Google I/O 2026 热点复盘:谷歌正在把 AI 推向“行动时代”
昨天的 Google I/O 2026 看起来不像是一场单点爆炸式发布会。它没有一个让所有人瞬间刷屏的产品,但如果把整场大会连起来看,会发现谷歌真正释放的是一个更深层的信号:AI 正在从“会聊天的工具”,进入“能理解世界、能执行任务、能持续在线”的行动时代。
从 Gemini Omni 到 Gemini 3.5 Flash,从 Google Antigravity 到 Gemini Spark,再到 Search Agents 和智能眼镜,谷歌这次并不是单纯展示模型能力,而是在补齐 AI 时代的三个关键基础设施:世界模型、多智能体交互界面,以及云端 24 小时运行的 Agent 系统。

一、Gemini Omni:视频生成背后,是谷歌押注“世界模型”
本次大会最值得关注的产品之一,是 Gemini Omni。表面上看,它是一个可以从任意输入生成任意输出的多模态模型,当前重点先落在视频生成和编辑上。但如果只把它理解成一个“视频生成模型”,可能低估了它真正的意义。
Gemini Omni 更重要的地方在于,它被谷歌放在了“世界模型”的方向上。所谓世界模型,不只是让 AI 生成看起来逼真的画面,而是让 AI 学会理解物理世界的运行规则。
比如,一个机器人站在河边,左边有断桥,地上有木棍,上方有藤蔓,旁边还有一艘漏水的小船。它不能只是识别这些物体,而是要在行动前模拟不同选择的后果:断桥会不会塌,木棍能不能支撑身体,藤蔓能不能承重,小船漏水速度够不够撑到对岸。
这正是未来机器人、具身智能和自动驾驶真正需要的能力。大语言模型预测的是下一个 token,而现实世界中的智能体需要预测的是“物理世界的下一个状态”。如果 Gemini Omni 能够持续提升物理一致性和多模态推演能力,它就不仅是内容创作工具,而可能成为机器人训练、虚拟仿真和具身智能闭环中的关键基础设施。
二、Antigravity:AI 交互正在从聊天框走向“任务指挥台”
另一个值得关注的方向,是 Google Antigravity 2.0。它不是传统意义上的 IDE,也不是单纯的聊天窗口,而是一个面向 Agent 的工作台。
过去一年,AI 编程工具的交互方式变化非常快。最早大家在聊天框里让 AI 写代码,后来转向 Cursor 这类 IDE,再后来又出现 Codex 桌面版这种更像任务工作台的产品。原因很简单:开发者并不想一直盯着命令行输出,也不想每一步都手动点目录、改文件、读日志。用户真正需要的是看到任务状态、执行结果、错误反馈和可接管节点。
Antigravity 的方向正是如此。它强调 agent-first,把 AI 从“代码补全助手”推向“多智能体执行系统”。未来的开发界面很可能不是让人盯着代码细节,而是让人看到多个 Agent 的运行状态:谁在写前端,谁在做素材,谁在跑测试,哪个任务需要批准,哪个 Agent 跑偏了需要暂停。
这就是字幕中提到的“Mission Control”式交互。AI 产品的核心界面,正在从 Chat 变成控制台,从单轮问答变成多任务编排。人类的角色也在变化:不再是每一步都亲自操作,而是负责设定目标、确认结果、审批关键动作,并在必要时接管。
更进一步看,谷歌还展示了生成式 UX 的趋势。未来 AI 不一定只返回 Markdown 文本,而是可以根据任务实时生成小组件、网页、卡片和交互界面。因为对人类来说,看一个结构化网页、进度面板或可点击控件,往往比阅读一大段文字更高效。
这意味着 UI/UX 的作用也变了。它不再只是“让软件更好看”,而是让人类更快理解 AI 的执行过程,更快确认结果,更安全地参与复杂任务。
三、Gemini Spark 与 Search Agents:云端 24 小时 Agent 正在成为新入口
第三条主线,是谷歌正在把 Agent 放进云端,并让它们持续工作。
Gemini Spark 可以理解为谷歌版的个人云端 Agent。它不是等用户每次提问,而是可以在后台处理多步骤任务,与 Gmail、Docs、Sheets、Slides 等工具联动,在用户授权下持续推进工作。
Search Agents 则把谷歌最擅长的搜索能力变成了一个长期运行的任务系统。过去,搜索是“我问一次,你答一次”;未来,搜索会变成“我设定目标,你持续监控”。比如关注某类股票、寻找合适房源、追踪球鞋联名发售、监控行业新闻,Agent 都可以在后台持续盯着信息变化,并在关键时刻给出综合判断。
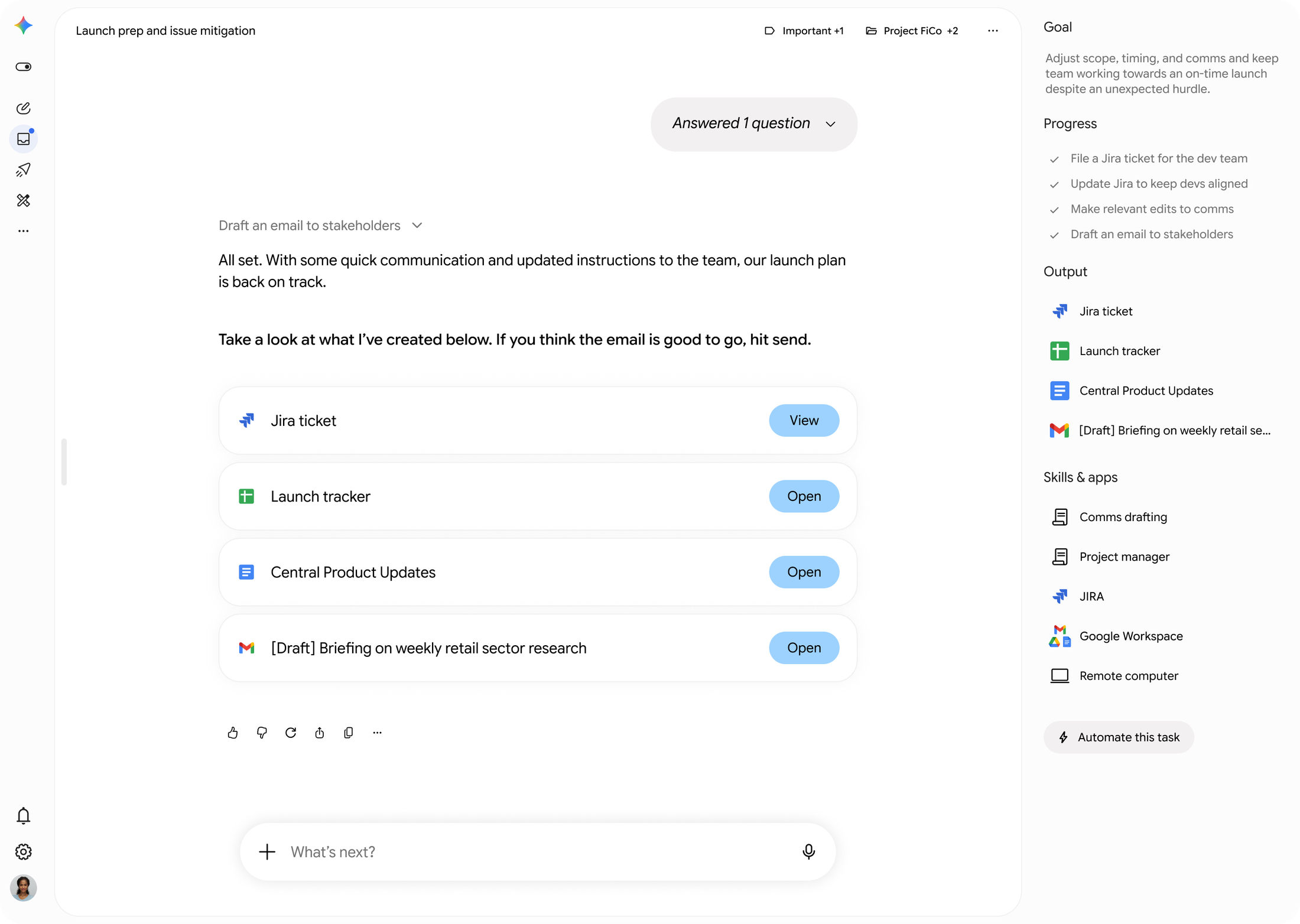
这背后真正重要的变化是:AI 不再只是一个即时响应工具,而开始变成 24 小时在线的数字劳动力。
它会等待信号,识别变化,调用工具,组织信息,生成方案,然后在需要人类确认的地方停下来。这种模式和传统搜索、传统办公软件都不一样。未来真正有价值的,不只是“问 AI 一个问题”,而是定义清楚:什么信号值得关注,什么条件触发行动,什么动作需要审批,什么任务可以自动执行。
四、智能眼镜:AI 入口不再局限于电脑和手机
这次 Google I/O 还展示了智能眼镜方向。虽然这个方向过去已经被反复讨论过很多次,但结合 Gemini、语音交互和后台 Agent 来看,它的意义正在发生变化。
智能眼镜不只是一个新的硬件设备,而是 AI 交互入口的延伸。未来用户可能不需要一直打开电脑,也不需要在手机上输入长文本。语音、眼镜、手表、车机、手机屏幕,都可能成为确认任务、查看结果、接管 Agent 的入口。

这也让 AI 交互进一步从“屏幕内的软件”走向“现实中的随身助手”。当 Gemini 可以看见环境、理解语音、调用服务、执行任务,并通过眼镜把关键信息实时呈现出来,AI 就不再只是一个 App,而是逐渐嵌入用户的生活场景。
结语:谷歌这次没有炫技,而是在顺应三个时代方向
如果只按单个产品看,Google I/O 2026 的很多发布并不算完全新鲜。世界模型、AI 编程、多 Agent、云端任务、智能眼镜,这些概念都不是谷歌第一次提出,也不是行业第一次讨论。
但谷歌厉害的地方在于,它正在把这些方向系统性地连起来。
第一,Gemini Omni 指向世界模型,让 AI 从“生成内容”走向“理解和模拟现实世界”。
第二,Antigravity 指向交互方式进化,让 AI 从聊天框走向多智能体任务指挥台。
第三,Gemini Spark 和 Search Agents 指向云端 24 小时 Agent,让 AI 从即时问答走向持续执行。
这三条线索放在一起,说明 AI 产品的下一阶段竞争,已经不只是模型参数和榜单分数的竞争,而是基础设施竞争、交互入口竞争和任务执行系统竞争。
谷歌这场大会真正的热点,不是某一个功能,而是它给出了 AI 未来形态的一种答案:AI 会越来越像一个随时在线、能理解世界、能调用工具、能协同工作的数字劳动力。
接下来真正的问题是:这些能力如何进入普通人的生活?国内玩家能不能看懂这条路线?又能不能在世界模型、多 Agent、生成式 UX 和云端执行系统上追上来?
这可能才是 Google I/O 2026 最值得关注的地方。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)