[QA] 如何测试一个 Agent:面向复杂 AI 应用的分层测试方法
背景
进入公司后,一直所在的部门属于算法部,作为 QA,经历了模型传统机器学习阶段、深度学习阶段,再到 23 年左右的大模型阶段,需求周期越来越短,迭代节奏越来越快。最开始做 OCR 业务测试那会,需求提出来后,光是local 打标都要一个月,还要训练,还要评测,出模型,工程结合算法提交最终的 API,一个周期下来一两个月。大模型时候来了后,需求的周期慢慢缩到了1 个月,训练更多地是强化学习;后面为了加强知识领域的能力,减少模型幻觉,出现了 RAG,各种知识的检索,筛选,解决冲突。
从 24 年开始一直负责智能 客服系统的测试,后端全是一个个模型+工程能力实现的单 API,一个 API 负责一块能力,通过 API 将流程串起来。一旦第一个环节做意图识别出现问题,后面基本都废了,另外几十个接口管理起来很痛苦,就来到了Multi-Agent 架构升级阶段了。一下子收敛成可分工、可编排、可观测的智能协作链路,让意图识别、任务规划、工具调用、专家处理和结果生成各司其职,降低链路耦合,也提升复杂任务的可维护性与可扩展性,现在就来说说作为 QA,怎么保证这块质量。
大模型应用和传统软件最大的不同在于:它不是一个单纯的确定性程序,而是由协议、路由、Prompt、模型输出解析、规划器、工具调用、状态流转、风控兜底和最终回复共同组成的系统,Multi-Agent 可以理解为每个 agent 负责的领域不一样,就像不同的职责分工。比如我们会有 Main agent、Planner agent、expert agent,Rewrite / Final Agent、Risk Control Agent。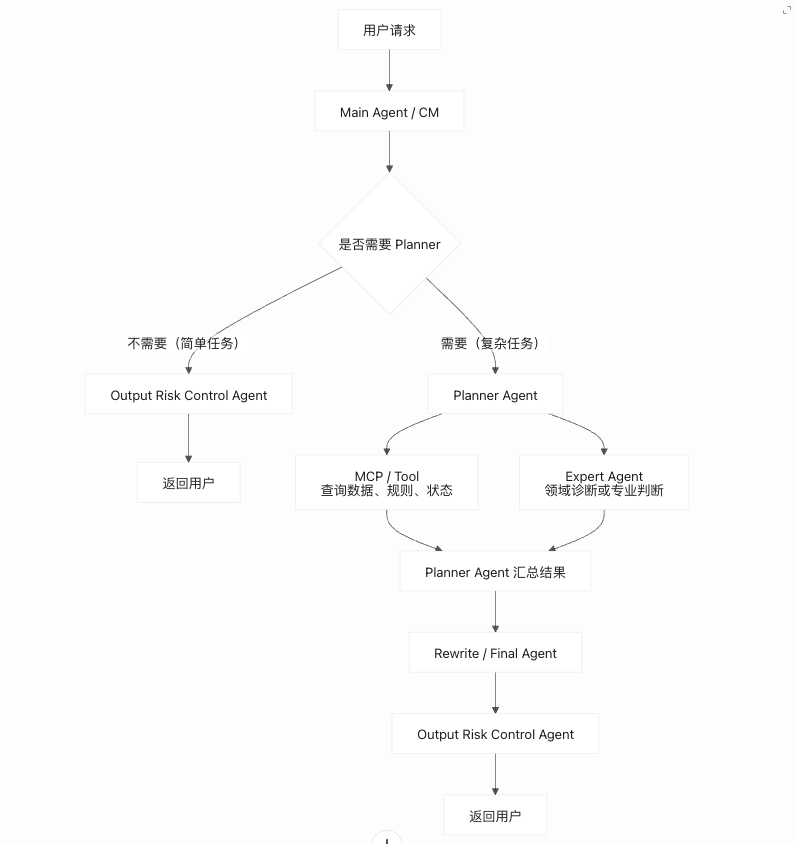
如果只看最终回答,很容易出现两个问题:
第一,结果看起来对,但过程可能错了。例如 Agent 调用了错误工具、没有做必要诊断、遗漏关键状态,只是靠模型“猜”出了一个看似合理的答案。
第二,结果看起来不稳定,但不知道该改哪里。到底是意图识别错了、Planner 拆解错了、工具返回错了、模型解析失败,还是最终 Rewrite 表达不清楚?
所以,Agent 测试不能只做“问答对不对”的黑盒测试,而应该做分层测试。
本文介绍一种三层测试方法,适用于诊断类、电商经营类、数据分析类、客服类等复杂 Agent 场景。
为什么 Agent 需要分层测试
传统应用的测试边界通常比较清晰:
- 接口输入输出是否正确
- 业务逻辑是否符合预期
- 数据库状态是否正确变更
- 前端展示是否正常
但 Agent 系统的问题更复杂,常见风险包括:
- 用户输入表达多样,同一个意图可能有几十种问法
- 模型输出不稳定,JSON 格式、字段值、语义内容都可能波动
- Agent 需要在多个能力之间路由,例如直接回答、规划、工具调用、转人工、风控拦截
- Planner 可能拆错步骤,或者调用了不合适的工具
- 工具返回结构正确,但模型理解错了
- 最终回答可能编造数据,或者把内部错误暴露给用户
- 多轮对话里状态可能丢失、串话、重复执行
因此,一个有效的 Agent 测试体系,至少要回答三类问题:
- 每个组件本身是否可靠?
- 多个组件串起来时,过程是否正确?
- 最终用户体验和业务效果是否达标?
对应地,可以把测试分成三层。
三层测试模型
我觉得把把 Agent 测试分为三层比较好:
用户输入query -->
组件契约层:协议 / Prompt/ 解析器 / 工具契约
Agent 编排层:路由 /Planner / 工具调用 /状态流转 / 风控
业务场景层:最终回答 /用户体验 / 效果评测 /回归集
这三层不是按代码目录划分,而是按测试目标划分。
第一层:组件契约层
组件契约层关注的是:每个基础组件是否按约定工作。
这一层不关心完整对话效果,而是验证单点能力是否稳定、可解析、可复用。
测试目标
组件契约层主要测试:
- 输入协议是否能被正确解析;
- Prompt 是否能稳定生成, 这里需要查看 prompt 槽位填写的信息是否正确、无丢失等;
- 写到 Redis 的 memory 数据格式、状态是否正确;
- 模型输出是否符合 schema,这个一般在 TD 时会定输入输出;
- 输出解析器是否能兼容异常格式;
- 工具 / MCP / Expert 的入参和返回结构是否符合契约;
- 风控模块是否返回标准字段;
- 卡片、结构化消息、finish 状态等协议字段是否完整;
这一层的核心是:把不稳定的大模型输出,约束成系统可消费的稳定结构。
应该覆盖哪些模块
在一个典型 Agent 中,下面这些都属于组件契约层:
| 模块 | 测试重点 |
|---|---|
| 协议解析 | 必填字段、默认值、异常输入、历史消息解析 |
| Prompt 构造 | 变量是否完整、上下文是否注入正确、敏感信息是否泄露 |
| 模型输出 Schema | JSON 是否合法、字段是否齐全、枚举值是否正确 |
| 输出解析器 | 半截 JSON、额外文本、字段缺失、类型错误时是否兜底 |
| 工具 / MCP 契约 | 入参 Schema、返回 Schema、错误结构、空数据结构 |
| Expert 契约 | 是否返回标准 agent_result、error_code、data_type |
| 风控契约 | 是否返回 has_risk、risk_text 等稳定字段 |
| 卡片协议 | card_type、card_payload、展示字段是否完整 |
测试方法
在测试初期,不一定马上建设完整自动化。通过一个简单 demo不带复杂业务逻辑的接口请求去检查这些项,可以从入口层,也可以从Agent 通过 A2A 协议进行请求,可以先通过 Log 或 Langfuse trace 手动检查关键协议内容是否符合预期,初期只任何做手工测试,检查无误后,可通过 pytest写成自动化 case,用作测试准出的第一层判断。比如这层自动化失败后,就没必要做端到端的自动化了,节约成本,减少模型调用。
示例:路由输出契约测试
对于诊断类 Agent,模型第一步通常需要判断用户问题是否需要进一步诊断。
例如用户问:
为什么我不能报名某个活动?
期望模型不要直接编答案,而是输出一个结构化决策(main agent 这层)
{
“action”: “call_planner”,
“response_language”: “Bahasa Indonesia”,
“response”: [
{
“type”: “text”,
“content”: “Baik Kak, bantu cek dulu ya.”
}
],
“need_planner_reason”: “Query requires seller-specific eligibility check”,
“idk”: false,
“transfer_to_human”: false,
“followup_questions”: []
}
初版重点检查:
- 请求协议是否完整,例如 query、session_id、user_id、region 等字段是否正确传递
- 路由模型输出是否符合预期,例如 action、need_planner_reason、response 等字段
- Planner 输入是否包含必要上下文
- Tool / MCP / Expert 的入参与返回结构是否符合约定
- 最终输出协议是否完整,例如文本、卡片、风控结果、finish 状态等
- 异常情况下是否有兜底字段,而不是直接抛出内部错误
- Log 更适合确认系统层面的字段传递、异常、超时、状态变化;
Langfuse 更适合查看 Prompt、模型原始输出、Planner结果、工具调用和最终回答。这一阶段的目标是先把协议链路看清楚,确认每个组件的输入输出边界是否稳定。
自动化需要覆盖维度:
- 第一类是规则断言。
例如:
assert action in [“direct_response”, “call_planner”, “final_response”]
assert if action == “call_planner”, need_planner_reason != “”
assert response is valid array
assert no unsupported card_type - 第二类是 schema 校验。
所有模型输出、工具输出、Expert 输出都应该有 JSON Schema 或等价结构定义,测试时自动校验。 - 第三类可以加一些异常样本测试。
专门构造一些模型常见坏输出,模拟(mock)模型输出,看看工程部分的兼容情况:
JSON 前后多了自然语言
字段缺失
字段类型错误
action 拼写错误
输出了不支持的 card_type
返回空 response
返回了重复 finish
工具返回空数据
工具返回 error
这一层的目标不是让模型永远不犯错,而是保证系统遇到坏输出时能识别、修复或兜底。
第二层:Agent 编排层
Agent 编排层关注的是:多个组件串起来之后,决策过程是否正确。
这一层不是只看最终回答,而是看 Agent 的“过程数据”。
比如一个诊断类问题,理想过程可能是:
识别为诊断类问题
选择调用 Planner
Planner 拆出合理步骤
调用相关工具或专家能力
汇总结果
Rewrite 成用户能理解的回复
经过风控
输出 finish
如果最终回答看起来不错,但中间没有调用任何诊断工具,那其实是不合格的。
测试目标
Agent 编排层主要回答:
- 是否识别出正确意图
- 是否走了正确路由
- 是否应该调用 Planner Planner
- 是否拆出合理步骤
- 是否调用了正确工具 / MCP /Expert
- 工具调用顺序是否合理
- 状态是否正确流转
- 多轮上下文是否正确继承
- 失败时是否进入兜底流程
- 最终是否 finish 是否经过风控
过程数据是关键,Agent 编排测试必须依赖 trace 数据。
我们系统是接入了 langfuse。Langfuse 可以理解为一个面向 LLM 应用的可观测与评测平台。它可以记录一次 Agent 请求中的完整 trace,至少应该包含:
用户输入
Prompt
模型原始输出
路由结果
Planner 过程
Tool / MCP / Expert 调用
Rewrite 输出
最终回答
没有 trace,就只能做黑盒评测;有 trace,才能定位问题发生在哪一环。
测试方法
这里就需要一个真正业务的请求 URL 发起测试了,或者通过端上发起真正的对话内容。然后拿到 trace_id去 langfuse 追溯调用链路。
自动化建设这一步可以和第三层合并在一起,进行 agent case回归评测。----我后面写一下我们怎么做的。
示例:诊断类问题的编排断言
以“为什么我不能报名某个项目”为例,可以设计如下断言:
用户 query:
“为什么我不能报名某个项目?”
期望过程:
- CM action = call_planner
- need_planner_reason 非空,且语义与“需要查询用户/店铺状态”相关
- Planner 至少调用一个状态查询类工具
- Planner 至少调用一个规则/知识类工具
- 如果问题属于项目报名/资格判断,需要调用资格检查相关能力
- 最终 Rewrite 不能编造工具没有返回的数据
- 最终回答需要说明:
- 当前状态
- 可能原因
- 下一步操作建议
- 风控通过
- 最终输出 finish = true
Agent 编排层的典型用例
建议覆盖以下场景:
| 场景 | 测试重点 |
|---|---|
| 纯闲聊 | 应该 direct_response,不应调用 Planner |
| 概念解释 | 可以直接回答,但不能编造个性化数据 |
| 个性化诊断 | 应该 call_planner,并调用相关工具 |
| 数据查询 | 应该调用数据工具,不能直接猜 |
| 多轮追问 | 应继承上一轮状态 |
| 用户否定/修改 | 状态应更新,不能继续旧计划 |
| 工具空返回 | 应给出合理兜底,不暴露内部错误 |
| 工具报错 | 应隐藏内部错误,给用户可执行建议 |
| 风险输入 | 应触发风控或安全兜底 |
| 卡片输出 | 应输出正确卡片类型和 payload |
五、第三层:业务场景层
业务场景层关注的是:最终结果对用户是否有用。
这层更接近真实用户体验,也更适合做模型效果评测。
它不是只判断格式,而是判断:
- 是否真正理解用户问题
- 是否给出正确结论
- 是否基于真实数据
- 是否表达清楚
- 是否符合业务规则
- 是否没有幻觉
- 是否让用户知道下一步怎么做
测试目标
业务场景层主要评估:
| 维度 | 说明 |
|---|---|
| 意图理解 | 是否正确识别用户要做什么 |
| 事实正确性 | 是否基于工具/知识库返回,不编造 |
| 业务正确性 | 是否符合业务规则 |
| 完整性 | 是否回答了原因、状态、建议 |
| 可执行性 | 用户是否知道下一步怎么做 |
| 表达质量 | 是否自然、清晰、符合地区语言 |
| 安全合规 | 是否避免敏感、违规、误导性内容 |
| 稳定性 | 多次运行结果是否一致 |
| 用户体验 | 是否避免内部术语、错误栈、系统失败信息 |
测试方法
我觉得这一层最难的就是覆盖的场景全不全、结果检查的方向(评估方向)。也为后面 agent 评测打下基础。初期手工 case 可以通过端上发起。上线稳定后完成 agent 回归自动化。
业务场景覆盖:主要来自 需求文档、第二类是 badcase 回归集(主要是 PM 体验、线上的反馈),第三类是边界用例,第四类工具error,第五类安全 risk用例。
自动化 Case 断言这一层,不能完全依赖规则,也不能完全依赖人工。比较实际的方式是:
规则评估 + LLM Judge + 人工校准
- 规则评估判断确定性问题:是否通过 risk,是否指定了工具等
- LLM Judge 判断语义问题;回答是否解决了问题,是否自然,是否有依据等
- 抽样复核 LLM Judge 的准确性:定期修正评分标准
三层之间怎么对应具体模块
以一个抽象的诊断类 Agent 为例。
用户问:
为什么我不能报名某个项目?
测试时不要只看最终回答,而要看完整过程。
| 类型 | 说明 | 示例 |
|---|---|---|
| 黄金用例 | 最核心、最高频、必须正确的场景 | 查询经营表现、诊断商品问题、诊断广告问题、判断是否符合某项目报名条件、查询某个状态异常的原因 |
| Badcase 回归集 | 来自线上真实问题,每次修复后都要沉淀为回归用例 | 意图识别错误、未走 Planner、工具调用错误、回复编造数据、卡片输出异常 |
| 边界用例 | 覆盖用户表达不完整、语言混杂、上下文复杂等情况 | 用户表达很短:“为什么不行”、中英混杂、错别字、缺少关键对象、多个意图混在一起、历史对话里有旧状态 |
| 工具异常用例 | 验证工具异常或数据异常时,系统是否能合理兜底 | 工具返回空、工具返回 error、工具返回部分字段缺失、工具数据与知识库描述存在冲突 |
| 安全用例 | 验证系统是否避免违规、误导、虚假承诺或敏感输出 | 用户要求绕过规则、要求虚假承诺、输入敏感内容、模型可能输出过度保证的话术 |
简单说:
组件契约层保证“零件没坏”
Agent 编排层保证“流程没跑偏”
业务场景层保证“结果真的有用”
评测 -> 发现问题 -> 归因 -> 修 Prompt / 修工具 / 补数据 / 调规则 -> 回归验证
~~
常见误区
误区一:只测最终回答
最终回答正确,不代表链路正确。Agent 可能没查数据,只是猜对了。
误区二:只做人工体验测试
人工测试能发现体验问题,但规模化差,也很难覆盖回归。
误区三:只看模型分数
模型分数高,不代表 Agent 系统可靠。工具调用、状态流转、协议解析都可能出问题。
误区四:没有 badcase 回归
Agent 的很多问题是长尾问题。线上发现一次,如果不沉淀成回归集,下次很可能再出现。
误区五:不采集中间过程
没有 trace,就很难判断问题是路由、Planner、工具、Rewrite 还是风控导致的。
总结
测试 Agent,本质上不是测试一个模型,而是测试一个由模型驱动的复杂系统。
一个实用的分层测试体系可以分成三层:
- 组件契约层:保证协议、Prompt、解析器、工具返回结构稳定
- Agent 编排层:保证路由、Planner、工具调用、状态流转过程正确
- 业务场景层:保证最终回答真实、可用、安全、符合用户预期
其中最关键的是两点:
第一,要基于 trace 做过程评估,而不是只看最终回答。
第二,要把各个方面反馈回来的 case持续沉淀为测试集,形成“评测 - 反馈 - 优化 - 回归”的闭环。
只有这样,Agent 才能从“偶尔回答得不错”,逐步变成“稳定、可解释、可回归、可持续优化”的 AI 应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)