用“挑西瓜”讲透《机器学习》第五章-神经网络
📖《机器学习》第5章·通俗解读 | 神经网络:模仿人脑的学习方式
神经网络的名字听起来很高大上,但它的灵感其实来自你身体里最神奇的东西——大脑。
大脑里有 billions 的神经元,它们互相连接、传递信号,让你能思考、记忆、做决定。
神经网络就是在计算机里模拟这种结构,让它也能“学习”。
1. 神经元模型:一个简单的“开关”
一个神经元长这样:
-
它有多个“树突”接收信号(输入)
-
每个信号有不同权重(重要程度不同)
-
所有信号加权求和,加上一个偏置(阈值)
-
如果总和超过某个门槛,神经元就“兴奋”,输出 1;否则输出 0

这就是M-P神经元模型,1943年就提出了,至今还在用。
但用“超过门槛就输出1”这种阶跃函数有个问题:它不光滑,不好训练。
所以实际中常换成Sigmoid函数(S形曲线),输出在0~1之间连续变化,可以理解为“兴奋的程度”。

一个神经元本身很简单,但把成千上万个连在一起,就能做非常复杂的事情。
2. 感知机:最简单的神经网络
感知机只有两层:
-
输入层:接收特征(比如色泽、根蒂、敲声的数值)
-
输出层:一个神经元,输出好瓜/坏瓜

它能学习线性可分的问题,比如“与门”、“或门”、“非门”。
但异或门(XOR)就不行——你无法用一条直线把(0,0)、(1,1)和(0,1)、(1,0)分开。
这个问题在1969年被Minsky和Papert指出,导致神经网络研究进入了第一个“寒冬”。
怎么办?加隐层(中间层)。
3. 多层网络与BP算法:神经网络的“翻身仗”
有了一个或多个隐层,神经网络就能解决异或这类非线性问题了。
但问题来了:怎么训练它?
-
感知机只有输出层有“答案”,很容易调整权重
-
多层网络里,隐层没有“标准答案”,你不知道它应该输出什么
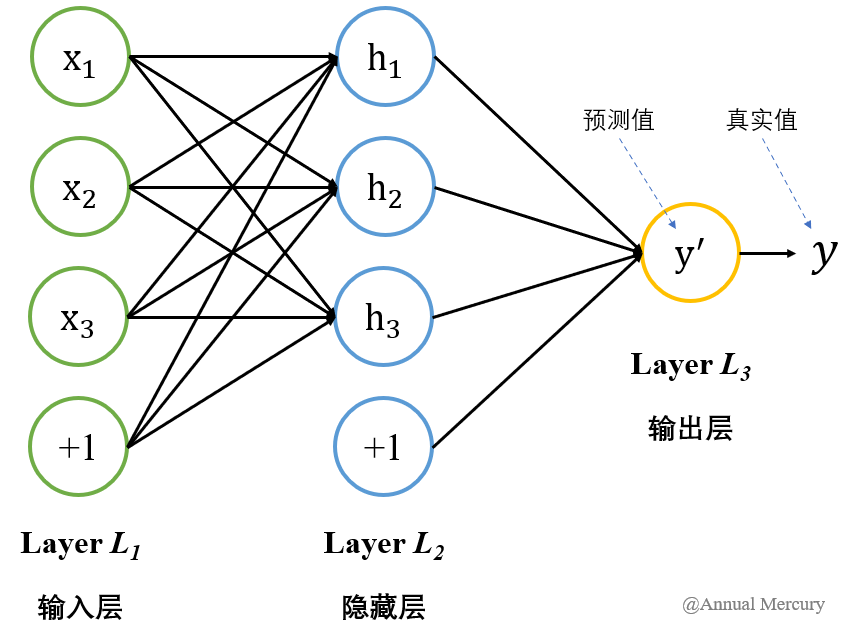
BP算法(误差反向传播)解决了这个问题:
-
输入数据,逐层向前计算,得到输出(前向传播)
-
计算输出与真实答案的误差
-
把误差从输出层反向传到隐层、再到输入层,根据误差调整每一层的权重
-
重复这个过程,直到误差足够小
通俗理解:
你闭着眼睛走迷宫,撞墙了,就“反向”退一步,调整方向,再走。
BP就是那个“撞墙反馈”,让网络知道自己哪里错了,然后改正。
BP算法让多层神经网络变得可训练,掀起了神经网络的第二次高潮。
4. 局部极小 vs 全局最小:别卡在“小山坡”
神经网络的误差就像一张起伏的地形图。
-
局部极小:你走到一个小坑里,四周都比它高,你出不去了。但这个坑可能不是整个地图的最低点。
-
全局最小:整个地图的最低点,是你真正想去的地方。
BP算法靠梯度下降一步步走,很容易陷在局部极小出不来。
怎么跳出小坑?
-
随机初始化多次:从不同起点出发,多试几次
-
模拟退火:偶尔允许“走差的一步”,可能帮你翻出小坑
-
随机梯度下降:每次只用一部分数据计算梯度,引入随机性
就像你在山里找最低点,如果只盯着脚下,你可能困在小水坑。
但如果你偶尔闭着眼瞎走一步,可能就跳出来,发现旁边有个大湖。
5. 其他常见神经网络(了解即可)
| 名称 | 一句话解释 |
|---|---|
| RBF网络 | 用“距离”来衡量相似度,离中心越近越兴奋 |
| ART网络 | 可以动态增加神经元,学新知识不遗忘旧知识 |
| SOM网络 | 把高维数据“压”到二维平面,还能保持拓扑结构(相近的点挨在一起) |
| 级联相关网络 | 边训练边增加隐层神经元,结构自动生长 |
| Elman网络 | 有“记忆”,输出不光看当前输入,还看上一时刻的状态(适合时间序列) |
| Boltzmann机 | 基于能量的模型,训练目标是让网络能量最小化 |
这些变种各有特长,但核心思想都一样:神经元 + 连接权重 + 学习算法。
6. 深度学习:神经网络“卷土重来”
深度学习就是有很多隐层的神经网络。
为什么以前不火?
-
层数多了,BP算法容易梯度消失(误差传到前面几层时几乎为0,学不动了)
-
计算量大,以前算不动
为什么现在火了?
-
大数据:深度学习参数多,需要海量数据来训练
-
强算力:GPU让训练速度快了几百倍
-
技巧进步:逐层预训练、ReLU激活函数、Dropout等
深度学习在图像识别、语音识别、自然语言处理等领域碾压传统方法。
卷积神经网络(CNN)是深度学习的代表:
-
用“卷积核”扫描图像,提取局部特征
-
用“池化”缩小尺寸,保留主要信息
-
多个卷积+池化层堆叠,最后接全连接层输出结果
CNN让计算机“看懂”了图片,是人脸识别、自动驾驶的核心技术。
📌 第五章总结(背下这5句就够了)
-
神经元 = 加权求和 + 激活函数,是神经网络的基本单元
-
感知机只能解决线性可分问题;多层网络+BP算法解决了非线性问题
-
BP算法 = 误差反向传播,让隐层也能学习
-
局部极小是陷阱,要用随机性跳出
-
深度学习 = 很多层的神经网络 + 大数据 + GPU,是当前主流
👇 下章预告
第六章讲支持向量机(SVM)——另一种非常强大的分类器。
它的核心思想是:找一个“最宽”的分界线,让两类数据离得越远越好。
用“挑西瓜”讲透《机器学习》第六章-支持向量机-CSDN博客

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)