DeepSeek RAG&MCP + Agent智能体项目 —— MCP项目初始化和基本使用
一、前言
前面我们学习的是RAG增强检索生成,也就是静态知识库,原理是通过指定对应的文档上下文,结合用户上下文,让大模型去指定文档中检索信息,最后响应。
二、MCP概念补充
这里我们将学一个新的技术——MCP,这个技术叫做模型上下文协议。通俗一点来讲就是动态知识库,但是即使这样讲也会感觉很模糊,所以我给出一个场景:
用户希望大模型在桌面创建一个test.txt文件,于是告诉大模型:我想在桌面创建一个test.txt文件。而大模型本身不具备操控设备的能力,于是它只能回复:我无法操作你的设备,你可以写一个脚本来实现一样的效果......
那现在有没有什么办法可以让大模型真正做到操控设备呢?
有,我们只要给大模型一个MCP服务,这个服务其实就是个简单的小项目,里面封装了各种操控设备的方法代码(相当于用Java代码实现和操作系统的交互)。
这时我们只需要通过配置让MCP客户端(大模型和MCP客户端在同一端)和MCP服务器连接上(事实上这一步很复杂,但是框架为我们隐藏了这些步骤),MCP服务就会告诉MCP客户端:我这里有操作设备的工具,这些工具的名字分别是xxx、xxx。
于是当用户想创建文件,大模型就会找到创建文件的指令,然后发(利用STDIO通信,以JSON-RPC的形式)给MCP服务,MCP服务会按照指令调用Java方法来向操作系统发命令,于是就创建出指定文件了。
这时操作系统就会传回一个成功的结果到MCP,MCP再传给大模型,大模型最后传给用户,于是用户就能收到:创建成功。
刚刚提到了 “ 通过配置让MCP客户端和MCP服务连接 ” ,其实这里面的步骤很复杂。
首先明确要MCP客户端、大模型、MCP服务的关系,我再用一个简洁的流程来表述:
用户告诉大模型创建文件 -> MCP客户端给大模型工具 -> 大模型根据用户需求选择工具 -> 大模型告诉MCP客户端需要调用的工具和参数 -> MCP客户端调用MCP服务
连接阶段:
首先MCP服务中的方法需要使用@Tool注解标记,当MCP服务启动时,就会去扫描@Tool注解,然后将这些标记的方法包装成大模型可以理解的工具(包装成JSON Schema格式),最后将这些工具注册到MCP服务端的工具列表中。
在这个连接阶段中,MCP客户端其实就会向MCP服务端发出一个请求,获取工具列表,然后拿到所有可以使用的指令,最后传给大模型。
三、项目初始化
1.基本配置
首先升级框架为SpringAI为1.0.0-M6版本
<properties>
<spring-ai.version>1.0.0-M6</spring-ai.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>同时配置部分需要小做更改,这个版本的API和0.8.1版本不完全一样
@Configuration
public class OpenAIConfig {
@Bean
public TokenTextSplitter tokenTextSplitter() {
return new TokenTextSplitter();
}
@Bean
public OpenAiApi openAiApi(@Value("${spring.ai.openai.base-url}") String baseUrl, @Value("${spring.ai.openai.api-key}") String apikey) {
return OpenAiApi.builder()
.baseUrl(baseUrl)
.apiKey(apikey)
.build();
}
@Bean("openAiSimpleVectorStore")
public SimpleVectorStore vectorStore(OpenAiApi openAiApi) {
OpenAiEmbeddingModel embeddingModel = new OpenAiEmbeddingModel(openAiApi);
return SimpleVectorStore.builder(embeddingModel).build();
}
@Bean("openAiPgVectorStore")
public PgVectorStore pgVectorStore(OpenAiApi openAiApi, JdbcTemplate jdbcTemplate) {
OpenAiEmbeddingModel embeddingModel = new OpenAiEmbeddingModel(openAiApi);
return PgVectorStore.builder(jdbcTemplate, embeddingModel)
.vectorTableName("vector_store_openai")
.build();
}
@Bean
public ChatClient.Builder chatClientBuilder(OpenAiChatModel openAiChatModel) {
return new DefaultChatClientBuilder(openAiChatModel, ObservationRegistry.NOOP, (ChatClientObservationConvention) null);
}
}可以做一下配置对比(右1.0.0-M6,左0.8.1):
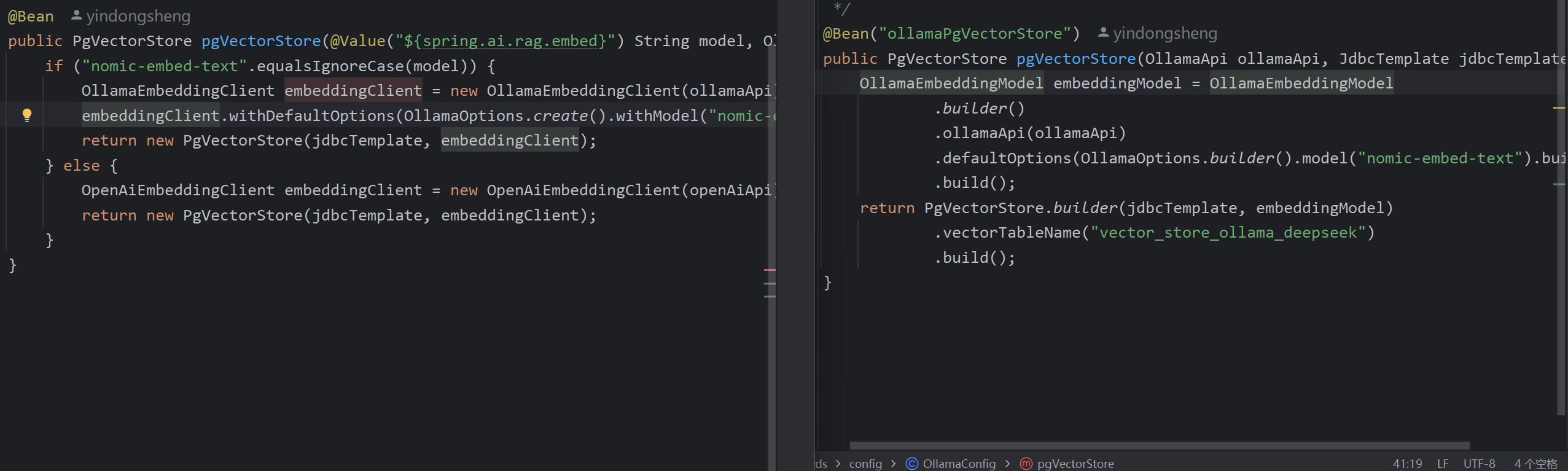
同理Ollama配置也要改:
@Configuration
public class OllamaConfig {
@Bean("ollamaSimpleVectorStore")
public SimpleVectorStore vectorStore(OllamaApi ollamaApi) {
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel
.builder()
.ollamaApi(ollamaApi)
.defaultOptions(OllamaOptions.builder().model("nomic-embed-text").build())
.build();
return SimpleVectorStore.builder(embeddingModel).build();
}
@Bean("ollamaPgVectorStore")
public PgVectorStore pgVectorStore(OllamaApi ollamaApi, JdbcTemplate jdbcTemplate) {
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel
.builder()
.ollamaApi(ollamaApi)
.defaultOptions(OllamaOptions.builder().model("nomic-embed-text").build())
.build();
return PgVectorStore.builder(jdbcTemplate, embeddingModel)
.vectorTableName("vector_store_ollama_deepseek")
.build();
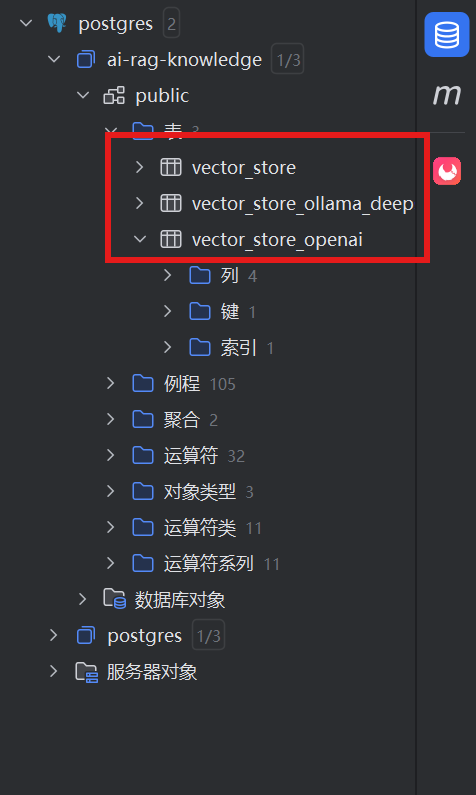
}这里使用了VectorDB的图形化界面,并创建了三张表供后续使用。
2.项目结构
四、基本使用
熟悉了MCP的概念后再去使用MCP就比较容易了:
首先,想让MCP客户端连接服务端就需要一个配置,指定服务端所在地方,这里我放到了Maven本地仓库中,事实上这个服务端就是个jar包,所以需要用参数中传-jar来启动,同时还要开启stdio通信,用于大模型和MCP客户端的相互通信。
{
"mcpServers": {
"filesystem": {
"command": "npx.cmd",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem@2025.3.28",
"C:/Users/\u5370\u4e1c\u5347/Desktop"
]
},
"mcp-server-computer": {
"command": "java",
"args": [
"-Dfile.encoding=utf-8",
"-Dspring.ai.mcp.server.stdio=true",
"-jar",
"D:/apache-maven-3.9.11/mvn_resp/ai-mcp-knowledge-test/mcp-server-computer-1.0.0.jar"
]
}
}
}同时别忘了让配置生效:(这里可能会说无法解析,可忽略)
ai:
mcp:
client:
stdio:
servers-configuration: classpath:/config/mcp-servers-config.json进行测试:
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class MCPTest {
@Resource
private ChatClient.Builder chatClientBuilder;
@Autowired
private ToolCallbackProvider tools;
@Test
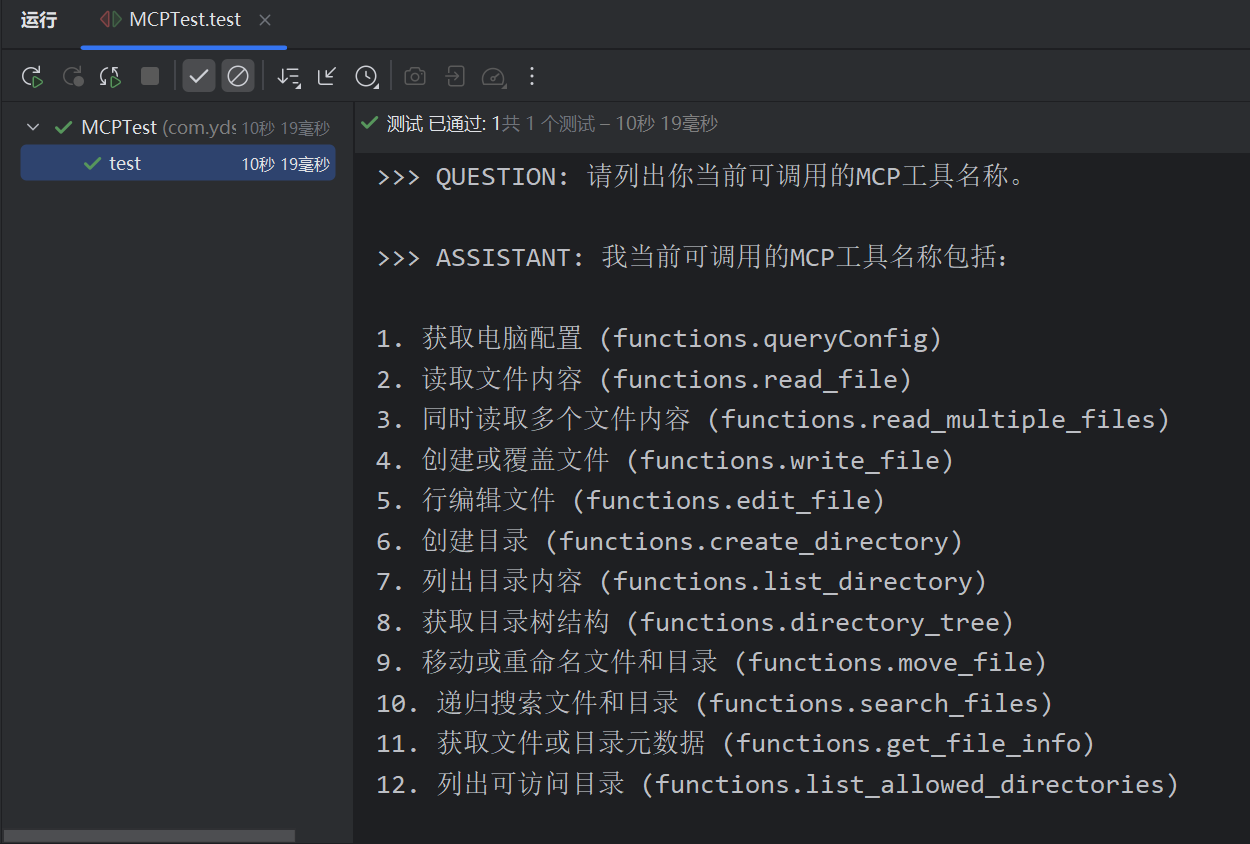
public void test() {
String userInput = "";
userInput = "请列出你当前可调用的MCP工具名称。";
var chatClient = chatClientBuilder
.defaultTools(tools)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4.1-mini")
.build())
.build();
System.out.println("\n>>> QUESTION: " + userInput);
System.out.println("\n>>> ASSISTANT: " + chatClient.prompt(userInput).call().content());
}
}测试如下:
相同的,这个也可以实现:
@Test
public void test_tool() {
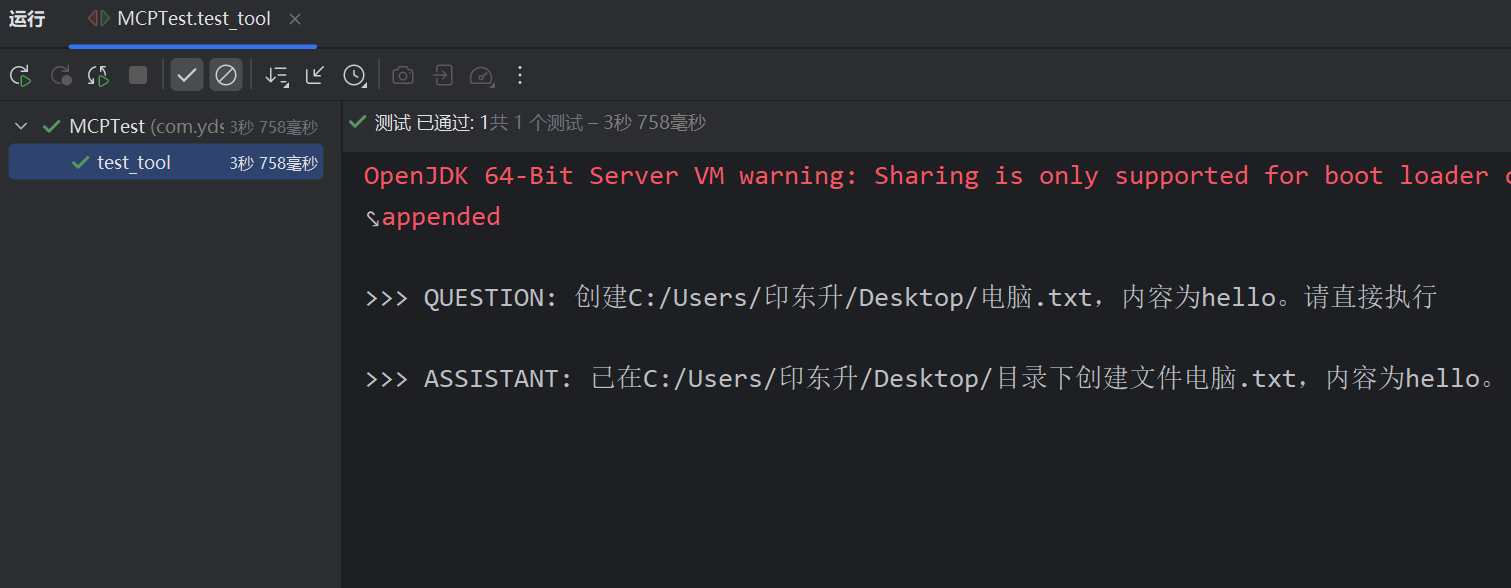
String userInput = "创建C:/Users/\u5370\u4e1c\u5347/Desktop/电脑.txt,内容为hello。请直接执行";
var chatClient = chatClientBuilder
.defaultTools(tools)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4.1-mini")
.build())
.build();
System.out.println("\n>>> QUESTION: " + userInput);
System.out.println("\n>>> ASSISTANT: " + chatClient.prompt(userInput).call().content());
}
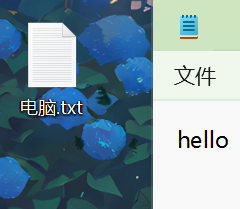
这里有几个需要注意的地方:
1.只能使用OpenAi,因为我们部署DeepSeek的版本不支持MCP。
2.尽量选择gpt-4.1-mini,这个消耗token会慢一些。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)