【2026年世界模型最全综述】:从开山之作到Sora与Genie 3
论文信息
- 标题:Understanding World or Predicting Future? A Comprehensive Surveyof World Models
- 会议:ACM Computing Surveys 2026(计算机领域顶级综述期刊)
- 单位:清华大学FIB-Lab
- 代码:https://github.com/tsinghua-fiblab/World-Model(包含所有代表性论文代码仓库汇总)
- 论文:https://arxiv.org/pdf/2411.14499
一、引言:AI的"大脑模拟器"时代来了
如果说2023年是大语言模型的爆发年,2024年是视频生成模型的元年,那么2025年毫无疑问是世界模型的黄金时代。从OpenAI的Sora能生成一分钟符合物理规律的视频,到DeepMind的Genie 3能实时交互生成游戏世界,再到清华大学的AgentSociety能模拟上万个智能体的社会演化,世界模型正在成为通往通用人工智能(AGI)的核心基石。
这篇由清华大学FIB-Lab团队撰写的综述是目前最全面、最新的世界模型综述,覆盖了从1943年心理学"心智模型"概念到2025年最新研究进展的完整历史,系统地将世界模型分为理解世界和预测未来两大核心功能,并深入探讨了它们在游戏、机器人、自动驾驶和社会模拟四大领域的应用。
通俗解释:世界模型就像AI的"大脑模拟器"。人类在做决定前会在脑子里"预演"一下可能的结果,比如过马路时会预判车辆的行驶轨迹。世界模型就是让AI也拥有这种能力——它能在虚拟空间里模拟世界的运行规律,然后根据模拟结果做出最优决策。
二、世界模型的前世今生与核心分类
2.1 从心理学概念到AI革命
世界模型的概念其实早在1943年就由苏格兰心理学家Kenneth Craik提出了。他在《解释的本质》一书中指出:"人类的大脑会构建现实的小规模模型,用来预测和理解外部事件。“这一观点后来被Philip Johnson-Laird发展为"心智模型理论”,成为现代认知科学的基础。
在AI领域,世界模型的发展可以分为几个关键阶段:
- 前深度学习时代(1960s-2017):从Minsky的框架理论到基于表格和简单函数的环境模型
- 模型强化学习时代(2018):David Ha和Jürgen Schmidhuber发表开山之作《Recurrent World Models Facilitate Policy Evolution》,正式将"世界模型"引入深度学习领域
- 自监督学习时代(2022):Yann LeCun提出JEPA架构,主张通过自监督学习在隐空间中预测世界状态
- 大语言模型时代(2023):LLM被发现天然蕴含丰富的世界知识,成为世界模型的强大 backbone
- 视频生成时代(2024-2025):Sora、Genie等模型通过生成视频来显式模拟世界动态
2.2 世界模型发展路线图
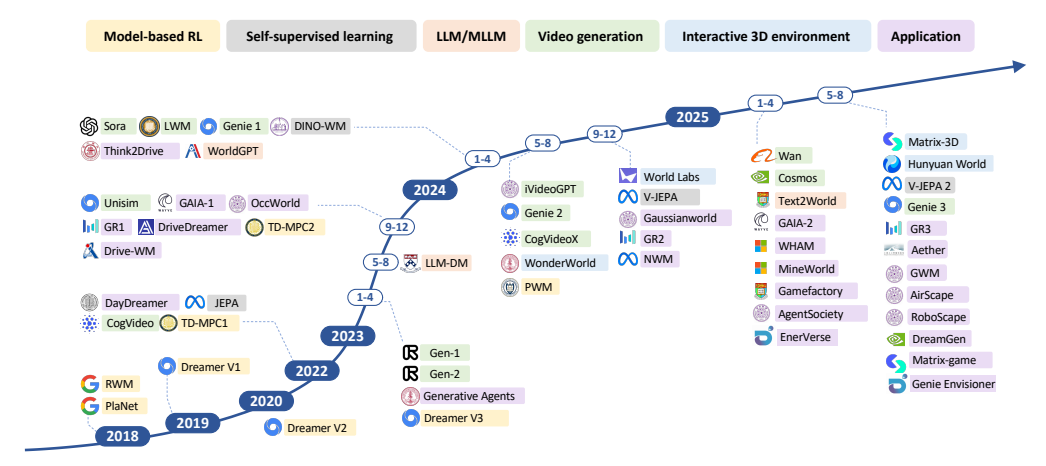
图1 深度学习时代世界模型发展路线图(来源:原论文Figure 1)
图1分析:这张图清晰地展示了世界模型从2018年到2025年的爆发式发展。可以看到:
- 2018-2022年:主要集中在模型强化学习领域,代表模型有RWM、Dreamer系列
- 2023年:开始向多模态扩展,出现了V-JEPA、Gen-2等模型
- 2024年:视频生成模型爆发,Sora、GAIA-1、Drive-WM等相继问世
- 2025年:进入交互式世界模型时代,Genie 3、Cosmos、Aether等模型实现了实时交互和物理规律的高度遵从
2.3 论文的核心分类框架
这篇综述最大的贡献就是提出了一个全新的世界模型分类体系,将所有研究分为两大核心功能:
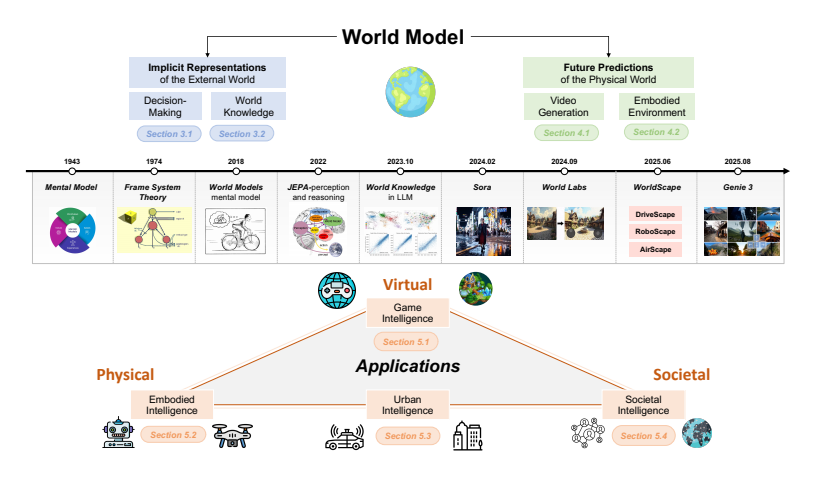
图2 世界模型整体分类框架(来源:原论文Figure 2)
-
外部世界的隐式表示:AI通过学习将外部世界转化为抽象的隐变量,就像人类对世界的"概念理解"。这部分又分为:
- 决策中的世界模型(主要用于强化学习)
- 模型学到的世界知识(主要来自大语言模型)
-
物理世界的未来预测:AI通过生成视频或3D环境来显式模拟世界的未来状态。这部分又分为:
- 作为视频生成的世界模型
- 作为具身环境的世界模型
通俗解释:“隐式表示"就像你脑子里知道"苹果是红色的、圆的、会从树上掉下来”,但不需要真的画出来;"未来预测"就像你能在脑子里想象出"苹果从树上掉下来砸到牛顿头上"的完整过程。
三、外部世界的隐式表示:AI如何"理解"世界
3.1 决策中的世界模型:强化学习的"大脑"
在强化学习中,世界模型本质上就是环境的动力学模型。一个典型的马尔可夫决策过程(MDP)可以表示为一个元组:
(S,A,M,R,γ)(S, A, M, R, \gamma)(S,A,M,R,γ)
其中:
- SSS:状态空间(环境所有可能的状态集合)
- AAA:动作空间(智能体所有可能的动作集合)
- MMM:状态转移动力学(给定当前状态和动作,预测下一个状态的概率分布)
- RRR:奖励函数(给定当前状态和动作,返回即时奖励)
- γ\gammaγ:折扣因子(未来奖励的衰减系数,通常在0到1之间)
通俗解释:这个公式就像一个游戏规则说明书。SSS是游戏里所有可能的场景,AAA是你能做的所有操作,MMM是游戏的物理引擎(告诉你按了跳跃键后角色会跳多高),RRR是得分规则(吃到金币加10分),γ\gammaγ是"及时行乐"系数(现在的10分比未来的10分更有价值)。
世界模型的核心任务就是学习这个状态转移动力学MMM。最基本的学习目标是最小化预测状态和真实状态之间的均方误差:
minθEs′∼M∗(⋅∣s,a)[∥s′−Mθ(s,a)∥22]\min_{\theta} \mathbb{E}_{s' \sim M^*(\cdot | s,a)} \left[ \| s' - M_{\theta}(s,a) \|_2^2 \right]θminEs′∼M∗(⋅∣s,a)[∥s′−Mθ(s,a)∥22]
其中:
- θ\thetaθ:世界模型的参数
- M∗M^*M∗:真实的环境动力学(我们想要学习的目标)
- MθM_{\theta}Mθ:我们训练的参数化世界模型
- E\mathbb{E}E:数学期望(对所有可能的状态-动作对求平均)
- ∥⋅∥22\| \cdot \|_2^2∥⋅∥22:L2范数的平方(也就是均方误差)
通俗解释:这个公式的意思就是"让模型预测的下一个状态和真实发生的下一个状态的差距越小越好"。就像你练习投篮,每次投完后都会根据实际结果调整自己的投篮姿势,直到预测的球的轨迹和实际轨迹几乎一致。
除了确定性的均方误差损失,还有概率性的损失函数,比如KL散度:
minθEs′∼M∗(⋅∣s,a)[log(M∗(s′∣s,a)Mθ(s′∣s,a))]\min_{\theta} \mathbb{E}_{s' \sim M^*(\cdot | s,a)} \left[ \log \left( \frac{M^*(s' | s,a)}{M_{\theta}(s' | s,a)} \right) \right]θminEs′∼M∗(⋅∣s,a)[log(Mθ(s′∣s,a)M∗(s′∣s,a))]
这种方法可以更好地建模环境中的不确定性,比如当你扔一个骰子时,结果是随机的,而不是确定的。
两种决策范式
在强化学习中,使用世界模型有两种主要范式:
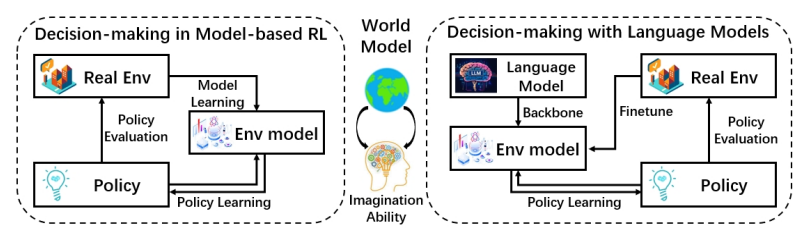
图3 决策中使用世界模型的两种范式(来源:原论文Figure 3)
-
模型强化学习范式:先学习世界模型,然后在世界模型中通过"想象"来训练策略。代表模型有Dreamer系列,其中最新的DreamerV3已经能在没有人类数据和领域特定调优的情况下解决超过150个任务,包括在Minecraft中收集钻石!
-
语言模型骨干范式:利用大语言模型作为世界模型的骨干,直接生成动作或者作为规划模块。比如在导航任务中,LLM可以根据环境描述生成下一步的移动指令。
3.2 模型学到的世界知识:LLM的"常识库"
大语言模型在预训练过程中,从海量的文本数据中自动学到了丰富的世界知识。这篇综述将这些知识分为四大类:
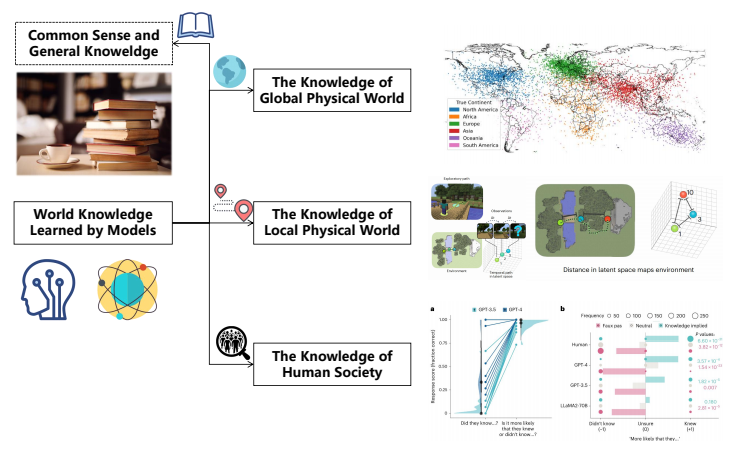
图4 大语言模型中的世界知识分类(来源:原论文Figure 4)
| 知识类别 | 包含内容 | 代表研究 |
|---|---|---|
| 常识与通用知识 | 日常生活中的基本事实和规律 | KoLA(2024), EWOK(2024) |
| 全球物理世界知识 | 地理、空间、时间等宏观知识 | GeoLLM(2024), CityGPT(2025) |
| 局部物理世界知识 | 物体属性、空间关系、物理规律 | Predictive(2024), Spatial457(2025) |
| 人类社会知识 | 心理理论、社会规则、文化习俗 | Testing ToM(2024), COKE(2024) |
表1 大语言模型世界知识研究概览(来源:原论文Table 1)
有趣案例:2024年的一项研究发现,Llama2模型中存在专门的"空间神经元"和"时间神经元"!这些神经元会对不同的地理位置和时间点产生特异性激活,说明LLM确实在内部构建了一个关于世界的"认知地图",而不仅仅是记住了文本的统计规律。
四、物理世界的未来预测:AI如何"想象"未来
4.1 作为视频生成的世界模型:从Sora到Cosmos
视频生成模型是当前世界模型最热门的研究方向。与传统的隐式表示不同,视频生成模型通过直接生成视觉序列来展示它们对世界动态的理解。
Sora:视频世界模型的里程碑
OpenAI的Sora无疑是视频世界模型的里程碑。它能生成长达一分钟的高质量视频,并且在很多情况下能正确模拟物理规律,比如物体的碰撞、光影的变化等。但Sora也有明显的局限性:
- 因果推理能力不足:它只能被动生成序列,不能主动预测动作对事件的影响
- 物理规律不一致:经常出现物体穿透、重力异常等错误
- 缺乏交互能力:用户不能在生成过程中干预视频的发展
视频世界模型的关键能力
一个优秀的视频世界模型需要具备以下能力:
- 长期预测能力:能生成长时间保持一致性的视频
- 多模态整合能力:能处理文本、图像、动作等多种输入
- 交互能力:能响应用户的输入,动态调整生成内容
- 多环境适应能力:能在不同的场景中生成符合规律的视频
| 能力维度 | 代表模型 | 核心技术 |
|---|---|---|
| 长期生成 | StreamingT2V, GAIA-1 | Transformer, 长短期记忆块 |
| 多模态 | 3D-VLA, Pandora | 跨模态注意力机制 |
| 交互式 | VideoDecision, Aether | 动作条件扩散模型 |
| 一致性 | DiffDreamer, WorldMem | 记忆机制, 关键帧生成 |
表2 视频生成世界模型分类(来源:原论文Table 2)
最新进展:2025年1月发布的Cosmos模型是专门为物理世界模拟设计的视频生成基础模型。它通过在海量真实物理视频上预训练,在物理规律遵从性方面取得了突破性进展,能正确模拟流体动力学、刚体碰撞等复杂物理现象。
4.2 作为具身环境的世界模型:从静态到动态
视频生成模型只能生成被动的视觉序列,而具身环境世界模型则能创建可交互的3D虚拟环境,让智能体在其中进行探索和学习。
这篇综述将具身环境世界模型分为三类:
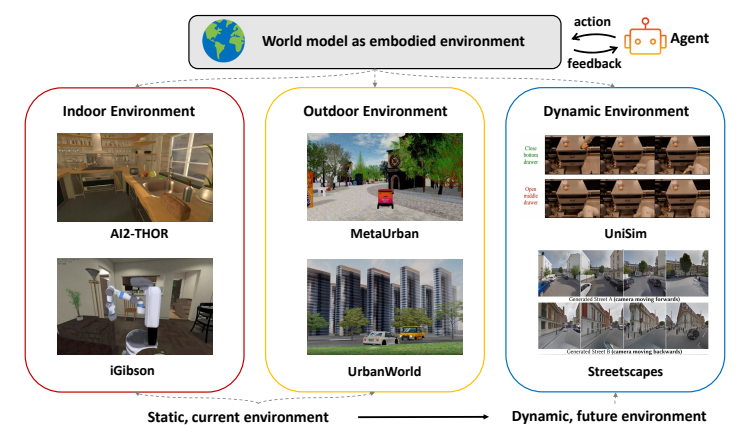
图5 具身环境世界模型分类(来源:原论文Figure 5)
- 室内环境:如AI2-THOR、VirtualHome等,主要用于家庭机器人任务训练
- 室外环境:如MetaUrban、MineDOJO等,用于城市导航和开放世界任务
- 动态环境:如UniSim、Aether等,利用生成模型动态创建场景,是当前的研究热点
| 环境类型 | 代表平台 | 场景数量 | 支持模态 | 物理模拟 |
|---|---|---|---|---|
| 室内 | AI2-THOR(2017) | 120 | 视觉 | ✓ |
| 室内 | Holodeck(2024) | 任意 | 视觉 | ✓ |
| 室外 | MetaUrban(2024) | 13800 | 视觉+激光雷达 | ✓ |
| 动态 | Aether(2025) | 任意 | 视觉+文本 | ✓ |
表3 具身环境世界模型对比(来源:原论文Table 3)
有趣案例:2025年的RoboScape模型是第一个物理感知的具身世界模型。它在视频生成过程中整合了深度图和关键点动力学,能生成符合物理规律的机器人运动轨迹。用RoboScape生成的合成数据训练的机器人策略,在真实世界中的表现比用传统模拟器数据训练的策略提升了30%以上!
五、世界模型的四大应用领域
5.1 游戏智能:生成式游戏的未来
游戏是世界模型最理想的测试场,因为游戏有明确的规则和清晰的奖惩机制。世界模型正在彻底改变游戏开发的方式:
- 交互性:GameNGen实现了完全基于神经网络的游戏引擎,能以20帧/秒的速度运行实时交互游戏
- 一致性:WHAM模型能生成一致且多样化的游戏序列,并且能保留用户对游戏世界的修改
- 泛化性:GameFactory能利用预训练视频扩散模型的通用先验,创建全新风格的游戏
未来展望:生成式无限游戏将成为可能。想象一下,你进入一个游戏,整个世界都是根据你的喜好和行为动态生成的,没有固定的剧情和结局,每次玩都有全新的体验!
5.2 具身智能:机器人的"虚拟训练场"
世界模型为机器人学习提供了一个安全、高效的虚拟训练场。传统的机器人训练需要在真实世界中进行大量的试错,成本高且风险大。而世界模型可以:
- 生成合成数据:DreamGen模型能生成高质量的机器人动作视频,用于训练视觉-语言-动作(VLA)模型
- 指导动作生成:UniPi模型将动作预测转化为视频生成问题,通过可视化未来场景来指导机器人行动
- 评估策略性能:IRASim模型能根据初始帧和动作序列生成对应的视频,用于评估机器人策略的性能
突破性进展:DayDreamer模型让机器人能在真实世界中直接学习运动技能,只需要几个小时的训练就能学会走路,大大减少了对模拟环境的依赖。
5.3 城市智能:自动驾驶与城市分析
世界模型在城市智能领域有广泛的应用,其中最成熟的是自动驾驶:

图6 世界模型在自动驾驶中的应用(来源:原论文Figure 6)
在自动驾驶中,世界模型主要有两种应用方式:
- 场景理解:通过感知数据学习驾驶场景的隐式表示,用于目标检测、轨迹预测等任务
- 世界模拟器:直接生成未来的驾驶场景视频或占用网格,用于规划和决策
代表模型:GAIA-1是第一个生成式自动驾驶世界模型,它能根据文本、图像和动作输入生成逼真的驾驶场景视频。Drive-WM则引入了闭环控制,能根据规划结果动态调整生成的场景。
除了自动驾驶,世界模型还在城市分析、自主物流等领域有重要应用。比如CityGPT模型能增强大语言模型的城市空间认知能力,用于城市规划和管理。
5.4 社会智能:模拟人类社会的演化
世界模型最令人兴奋的应用之一是社会模拟。通过创建由大量LLM驱动的智能体组成的虚拟社会,我们可以研究复杂的社会现象,比如信息传播、群体行为、经济系统等。
里程碑工作:2023年的Generative Agents(生成式智能体)创建了一个由25个智能体组成的虚拟小镇。这些智能体有自己的记忆、性格和目标,能进行自然的社交互动,甚至会自发组织活动,比如举办派对!
最新进展:2025年的AgentSociety平台能模拟上万个智能体的社会演化,已经被用于研究极化现象、政策干预等重要社会问题。
六、开放问题与未来方向
尽管世界模型取得了巨大的进展,但仍然面临许多挑战:
6.1 物理规则与反事实模拟
当前的数据驱动生成模型虽然能生成看起来很真实的视频,但在理解和遵从物理规律方面仍然存在很大不足。比如Sora经常会生成物体穿透、重力异常等不符合物理规律的内容。
未来方向:混合方法,即将显式的物理模拟器与数据驱动的生成模型结合起来。比如PhysGen模型将刚体模拟器与扩散细化器结合,能生成物理上合理的运动。
6.2 丰富社会维度
当前的世界模型主要关注物理世界的模拟,而对人类行为和社会互动的模拟还比较初级。设计能模拟真实人类行为和社会动态的智能体是一个重要的研究方向。
6.3 基准测试
由于世界模型的目标和技术路线非常多样化,目前还没有一个统一的基准测试。这使得不同模型之间的比较变得非常困难。
| 基准类别 | 代表基准 | 测试内容 |
|---|---|---|
| 视频模拟 | WorldSimBench, VBench-2.0 | 视觉质量、时间一致性、物理遵从性 |
| 物理推理 | Physics-IQ, T2VPhysBench | 对基本物理规律的理解 |
| 具身决策 | EAI, EWMBench | 场景一致性、运动正确性、语义对齐 |
表4 世界模型基准测试汇总(来源:原论文Table 8)
6.4 模拟到现实的鸿沟
如何将在虚拟世界中训练的策略有效地迁移到真实世界,是一个长期存在的问题。世界模型通过学习通用的世界表示,有望缩小这一鸿沟。
6.5 模拟效率
当前的大模型推理速度较慢,无法满足实时模拟的需求。比如Transformer的自回归特性只能一次生成一个token,这对于需要每秒生成几十帧的游戏和机器人应用来说是一个巨大的挑战。
6.6 伦理与安全问题
世界模型的发展也带来了新的伦理和安全挑战:
- 数据隐私:训练世界模型需要大量的数据,可能会侵犯个人隐私
- 不安全场景模拟:恶意用户可能会利用世界模型模拟有害场景,用于策划非法活动
- 虚假信息:世界模型能生成高度逼真的视频和3D环境,可能会被用于制造和传播虚假信息
七、核心代码:简化版DreamerV3世界模型实现
下面是一个简化版的DreamerV3世界模型核心实现,包含编码器、动力学模型和奖励模型三个主要部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class WorldModel(nn.Module):
"""
简化版DreamerV3世界模型
包含编码器、动力学模型和奖励模型
"""
def __init__(self, obs_dim=64, action_dim=6, hidden_dim=512, latent_dim=32):
super().__init__()
self.obs_dim = obs_dim
self.action_dim = action_dim
self.hidden_dim = hidden_dim
self.latent_dim = latent_dim
# 编码器:将观测图像编码为隐状态
# 通俗解释:就像人的眼睛把看到的画面转化为大脑能理解的信号
self.encoder = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(128, 256, kernel_size=4, stride=2),
nn.ReLU(),
nn.Flatten(),
nn.Linear(256 * 2 * 2, hidden_dim),
nn.ReLU()
)
# 动力学模型:根据当前隐状态和动作预测下一个隐状态
# 通俗解释:就像人的大脑根据当前情况和将要做的动作,预测接下来会发生什么
self.dynamics = nn.GRUCell(hidden_dim + action_dim, hidden_dim)
# 奖励模型:根据隐状态预测即时奖励
# 通俗解释:就像人的大脑判断当前情况是好是坏
self.reward_head = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
# 观测解码器:从隐状态重建观测图像(用于训练)
self.decoder = nn.Sequential(
nn.Linear(hidden_dim, 256 * 2 * 2),
nn.ReLU(),
nn.Unflatten(1, (256, 2, 2)),
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(32, 3, kernel_size=4, stride=2),
nn.Sigmoid()
)
def forward(self, obs, action, hidden=None):
"""
前向传播
参数:
obs: 观测图像,形状为(batch_size, 3, 64, 64)
action: 动作,形状为(batch_size, action_dim)
hidden: 上一步的隐状态,形状为(batch_size, hidden_dim)
返回:
next_hidden: 下一个隐状态
reward_pred: 预测的奖励
obs_recon: 重建的观测图像
"""
# 编码当前观测
obs_encoded = self.encoder(obs)
# 如果没有提供隐状态,就用编码后的观测初始化
if hidden is None:
hidden = obs_encoded
# 预测下一个隐状态
dynamics_input = torch.cat([obs_encoded, action], dim=1)
next_hidden = self.dynamics(dynamics_input, hidden)
# 预测奖励
reward_pred = self.reward_head(next_hidden)
# 重建观测(用于训练)
obs_recon = self.decoder(next_hidden)
return next_hidden, reward_pred, obs_recon
# 测试代码
if __name__ == "__main__":
# 创建世界模型实例
world_model = WorldModel()
# 生成随机输入
batch_size = 4
obs = torch.randn(batch_size, 3, 64, 64)
action = torch.randn(batch_size, 6)
# 前向传播
next_hidden, reward_pred, obs_recon = world_model(obs, action)
print(f"输入观测形状: {obs.shape}")
print(f"输出隐状态形状: {next_hidden.shape}")
print(f"预测奖励形状: {reward_pred.shape}")
print(f"重建观测形状: {obs_recon.shape}")
代码解释:
- 这个简化版世界模型实现了DreamerV3的核心思想:在隐空间中学习世界的动力学
- 编码器将高维的图像观测压缩为低维的隐状态
- 动力学模型预测隐状态的演化
- 奖励模型预测每个状态的奖励
- 解码器用于重建观测,作为训练的辅助损失
八、结论
世界模型正在成为人工智能领域最热门的研究方向之一。这篇综述系统地梳理了世界模型的发展历史、核心技术和应用领域,提出了"理解世界"和"预测未来"的二元分类框架,并指出了未来的研究方向。
从2018年的开山之作到2025年的Genie 3和Cosmos,世界模型已经从一个小众的强化学习技术发展为通往通用人工智能的核心基石。未来,随着物理规律建模、社会模拟、模拟效率等问题的逐步解决,世界模型将在游戏、机器人、自动驾驶、社会科学等领域发挥越来越重要的作用。
正如Yann LeCun所说:"如果没有世界模型,AI就永远无法达到人类水平的智能。"世界模型的时代已经到来,让我们拭目以待它将带来的革命性变化!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献86条内容
已为社区贡献86条内容

所有评论(0)