Gemini 3.5 Flash 超越旗舰 Pro:你的模型选型标准,该重新校准了
Gemini 3.5 Flash 超越旗舰 Pro:你的模型选型标准,该重新校准了
一句话核心判断:Gemini 3.5 Flash 在编程和 Agent 任务上跑赢上代旗舰,同时速度 4 倍于竞品、价格低 25%——这不只是一次模型发布,是 AI 推理层选型维度的一次结构性重写。如果你的项目还在用"Benchmark 分 = 选型依据"这套逻辑,这篇文章值得读完。
先说一个你可能遇到过的场景
你们团队在做一个 AI Agent 项目,推理层选了某款旗舰模型——理由很充分:Benchmark 评分最高,文档完善,社区有保障,出了问题好甩锅。
上线之后,有几个问题一直没彻底解决:
多步 Agent 链路里,单次推理 latency 偶尔飙到 8-12 秒,下游步骤全部在等;用量上来之后,每月推理成本比预算高了 40%;用户反馈"响应太慢",但你不确定是网络问题还是模型问题,因为你没有一套清晰的 tokens/s 基准。
你以为这些是工程优化的问题。
其实其中一部分,是模型选型的问题。
2026-05-19 发生了什么
Google I/O 2026,谷歌发布了 Gemini 3.5 Flash。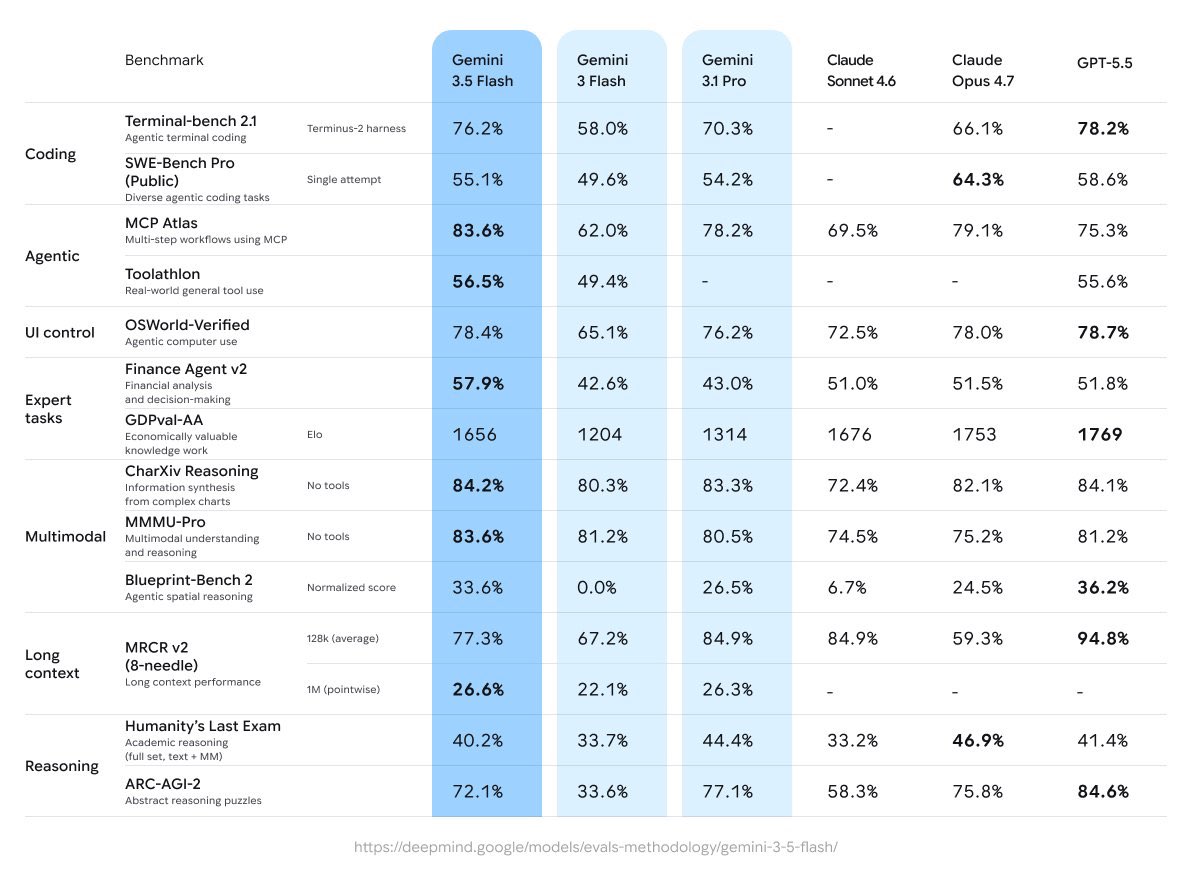
关键数字:
- 性能:在编程和 Agent 自动化任务上,Flash 超越上一代旗舰 Gemini 3.1 Pro。Terminal-Bench 2.1:76.2%(vs Pro 未公布但明确落后);MCP Atlas:83.6%(vs Pro 78.2%);CharXiv Reasoning:84.2%
- 速度:约 280 tokens/s 输出,GPT-5.5 和 Claude Opus 4.7 约 60-70 tokens/s,约 4 倍差距
- 成本:$1.50 / $9(输入/输出,百万 token),比上代旗舰 Gemini 3.1 Pro 便宜约 25%
- 上下文窗口:1,048,576 输入 tokens,64K 输出,知识截止 2026 年 1 月
- Dynamic Thinking:默认开启,模型自动判断是否需要链式推理,无需开发者手动配置
- 工具支持:函数调用、结构化输出、Search-as-a-Tool、代码执行,全部 GA
Flash 层级第一次在实际工作负载上超过 Pro 层级。
这打破了过去两年 AI 工具选型的一个核心假设:贵的旗舰版 = 能力最强 = 最值得接入。
旧的选型标准为什么失效了
过去选推理模型,开发者常用的判断链路大概是这样的:
- 看 Benchmark 排行榜(MMLU / HumanEval / MATH 等)
- 选最高分的,或者选"够用"分数里最便宜的
- 如果是旗舰应用,默认选旗舰版
- 观望等竞品旗舰版出来再对比
这套逻辑在模型能力高度分层、Flash = 简化版的时代是成立的。
Gemini 3.5 Flash 发布之后,它不再完全成立,原因有三个。
第一,Benchmark 测的不是你的 workload。
Flash 落后 Pro 的两个测试是 Humanity’s Last Exam(HLE)和 ARC-AGI-2,这两项考的是极限知识储量和高难度抽象推理。绝大多数生产环境里的 AI 任务——代码生成、文档处理、多步骤 Agent 工作流、RAG 问答——都不在这个区间。
你的 Benchmark 参考指标,和你的生产 workload,可能根本不在同一个能力维度上。
第二,速度差距已经大到影响架构决策。
280 tokens/s vs 60-70 tokens/s,这是 4 倍的速度差。
对一个单次问答的 chatbot 来说,这个差距可能不明显。但在 Agent 场景下,推理速度是链路总耗时的核心变量:
假设一个 5 步 Agent 工作流,每步平均生成 200 tokens。
- 慢模型(70 tokens/s):每步约 2.9s,5 步合计约 14.3s
- 快模型(280 tokens/s):每步约 0.7s,5 步合计约 3.6s
这不只是用户体验的差距。在需要实时响应的场景里,这决定了你的超时阈值设置、重试策略、并发数量,以及整个链路的可靠性设计。
第三,成本模型在规模化后的影响被低估。
$1.50/$9 vs $2.00/$12(Gemini 3.1 Pro),乍看差距不大。
但放到规模来看:假设每月推理量 10 亿输入 tokens + 5000 万输出 tokens:
- 3.1 Pro:$2,000 + $600 = $2,600
- 3.5 Flash:$1,500 + $450 = $1,950
节省约 25%,折合每月 $650,每年 $7,800。这还是在 Flash 实际任务表现不差于 Pro 的前提下。
我的判断是
下半年,推理层选型的核心指标会发生一次明显的漂移。
从:Benchmark 排名 × 旗舰溢价背书
转向:tokens/s × cost/token × task_success_rate
这三个指标的组合,才是你的 workload 真正需要的选型依据。Gemini 3.5 Flash 在前两项上已经建立了明显优势,在 Agent 和编程类 task_success_rate 上超越了上代旗舰。
这不意味着你现在就要迁移。这意味着你需要重新跑一次评估——用你的实际 workload,不是 leaderboard。
关于大家的反对意见
“Flash 在 HLE 和 ARC-AGI-2 上明显落后 Pro,我们的项目有复杂推理需求,不能用 Flash。”
这是目前最有分量的反驳。
我的回应分两层。
第一层:确认你的"复杂推理需求"是否真的在 HLE/ARC-AGI-2 的能力区间。这两个测试的典型任务是:需要跨域知识整合的超难问答(如物理+经济+法律交叉题),和纯视觉抽象规律推理(图形变换、规律归纳)。
如果你的"复杂推理"是:长上下文文档总结、多轮代码调试、复杂 SQL 生成、API 调用链规划——这些在 Flash 上的表现可能和 Pro 差距并不显著,而且 Flash 的速度优势在这些任务上会更明显。
第二层:即使你确认有 HLE 级别的推理需求,混合路由策略也值得评估。简单任务走 Flash,推理密集型任务走 Pro 或 Claude Opus,而不是把所有任务都喂给最贵的模型。这是成本控制和能力匹配的标准工程解法。
具体的 review 步骤
Step 1:审计你的推理层 workload 构成
在你现有的 AI 调用日志里,按 task_type 分类(单轮 QA / 多轮 Agent 步骤 / 代码生成 / 文档处理 / 推理密集型),统计各类占比。
如果推理密集型 < 20%,你已经在为 80% 不需要旗舰能力的任务付旗舰价格。
Step 2:跑 latency 基准测试
取你生产环境里最有代表性的 20 个 prompt,分别用 Gemini 3.5 Flash 和现有模型跑,记录:
- Time to First Token(TTFT)
- 总生成时间(按相同 max_tokens 设置)
- 对于 Agent 场景:模拟 5 步链路的端到端耗时
Step 3:对比 task success rate
不要只看 latency。用你实际的评估集(如果有)跑 Flash,看任务完成质量是否满足你的 acceptance threshold。
如果没有评估集,这是你应该建立一个的时机——不管用什么模型。
Step 4:算实际成本模型
用你过去 30 天的实际 token 用量,代入 Flash 的价格,算出迁移后的月度成本差。
如果差额 < $500/月,成本不是你的主要决策因素;如果差额 > $2000/月,值得认真评估。
Step 5:评估 vendor lock-in 风险
检查你的代码里有没有深度依赖某个厂商的专属 feature——比如 Anthropic 的 system_prompt 格式、OpenAI 的 function_call schema、Google 的 grounding 配置。
vendor lock-in 不是拒绝迁移的理由,但它是迁移成本的一部分,要算进去。
Dynamic Thinking 的工程化含义
Gemini 3.5 Flash 默认开启 Dynamic Thinking,模型会根据问题难度自动决定是否使用链式推理,不需要开发者在 API 调用里手动设置 thinking: true。
这对工程层有几个影响:
- 响应时间的不确定性增加:同样的 prompt,有时模型决定思考,有时直接输出,latency 分布会变宽。你的超时设置需要覆盖到思考模式的 p99。
- 输出 token 数量可能增加:思考过程也计入 token 计费,需要在成本模型里加入这个变量。
- 可预测性降低:如果你需要严格控制推理行为,考虑通过 API 参数关闭 Dynamic Thinking(
thinking_budget: 0),用确定性换可预测性。
最后一个问题留给你
你现在项目里的 AI 调用,有没有因为推理速度慢导致过用户投诉或超时报警?
如果有,那不只是工程问题。那是一个信号,说明你的选型标准里,speed 的权重一直是 0。
Gemini 3.5 Flash 提供了一个重新校准这个权重的机会。至于要不要用,跑完测试再说——别在没有数据的情况下做选型决定,不管是换还是不换。
评论区聊聊:你们项目的 AI 推理层,tokens/s 是显性指标还是根本没监控?
事实来源:Google I/O 2026 官方发布(2026-05-19)/ Google AI Blog / LLM-Stats / MarkTechPost
发布前请过 humanizer 润色

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)