AI小白必看!40分钟搞懂大模型、Token、API、Prompt等核心概念
本文系统讲解了AI领域的基础概念,包括大模型(LLM)的工作原理、关键参数、幻觉问题,以及Token、API、Prompt、温度等使用要点。此外,还介绍了Agent、Function Calling、Skill、微调和RAG等技术,并针对不同场景给出了模型选型建议。文章旨在帮助读者建立完整的AI概念地图,避免被市场信息碎片化误导,从而更好地理解和应用AI技术。
今天中午12点,我做了一个AI咨询。
客户是一个计算机专业的学生,研究生方向是知识图谱、RAG、深度学习这些AI领域。
按说,计算机/AI相关专业的学生,对这些概念应该比普通人清楚对吧?
结果聊了40分钟,我发现她对这些基础概念的理解,其实和我平时接触到的很多小白差不多——大模型是什么?Token是什么?Agent和大模型有什么区别?API和Prompt又是什么?微调是什么?
全是模糊的。
我意识到一个很残酷的事实:哪怕你是相关专业的学生,如果不是在这个行业里每天泡着,这些概念也只是一个个"听过但不太懂"的词。
所以有了这篇文章。
我想系统地把这些概念讲清楚。不是那种教科书式的定义轰炸,而是从最底层开始,一层一层往上搭,让你看完之后脑子里有一个完整的概念地图。
你可能不需要用AI写代码,但了解这些,至少不会被人割韭菜。

一切的核心:大模型
大模型(Large Language Model,简称LLM)是所有AI应用的基础。
怎么理解它?
大模型就是一个"超级接话茬机器"。
你给它一句话,它根据它学过的海量数据,推测出最合理的下一句话是什么。
它不"理解"你在说什么,它只是极其擅长预测"在这个上下文里,最应该出现的文字是什么"。
但因为它训练时读过的数据量实在太大了——整个互联网的文本,几万亿个字——所以它"猜"出来的东西,看起来就像真的理解了一样。
大模型有几个关键参数你需要知道:
参数量。这是大模型"大"的体现。几十亿到几千亿的参数,相当于模型里几万亿个微小的"旋钮"。训练的时候,这些旋钮被反复拧到最合适的位置,让模型的预测越来越准。参数量越大,模型理论上越"聪明",但也意味着更贵、更难部署。
上下文长度。大模型能"记住"的对话历史长度。早期的GPT-4只有8K(约6000个汉字),现在最新的模型已经支持128K甚至1M。上下文越长,你就能一次性塞进去更多的背景信息。
训练 vs 推理。
- 训练(Training):给模型喂海量数据,让它学会预测。这个过程非常昂贵,OpenAI训练GPT-4据说花了上亿美元。
- 推理(Inference):模型训练好了之后,你用它回答问题。每次对话都是一次推理。推理的成本比训练低得多,但也是按量收费的。
多模态。早期的大模型只能处理文字。现在的模型可以同时处理文字、图片、音频、视频。你给它一张图,它能说出图里是什么——这就是多模态能力。
但有一点我必须强调——大模型有一个非常致命的问题:幻觉。
幻觉(Hallucination) 就是大模型会"编造"事实。
它说得头头是道,但内容可能是假的。不是它想骗你,是它的工作机制决定的——它本质上是"预测下一句话",不是"从数据库里查事实"。对它来说,"编造一个合理的回答"和"说出事实"没有本质区别。
所有大模型都有幻觉,只是程度不同。越强的模型幻觉越少,但不可能完全消除。所以你在用AI处理重要信息(法律条款、医疗建议、财务数据)时,一定要人工核实。
减轻幻觉的常见方法:
- RAG(后面会讲):让AI"先查资料再回答"
- 更好的Prompt:要求AI引用来源,不确定就说不知道
- 选更可靠的模型:付费闭源模型比免费开源模型幻觉少
这是使用AI最重要的一条认知——你可以把TA当助手,但别当"真理机器"。
好,大模型是整个AI世界的"地基"。那它怎么收费?

大模型的计价单位:Token
Token(令牌)是大模型世界里最基础的计价单位。
怎么理解?
你把一句话发给大模型,它不是按"字"算的,是按"词块"算的。
比如"我今天很开心",会被拆成"我"、“今天”、“很”、"开心"这样的Token。英文里一个Token大概对应0.75个单词,中文里大概1-2个字一个Token。
你的每一次提问(输入)和模型的每一次回答(输出),都要消耗Token。比如你用ChatGPT问了一个问题,你的问题可能消耗了100个Token,ChatGPT返回的回答消耗了500个Token,总共600个Token。
不同模型的价格天差地别。
国内模型:DeepSeek的API价格极低,百万Token可能只要几块钱,日常使用几乎感觉不到成本。
国外顶级模型:Claude或GPT-4,百万Token可能要几十到上百块钱。
所以为啥我给学生推荐DeepSeek当主力?因为做课程作业一个月可能都花不到10块钱。
**省Token的核心技巧:把你想要什么说清楚。**模糊的需求导致多轮反复对话,每一轮都在消耗Token。一次把背景、目标、约束、示例都说清楚,反而最省钱。
好,大模型有了,Token知道了。那我怎么用上大模型呢?

调用的通道:API
API(Application Programming Interface,应用程序接口)是让你能用上大模型的通道。
大模型本身是一串代码和数据,它自己生活在你碰不到的服务器里。你没有办法直接"访问"它。
但大模型公司会开一个"门"给你——这就是API。
具体来说:
- 你去大模型公司(比如DeepSeek、OpenAI)注册一个账号
- 拿到一个API Key(相当于你的身份验证钥匙)
- 你的程序通过API Key,向API地址发送请求
- API把请求转给大模型
- 大模型处理完,API再返回结果给你
所以每次你使用Claude Code、Cursor这些工具,本质上都是:
工具 → API → 大模型 → API → 工具
API Key还有一个好处:同一个模型可以创建多个Key。你可以一个给自己用,一个给同事用,一个给测试环境用,账单分开算,方便管理。
所以API是"通道",Token是"过路费"。明白了吧?
那过了这个通道,你发给大模型的消息叫什么?

指挥大模型的语言:Prompt
Prompt(提示词)就是你发给大模型的指令。
你可以跟它聊天,也可以让它帮你写代码、写文章、分析数据。你给它的所有内容——问题、背景信息、格式要求——统称为Prompt。
很多人以为写Prompt很玄学,其实核心就4个要点:
说清背景。你是谁?你在什么场景下?比如"我是一个大二学生,在做人工智能课程作业"——让大模型知道你是什么水平、什么需求。
说清目标。你要什么结果?“帮我实现一个简单的知识图谱构建脚本”——越具体越好。
说清约束。有什么限制?“用Python,不要用第三方库,要有中文注释”——没有约束,大模型可能用你不想要的方式实现。
给示例。最好给一个输入和输出的例子。大模型是模式匹配大师,给一个例子比说一百句描述更有效。
以前Prompt技巧很重要,因为早期的大模型比较笨,你得小心翼翼地"引导"它才能答好。但现在的大模型越来越聪明,表达能力越来越强,对Prompt的要求反而降低了。你自然地说出需求就行,不需要学什么"Prompt工程"。
还有一个实用参数你可能会经常遇到——温度。
温度(Temperature) 控制大模型的"创造性"。取值从0到2,数值越大回答越随机越有创意,数值越小越保守越准确。
低温度(0.1-0.3):适合写代码、数学计算、事实问答。它胆最小,只敢说最有把握的答案。
高温度(0.8-1.5):适合写文案、头脑风暴、创意写作。它放飞自我,敢说点不一样的。
日常使用(0.5-0.8):平衡模式,大多数场景够用。
所以如果你发现AI写的文案太"套路",可以试试把温度调高一点。如果你发现它写Python代码经常编些不存在的函数,把温度调低一点。
那问题来了:如果大模型只能"说"不能"做"怎么办?

能动手的AI:Agent
这是很多人最混淆的概念——大模型和Agent到底什么区别?
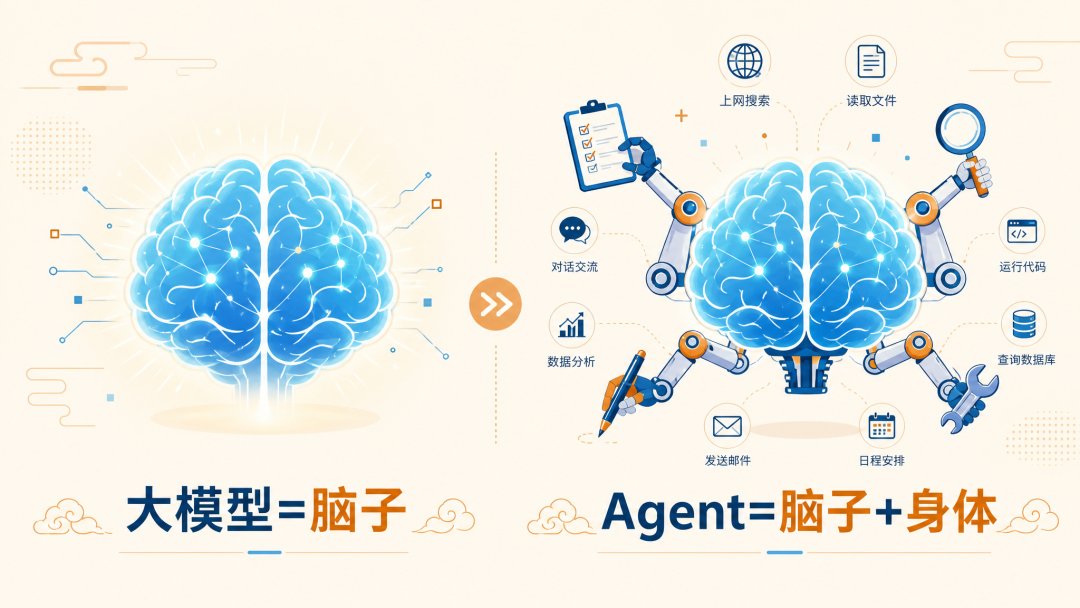
大模型 = 脑子。它只能思考,不能行动。
你跟大模型说"帮我把这个文件夹里的全部文件整理一下",它可能会给你一个Python脚本让你自己跑。因为它没有"手",它只负责"想"。
Agent = 脑子 + 身体。
Agent是在大模型的基础上,给它装上了工具调用能力——读文件、写文件、执行命令、搜索网络、操作数据库。它不再只是"说",而是真的"做"。
Agent背后的核心技术叫 Function Calling(函数调用/工具调用)。大模型判断需要做什么事,输出一个结构化的指令(比如"调用read_file函数,参数是./data.txt"),系统收到这个指令后执行对应操作,把结果返回给大模型,大模型再整合成回答呈现给你。整个过程对用户来说是一句话的事,后台其实是大模型+Function Calling+工具链在协作。
现在流行的AI编程工具全是Agent:
Claude Code。综合能力最强、生态最好的代码Agent。装在你的终端里,你说"帮我重构这个项目",它就真的开始读代码、写代码、跑命令。我日常重度使用。
Codex(OpenAI出的)。写代码能力很强,跟Claude Code类似,也是终端里的Agent。
Cursor。比较早期的AI编程IDE。坦白说现在有点落伍了,不如Claude Code和Codex。
这三个都是Agent。它们的共同点是:“你说需求,AI直接动手。”
这其实是非常大的一个跨越。以前你用AI只能"问",现在你可以让AI"干"。
那这些工具的"技能拓展"又是什么?

拓展AI的能力:Skill
Skill(技能包)可以理解为AI的"插件"或"扩展包"。
大模型本身是个"通才"——它什么都知道一点,但什么都不精。你可以通过安装Skill,让它在特定领域表现更好。
比如,装一个「文档处理」Skill,AI就更擅长处理PDF、Word文档。装一个「文章配图」Skill,AI就懂得怎么给你的公众号文章配图。
最简单的理解:Skill = 分类存储的高级提示词。
它告诉AI:“当你在做这件事的时候,参考这套规则和方法论,而不是泛泛地回答。”
用过iPhone的人,可以把Skill理解成App Store——你需要什么功能,就下载对应的"应用"。
有经验的人,可以自己写Skill,把团队的最佳实践固化进去。没经验的人就先用别人写好的。这就是经验的差别——Skill本质上是经验的数字化。你有经验,就能让AI按你的方式来。没经验,也能用,但容易走弯路。
好,那如果通用大模型不够用,想让它在特定领域更专业怎么办?
定制化训练:微调
微调(Fine-tuning)就是用你自己的数据,对已经训练好的大模型做"二次训练"。
听起来高大上,其实本质就是:大模型预训练的时候学的是通用知识。微调就是给它补充专业知识。
比如一个医疗大模型,基座是GPT-4,然后用100万份病历数据做微调,它看病的能力就比通用大模型强得多。
但微调有几个硬伤:
贵。需要显卡(至少A100级别),需要训练数据,需要工程师调参。对企业来说少则几万,多则上百万。
慢。一次微调可能跑几天甚至几周。
维护成本高。模型更新了,你得重新微调。
所以对我来说,我一直给个人用户和小团队的建议是:现阶段不需要做微调。
对99%的个人用户来说,直接用好大模型的通用能力+写清楚Prompt,就已经够用了。微调是企业的活,不是你的。
那如果不微调,又想让它更理解你的业务,怎么办?
RAG:微调的平替
RAG(Retrieval Augmented Generation,检索增强生成)是这两年最火的技术方案之一。
原理很简单:不改变大模型本身,而是让它在回答问题的时候,先去你的知识库里查资料。
RAG背后依赖的技术叫 Embedding(向量化)——就是把文字变成一串数学向量(一串数字)。意思相近的文字,它们的向量距离更近。比如"怎么退款"和"退货流程介绍",词完全不同,但语义相近,Embedding能识别出它们是一类问题。
RAG的工作流程:
- 先把你的知识库文档全部做Embedding,存到向量数据库
- 收到一个问题,也做Embedding
- 去向量数据库里找"长得最像"的文档片段
- 把找到的片段+你的问题,一起喂给大模型
- 大模型基于这些资料回答问题
想象一下:你问AI"我们的退款政策是什么?"
- 不搞RAG:AI根据自己的训练数据回答,可能会编一个不存在的政策。
- 搞了RAG:AI先去你的公司文档库里搜索"退款政策",找到相关条目,再基于这些真实信息回答。
RAG的好处是很明显的:
1. 不需要训练。只要把文档放进去就行。
2. 随时更新。更新文档,回答立即生效。
3. 可控。AI的每个回答都有依据来源,不是拍脑袋编的。
所以对于做AI课程作业的学生来说,如果项目是RAG方向的,这其实是一个非常实用且有市场需求的技术——很多企业都在做RAG,因为它成本低、效果好。
这么多模型,到底选哪个?
最后说说模型选型。
现在市面上的大模型多到让人眼花缭乱。我的建议很简单:分场景选。
日常学习/写作业:首选DeepSeek。性价比之王,国内编程模型里数一数二,API价格极低。学生做课程作业一个月花不到10块钱。我推荐用V10 Pro版本,性能和价格的平衡点非常好。
预算充足想包月:可以考虑MiniMax。29-50元/月,适合用量大的场景。一个月超过50-100元的用量时切换过来更划算。
追求高质量输出:智谱GLM-5.1,44元/月(需要抢名额)。国内质量最好的模型之一。Kimi 2.6也不错,长文本能力突出,适合读论文。
商业变现场景:才需要考虑GPT-4或Claude。按Token计费,实际使用下来月花费可能上万。个人用户和学生完全不用考虑。
还有一个选择维度:开源 vs 闭源。
开源模型(DeepSeek、Llama、Qwen):免费、可以下载到自己的服务器跑、数据不出门。对注重隐私的企业来说很有价值。对普通用户来说,最直接的好处是便宜甚至免费。
闭源模型(GPT-4、Claude):付费使用,只能通过API调用。通常能力更强、服务更稳定,但不方便做深度定制。
对个人用户来说,不需要纠结这个。好用的闭源模型直接用,DeepSeek这样的开源模型也非常好。选能力够用的就行。
一个实用的原则:模型也在快速迭代,不用追求"最新最强"。选一个能力够用、价格合适的,用熟它,比频繁换模型效果好得多。
一张图总结
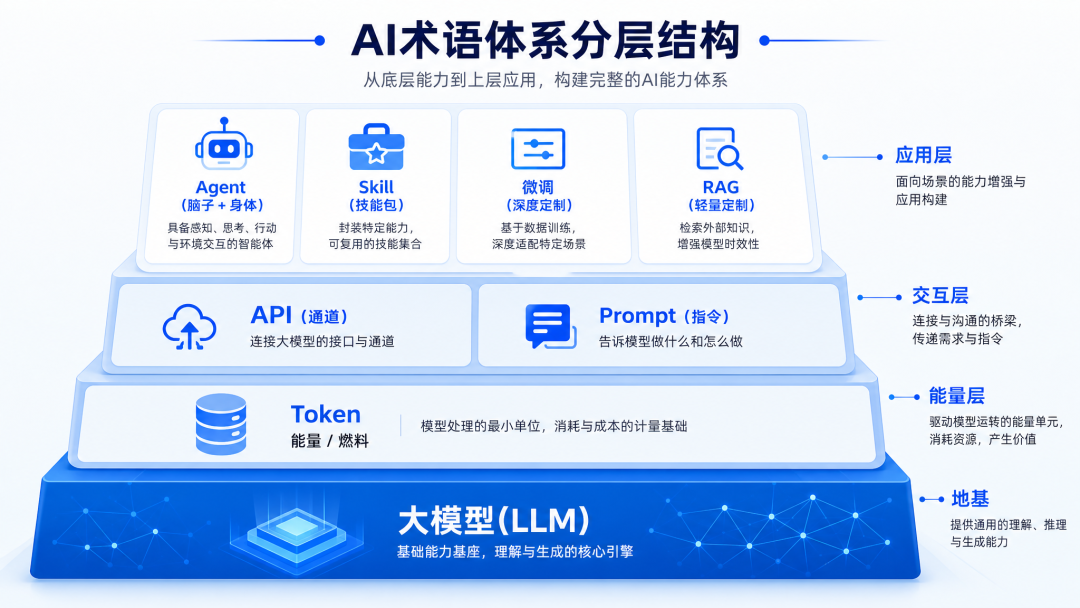
如果要把所有概念串起来,关系大概是这样:
1. 大模型(LLM)是地基——一个经过海量数据训练的文字预测引擎
2. Token 是它的燃料——每次使用都在消耗,按量付费
3. API 是通道——程序通过它调用大模型
4. Prompt 是你对大模型说的话——背景、目标、约束、示例
5. 温度 是创造力的旋钮——调高更有创意,调低更准确
6. 幻觉 是它的天生缺陷——它可能编造事实,记得核实
7. Agent 是装了身体的大模型——能思考,也能动手操作
8. Function Calling 是Agent的"手"——告诉系统去调用什么工具
9. Skill 是它的技能包——按需加载的专业能力
10. Embedding 是把文字变向量的技术——让机器懂语义
11. 微调 是深度定制——花大钱让模型更懂你
12. RAG 是轻量定制——不给模型动手术,只给它装个知识库
这些都是相互配合的,不是一个取代另一个的关系。
比如我现在写这篇文章:用Claude Code(Agent)通过API调用DeepSeek(大模型),消耗Token,写好Prompt,配合专门的写作Skill,最后成文。
你没发现吗?上面这句话,囊括了这篇文章的核心概念。再加上温度、幻觉、Embedding、Function Calling——整张概念地图就完整了。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)