不止是算术:深入理解“标准误”家族(SEM、SED、MSE)
如果你做科研做久了,就会发现一个很有意思的现象:
很多人会算均值、会做 t 检验、会跑回归,但一碰到“标准误”就开始混乱——
SEM 是什么?SED 又是什么?MSE 和它们有什么关系?为什么名字都像,但含义完全不同?
更麻烦的是,这几个概念常常出现在不同场景里:
- 心理测量里谈 SEM
- 两组均值比较里谈 SED
- 方差分析、回归、线性模型里谈 MSE
如果没有真正理解它们,你就很容易在论文阅读、结果解释和统计建模中“半懂不懂”,甚至把不同层面的误差混为一谈。
这篇文章想做的,不是给你背定义,而是帮助你建立一个更高层次的理解框架:
标准误不是一个孤立概念,而是统计推断中“估计不确定性”的不同表达方式。
我们会系统讲清楚:
- 标准误到底在“标准”什么
- SEM、SED、MSE 分别是什么
- 它们之间的差异、联系和使用场景
- 为什么它们对科研结论非常重要
- 如何在实际研究中理解、报告和利用它们
- 如何借助 AI 提升你对这三个概念的理解、写作和分析能力
一、先建立一个大框架:标准误,本质上是在描述“不确定性”
很多人第一次接触标准误时,会把它简单理解成“平均值的波动程度”。
这个理解不算错,但太粗糙。
更准确地说,标准误 (standard error) 是:
某个统计量的抽样分布的标准差。
也就是说,它描述的不是原始数据本身有多分散,而是:
- 如果我重复抽样
- 每次都算同一个统计量
- 这个统计量会波动多大
比如:
- 样本均值的标准误
- 两组均值差的标准误
- 回归系数的标准误
它们都在回答同一个问题:
这个估计值稳定吗?精确吗?
二、为什么“标准误家族”会让人混淆?
因为它们名字都带“误”,但其实针对的是不同对象。
- SEM 常常指 Standard Error of the Mean
即“均值标准误” - SED 常常指 Standard Error of Difference
即“差值标准误” - MSE 是 Mean Square Error
即“均方误差”,常作为误差方差估计量使用
三者都和“误差”有关,但层次完全不同:
- SEM 关注的是一个均值估计的不确定性
- SED 关注的是两个估计值之差的不确定性
- MSE 关注的是模型残差的平均平方大小,通常是对误差方差的估计
所以,最核心的理解不是“它们都叫 standard error 吗”,而是:
它们分别对应“均值”“差异”“残差”这三种不同的统计问题。
三、SEM:均值的标准误,不是“标准差”
这是最常见的混淆点之一。
1. SEM 的定义
SEM 通常指样本均值的标准误,表示样本均值作为总体均值估计时的不确定性。
若总体标准差为 σ,样本量为 n,则:
![]()
实际中通常不知道 σ,所以会用样本标准差 s 估计:
![]()
2. 它和标准差有什么区别?
这是科研写作里非常重要的一点。
- 标准差 SD:描述原始数据的离散程度
- 标准误 SEM:描述样本均值的精确程度
二者不是一回事。
如果你的样本变大:
- SD 可能变化不大,因为数据本身的分散程度没变
- SEM 会变小,因为均值估计更稳定了
换句话说:
SD 讲的是“个体之间差异有多大”,SEM 讲的是“均值估计有多准”。
3. 为什么 SEM 会随样本量增大而减小?
因为样本越大,均值越接近总体真实均值。
抽样波动会被平均掉。
这也是为什么很多论文中均值旁边的误差线如果用的是 SEM,看起来会比用 SD 更“短”。
但注意:
误差线短,不代表数据更集中;
可能只是因为样本量更大。
4. SEM 的常见用途
- 构建均值的置信区间
- 估计均值估计的精确程度
- t 检验和均值比较中的基础量
- 图形展示中的误差线
5. 一个直观例子
假设某变量的样本标准差是 $$20$$。
- 若 n = 25,则 SEM = 20 / sqrt(25) = 4
- 若 n = 100,则 SEM = 20 / sqrt(100) = 2
注意,数据本身的离散程度没变,但均值估计更稳定了。
四、SED:两个均值差的标准误
如果说 SEM 是“一个均值有多准”,那么 SED 就是:
两个均值之差有多不稳定。
1. SED 的定义
SED 即两个独立估计值之差的标准误,最常见于两组均值差。
假设两组均值分别为 X̄1 和 X̄2,那么差值为:X̄1 - X̄2
其标准误为:
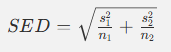
其中:
- s1² 和 s2² 是两组样本方差
- n1 和 n2 是样本量
2. 它和 t 检验有什么关系?
非常直接。
两独立样本 t 检验里,核心就是:
![]()
也就是说:
- 分子是“差了多少”
- 分母是“这个差值有多不稳定”
如果差值大,但 SED 也大,未必显著。
如果差值不大,但 SED 很小,也可能显著。
所以,统计显著性从来不是只看“差多少”,而是看:
差异相对于波动性是否足够大。
3. SED 的核心意义
它回答的是:
“这两个组均值的差异,是否稳定到足以超出随机波动?”
这在研究报告中非常关键,因为很多“看起来有差异”的结果,实际上只是样本波动造成的。
4. 一个简单直觉
假设两组均值差为 5。
- 如果 SED = 1,那这个差异比较稳定
- 如果 SED = 5,那这个差异就不太可靠
也就是说,差值的意义不能脱离其不确定性。
5. 配对样本中的 SED
如果是配对设计,比如同一批对象前后测比较,那么差值的标准误会考虑差值分数本身的波动,而不是简单把两组当独立样本。
这时的核心仍然是:
差值的标准误 = 差值分布的标准差 / 样本量平方根相关形式
具体公式会因设计不同而变,但思想是一致的:
看“差”本身的抽样不确定性。
五、MSE:均方误差,误差方差的估计基础
前面讲的 SEM 和 SED 都是“标准误”意义上的概念,而 MSE 则稍有不同。
它在统计建模中非常常见,尤其在:
- 方差分析
- 回归分析
- 线性模型
- 实验设计
里经常出现。
1. MSE 的定义
MSE = SSE / df
其中:
- SSE 是误差平方和
- df 是自由度
更直观地说,MSE 是:
残差平方的平均水平。
因为残差平方越大,说明模型拟合越差,数据围绕模型的散布越大。
2. MSE 为什么重要?
因为它常常是对总体误差方差 σ² 的估计。
在很多模型中,MSE 是后续计算标准误、构建 t 检验、做置信区间和方差分析的基础。
换句话说:
MSE 是模型误差大小的核心估计量之一。
3. MSE 和 SEM、SED 的关系
它们之间不是同一个概念,但有联系。
例如在回归模型中,系数标准误通常会基于:
- 设计矩阵
- 残差方差估计
- 即 MSE
然后推导出参数估计的标准误。
所以你可以把 MSE 理解为:
“误差总体水平”的估计基础;
而 SEM、SED 则是基于此进一步得到的“某个统计量的不确定性”。
4. MSE 的一个核心视角
它体现的是:
模型没解释掉的部分有多大。
这提醒我们:
- 不是所有变异都能被解释
- 模型越复杂,不一定越好
- 误差项不是噪音垃圾,而是现实复杂性的体现
六、一个统一框架:从数据到统计推断,三者分别在不同层次上起作用
你可以用下面这个结构来理解:
1. 原始数据层面:SD
看个体数据本身分散程度。
2. 统计估计层面:SEM 和 SED
看均值、差值等统计量有多稳定。
3. 模型残差层面:MSE
看模型对数据的解释程度,以及剩余误差多大。
4. 一句话概括
- SD:数据本身离散不离散
- SEM:一个均值估计准不准
- SED:两个均值之差稳不稳
- MSE:模型剩余误差大不大
七、为什么科研人必须搞清楚这三者?
因为很多论文问题,根子都出在这里。
1. 误把 SD 当 SEM
这是展示数据时最常见的混淆之一。
如果你把 SD 说成 SEM,读者会误以为你的估计更精确。
这会严重影响结果解读。
2. 误把误差线当成“数据离散程度”
很多图中的误差线如果画的是 SEM,并不能表示个体差异大小。
如果你要表达群体内部的分散,应该考虑 SD;
如果你要表达均值估计的不确定性,才是 SEM。
3. 看见均值差就下结论
均值差必须结合 SED 或置信区间解释。
否则很容易把随机波动当成真实效应。
4. 只看 p 值,不看误差结构
p 值小,不代表效应大;
p 值大,也不一定说明没差异。
你必须理解误差、方差和估计精度。
八、在论文中怎么正确理解和报告?
1. 描述性统计:常见写法
- 平均值 ± SD
- 均值及其 95% 置信区间
- 中位数及四分位数
如果你想表达样本离散程度,优先用 SD。
如果你想表达均值估计精度,可以报告 SEM 或置信区间。
2. 组间比较
两组比较时,重点不是“均值差有多大”,而是:
- 差异是否显著
- 差异的置信区间是否跨零
- 差异相对于其标准误是否足够大
3. 模型分析
在线性回归、方差分析中,要关注:
- 残差是否合理
- MSE 是否过大
- 标准误是否稳定
- 模型是否存在异方差、非正态或拟合不足
九、几个常见误区,一次讲透
误区 1:SEM 越小,说明数据越好
不一定。
SEM 小可能只是因为样本量大。
它说明的是均值估计更稳定,不代表研究质量自动更高。
误区 2:MSE 就是“平均误差”
严格说不是。
MSE 是“误差平方的平均”,更准确地说是均方误差或误差均方。
误区 3:SED 只是两个 SEM 相加
也不对。
对于独立样本,SED 不是简单相加,而是方差相加后再开方:
![]()
而因为 ![]() ,就得到前面那个更一般的公式。
,就得到前面那个更一般的公式。
误区 4:标准误就是误差
标准误不是“错误”,而是不确定性的量化。
它告诉你“这个估计有多稳”,不是在说“你做错了”。
十、一个极简的数值直觉
假设两组数据:
- 组 A:X̄A = 50,sA = 10,nA = 100
- 组 B:X̄B = 46,sB = 10,nB = 100
那么:
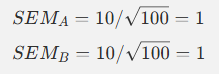
两组均值差为:
50 - 46 = 4
则:
![]()
这说明差值相对其不确定性不算小,进一步做 t 检验就有可能显著。
这个例子最重要的不是计算,而是理解:
统计结论来自“差异/不确定性”的比值,而不是只看差异本身。
十一、如何让 AI 帮你理解标准误家族?
AI 非常适合做三类辅助:
- 帮你建立概念图谱
- 帮你检查公式和解释是否混淆
- 帮你生成适合论文和科普表达的版本
Prompt 1:让 AI 帮你区分 SEM、SED、MSE
请你作为统计学导师,用“科研写作可直接引用”的方式,帮我区分 SEM、SED 和 MSE。
要求:
1. 分别解释三个概念
2. 说明它们的数学含义
3. 说明各自适用场景
4. 指出常见误区
5. 给出一个容易理解的例子
6. 用表格总结三者区别
Prompt 2:让 AI 帮你检查论文中的误差表述
请你作为审稿人,检查下面这段论文中关于标准误、标准差和均方误差的表述是否准确。
文本:
[粘贴你的段落]
请输出:
1. 概念是否混淆
2. 哪些句子需要改写
3. 如何改得更符合统计学规范
4. 是否需要补充公式或说明
Prompt 3:让 AI 帮你生成科普版解释
请将“SEM、SED、MSE”的区别解释给没有统计学基础的研究生听。
要求:
- 不要过度公式化
- 但要保持科学准确
- 使用生活化类比
- 最后用一句话总结每个概念
十二、标准误家族理解清单
你可以把下面这份 checklist 放进自己的科研笔记里。
标准误家族理解 checklist
- 我是否知道 SD、SEM、SED、MSE 各自对应什么层面?
- 我是否知道 SEM 不是 SD?
- 我是否知道 SED 主要用于差值的误差评估?
- 我是否知道 MSE 与残差和模型拟合相关?
- 我是否能解释为什么标准误会随样本量增大而减小?
- 我是否能正确解读误差线到底是 SD 还是 SEM?
- 我是否能在论文中避免把不同误差概念混为一谈?
- 我是否知道什么时候应该看置信区间而不是只看 p 值?
十三、读文献时快速识别“标准误”信息的流程
很多时候你不是不会算,而是不知道文献到底在说什么。
下面这个流程可以帮助你快速拆解论文。
Step 1:先看它报告的是哪种量
是均值、差值、回归系数,还是模型残差?
Step 2:判断它的误差指标是什么
是 SD、SEM、CI,还是模型里的 MSE?
Step 3:判断它想表达什么
- 个体离散程度?
- 均值估计精度?
- 两组差异稳定性?
- 模型剩余误差?
Step 4:判断是否存在概念混用
如果作者把 SD 写成 SEM,或者把标准误解释成效应大小,就要提高警惕。
Step 5:看统计结论是否依赖于误差结构
如果显著性完全取决于样本量、误差线大小或模型残差,说明你必须更谨慎解释。
十四、标准误家族的科研理解Skill
# Skill.md:标准误家族(SEM、SED、MSE)理解能力卡片
## 目标
能够准确区分 SEM、SED 和 MSE,理解它们的统计含义、适用场景和常见误区,并能在科研写作和数据分析中正确使用。
## 核心概念
- 标准差(SD)
- 标准误(SE)
- 均值标准误(SEM)
- 差值标准误(SED)
- 均方误差(MSE)
- 残差
- 抽样分布
- 置信区间
- t 检验
- 方差分析
## 操作流程
1. 确认统计量的类型:均值、差值还是模型参数
2. 判断对应的不确定性指标
3. 区分 SD 与 SEM
4. 判断差值是否需要 SED
5. 理解 MSE 与残差/模型拟合的关系
6. 用置信区间或误差线辅助解释
7. 在论文中避免混淆术语
8. 用可视化或例子验证理解
## 常见错误
- 把 SD 当 SEM
- 把 SEM 当数据离散程度
- 把 SED 简单理解为两个 SEM 相加
- 把 MSE 当成平均偏差
- 只看显著性,不看误差结构
- 误把误差线当成效应大小
- 忽略样本量对标准误的影响
## 判断标准
我是否能回答:
- 这个误差指标对应的是哪个层次的数据问题?
- 它在统计推断中起什么作用?
- 它和样本量有什么关系?
- 在我的论文或图表中应该如何正确使用?
十五、总结:理解标准误家族,是走向“统计成熟”的标志
如果说数据分析是科研中的“算术”,那么对标准误的理解,就是科研中的“统计素养”。
你必须记住下面这组最核心的区分:
- SD:数据本身有多分散
- SEM:一个均值估计有多稳
- SED:两个均值之差有多稳
- MSE:模型残差有多大
这四者处在不同层面,但它们共同服务于同一个目标:
让我们更准确地理解数据中的不确定性。
科研不是把不确定性消灭掉,
而是把它看清楚、讲明白、控制住。
而这,正是严谨研究与“看起来很科学”的伪精确之间,最本质的区别。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)