OpenHuman 两日破万星背后:AI Agent 开箱即用、本地记忆、隐私安全与个人数字分身全解析

导读:过去两年,AI Agent 的主线是“让模型学会调用工具”;现在,新的竞争焦点正在转向“让 Agent 真正懂你、记住你、保护你,并在你没开口时提前准备”。OpenHuman 的热度之所以能迅速爆发,不只是因为它会聊天,而是因为它把个人 AI 的四个痛点:部署、记忆、成本、隐私,做成了一套可感知的产品体验。
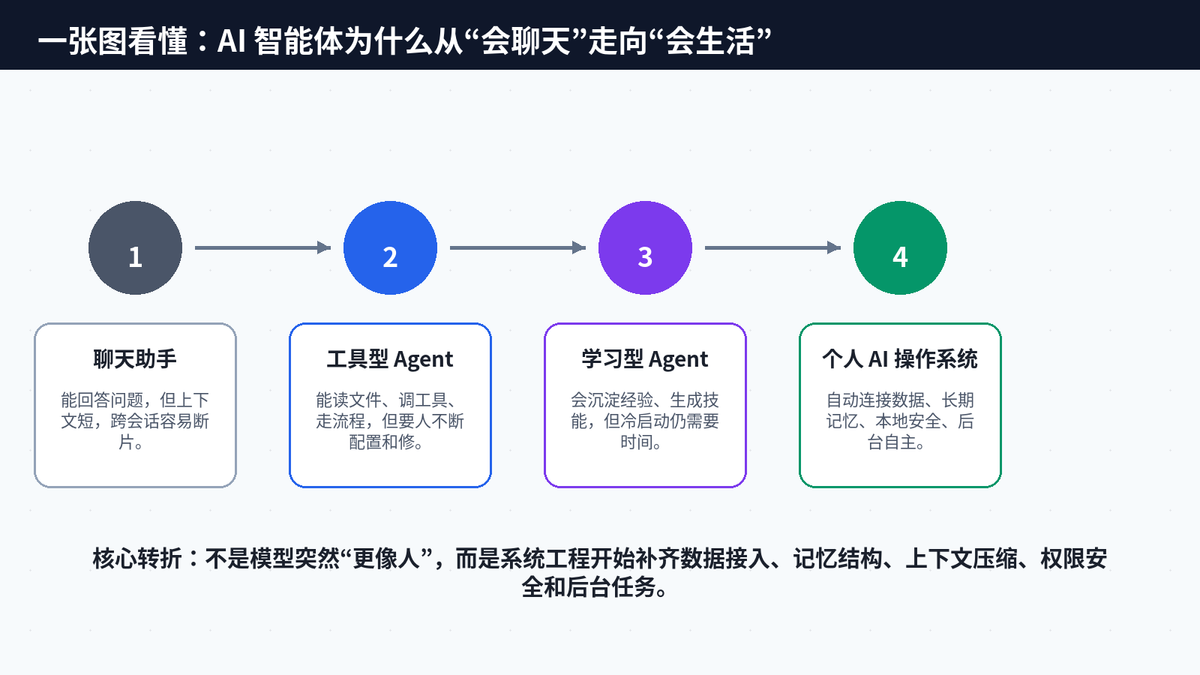
一、开篇:AI Agent 的竞争,正在从“谁更聪明”变成“谁更懂我”
2026 年开源 AI 智能体赛道最大的变化,不是突然多了一个聊天机器人,而是个人 AI 的底层逻辑变了。过去大家追求的是插件数量、模型能力、工具调用、自动化脚本;现在真正能打动用户的,是一个更朴素的问题:这个 AI 能不能像真正的个人助手一样,知道我的邮件、日历、文档、项目、偏好、习惯,并且在我第二天打开电脑时,仍然记得昨天发生过什么。
这也是 OpenHuman 迅速被讨论的原因。它的定位不是传统的“万能工作流网关”,也不是单纯依靠长期训练慢慢进化的学习型 Agent,而是把个人数据连接、长期记忆、本地知识库、Token 压缩、隐私安全、桌面交互、后台自主任务打包成一个更接近“个人 AI 操作系统”的产品形态。
从公开资料看,OpenHuman 官方仓库把自己定义为“Personal AI super intelligence”,强调私有、简单、强大;官方 README 明确写到,它支持 118+ 第三方集成、20 分钟自动同步、Memory Tree + Obsidian Wiki、TokenJuice 压缩、本地加密与桌面体验。也就是说,它真正的卖点不是“又一个 Agent”,而是“把 Agent 的养成成本前置消化掉”。
二、为什么 OpenClaw、Hermes 之后,用户还在等一个新答案?
OpenClaw 和 Hermes 代表了两种很典型的开源 Agent 路线。OpenClaw 更像“广度型网关”:它能连很多渠道,适合消息平台、企业流程、插件生态和自动化调度。公开资料显示,OpenClaw 支持 WhatsApp、Telegram、Slack、Discord、飞书、LINE、WeChat、QQ 等大量通道,Gateway 是它的控制平面。
Hermes 更像“深度型学习者”:它强调内置学习闭环,会从经验里创建技能、在使用中改进技能、提醒自己保存知识,并通过历史会话搜索形成更深的用户模型。官方仓库中也明确强调,它可以运行在 VPS、GPU 集群、Serverless 环境里,不局限于本地电脑。
这两个方向都很重要,但它们没有完全解决普通用户最直接的焦虑:上手太复杂、记忆不连续、维护太累、隐私不确定、成本不可控。技术玩家可以接受“调密钥、写配置、看日志、修工作流”,普通人不行。
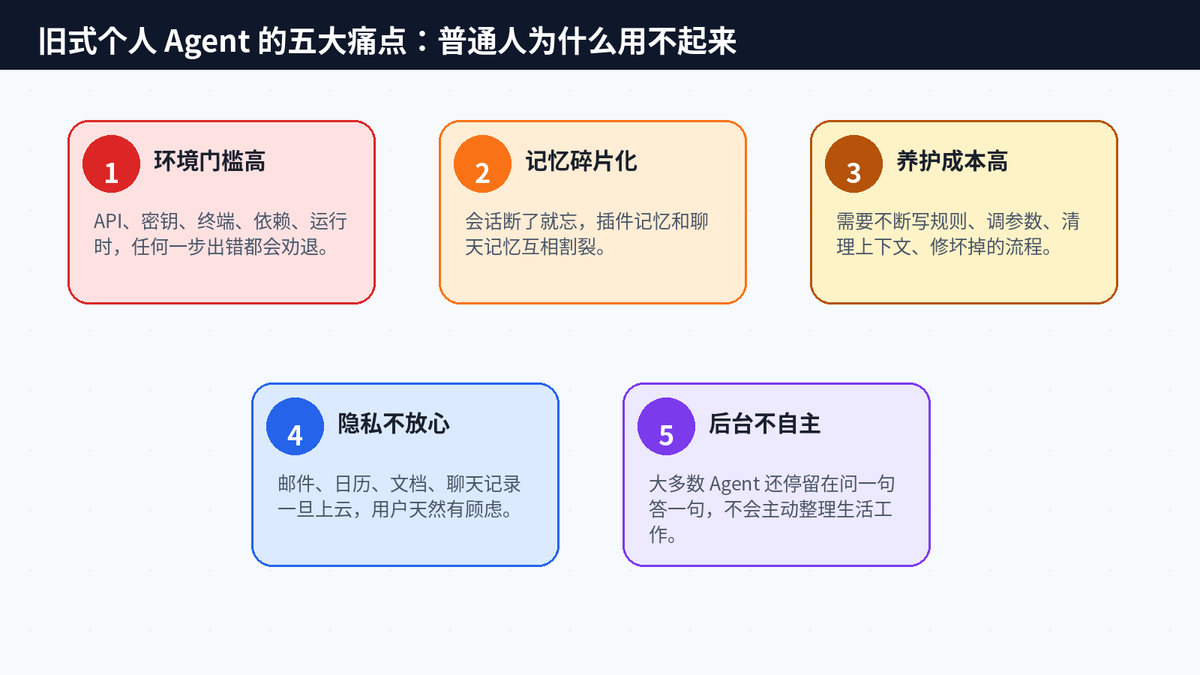
三、OpenHuman 的核心变化:不是让用户养 AI,而是让 AI 自动长出上下文
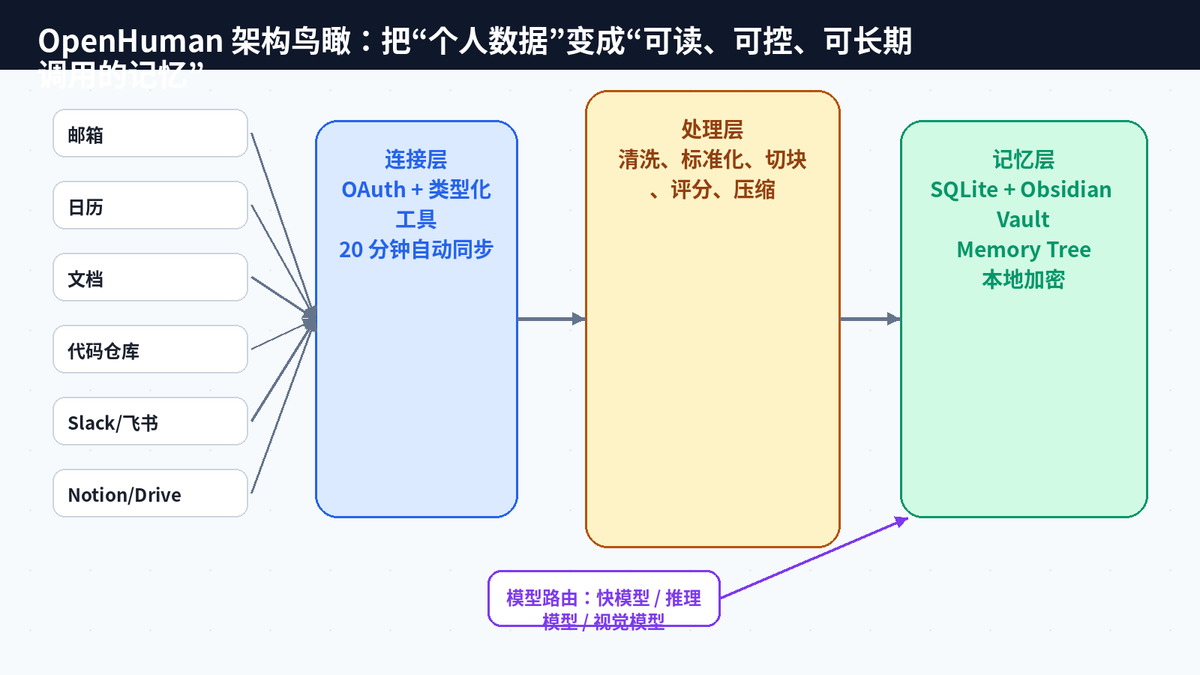
过去很多 Agent 都有一个默认假设:用户愿意持续投喂、持续配置、持续维护。可是绝大多数真实用户只想打开软件,点几下授权,然后让 AI 自己开始理解工作和生活。OpenHuman 把这个逻辑反过来了:用户不再负责“养 AI”,系统自己负责捕获上下文、清洗数据、压缩成本、组织记忆。
这种变化可以概括为一句话:从“Prompt 驱动”升级到“个人上下文驱动”。Prompt 仍然重要,但它不再是唯一入口。邮件、日程、会议、代码、文档、聊天记录、项目进展,都会进入一个自动整理的记忆系统。用户真正得到的不是一个会聊天的窗口,而是一个逐渐同步自己生活和工作的私人数据大脑。
四、第一大技术点:118+ 集成与 20 分钟自动同步,让上下文不再靠手动输入
OpenHuman 的第一个关键点,是把“连接数据”做成了默认能力。官方资料提到,它通过 OAuth 方式连接 Gmail、Notion、GitHub、Slack、Stripe、Calendar、Drive、Linear、Jira 等服务,并把每个连接暴露为类型化工具。更关键的是,它不是等用户每次手动触发,而是按周期自动抓取新数据。
这一步看起来只是“多接几个服务”,但对 Agent 体验影响非常大。传统聊天式 AI 只有当前对话;工具型 Agent 只有你主动调用时才拿到信息;OpenHuman 这类设计则让个人上下文持续刷新。今天早上它就已经知道你昨晚的新邮件、今天的日程、最近的代码提交和文档变化。
通俗理解:以前你每次问 AI,都像重新给新人介绍项目背景;现在它先把你的资料柜整理好,等你问的时候,直接从整理好的档案里找答案。
对普通用户:不用写脚本,不用手动导入资料,不用每次重复交代背景。
对开发者:项目文档、Issue、PR、提交记录可以自然进入上下文。
对企业用户:如果后续加入权限、审计、审批机制,这类同步系统可以成为知识治理入口。
五、第二大技术点:Memory Tree,把“记住”从玄学变成工程结构
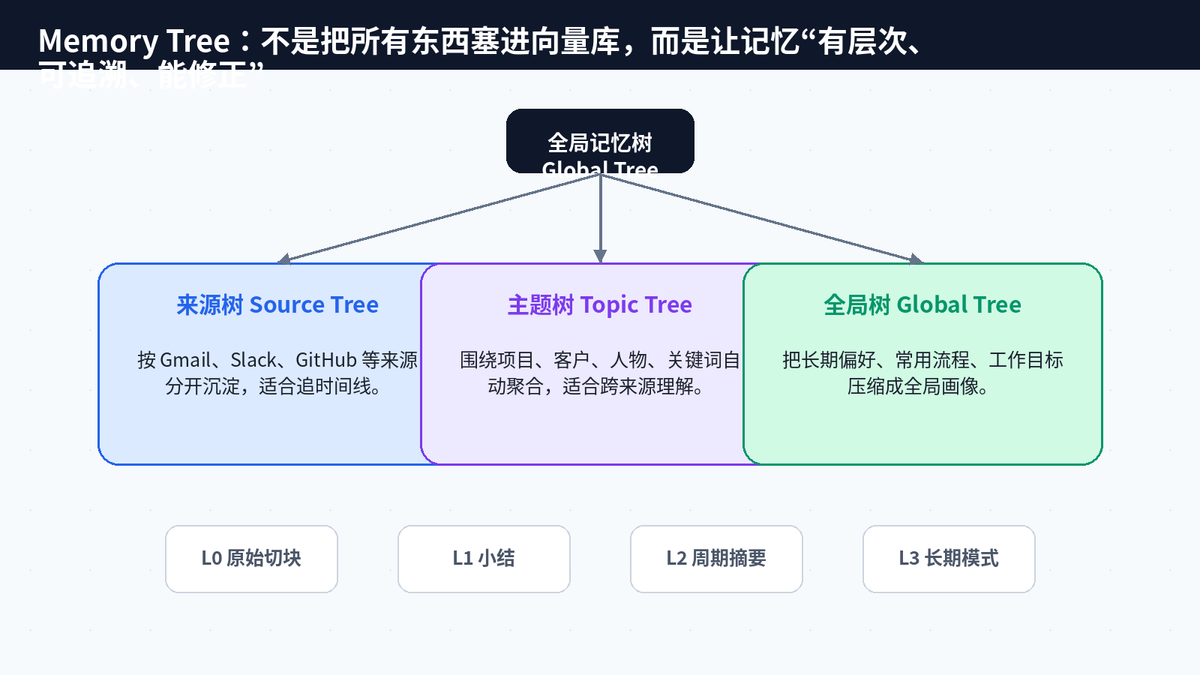
很多 AI 产品都说自己有记忆,但“有记忆”并不等于“记得好”。如果只是把对话塞进数据库,或者把碎片丢进向量库,时间一长就会出现三个问题:噪音越来越多、来源不可追溯、用户很难纠错。
OpenHuman 的 Memory Tree 思路更接近“可读的个人知识库”。根据官方 README,接入的数据会被标准化为不超过约 3000 token 的 Markdown 切块,然后打分,并折叠进层级摘要树,存放在本机 SQLite 中;同样的切块还会落入 Obsidian 兼容的 vault,用户可以直接打开、浏览、修改。
这套设计的好处在于:AI 的记忆不是一个看不见的黑盒,而是一个用户可以检查和修正的知识库。AI 记错了项目背景,用户可以去 Markdown 里改;AI 混淆了某个客户,用户也可以直接找到对应材料修正。这比“模型说它记住了”更值得信任。
来源树:按邮箱、Slack、GitHub、Drive 等来源组织,适合追溯某条线索从哪里来。
主题树:围绕项目、客户、人物、关键词聚合,适合跨来源理解。
全局树:沉淀长期偏好、工作习惯、重要目标,形成个人长期画像。
六、第三大技术点:TokenJuice,真正解决“记忆越多越贵”的问题
个人 AI 最大的隐藏成本,是上下文。邮件、文档、网页、聊天记录、代码差异,只要原封不动塞进模型,成本和延迟都会迅速上涨。很多 Agent 不是能力不强,而是跑起来太贵、太慢、太不稳定。
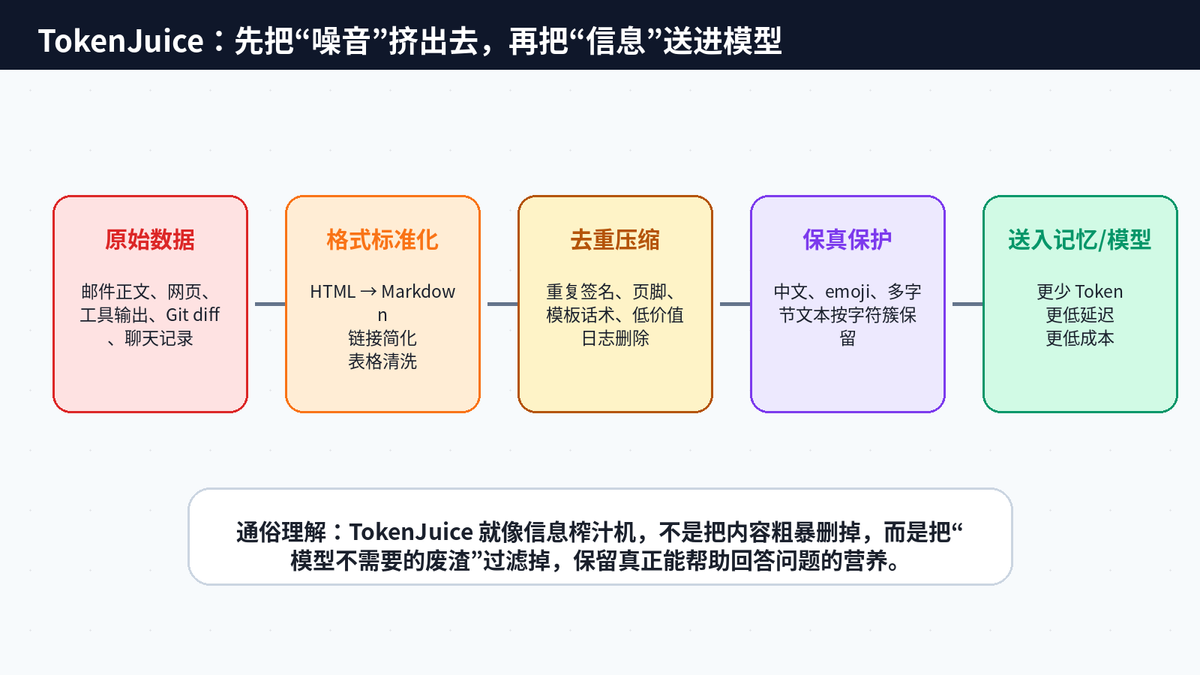
OpenHuman 提到的 TokenJuice,本质就是在信息进入大模型之前做一层“压缩与保真”。它会把 HTML 转成 Markdown,简化长链接,去掉重复页脚、模板噪音和冗余工具输出,同时保留中文、emoji、多字节字符等关键信息。官方资料中提到,这能把成本和延迟最多降低 80%。
用一个生活化比喻:把 200 封邮件直接扔给模型,就像把整袋水果连皮带核倒进榨汁机;TokenJuice 做的是先洗净、去皮、去核、切块,再把真正有营养的信息送进去。不是粗暴删除,而是减少无意义消耗。
七、第四大技术点:本地优先与可读知识库,隐私安全不再只是口号
个人 AI 迟迟难以大众化,一个核心原因是隐私。邮箱、日历、聊天记录、文档、代码仓库,这些都是最敏感的个人数据。如果用户不确定数据去了哪里、能否删除、是否被训练,任何“懂你”的产品都会让人不安。
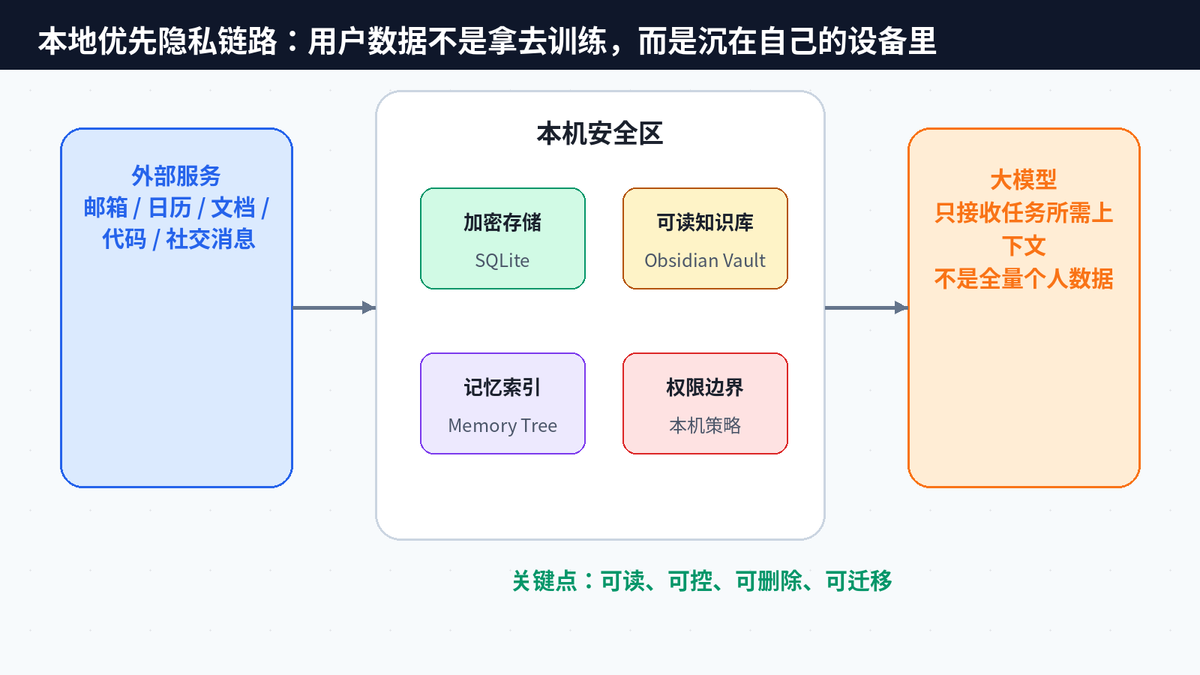
OpenHuman 的本地优先思路,是把工作流数据留在设备上,进行本地加密,并以用户可理解的形式保存。SQLite 负责结构化存储,Obsidian 兼容 vault 负责可读可编辑的知识文件。这个设计非常重要,因为它让用户从“相信平台不会乱用”变成“我能看见、能修改、能删除”。
隐私安全并不是不联网,而是把数据边界讲清楚:哪些数据在本地、哪些上下文会发给模型、哪些连接器需要授权、哪些数据可以随时撤回。一个真正的个人 AI 分身,必须先让用户敢把长期数据交给它。
八、第五大技术点:后台自主运行,让 Agent 从“被动问答”走向“主动助手”
如果一个 AI 只有在用户提问时才工作,它更像一个高级搜索框;如果它能在后台整理数据、同步日程、发现待办、准备材料、生成提醒,它才开始接近真正的助手。
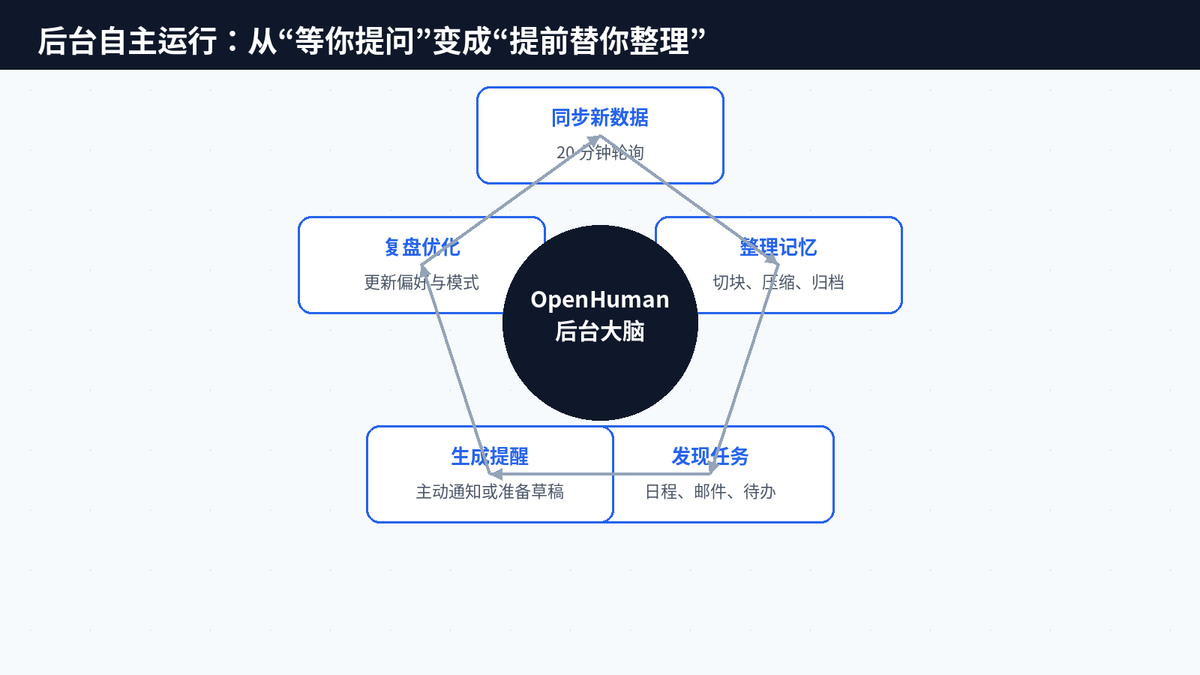
OpenHuman 在公开说明中强调,它会保持后台思考与自动抓取能力。用户停止输入之后,系统仍然可以继续同步新数据、整理记忆、准备明天的上下文。这个方向非常重要,因为个人 AI 的价值不只是“回答快”,而是“提前准备”。
比如第二天早上,你不是问“昨天客户说了什么”,而是打开电脑就看到系统已经整理好邮件、会议、代码变更和待处理事项;你不是让它从零开始写周报,而是它已经把一周里值得写的内容提取出来。
九、OpenHuman、OpenClaw、Hermes 的真实差异:三条路线,不是简单替代
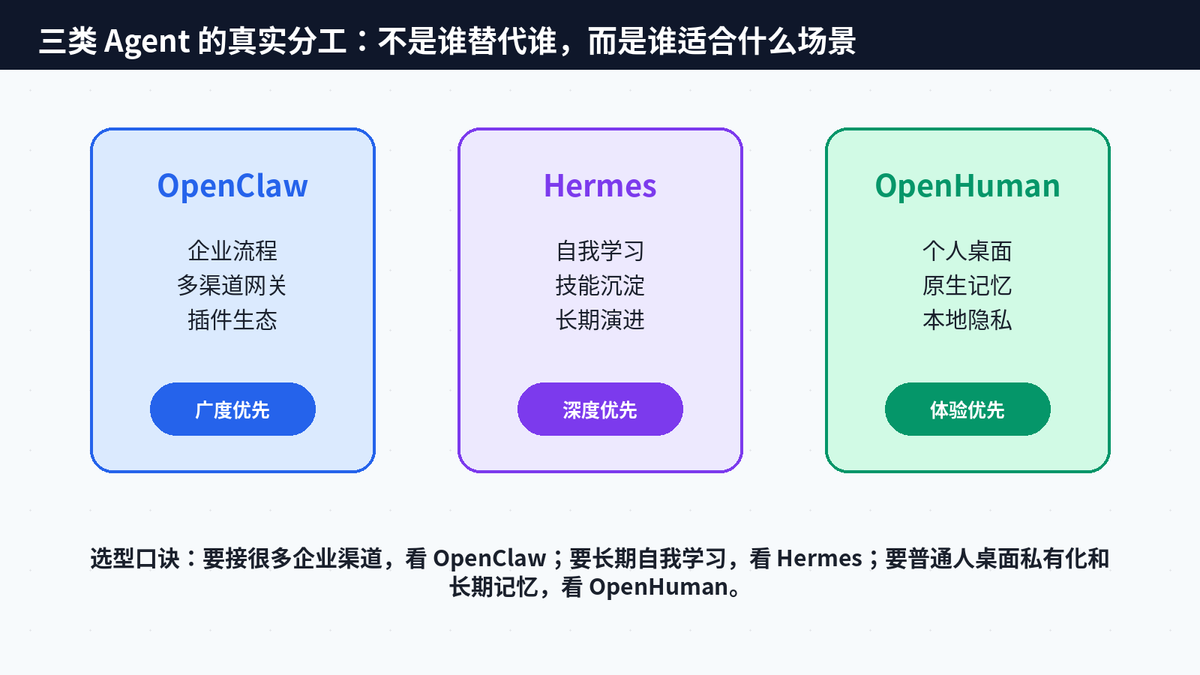
很多爆款文章喜欢把新项目写成“彻底碾压前代”,但从工程视角看,更准确的判断是:三类项目解决的问题不同。OpenClaw 的优势是广度,适合企业多渠道、多插件、多流程调度;Hermes 的优势是自我学习和技能演进,适合长周期任务与复杂自动化;OpenHuman 的优势是个人场景开箱即用、本地记忆和桌面体验。
这也解释了为什么 OpenHuman 会突然吸引很多普通用户:它没有要求用户先成为开发者。它把“连接数据、压缩信息、保存记忆、同步上下文”做成默认流程,把复杂工程藏在简单体验背后。
十、横向对比:三款 Agent 更适合谁?
|
维度 |
OpenClaw |
Hermes |
OpenHuman |
|
核心定位 |
多渠道网关与企业流程调度 |
自我学习、技能沉淀、长期演进 |
个人桌面、原生记忆、本地隐私 |
|
上手体验 |
偏技术化,依赖配置和渠道接入 |
偏工程化,适合长任务和云端运行 |
UI 优先,强调几分钟内开始使用 |
|
记忆路线 |
依赖配置、插件和本地记忆文件 |
学习闭环、技能库和历史会话搜索 |
Memory Tree + Obsidian Wiki + 本地 SQLite |
|
集成方式 |
多消息平台和插件生态 |
多模型、多后端、多消息通道 |
118+ OAuth 集成 + 自动抓取 |
|
隐私关注点 |
插件与网关权限需要谨慎治理 |
云端部署和多后端需要审计 |
本地优先、加密、可读 vault |
|
适合人群 |
企业自动化、技术玩家、多平台运营者 |
重度开发者、自动化团队、长周期任务用户 |
普通个人用户、知识工作者、需要个人数字分身的人 |
注意:GitHub star、插件数量、故障率等数字会随时间变化,传播素材中的历史速度更适合作为热度线索,不宜当成永久固定事实。写技术文章时,应把“可验证能力”和“传播叙事”分开处理。
十一、为什么“开箱即用”会成为 Agent 的下一个战场?
AI Agent 过去的增长主要来自技术人:程序员愿意忍受命令行,愿意配置模型,愿意研究插件,愿意看报错日志。但个人 AI 真正要走向大众,必须跨过一个门槛:普通人不会养系统,只会用产品。
OpenHuman 的爆发,说明用户正在用脚投票。大家并不是不需要 Agent,而是不想再折腾 Agent。谁能把部署、授权、记忆、压缩、隐私、安全、后台任务都做成“默认体验”,谁就更可能进入普通人的日常工作流。
这和智能手机早期很像。技术玩家关心参数,普通人关心能不能拍照、导航、发消息、付钱。AI Agent 也是如此,最后决定普及的不是底层多复杂,而是用户第一次打开时能不能马上感受到它有用。
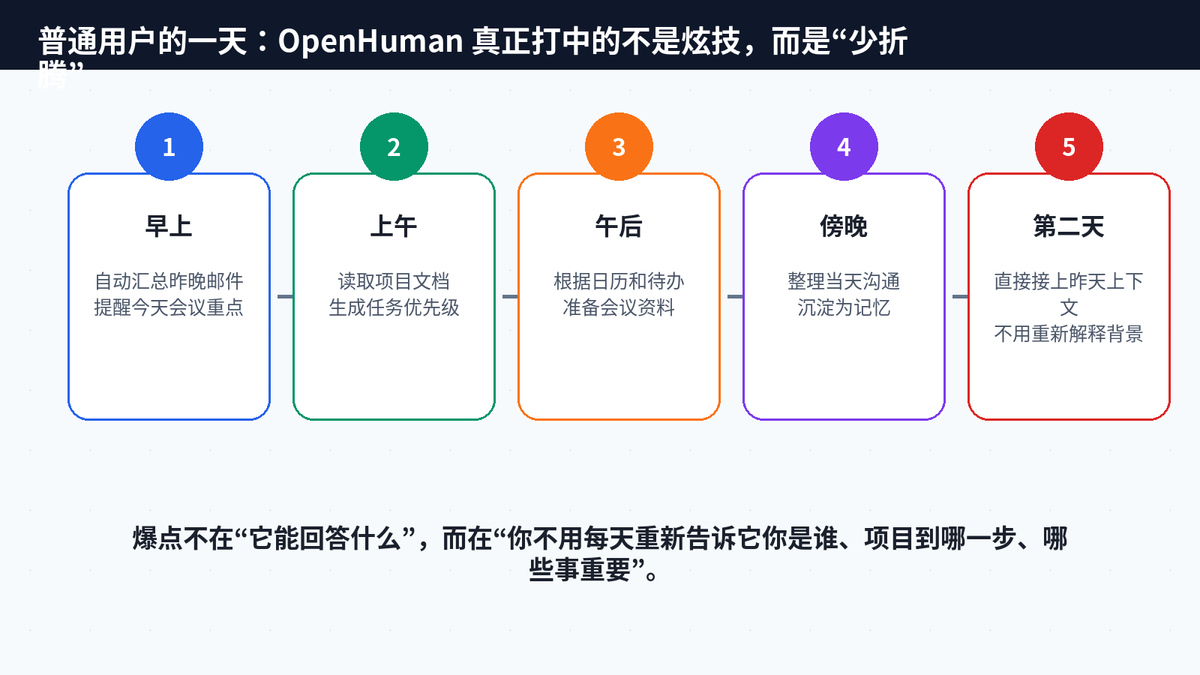
十二、从工程角度看,OpenHuman 背后的六层能力栈
如果把 OpenHuman 拆开,它并不是单点创新,而是一组工程能力的叠加。桌面 UI 解决进入门槛;OAuth 集成解决数据接入;TokenJuice 解决成本;Memory Tree 解决长期记忆;本地加密解决信任;后台自主任务解决主动性。
这六层能力任何一层缺失,产品体验都会塌。只有 UI,没有记忆,就只是好看的聊天窗口;只有记忆,没有压缩,就会越来越贵;只有自动化,没有隐私边界,用户不敢授权;只有插件,没有本地知识库,就难以形成个人长期上下文。
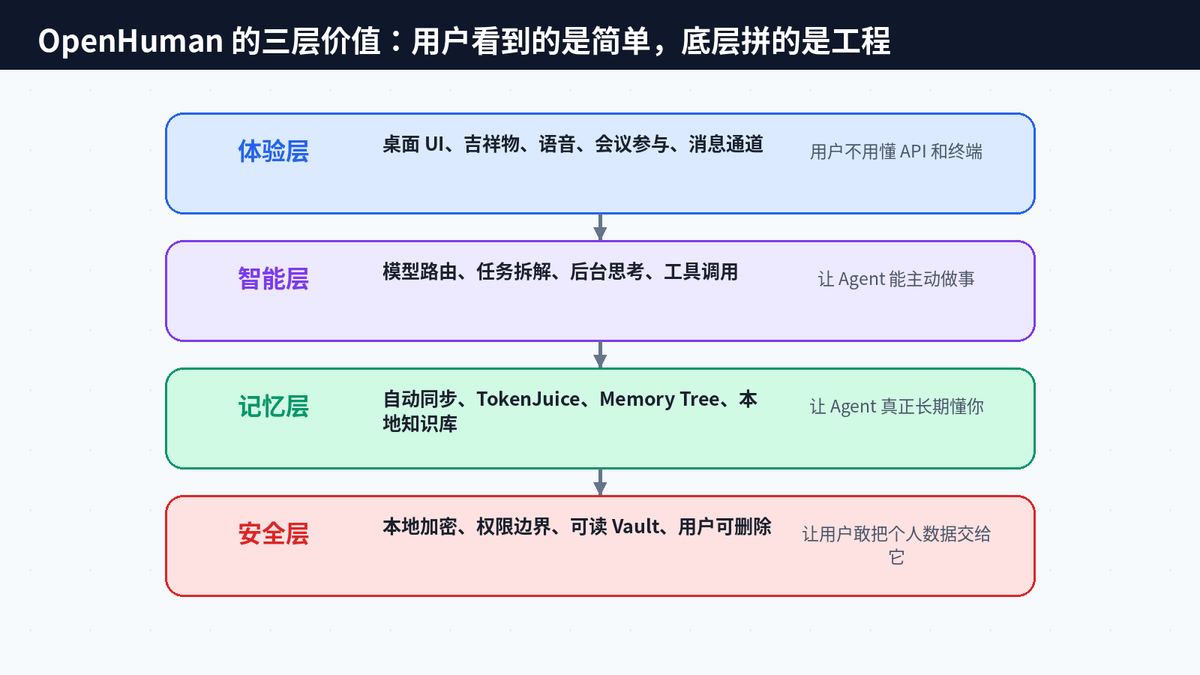
十三、不能只吹爆火:OpenHuman 仍然有几道必须跨过的坎
越是个人化的 AI,越不能只看热度。OpenHuman 的方向很有想象力,但也有明显挑战。第一,连接 118+ 服务意味着权限边界必须非常清楚;第二,自动抓取数据意味着同步策略、去重策略、错误恢复都要稳定;第三,长期记忆意味着纠错机制必须简单,否则 AI 记错比 AI 忘记更麻烦。
第四,本地优先并不等于绝对安全。本地数据库、知识库、桌面应用、OAuth Token、插件调用,都需要权限隔离、加密、审计和备份机制。第五,后台自主运行也不是越主动越好,用户需要知道它什么时候做了什么、为什么做、能不能撤回。
所以,真正成熟的个人 AI 分身,不只是会帮你做事,还要让你能控制它、理解它、纠正它、关闭它。
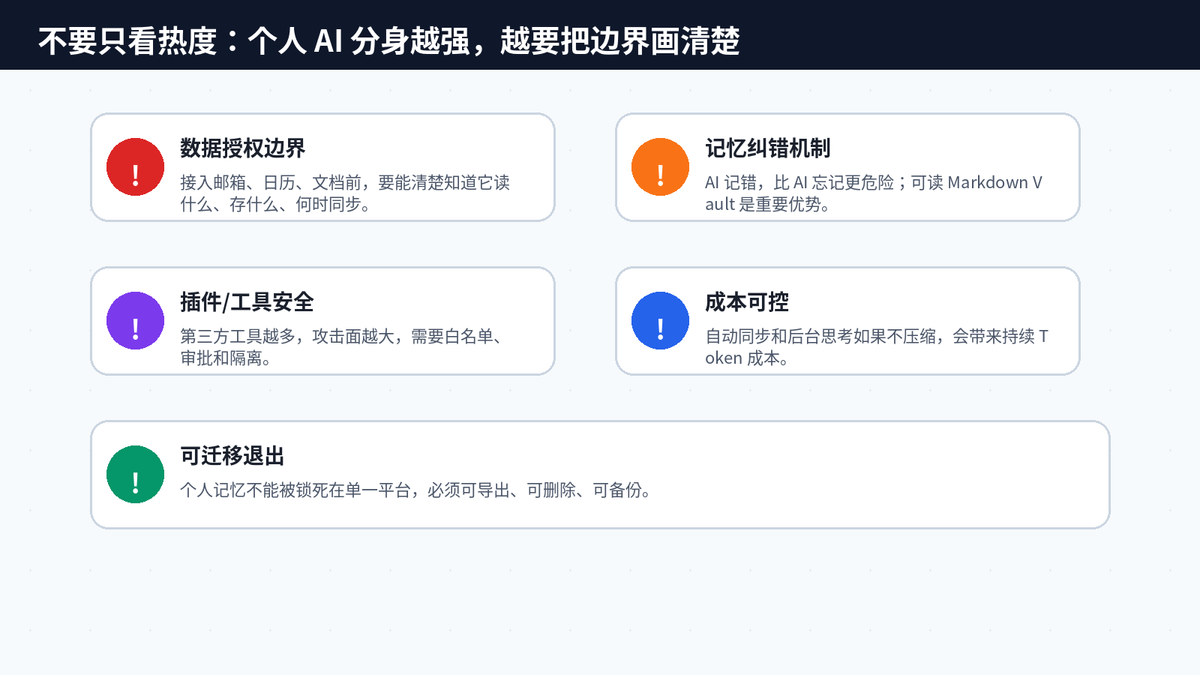
十四、未来判断:开源 Agent 赛道会分成三条主线
第一条主线是企业流程型 Agent。它们继续强化多渠道接入、插件市场、权限审批、审计、任务编排,核心竞争力是“能接多少系统、能稳定跑多少流程”。OpenClaw 这类项目更接近这个方向。
第二条主线是自我进化型 Agent。它们重视技能生成、经验复盘、长期自动化、云端运行、多模型调度,核心竞争力是“越用越会做复杂任务”。Hermes 这类项目更接近这个方向。
第三条主线是个人数字分身型 Agent。它们重视本地记忆、桌面体验、隐私安全、低门槛接入、后台整理,核心竞争力是“越用越懂你,而且你能掌控它”。OpenHuman 正在押注这个方向。
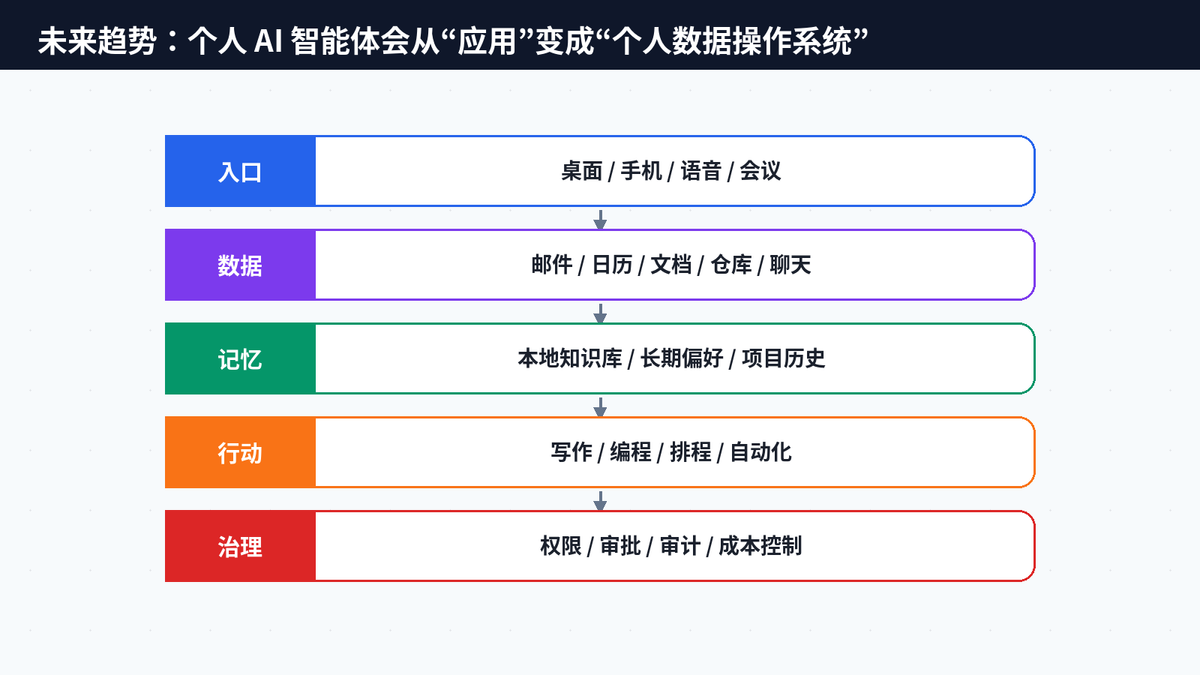
十五、结尾总结:OpenHuman 的意义,是让个人 AI 从“玩具”变成“生活系统”
OpenHuman 的走红,不应该简单理解成又一个开源项目爆火。它真正代表的是个人 AI Agent 的产品逻辑正在改变:过去比谁插件多、谁模型强、谁自动化更猛;现在开始比谁更容易上手、谁更懂个人上下文、谁更尊重隐私、谁更能长期稳定地融入日常生活。
OpenClaw 证明了多渠道网关和插件生态的价值,Hermes 证明了学习闭环和技能进化的价值,OpenHuman 则把问题推向了更大众的一侧:普通人能不能不折腾、不养成、不反复解释背景,也拥有一个真正懂自己的 AI 伙伴。
如果说上一代 Agent 是技术玩家的自动化玩具,那么下一代 Agent 就会成为每个人的第二大脑、私人秘书、知识管家和工作分身。OpenHuman 是否能长期领先还需要时间检验,但它已经非常清楚地指出了一个方向:未来的 AI,不只是回答你的问题,而是持续理解你的生活。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)