RL Token: Bootstrapping Online RL with Vision-Language-Action Models
RL 令牌:使用视觉-语言-动作模型引导在线强化学习
“我们引入了一种轻量级方法,只需几个小时的实际实践,就可以对预训练的 VLA 进行高效的在线 RL 微调。我们 (1) 调整 VLA 以公开“RL 令牌”,这是一种紧凑的读出表示形式,可保留与任务相关的预训练知识,同时充当在线 RL 的有效接口,以及 (2) 在该 RL 令牌上训练一个小型行动者评论家头以改进操作,同时将学习到的策略锚定到 VLA。使用 RL 代币 (RLT) 的在线 RL 可以快速高效地使用 RL 微调大型 VLA。”
“冻结的 VLA 提供广泛的感知理解和行动建议,而轻量级参与者和评论家则调整策略以成功完成在线任务中最困难的部分。”
“我们的方法使用样本高效的在线 RL 算法来训练使用 RL 令牌表示的小型参与者和评论家网络,并使用额外的正则化器将参与者锚定到 VLA 动作,以便在线 RL 改进有希望的行为,而不是从头开始学习。”
解读:看完摘要和引言的上述三段话,咱们就知道了本文核心的是三个点:①VLA与RL 令牌也就是token的关系、②轻量级参与者和评论家 actor-critic networks、③正则化器将参与者actor锚定到 VLA 动作
把这三点弄懂了,这篇文章就内化于心了。
“首先,RLT 引入了 RL 令牌(一种经过训练以压缩 VLA 内部嵌入的紧凑读出表示),用作轻量级行动评论家的状态观察,保留 VLA 的预训练感知结构,同时实现高效的在线学习。其次,RLT 在与 VLA 的本机操作接口一致的分块操作上进行操作,缩短了高控制频率下稀疏奖励下时差学习(tem poral-difference,TD,我强化学习基础薄弱这块我好久才弄懂)的有效决策范围,这与面临更长的信用分配问题的单步方法 [28-30] 形成鲜明对比。第三,RLT actor 不是预测残差或潜在噪声,而是直接以 VLA 的采样参考动作块为条件并对其进行正则化,将在线 RL 转化为良好 VLA 先验行为策略的局部细化,而不是无约束搜索或扩散过程的隐式调制。”
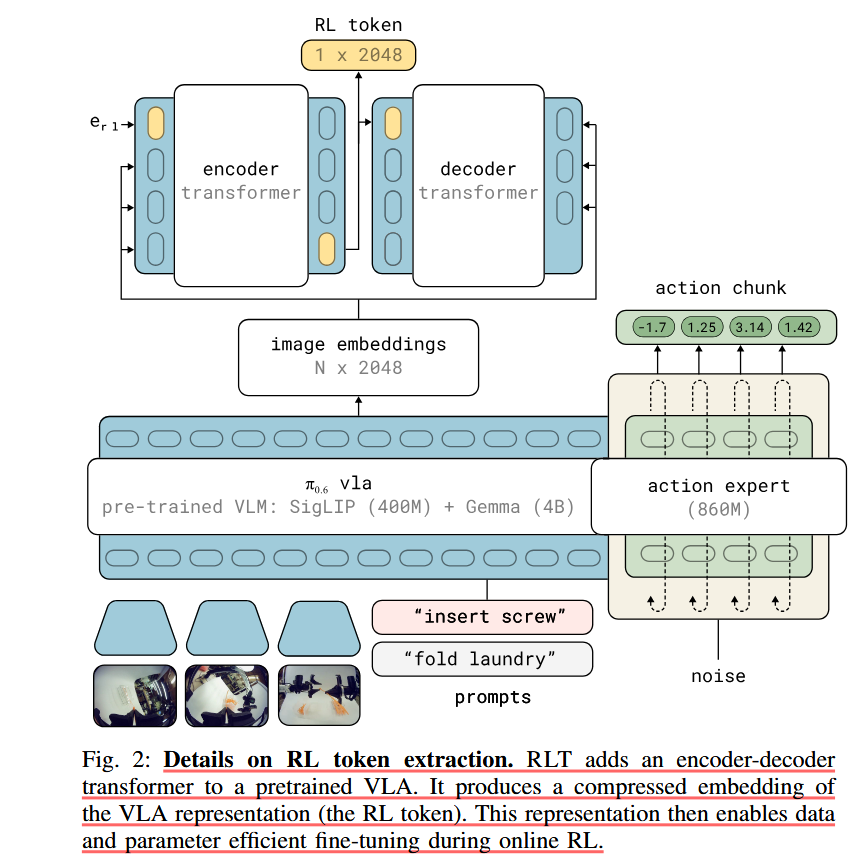
图 2:RL 令牌提取的详细信息。 RLT 将编码器-解码器变压器添加到预训练的 VLA 中。它生成 VLA 表示(RL 令牌)的压缩嵌入。这种表示可以在在线强化学习期间实现数据和参数高效的微调。
①得到RL token
“我们通过添加 RL 令牌(图 2)来实现这一点:一个学习的读出嵌入,将 VLA 的知识总结为一个充当 RL 状态的小向量。具体来说,我们从添加到预训练 VLA 的小型附加变压器中获取 RL 令牌。我们以编码器-解码器 [35] 的方式训练这个变压器,编码器的最后一个输入是 RL 令牌(这里也就是erl)。由于 RL 令牌的表示必须保留足够的信息以使解码器能够重建输入,因此它成为了瓶颈。令 z = f (s, l; θvla) 表示状态 s 和语言指令 l 的预训练 VLA 生成的最终层令牌嵌入。嵌入 z 分解为 z1:M = {z1, . 。 。 , zM },其中每个 zi 对应于一个输入标记的嵌入。我们将学习的嵌入 erl = eφ(<rl>) 附加到序列中,并使用轻量级编码器变换器 gφ 处理增强序列。特殊令牌位置处的编码器输出(表示为 zrl)是我们的 RL 令牌(变换后的RL令牌)”
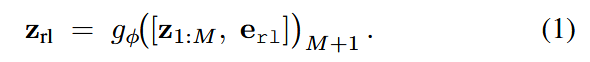
“然后训练具有线性输出投影 hφ 的解码器变换器 dφ,以根据 zrl 自回归重建原始嵌入。让 ̄zi = sg(zi) 表示应用于 VLA 嵌入的停止梯度运算,则演示 D 上的自回归重建目标给出为:”
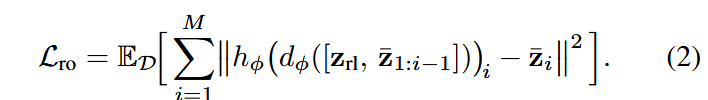
解读:这里可以理解为利用自编码器结构使得作为中间桥梁的RL token越来越能容纳VLM输出的重要信息。
②利用这个RL token进行在线强化学习
“在初始适应阶段之后,我们冻结 VLA 和 RL 令牌表示。然后,我们在线训练轻量级参与者(πθ)和评论家(Qψ)网络。它们的输入 x 将 RL 令牌与任何有助于实现闭环控制的附加信息(例如机器人的本体感受状态)结合起来。 评论家 模型估计状态和动作的值:Qψ(x, a1:C ) ∈ R。值得注意的是,RL 参与者 πθ(·|x, a ̃1:C ) 不是从头开始生成动作,而是经过训练来细化 VLA 提出的动作序列 a ̃1:C (称为动作块)。”
(1)训练评论家。我们的评论家 Qψ(x, a1:C ) 将状态和动作块 a1:C 作为输入。我们使用标准的离策略时间差异学习(TD)对从重放缓冲区 B 采样的动作块转换进行训练:
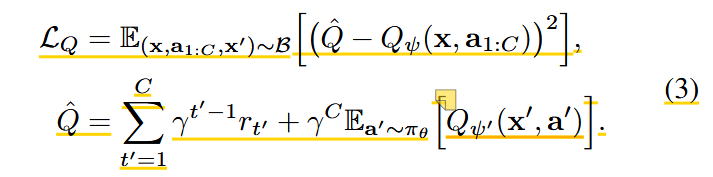
解读:这个目的是为了什么?训练 评论家,让它学会评价 action chunk 的长期价值,从而指导 参与者 改进 VLA 给出的动作。本质上是为了训练Qψ让他能进行评估奖励。这里的rt'是人工标注的奖励,不过是稀疏的,附件中有讲到。注意Qψ'它是当前 critic Qψ 的慢速拷贝,用来提供更稳定的 target。
a'是下一步的动作吗?不是单个 low-level 下一步动作,而是到达 x′ 后,由当前 policy 采样的“下一段 action chunk”。
为什么跟x'放在一起,然后公式三里下面的这个公式是什么意思?因为 critic 是 Q(x,a),要评价未来价值就必须输入“下一个状态 x”和“下一个动作 chunk a′”。它定义 TD target Q^\hat :当前 chunk 内真实奖励之和,加上执行完 chunk 后从 x′ 继续按照 policy 行动的未来价值估计。
可以先把 TD target Q^\hat 理解成一句话: Q^\hat 是 critic 训练时用来当“答案标签”的目标值,它由“已经真实拿到的奖励” + “对未来价值的估计”组成。反复训练后,critic 越来越会预测长期价值。
(2)训练 RL 策略。我们的行动者网络 πθ(·|x, a ̃1:C ) 在动作块上产生高斯动作分布。它接受输入状态和参考动作块 a ̃1:C ,并生成动作分布:
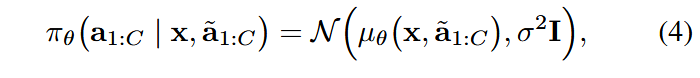
训练目标就是:
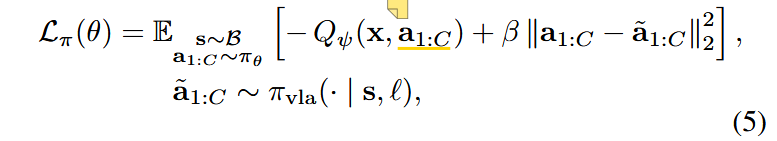
这里a1:C指的是从上述(4)动作分布中采样得到的动作,带~的a1:C是VLA生成的动作,在文章中指的就是参考动作
然后再连起来看这个算法图就比较清晰

在算法图下面写了一段关于update的话
“更新。根据算法 1,策略更新是从重播缓冲区中离线策略执行的。为了在训练期间保持计算和时间效率,我们异步执行推理和学习。在实践中,我们为每个演员更新执行两次评论家更新,并在热身阶段后不久开始学习。我们使用 5 的高更新数据比率,这在低数据在线制度中至关重要。”
解读:critic 和 actor 的更新频率比例是 2:1。因为 actor 的学习依赖 critic。也就是说,actor 是根据 critic 的打分来调整动作的。如果 critic 还很不准,actor 就可能被错误的 Q 值带偏。比如 critic 错误地认为某个奇怪动作价值很高,actor 就会学那个奇怪动作。所以需要先让 critic 多学一点,让它的价值估计更靠谱,然后再更新 actor。
每新收集一份数据,平均做 5 次从 replay buffer 采样出来的训练更新。每收集 1 份新的环境数据,就做 5 次梯度更新。
实验的话就比较常规了

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)