【从 while 循环到可视化智能体:深入拆解 Agent Loop、Codex 风格工具调用、OpenClaw 与 Hermes 背后的技术细节】
关键词:Agent Loop、AI Agent、Codex、OpenClaw、Hermes、Tool Calling、Function Calling、OpenAI SDK、SSE 流式输出、工具调用、智能体框架、Python Agent、FastAPI、gpt-image-2
项目地址:https://gitee.com/xiaoyun2003/simple-agent-loop
1. 为什么要理解 Agent Loop
很多人第一次接触大模型应用时,看到的是一个聊天框:
用户输入问题 -> 大模型生成回答
这种模式适合问答、改写、翻译、总结,但它有一个明显边界:模型只能根据上下文“说”,不能真正“做”。
比如用户问:
帮我查看当前项目有哪些文件,并运行 python --version。
普通聊天机器人如果没有工具能力,只能猜测或者拒绝。但 Agent 可以这样工作:
- 理解用户目标。
- 判断需要调用工具。
- 调用
list_files查看目录。 - 调用
run_command执行命令。 - 获取真实工具结果。
- 把结果交给模型总结。
- 最终回答用户。
这里的关键,就是 Agent Loop。
Agent Loop 不是某个框架独有的概念,而是一种通用控制结构:
让模型在一个循环中不断决策,程序负责执行工具,工具结果再回到模型上下文中。
本文结合一个教学项目 SimpleAgentLoop,从工程实现角度详细拆解 Agent Loop 的核心技术细节。
如果你最近关注过 Codex 风格的编程智能体、OpenClaw 这类开源 Agent 项目、Hermes 这类模型/Agent 生态关键词,背后的核心问题其实很相似:大模型如何从“会说话”变成“能规划、能调用工具、能观察结果、能继续完成任务”的智能体系统。
本文不追逐概念,而是用一个从零实现的小项目,把这些关键词背后的底层技术拆开讲清楚。
2. 项目简介
这个项目是一个用于教学演示的 Python Agent Loop,实现了一个完整但轻量的智能体闭环。
它支持:
.env配置模型地址、API Key、模型名称- OpenAI SDK 兼容格式请求
- Chat Completions 流式输出
while循环驱动 Agent- 模型自动发起工具调用
- Python 执行真实工具函数
- 命令执行、文件读取、文件发送、图片生成
- SSE 推送工具过程和文本增量
- 前端聊天页面
- 每条 Agent 回复上方展示工具过程
- 工具调用过程支持折叠和展开
gpt-image-2图像生成工具- Codex 风格的工具步骤 UI:默认折叠工具过程,需要时展开查看参数和结果
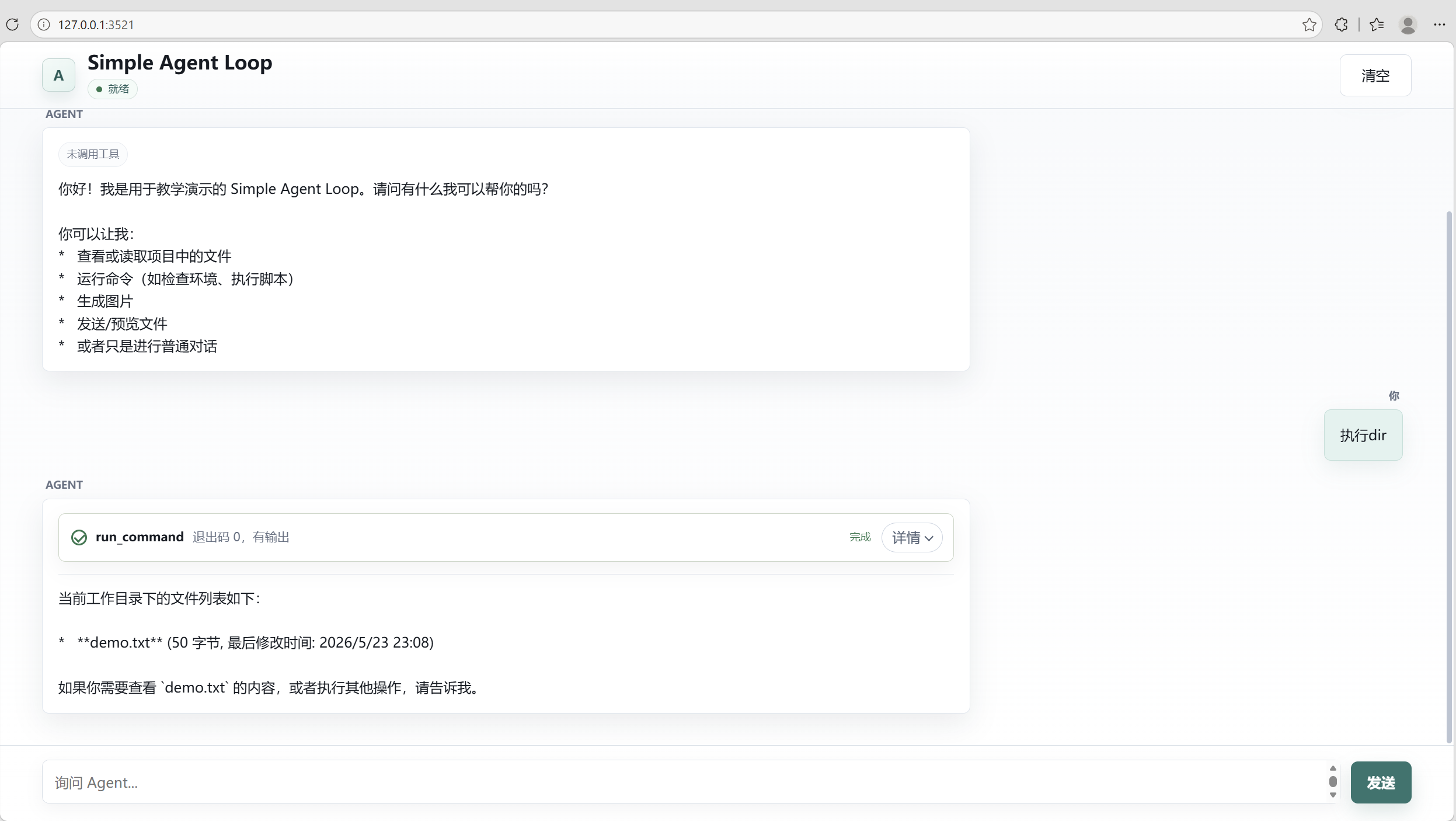
下面是项目实际运行界面。可以看到页面采用全屏聊天工作台布局,Agent 回复上方展示工具过程,正文在下方流式输出。
项目目录:
SimpleAgentLoop/
app/
agent_loop.py # Agent Loop 主循环
llm_client.py # OpenAI SDK 流式请求封装
tools.py # 工具注册、Schema、执行逻辑
attachments.py # 文件附件登记和访问
server.py # FastAPI 接口、SSE、静态页面
config.py # .env 配置加载
static/
index.html # 聊天页面结构
app.js # SSE 解析、消息渲染、工具折叠
styles.css # 全屏聊天工作台样式
docs/
TECHNICAL_DESIGN.md
DESIGN_SPEC.md
CSDN_AGENT_LOOP_BLOG.md
3. Agent Loop 到底是什么
最小的 Agent Loop 可以抽象为下面这段伪代码:
messages = [system_prompt, user_message]
while step < max_steps:
response = llm(messages, tools=tool_schemas)
if response.has_tool_calls:
messages.append(response.assistant_message)
for tool_call in response.tool_calls:
result = execute_tool(tool_call.name, tool_call.arguments)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result,
})
continue
return response.content
它的本质是一个 控制循环:
模型决策 -> 程序执行 -> 结果回填 -> 模型继续决策
下面这张图展示了 Agent Loop 的核心控制流。注意图中的虚线回路:只要模型继续返回 tool_calls,后端就会继续执行工具并把结果回填;直到模型返回普通文本,本轮对话才结束。
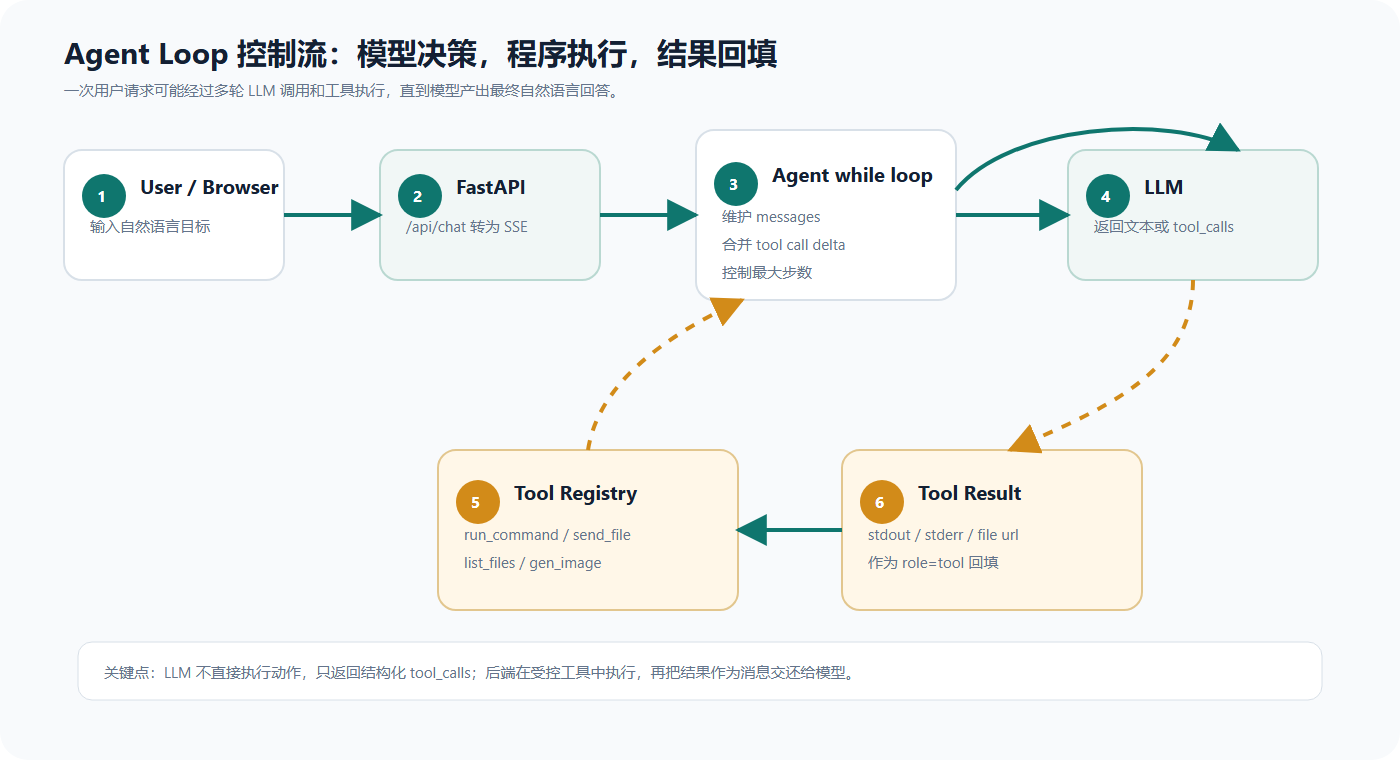
和普通聊天相比,Agent Loop 多了三个关键环节:
| 环节 | 作用 |
|---|---|
| Tool Schema | 告诉模型有哪些工具、每个工具需要什么参数 |
| Tool Execution | 后端根据模型返回的工具调用执行真实函数 |
| Tool Result Message | 把工具结果作为 role=tool 消息放回上下文 |
也就是说,模型不是直接操作系统,而是生成一个结构化请求。真正执行动作的是我们写的程序。
这点非常重要,因为它决定了 Agent 的安全边界:
模型只能请求工具,工具是否执行、怎么执行、能访问什么资源,都由程序控制。
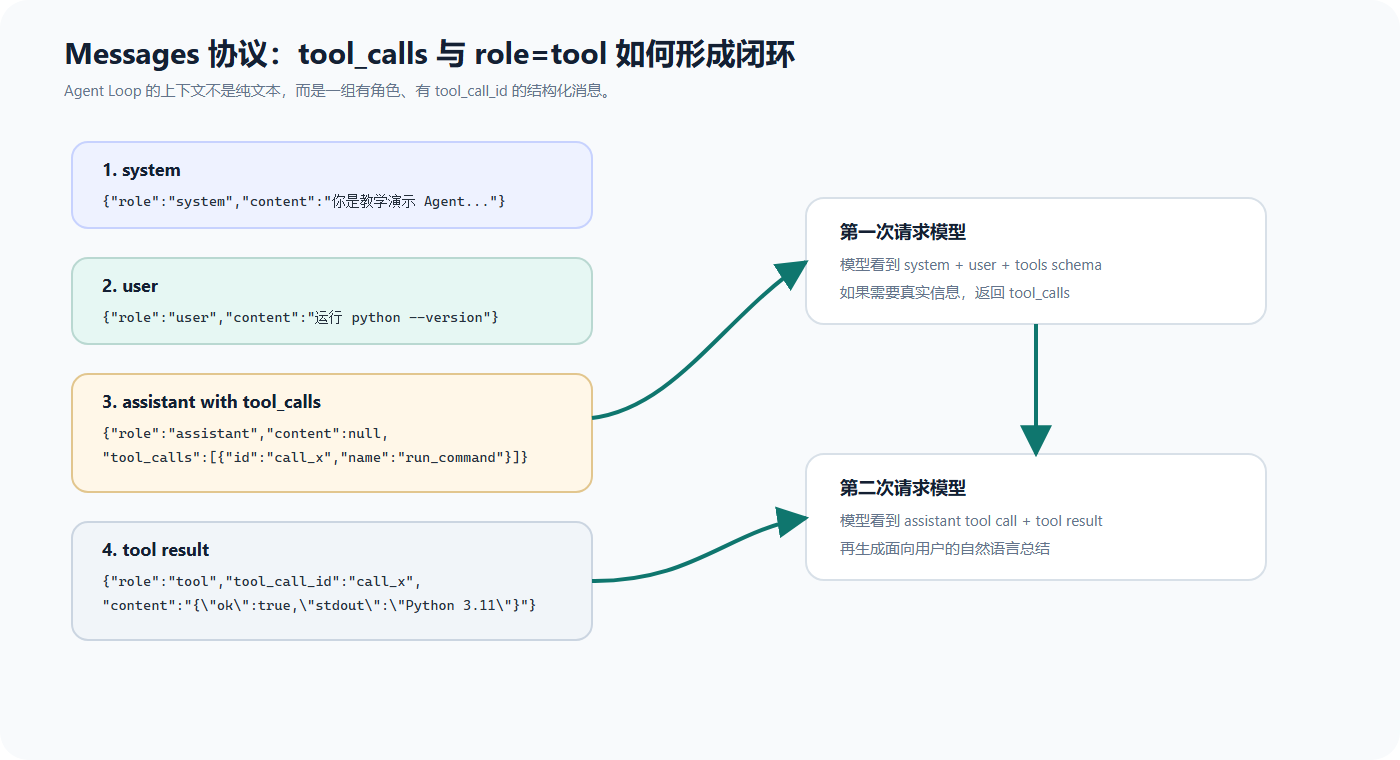
4. Agent Loop 的消息协议
Agent Loop 的核心数据结构是 messages。
在 OpenAI Chat Completions 风格中,一轮对话通常由不同角色的消息组成:
[
{
"role": "system",
"content": "你是一个用于教学演示的 Agent。"
},
{
"role": "user",
"content": "运行 python --version"
}
]
当模型决定调用工具时,会返回一条 assistant 消息,但这条消息不是普通文本,而是带有 tool_calls:
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_xxx",
"type": "function",
"function": {
"name": "run_command",
"arguments": "{\"command\":\"python --version\"}"
}
}
]
}
后端执行工具后,需要追加一条 role=tool 消息:
{
"role": "tool",
"tool_call_id": "call_xxx",
"name": "run_command",
"content": "{\"ok\":true,\"stdout\":\"Python 3.11.0\"}"
}
然后再次请求模型。模型就能看到:
- 用户想运行命令。
- 它刚刚请求了
run_command。 - 工具返回了真实结果。
于是模型再生成自然语言回答:
当前 Python 版本是 3.11.0。
这就是 Agent Loop 的消息闭环。
下面这张图把消息协议拆成了四层:system 约束行为,user 表达目标,assistant.tool_calls 发起工具请求,tool 消息承载真实执行结果。Agent Loop 的关键就是维护好这组消息。
5. 为什么一定要把工具结果放回 messages
有些初学者会问:工具执行完之后,后端直接把结果展示给用户不就行了吗?为什么还要再发给模型?
因为工具结果通常是原始数据,而用户需要的是解释后的答案。
例如命令输出:
Python 3.11.0
这个结果很短,直接展示也可以。但如果输出是:
systeminfo
pip list
pytest result
git diff
log file
用户真正想要的往往不是原始输出,而是:
- 这条命令是否成功?
- 关键信息是什么?
- 有哪些异常?
- 下一步应该怎么做?
这些解释工作适合交给模型完成。
所以 Agent Loop 的设计不是“工具替代模型”,而是:
工具负责拿到真实世界的数据,模型负责理解和表达。
6. 工具 Schema:模型如何知道能调用什么
模型能调用工具,是因为我们在请求中把工具列表传给它。
以 run_command 为例,工具 Schema 大致如下:
{
"type": "function",
"function": {
"name": "run_command",
"description": "Run a shell command in the configured workspace.",
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "Command to execute."
},
"cwd": {
"type": "string",
"description": "Optional relative working directory under the workspace."
}
},
"required": ["command"]
}
}
}
这里有三个重点:
name是模型返回工具调用时使用的函数名。description决定模型什么时候倾向于调用这个工具。parameters用 JSON Schema 约束参数结构。
一个工具描述写得好不好,会直接影响模型是否正确调用工具。
例如:
Run a shell command.
这个描述太宽泛,模型可能滥用。
更好的描述是:
Run a shell command in the configured workspace and return exit code, stdout, and stderr. Use this only when a command is necessary. On Windows this tool runs PowerShell.
它告诉模型:
- 命令只能在工作区运行
- 返回值包含哪些字段
- 只有必要时才调用
- 当前环境是 PowerShell
这些信息能显著提升工具调用质量。
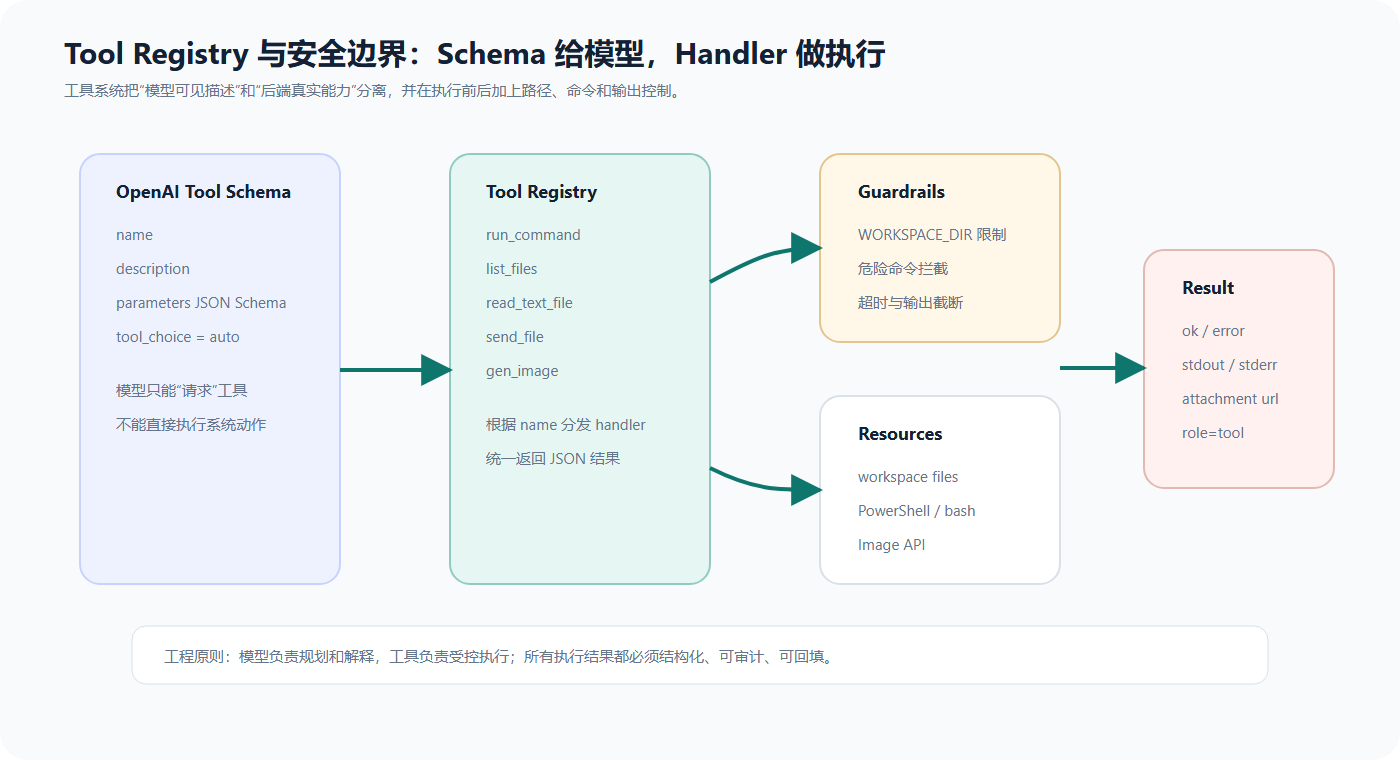
7. 工具注册表:把 Schema 和 Python 函数绑定起来
项目中使用 ToolRegistry 管理工具。
每个工具包含四个字段:
@dataclass(frozen=True)
class Tool:
name: str
description: str
parameters: dict[str, Any]
handler: ToolHandler
也就是:
| 字段 | 作用 |
|---|---|
name |
工具名称 |
description |
模型可见的工具说明 |
parameters |
JSON Schema 参数定义 |
handler |
Python 真实执行函数 |
注册工具时:
self.register(
Tool(
name="run_command",
description="Run a shell command ...",
parameters={...},
handler=self._run_command,
)
)
模型请求工具时,只会返回工具名和参数:
{
"name": "run_command",
"arguments": {
"command": "python --version"
}
}
后端通过工具名找到对应 handler:
tool = self._tools.get(name)
return await tool.handler(arguments)
这种设计的好处是很清晰:
- Schema 是给模型看的
- handler 是给程序执行的
- 注册表负责二者映射
后续新增工具,只需要注册一个新的 Tool。
工具系统的架构可以理解为三层:模型看到的是 Schema,后端维护 Registry,真正执行的是 Handler。执行前后再加上工作区限制、危险命令拦截、超时、输出截断等安全边界。
8. 流式 Tool Call 的一个坑:参数不是一次性返回
如果使用非流式接口,模型返回的 tool_calls 通常是完整的。
但本项目使用流式输出。流式模式下,工具调用参数可能会被拆成很多 delta:
delta 1: function.name = "run_"
delta 2: function.name = "command"
delta 3: arguments = "{\"command\":"
delta 4: arguments = "\"python --version\"}"
因此后端不能拿到一个 delta 就立即执行工具,而是要先把同一个 index 的片段合并起来。
项目中有一个函数专门处理这个问题:
def _merge_tool_call_deltas(tool_call_parts, deltas):
for delta in deltas:
index = int(delta.get("index", 0))
part = tool_call_parts.setdefault(index, {
"id": "",
"type": "function",
"function": {"name": "", "arguments": ""},
})
if delta.get("id"):
part["id"] = delta["id"]
function_delta = delta.get("function") or {}
if function_delta.get("name"):
part["function"]["name"] += function_delta["name"]
if function_delta.get("arguments"):
part["function"]["arguments"] += function_delta["arguments"]
等本轮模型流结束后,再把片段 materialize 成完整工具调用对象:
tool_calls = _materialize_tool_calls(tool_call_parts)
这是实现流式 Agent Loop 时非常容易踩坑的点。
9. Agent Loop 的完整执行时序
下面是一次带工具调用的完整时序。
如果 CSDN 不支持 Mermaid,可以把上面的流程作为普通代码块阅读。
10. SSE:为什么前端能实时看到工具过程
后端通过 Server-Sent Events 推送流式事件。
一次 Agent 回复可能包含多个事件:
event: assistant_start
data: {"message_id":"assistant-xxx"}
event: tool_call_start
data: {"name":"run_command","arguments":{"command":"python --version"}}
event: tool_call_result
data: {"result":{"ok":true,"stdout":"Python 3.11.0"}}
event: message_delta
data: {"content":"当前"}
event: message_delta
data: {"content":" Python 版本是 3.11.0"}
event: message_end
data: {"finish_reason":"stop"}
前端不是等全部完成后一次性展示,而是边收边渲染。
项目中定义了这些事件:
| 事件 | 含义 |
|---|---|
assistant_start |
创建一条 Agent 消息 |
tool_call_start |
某个工具开始执行 |
tool_call_result |
某个工具执行完成 |
attachment |
工具产生文件或图片附件 |
message_delta |
文本片段 |
message_end |
当前 Agent 回复结束 |
error |
错误事件 |
前端使用 fetch() 读取 ReadableStream,然后按 \n\n 拆分 SSE 帧。
下面这张图展示了 SSE 事件如何从后端流向浏览器。前端不是等最终答案生成完才更新 UI,而是在每个事件到达时立刻更新对应区域。
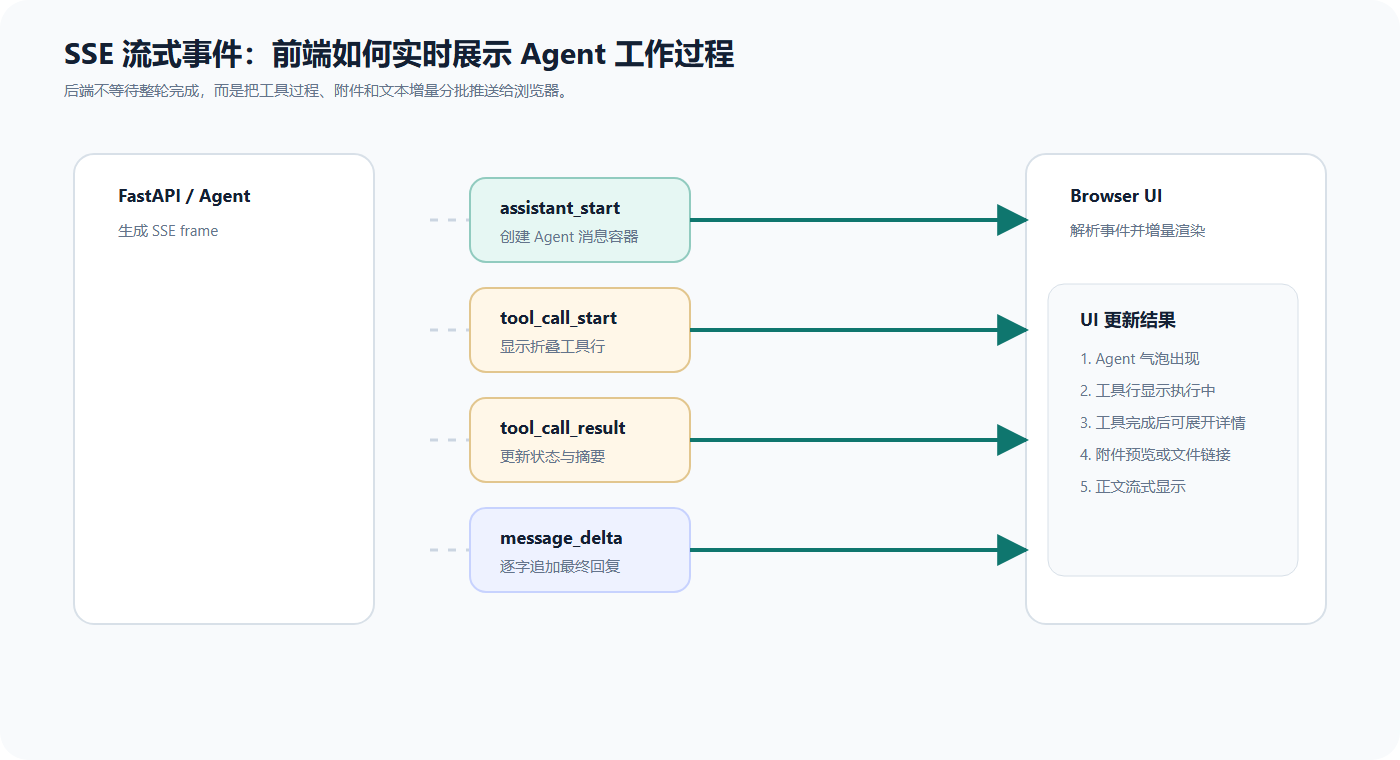
这样做有两个好处:
- 用户能看到 Agent 正在做什么。
- 长任务不会让页面看起来卡住。
11. 前端为什么要折叠工具过程
工具结果可能很长。
例如用户要求:
帮我查一下系统信息。
模型可能调用:
{
"command": "systeminfo"
}
这个命令会返回大量系统信息。如果直接全部展开,页面会被工具结果撑满,用户看不到最终回答。
因此项目把工具过程做成类似 Codex 的折叠行:
✓ run_command 退出码 0,有输出 详情
默认只显示:
- 状态图标
- 工具名
- 简短摘要
- 详情按钮
点击「详情」后才展开:
参数
{
"command": "systeminfo"
}
结果
ok: true
exit_code: 0
stdout:
...
stderr:
(empty)
这个设计兼顾了两点:
- 保留 Agent 执行过程的透明度
- 不打断用户阅读最终回答
项目实际运行时,工具过程默认就是折叠状态。用户只需要看到“工具名 + 摘要 + 状态”,需要排查细节时再点击「详情」展开。
12. 命令执行工具 run_command 的实现细节
命令执行是 Agent 工具中风险最高、也最能体现 Agent 能力的部分。
项目中的 run_command 做了几件事:
12.1 限制工作目录
命令不能在任意目录执行,而是限制在 WORKSPACE_DIR 中:
WORKSPACE_DIR=./workspace
后端会把传入的 cwd 解析为绝对路径,并检查是否仍然位于工作区内。
如果模型试图传入:
../../
就会被拒绝。
12.2 危险命令拦截
项目内置了一个基础 guard:
patterns = [
r"\brm\s+-rf\b",
r"\bRemove-Item\b.*\b-Recurse\b",
r"\bformat\b",
r"\bshutdown\b",
r"\breboot\b",
r"\bdiskpart\b",
]
这不是生产级安全沙箱,但适合教学演示。
12.3 Windows 命令兼容
大模型经常默认生成 Linux/bash 命令,例如:
pwd && ls -la
但本项目运行在 Windows 上,实际 shell 是 PowerShell。为了降低教学时的失败率,项目做了少量常见命令转换:
pwd && ls -la
会被转换为:
Get-Location; Get-ChildItem -Force
12.4 使用 subprocess.run 而不是异步子进程
在 Windows 下,asyncio.create_subprocess_exec 在某些事件循环环境中可能出现兼容问题,甚至抛出空错误。
项目改为在线程中运行:
return await asyncio.to_thread(
_run_command_sync,
command,
cwd,
timeout,
)
同步函数中使用:
subprocess.run(
argv,
cwd=str(cwd),
capture_output=True,
text=True,
timeout=timeout,
)
这样实现更稳定,也更容易拿到:
exit_codestdoutstderrtimeouterror
13. send_file:让 Agent 不只返回文本
很多 Agent 任务的结果不是一段话,而是一个文件。
例如:
把 demo.txt 文件发送给我。
模型会调用:
{
"name": "send_file",
"arguments": {
"path": "demo.txt"
}
}
后端不会直接把本机路径暴露给前端,而是把文件登记到附件表:
{
"id": "d5b98614166c4833924aa567fef844bb",
"name": "demo.txt",
"mime_type": "text/plain",
"size": 50,
"kind": "file",
"url": "/api/files/d5b98614166c4833924aa567fef844bb"
}
前端收到 attachment 事件后展示文件卡片。用户点击「打开」,访问的是:
/api/files/{file_id}
这种设计比直接返回本地路径更安全,也更适合 Web 展示。
需要注意:当前附件表是内存态的,服务重启后旧链接会失效。这对教学项目足够简单,但生产环境应使用持久化存储。
14. gen_image:把图片生成也作为工具
项目还实现了 gen_image 工具,用于调用图像模型生成图片。
.env 中可以配置:
OPENAI_IMAGE_BASE_URL=https://yunwu.ai/v1
OPENAI_IMAGE_API_KEY=你的图片 API Key
OPENAI_IMAGE_MODEL=gpt-image-2
OPENAI_IMAGE_SIZE=1536x1024
OPENAI_IMAGE_QUALITY=high
用户可以说:
生成一张 Agent Loop 教学插图。
模型会调用:
{
"prompt": "A clean educational illustration showing an agent loop...",
"size": "1536x1024",
"quality": "high"
}
后端调用 Images API:
client = AsyncOpenAI(
api_key=settings.image_api_key,
base_url=settings.image_base_url,
)
response = await client.images.generate(
model=settings.image_model,
prompt=prompt,
size=size,
quality=quality,
)
如果返回的是 b64_json,项目会把图片保存到:
generated/images/
然后通过附件机制发给前端。
如果兼容服务直接返回 URL,前端也可以直接展示该 URL。
下面是项目实际调用 gen_image 后的 UI 效果。工具过程仍然以折叠行显示,图片作为附件卡片展示,用户可以直接预览,也可以点击「打开」查看原图。
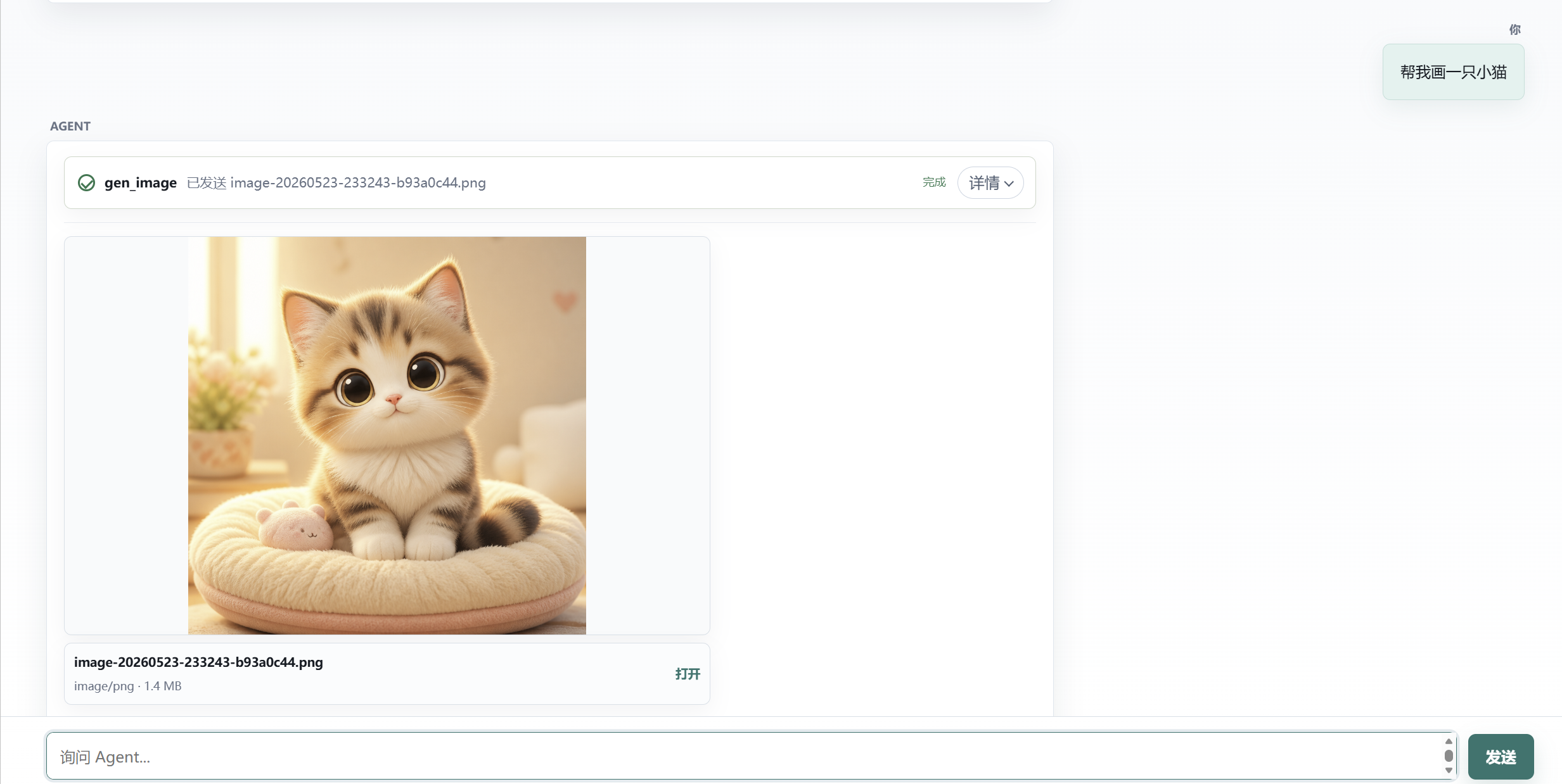
这说明 Agent 工具并不局限于命令行,它可以是:
- 文件工具
- 数据库工具
- 搜索工具
- 浏览器工具
- 图像生成工具
- 报表生成工具
- Word/PPT/PDF 生成工具
Agent Loop 提供的是统一的工具调用框架。
15. 配置系统:为什么要支持 .env
教学项目里不应该把 API Key 写死在代码里。
本项目通过 .env 统一配置:
OPENAI_API_KEY=...
OPENAI_BASE_URL=...
OPENAI_CHAT_MODEL=qwen3.6-plus
OPENAI_REQUEST_TIMEOUT_MS=120000
OPENAI_MAX_OUTPUT_TOKENS=16000
OPENAI_IMAGE_BASE_URL=...
OPENAI_IMAGE_API_KEY=...
OPENAI_IMAGE_MODEL=gpt-image-2
配置加载逻辑有几个细节:
- 先读取
.env - 如果系统环境变量已经存在,则优先使用系统环境变量
- 支持新变量名
OPENAI_* - 兼容旧变量名
LLM_* - 图片模型可以使用独立 base url 和 api key
这样做的好处是:
- 本地开发方便
- 部署时可由平台注入环境变量
- 聊天模型和图片模型可以分开配置
- 不需要改代码就能切换模型服务
16. 前端渲染:从 SSE 到聊天 UI
前端核心逻辑在 static/app.js。
浏览器发送请求:
const response = await fetch("/api/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ messages: conversation }),
});
然后读取流:
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
while (true) {
const { value, done } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const parsed = parseSseFrames(buffer);
parsed.frames.forEach(handleEvent);
}
不同事件对应不同 UI 更新:
| 事件 | 前端动作 |
|---|---|
tool_call_start |
创建折叠工具行 |
tool_call_result |
更新工具状态和摘要 |
attachment |
显示文件或图片附件 |
message_delta |
追加文本 |
message_end |
保存本轮 assistant 消息 |
这里有一个细节:浏览器只保存简化后的对话历史:
[
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."}
]
工具消息不由前端保存,而是在后端 Agent Loop 内部临时维护。
这样前端更简单,也避免把大量工具结果反复传来传去。
17. Agent Loop 的几个关键工程问题
17.1 如何避免无限工具调用
模型可能连续调用工具,如果不加限制,就可能陷入循环。
项目使用:
AGENT_MAX_STEPS=6
超过最大步数后停止。
17.2 工具参数必须 JSON 解析
模型返回的 arguments 是字符串:
"arguments": "{\"command\":\"python --version\"}"
后端必须:
json.loads(raw_arguments)
如果解析失败,也不能直接崩溃,而要返回友好的错误。
17.3 工具错误要回传给模型
工具失败不是系统失败。
例如命令不存在:
{
"ok": false,
"error": "Command not found"
}
应该作为工具结果返回给模型,让模型解释失败原因和下一步建议。
17.4 工具结果要限制长度
命令输出、文件内容、日志结果都可能很长。
项目中对输出做了截断:
def _trim_output(text, limit=12000):
if len(text) <= limit:
return text
return text[:limit] + "... output truncated ..."
否则上下文会被工具结果撑爆。
17.5 前端展示不应信任模型输出为 HTML
项目中消息内容使用:
element.textContent = content;
而不是:
element.innerHTML = content;
这是为了避免模型输出中混入 HTML/JS 导致注入风险。
18. Agent Loop 和传统后端流程的区别
传统后端流程通常是确定性的:
用户点按钮 -> 后端调用固定函数 -> 返回结果
Agent Loop 中,调用哪个工具是模型决定的:
用户自然语言输入 -> 模型选择工具 -> 后端执行工具 -> 模型解释结果
这让系统更灵活,但也带来新问题:
| 问题 | 说明 |
|---|---|
| 工具选择不稳定 | 模型可能选错工具 |
| 参数可能错误 | 模型生成的 JSON 可能不符合预期 |
| 工具可能失败 | 命令不存在、文件不存在、权限不足 |
| 安全边界复杂 | 模型可能请求危险操作 |
| 调试更困难 | 需要观察中间工具过程 |
所以一个好的 Agent 应用必须具备:
- 工具过程可视化
- 错误可解释
- 工具调用可审计
- 执行边界可控
- 失败可恢复
这也是本项目为什么把工具过程显示在每条 Agent 回复上方。
19. 和 Codex、OpenClaw、Hermes、LangChain、AutoGen、Agents SDK 的关系
讨论 Agent Loop 时,经常会看到很多热门关键词:Codex、OpenClaw、Hermes、LangChain、AutoGen、OpenAI Agents SDK 等。
这些名字覆盖的范围并不完全相同,有的是编程智能体产品形态,有的是开源 Agent 项目,有的是模型或模型生态关键词,有的是 Agent 开发框架。但从工程视角看,它们都会碰到一组共同问题:
- 模型如何理解任务?
- 模型如何决定要不要调用工具?
- 工具参数如何结构化?
- 工具执行结果如何回填给模型?
- 多步任务如何避免无限循环?
- 如何把中间过程展示给用户?
- 如何记录、审计和复现工具调用过程?
这就是 Agent Loop 的价值。它不是某个单独框架的专有概念,而是几乎所有工具型智能体都会遇到的底层控制结构。
例如,Codex 风格的编程智能体强调“可观察的执行过程”:你能看到它读取文件、修改代码、运行测试、处理错误。这个项目里的可折叠工具过程,就是借鉴这种体验:默认只显示工具名、状态和摘要,点击「详情」再查看参数与结果。
OpenClaw、Hermes 这类关键词适合放在更大的 Agent 生态语境里理解:无论上层名字怎么变化,只要系统允许模型发起工具调用,就需要处理 Tool Schema、Tool Execution、Tool Result、Streaming Events 和安全边界这些底层问题。
LangChain、AutoGen、OpenAI Agents SDK 等框架都能构建 Agent。
但这些框架封装较多,初学者容易只会调用 API,却不理解底层发生了什么。
本项目刻意不做复杂封装,只保留 Agent Loop 的最小核心:
messages
tools schema
while loop
tool_calls
tool result
streaming
frontend events
当你理解这个闭环后,再去看各种 Agent 框架,会更容易理解:
- planner 是什么
- tool executor 是什么
- memory 是什么
- trace 是什么
- callback/event stream 是什么
- human-in-the-loop 是什么
框架只是把这些概念做了更完善的工程化封装。
20. 生产化还需要补什么
这个项目适合教学演示,但生产环境还需要很多增强。
20.1 鉴权和权限
不能让所有用户都能执行命令、读取文件、生成图片。
需要:
- 登录鉴权
- 用户角色
- 工具权限
- 文件权限
- 图片额度控制
20.2 人类确认机制
高风险工具执行前,应该让用户确认。
例如:
Agent 想执行:pip install xxx
是否允许?
这就是 Human-in-the-loop。
20.3 审计日志
每次工具调用都应该记录:
- 用户是谁
- 调用了什么工具
- 参数是什么
- 结果是什么
- 执行时间
- 是否成功
这样出了问题可以追踪。
20.4 沙箱隔离
命令执行最好放在容器、虚拟机或受限环境中。
不能直接在生产服务器宿主机上跑任意命令。
20.5 上下文管理
工具结果太长时,需要做:
- 截断
- 摘要
- 向量检索
- 分块读取
- 按需引用
否则上下文成本会快速上升。
21. 如何扩展一个新工具
新增工具一般分四步。
第一步,写 handler:
async def _echo(self, arguments):
return {
"ok": True,
"text": arguments["text"]
}
第二步,写 JSON Schema:
parameters = {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "Text to echo."
}
},
"required": ["text"]
}
第三步,注册工具:
self.register(
Tool(
name="echo",
description="Echo the input text.",
parameters=parameters,
handler=self._echo,
)
)
第四步,在系统提示中告诉模型什么时候使用它。
这就是最小扩展路径。
22. 快速运行项目
安装依赖:
python -m venv .venv
.\.venv\Scripts\Activate.ps1
pip install -r requirements.txt
复制配置:
Copy-Item .env.example .env
编辑 .env:
OPENAI_API_KEY=你的 API Key
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_CHAT_MODEL=qwen3.6-plus
OPENAI_IMAGE_BASE_URL=https://yunwu.ai/v1
OPENAI_IMAGE_API_KEY=你的图片 API Key
OPENAI_IMAGE_MODEL=gpt-image-2
WORKSPACE_DIR=./workspace
启动服务:
python main.py
访问:
http://127.0.0.1:8000
如果端口被占用:
uvicorn app.server:app --host 127.0.0.1 --port 8001
23. 推荐测试问题
你好
现在几点?
列出当前工作区文件。
运行 python --version,并告诉我结果。
运行 pwd && ls -la,并总结当前目录。
把 demo.txt 文件发送给我。
生成一张 Agent Loop 教学插图。
24. 总结:Agent Loop 的技术细节清单
最后用一张清单总结 Agent Loop 的核心技术点。
模型侧
- 通过 system prompt 约束行为
- 通过 tools schema 告诉模型可用工具
- 模型返回
tool_calls - 流式模式下 tool call 需要合并 delta
- 工具结果回填后模型继续回答
后端侧
- 维护
messages - 控制
while最大步数 - 解析工具参数 JSON
- 分发工具 handler
- 捕获工具错误
- 将工具结果转成
role=tool - 用 SSE 推送中间过程
工具侧
- 工具必须有清晰 description
- 参数必须有 JSON Schema
- 执行范围必须受限
- 输出必须可序列化
- 长输出需要截断
- 失败也要返回结构化结果
前端侧
- 使用 fetch 读取流
- 解析 SSE 帧
- 展示工具开始和结束
- 展示附件
- 流式追加文本
- 工具过程默认折叠
- 不使用
innerHTML渲染模型输出
安全侧
- API Key 放
.env - 命令限制在工作区
- 文件限制在工作区
- 危险命令拦截
- 命令超时
- 生产环境需要鉴权、审批、沙箱、审计
Agent Loop 的代码不一定复杂,但它连接了模型协议、工具执行、上下文管理、流式传输、前端交互和安全控制。
如果只看框架,很容易忽略这些底层细节。
自己从零实现一遍,才能真正理解 Agent 为什么能“行动”,以及行动的边界应该由谁控制。
这也是这个项目的价值:
它不是为了替代成熟框架,而是帮助你看清 Agent 系统最核心的运行机制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)