基于langchain4j的ai编程助手项目(完整篇)
文章目录
注意
- langchain4j需要JDK17以上的版本,比如JDK21.
- 使用
@Bean的原因:
Spring容器管理:让Spring框架管理这个对象的生命周期,自动创建、初始化和销毁
依赖注入:其他组件可以通过@Resource或@Autowired直接注入使用,无需手动new对象
单例复用:默认情况下Spring会保证整个应用只有一个实例,避免重复创建开销
配置集中:在@Configuration类中统一管理所有服务的创建逻辑,便于维护
在这个项目中,通过@Bean注册AI服务后,Controller或其他Service就能直接使用这个具备AI能力的服务了。
一、ai对话——chatModel
导入阿里大模型
阿里大模型maven依赖地址
在pox.xml添加依赖:
<!-- Source: https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-community-dashscope-spring-boot-starter -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
<version>1.14.1-beta24</version>
<scope>compile</scope>
</dependency>
在下面链接找到对应模型的依赖导入,然后复制下来到搜索框,找到最新版本号依赖,添加:
langchain4j中文教程对应LLM模型依赖
对chat单元测试报错:
报错内容:
Exception in thread "main" java.lang.NoSuchMethodError: 'java.lang.String org.junit.platform.engine.discovery.MethodSelector.getMethodParameterTypes()
解决:
在搜索任何方法之前,先检查你的JDK版本,在IDEA终端运行MVN
二、多模态
多模态是指能够同时处理、理解和生成多种不同类型数据的能力,比如文本、图像、音频、视频、PDF等等
//简单对话,自定义消息类型
public String ChatWithMessage(UserMessage userMessage) {
ChatResponse chatResponse = qwenChatModel.chat(userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
log.info("AI 输出:" + aiMessage.toString());
return aiMessage.text();
}
测试

**原因:**因为qwen大模型本身不支持多模态进而导致识别不出来
三、系统提示词SystemMessage
系统提示词是设置AI模型行为规则和角色定位的隐藏指令,用户通常不能直接看到。系统Prompt 相当于给AI设定人格和能力边界,也就是告诉AI"你是谁?你能做什么?
区别于用户提示词
//系统消息是全局唯一,如果有多个,会替换掉旧的
private static final String SYSTEM_MESSAGE = """
你是编程领域的小助手,帮助用户解答编程学习和求职面试相关的问题,并给出建议。重点关注4 个方向:1.规划清晰的编程学习路线
2.提供项目学习建议
3.给出程序员求职全流程指南(比如简历优化、投递技巧)
4.分享高频面试题和面试技巧
请用简洁易懂的语言回答,助力用户高效学习与求职。
""";
//简单对话
public String chat(String message) {
SystemMessage systemMessage = SystemMessage.from(SYSTEM_MESSAGE);
UserMessage userMessage = UserMessage.from(message);
ChatResponse chatResponse = qwenChatModel.chat(systemMessage,userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
log.info("AI 输出:" + aiMessage.toString());
return aiMessage.text();
}
开发agent应用,这一部分系统提示词要写的严谨一点。
四、ai service
在学习更多特性前,我们要了解LangChain4j 最重要的开发模式–AI Service,提供了很多高层抽象的、用起来更方便的API,把AI应用当做服务来开发。
注意:前面写的chatModel是低层api,自由度比较高。
而高级api,则会封装好很多东西,直接调用,没有那么灵活。
public class AiCodeHelperServiceFactory {
@Resource
private ChatModel qwenChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService() {
return AiServices.create(AiCodeHelperService.class, qwenChatModel);//创建接口实现类
}
}
调用 Aiservices.create 方法就可以创建出AI Service 的实现类了,背后的原理是利用Java 反射机制创建了一个实现接口的代理对象,AiServices.create生成代理对象,代理对象负责输入和输出的转换,比如把String类型的用户消息参数转为UserMessage类型并调用 CHatModel, 再将 AI返回的AiMessage类型转换为 String类型作为返回值。
五、会话记忆 ChatMemory
会话记忆是指让AI能够记住用户之前的对话内容,并保持上下文连贯性,这是实现AI应用的核心特性。
LangChain4j提供了对应类
LangChain4j为我们提供了开箱即用的Messagewindow ChatMemory会话记忆,最多保存N条消息,多余的会自动淘汰。创建会话记忆后,在构造AI Service 设置chatMemory:
public AiCodeHelperService aiCodeHelperService() {
//创建一个会话内存,之处区分用户的
ChatMemory chatMemory= MessageWindowChatMemory.withMaxMessages(10);
//创建接口实现类,不需要原先那种创建接口实现的类,直接可以动态创建接口实现类
//构建ai-service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory) //会话记忆
.build();
return aiCodeHelperService;
}
}
进阶语法
会话记忆默认是存储在内存的,重启后会丢失,可以通过自定义ChatMemoryStore接口的实现类,将消息保存到MySQL等其他数据源中。
六、结构化输出
结构化输出是指将大模型返回的文本输出转换为结构化的数据格式,比如一段JSON、一个对象、或者是复杂的对象列表。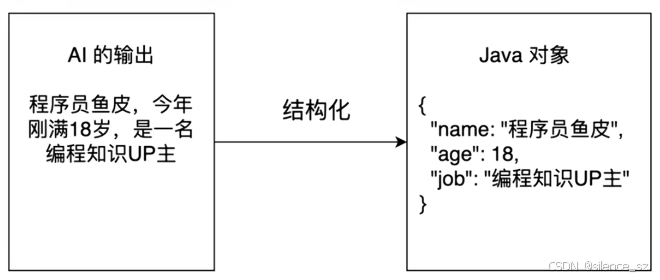
三种实现方式
- 利用大模型的JSONschema
- 利用 Prompt + JSON Mode
- 利用Prompt
前两种效果要好于第三种;
原因第一种是langchain4j内在的设计好的框架,第三种,则需要用户设置好prompt,让agent知道要这么做,有点强硬。没有第一种原生态的效果好。
自然语言是给人看的,结构化输出是给程序运行的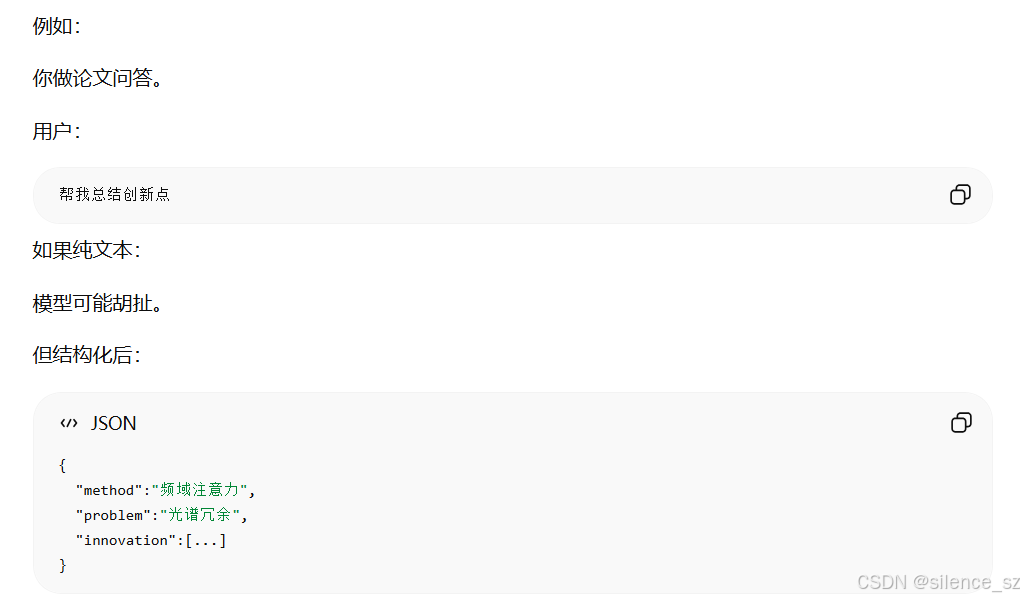
代码实现
1.接口
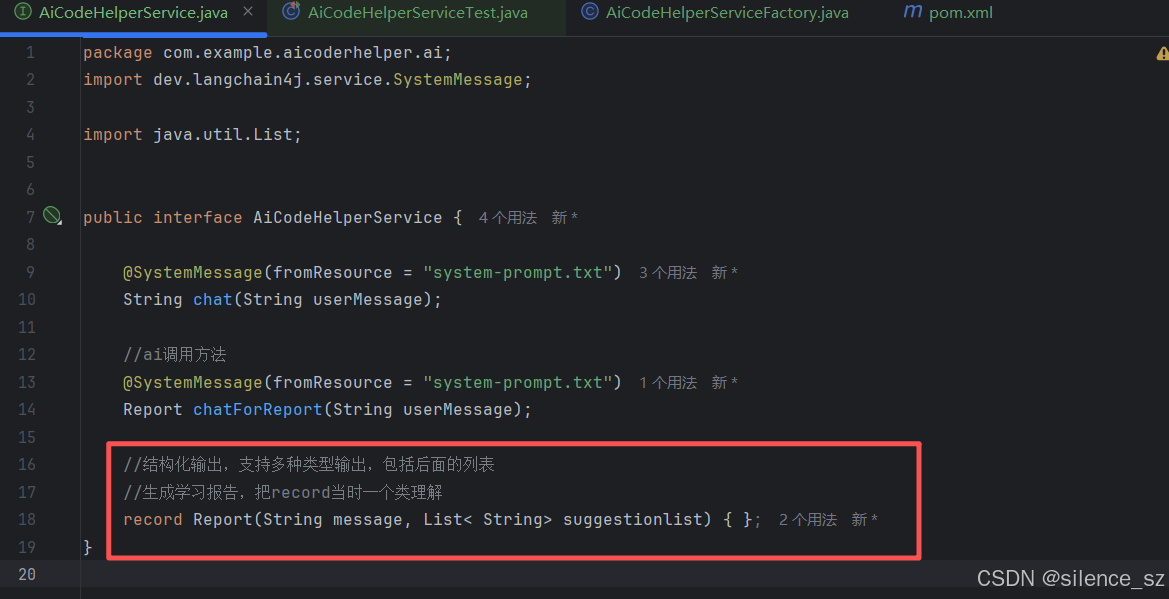
2.具体实现–测试
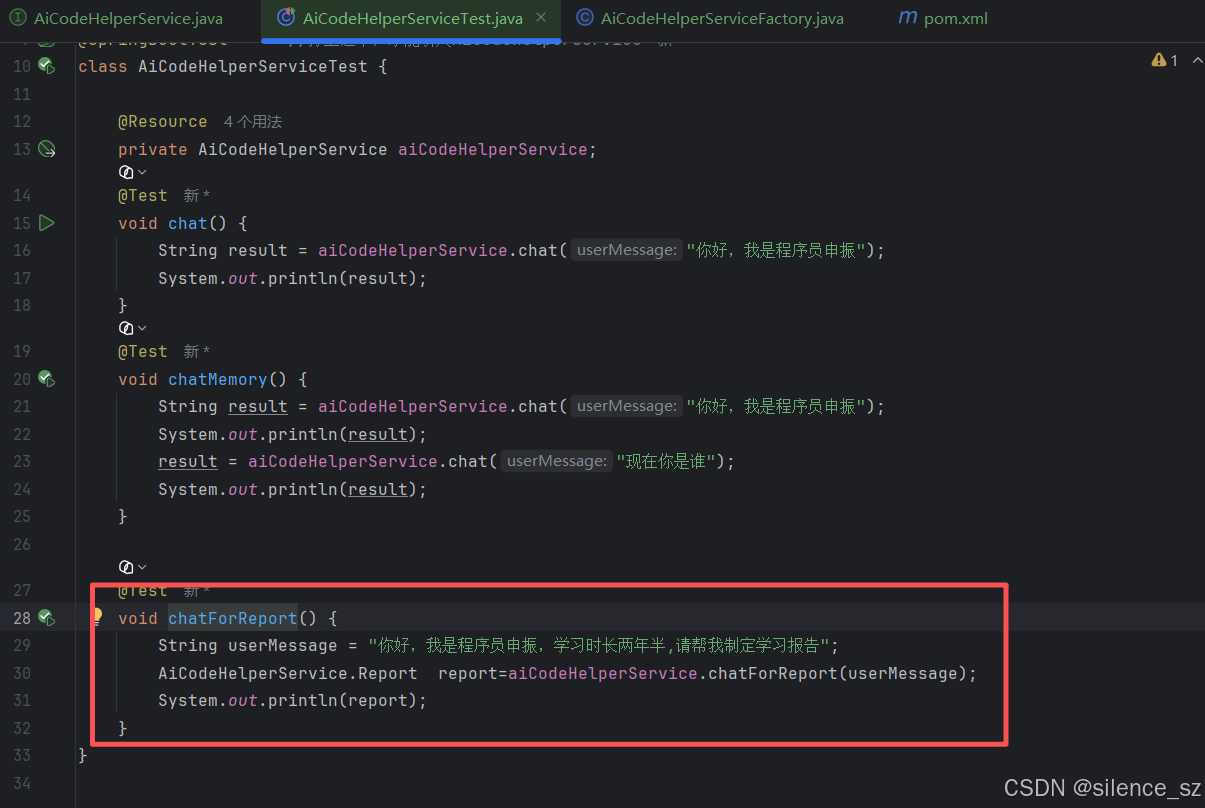
七、RAG 检索增强生成
简述
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和AI 内容生成的混合架构,可以解决大模型的知识时效性限制和幻觉问题。
简单来说,RAG就像给AI配了一个“小抄本”,让AI回答问题前先查一查特定的知识库来获取知识,确保回答是基于真实资料而不是凭空想象。很多企业也基于RAG搭建了自己的智能客服,可以用自己积累的领域知识回复用户。
如果某一个用户问的问题,和知识库越接近,那么两个向量距离距离就会越接近。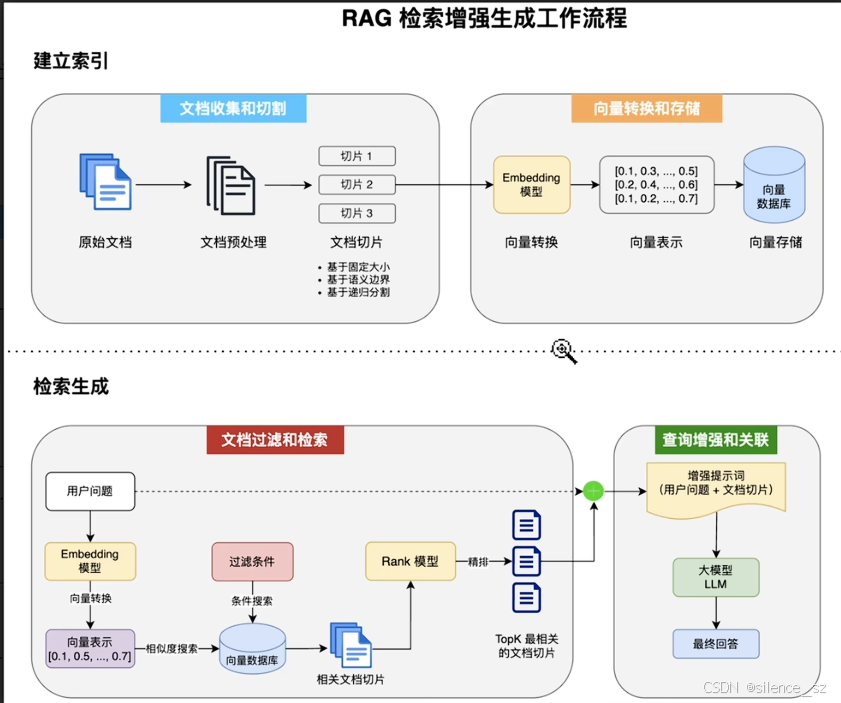
注意这里向量就理解成表示文本的一种方式
RAG的风格
基础版一切都是基于内置,效果不太好,不建议使用,在实战中,建议用下面两种。
标准版
下面来试试标准版RAG实现,为了更好地效果,我们需要:
- 加载Markdown文档并按需切割
- Markdown文档补充文件名信息
- 自定义Embedding模型:选择一些更好的模型,提高维度,最后检索效果会更好
- 自定义内容检索器:怎么样从向量数据库里面检测内容
重叠切片的含义
public class RagConfig {
@Resource
private EmbeddingModel qwenEmbeddedModel;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
//为aiservice提供一个内容检索器
@Bean
public ContentRetriever contentRetriever() {
//-----RAG----
//1.加载文档
List<Document> documents=FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
//2.切割文档:每个文档按照段落切割,最大1000字符,重叠200字符
DocumentByParagraphSplitter documentByParagraphSplitter =
new DocumentByParagraphSplitter(1000, 200);
//3.自定义文档加载器,把文档转换成向量保存在向量数据库里面
EmbeddingStoreIngestor ingestor=EmbeddingStoreIngestor.builder()
.documentSplitter(documentByParagraphSplitter)
//为了提高文档切片质量,为切割后的文档碎片TextSegment添加文档名称作为元信息,加载向量
.textSegmentTransformer(textSegment ->
TextSegment.from(textSegment.metadata().getString("file_name")+"\n"
+textSegment.text(),textSegment.metadata()))
//使用向量模型,保存到向量存储中
.embeddingModel(qwenEmbeddedModel)
.embeddingStore(embeddingStore)
.build();
//加载文档
ingestor.ingest(documents);
//4.自定义内容加载器
EmbeddingStoreContentRetriever contentRetriever= EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddedModel)
.maxResults(5) //最多五条结果
.minScore(0.75) //过滤分数小于0.75的结果
.build();
return contentRetriever;
}
}
怎么样实现ai回答的内容后面带上依据文件
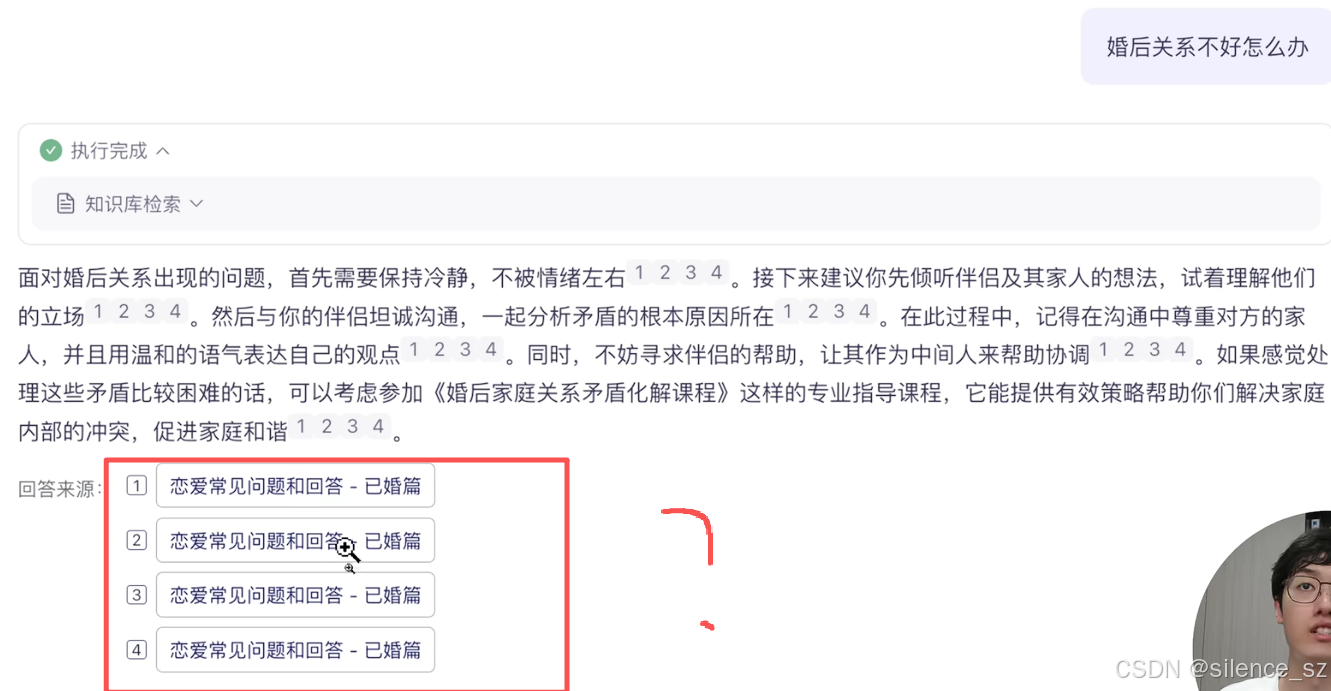
在LangChain4j 中,实现这个功能很简单。在AI Service 中新增方法,在原本的返回类型外封装一层Result类,就可以获得封装后的结果,从中能够获取到RAG引用的源文档、以及Token的消耗情况等等。
先在接口里面添加第一模块;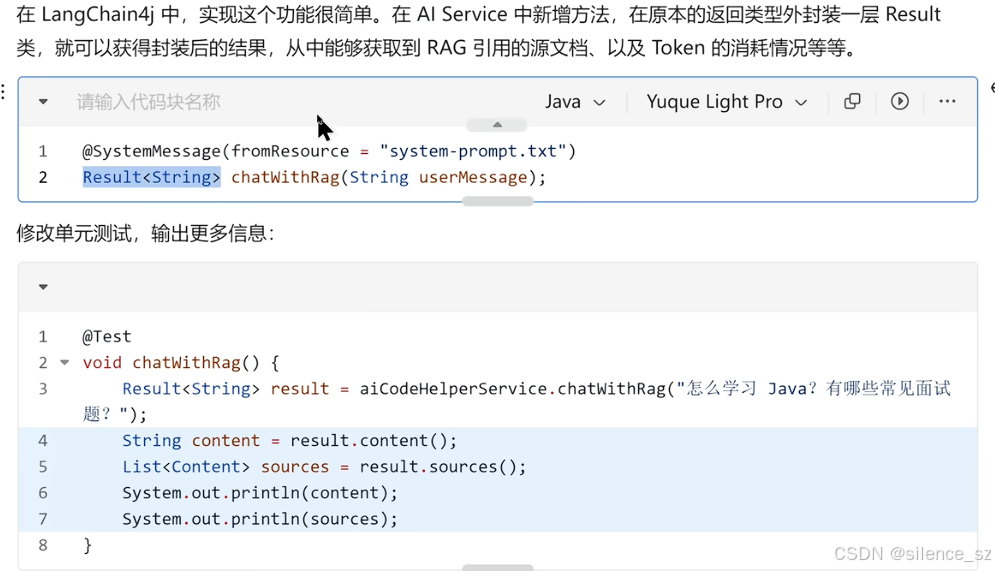
进阶版
八、工具调用-Tools
工具调用(Tool Calling)可以理解为让AI大模型借用外部工具来完成它自己做不到的事情。
跟人类一样,如果只凭手脚完成不了工作,那么就可以利用工具箱来完成。
工具可以是任何东西,比如网页搜索、对外部API的调用、访问外部数据、或执行特定的代码等。
比如用户提问“帮我查询上海最新的天气”,AI本身并没有这些知识,它就可以调用“查询天气工具”,来完成任务。
需要注意的是,工具调用的本质并不是AI服务器自己调用这些工具、也不是把工具的代码发送给 AI服务器让它执行,它只能提出要求,表示“我需要执行XX工具完成任务”。而真正执行工具的是我们自己的应用程序,执行后再把结果告诉AI,让它继续工作。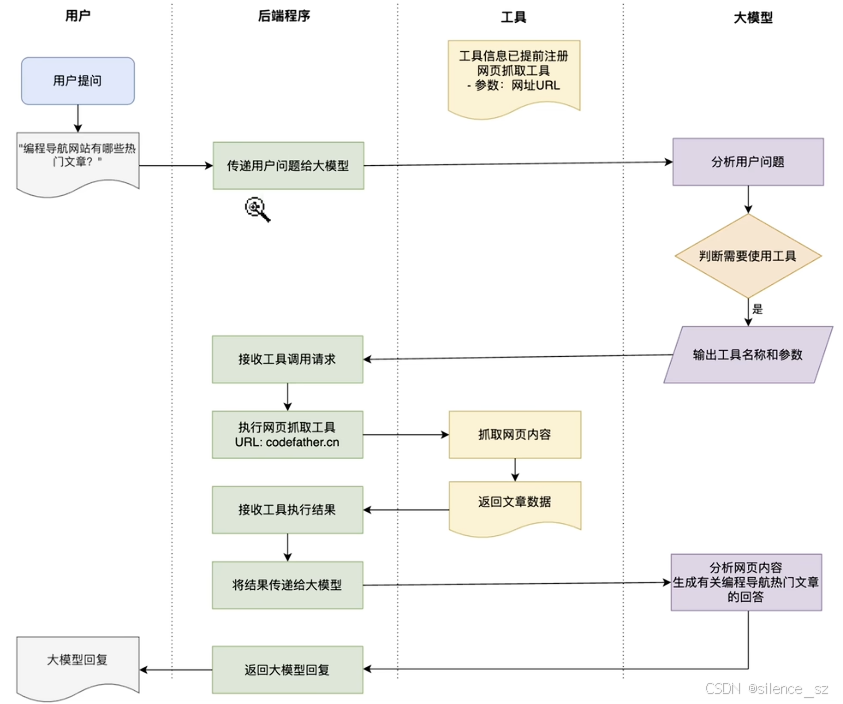
我们需要的网络搜索能力,就可以通过工具调用来实现。这里我们细化下需求:让AI能够通过我的面试鸭刷题网站来搜索面试题。
实现方案很简单,因为面试鸭网站的搜索页面支持通过URL参数传入不同的搜索关键词,我们只需要利用Jsoup库抓取面试鸭搜索页面的题目列表就可以了
九、模型上下文协议——MCP
MCP(Model Context Protocol,模型上下文协议)是一种开放标准,目的是增强AI与外部系统的交互能力。MCP为AI提供了与外部工具、资源和服务交互的标准化方式,让AI能够访问最新数据、执行复杂操作,并与现有系统集成。
————————————————————————————————————————————
可以将MCP想象成AI应用的USB接口。就像USB为设备连接各种外设和配件提供了标准化方式一样,MCP为AI模型连接不同的数据源和工具提供了标准化的方法。
刚刚我们通过工具调用实现了面试题的搜索,下面我们利用MCP实现全网搜索内番:这也是一个典型的MCP应用场景了。
- 一种是在线使用别人的服务器
- 另一种则需要下载到本到来连接MCP
十、护栏机制 Graudrail(拦截器)
Guardrails 是一种机制,可以让你验证 LLM(大语言模型)的输入和输出,确保其符合预期。通过 Guardrails,你可以完成以下操作:
- 验证用户输入是否不在允许范围内
- 确保输入在调用 LLM 前满足特定条件(例如防御 提示注入攻击)
- 确保输出格式正确(例如是符合正确模式的 JSON 文档)
- 确保 LLM 输出符合业务规则和约束(例如,如果这是 X 公司的聊天机器人,回答中不能包含对竞争对手 Y 的引用)
- 检测幻觉(hallucinations)
以上只是示例,你可以用 Guardrails 做更多的事情。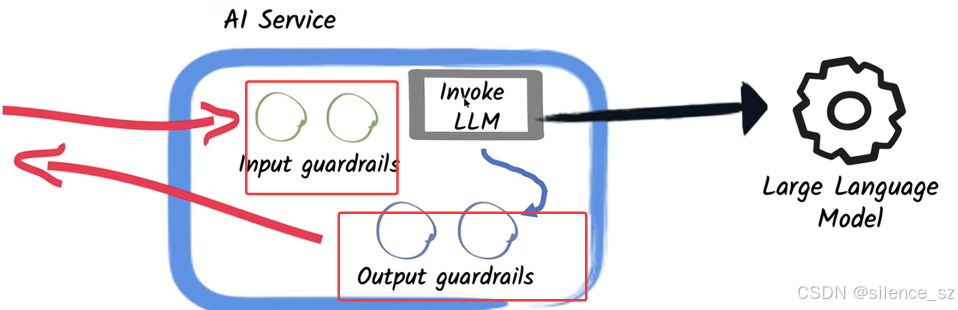
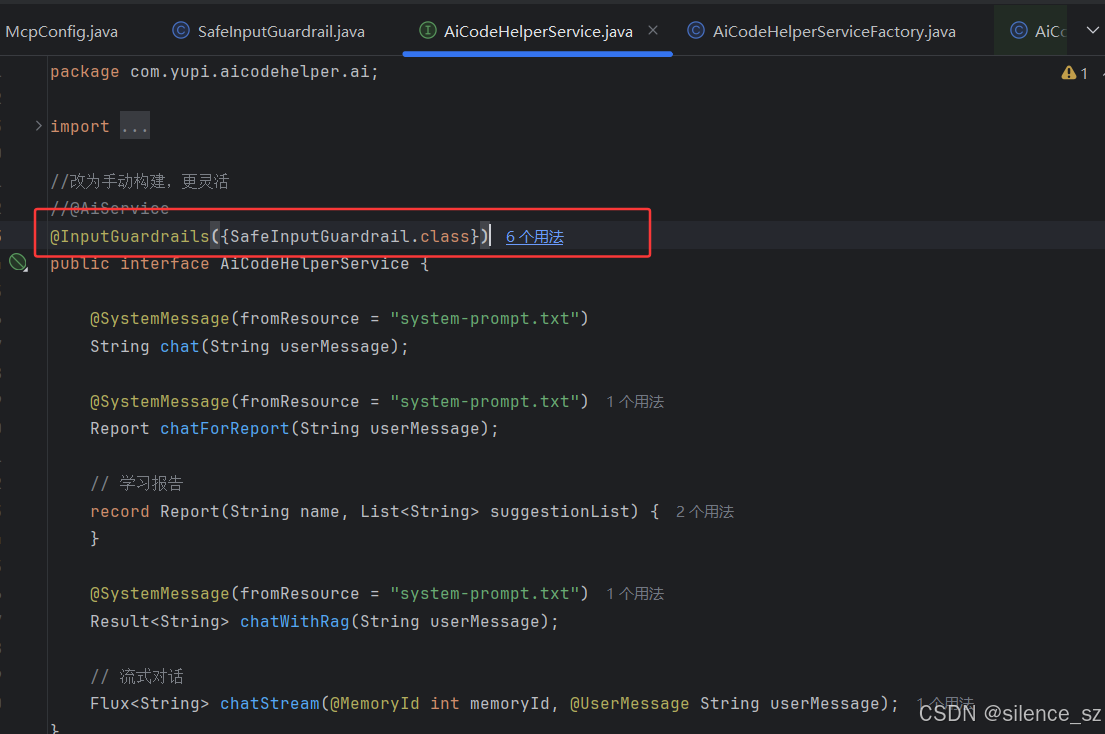
十、日志和可观测性
之前我们都是通过Debug查看运行信息,不仅不便于调试,而且生产环境肯定不能这么做。
官方提供了日志和可观测性,来帮我们更好地调试程序、发现问题。
日志 用国外的大模型才支持
所以我们这里只记录可观测性
问题:下面写完listener之后,测试时发现没有监听到自定义的model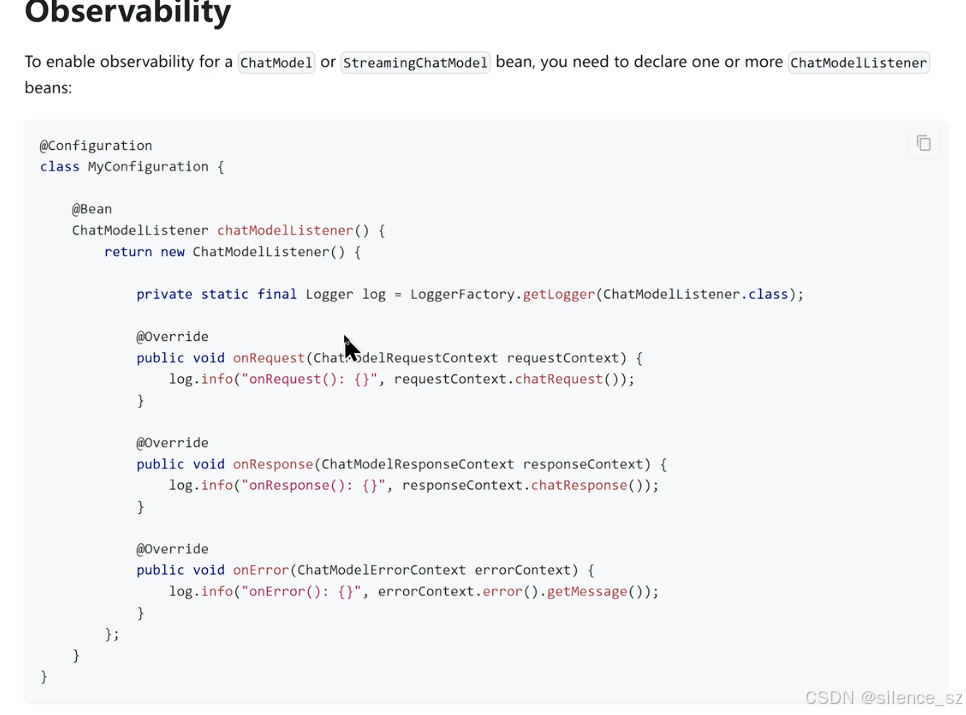
解决方法:自己定义一个大模型
package com.yupi.aicodehelper.ai.model;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.chat.listener.ChatModelListener;
import jakarta.annotation.Resource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
@ConfigurationProperties(prefix = "langchain4j.community.dashscope.chat-model")
@Data
public class QwenChatModelConfig {
private String modelName;
private String apiKey;
@Resource
private ChatModelListener chatModelListener;
@Bean
public ChatModel myQwenChatModel() {
return QwenChatModel.builder()
.apiKey(apiKey)
.modelName(modelName)
.listeners(List.of(chatModelListener))
.build();
}
}
十一、服务化SSE流式输出
AI服务化
至此,AI的能力基本开发完成,但是目前只支持本地运行,需要编写一个接口提供给前端调用,让AI能够成为一个服务。
我们平时开发的大多数接口都是同步接口,也就是等后端处理完再返回。但是对于AI应用,特别是响应时间较长的对话类应用,可能会让用户失去耐心等待,因此推荐使用 SSE(Server-Sent Events)技术实现实时流式输出,类似打字机效果,大幅提升用户体验。
1.引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>
2.写入service接口
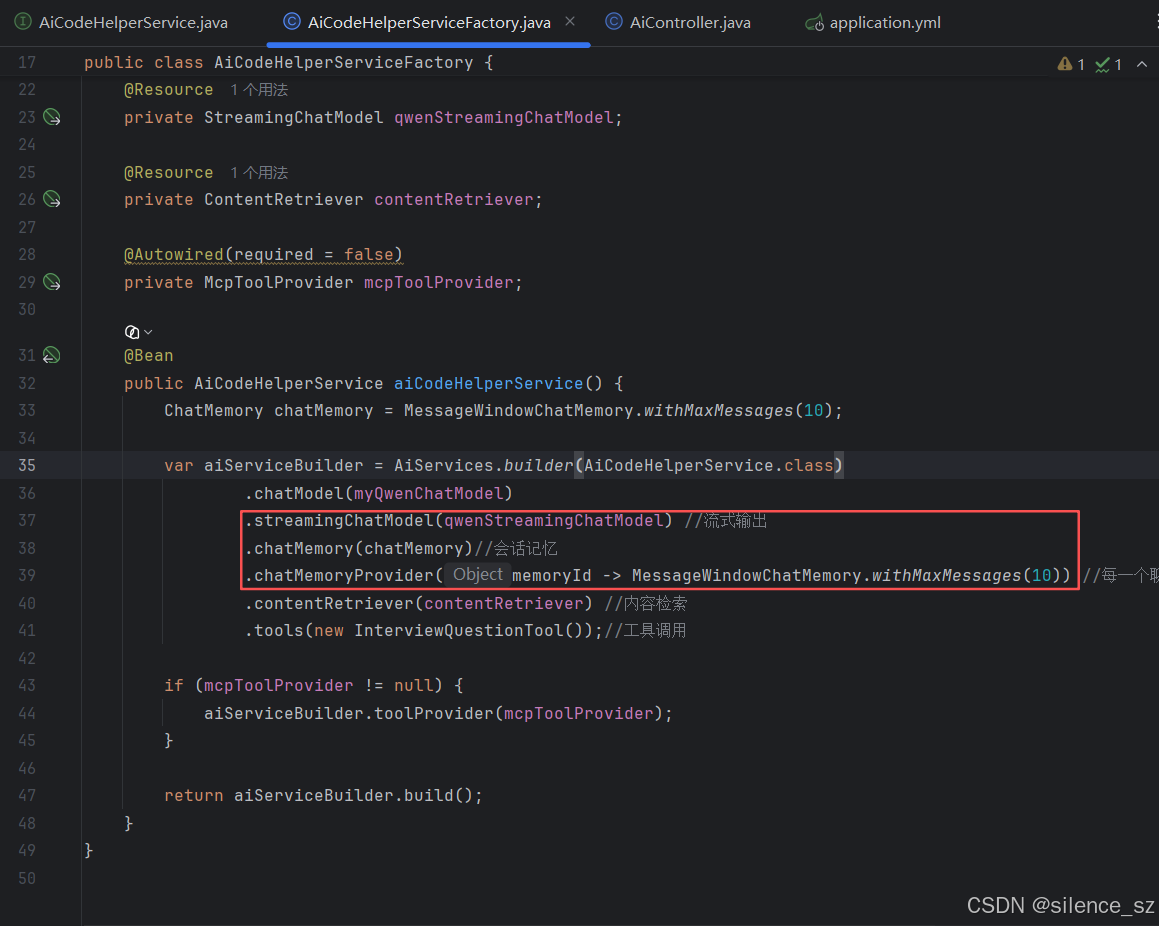
// 流式对话,因为是给前端使用,每次会话要隔离,所以用到chatmemory的另一个特性,隔离会话
Flux<String> chatStream(@MemoryId int memoryId, @UserMessage String userMessage);
3.
4.写一个contorller
package com.yupi.aicodehelper.controller;
import com.yupi.aicodehelper.ai.AiCodeHelperService;
import jakarta.annotation.Resource;
import org.springframework.http.codec.ServerSentEvent;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/ai")
public class AiController {
@Resource
private AiCodeHelperService aiCodeHelperService;
@GetMapping("/chat")
public Flux<ServerSentEvent<String>> chat(int memoryId, String message) {
return aiCodeHelperService.chatStream(memoryId, message)
.map(chunk -> ServerSentEvent.<String>builder()
.data(chunk)
.build());
}
}
5.此时前端还没写,怎么测试
(1)用api测试工具
(2)在项目文件夹运行git
十二、前端开发
直接使用cursor开发;
提示词
首先准备一段详细的Prompt,一般要包括需求、技术选型、后端接口信息,还可以提供一些原型图、后端代码等
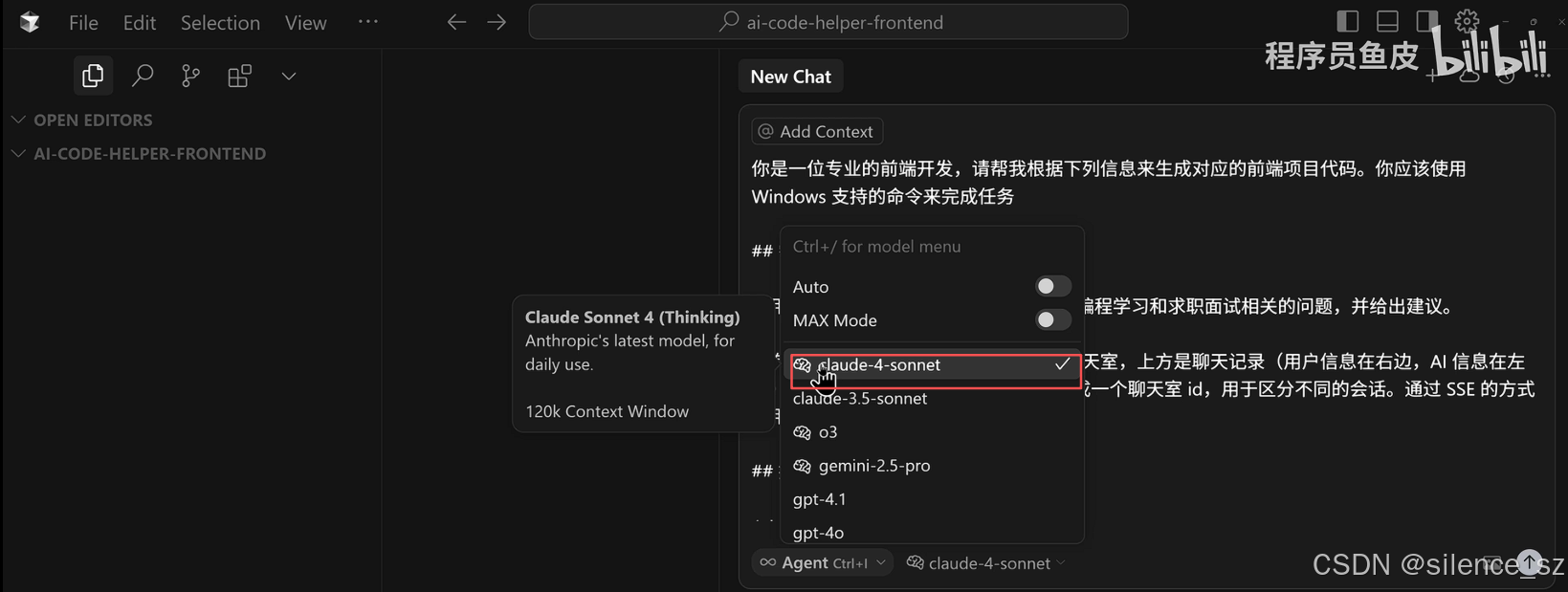
你是一位专业的前端开发,请帮我根据下列信息来生成对应的前端项目代码。
## 需求
应用为《AI 编程小助手》,帮助用户解答编程学习和求职面试相关的问题,并给出建议。
只有一个页面,就是主页:页面风格为聊天室,上方是聊天记录(用户信息在右边,AI 信息在左边),下方是输入框,进入页面后自动生成一个聊天室 id,用于区分不同的会话。通过 SSE 的方式调用 chat 接口,实时显示对话内容。
## 技术选型
1. Vue3 项目
2. Axios 请求库
## 后端接口信息
接口地址前缀:http://localhost:8081/api
## SpringBoot 后端接口代码
@RestController
@RequestMapping("/ai")
public class AiController {
@GetMapping("/chat")
public Flux<ServerSentEvent<String>> chat(int memoryId, String message) {
return aiCodeHelperService.chatStream(memoryId, message)
.map(chunk -> ServerSentEvent.<String>builder()
.data(chunk)
.build());
}
}
注意:如果使用的是 Windows 系统,最好在 prompt 中补充“你应该使用 Windows 支持的命令来完成任务”。
开发
1.因为项目还是比较复杂的,选择带大脑的claude4来执行
2.报错了,查找错误方法:按F12
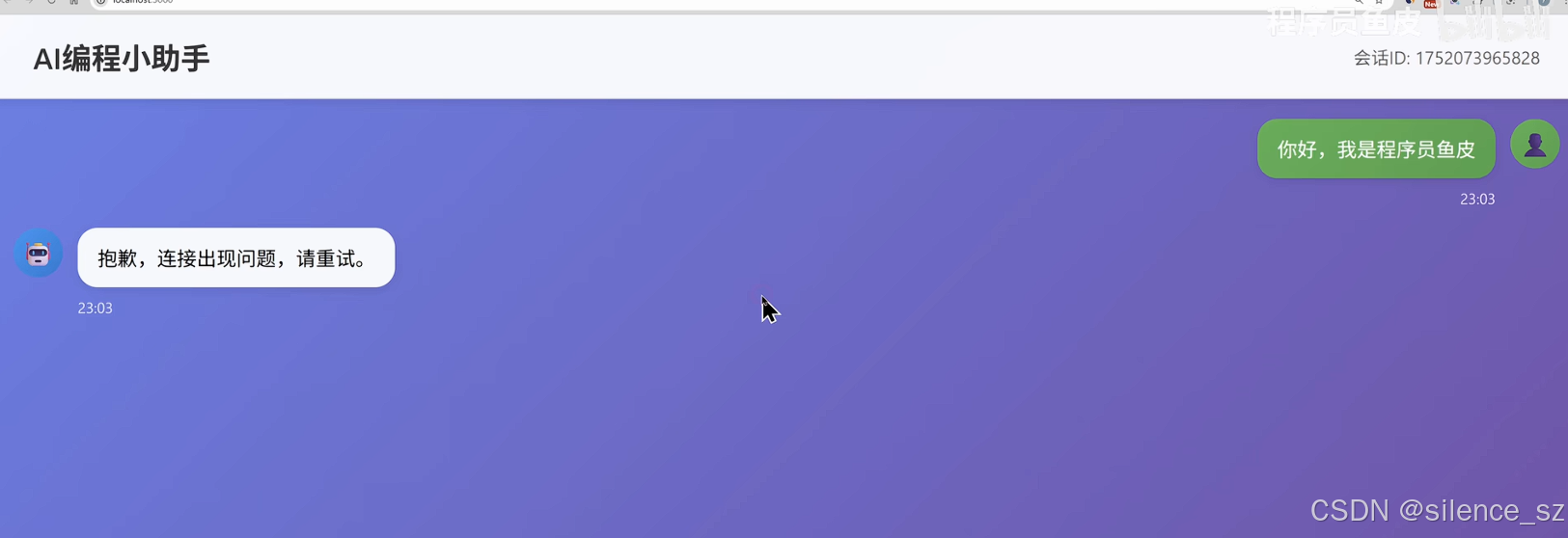
a,查找错误方法:按F12,打开开发者工具,看看是前端还是后端错误
b,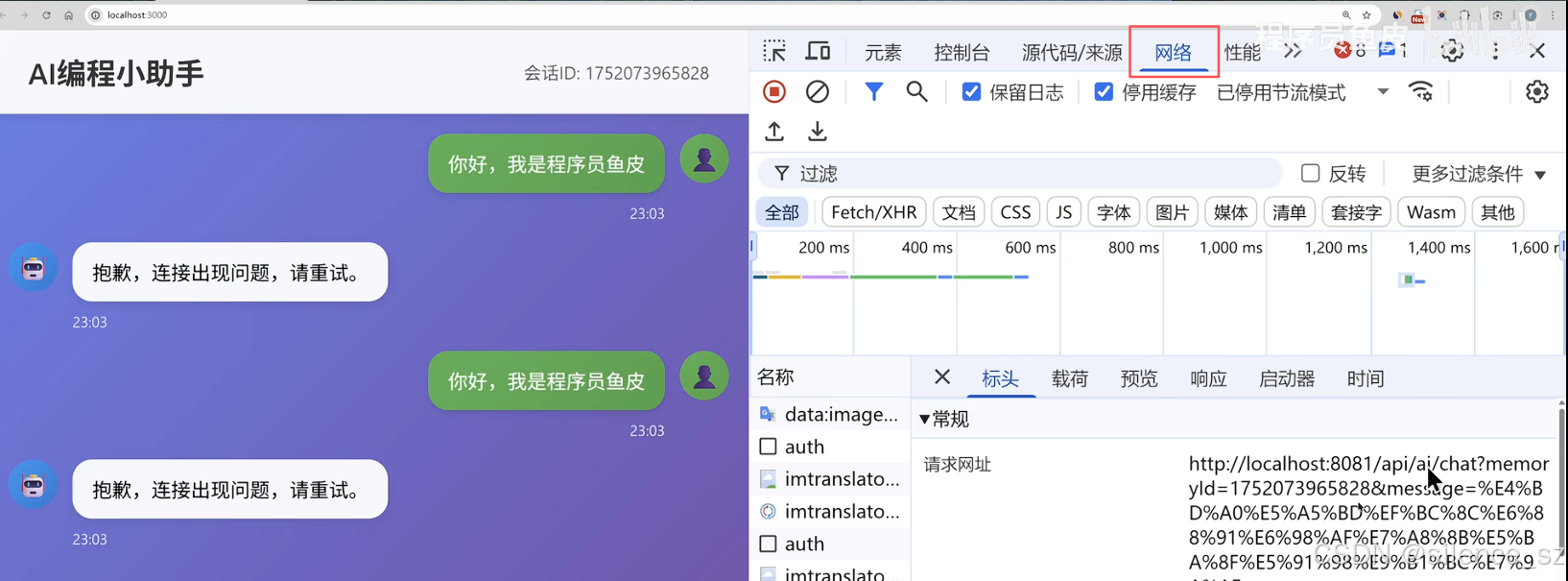
c,再查看后端debug的报错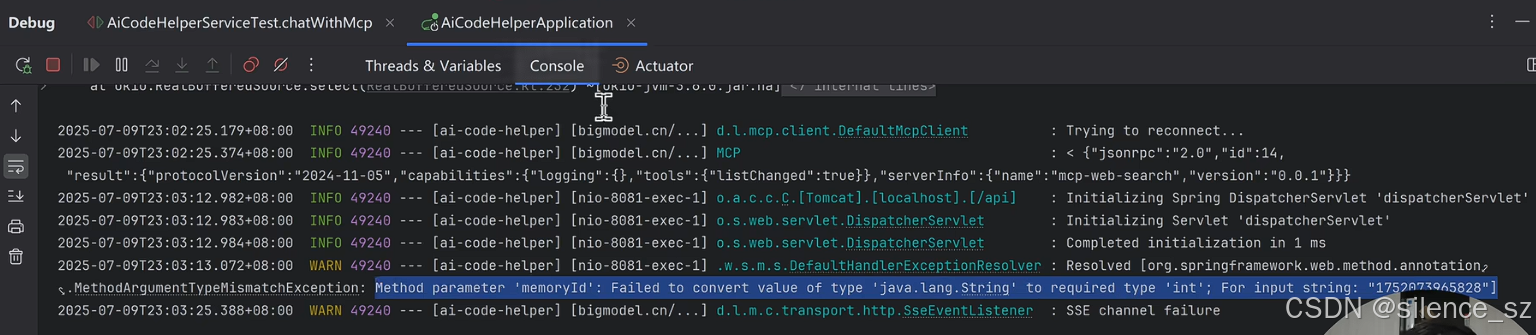
d,找到报错信息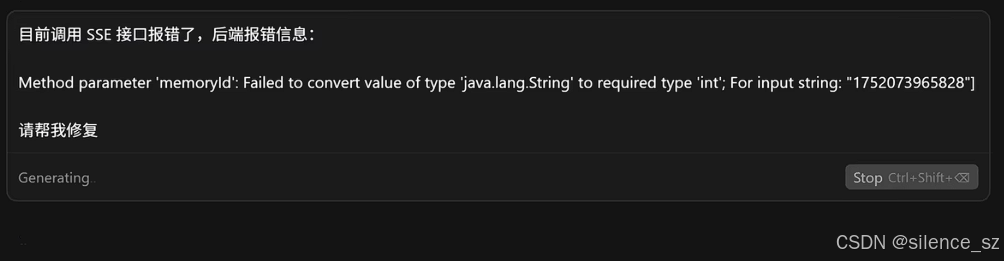
十三、总结
回到开头的那个问题:实际开发中应该如何选择 AI 开发框架呢?
就拿 Spring AI 和 LangChain4j 来说,不知道大家更喜欢哪个框架?我其实会更喜欢 Spring AI 的开发模式,而且 Spring AI 目前支持的能力更多,还有国内 Spring AI Alibaba 的巨头加持,生态更好,遇到问题更容易解决;LangChain4j 的优势在于可以独立于 Spring 项目使用,更自由灵活一些。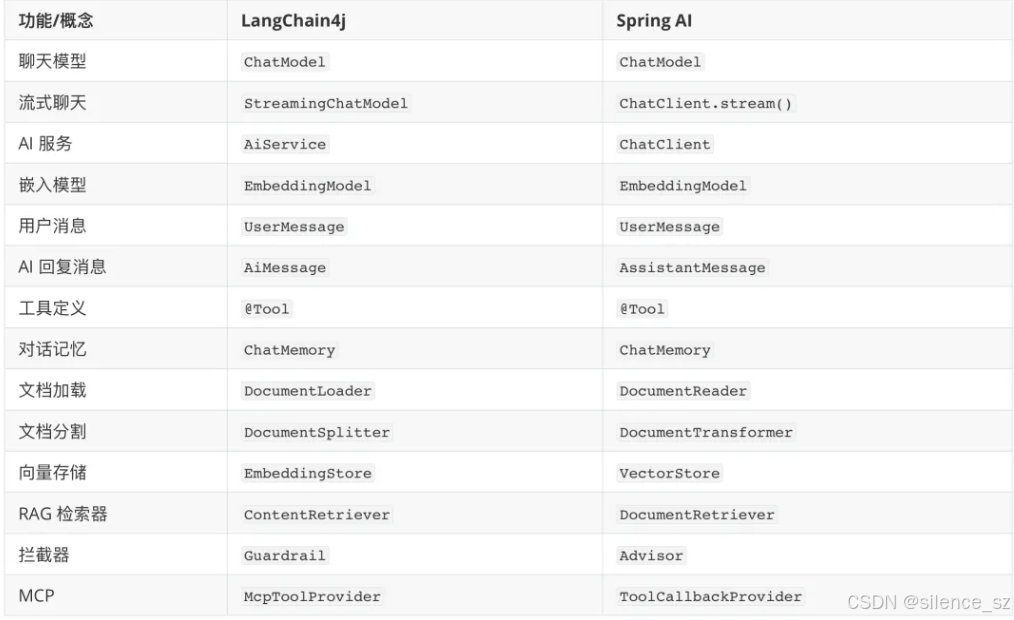
last:注意要点
一.企业实战笔记:启动阶段依赖外网的正确姿势
- 先区分依赖类型
- 核心依赖:缺失就不能安全/正确运行(可 fail fast)。
- 增强依赖:只影响部分能力(应降级,不阻塞启动)。
- 不要让增强能力阻塞应用启动
- RAG、MCP、推荐、外部搜索等应懒加载/异步初始化。
- 外网失败时只关闭该功能,不让整个服务起不来。
- 必备工程手段
- 功能开关(Feature Flag),如 app.mcp.enabled。
- 超时、重试、熔断、限流。
- 清晰日志和告警(记录“已降级”而非静默失败)。
- 健康检查要分层
- liveness:进程是否存活。
- readiness:是否可接流量(可按核心依赖判断)。
- 增强依赖异常不应直接判定服务死亡。
- 配置与安全
- API Key 放环境变量/配置中心,不写死在仓库。
- 外部地址和策略参数化(可按环境切换)。
- 一句话原则
核心链路:失败即停(Fail Fast)。
增强链路:失败降级(Graceful Degradation)。
二、项目本质
无论是RAG。还是TOOLS,它们本质上面都是讲最后额结果重新给ai,只不过这个结果是增强了或者说准确了。ai就是大脑。
三、测试技巧
直接用 Maven 跑最稳。
在项目根目录 E:\github\ai-code-helper-master 打开终端后:
跑全部测试
mvn test
只跑某个测试类(示例)
mvn -Dtest=AiCodeHelperTest test
只跑某个测试方法(示例)
mvn -Dtest=AiCodeHelperTest#testChat test
比如,要跑AiCodeHelperServiceTest里面的chatWithMcp方法
mvn -Dtest=AiCodeHelperServiceTest#chatWithMcp test
四、解决前后端跨域代码,
1.创建config软件包
2.在里面复制这一段代码即可,无需改动
package com.yupi.aicodehelper.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
/**
* 全局跨域配置
*/
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
// 覆盖所有请求
registry.addMapping("/**")
// 允许发送 Cookie
.allowCredentials(true)
// 放行哪些域名(必须用 patterns,否则 * 会和 allowCredentials 冲突)
.allowedOriginPatterns("*")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*")
.exposedHeaders("*");
}
}
五、报错代码解释
400,用户请求参数出现问题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)