GraphRAG也能玩Skill,西交大知识超图起飞
你让一个大模型从医学文献里抽知识图谱,它常常漏掉关键的时空限定;换到法律文书,它又开始把一个完整事件拆成一堆零散的三元组。换个领域就拉跨,这不是个例,而是现有知识抽取方法的通病。

问题不是模型笨,而是它在不同领域面前缺的不是知识,而是一套"怎么抽"的技能。Hyper-KGGen 就是为了解决这个问题来的。
知识图谱的单薄和超图方法的头重脚轻
传统知识图谱只存三元组——(头实体, 关系, 尾实体),但现实中大量事实天然是多元的。比如"2024 年 3 月,甲公司在上海收购了乙公司",这不是一个三元组能装下的:涉及时间、地点、两个实体和具体动作,至少是五元关系。硬拆成多个三元组,语义就散了。
知识超图可以解决这个问题——它把一组相关实体和关系打包成一个"超边",保留完整语义。但现有超图抽取方法普遍有两个毛病:一是头重脚轻,只盯着复杂的高阶关系,基础二元关系反而抓不好;二是跨域拉跨,通用抽取器遇到行业术语和隐含逻辑就大幅掉分。
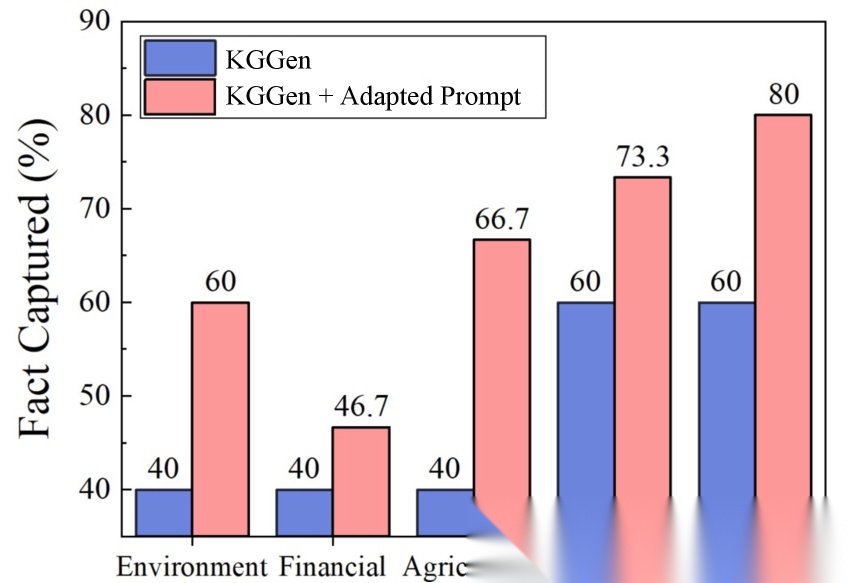
Scenario Gap 对比:通用 prompt vs 领域自适应 prompt 的抽取效果差异
Figure 1 很直观地展示了这个 gap:同一个模型,用通用 prompt 抽取效果差,但换上领域自适应的 prompt 就好很多。说明模型不是不会,而是缺少对齐领域约束的Skill技能。
Hyper-KGGen 怎么做:先搭骨架,再练技能
Hyper-KGGen 的核心思路是两步闭环:
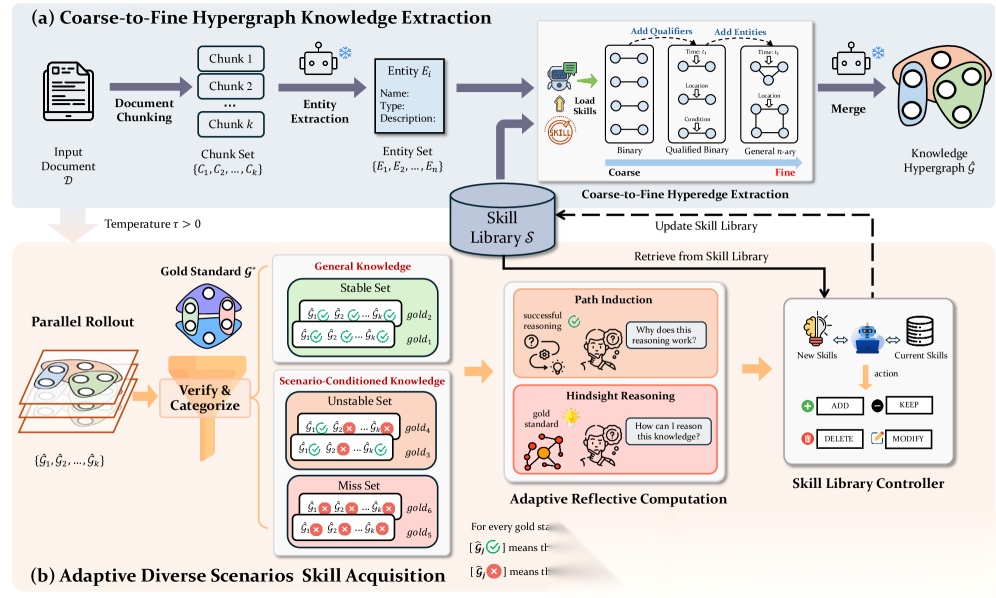
Hyper-KGGen 整体架构:左侧粗到细抽取,右侧自适应Skill获取
第一步,粗到细分层抽取。 先抽二元关系搭骨架,再加时空限定条件丰富细节,最后才抽多元事件做完整超边。模型每一步的认知负担小,结构也更完整。
第二步,也是这篇论文最关键的创新——把失败变成技能库。
具体做法:对同一文档并行抽 K 次,按稳定性把结果分成三类:
- 稳定集:每次都抽到的,属于通用知识,不用管
- 不稳定集:有时抽到有时漏掉的,属于领域特定知识
- 遗漏集:完全没抽到的,属于领域盲区
对不稳定的关系,分析成功轨迹里的推理路径,总结出"为什么会抽对"——这叫路径归纳。
对完全漏掉的关系,把正确答案塞回上下文,让模型反推"应该怎么发现这条关系"——这叫事后推理。
这些总结出来的经验被提炼成技能,存进一个全局Skill技能库。推理时,系统会从技能库里检索相关技能,动态注入 prompt,让模型带着"前人经验"去抽取新文档。
Skill技能库的维护也很有讲究——不是只进不出,而是通过 ADD(新增)、MODIFY(修正)、MERGE(合并冗余)、KEEP(保持不变)四个操作持续进化,避免过度拟合。
效果:Skill技能比示例有效得多
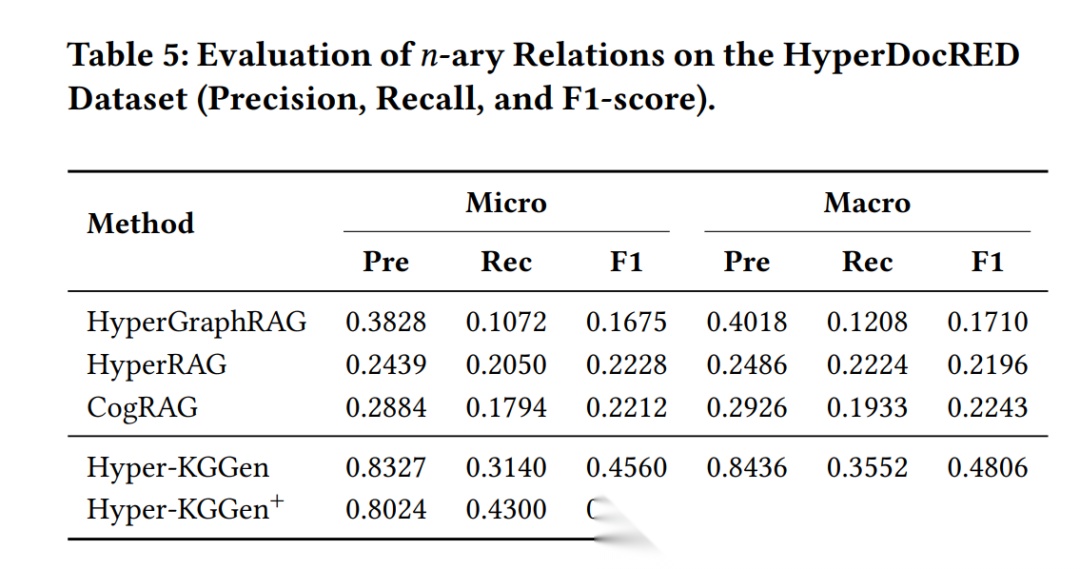
数字说话:
n-ary 关系抽取(HyperDocRED):Hyper-KGGen+ 的 Micro F1 达到 0.5600,是 HyperGraphRAG(0.1675)的 3.3 倍。加了技能库之后,recall 从 0.314 提升到 0.430,而 precision 只从 0.833 降到 0.802——用很小的精度代价换来了大量被遗漏关系的发现。
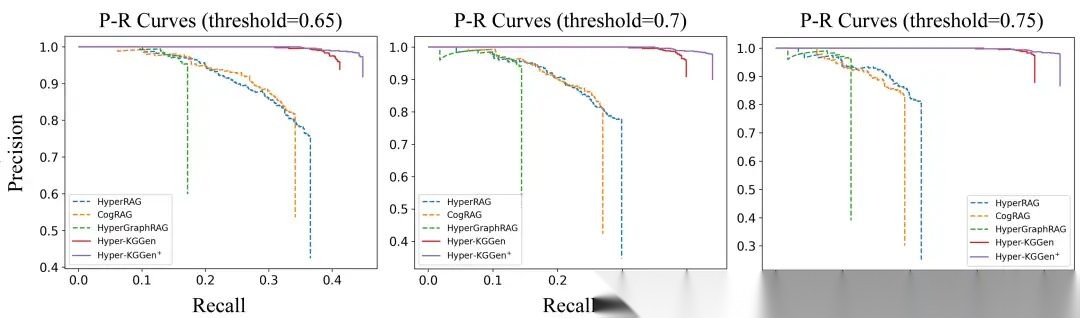
PR 曲线:Hyper-KGGen 在不同语义匹配阈值下全面领先
跨域事实覆盖(MINE):在 4 个不同底层 LLM(GPT-4o-mini、Gemini-2.5-Flash、Qwen3、DeepSeek-V3.2)上,Hyper-KGGen+ 的平均事实覆盖准确率约 0.80,比 Cog-RAG(~0.73)和 Hyper-RAG(~0.74)高约 7 个百分点。说明技能库的增益不依赖特定模型。
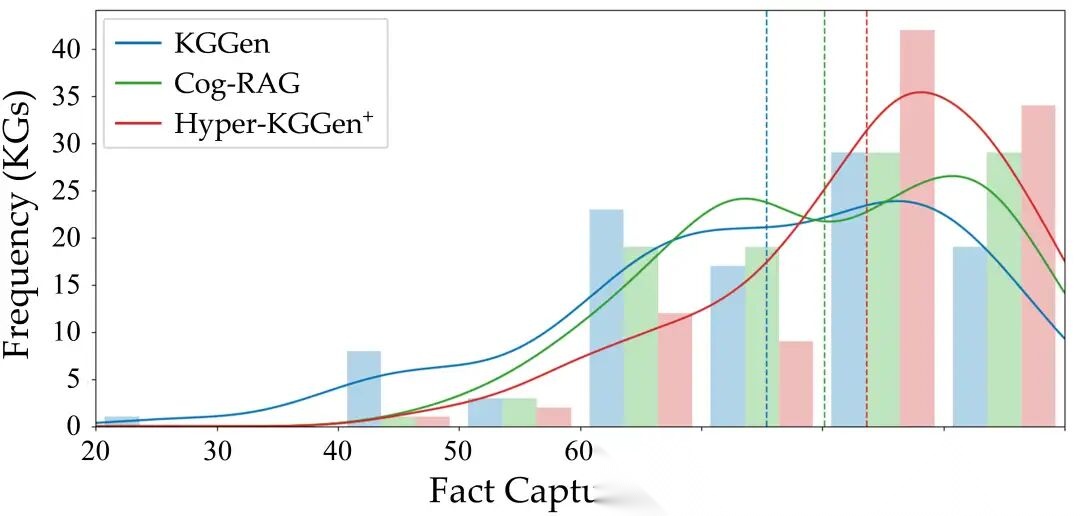
Figure 4: Distribution of MINE scores across 100 articles for KGGen, Cog-RAG, and Hyper-KGGen.
RAG 下游任务(UltraDomain):在 Mix 和 Pathology 两个基准上,Hyper-KGGen+ 的平均分分别为 85.10 和 86.72,均为所有方法最高。即使在较少检索量(k=40)下,Hyper-KGGen 的表现就能匹配 Hyper-RAG 在 k=80 时的水平——意味着它构建的超图信息密度更高,检索效率更好。
最关键的对比在 Figure 5:SKill vs Few-shot。Few-shot 示例加到一定数量就饱和了,因为示例主要帮模型对齐格式和局部规律;但技能是从跨场景失败模式中总结的决策规则,能持续积累,且领域切换时仍然有效。
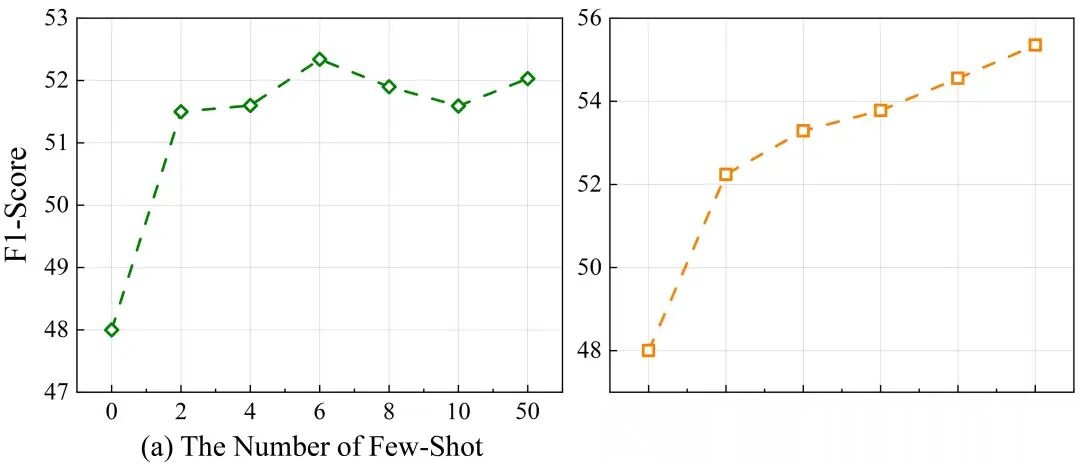
Skills vs Few-shot:技能库持续累积增益,few-shot 示例很快饱和
这意味着什么
Hyper-KGGen 证明了一件事:在知识抽取场景下,从失败中提炼的可复用技能,比喂更多示例有效得多。
这个思路不限于知识图谱。任何需要 agent 在多场景下持续改进的 workflow——文档分析、信息抽取、自动化决策——都可以借鉴这种"稳定性反馈 + 技能进化"的范式:让模型跑多遍,找到它不稳定和完全遗漏的地方,从中提炼规则,反哺下一次执行。
模型不是不会做,而是缺一套方法。给例子不如教技能。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献186条内容
已为社区贡献186条内容

所有评论(0)