【LangGraph】House_Agent 实战(三):推荐子图 —— 数据库交互与工具调用
·
【LangGraph】LangGraph 实战(三):推荐子图 —— 数据库交互与工具调用
上一章——>【LangGraph】House_Agent 实战(二):状态设计与主图构建
一、推荐子图架构
1.1 子图职责
推荐子图负责根据用户需求查询数据库,推荐合适的房源
主要流程:
- 收集用户需求:从对话中提取城市、预算、房型等信息
- 查询数据库:使用 SQL 查询匹配的房源
- 返回推荐结果:格式化并返回给用户
1.2 整体流程图
# 生成命令
print(recommend_graph.get_graph(xray=True).draw_mermaid())
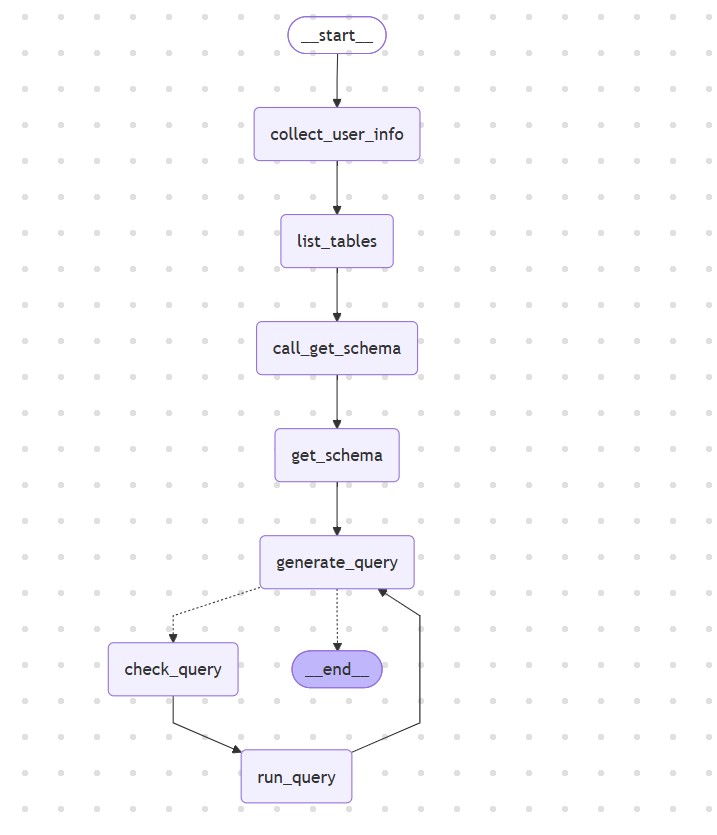
1.3 节点说明
| 节点 | 职责 | 输入 | 输出 |
|---|---|---|---|
collect_user_info |
收集用户需求 | 用户消息 | 更新状态字段 |
list_tables |
获取表列表 | - | 表名列表 |
call_get_schema |
调用 schema 工具 | 表名 | 表结构 |
get_schema |
获取表结构 | 工具调用 | 表结构信息 |
generate_query |
生成 SQL | 用户需求+表结构 | SQL 查询 |
check_query |
检查 SQL | SQL 查询 | 验证后的 SQL |
run_query |
执行 SQL | SQL 查询 | 查询结果 |
1.4 与主图的状态共享
# 推荐子图状态
class RecommendState(TypedDict):
# 共享字段(与主图相同)
messages: Annotated[list[BaseMessage], add_messages]
# 私有字段(推荐子图特有)
city: Optional[str] # 城市
district: Optional[str] # 区域
budget_min: Optional[float] # 最低预算
budget_max: Optional[float] # 最高预算
room_type: Optional[str] # 房屋类型
orientation: Optional[str] # 朝向
room_count: Optional[int] # 推荐数量
others: Optional[str] # 其他要求
二、用户信息收集节点
2.1 collect_user_info 设计思路
核心流程:
2.2 实现代码
# src/agent/node/recommend.py
import uuid
from typing import Optional
from langchain_core.messages import HumanMessage, SystemMessage, filter_messages
from langgraph.runtime import Runtime
from langgraph.store.base import BaseStore
from pydantic import BaseModel, Field
from src.agent.common.context import ContextSchema
from src.agent.common.llm import model
from src.agent.state.recommend import RecommendState
from src.agent.common.store import UserPreferences
# 定义用户信息的数据模型(结构化输出)
class UserInfo(BaseModel):
"""用户的租房需求信息"""
city: Optional[str] = Field(
default=None,
description="用户所在或想要租房的城市,例如:西安、北京、上海"
)
district: Optional[str] = Field(
default=None,
description="用户想要租房的具体区域或行政区,例如:雁塔区、碑林区、海淀区"
)
budget_min: Optional[float] = Field(
default=None,
description="用户的最低预算,单位为元/月"
)
budget_max: Optional[float] = Field(
default=None,
description="用户的最高预算,单位为元/月"
)
room_type: Optional[str] = Field(
default=None,
description="房屋类型,例如:整租、合租、公寓、一室一厅、两室一厅"
)
orientation: Optional[str] = Field(
default=None,
description="房屋朝向,例如:朝南、朝北、东南、南北通透"
)
room_count: Optional[int] = Field(
default=None,
description="需要推荐的房屋数量"
)
others: Optional[str] = Field(
default=None,
description="特殊要求,例如:带阳台、独立卫生间、近地铁、可养宠物、有电梯等"
)
# 节点:收集用户信息
def collect_user_info(
state: RecommendState,
runtime: Runtime[ContextSchema],
*,
store: BaseStore
):
"""
收集用户租房需求
流程:
1. 从历史偏好初始化
2. 从当前对话提取
3. 更新状态字段
4. 持久化更新用户偏好
"""
# 1. 获取需要被解析的数据:最新的用户消息 + 偏好数据
pref = state.get("user_preferences")
user_messages = filter_messages(state["messages"], include_types="human")
if pref and (pref.get('budget_min') or pref.get('budget_max')):
# 如果有历史偏好,加入到提取消息中
extract_messages = [
HumanMessage(
content="用户的历史偏好信息如下:"
f"1. 最低预算:{pref['budget_min']}"
f"2. 最高预算:{pref['budget_max']}"
),
user_messages[-1]
]
else:
extract_messages = [user_messages[-1]]
# 2. 提取信息
def extract_info(messages) -> UserInfo:
system_message = SystemMessage(
content="你是一个租房需求信息提取专家。"
"请从用户的描述与历史信息中提取租房相关信息。"
)
response = model.with_structured_output(UserInfo).invoke(
[system_message] + messages
)
return response
user_info = extract_info(extract_messages)
# 3. 更新状态
updated_state = {}
if user_info.city:
updated_state['city'] = user_info.city
if user_info.district:
updated_state['district'] = user_info.district
if user_info.budget_min:
updated_state['budget_min'] = user_info.budget_min
if user_info.budget_max:
updated_state['budget_max'] = user_info.budget_max
if user_info.room_type:
updated_state['room_type'] = user_info.room_type
if user_info.orientation:
updated_state['orientation'] = user_info.orientation
if user_info.room_count:
updated_state['room_count'] = user_info.room_count
if user_info.others:
updated_state['others'] = user_info.others
# 4. 持久化更新用户偏好
user_id = runtime.context["user_id"]
namespace = (user_id, "preferences")
prefs_result = store.search(namespace)
if prefs_result:
# 更新现有偏好
prefs = prefs_result[0].value
if user_info.budget_min:
prefs['budget_min'] = user_info.budget_min
if user_info.budget_max:
prefs['budget_max'] = user_info.budget_max
store.put(namespace, prefs_result[0].key, prefs)
updated_state['user_preferences'] = prefs
# 5. 准备最终消息
updated_state['messages'] = [
HumanMessage(content=get_recommend_info(updated_state))
]
# 打印日志
print(f"已收集用户信息: 城市={updated_state.get('city')}, "
f"区域={updated_state.get('district')}, "
f"预算={updated_state.get('budget_min')}-{updated_state.get('budget_max')}")
return updated_state
def get_recommend_info(state: dict) -> str:
"""构建推荐查询信息"""
info_parts = []
if state.get('city'):
info_parts.append(f"城市:{state['city']}")
if state.get('district'):
info_parts.append(f"区域:{state['district']}")
if state.get('budget_min'):
info_parts.append(f"最低预算:{state['budget_min']}元/月")
if state.get('budget_max'):
info_parts.append(f"最高预算:{state['budget_max']}元/月")
if state.get('room_type'):
info_parts.append(f"房屋类型:{state['room_type']}")
if state.get('room_count'):
info_parts.append(f"推荐数量:{state['room_count']}套")
return "用户租房需求:" + ",".join(info_parts)
2.3 关键点解析
- 结构化输出:使用
with_structured_output(UserInfo)确保 LLM 返回固定格式 - 历史偏好:从
store中读取用户历史偏好,与当前消息一起提取 - 持久化更新:将提取的信息保存到
store,供下次使用 - 日志记录:打印提取结果,便于调试
三、SQLDatabaseToolkit 详解
3.1 工具包介绍
SQLDatabaseToolkit 是 LangChain 提供的 SQL 数据库交互工具包,包含以下工具:
| 工具名 | 功能 |
|---|---|
sql_db_list_tables |
列出数据库中的所有表 |
sql_db_schema |
获取指定表的结构和示例数据 |
sql_db_query |
执行 SQL 查询 |
3.2 初始化工具包
# src/agent/node/recommend.py
from langchain_community.utilities import SQLDatabase
from langchain_community.agent_toolkits import SQLDatabaseToolkit
import os
# 获取数据库连接信息
db_host = os.getenv("DB_HOST", "localhost")
db_port = os.getenv("DB_PORT", "3306")
db_name = os.getenv("DB_NAME", "houser_agent")
db_user = os.getenv("DB_USER", "root")
db_password = os.getenv("DB_PASSWORD", "")
# 创建数据库连接
db = SQLDatabase.from_uri(
f"mysql+pymysql://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}"
)
# 创建工具包
toolkit = SQLDatabaseToolkit(db=db, llm=model)
tools = toolkit.get_tools()
3.3 工具节点封装
from langgraph.prebuilt import ToolNode
# 获取表信息工具
get_schema_tool = next(tool for tool in tools if tool.name == "sql_db_schema")
get_schema_node = ToolNode([get_schema_tool], name="get_schema")
# 执行查询工具
run_query_tool = next(tool for tool in tools if tool.name == "sql_db_query")
run_query_node = ToolNode([run_query_tool], name="run_query")
关键点:
ToolNode会自动处理工具调用的解析和执行name参数用于在图中标识节点
四、SQL 生成与执行循环
4.1 list_tables 节点
职责:获取数据库中的所有表
# src/agent/node/recommend.py
from langchain_core.messages import AIMessage
# 节点:获取全量表
def list_tables(state: RecommendState):
"""
调用 sql_db_list_tables 工具,获取所有表名
"""
tool_call = {
"name": "sql_db_list_tables",
"args": {},
"id": "abc123",
"type": "tool_call"
}
# 返回工具调用消息
return {"messages": [AIMessage(content="", tool_calls=[tool_call])]}
4.2 call_get_schema 节点
职责:LLM 决定需要查看哪些表的结构
# src/agent/node/recommend.py
from langchain_core.messages import SystemMessage
# 节点:LLM 决定获取哪些表的 schema
def call_get_schema(state: RecommendState):
"""
LLM 根据用户需求,决定需要查看哪些表的结构
使用强制工具调用,确保一定会调用 sql_db_schema
"""
# 系统提示词
system_prompt = """
根据用户的问题和可用的表列表,确定需要查看哪些表的结构。
请调用 sql_db_schema 工具获取这些表的详细信息。
"""
# LLM 绑定工具,强制调用
llm_with_tools = model.bind_tools(
[get_schema_tool],
tool_choice={"type": "function", "function": {"name": "sql_db_schema"}}
)
response = llm_with_tools.invoke(
[SystemMessage(content=system_prompt)] + state["messages"]
)
return {"messages": [response]}
4.3 generate_query 节点
职责:LLM 生成 SQL 查询
# src/agent/node/recommend.py
# 节点:生成 SQL 查询
def generate_query(state: RecommendState):
"""
LLM 根据用户需求和表结构,生成 SQL 查询
使用非强制工具调用,允许 LLM 自然响应
"""
# 系统提示词
system_prompt = """
你是一个 SQL 专家。根据用户的问题和数据库表结构,生成正确的 SQL 查询。
注意:
1. 只查询用户需要的字段
2. 使用适当的 WHERE 条件过滤
3. 限制结果数量(默认 5 条)
4. 确保 SQL 语法正确
给定一个输入问题,创建一个语法正确的 {dialect} 查询来运行,
然后查看查询的结果并返回答案。
"""
# LLM 绑定工具,非强制调用
llm_with_tools = model.bind_tools([run_query_tool])
response = llm_with_tools.invoke(
[SystemMessage(content=system_prompt)] + state["messages"]
)
return {"messages": [response]}
4.4 check_query 节点
职责:检查生成的 SQL 是否正确
# src/agent/node/recommend.py
# 节点:强制创建一个调用查询 SQL 的工具调用
def check_query(state: RecommendState):
"""
检查 SQL 查询的正确性
使用强制工具调用,确保 SQL 被执行
"""
# 系统提示词
check_query_system_prompt = """
你是一个非常注重细节的 SQL 专家。仔细检查 {dialect} 查询中的常见错误,包括:
- 使用 NULL 值的 NOT IN
- 在应该使用 UNION ALL 时使用 UNION
- 使用 BETWEEN 表示独占范围
- 数据类型不匹配
- 引号使用错误
- 函数参数数量错误
- JOIN 条件错误
如果发现错误,请修正后重新输出。
如果没有错误,直接输出原始 SQL。
"""
# LLM 绑定工具,强制调用
llm_with_tools = model.bind_tools(
[run_query_tool],
tool_choice={"type": "function", "function": {"name": "sql_db_query"}}
)
response = llm_with_tools.invoke(
[SystemMessage(content=check_query_system_prompt)] + state["messages"]
)
return {"messages": [response]}
4.5 循环执行流程
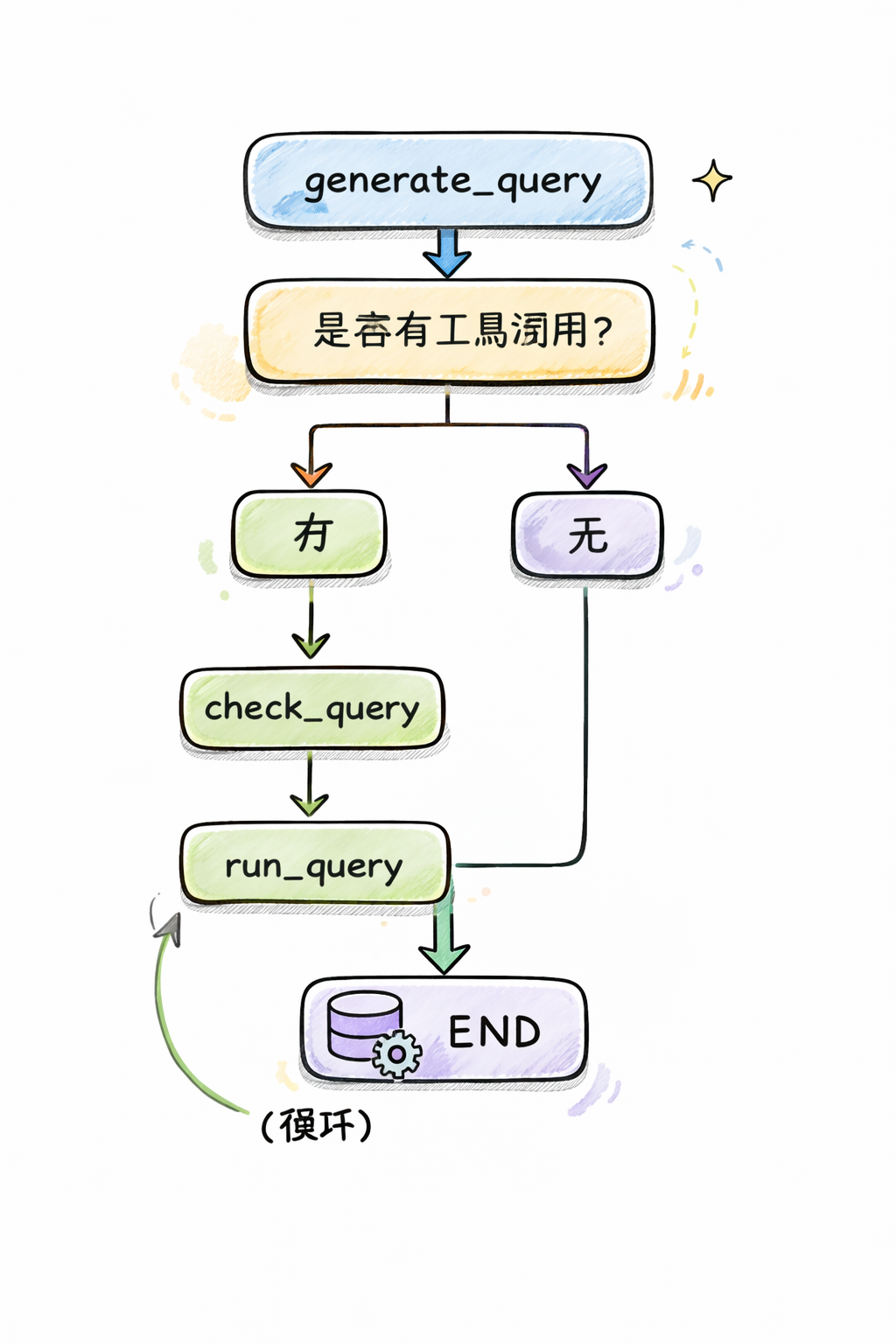
4.6 条件边配置
# src/agent/recommend.py
from typing import Literal
from langgraph.constants import START, END
from langgraph.graph import StateGraph
builder = StateGraph(RecommendState, context_schema=ContextSchema)
# 添加节点
builder.add_node(collect_user_info)
builder.add_node(list_tables)
builder.add_node(call_get_schema)
builder.add_node("get_schema", get_schema_node)
builder.add_node(generate_query)
builder.add_node(check_query)
builder.add_node("run_query", run_query_node)
# 添加边
builder.add_edge(START, "collect_user_info")
builder.add_edge("collect_user_info", "list_tables")
builder.add_edge("list_tables", "call_get_schema")
builder.add_edge("call_get_schema", "get_schema")
builder.add_edge("get_schema", "generate_query")
# 条件边:检查是否需要执行 SQL
def should_continue(state: RecommendState) -> Literal[END, "check_query"]:
"""
检查 LLM 是否有工具调用
- 有工具调用:继续检查并执行
- 无工具调用:结束流程
"""
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return END # LLM 不再调用工具,结束循环
else:
return "check_query" # 继续检查并执行
builder.add_conditional_edges(
"generate_query",
should_continue,
[END, "check_query"]
)
builder.add_edge("check_query", "run_query")
builder.add_edge("run_query", "generate_query")
# 编译图
recommend_graph = builder.compile()
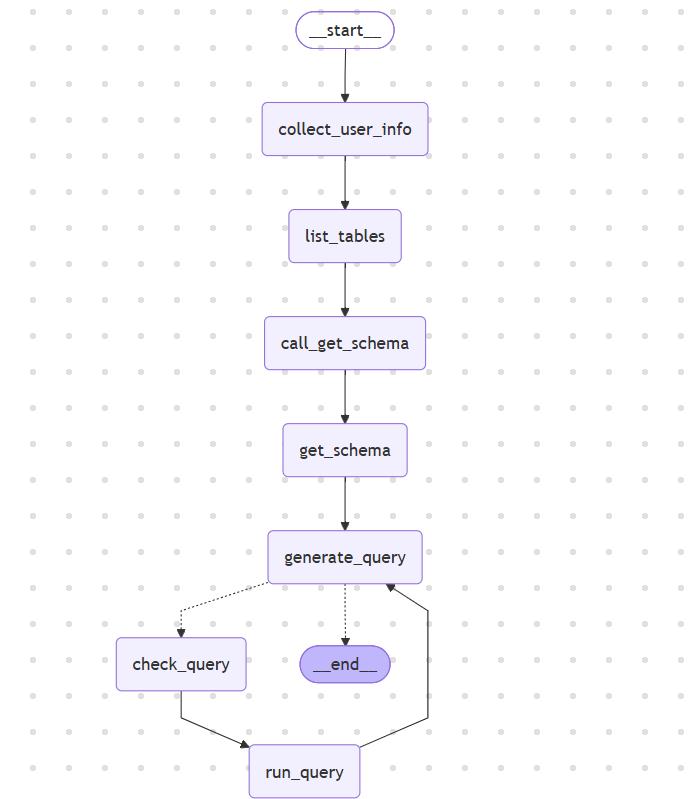
4.7 推荐子图 Mermaid 流程图
# 生成命令
print(recommend_graph.get_graph(xray=True).draw_mermaid())
五、完整代码与执行效果
5.1 recommend.py 完整代码
# src/agent/recommend.py
from typing import Literal
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from src.agent.common.context import ContextSchema
from src.agent.node.recommend import (
collect_user_info,
list_tables,
call_get_schema,
get_schema_node,
generate_query,
check_query,
run_query_node
)
from src.agent.state.recommend import RecommendState
# 构建图
builder = StateGraph(RecommendState, context_schema=ContextSchema)
# 添加节点
builder.add_node(collect_user_info) # 收集用户信息节点
builder.add_node(list_tables) # 调用 sql_db_list_tables 工具
builder.add_node(call_get_schema) # LLM 绑定 sql_db_schema 工具
builder.add_node("get_schema", get_schema_node) # sql_db_schema 工具
builder.add_node(generate_query) # LLM 绑定 sql_db_query 工具
builder.add_node(check_query) # LLM 绑定 sql_db_query 工具
builder.add_node("run_query", run_query_node) # sql_db_query 工具
# 添加边
builder.add_edge(START, "collect_user_info")
builder.add_edge("collect_user_info", "list_tables")
builder.add_edge("list_tables", "call_get_schema")
builder.add_edge("call_get_schema", "get_schema")
builder.add_edge("get_schema", "generate_query")
# 条件边
def should_continue(state: RecommendState) -> Literal[END, "check_query"]:
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return END
else:
return "check_query"
builder.add_conditional_edges(
"generate_query",
should_continue,
[END, "check_query"]
)
builder.add_edge("check_query", "run_query")
builder.add_edge("run_query", "generate_query")
# 编译图
recommend_graph = builder.compile()
5.2 执行效果展示
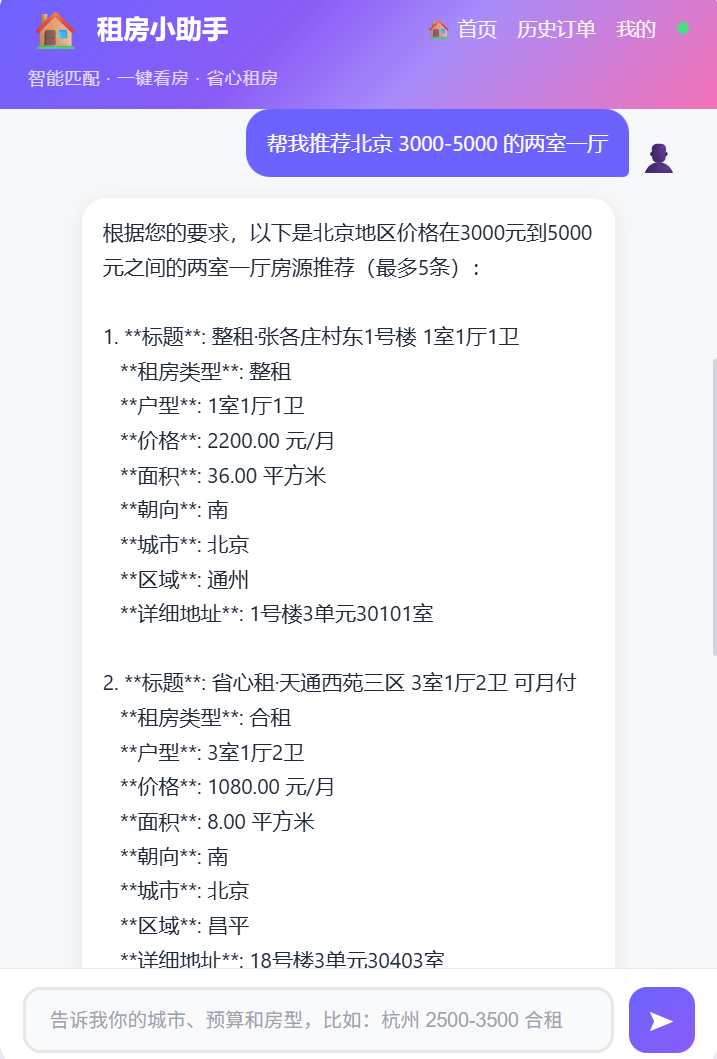
示例对话:
用户:帮我推荐北京 3000-5000 的两室一厅
助手:已收集用户信息: 城市=北京, 区域=None, 预算=3000-5000
根据您的需求,为您推荐以下房源:
1. 长安花园
- 价格:2800 元/月
- 户型:2室1厅
- 朝向:朝南
- 特点:精装修,近地铁
2. 翠苑小区
- 价格:3500 元/月
- 户型:2室1厅
- 朝向:南北通透
- 特点:交通便利,周边配套齐全
请问您是否需要预定这些房源?
六、本文总结
本文详细介绍了推荐子图的实现:
- 子图架构:收集信息 → 查询数据库 → 返回结果
- 用户信息收集:使用结构化输出提取租房需求
- SQLDatabaseToolkit:与数据库交互的工具包
- SQL 循环执行:生成 → 检查 → 执行的循环
- 完整代码:recommend.py 的完整实现
下一篇文章:
我们将深入探讨预定流程的实现,学习如何使用 interrupt 实现人工干预
本文是 House_Agent 实战系列的第二篇
如果觉得有帮助,欢迎点赞和分享!
咱们下篇再见~~~~


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 23
23 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)