深度学习新手必懂的激活函数!Sigmoid、Tanh、ReLU、Leaky ReLU、Softmax 详解
很多深度学习新手训练模型时,经常遇到模型不收敛、梯度消失、训练速度极慢、神经元死亡等问题,却不知道根源大概率是激活函数选错/不懂特性。
激活函数是神经网络的灵魂核心!如果没有激活函数,无论多少层的神经网络,都等价于单层线性回归,无法拟合复杂的非线性数据。
本文从零讲解深度学习所有主流激活函数,包含数学公式、图像特征、优缺点、适用场景、避坑要点、PyTorch代码实战,一篇搞定新手所有疑问,建议收藏反复查阅!
一、为什么需要激活函数?(核心本质)
神经网络每一层的计算本质是:$$y = Wx+b$$,这是纯线性变换。
多层线性变换叠加,结果依然是线性变换,无法拟合图像、文本、语音等复杂的非线性数据。
激活函数的核心作用:引入非线性!
让深层神经网络具备拟合任意复杂函数的能力,这也是深度学习能解决复杂任务的根本原因。
二、五大主流激活函数超详细解析
1. Sigmoid 激活函数(经典老牌)
1.1 数学公式
1.2 函数特点
-
输出范围:(0, 1),所有输出值被压缩在0到1之间
-
单调递增、连续可导,梯度平滑
-
输出天然具备概率意义
1.3 核心缺点(新手高频坑)
-
梯度消失严重:x极大/极小时,梯度无限趋近于0,深层网络无法更新参数
-
输出非0均值:所有输出恒大于0,会导致下一层输入偏移,收敛速度变慢
-
计算量大:包含指数运算,训练耗时高
1.4 适用场景
仅用于二分类任务最后一层(输出概率),隐藏层坚决不用!
2. Tanh 双曲正切函数(Sigmoid升级版)
2.1 数学公式
2.2 函数特点
-
输出范围:(-1, 1),解决了Sigmoid非0均值问题
-
0均值输出,数据中心化,模型收敛速度更快
-
依然是单调递增、连续可导
2.3 缺点
依然存在梯度消失问题,x极值处梯度趋近于0,不适合深层网络;同时保留指数运算,计算成本较高。
2.4 适用场景
早期浅层神经网络、RNN传统时序模型,现代深层CNN、Transformer基本淘汰。
3. ReLU 整流线性单元(深度学习万金油)
目前最经典、使用最广泛的激活函数,绝大多数CNN、深层网络默认首选!
3.1 数学公式
3.2 函数特点
-
计算极其简单:无指数、无除法,仅判断大小,训练速度大幅提升
-
缓解梯度消失:x>0时,梯度恒为1,深层网络梯度可正常回传
-
单侧抑制特性,稀疏激活,贴合生物神经元机制
3.3 致命缺点:神经元死亡
当输入x<0时,梯度永久为0,神经元参数永远不会更新,直接“坏死”,不再参与训练。
出现场景:学习率过大、参数初始化不当,会导致大量神经元死亡,模型彻底不收敛。
3.4 适用场景
几乎所有卷积神经网络CNN、深层全连接网络的隐藏层首选。
4. Leaky ReLU(ReLU改进版,解决神经元死亡)
专为解决ReLU神经元死亡问题诞生,是ReLU的最优平替!
4.1 数学公式
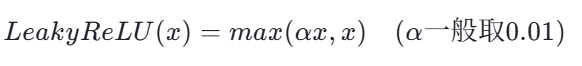
4.2 核心改进
x<0时,不再直接置0,而是保留一个极小的线性梯度,让神经元始终可以更新参数,彻底杜绝神经元死亡问题。
4.3 优缺点
-
优点:保留ReLU所有优势,解决神经元死亡、梯度消失问题
-
缺点:负区间斜率固定,自适应能力较弱
4.4 适用场景
ReLU训练出现神经元死亡、模型不收敛时,直接替换为Leaky ReLU;常用于图像分割、检测等高精度任务。
5. Softmax 激活函数(多分类专属)
5.1 数学公式
5.2 核心特点
-
将网络输出转换为概率分布,所有输出值之和为1
-
输出越大,对应类别概率越高,完美适配多分类任务
5.3 优缺点
-
优点:输出可解释性强,适配多分类概率输出
-
缺点:计算量大,存在梯度饱和问题,仅用于输出层,禁止用于隐藏层
5.4 适用场景
所有多分类任务最后一层(图像分类、文本分类、语音分类等)。
三、激活函数核心对比表(新手速查)
|
激活函数 |
输出范围 |
核心优点 |
核心缺点 |
适用场景 |
|---|---|---|---|---|
|
Sigmoid |
(0,1) |
输出概率化 |
梯度消失、非0均值、计算慢 |
二分类输出层 |
|
Tanh |
(-1,1) |
0均值、收敛快 |
依然梯度消失、计算慢 |
浅层网络、传统RNN |
|
ReLU |
[0,+∞) |
计算快、缓解梯度消失 |
神经元死亡、输出非0均值 |
深层网络隐藏层首选 |
|
Leaky ReLU |
(-∞,+∞) |
杜绝神经元死亡、保留ReLU优势 |
负区间斜率固定 |
ReLU优化替换、高精度视觉任务 |
|
Softmax |
(0,1),和为1 |
概率分布、可解释性强 |
计算量大、梯度饱和 |
多分类输出层 |
四、PyTorch 代码实战(直接复制可用)
极简代码实现五大激活函数,新手可直接运行测试效果:
import torch
import torch.nn as nn
# 定义测试张量
x = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
# 1. Sigmoid
sigmoid = nn.Sigmoid()
print("Sigmoid结果:", sigmoid(x))
# 2. Tanh
tanh = nn.Tanh()
print("Tanh结果:", tanh(x))
# 3. ReLU
relu = nn.ReLU()
print("ReLU结果:", relu(x))
# 4. Leaky ReLU
leaky_relu = nn.LeakyReLU(negative_slope=0.01)
print("Leaky ReLU结果:", leaky_relu(x))
# 5. Softmax(维度1,适配分类输出)
softmax = nn.Softmax(dim=0)
print("Softmax结果:", softmax(x))五、新手必记:激活函数使用黄金准则
-
隐藏层首选 ReLU / Leaky ReLU,坚决不用 Sigmoid、Tanh
-
二分类输出层用 Sigmoid,多分类输出层用 Softmax
-
训练出现神经元死亡、损失不下降:ReLU 替换为 Leaky ReLU
-
深层网络杜绝 Sigmoid、Tanh,避免梯度消失导致模型瘫痪
-
Softmax 只用于输出层,隐藏层使用会大幅降低训练效率
六、总结
1. 激活函数的核心价值是引入非线性,是深度学习拟合复杂数据的关键;
2. Sigmoid、Tanh 是复古函数,仅用于特定场景,不适合深层网络;
3. ReLU 是通用首选,Leaky ReLU 是优化升级版,解决核心缺陷;
4. Softmax 专属多分类输出层,概率输出直观可解释。
吃透激活函数,能解决新手80%的模型训练不收敛、精度上不去的问题!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)