]:
model.eval()
total_loss = 0.0
pred_list = []
true_list = []
with torch.no_grad():
for batch_x, batch_y in loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
total_loss += loss.item() * batch_x.size(0)
pred_list.append(pred.cpu().numpy())
true_list.append(batch_y.cpu().numpy())
avg_loss = total_loss / len(loader.dataset)
y_pred = np.vstack(pred_list).ravel()
y_true = np.vstack(true_list).ravel()
return avg_loss, y_true, y_pred
##训练过程中使用 MSELoss 作为损失函数,Adam 作为优化器,并通过验证集损失保存表现最好的模型参数。
def main() -> None:
set_seed()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x, y, feature_names = load_data()
train_loader, val_loader, test_loader, _ = build_loaders(x, y, batch_size=32)
model = MLPRegressor(input_dim=len(feature_names)).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=1e-3, weight_decay=1e-4
)
epochs = 200
best_val_loss = float("inf")
best_state = None
history = []
for epoch in range(epochs):
model.train()
train_loss = 0.0
for batch_x, batch_y in train_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
optimizer.zero_grad()
pred = model(batch_x)
loss = criterion(pred, batch_y)
loss.backward()
optimizer.step()
train_loss += loss.item() * batch_x.size(0)
train_loss /= len(train_loader.dataset)
val_loss, _, _ = evaluate(model, val_loader, criterion, device)
history.append(
{
"epoch": epoch + 1,
"train_loss": round(train_loss, 6),
"val_loss": round(val_loss, 6),
}
)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_state = copy.deepcopy(model.state_dict())
if (epoch + 1) % 20 == 0:
print(
f"Epoch {epoch + 1:03d} | "
f"Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f}"
)
##训练结束后,加载验证集表现最优的模型参数,并在测试集上计算 MAE、RMSE 和 R² 指标。
if best_state is not None:
model.load_state_dict(best_state)
test_loss, y_true, y_pred = evaluate(model, test_loader, criterion, device)
mae = mean_absolute_error(y_true, y_pred)
rmse = float(np.sqrt(mean_squared_error(y_true, y_pred)))
r2 = r2_score(y_true, y_pred)
metrics = {
"dataset": DATA_FILE.name,
"samples": int(x.shape[0]),
"features": int(x.shape[1]),
"train_size": int(len(train_loader.dataset)),
"val_size": int(len(val_loader.dataset)),
"test_size": int(len(test_loader.dataset)),
"device": str(device),
"hyperparameters": {
"hidden_layers": [64, 32],
"activation": "ReLU",
"dropout": 0.2,
"optimizer": "Adam",
"learning_rate": 0.001,
"weight_decay": 1e-4,
"batch_size": 32,
"epochs": 200,
"loss_function": "MSELoss",
"seed": SEED,
},
"metrics": {
"best_val_mse": round(float(best_val_loss), 6),
"test_mse": round(float(test_loss), 6),
"mae": round(float(mae), 6),
"rmse": round(float(rmse), 6),
"r2": round(float(r2), 6),
},
}
(OUTPUT_DIR / "metrics.json").write_text(
json.dumps(metrics, ensure_ascii=False, indent=2),
encoding="utf-8",
)
pd.DataFrame(history).to_csv(
OUTPUT_DIR / "training_history.csv", index=False, encoding="utf-8-sig"
)
pd.DataFrame({"y_true": y_true, "y_pred": y_pred}).to_csv(
OUTPUT_DIR / "test_predictions.csv", index=False, encoding="utf-8-sig"
)
torch.save(model.state_dict(), OUTPUT_DIR / "mlp_regressor_red_wine.pth")
print("\nFinal Test Metrics")
print(f"MAE = {mae:.4f}")
print(f"RMSE = {rmse:.4f}")
print(f"R^2 = {r2:.4f}")
print(f"Saved outputs to: {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
main()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)