大模型到底是怎么“思考“的?看懂 Token Space 与 Latent Space,你才真的理解了 LLM
很多人解释大模型,张口就是一句"它在预测下一个 token"。这话没错,但只说了最外面那层——就像说"汽车在前进",确实在前进,可你不知道发动机里发生了什么。
真正有意思的事情藏在这句话内部:模型先把人类写的文字切成 token,再把 token 抬升到一个连续的高维空间里做计算,最后把计算结果投影回 token 输出。
那个高维空间,就是这两年"机制可解释性""激活引导""latent reasoning"都在围着转的 latent space。要真正看懂今天的 LLM,你必须同时看懂这两个空间,以及它们之间那条来回穿梭的路径。
从一句话到一个回答,模型经历了什么
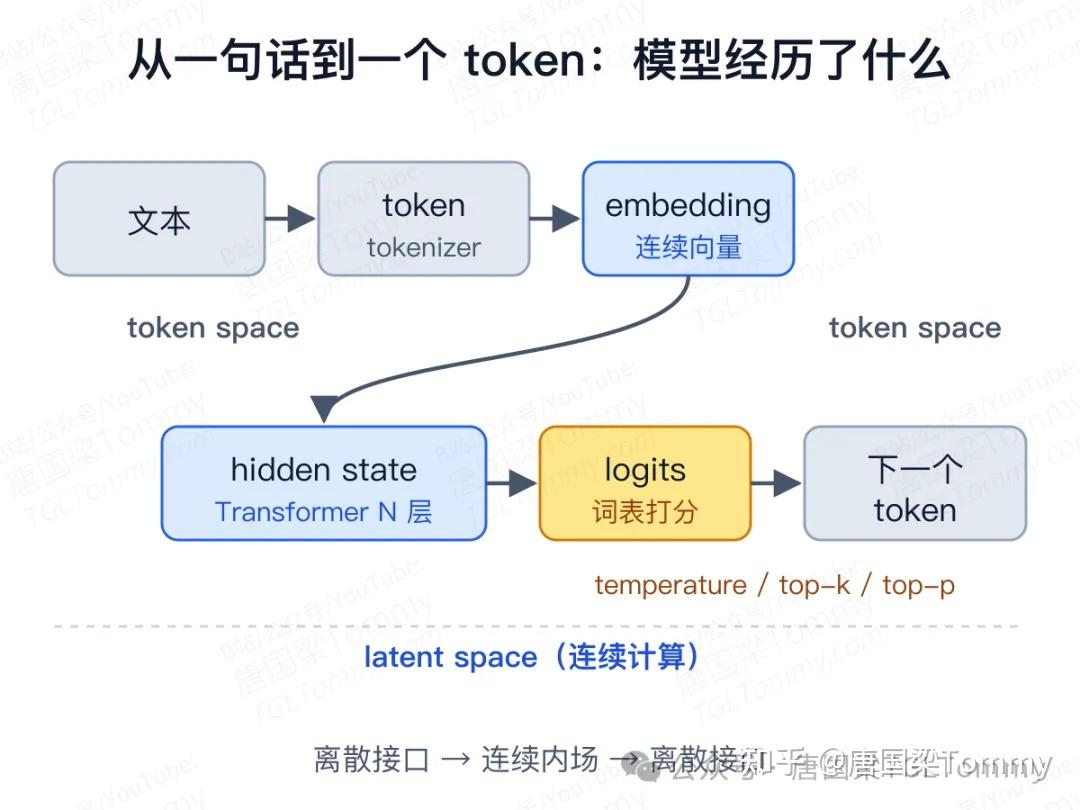
我们先把一次最普通的生成过程拆开。
用户输入的是文字,但模型不直接处理文字——它先经过 tokenizer,把文本切成一串 token,再换成 token ID。
接下来,embedding matrix 把每个离散编号变成一组连续向量。可以理解成:每个 token 在模型内部都拿到一个"初始坐标"。
但这只是入口。Transformer 每一层都会继续加工这些向量:attention 从上下文里读取和搬运信息,MLP 负责非线性加工。一层一层下去,模型得到 hidden state——它读完上下文之后的内部表示。
最后一步,hidden state 投影回整个词表,对每个候选 token 打分,得到 logits。再经过 temperature、top-k、top-p 这些解码策略,才采出下一个 token。
整条路径:文本 → token → embedding → hidden state → logits → 下一个 token。token space 与 latent space 的分工,就藏在这里。
一个离散接口,一个连续内场
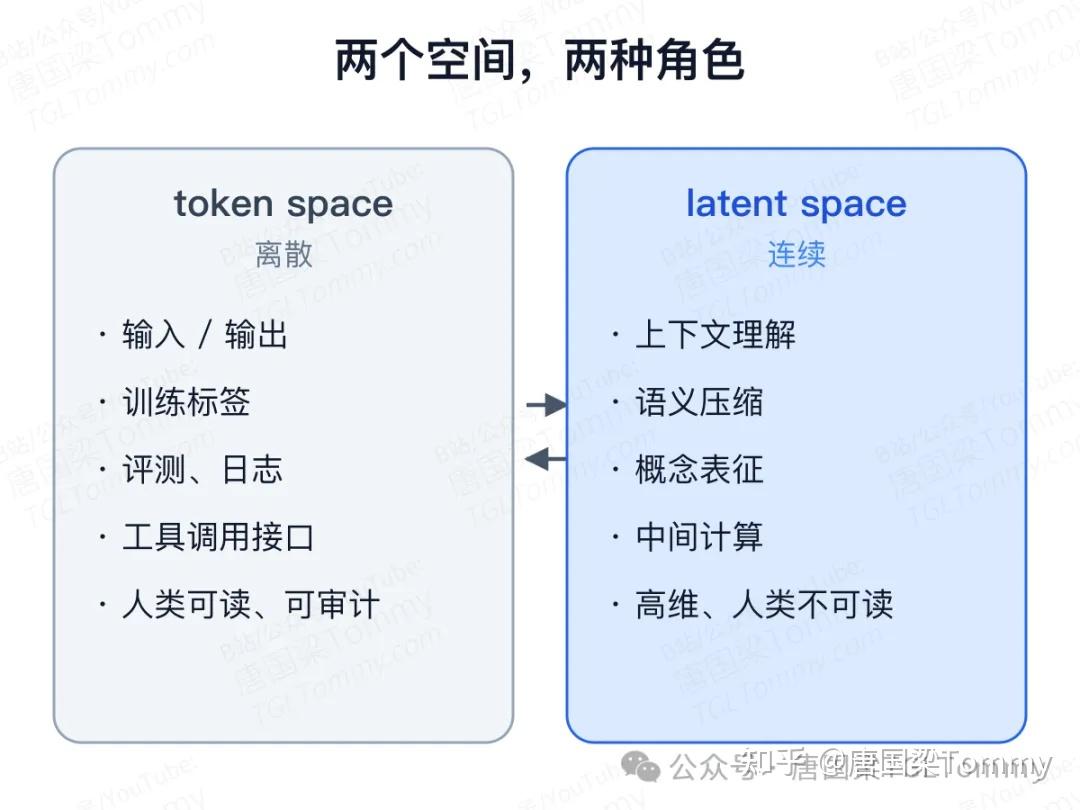
token space 是离散的,负责输入、训练标签、输出和评测——任何能被人类读到、被工具调用、被日志记录的东西,都活在这一层。latent space 是连续的,负责上下文理解、语义压缩、概念表征,以及发生在层与层之间的"中间计算"。
这两个空间不是替代关系,而是同一个系统的两个阶段。模型用 token 接收和输出离散符号,用 latent state 做连续计算,再通过 logits 把连续结果翻译回 token 概率。
顺带澄清一个常见误解:token space 不只发生在 tokenizer,也发生在输出端。模型从来不"直接吐出一句话",而是每一步都在整个词表上分配概率——所以同一个模型、同一个 prompt,换一组解码参数,结果就可能完全不同。
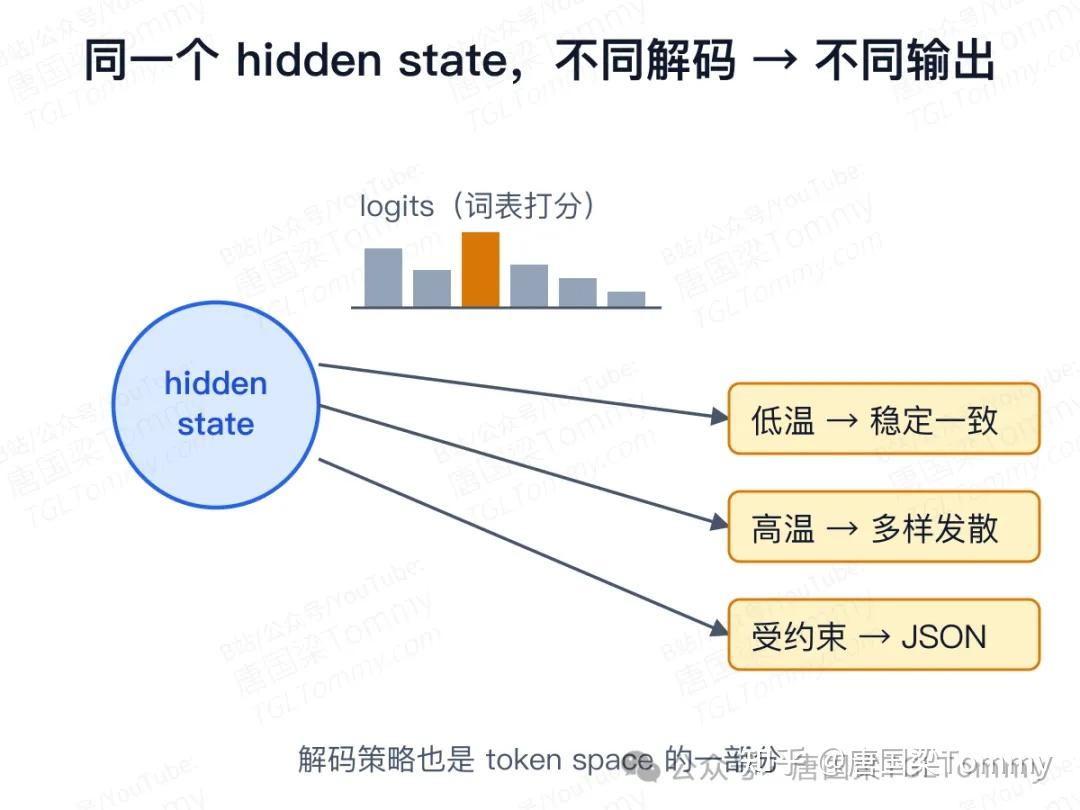
这个区分对分析模型行为很关键:模型"不知道",可能是 latent representation 里没有正确编码;"知道但没说",可能是解码或安全策略卡住了输出;"说法不稳定",可能是 logits 分布本来就接近,采样噪声大。三种现象,根因完全不同。
tokenizer 会改变模型看到的世界
下面这件事一开始会让人不太适应:tokenizer 不只是个无害的预处理步骤,它会改变模型接收到的信息结构。
英文有空格,词边界清楚;中文没有天然空格。一句"我喜欢机器学习",tokenizer 可能切成"我 / 喜欢 / 机器 / 学习",也可能切成"我 / 喜欢 / 机器学习"。两种切法,模型进入 latent space 的初始信号就不一样。

2025 年关于中文 tokenization 的研究把话说得很直白:当 token 切分和中文语义部件、部首结构不对齐时,主流大模型的内部表征会系统性受损。类似的后缀错位问题,也出现在欧洲语言里。token 边界从来不是工程细节——它会直接影响 latent space 里的语义几何。
把这个现象放进更严格的场景,你会更吃惊。多选题评测看起来不能更简单了——A、B、C、D 选一个。但 Mind the Gap 这类研究发现:仅仅是 Answer: 后面那个前导空格和答案字母合不合并成同一个 token,就能让准确率波动高达 11%,甚至改变模型排名。

你以为模型在比较选项语义,它其实同时被 token 边界、leading space、答案标签是 single-token 还是 multi-token 这些因素影响。
数字也一样。人类看到 1234567 和 1,234,567 知道是同一个数,模型看到的 token 序列可能完全不同。Tokenization Counts 指出:不同的数字切分会显著影响算术表现,某些右对齐分组能改善大数计算,常规切法则带来系统性错误。

tokenizer 的未来:把"切分"也变成模型的一部分
未来方向不是简单的"越细越好"或"越粗越好"。一条最有代表性的路线是 Byte Latent Transformer(BLT)。

传统 BPE 是先训练一个固定词表再照着切。BLT 不一样——它直接在 byte 层面工作,根据 next-byte entropy(下一字节的不确定性)动态把字节组成 patch:简单片段合成更大块,复杂片段保留更细颗粒。
通俗说:固定 tokenizer 是"提前把文本切好",BLT 是"让模型自己决定该在哪里细看"。论文在 8B 参数、4T bytes 规模上展示了 byte-level 模型追上传统 tokenizer-based LLM 的可行性——它的价值不只是"摆脱 tokenizer",而是把切分粒度变成模型计算的一部分。
另外两条路线一句话带过:SuperBPE 允许 token 跨空格形成 superword,减少 token 数;T-Free 用三字符 triplet 替代传统 token embedding,在多语言上有潜力。它们指向同一个判断:tokenization 的本质是把语言信号压缩成最适合模型学习的离散代码。
走进 latent space:一张超高维地图
讲完 token 这一侧,转向 latent space。
这个概念最容易被讲玄。有人会说成模型的"思想""意识"——这种说法不准确。更朴素的定义是:latent space 就是模型内部用来表示信息的连续向量空间。一个 hidden state 可能是几千维向量,人类直接看不懂,但里面同时压缩了语义、风格、任务、上下文关系,以及下一步的输出倾向。
而且 latent space 不是单一房间:embedding 层、residual stream(残差流)、attention 输出、MLP 激活、KV cache——它们都是模型内部不同位置上的连续表示。所以当论文说"在 latent space 里找到一个方向",值得追问:是哪一层?哪个 token 位置?在残差流里,还是在某个 attention head 里?
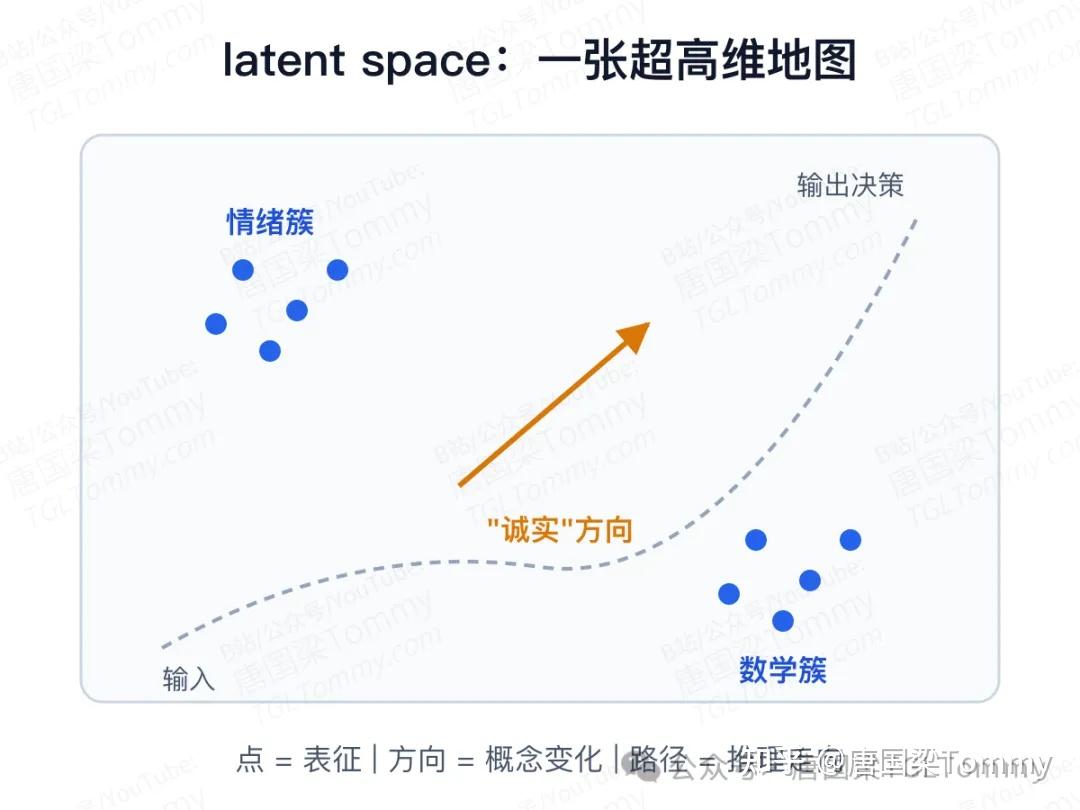
把 latent space 想象成一张超高维地图:相近的点代表语义或功能相似,某个方向代表属性变化,某条路径对应模型从输入理解走向输出决策的过程。研究里经常去找"诚实方向""礼貌方向""有害方向"——Representation Engineering(表征工程) 把这件事变成明确目标:能不能从模型内部表示里读出某种概念,并适度干预。
但要小心:不是所有概念都能被一个简单方向完美表示。现有研究确实找到了不少可线性读出的概念,比如空间、时间、情感——这支持一个判断:latent space 不是黑箱噪声,它有结构、有方向、有几何关系。
但单个坐标轴通常不等于一个人类概念。不能说第 17 维就是"诚实",第 302 维就是"数学"。更稳健的提法是:概念往往是分布式模式,激活往往是多个特征的混合。
当多个特征挤进同一组神经元:superposition 与 SAE
这就引出了机制可解释性里的核心问题:superposition,叠加。直观说:模型想表示的特征非常多、可用维度有限,而且很多特征是稀疏出现的——模型于是把多个很少同时出现的特征压进同一组维度。
这会带来 polysemanticity(多义性):同一个神经元、同一种激活模式,在不同上下文里可能对应几个毫不相关的概念。"一个神经元 = 一个概念"这种朴素理解,在大模型里基本不成立。
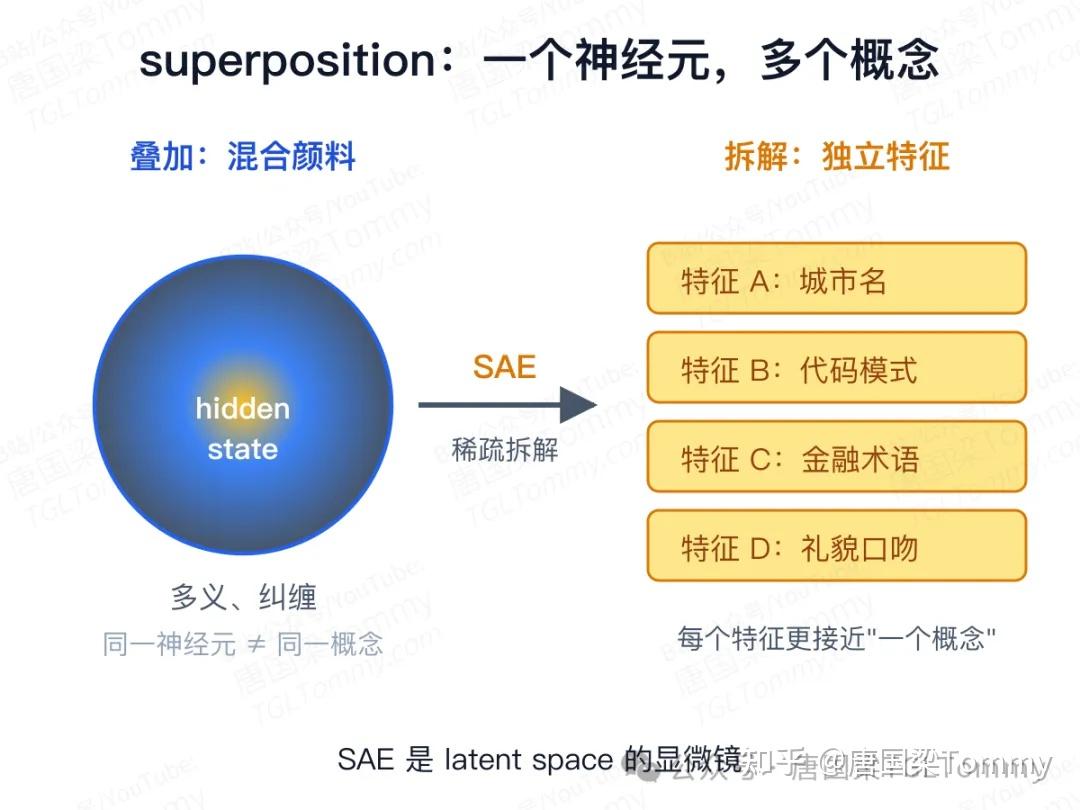
SAE(Sparse Autoencoder,稀疏自编码器) 正是为这个问题设计的"拆解工具":把混在一起的隐藏状态,拆成更容易解释的特征组合。普通 hidden state 像一锅混合颜料,SAE 试图把它分回更独立的"基色"——在 LLM 上可能对应实体、语言、代码模式或抽象概念。
Anthropic 在 2024 年的 Mapping the Mind of a Large Language Model 中报告,他们从 Claude 3 Sonnet 的中间层提取出数百万个可解释特征,对部分特征做干预能改变模型行为。但 SAE 的目标不是让模型变强,而是让我们看清模型内部激活了哪些概念——它更像 latent space 的显微镜,而不是最可靠的方向盘。
往前再走一步是 circuit tracing——SAE 问"模型里有哪些可解释特征",circuit tracing 进一步问"这些特征如何一步步导致某个输出"。这是 latent space 研究从"找概念"过渡到"找概念之间的计算关系"。
latent reasoning:推理可以不写在草稿纸上
下一个更前沿、也更容易被过度解读的方向,是 latent reasoning——把中间推理状态留在 latent space 里,而不是写成文字。
传统 Chain-of-Thought(CoT)是在 token space 里推理:模型把每一步推理写成自然语言。优点是人类可读、容易监督;代价是 token 成本高、自然语言带宽有限、中间步骤一旦写出就难修改,而且 CoT 是否真实反映模型内部推理,本身就是个研究问题。
latent reasoning 的想法是:模型未必非要把每一步想法都写成人类语言。它可以在隐藏状态里保留中间推理,只输出最终答案。形象地说:CoT 像在草稿纸上逐字写推理;latent reasoning 更像在脑内同时试几条路线,只把结论说出来。
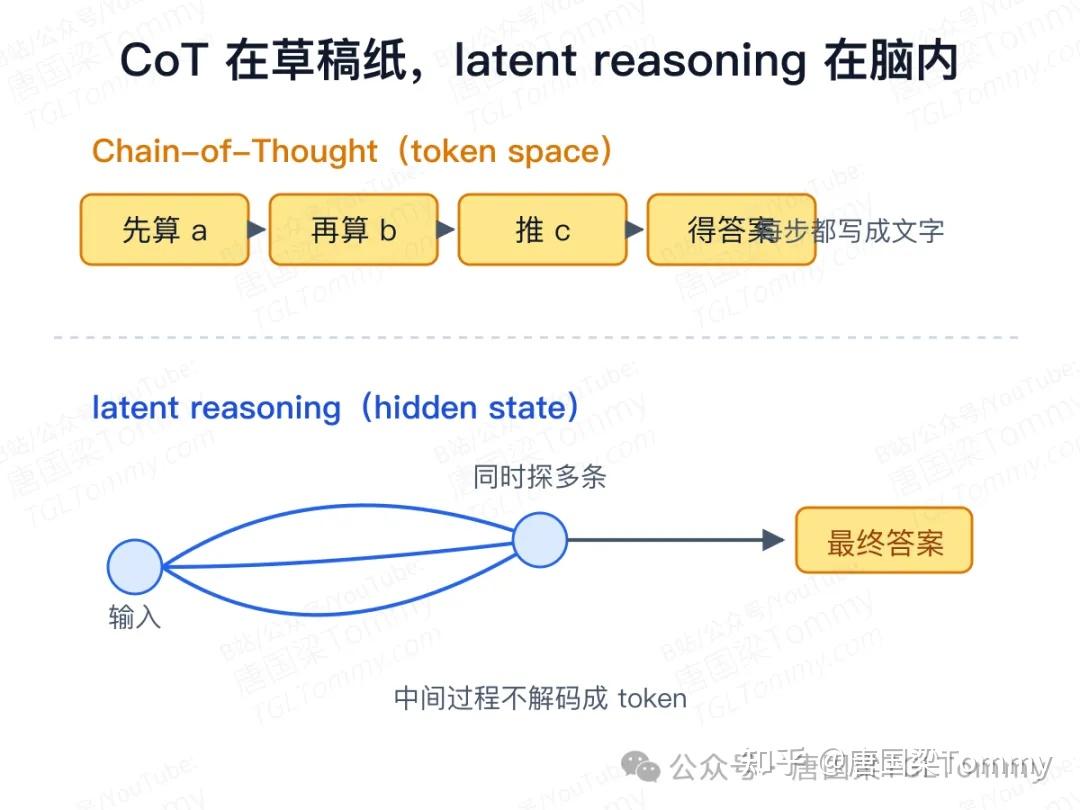
代表工作之一是 Coconut:它把 LLM 的最后隐藏状态当作 continuous thought——不解码成文字,而是直接作为下一步输入向量喂回模型。论文认为,这种连续思考可以同时保留多个推理方向,避免过早绑定到某条自然语言路径,在某些逻辑任务上表现出类似 BFS 的行为。
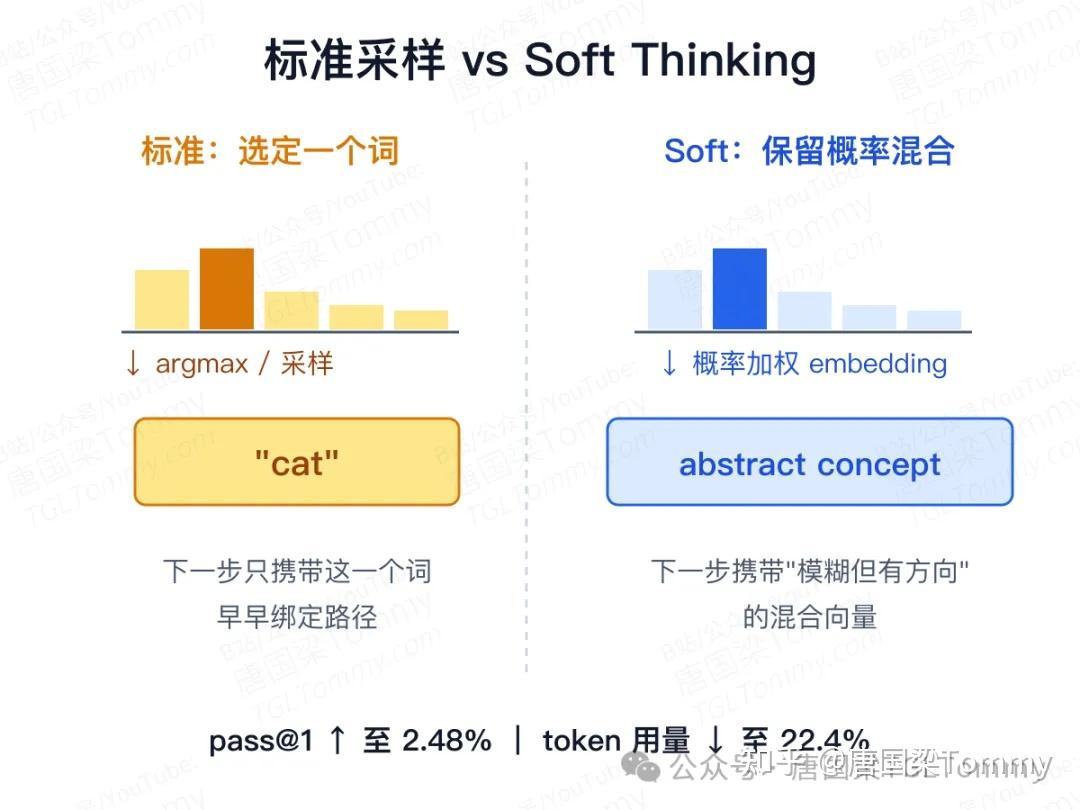
另一个工作 Soft Thinking 可作为补充:不立刻采样一个离散 token,而是用 token 概率分布加权 embedding,形成连续的 abstract concept token——先保留多个候选想法的混合向量,而不是急着选一个词。论文称,相对标准 CoT,Soft Thinking 的 pass@1 最多提升 2.48 个百分点,token 使用最多减少 22.4%。
这里要克制:latent reasoning 不等于一定更聪明或更高效。少生成可见 token,可能只是把计算转移到了 hidden steps 里。公平比较必须看总 FLOPs、wall-clock latency、latent 步数,以及 benchmark 是不是天然偏向自然语言 CoT。
未来更可能是 token-latent hybrid
讲到这里,可以给一个相对靠谱的判断:token 不会被淘汰,latent space 也不会取代一切,两者会分工。
人类交互、最终回答、工具调用、程序代码、安全审计——仍然需要 token,因为 token 是可读、可监督、可评测、可记录的接口。而中间推理压缩、多路径搜索、语义规划、跨语言表示、多模态融合——更适合 latent space。它带宽更高,也可能更接近模型内部真实的计算机制。
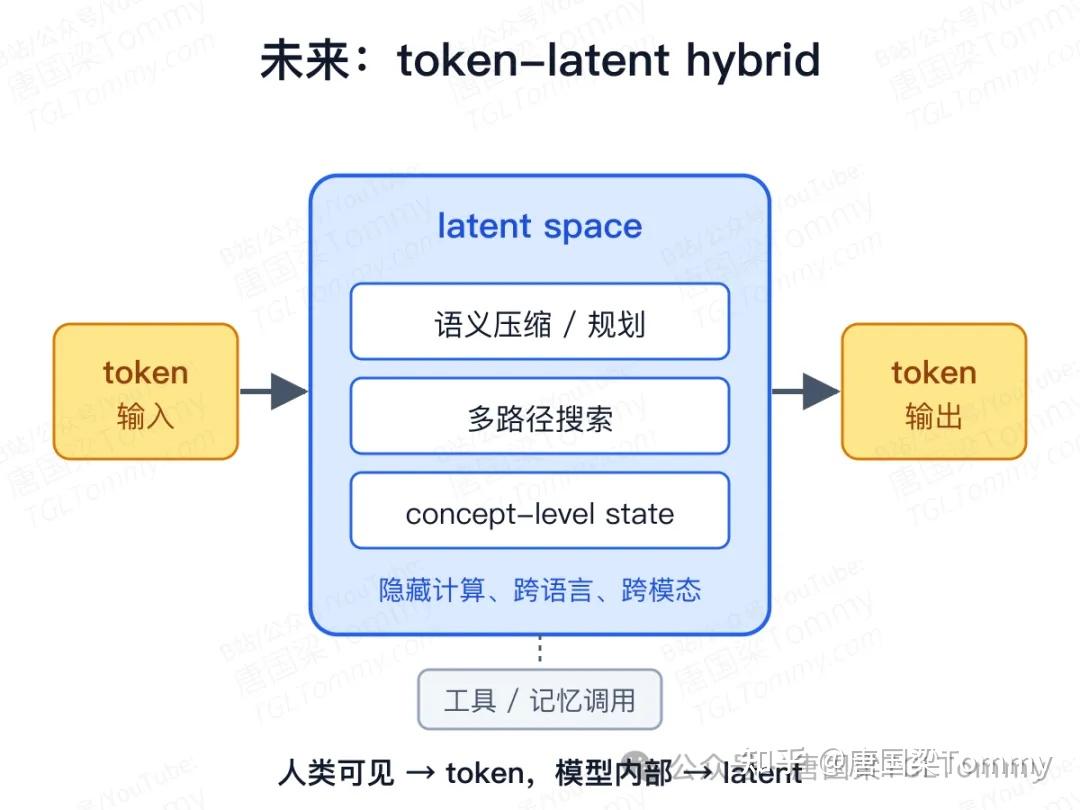
一个合理的未来形态:token 输入 → 在 latent space 里规划和推理,形成 concept-level state → 必要时调用工具和记忆 → 回到 token 输出。
这条路也带来开放问题。tokenizer 不会消失:BLT 说明 tokenizer-free 是可行方向,SuperBPE 又说明更强的 tokenizer 仍能带来收益——更准确的判断是固定 BPE 不再是唯一合理默认。latent CoT 也很难审计:自然语言 CoT 至少可读,latent state 则需要 decoder、probe、SAE、causal intervention 一整套工具组合,而这些工具本身也会出错——不能把"翻译出来的 latent thought"直接当成真实机制。
未来比较模型,不应该只问"准确率谁更高"。还要问:用了多少可见 token?多少隐藏计算?中间状态能不能解释和审计?失败时能不能定位原因?
回到那四句话
把整篇文章压成四句话:
- 1. LLM 不直接处理文字,而是处理 token——token 是模型眼里的"文字小块"和离散编号。
- 2. token 转成向量后,模型在 latent space 中做连续计算。latent 不是神秘意识,而是模型内部的隐藏表示。
- 3. tokenization 影响模型看到什么,latent representation 影响模型理解什么——输入切分、内部表示、输出解码,三者一起塑造模型行为。
- 4. 下一代模型很可能是 token-latent hybrid:输入输出仍是 token,中间推理、语义压缩和规划越来越多发生在 latent space。
书籍PDF及配套代码可点赞文章后添加小助手获取


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)