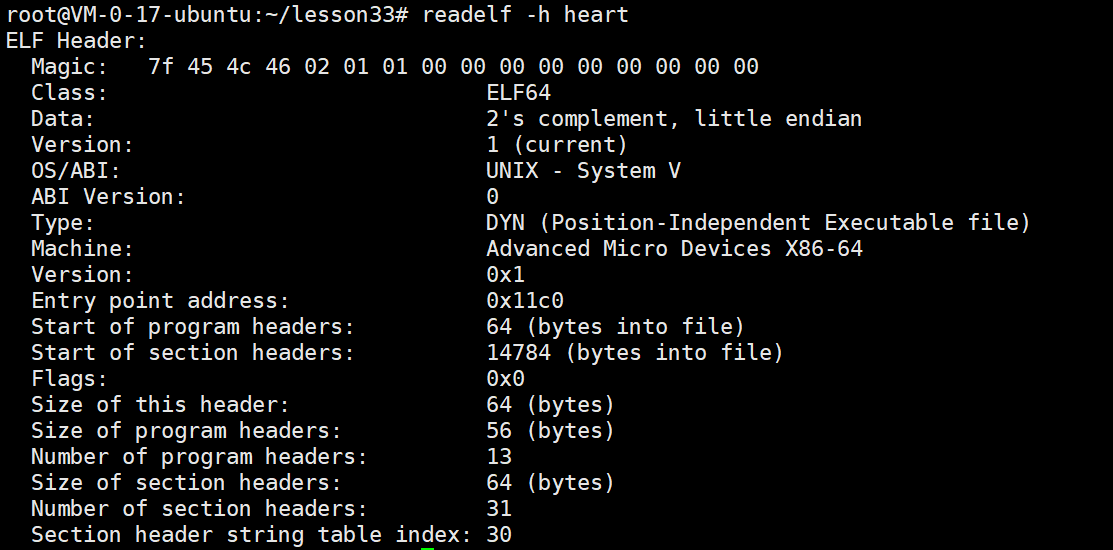
ELF动态库
在学习C语言的过程中,我们常常会听到这样的说法:C语言程序第一个执行的函数是main函数。
今天,我们要纠正这一普遍存在的认知误区。实际上,在Linux系统中,程序真正第一个执行的函数是_start()。通过反汇编分析可以清晰地验证这一点:_start()函数执行完毕后才会跳转到main函数。
从程序入口点(entry point address)给出的地址0x11c0可以看出,这正是_start()函数的地址。在执行_start()函数的过程中,才会通过call指令跳转到main函数。
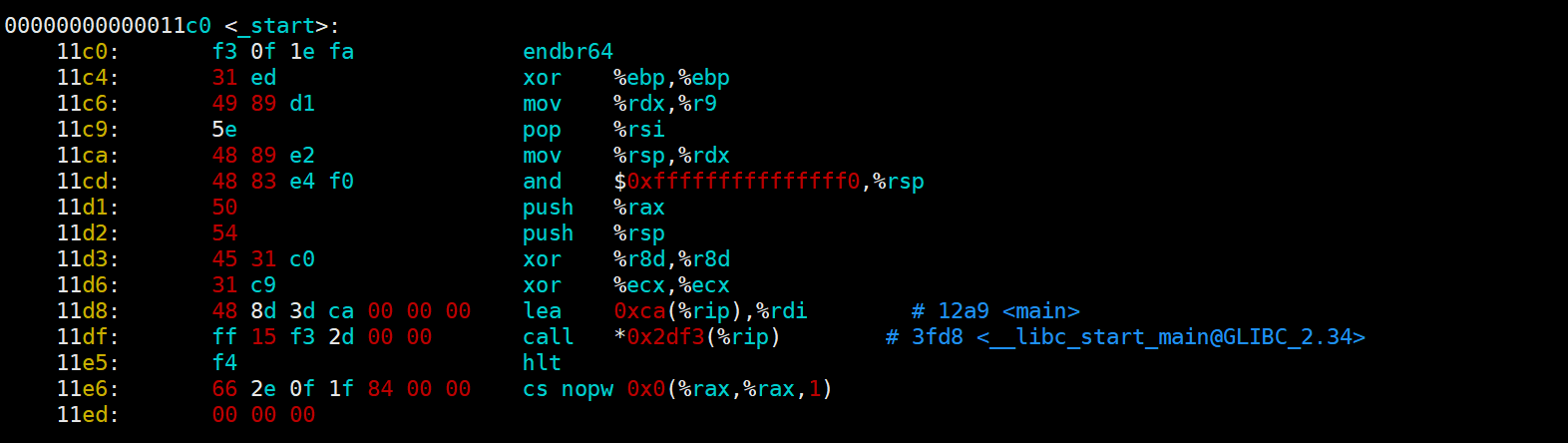
从反汇编结果中,我们可以清晰地观察到指令的长度、操作码以及数据部分。
例如这些就是指令,从中可以直观地看出字节个数。由于采用十六进制表示,每两个数字组合在一起就构成一个字节。
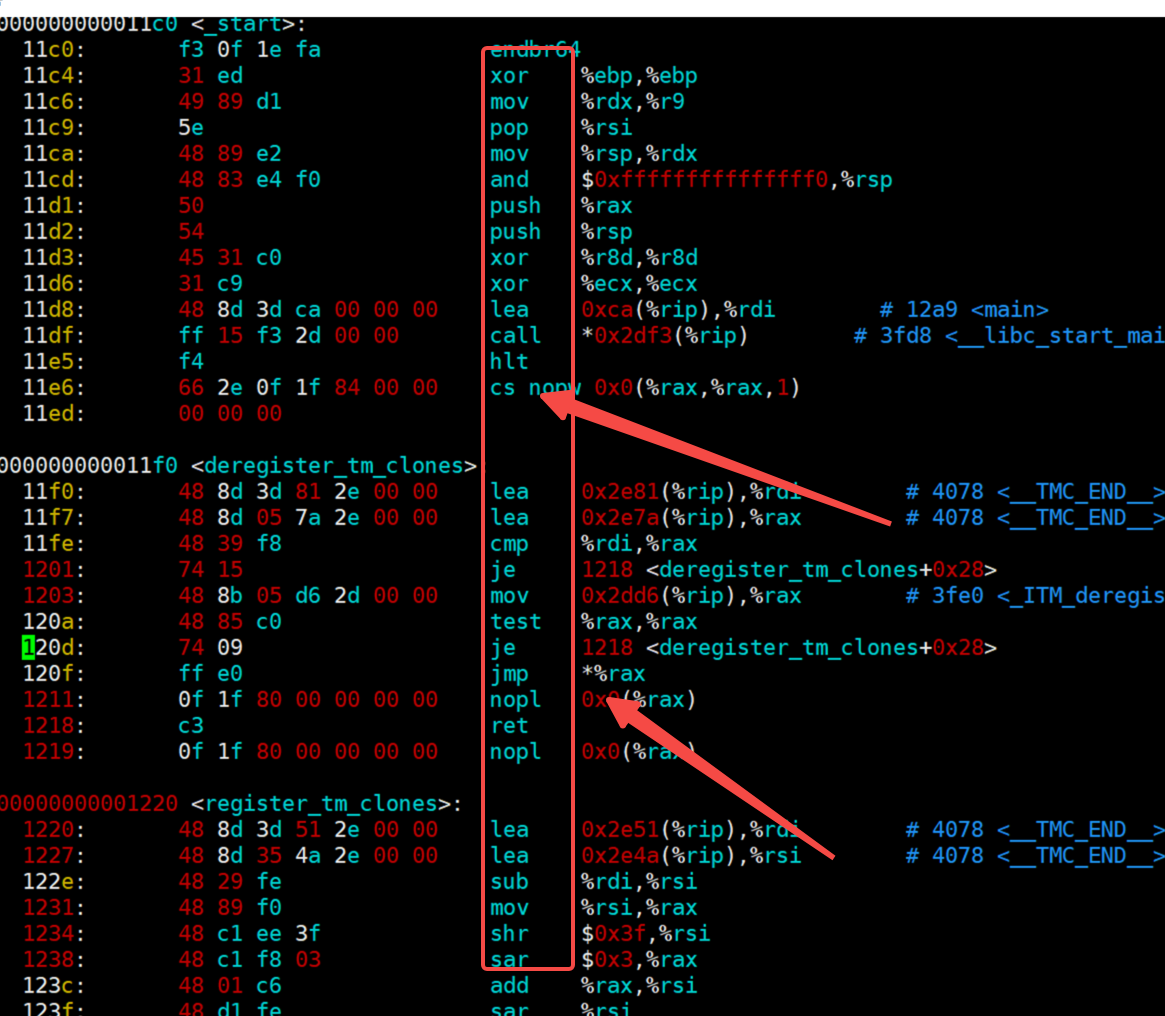
这些部分对应的是操作码。
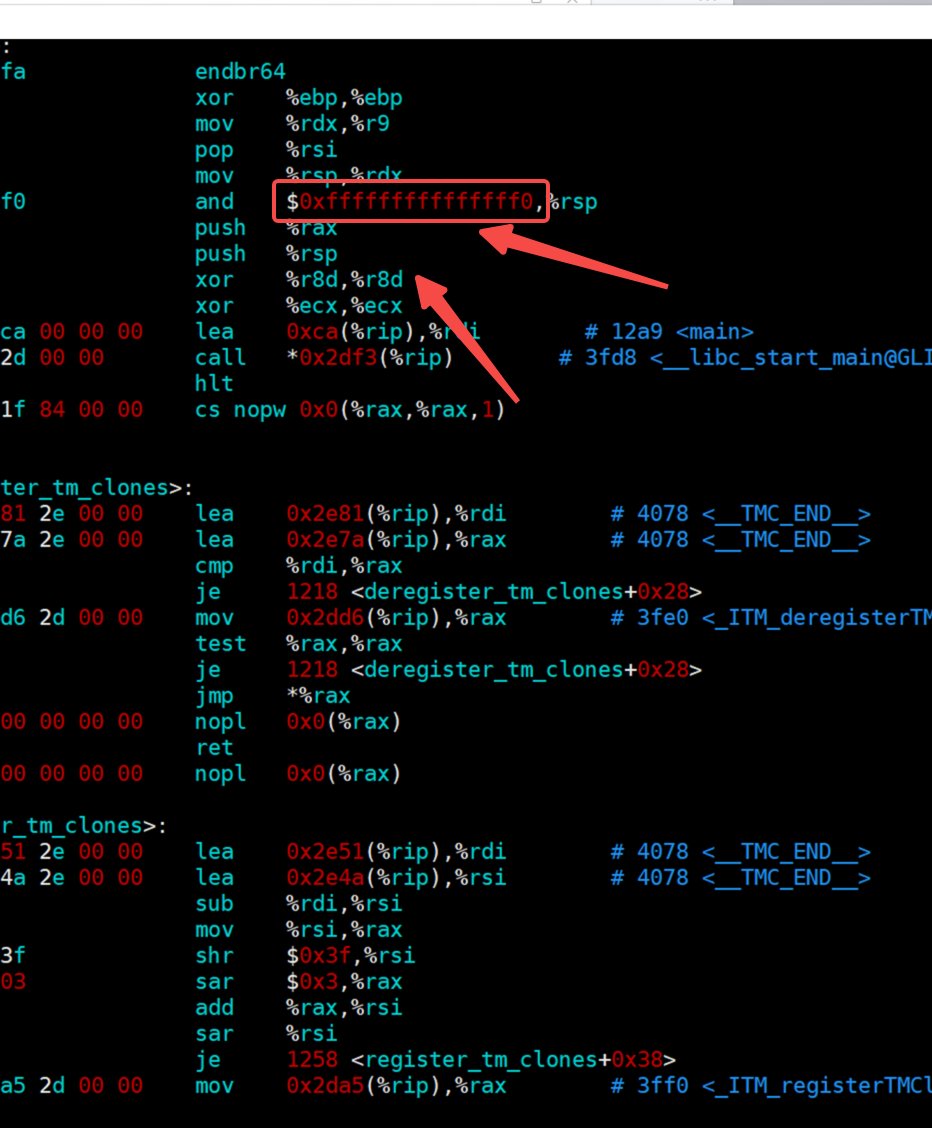
这里显示的是数据。需要注意的是,并非每一行都包含数据,例如xor指令后面跟随的两个ebp就是寄存器。
CPU拥有特定的指令集,而汇编语言本质上就是将汇编语句与指令集进行文本映射的产物。在编译程序时,实质上是将C/C++语言转换为对应的机器指令集。
补充说明:指令集(ISA)是CPU硬件层面能够直接理解的二进制命令(例如10110000…),而汇编语言则是这些二进制码的"人类助记符"(如MOV、ADD等)。两者之间存在着严格的一一对应关系。汇编器的主要工作,就是将编写好的汇编助记符按照既定规则"翻译"成对应的二进制机器码。
使用命令objdump -S a.out可以查看反汇编结果。
_start()函数的简化逻辑如下:
_start()
{
if(argc == 1)
{
return main();
}
else
{
return main(argc, argv, env);
}
}
这段代码不具备跨平台性,硬件层面的差异主要体现在指令集的不同,而软件层面则表现为系统调用的差异。
因此,在C语言程序启动时,第一个实际执行的函数是CRTstart()(C运行时启动函数)。
链接过程
静态链接的本质是将库中的相关代码拷贝到你的程序中!
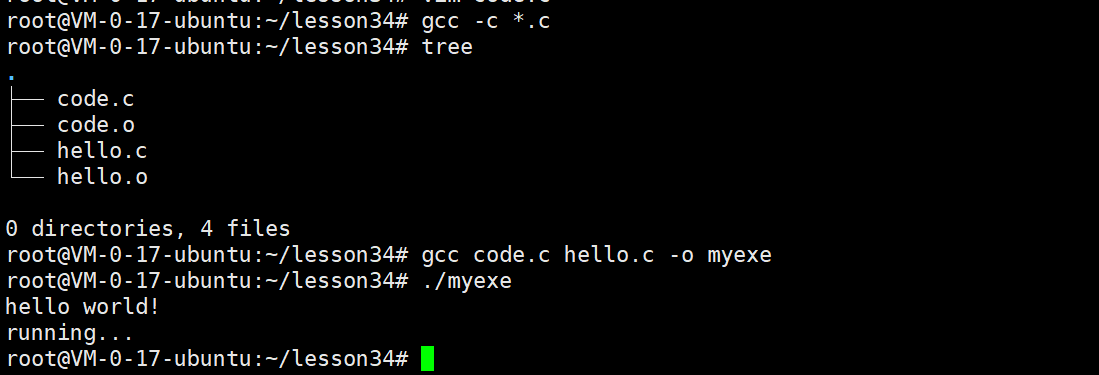
我们通过一个具体示例来说明。假设有两个源文件:
hello.c
#include<stdio.h>
void run();
int main() {
printf("hello world!\n");
run();
return 0;
}
code.c
#include<stdio.h>
void run() {
printf("running...\n");
}
首先,分别对这两个文件进行编译,生成对应的目标文件(.o文件):
接下来,我们反汇编生成的code.o文件:
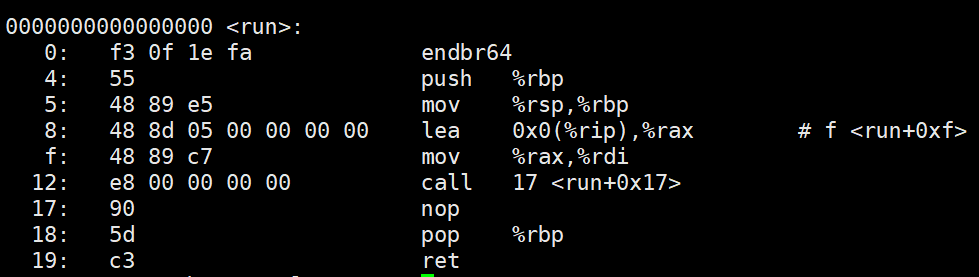
从反汇编结果可以看到,call指令调用的printf函数地址被暂时置为0。这是因为printf函数是在链接阶段才确定具体地址的,在编译阶段,编译器会先将外部函数的地址默认设置为0。
同样,反汇编hello.o文件:
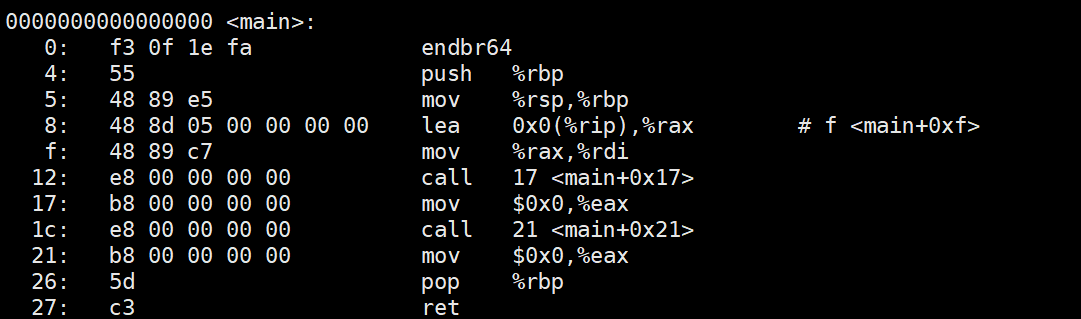
第一个call指令对应的是printf函数,第二个call指令则对应run函数。由于run函数在hello.c中只有声明而没有定义,编译器同样会将其地址暂时置为0。
在后续的链接过程中,链接器会将这些暂时为0的地址修正为最终函数的实际地址。
读取code.o符号表
使用命令 readelf -s code.o 读取code.o的符号表:
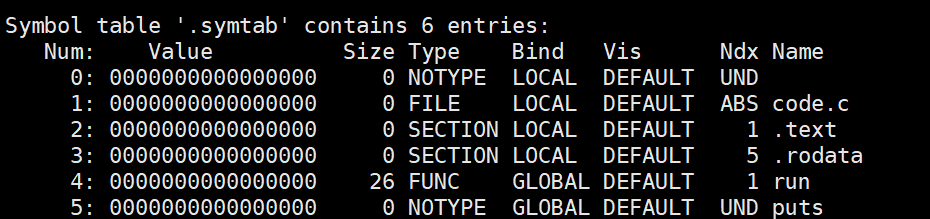
从符号表中可以进一步证明,在编译阶段,printf函数尚未找到具体地址,puts函数的状态仍为UND(undefined,即未定义)。
接下来,将所有的.o文件进行链接:
gcc *.o -o main.exe
链接完成后,再次读取main.exe的符号表:
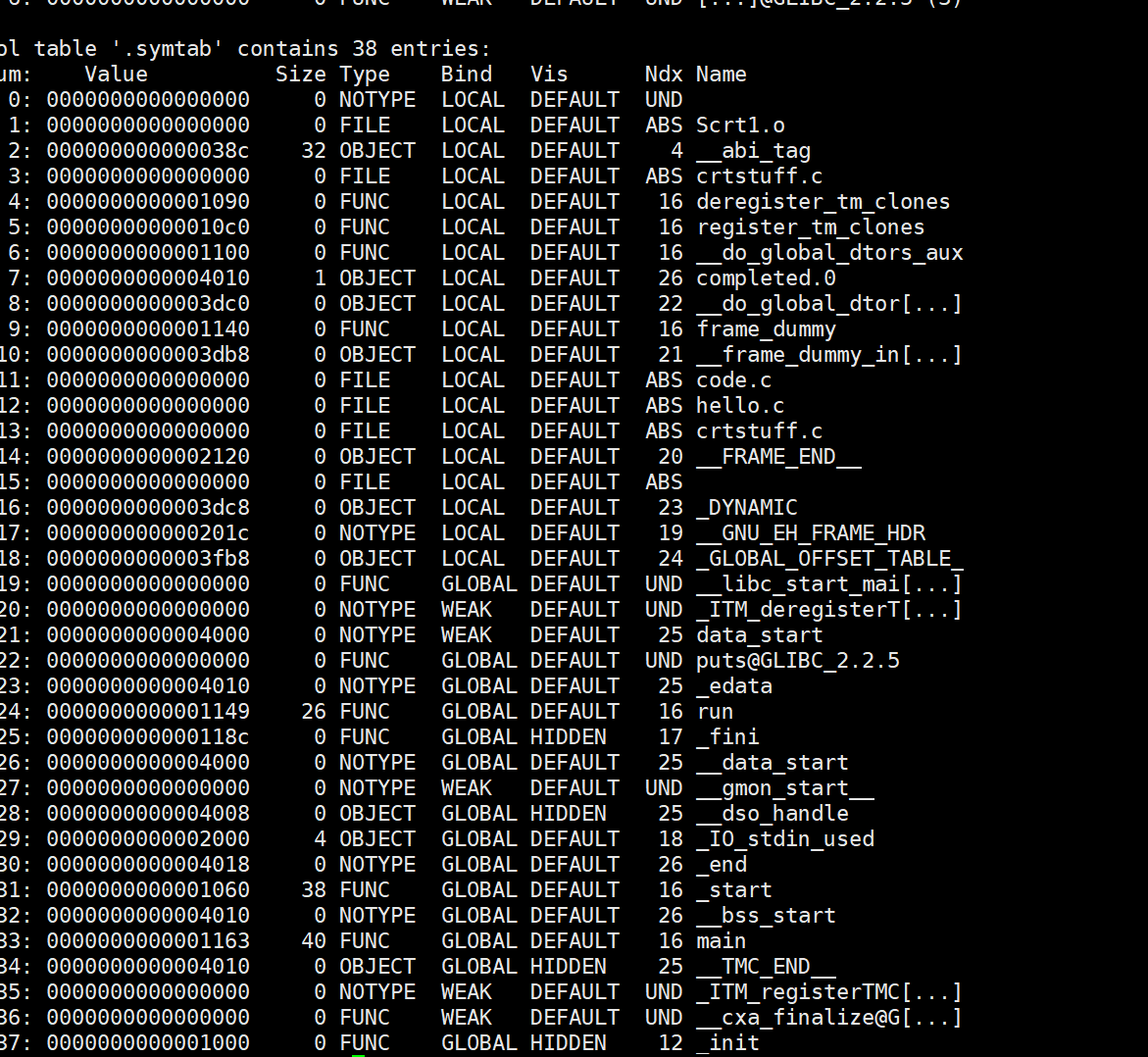
此时可以看到,run函数和main函数都有了具体的地址信息。
注意:这里的puts函数仍然显示为UND状态,这是因为当前采用的是动态链接方式。如果使用静态链接,puts函数在链接时就会被解析并分配具体地址。符号表中的NDX值对应的是该符号所在节(section)的下标。
链接过程在编译器进行链接时,在加载之前就已经全部完成了。具体来说:
- 链接器会把所有的.o文件合并到一起,并根据平坦模式为函数分配位置
- 将可执行程序中原本置为0的函数地址根据页表进行修改
最终实现的效果是:
- 两个.o文件的代码段合并到了一起,并进行了统一的编址
- 链接时,会修改.o文件中未确定的函数地址,在合并完成后,修正相关call指令的地址,完成代码调用
- 链接其实就是将编译之后的所有目标文件连同用到的一些静态库、运行时库组合,拼装成一个独立的可执行文件。其中就包括我们之前提到的地址修正,当所有模块组合在一起之后,链接器会根据我们的.o文件或者静态库中的重定位表找到那些需要被重定位的函数和全局变量,从而修正它们的地址。这就是静态链接的过程。
因此,链接过程中会涉及到对.o文件中外部符号进行地址重定位。
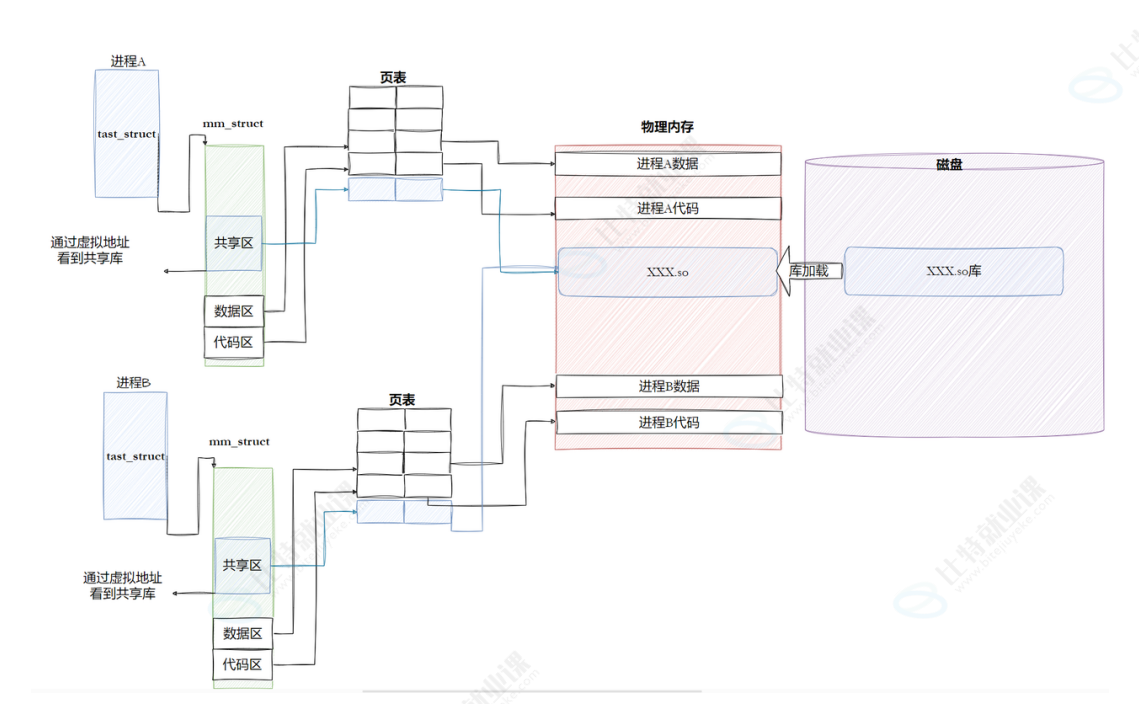
动态库
在进程创建时,操作系统会先建立PCB(进程控制块)等内核数据结构,然后再加载用户程序。
对于采用动态链接的程序,在加载阶段需要先找到对应的动态库。与静态链接不同,静态链接的程序在运行前就已经确定了函数的地址;而动态链接的程序在加载时,外部函数的地址仍然是未知的,在符号表中显示为UND(未定义)状态。

即使程序知道自己使用了哪些库,这些库中具体函数的地址在加载时仍然是未知的。
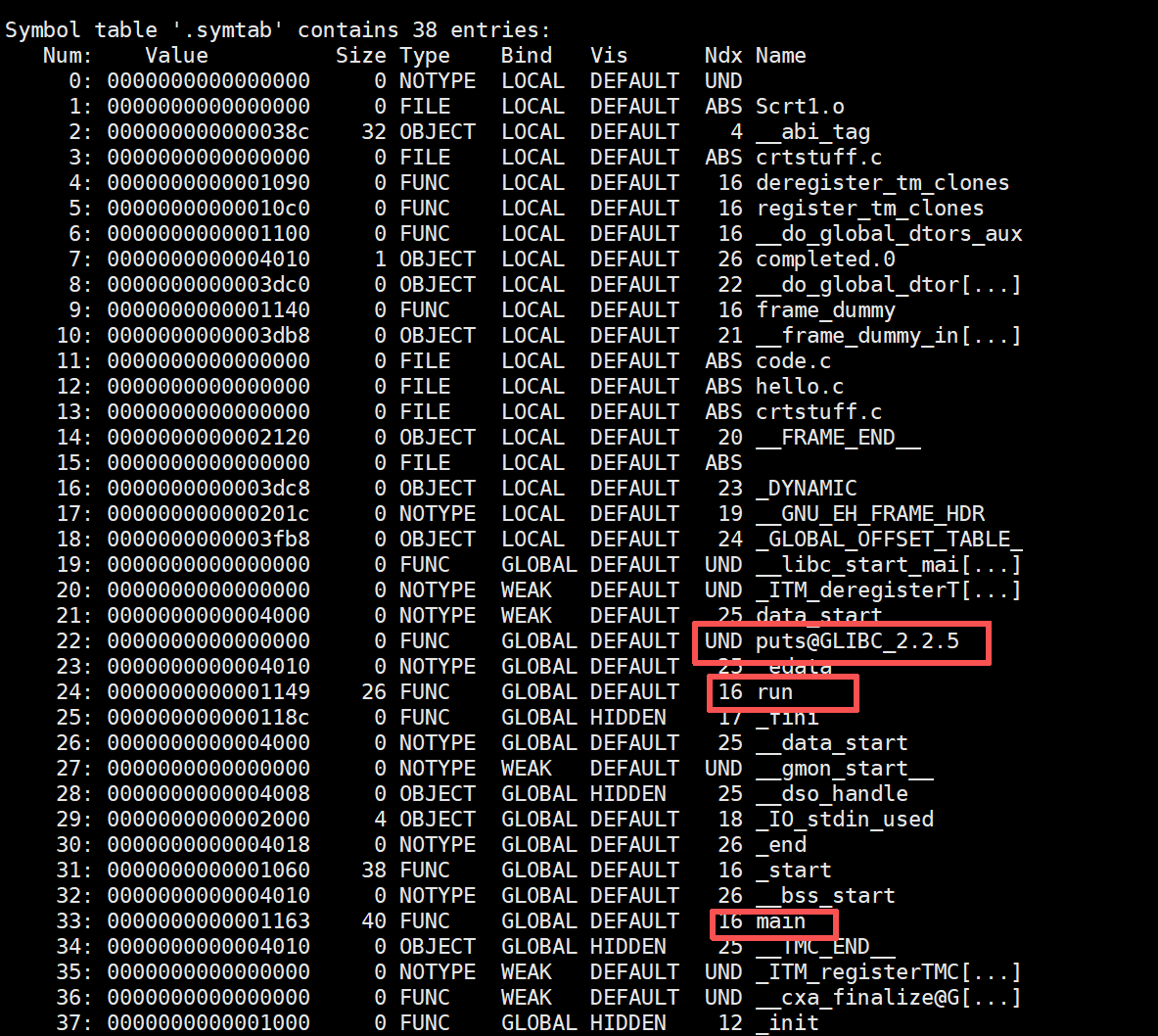
当程序开始运行时,操作系统会先将C标准库的内容加载到内存中,并为其分配地址空间。此时,像puts这样的函数才会从UND状态转变为具有确定地址的状态。这个过程清晰地展示了静态库与动态库的核心区别。
要找到对应的动态库,系统需要从磁盘文件中读取库文件,因此必须知道库的路径信息。
总结
以我们编写的code.c和hello.c为例,这两个文件同时包含了静态链接(自定义的run函数)和动态链接(C语言的printf函数)两种方式。
编译阶段:code.c和hello.c分别编译生成hello.o和code.o目标文件。此时,无论是printf函数还是run函数,它们的地址都是不确定的,编译器会先将这些外部函数的地址暂时置为0,等待后续修改。
链接阶段:在加载器尚未加载程序之前(即静态链接阶段),链接器会为run函数分配虚拟地址,但此时还没有对应的物理地址。
加载阶段:动态链接器将程序中需要的动态库函数加载到共享内存区域。此时,这些函数仍然只有虚拟地址,尚未分配物理地址。当动态库被加载到内存以后,⼀旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。(这里的地址都是虚拟地址)
运行阶段:程序执行过程中,当首次访问这些函数时,会触发“缺页中断”,操作系统此时才会真正为这些函数分配物理地址。
动态库,也称为共享库。其核心优势在于:多个进程需要使用的相同资源(如库函数),只需在内存中保留一份副本,从而实现资源共享,节省内存空间。
那么,操作系统如何知道哪些库已经被加载到内存中了呢?实际上,系统中有很多库已经被加载到内存中,需要统一管理。遵循“先描述,再组织”的原则,操作系统会使用专门的数据结构(如结构体)来管理这些已加载的动态库信息。
动态链接的本质,是将链接的过程从传统的编译-链接阶段推迟到了程序加载的时候。这种延迟绑定机制带来了灵活性和资源效率的提升。
在C/C++程序中,当程序开始执⾏时,它⾸先并不会直接跳转到 main 函数。实际上,程序的⼊⼝点
是 _start ,这是⼀个由C运⾏时库(通常是glibc)或链接器(如ld)提供的特殊函数。
在 _start 函数中,会执⾏⼀系列初始化操作,这些操作包括:
- 设置堆栈:为程序创建⼀个初始的堆栈环境。
- 初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位
置,并清零未初始化的数据段。 - 动态链接:这是关键的⼀步, _start 函数会调⽤动态链接器的代码来解析和加载程序所依赖的
动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调
⽤和变量访问能够正确地映射到动态库中的实际地址。
动态库是没有main函数的!动态库内部,包含了大量的方法,每一个方法都要有自己的地址。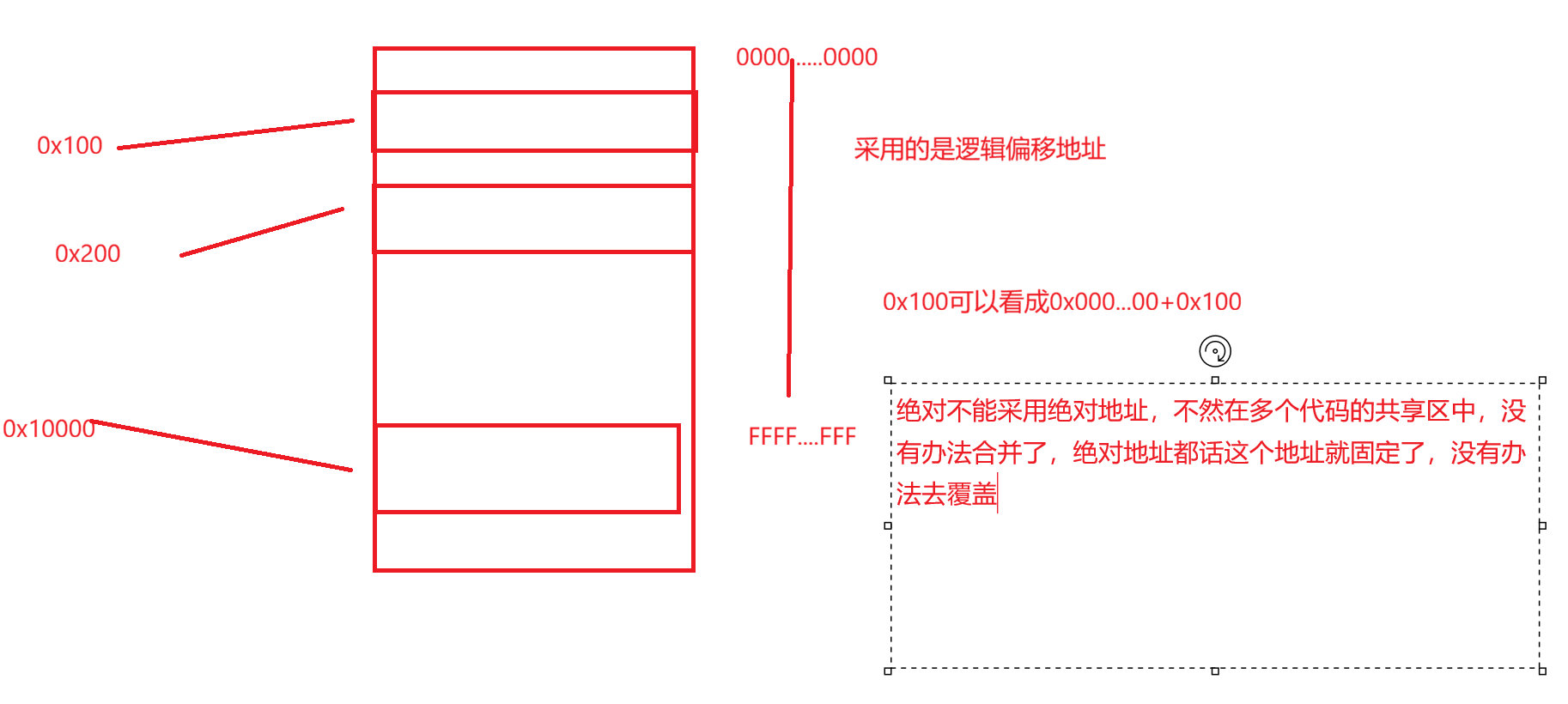
库加载:
第一步:定位与映射(发生在加载阶段)
当你启动程序时,动态链接器会先读取你的可执行文件,查看它依赖了哪些动态库ldd main.exe就可以查看到用了哪些头文件
动作:动态链接器在硬盘上找到这些库文件,然后将它们映射(mmap)到进程的虚拟内存空间中。
结果:此时,库的代码和数据依然躺在硬盘上,但操作系统已经在虚拟内存里给它们划好了专属的“地盘”(分配了虚拟地址),并建立好了“虚拟地址 -> 磁盘文件”的对应关系。
第二步:物理内存分配(发生在运行阶段)
这一步就是你之前理解非常到位的“缺页中断”环节。
动作:当 CPU 执行到库里的某行代码时,拿着虚拟地址去找物理内存,发现页表里没有记录(因为代码还在硬盘上)。
结果:触发缺页中断,操作系统赶紧把硬盘上对应的库代码真正搬运到物理内存中,并更新页表,将虚拟地址和物理地址绑定。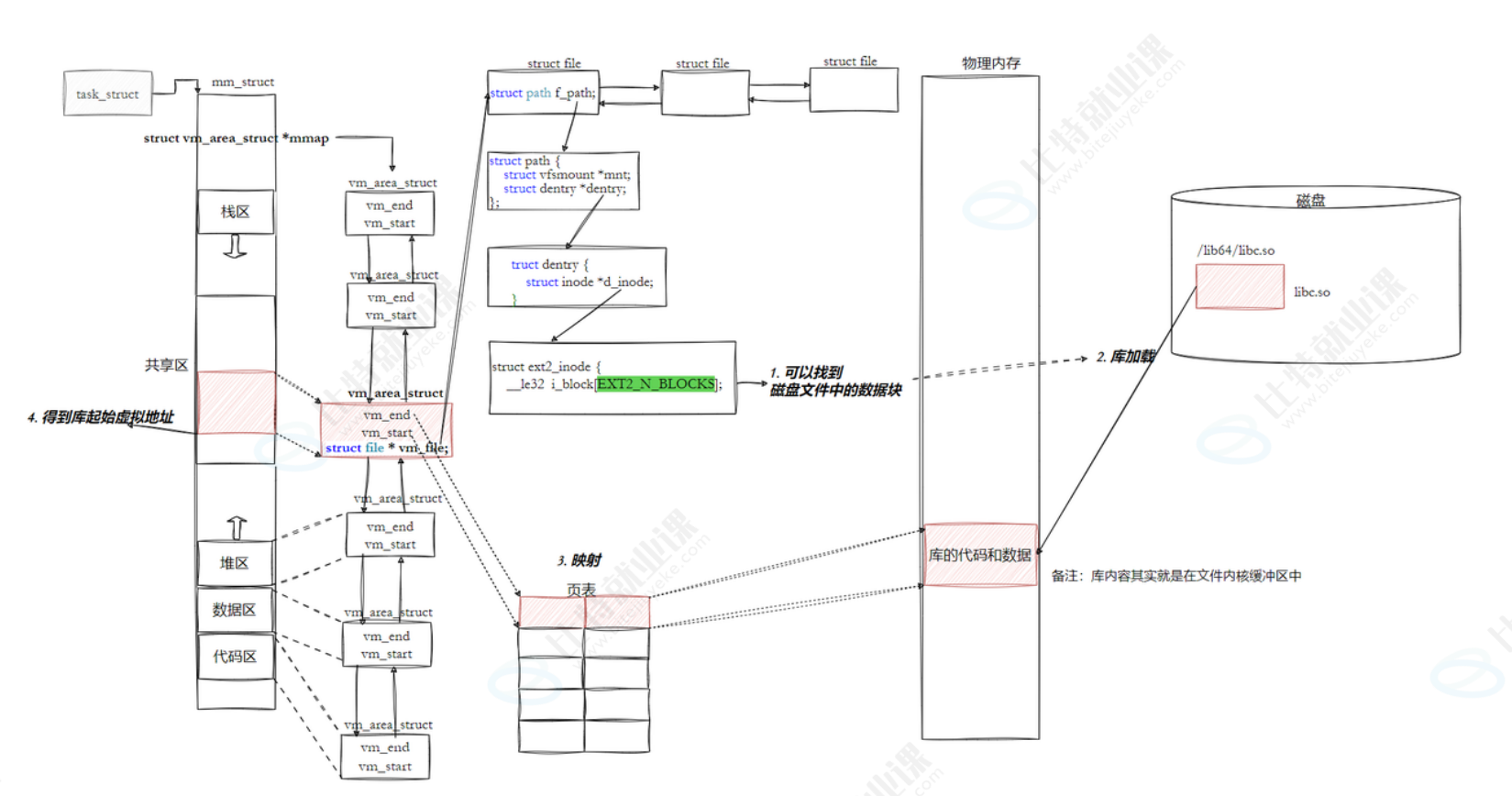
总过程:假设你现在要执行一个./program
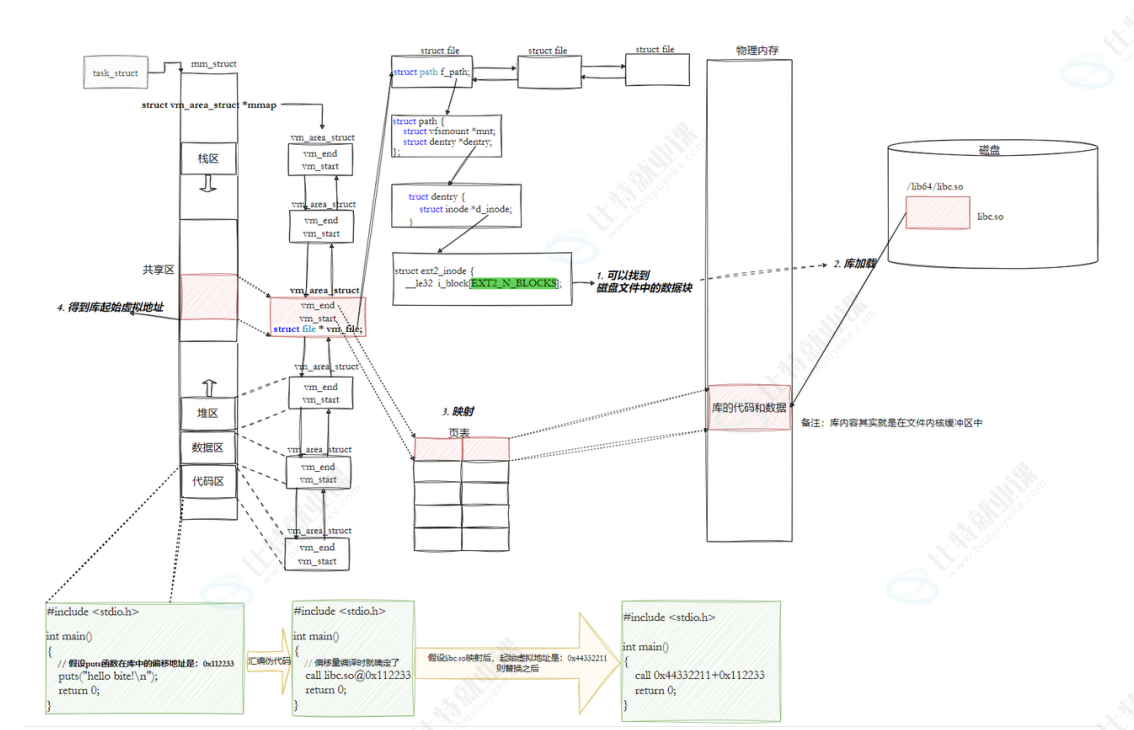
1.创建一个全新的PCB,分配独立的虚拟内存管理结构mm_struct(内核结构)
2.查看Program Header Table
如果是静态链接,PCB里面的ip直接指向main函数,程序跑起来
如果是动态链接,见到到了.interp段,里面会有动态链接器的路径,知道程序不完成,将动态链接器加载到内存中,将PCB中的寄存器修改为动态链接器的入口地址。
3.CPU的动态链接库查看这个不完成的程序到底缺少哪些库
4.通过PCB中的fs和files(文件描述符表)去磁盘中搜索这个路径。
5.有路径了,我就可以通过string path,找到对应的dentry(目录项缓存)在找到对应的inode,在找到对应的数据块,就得到了磁盘上的库了。(动态库)
库加载:
6.动态链接库找到了这个库文件之后,知道了他的大小,此刻,内核在进程PCB的mm_struct中所指向的虚拟地址空间中,专门在共享区创建了一块虚拟地中空间,给这个库函数分配虚拟地址。vm_file指针指向刚才文件系统中找到的libc.so文件的结构体(加载过程)
7.符号重定位(还未学到)
8.程序执行过程中,执行到了一行代码:printf
查找PCB对应的寄存器,跳转到了共享区中,查找对应的页表,发现页表对应的页表项是空的,触发缺页中断,物理加载,把磁盘中的代码块加载到物理内存中,恢复运行。
在执行第6步的时候,假设你用到的是libc.so,他给你分配的libc.so的放在进程共享区的0x7fff0000位置,这个位置我们叫做基地址,这时库函数里面的printf函数在库中的偏移量是0x5000;那么,这个printf在共享区中的地址就是:
函数的最终虚拟地址=库的虚拟基地址+函数在库中的偏移量(代码和数据)
代入:
0x7fff0000+0x5000=0x7fff5000
别的进程就算调用printf也是看到的这个地址,所以就能看到这个函数的物理内存了。
加载到时候,修改代码中的call后面的000…000修改为动态库中的起始虚拟地址+方法在库中的偏移量。
这种边加载程序,边修改调用库方法的地址,把这个过程,叫做动态链接的过程。
地址重定位(符号重定位)
地址重定位描述的是整个修改函数地址的过程(宏观层面),而符号重定位则特指对具体符号(如函数名、变量名)进行地址修正的操作(微观细节)。
地址重定位的核心任务,就是修改程序调用指令(如 call)后面跟随的目标地址,即函数地址。
这里引出一个关键问题:修改的是代码区(.text段)吗?不是说代码区在进程中是只读的吗?这怎么修改?真的能修改吗?
动态链接采用了一种巧妙的解决方案:在可执行程序或库自身的 .data 段(数据区) 中专门预留一片区域,用来存放外部函数的跳转地址。这片区域被称为全局偏移表(GOT,Global Offset Table)。表中的每一项都对应本运行模块需要引用的一个全局变量或函数的地址。
• 由于 .data 段(数据区)在程序运行时是可读写的,因此支持动态修改其中的内容,完美解决了代码区只读的限制。
一、 核心概念与角色扮演
在阅读流程前,必须死死记住这四个核心组件的职责:
- 代码区(只读,如光盘):程序运行期间绝对不允许修改。main 函数和 **PLT 表(过程链接表)**都住在这里。
- 数据区(可读写,如小本子):程序运行期间可以随便修改。**GOT 表(全局偏移表)**住在这里,专门用来存放外部函数的地址。
- 动态链接器(内核与用户态的秘书,ld.so):负责在运行时去磁盘找库文件、算地址、改写 GOT 表。
- PIC(位置无关代码技术):一种编译技术。利用“无论库怎么移动,代码区和数据区的相对距离保持不变”的物理特性,让 PLT 可以通过 %rip(当前指令位置)+ 固定偏移量,闭着眼睛精准摸到对应的 GOT 表格子。
二、 动态链接程序执行的全生命周期
假设场景:你的代码中有一行 printf(“Hello”);。
[磁盘阶段] call 0x0 (编译期,符号未绑定)
│
▼ 静态链接器介入
[磁盘阶段] call printf@plt (链接期,固定指向跳板)
│
▼ 运行程序 (./program)
[加载阶段] 内核圈地,GOT填入“假地址” (延迟绑定初始化)
│
▼ 第一次调用 printf
[运行阶段] 触发动态解析 -> 修改GOT -> 触发缺页中断 -> 真正执行
│
▼ 后面再次调用 printf
[运行阶段] PLT -> GOT(真地址) -> 直达物理内存 (瞬间完成)
【第一阶段】 编译与静态链接阶段(程序还在磁盘上)
- 源码编译:编译器在编译你的 main.m 或 main.cpp 时,看到 printf 这种外部函数,由于不知道它的地址,会在代码区的 call 指令后面留个空位(比如全 0)。
- 静态链接:静态链接器(ld) 介入。它在可执行文件的代码区(只读区)里,为 printf 专门建了一个专属的跳板格子,叫做 printf@plt。
- 钉死地址:链接器把刚才 main 函数里 call 后面的空位,修改为 printf@plt 的虚拟地址。
⚠️ 注意:改完之后程序存盘。代码区里的 call printf@plt 这一行字,在运行时是永远死锁、不能修改的。
【第二阶段】 装载阶段(程序刚跑起来,还没执行到函数)
- 内核创建环境:用户输入 ./program,内核为其创建一个全新的进程控制块 PCB(task_struct),并分配独立的虚拟内存管理结构 mm_struct。
- 检测不完整性:内核读取 ELF 文件的程序头表,检测到了 .interp 段(里面写着动态链接器的路径)。内核意识到这个程序是不完整的,它不会把控制权给 main,而是先把动态链接器加载到内存,把 CPU 寄存器指向动态链接器。
- 在共享区圈地:动态链接器通过当前进程 PCB 的 fs 和 files(文件描述符表)在磁盘上顺藤摸瓜(通过 dentry \rightarrow inode \rightarrow 数据块)找到了库文件 /lib64/libc.so。内核在 mm_struct 的**共享区(Shared Mapping Area)**里挖出了一块虚拟空间(vm_area_struct),并把 vm_file 指针拴在库文件上。
- 设置延迟绑定(温柔的陷阱):为了偷懒,动态链接器此时绝不去算库函数的真地址。它在数据区(可读写)的 GOT[printf] 表格子里,故意填入了一个**“假地址”**。
⚠️ 这个假地址是什么? 它绝对不是基地址+偏移量!它回指到了 printf@plt 格子里的第二条指令(小黑屋入口)。
【第三阶段】 运行阶段:第一次调用 printf(高能接力赛)
当程序真正执行到 printf(“Hello”); 这行代码时,会上演一场精彩的动态改写和物理加载:
- 步一(冲向跳板):CPU 执行代码区的 call printf@plt。
- 步二(PIC 定位):进入 PLT。PLT 的第一条指令是 jmp *偏移量(%rip)。这条指令利用 PIC 技术,根据当前执行位置加上固定距离,精准锁定了数据区的 GOT[printf] 表格子,CPU 进去读取里面的地址。
- 步三(踩中陷阱回流):CPU 一读,发现 GOT 表里是那个预填的假地址(小黑屋入口)。一根筋的 CPU 顺着假地址一迈腿,又跳回了 PLT 格子内部的第二条指令。
- 步四(贴标签):CPU 执行 PLT 里的第二条指令:push $序号。在栈里存下当前要找的函数号(比如 printf 是 1 号),这就打上了函数的记号。
- 步五(叫秘书):CPU 执行 PLT 里的第三条指令,通过公共通道跳转,把动态链接器(秘书)给叫了过来。
- 步六(算真地址并改写 GOT):动态链接器现身:
- 看一眼栈里的序号(噢,是要找 printf)。
- 查一下库文件,得知 printf 的内部相对偏移量。
- 查看进程的 mm_struct,拿到库在共享区的虚拟基地址。
- 算加法:真实虚拟地址= 共享区基地址 + 相对偏移量。
- 覆写改动:动态链接器拿着改字笔,冲到数据区的 GOT[printf] 表格子前,把原来的假地址擦掉,把刚刚算出来的“真实虚拟地址”写进去!
- 步七(触发缺页中断,物理加载):动态链接器把 CPU 领到共享区的真虚拟地址去执行代码。由于代码第一次被访问,物理内存里还是空的,CPU 硬件瞬间触发缺页中断。内核的中断处理程序接管,顺着 vm_file 线把磁盘上 libc.so 里的 printf 真实代码块抓进物理内存,并填好页表。
- 步八(恢复运行):通电,printf 成功在物理内存中执行,打印出 “Hello”。
【第四阶段】 运行阶段:第二次及以后调用 printf(瞬间直达)
随着程序继续向下跑,后面再次遇到了 printf 代码:
- CPU 执行代码区的 call printf@plt。
- 进入 PLT,第一条指令利用 PIC 技术瞬间定位到数据区的 GOT[printf] 格子。
- CPU 往 GOT 格子里一看——哇塞!里面躺着的已经是上一次动态链接器改好的“共享区真虚拟地址”了!
- CPU 根本不会再执行后面的 push 序号,也不会再找动态链接器。它拿上真地址,一脚油门穿过已经建好的页表,直达物理内存开始执行。
💡 终极复习口诀(应付考试/面试/笔记总结)
代码区死锁不能改(call 锁定 PLT),
数据区可写当盾牌(GOT 存指针)。
PIC 相对寻址是地图(%rip + 距离),
初次调用回流贴标签(push 序号找秘书)。
秘书现场算加法(基地址 + 偏移量),
改写 GOT 改生死,
缺页中断调代码,
从此访问走高速!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)