ACL Oral ! 最强纠错模型ChineseErrorCorrector4开源
🏆 重磅喜讯!在自然语言处理领域的国际顶级学术会议 ACL 2026 中,由华东师范大学 计算机学院 Cube-NLP 团队提交的论文:
《CSRP: Chain-of-Thought Reasoning for Chinese Text Correction via Reinforcement Learning with Efficiency-Aware Rewards》
昨天被正式录用为Oral !团队自主研发的 ChineseErrorCorrector4 在 NACGEC和CSCD 双大基准上斩获SOTA,中文纠错模型 ChineseErrorCorrector4-4B 现已在 Hugging Face 平台全面开源!并且配套训练、590万高质量数据和推理代码同步在 GitHub 开源,欢迎大家查看。
🐙GitHub :
https://github.com/TW-NLP/ChineseErrorCorrector
下面让我们大家一起来看一下,Cube-NLP 团队是怎么做到这些的,文章分了六部分,一到四部分是介绍的论文内容,第五部分是模型的部署,第六部分是作者的一些感悟,感谢大家观看,好下面开始进入正题。
01. 解决LLM在文本纠错任务上存在的“过度纠正问题”
随着大语言模型(LLM)的崛起,利用大模型进行中文语法纠错(CGEC)和拼写检查(CSC)已成为主流。然而,学术界与工业界在实际落地中,始终面临着两大难以逾越的鸿沟:
(1)“常识丰富,但偏科严重”——缺乏专业语言先验知识通用大模型在干净、规范的语料上表现出色,但对学习者、拼音输入法等产生的“非规范”错误分布(如:同音字混淆、虚词冗余等)极不敏感。
(2)“越改越错,画蛇添足”——最大似然估计(MLE)带来的过度纠错(Over-correction)传统监督微调(SFT)训练的模型,往往倾向于将输入文本往高概率的内部分布上靠。这导致模型在遇到已经正确的句子时,也会忍不住进行“润色”和“改写”(Paraphrasing),违背了纠错领域的核心原则——最小编辑原则(Minimal Editing)。
传统的 SFT 训练范式似乎遇到了难以突破的性能天花板,如下图所示:
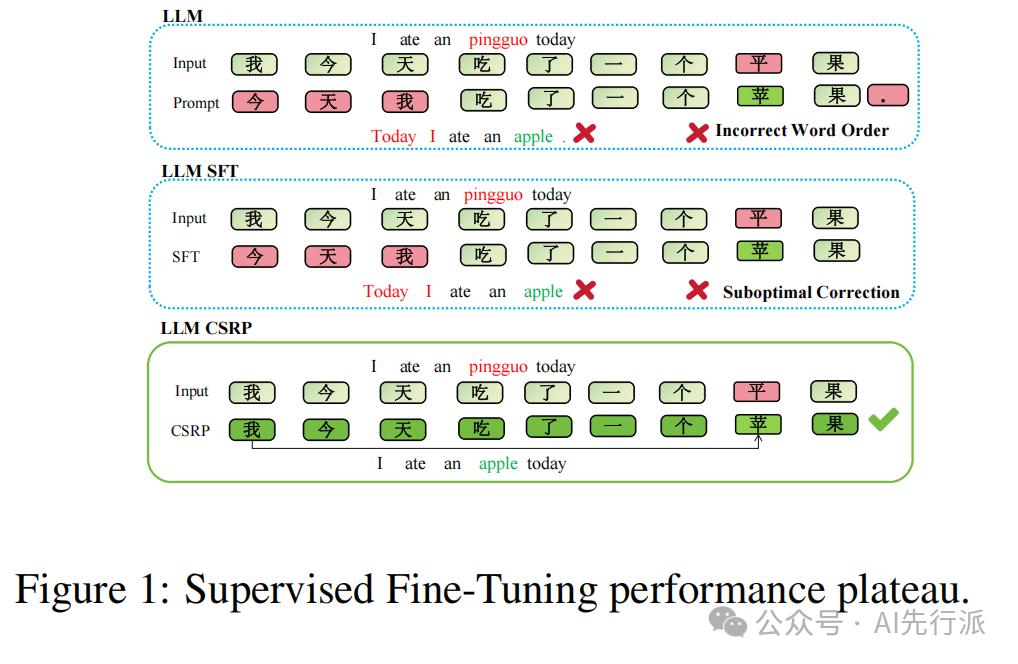
从上图我们可以了解到,现有的LLM和传统的SFT方式,无法解决业界存在的过度纠正问题。
02. CSRP框架
为了彻底解决上述痛点,Cube-NLP 团队提出了CSRP(CPT-SFT-RL)三阶段渐进式训练框架。通过知识内化、诊断显式化、策略对齐,成功实现了对模型纠错边界的精准微调:
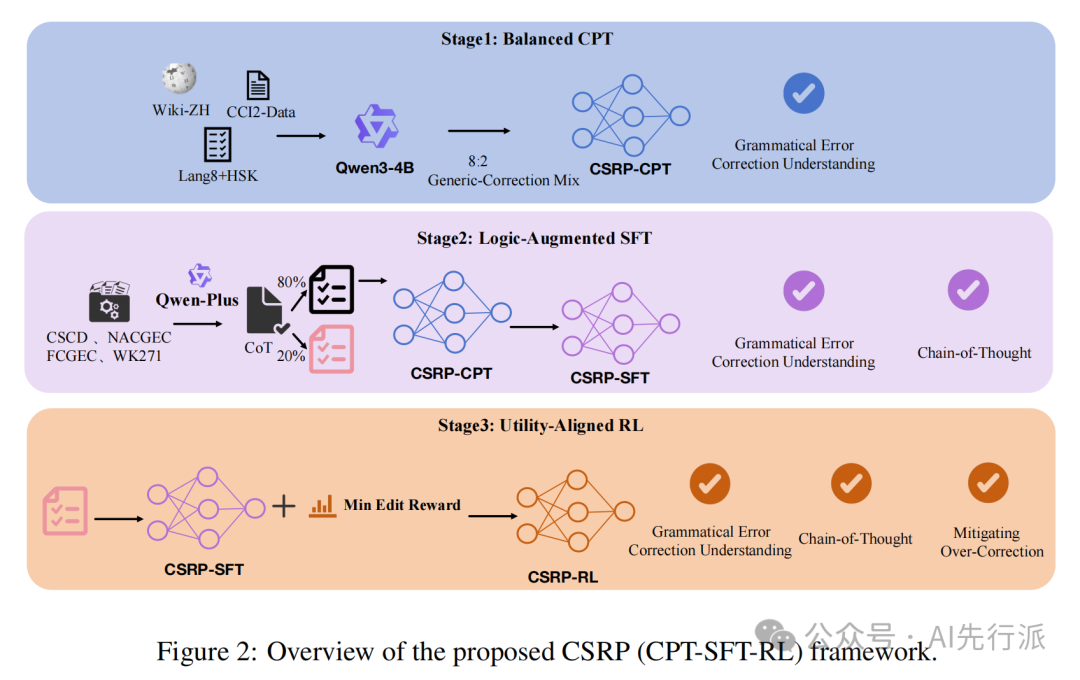
阶段一:平衡增量预训练
为了解决知识稀疏性问题,团队构建了一个包含 5.9M 样本的高质量平衡语料库,所有语料占比如下图所示:
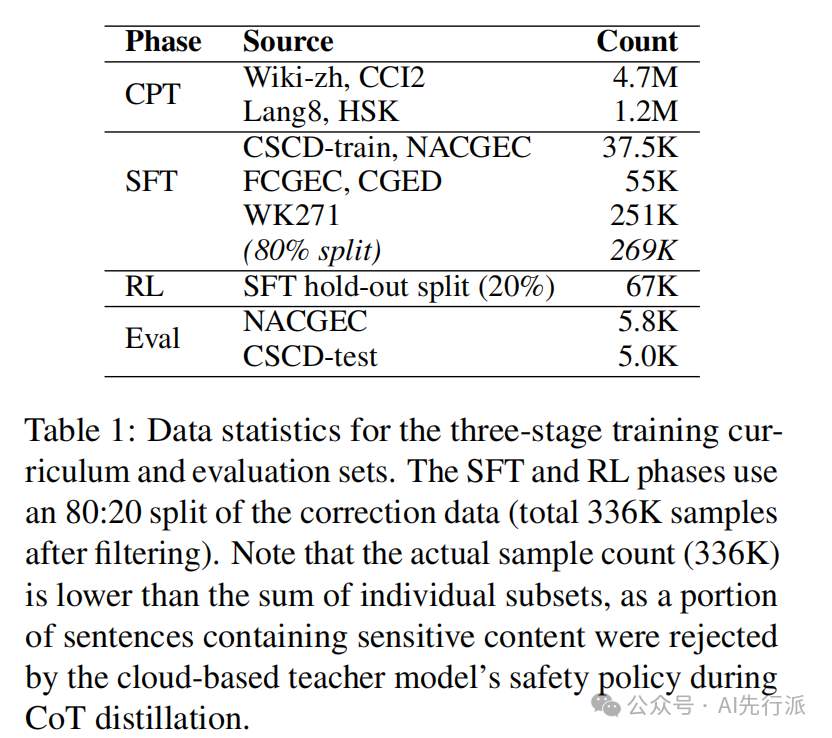
数据配比:采用 8:2 的通用领域数据与纠错专属数据混合配比。
效果:既让模型深度内化了细粒度的中文语法约束,又防止了基础通用推理能力的灾难性遗忘。
阶段二:逻辑增强监督微调
传统的纠错是黑盒式的(直接输入句子S,输出纠错G)。CSRP 引入了诊断明晰化(Chain-of-Thought, CoT)机制:
“先诊断,后纠正”:引导模型按 [纠错定位] -> [错误分类] -> [纠错理由] 的思考链进行推理,然后再输出最终结果。

格式化思考:支持9种类型的错误检测的识别和对应纠错理由,帮助用户更加清晰知道错误原因,结果更加透明,训练实例如下图所示。

这使得模型的纠错决策高度可解释,告别盲目瞎改。
阶段三:效能感知策略强化对齐
这是解决 “过度纠错” 的核心终极武器!CSRP 首次引入了GRPO(Group Relative Policy Optimization)算法,并设计了全新的效能感知奖励(EAR, Efficiency-Aware Reward)函数。核心公式指标:
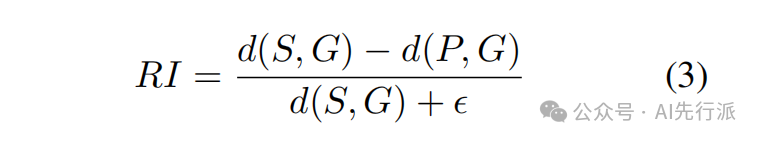
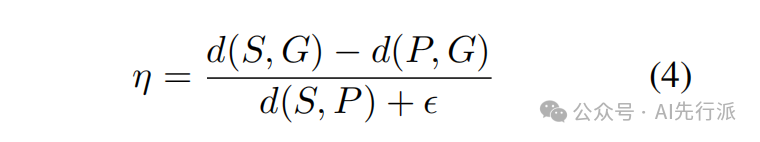
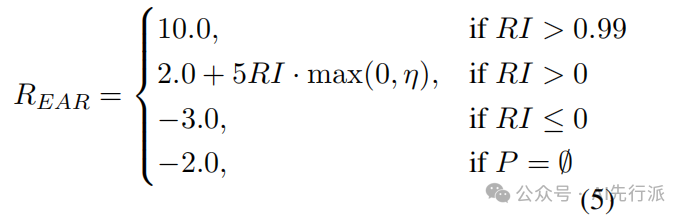
奖惩机制:对于正确的输入句((S, G)=0),若保持原样则奖励+2.0,只要动笔修改就严厉扣除-2.0。
03. 效果惊艳,以 4B 参数超越 14B 模型及 GPT-4!
在多项权威基准评测中,CSRP 框架训练的 4B 模型展现出了极度震撼的降维打击能力。
榜单一:中文语法纠错(CGEC)- NACGEC 基准
在针对原生中文及学习者文本的 NACGEC 评测上,CSRP (4B) 斩获了新 SOTA,其 F_0.5 评分高达 50.99,显著超越此前的专业大模型:
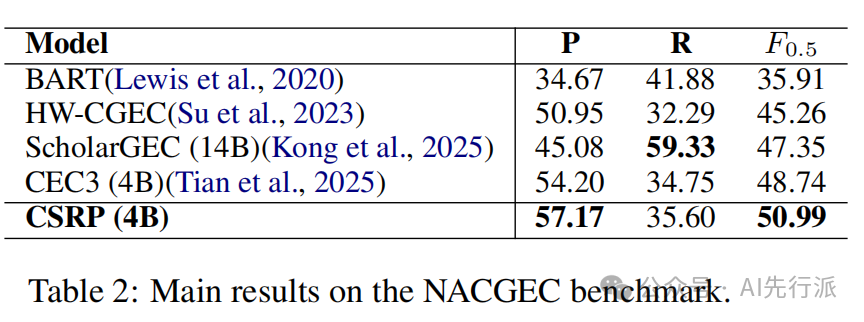
🔥超越 14B 大模型:参数量仅为三成,但F_0.5得分相比 ScholarGEC-14B 提升3.64分!
🔥极高准确率 (Precision 57.17%):远超其他模型,最大程度压制了 false-positive(假阳性改写),真正做到了“无错不改,有错必精”。
榜单二:中文拼写检查(CSC)- CSCD 基准
在中文拼写错误纠正上,CSRP 在性能上同样表现出强烈的统治力,字符级纠错 F1 达到了惊人的59.61:
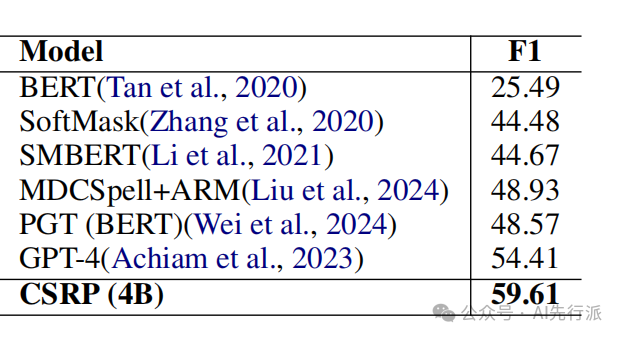
🌟击败 GPT-4:4B 专属模型在纠错任务上,直接超过万亿参数级别的 GPT-4 ,超出整整 5.20 个百分点!
04. 为什么 CSRP 既能精准纠错,又不会降低召回率?
在强化学习阶段,由于引入了效能感知奖励(EAR),模型在 NACGEC 上的 Precision 狂飙了+8.44 点,在 CSCD 上狂飙了+7.37 点。令人惊奇的是,模型召回率几乎没有受到任何损害(NACGEC 仅微降 -0.20,CSCD 仅微降 -0.72)!
通过深入探究,我们发现了背后的三大核心机制:
(1)对比学习实现置信度自校准:GRPO 的组相对评估机制(每次对比 8 个候选采样)让模型学会了在纠错时进行自我信心评估,对于高置信度区域果断出手,低置信度区域保持克制。
(2)显式防过度纠错惩罚:强化学习阶段让模型认识到“不修改原本正确的文字”也可以获得极高奖励。
(3)发现保守的高效策略:模型学会了寻找最精简、最高效的修改路径(编辑效率比极大化),以最小的代价换取最大的纠错红利。
05. 继续拥抱开源:一键部署你自己的中文纠错专家!
目前,该论文配套的所有代码已全部开源,并且模型文件已上传至 Hugging Face。开发者可以极其轻松地将该模型集成到现有的文本编辑器、公文写作助手、OCR 后处理等应用场景中。
🐍 示例:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "twnlp/ChineseErrorCorrector4-4B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
# Professional instruction template
instruction = (
"假如你是一名专业的纠错专家,请分析输入句子的语法错误类型和修改原因,"
"并只输出纠正后的语句,错误类型如下:错别字、词语搭配错误、词性错误、"
"语序错误、成分残缺、成分赘余、关联词使用错误、指代不明、语义逻辑不通、无误。"
)
text_input = "下个星期,我跟我朋唷打算去法国玩儿。"
messages = [
{"role": "system", "content": instruction},
{"role": "user", "content": text_input}
]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.1
)
response = tokenizer.decode(
generated_ids[0][len(model_inputs.input_ids[0]):],
skip_special_tokens=True
)
print(response)-
06. ChineseErrorCorrector的发展
ChineseErrorCorrector 一个面向中文文本纠错任务的综合平台,集学术研究、模型训练、模型评测和推理部署于一体,目前是文本纠错新Sota,一步步走到现在全依赖大家的信任和支持。
从知识积累(CPT)到逻辑诊断(SFT+CoT),再到最终的效能博弈对齐(GRPO+EAR),CSRP 成功向学术界和工业界证明:纠错质量的提升不单单依赖模型的无脑扩张,更在于对训练策略和对齐目标的精心设计。如果您正在苦于大模型写起文章来“画蛇添足”、“过度纠错”,或者希望给现有的 NLP 系统加入一道严谨、有逻辑、可解释的语法纠错防线,那么ChineseErrorCorrector4-4B 绝对值得您一试。
感谢您的关注,欢迎前往 GitHub 给我们点亮一颗珍贵的 ⭐ Star 推动开源技术的进步,您的支持是我们团队持续努力的动力。欢迎在 Hugging Face 下载并测试我们的模型!目前我们上个版本的ChineseErrorCorrector3,已经累计突破上万次下载,服务于上千个企业。
期待与学术界、工业界的同仁们在开源社区相遇,共同推进中文文本纠错技术迈向下一个高峰!🎉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)