一个BUG,AI分析了几千行代码,一顿操作猛如虎,最后我删了一张头像照片搞定!
一个BUG,折腾了将近一个月。
AI翻遍了存储过程、写了十几个Python脚本、查了数据库里和签到相关的所有表、找到了两个独立的根因、给出了完整的根治方案和技术文档——
最终的解决方案:打开系统后台,把一个员工的头像照片删掉,重启服务器。
完事。全程两分钟。
我盯着屏幕发了好一会儿呆。
一、问题出现
那天早上,有同事反映:工作轨迹模块里,H工的签到记录,每次都显示两条一模一样的。
不是偶尔,是每次。不是某一天,是所有历史记录,全都翻倍。
签到列表看起来大概是这个样子(复原示意):
【图1:
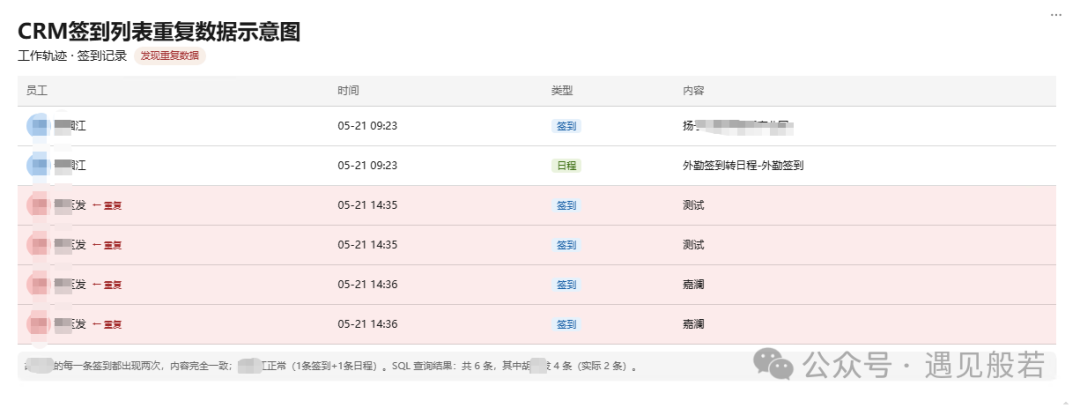



可以看到,T工的记录一切正常,而H工的每一条签到却都出现了两次——时间、地点、状态完全一致。就像数据库里多了个影子。
"是不是他点了两次?"
不是。时间戳精确到秒,一模一样。人不可能在同一秒签到两次。
"是不是有人手工录了一条?"
排查了操作日志,没有。
那就是系统的问题。
二、第一轮排查:找到了一个根因,但不是全部
把问题交给AI处理。
AI的第一步是去读存储过程。CRM系统的签到列表,由一个叫 spCRM_SelectSignInList 的SQL存储过程生成,它把签到和日程两张表的数据合并查询后返回给前端。
-- SignInRange 控制返回哪些数据:
-- bit1=签到(2),bit0=日程(1),SignInRange=3 表示两者都要
IF @SignInRange & 2 = 2 -- 查签到
SELECT ... FROM CRM_SignIn ...
IF @SignInRange & 1 = 1 -- 查日程(只查带GPS坐标的)
UNION ALL
SELECT ... FROM CRM_Schedule
WHERE ISNULL(Longitude, 0) <> 0这里藏着一个逻辑问题:当员工签到并开启了"签到转日程"功能(IsRollSchedule=True)时,系统会自动生成一条关联日程,继承签到的GPS坐标。这条自动生成的日程完全满足日程查询的条件,于是通过 UNION ALL 又被查了出来。
一条签到,出现了两次。
AI给出了修复方案——在日程查询的 WHERE 条件里加一个过滤,排除由签到自动生成的日程:
AND (a.CoObjectType IS NULL OR a.CoObjectType <> 'SignIn')修复脚本写好、部署上线、测试验证……
H工的记录还是翻倍。
说明还有另一个独立的重复来源,和日程没关系。
三、第二轮排查:六年前的隐患浮出水面
AI继续追查。这次把目光锁定在存储过程的另一段逻辑——签到查询在取员工头像时,有这样一段 JOIN:
SELECT ... FROM CRM_SignIn a
INNER JOIN CRM_Employee b ON b.TypeID = a.Creator
LEFT JOIN CRM_UploadFile d
ON d.CoObjectTypeID = a.Creator
AND d.CoObject = 'HeadPicture'最后这行 LEFT JOIN,目的是顺手把员工头像路径带出来,省得前端再单独请求一次。
但这里有一个经典陷阱:LEFT JOIN 是一对多关系时,左表的每一行都会被复制多次。这就是数据库里的笛卡尔积。
AI立刻写了一个验证脚本,几秒钟后结果出来了:
=== 员工头像(HeadPicture)数量 === H工: 2 个头像 ← 问题! T工: 1 个头像 ← 正常
找到了。
进一步查询发现:H工在头像表里有两条记录,上传时间分别是 2020-05-25 11:45:45 和 2020-05-25 11:46:32,相隔仅47秒。
还原当时的情景:大概六年前,他上传头像时网络卡顿,或点击提交没有立即响应,于是又点了一次。系统没有做去重约束,两条记录就这样并存了六年。
这六年里,它们静静地躺在数据库里,从未引发任何问题——直到今天,这个存储过程的 LEFT JOIN 碰到了它们。2条签到 × 2条头像 = 4行结果。每条签到都多了一个"影子"。
四、AI给出了"完美"的根治方案
定位到完整的根因后,AI给出了一套修复方案。
将 LEFT JOIN 改为 OUTER APPLY,取最新的一条头像:
-- 修复前(有问题的写法)
LEFT JOIN CRM_UploadFile d
ON d.CoObjectTypeID = a.Creator
AND d.CoObject = 'HeadPicture'
-- 修复后(正确写法)
OUTER APPLY (
SELECT TOP 1 FilePath
FROM CRM_UploadFile
WHERE CoObjectTypeID = a.Creator
AND CoObject = 'HeadPicture'
ORDER BY ID DESC
) dOUTER APPLY 对每一行签到单独执行一次子查询,TOP 1 确保最多只返回一条头像记录。无论员工上传了多少张头像,都只取最新的那一张,笛卡尔积问题被彻底杜绝。
同时,AI把第一轮发现的日程重复问题也一并打包处理。附带了完整修复SQL脚本、测试验证脚本、回滚方案和技术文档。
方案写得很严谨,很漂亮。
五、但我用了两分钟就解决了
我看了看AI给的修复脚本。
改存储过程,意味着要动生产数据库的核心逻辑。这是一个用了多年的老系统,存储过程有几百行,内部依赖复杂。虽然有回滚方案,但改一处说不定影响另一处,任何线上变更都有风险。
同时,我想到了另一个角度:这个问题是从哪里来的?
H工有两条头像记录,因为他当年上传了两次。系统没有对头像做去重约束——这是数据问题,不是逻辑问题。
既然问题是数据坏了,为什么不直接修数据?
我打开系统后台,找到H工的员工资料,删掉那张旧的头像,只保留最新一张。然后重启了一下服务器。
回到签到记录:一条。
完事。全程两分钟。
六、完整排查时间线
下面是这次问题从发现到解决的完整过程:
【图2:签到重复问题排查时间线】(请在此处插入对应截图)
整个排查经历了五轮:
- 问题上报:H工签到每条显示两条,其他同事正常
- 第1轮排查:发现BUG1——UNION ALL 合并签到和日程,签到转日程的自动日程也被查出来导致重复。修复部署后——问题仍在
- 第2轮排查:发现BUG2——LEFT JOIN 头像表按员工ID取头像,H工有2条头像记录导致笛卡尔积。验证确认:T工1个头像正常,H工2个头像翻倍
- AI根治方案:OUTER APPLY TOP 1 替代 LEFT JOIN,同时修复 BUG1 + BUG2
- 实际操作:不采用存储过程修复(生产系统风险),直接在后台删除多余头像 + 重启服务器,2分钟消除问题
七、AI的工作有没有价值?
有,而且价值不小。
第一,确认了根因。 笛卡尔积这个结论是正确的。如果没有AI的分析,我可能还要花很长时间猜测。这个问题藏在存储过程深处,不打开来仔细读是无法定位的。
第二,发现了隐藏问题。 AI在分析过程中一共找到了两个独立的重复根因:不只是头像笛卡尔积,还有签到转日程的 UNION ALL 逻辑缺陷。那个问题这次因为删头像被掩盖了,但它是真实存在的——下一个开启了签到转日程的员工,同样的问题还会出现。已记录在案,留待后续处理。
第三,留下了技术资产。 AI生成的分析报告、修复脚本、技术文档,对未来的系统升级有参考价值。如果哪天要做大版本迭代,存储过程该怎么改,有现成的方案。
所以AI的工作不是徒劳的。只是在这个具体的时刻,"删头像"比"改存储过程"更快、更安全、风险更小。
八、一个更深的问题:修系统,还是修数据?
这件事让我想到软件系统维护中一个永恒的张力。
修系统:更彻底,能根治所有类似情况。改一次存储过程,以后所有员工都不会再遇到笛卡尔积的问题。但成本高、风险大、需要充分的测试时间。
修数据:更快,仅需删除一条脏记录。但只治标——下一个上传了两张头像的员工,问题还会复现。
教科书上的标准做法是两个都做:先修数据快速止血,再修系统根治根因。
但现实往往是:"先修数据"做完之后,"再修系统"就被搁置了。问题不再报警,优先级自然下移,其他更紧急的事情接踵而来,然后——就再也没有然后了。
这是所有遗留系统都面临的困境。每一个"先这样凑合一下",都是未来某次故障的伏笔。
这次删掉了头像,存储过程里 LEFT JOIN 的隐患还在。下一个上传了两张头像的员工,问题还会复现。
只是不知道是哪天,哪个员工,哪个场景下。
九、AI和人,各自的位置
这件事让我对"AI辅助工作"有了更清楚的认识。
AI在分析问题时,天然倾向于找到系统性的根因,给出系统性的修复。这是工程师思维,也是正确的思维方向。
但在具体的生产场景里,决策需要结合当下的约束:系统有多老、改动风险有多大、问题有多紧急、有没有时间做充分测试……
AI帮你找到了最优解的方向。
人来决定在当下走哪条路。
最优解存在于理论里。
次优解活在现实里。
这大概就是人和工具最好的分工方式。
头像已删。
服务重启。
签到正常。
一切如故。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)