【VLM-Agent】多模态搜索智能体OpenSearch-VL
note
- 数据不是普通 VQA,而是“工具需求型多跳 VQA”
- 工具不是只做搜索,而是加入主动视觉处理(如crop / OCR / 超分 / 透视矫正 / 图搜 / 文搜)
- RL 不是简单 GRPO,而是适配长链路工具失败:
- 如下例子:虽然最终结果错了,但直接给0分其实不太合适,因为其实 Step 1 甚至“调用 IMAGESEARCH 这个动作”本身可能是对的,只是搜索结果/实体识别错了
fatal-aware GRPO:先判断这条轨迹从哪一步开始“彻底崩了”,然后只训练崩溃前的部分,崩溃后的 token 不参与 loss
Step 1:观察图片,觉得像一座大学建筑 ✅ 合理
Step 2:调用 IMAGESEARCH,误识别成“牛津大学某建筑” ❌ 错了
Step 3:搜索“牛津大学创始人” ❌ 被带偏
Step 4:回答错误答案 ❌
- 用
ClaudeOpus4.6在真实工具环境生成轨迹,经答案正确性+过程级两级拒绝采样,得到36592条SFT轨迹,再抽取8k独立样本作为RL数据;
文章目录
一、OpenSearch-VL
项目:https://github.com/shawn0728/OpenSearch-VL
【多模态搜索智能体训练方案进展】多模态深度搜索智能体训练方案,基于Agentic 强化学习,通过维基百科路径采样等流水线构建SearchVL-SFT-36k与SearchVL-RL-8k高质量数据集,搭配整合文本 / 图像搜索、OCR、图像增强等的多样化工具体环境。
工作在:OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents, https://github.com/shawn0728/OpenSearch-VL,https://huggingface.co/OpenSearch-VL。
看核心几个点: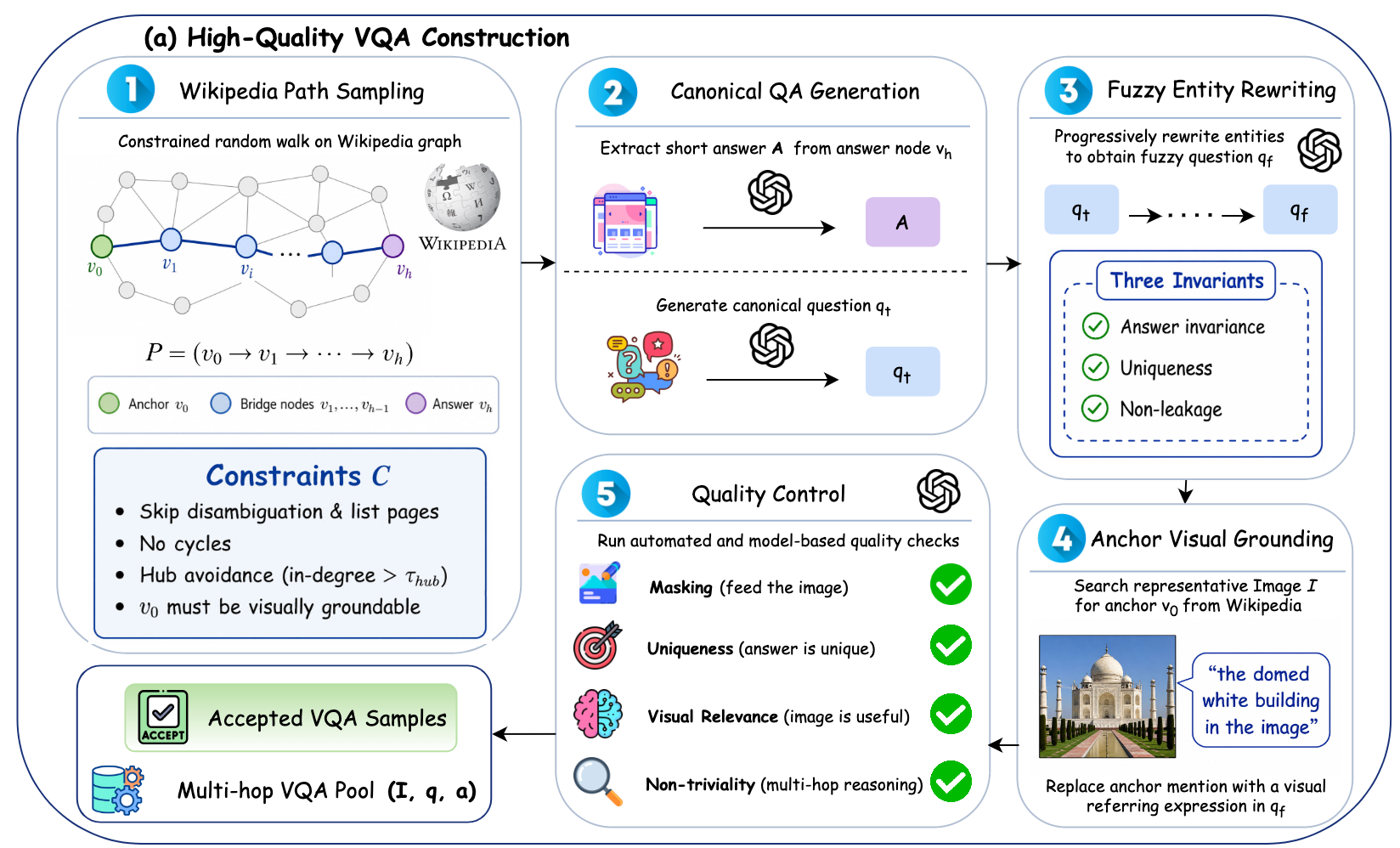
1)数据合成。
【step1.维基百科路径采样】以维基百科为有向图,从种子实体出发做2-4跳受限随机游走,跳过消歧义页、列表页、循环路径与高入度枢纽节点,为节点分配锚点/桥接/答案角色
->【step2.标准问答生成】从答案节点提取简短唯一答案,用GPT-4o生成标准问题,保证问题仅指向答案属性
->【step3.模糊实体重写】从最远桥接点向锚点迭代改写,将实体名替换为属性描述,满足答案不变、唯一指向、无实体泄露三大约束
->【step4.锚点视觉定位】为锚点实体检索维基共享资源图像,用CLIP筛选匹配图像,将问题中锚点名替换为视觉指代表达
->【step5.自动化质量控制】执行掩码检查、唯一性检查、视觉相关性检查,过滤低质样本
->【step6.分阶段过滤】先用无工具模型过滤,再用单轮图像搜索过滤,仅保留必须多工具、多跳才能解决的样本
->【step7.数据增强】抽取10%样本做模糊/降采样/透视畸变,配对锐化/超分/透视校正工具,生成视觉增强子集
->【step8.专家轨迹合成】用ClaudeOpus4.6在真实工具环境生成轨迹,经答案正确性+过程级两级拒绝采样,得到36592条SFT轨迹,再抽取8k独立样本作为RL数据;
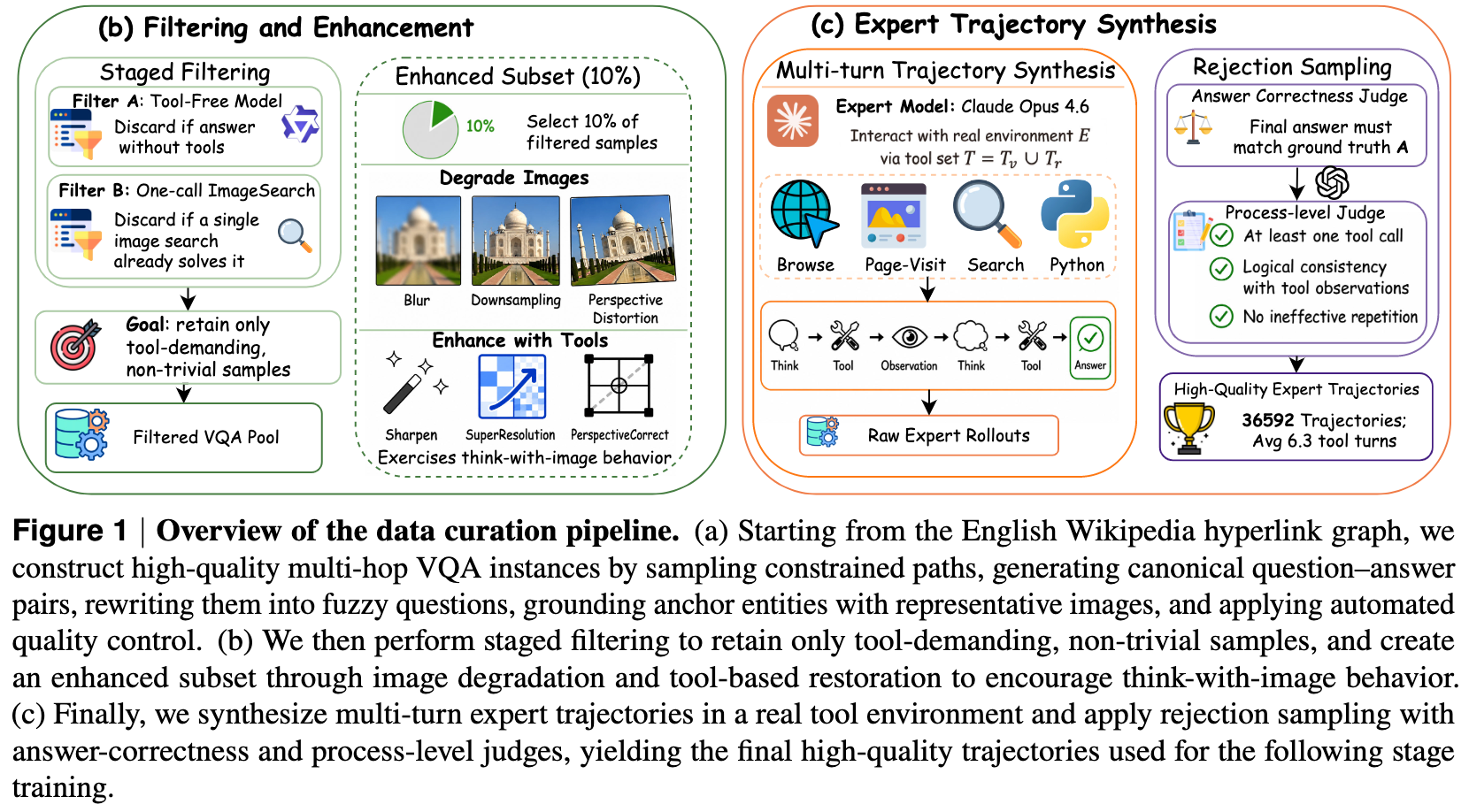
2)工具环境构建。3 大类 8 种工具,
检索工具:TEXTSEARCH、IMAGESEARCH
图像增强:SHARPEN、SUPERRESOLUTION PERSPECTIVECORRECT
注意力解析:CROP、OCR
【Step1.检索工具集成】文本搜索=Serper查询+JINA网页解析+Qwen3-32B摘要;图像搜索=PolarisLens反向图搜+实体识别
->【Step2.图像增强工具实现】锐化=OpenCV反锐化掩码;超分=EDSR深度模型;透视校正=Canny边缘+四边形拟合+透视变换
->【Step3.注意力与解析工具实现】裁剪=按坐标提取矩形区域;OCR=PaddleX布局解析+文本块按阅读顺序输出
->【Step4.工具环境统一封装】按视觉工具Tv、检索工具Ts分类,提供统一调用接口与观测返回格式

3)监督微调SFT。基于36592 条多轮专家轨迹全参数微调。
【Step1.模型初始化】以Qwen3-VL-8B/30B-A3B/32B为基座,视觉塔与多模态投影器不冻结
->【Step2.数据加载与打包】加载36592条多轮专家轨迹,支持图像观测交错对齐,截断长度32000token
->【Step3.损失计算与掩码】按自回归分解监督推理迹与工具调用,掩码观测token,仅对模型生成token计算损失
->【Step4.分布式训练配置】使用DeepSpeedZeRO-3,256块H20GPU,学习率2e-5,余弦调度,训练8轮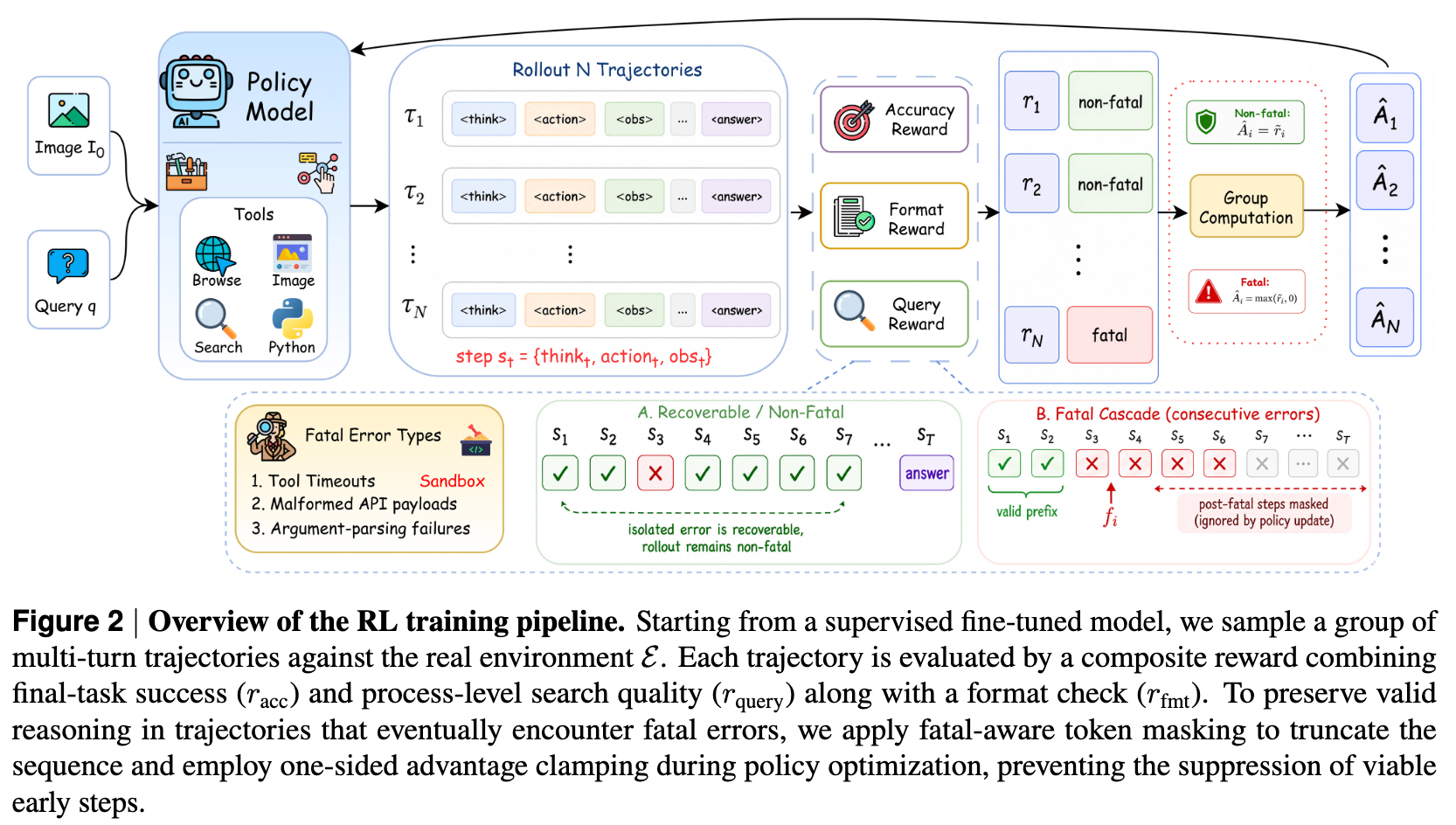
4)强化学习RL。GRPO,自动识别轨迹中连续 3 次工具错误的崩溃起点,只保留崩溃前的有效内容,屏蔽之后的无效 token,不让模型学到错误信息
【Step1.多轮轨迹采样】从SFT模型出发,在工具环境中每组提示采样8条轨迹,支持异步滚动生成
->【Step2.复合奖励计算】格式奖励r_fmt(检查结构完整性)+准确率奖励r_acc(GPT-4o判题)+查询质量奖励r_query(GPT-5.4判分),α=0.8融合
->【Step3.致命错误检测】连续3次工具执行错误标记为致命,记录致命起始步骤
->【Step4.致命感知掩码】将致命步骤后所有生成token置0,仅保留有效前缀计算梯度
->【Step5.单边优势钳制】非致命轨迹用标准归一化优势;致命轨迹取max(归一化奖励,0),不惩罚有效前缀->【Step6.GRPO优化】按token级重要性比率更新,加入KL散度约束。
Reference
[1] OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents, https://github.com/shawn0728/OpenSearch-VL,https://huggingface.co/OpenSearch-VL

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)