越大越好?Chinchilla说:你可能练错了

2020年,OpenAI发布了一篇轰动业界的论文——Scaling Laws。它的核心结论简单粗暴:想要更强的模型,就堆更多的参数。一时间,全行业都在疯狂造大模型,千亿参数成了标配,万亿参数也不是梦。
然后DeepMind站出来说:等一下,你们可能搞错了。
这就是今天要聊的这篇论文——Chinchilla,全名《Training Compute-Optimal Large Language Models》。它用一个精妙的实验设计,给整个行业上了一课。
大模型的「营养失衡」问题
打个比方。假设你在健身,Scaling Laws告诉你「举更重的铁就能变强」。于是你疯狂加重量,从50公斤加到200公斤——但每天只吃一顿饭。
问题很明显:你的肌肉(模型参数)确实在增长,但你的营养(训练数据)远远跟不上。你不是变强了,你只是变得又大又虚。
这就是Chinchilla论文最核心的发现:**当时的GPT-3,以及一大批大模型,都处于「欠训练」状态。**参数量上去了,但训练数据根本没喂够。
想想GPT-3:1750亿参数,但训练数据只有大约3000亿token。按照Chinchilla的结论,这个数据量大概只够「喂饱」一个150亿参数左右的模型。差距足足有一个数量级。
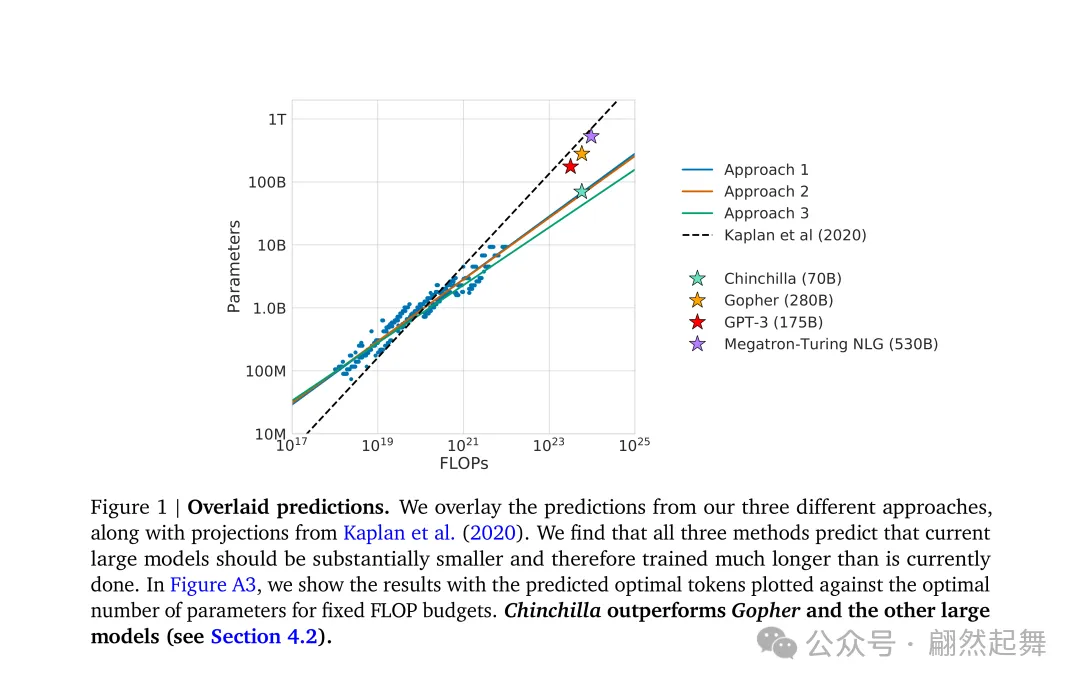
三种方法(Kaplan、IsoFLOP、Chinchilla)对最优模型大小和数据量关系的预测(来源:原论文Figure 1)
怎么发现这个问题的?
DeepMind的做法非常工程化。他们在不同的计算预算下(从小的到超大的),训练了超过400个模型。每个计算预算下,都尝试了不同的「模型大小 vs 数据量」组合。
然后他们画出了一条等损耗曲线(iso-loss contour),就像地形图上的等高线。这条曲线清楚地告诉你:给定一个计算预算,模型该多大、数据该多少,才能达到最优。
结论非常清晰:**模型参数量和训练数据量应该大致按1:1的比例增长。**也就是说,如果你的模型翻一倍,训练数据也应该翻一倍。而不是像之前大家做的那样,模型参数增加五倍多,而数据量只增加不到两倍。
用更技术的话说,Scaling Laws提出的幂律关系是 N^0.74 和 D0.26,也就是算力增长时,模型规模的增长幅度占主导(指数为0.74),而数据量的增长幅度较小(指数为0.26)。而Chinchilla修正了这个比例——应该大约各占一半:N0.50 和 D^0.50。
实战证明:小模型+大数据 = 碾压
光说理论不够,DeepMind直接拿结果说话。
他们之前训练了一个叫 Gopher 的模型:2800亿参数,用3000亿token训练。这是当时DeepMind的旗舰,各项指标都很能打。
然后他们按照Chinchilla的最优配比,训练了 Chinchilla:只有700亿参数(Gopher的四分之一),但用了1.4万亿token的训练数据(将近Gopher的4倍)。
结果?Chinchilla在几乎所有benchmark上全面碾压Gopher。
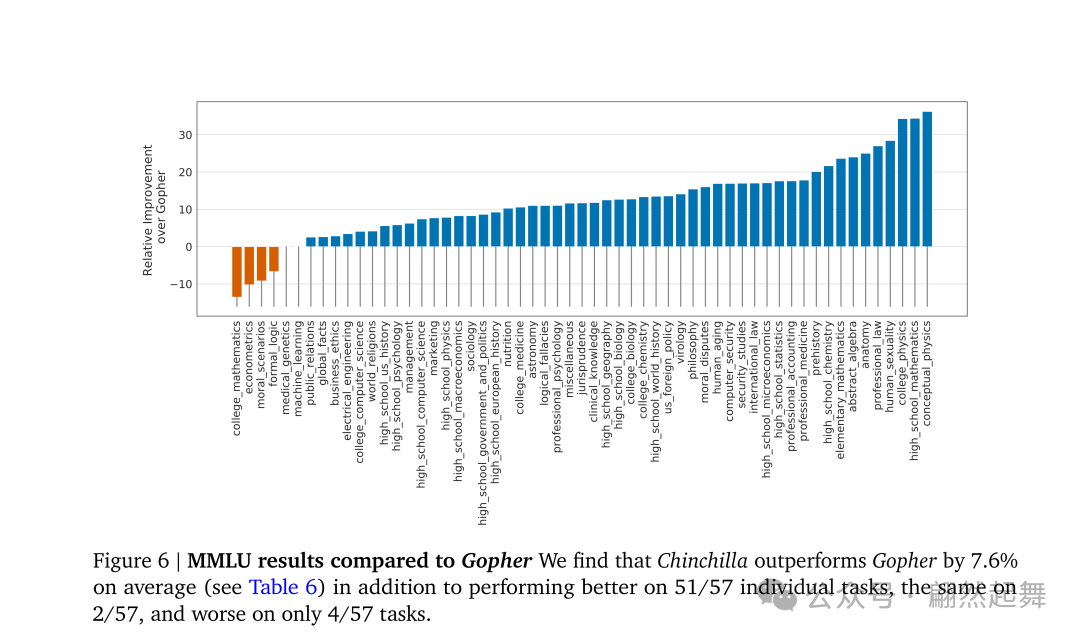
Chinchilla在MMLU各科目上相对Gopher的提升(来源:原论文Figure 6)
打个比方,这就像一个体重70公斤但训练充分的拳手,在擂台上轻松击败了一个体重280公斤但训练不足的巨汉。参数量小了四分之三,反而更强。
更关键的是,Chinchilla的推理成本只有Gopher的四分之一。又强又便宜,没有比这更香的了。
这对行业意味着什么?
Chinchilla的影响是深远的,几乎重塑了大模型的训练范式。
第一,数据是比参数更稀缺的资源。 之前大家疯狂堆参数,却忽略了数据的重要性。Chinchilla之后,高质量训练数据的收集和清洗成了核心竞争力。现在回头看,为什么各个大厂都在拼命搞数据质量,源头就在这里。
第二,小模型路线被正名。 Meta的LLaMA就是Chinchilla理念的直接践行者——用相对较小的模型(7B到65B),但在海量高质量数据上充分训练。结果大家都看到了,LLaMA系列成为了开源社区的基础,衍生出了无数优秀模型。
第三,推理效率的重要性被凸显。 一个700亿参数的模型和2800亿参数的模型效果相当,但部署成本差了四倍。对于实际落地的工程系统来说,这意味着真金白银。
当然,后来的研究也发现了一些Chinchilla没考虑到的问题。比如,如果你想训练一个模型后持续用很久,那在固定参数量下过训练(over-training)是划算的——推理成本会伴随模型整个生命周期,多花点训练算力换来更小的模型是值得的。这可以理解为Chinchilla的「推理成本修正版」,但核心思路没有变:数据量必须跟得上。
工程上的直觉
作为工程师,我从Chinchilla里得到的一个直觉是:在做任何系统优化时,要注意瓶颈在哪里。Scaling Laws时代的行业瓶颈是模型容量不够,但当大家把模型容量堆上去之后,瓶颈悄悄转移到了数据上。
这很像我们做性能优化——先把CPU优化到极致,结果发现瓶颈跑到了IO上。如果你还在拼命优化CPU,收益会越来越小。同样的道理,如果你还在拼命堆参数而不去搞数据,你的模型也只会「又大又虚」。
Chinchilla的价值不在于它给出了一个绝对精确的公式,而在于它及时提醒了整个行业:该换瓶颈了。
论文链接:https://arxiv.org/abs/2203.15556
kk的大模型论文学习笔记 · 第7篇 · Chinchilla

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)