长上下文不等于长记忆,这篇论文想把两件事拆开
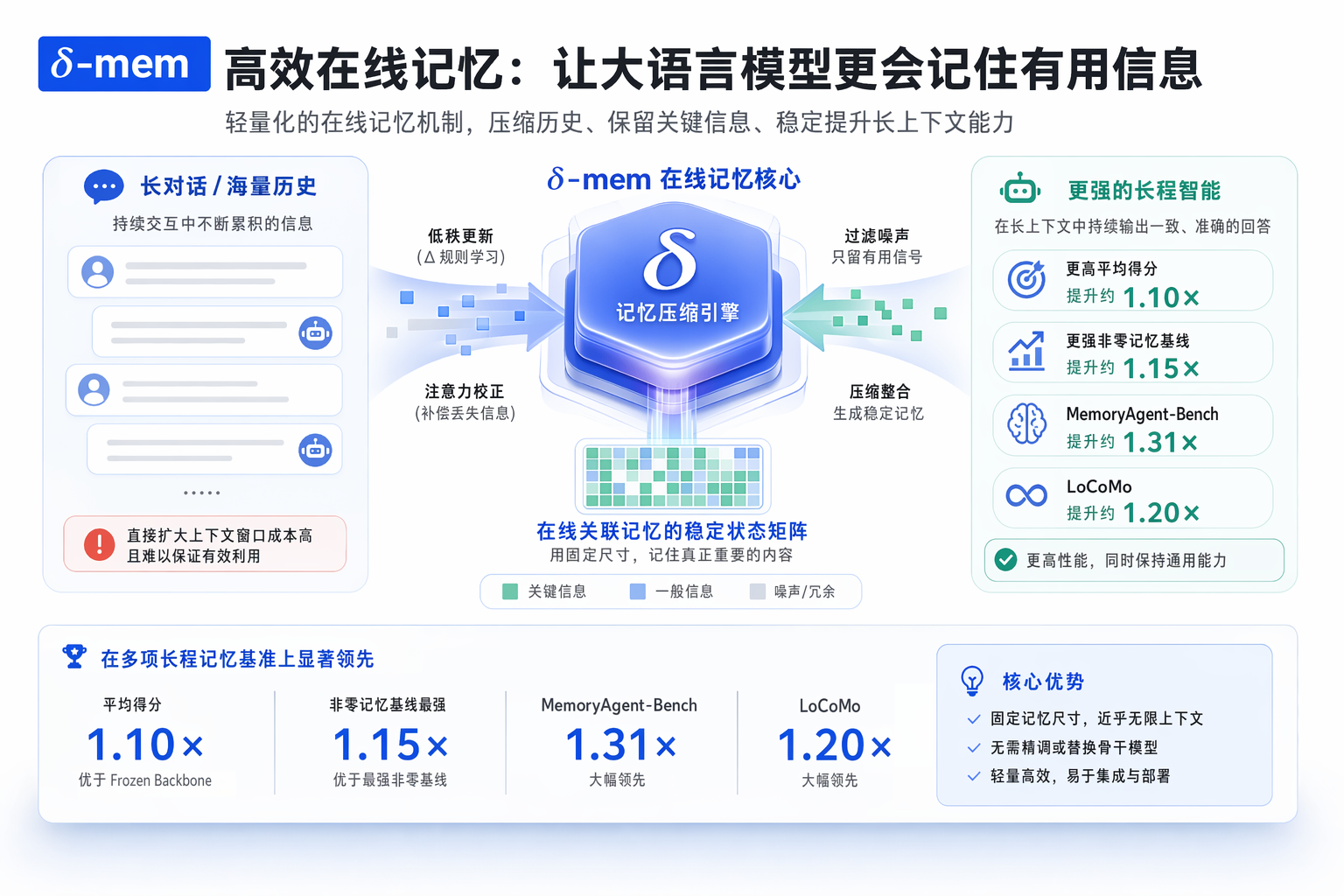
论文:$未$-mem: Efficient Online Memory for Large Language Models 原文:https://arxiv.org/abs/2605.12357 一句话先看懂:不给模型无限拉长上下文,而是外挂一个很小的在线记忆状态,试着把“记住什么”这件事做得更聪明。
一说到长记忆,很多人的第一反应还是,把上下文窗口继续拉长。
但你真做过长流程 agent 就会知道,窗口更长,不等于模型真的记得住,更不等于它会把历史里最重要的那部分拿出来用。未-mem 这篇论文,干的就是把这件事掰开。
论文速读
如果你没时间把原文从头看到尾,这篇 paper 其实可以按一条很清楚的线来抓。
前面先做一件很重要的事,把很多人平时混着说的两个概念拆开,长上下文解决的是模型能看到多少历史,长记忆解决的是模型看过之后,到底留下了什么、下次还能不能稳定调用。作者一上来就在纠这个地方,所以它不是单纯在卷窗口长度,而是在重新定义什么叫可用的记忆。
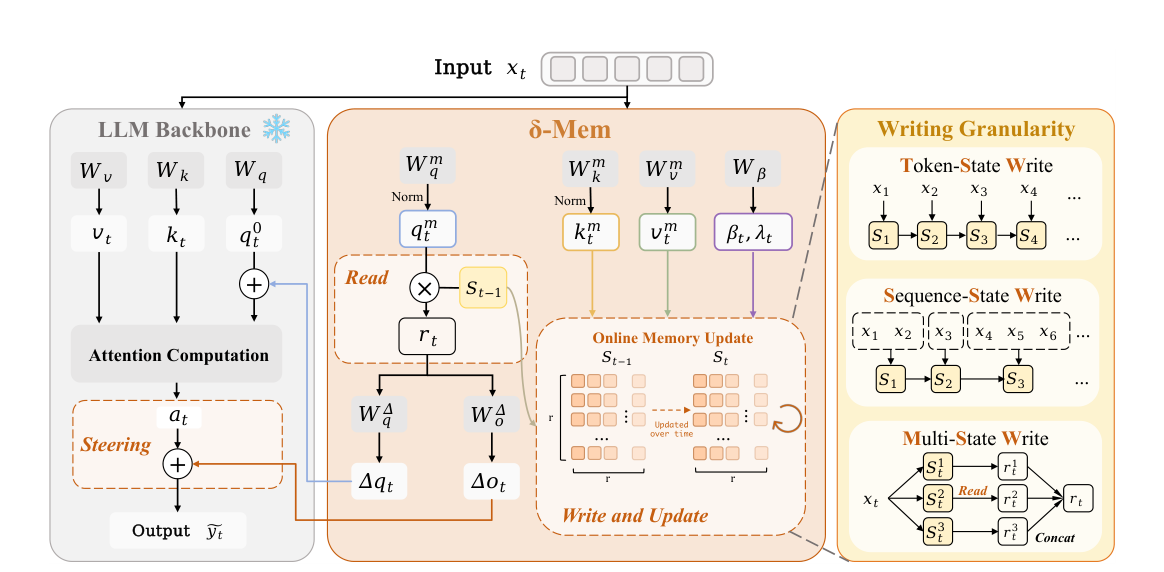
中间的方法部分也不绕,核心就是给冻结的主干模型外挂一个很小的在线状态,让历史信息不是继续平铺在上下文里,而是被压成一个能持续更新的记忆表示。你读这一段时,重点看三件事就够了,它怎么写进去,它怎么读出来,它又是怎么反过来影响后续 attention 的。
后半篇基本都是实验和消融。作者一边看记忆型任务到底有没有涨,一边看这种改法会不会把通用能力拉坏,还顺手去比较不同状态规模和写入策略。整篇论文的论证顺序其实很标准,先把问题定义清楚,再给最小改动的机制,最后拿实验去证明这不是概念包装,而是真的能在长程记忆任务里占到便宜。
所以它最后落下来的结论也很明确,别再把长上下文和长记忆当一回事了。如果你的目标是做长流程助手、持续对话 agent 或者长期协作系统,那记忆本身就值得被单独设计。
这篇论文到底解决了什么问题
上下文全塞进去,当然简单粗暴。
但这条路的问题,不只是贵。真正做过长流程助手的人都知道,历史越长,模型面前越像摊着一整桌资料。它不是没看见,而是看见了太多,于是最该抓住的那几根线,反而会被淹掉。
这也是为什么很多系统明明已经给了超长上下文,实际体验还是会飘。前面聊过的约束忘了,用户反复强调过的偏好掉了,关键决策点被后来的噪声覆盖了。你会发现,窗口长度解决的是装得下,解决不了记得准。
论文其实就在盯这个缝。作者想问的不是还能再塞多少 token,而是能不能把历史里真正有用、对下一步有影响的东西,压成一个持续存在的状态,而不是每一轮都重新从海量上下文里打捞。
所以它要拆开的,是两个经常被混着讲的概念。长上下文更像把材料都摆在桌上,长记忆更像你已经把材料看完,并且在脑子里留下了可调用的结论。这两件事,工程上不是一回事。
论文首页
它的方法,为什么值得看
这篇论文的做法很妙,它没有重改主干,也没有整模微调,而是在冻结的全注意力骨架旁边,外挂了一个很小的在线记忆状态。
过去的信息不再原样堆着,而是通过 delta-rule 一点点压进一个固定大小的状态矩阵里。后面模型继续做注意力计算时,这块状态不是旁观者,它会回过头来参与修正,让模型在当前步里读到一种被提炼过的历史。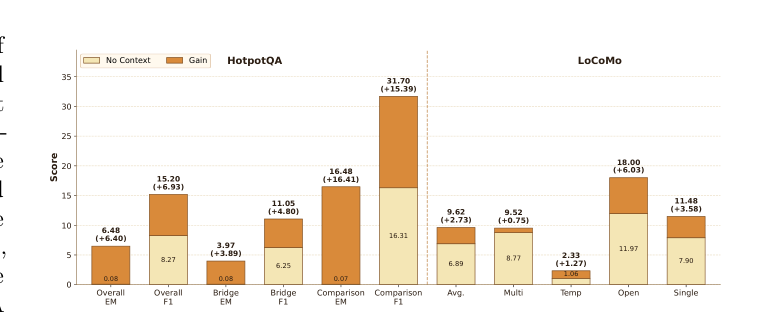
原论文图 Figure 2:Figure 2 Context recovery performance on HotpotQA and LoCoMo with Qwen3-4B-Instruct as the backbone.
这件事值钱的地方,不是又多了一个模块,而是它把记忆从文本堆积,改成了状态积累。以前你留住历史,靠的是把旧内容完整保留。现在你留住历史,靠的是把历史不断写成一个工作中的内隐状态。
你可以把它理解成,不再留一整仓库原始纸张,而是边看边记、边记边提炼,最后留下一个紧凑但能继续调用的工作记忆。这个比喻听起来很朴素,但它其实正好点中了 agent 记忆最缺的那一层。
而且作者还特意把改动压得很小。不是另起一套庞大记忆系统,也不是把 backbone 整个换掉,而是在尽量不破坏原模型通用能力的前提下,把在线记忆这件事单独拎出来做。这种克制,反而说明他们真抓住了问题。
这件事会怎么影响开发者和企业
论文里提到,这套方法只靠一个 8×8 的在线记忆状态,就能把平均分数拉到冻结骨干基线的 1.10 倍左右,在 MemoryAgentBench 这类任务上甚至能到 1.31 倍,同时又基本不伤通用能力。
这个结果为什么重要。因为它说明记忆增强不一定非得靠更大的窗、更贵的推理预算,或者把整套历史一遍遍带着走。有时候,真正缺的不是更多上下文,而是一个更像记忆的中间层。
对开发者来说,这个启发非常直接。以后做长流程助手、长会话客服、复杂工作流 agent,别默认只能在扩窗和检索里二选一。你完全可以把记忆当成单独的一层来设计,考虑它怎么写入、怎么压缩、怎么回读、怎么在多轮中保持稳定。
这篇论文其实也不是在否定检索。检索适合把外部知识找回来,记忆更适合把交互过程中沉淀出来的状态留下来。一个管找资料,一个管留痕迹,别再混成同一件事。
对企业来说,这意味着长记忆产品的成本结构还有很大优化空间。并不是所有历史都要原样背着走,真正值钱的是把对下一步有用的东西,稳定沉下来,而且能在权限、成本和时延都可控的条件下沉下来。
所以我会把这篇论文看成一个提醒,长上下文解决的是能看到多少,长记忆解决的是最后真正留下了什么。真要把这种能力接进企业工作流,后面很快就会碰到状态管理、回放、权限隔离、长期存储和成本控制。那个阶段,单个模型已经不是全部,系统层才是真正的主战场。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)