基于Streamlit的轻量本地RAG知识库问答系统(纯本地部署、无API依赖)
一、项目前言
当下RAG(检索增强生成)技术是大模型落地应用的核心方案,市面上多数RAG项目依赖云端大模型API、向量服务,部署复杂且存在数据隐私泄露风险。对于新手学习、个人知识库使用场景,笨重的企业级RAG架构完全没必要。
因此本文复现一款轻量级、纯本地部署、零API依赖的RAG知识库问答系统。项目基于Streamlit搭建可视化界面,实现文档上传、本地知识存储、智能问答全流程,架构规范可扩展,既能作为RAG入门练手项目,也可日常用于个人知识检索。
项目核心优势:
-
完全本地化:无需联网、无需任何大模型API Key,彻底告别401认证、接口超时问题
-
功能完整:支持TXT文档上传、自动去重、知识库持久化、多轮对话问答
-
架构规范:区分基础运行模块与高阶扩展模块,预留向量检索、大模型升级接口
-
极简易部署:基于Streamlit快速搭建,代码简洁、无冗余依赖,新手可一键运行
二、项目整体架构与文件说明
2.1 完整目录结构
本项目采用模块化分层设计,职责解耦,兼顾可用性与扩展性,完整目录如下:
chatbot/
├── app_chat.py # 问答可视化前端界面(核心运行)
├── app_upload.py # 知识库文件上传界面(核心运行)
├── rag.py # RAG问答核心逻辑(核心运行)
├── knowledge_base.py # 知识库管理工具类(核心运行)
├── vector_stores.py # 向量库扩展模块(预留高阶功能)
├── config_data.py # 全局配置文件(预留高阶功能)
├── local_kb.txt # 自动生成-本地知识库存储文件
└── local_md5.txt # 自动生成-文件去重记录文件2.2 文件功能详细解析
核心运行模块(当前版本必需)
-
app_chat.py:系统问答前端页面,基于Streamlit实现多轮对话界面,展示用户提问与机器回答,记录对话历史,调用核心RAG问答接口。
-
app_upload.py:知识库上传专属界面,支持本地TXT文件上传,联动知识库工具类完成文件解析与存储。
-
knowledge_base.py:知识库管理核心工具,实现文件内容读取、本地持久化存储、MD5文件去重,避免重复上传冗余数据。
-
rag.py:RAG核心逻辑层,负责启动加载本地知识库、关键词检索匹配、问答结果返回,兼容后续LangChain链调用格式。
预留扩展模块(当前版本不启用,保留架构)
-
config_data.py:全局配置中心,预留向量库参数、文本分块参数、模型路径、项目路径等通用配置。当前轻量版本无需硬编码配置,后续升级向量检索、大模型功能时可直接启用,规范项目代码。
-
vector_stores.py:向量数据库管理模块,为高阶RAG功能预留。后续可接入Chroma、FAISS等向量库,搭配Embedding模型实现语义检索(替代当前关键词匹配),大幅提升问答智能度。
三、核心功能模块实现(代码框架讲解)
本文仅展示各模块核心代码框架与逻辑思路,剔除冗余重复代码,聚焦功能实现原理,方便读者理解与二次开发。
3.1 知识库管理模块(knowledge_base.py)
核心功能:接收上传文件内容、写入本地知识库、MD5哈希去重,保证知识库数据整洁,避免重复存储相同内容。
class KnowledgeBaseService:
# 文件上传、内容持久化、MD5去重核心方法
def upload_by_str(self, data: str, filename):
# 1. 将上传文本内容写入本地知识库文件
# 2. 计算文件MD5哈希值,校验是否已存在
# 3. 新增文件记录,返回上传状态提示
pass3.2 RAG核心问答模块(rag.py)
项目核心逻辑,实现知识库自动加载、关键词检索、问答应答,同时预留chain属性,兼容后续LangChain流式输出、大模型扩展。
class RagService:
def __init__(self):
# 项目启动自动加载本地知识库
self.knowledge_lines = self._load_knowledge_base()
# 读取本地知识库文件
def _load_knowledge_base(self):
# 异常捕获,处理文件不存在、文件为空场景
pass
# 核心问答匹配逻辑
def ask(self, question):
# 1. 校验知识库是否加载成功
# 2. 关键词遍历匹配知识库内容
# 3. 返回匹配结果或无数据提示
pass
# 兼容高阶扩展的链属性(预留功能)
@property
def chain(self):
# 适配流式输出、模型调用的伪链对象
pass3.3 上传界面模块(app_upload.py)
基于Streamlit实现可视化文件上传页面,初始化知识库服务,监听文件上传事件,实时返回上传结果。
import streamlit as st
from knowledge_base import KnowledgeBaseService
# 页面初始化与配置
st.title("知识库文件上传中心")
# 初始化会话服务
if "kb" not in st.session_state:
st.session_state.kb = KnowledgeBaseService()
# 监听文件上传并执行存储逻辑
uploaded_file = st.file_uploader("上传TXT知识库文件", type=["txt"])
if uploaded_file:
# 读取文件内容、调用上传方法、展示结果
pass3.4 问答对话界面模块(app_chat.py)
系统前端交互核心,实现页面渲染、对话历史记录、用户提问接收、问答结果展示,界面简洁流畅,支持多轮对话。
import streamlit as st
from rag import RagService
# 页面全局配置
st.set_page_config(page_title="本地RAG智能问答", page_icon="🧠")
st.title("🧠 本地知识库智能问答系统")
# 初始化RAG服务与对话历史
if "rag" not in st.session_state:
st.session_state.rag = RagService()
if "messages" not in st.session_state:
st.session_state.messages = []
# 渲染历史对话
for msg in st.session_state.messages:
# 展示用户/助手对话记录
pass
# 接收用户提问并返回答案
user_input = st.chat_input("请输入你的问题...")
if user_input:
# 保存提问、调用RAG问答、渲染回答结果
pass四、环境部署与项目运行
4.1 环境依赖安装
项目依赖极简,仅需安装Streamlit可视化框架,推荐使用虚拟环境部署,避免环境冲突。
# 创建虚拟环境
conda create -n chatbot python=3.10
# 激活环境
conda activate chatbot
# 安装核心依赖
pip install streamlit4.2 项目启动流程
项目分为上传服务和问答服务两个页面,需分别启动,分工明确:
# 启动知识库上传服务(默认8501端口)
streamlit run app_upload.py
# 启动智能问答服务(指定8502端口,避免冲突)
streamlit run app_chat.py --server.port 85024.3 完整使用流程
-
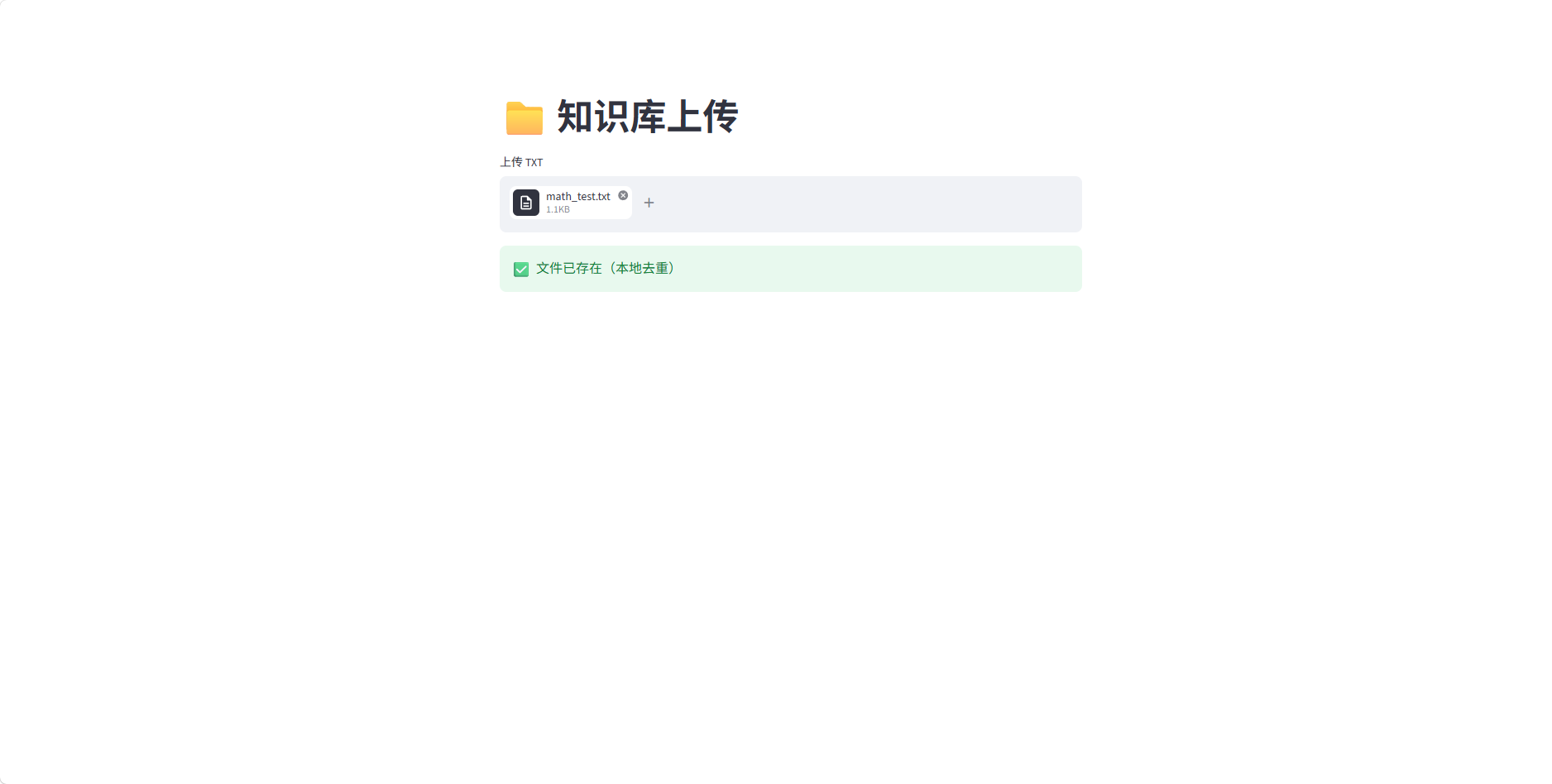
启动上传服务,上传自定义TXT格式知识库文件(如公式、知识点、笔记文档);
-
系统自动完成内容存储与去重,生成本地知识库文件;
-
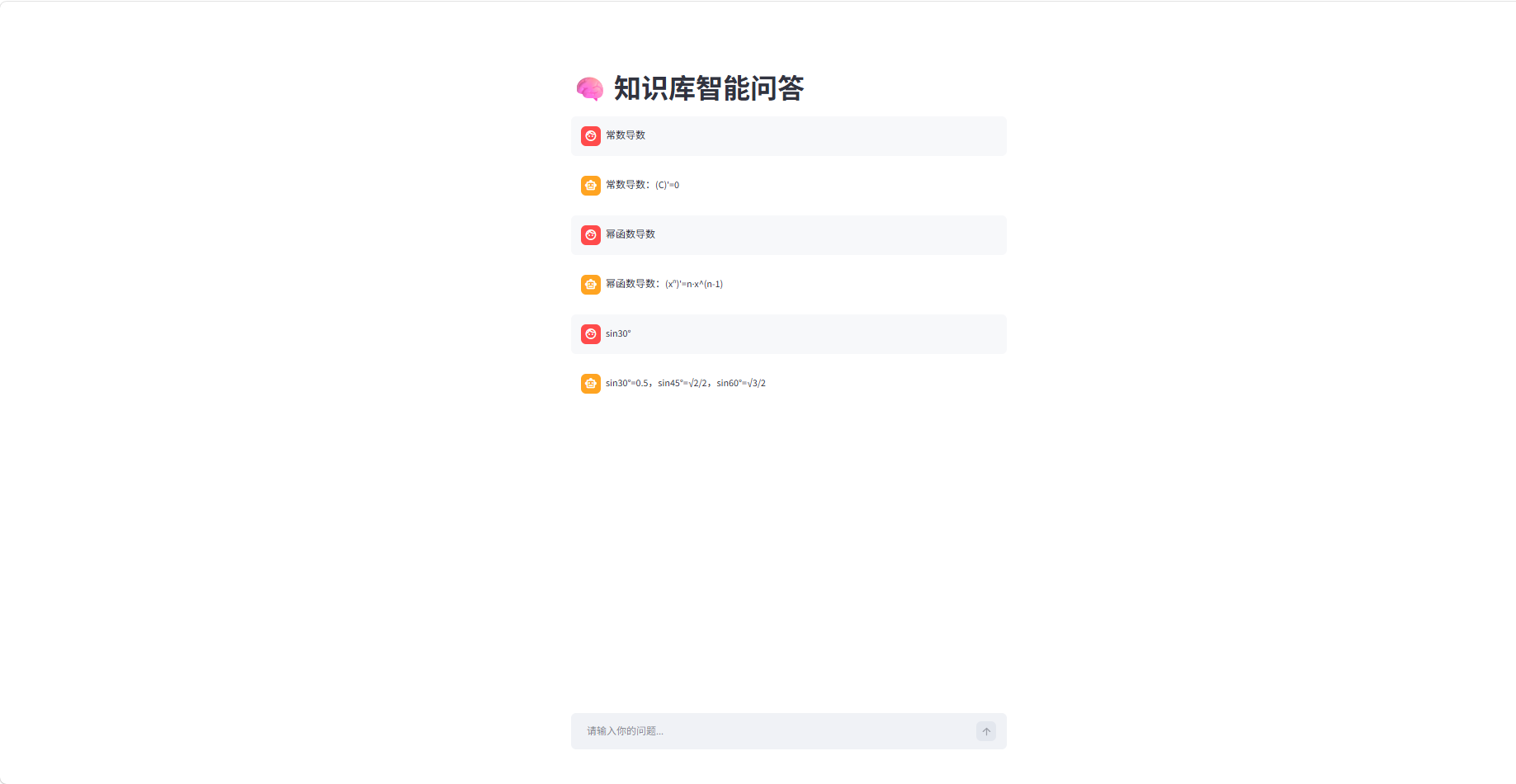
启动问答服务,输入相关问题,系统自动检索知识库并返回对应答案;
-
支持多轮连续问答,自动保存对话历史。
五、项目效果展示
六、项目优势与迭代扩展方向
6.1 项目核心优势
-
纯本地离线运行:无任何网络请求、无API密钥依赖,彻底解决接口报错、密钥失效问题;
-
优于传统文档查找:区别于Word本地查找,拥有完整RAG项目架构,可扩展语义检索、智能问答;
-
架构高可扩展:预留配置文件、向量库模块,无需重构代码即可升级高阶功能;
-
轻量化易上手:代码简洁、依赖极少,适合新手学习RAG核心原理。
6.2 后续迭代方向
-
启用
vector_stores.py模块,接入Chroma向量数据库+本地Embedding模型,实现语义检索,摆脱关键词精准匹配限制; -
接入本地开源大模型(Qwen、Llama等),实现真正的大模型智能生成回答,而非返回原文;
-
优化
config_data.py全局配置,统一管理分块大小、检索数量等参数; -
新增多文件知识库管理、对话历史导出、知识库在线编辑功能。
七、总结
本次复现的轻量本地RAG知识库问答系统,摒弃了传统RAG项目复杂的云端依赖与冗余配置,以轻量化、实用化、可扩展为核心,实现了文档上传、知识存储、智能问答的完整闭环。
项目既保留了标准RAG的架构规范,又适配新手学习与个人使用场景,解决了云端API依赖、隐私泄露、部署复杂等痛点。同时预留了完整的高阶扩展接口,可无缝升级为企业级语义问答系统,是非常优质的RAG入门实战项目。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)