基于LeRobot的SO100 机械臂模仿学习抓取项目
项目结果展示
下面的视频展示了训练后的 ACT 策略在 SO100 机械臂上的真机 rollout 效果。机械臂不再由人手控制,而是根据相机图像和自身关节状态,由模型直接输出动作序列完成抓取任务。
视频如下:
最终成功抓取
这个项目的目标不是单纯跑通一个模型,而是完整打通机器人模仿学习的工程闭环:从人类示教采集数据,到 LeRobot 数据集构建,再到 ACT 策略训练,最后部署到 SO100 真机上进行 rollout 测试。
项目背景
传统机械臂抓取任务通常会被拆成几个模块:目标检测、位姿估计、运动规划、轨迹执行和夹爪控制。对于规则明确、物体种类少、环境固定的场景,这种方法非常有效。例如,如果目标物体位置已知,只需要通过视觉系统估计物体中心点,再规划一条从当前位姿到抓取位姿的轨迹即可。
但这种方法也有明显的问题:当任务需要连续调整动作,或者视觉、接触、夹爪状态之间存在复杂耦合时,人工设计规则会变得越来越困难。比如机械臂抓取一个小物体时,不仅需要知道物体在哪里,还需要在靠近、闭合夹爪、抬起、放置等连续动作中保持稳定。如果每一步都手写规则,系统会变得复杂,而且泛化能力有限,这也是我上一个项目存在的问题,详情可以查看我上一个项目。
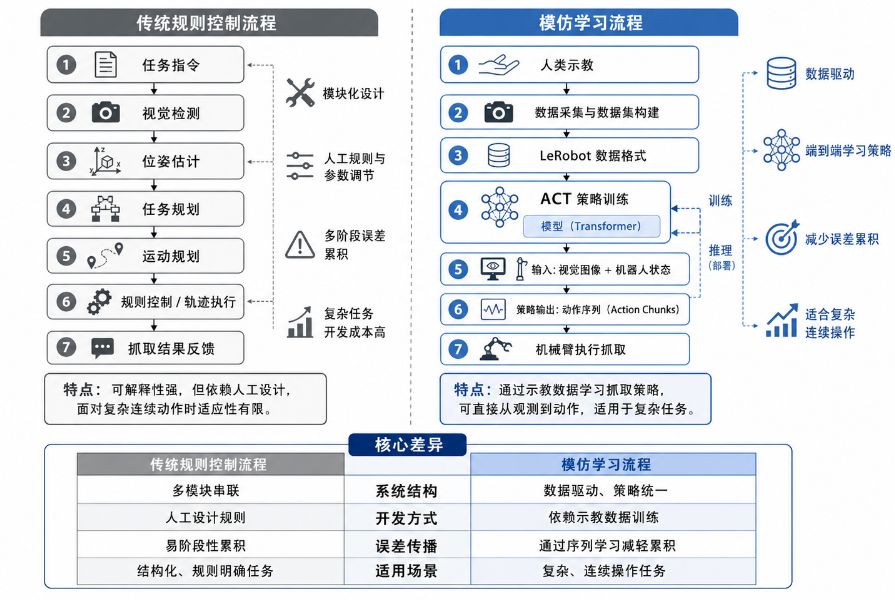
图1:传统规则控制流程VS模仿学习流程
因此,本项目尝试使用模仿学习方法。核心思路是:不再手动设计每一步抓取规则,而是通过人类示教数据,让模型学习“看到什么状态时应该怎么动”。模型输入相机图像和机械臂自身状态,输出未来一段时间的动作序列,从而控制机械臂完成抓取和放置任务。
项目简介
本项目选择 LeRobot 作为机器人学习框架,主要原因是它提供了比较标准化的数据采集、数据管理、模型训练和评估流程。
项目链接:https://github.com/huggingface/lerobot对于模仿学习项目来说,数据格式非常重要。如果自己从零设计数据结构,需要处理 episode、视频、状态、动作、metadata 等多个部分,工作量较大,也不利于后续复现实验。
LeRobot 可以将机器人示教数据整理为 episodes、videos、metadata,使数据采集和训练流程更加清晰。模型方面,本项目使用 ACT,也就是 Action Chunking Transformer。ACT 的特点是一次预测未来一段动作序列,而不是只预测下一步动作。对于机械臂抓取这种连续控制任务,action chunking 可以让动作更加平滑,也能减少单步预测带来的误差累计。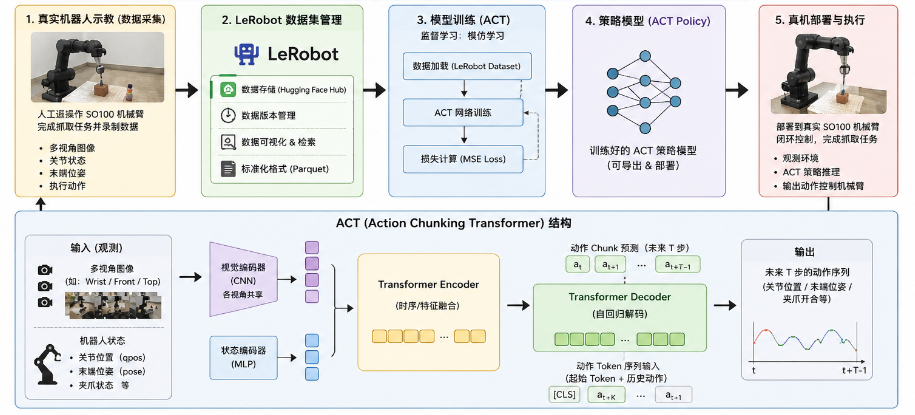
图2:LeRobot + ACT 整体架构图
模仿学习简介
模仿学习的核心思想是让模型从专家示教数据中学习策略。在本项目中,专家就是人类操作者,示教数据就是人类通过主臂操作机械臂完成抓取任务时记录下来的轨迹。最直接的模仿学习方法是行为克隆,也就是 Behavior Cloning(BC)。行为克隆可以理解为监督学习:给定专家示教中的状态和动作,模型学习从状态到动作的映射。
在机械臂任务中,过程可以理解为:当前相机图像 + 当前关节状态 + 当前夹爪状态 → 专家动作
行为克隆的优点是简单直接,适合真实机器人数据量有限的场景。但它也存在一个典型问题:分布偏移。训练时模型看到的是专家产生的状态分布,测试时模型看到的是自己执行动作后产生的状态分布。一旦某一步动作预测出现偏差,机械臂就可能进入专家示教数据中没有出现过的状态,后续错误会继续累积,这就是复合误差问题。
训练时看到的是专家产生的状态分布,测试时看到的是自己产生的状态分布,这两个分布不一样,一旦模型那一步出错了,它就会进入专家从来没去过的状态,于是错误不断积累
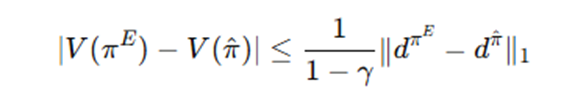
如果你学到的策略导致访问分布偏离专家很多,那么价值就会差很多
![]()
在专家分布上,你每一步平均只错 ε,但是还存在一项1/1-r,就会被放大
![]()
如果 BC 的误差是 ϵ,那价值差的上界是 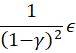 这就是为什么行为克隆很脆弱:r=0.99
这就是为什么行为克隆很脆弱:r=0.99
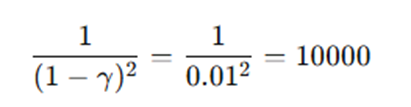
如何解决复合误差?
方法一:使用Dagger,其实就是让训练数据包含“模型自己会遇到的状态
模型运行 → 收集状态 → 询问专家 → 加入训练集
方法二:使用 ACT 的动作块预测,模型根据当前图像和机器人状态,一次性预测未来一段连续动作序列,使策略输出更加平滑,并降低长时序任务中的误差累积,这也是本项目使用ACT的原因
SO100机械臂硬件平台
系统由主从臂(示教与执行)、USB摄像头、STS3215舵机构成。主臂记录人类操作轨迹,从臂执行策略;相机采集图像,控制程序同步记录关节状态(6自由度)、夹爪开合及动作指令。
系统主要硬件包括:
| 硬件 | 作用 |
| SO100 主臂 | 人类示教输入,记录操作者动作 |
| SO100 从臂 | 执行示教动作或模型输出动作 |
| USB 摄像头*2 | 采集桌面、物体、夹爪和机械臂图像 |
| STS3215 舵机 | 驱动机械臂关节和夹爪 |
| FE-URT2-C001舵机调试板子 | 读取机械臂关节角度 |
在这个项目中,相机不是单纯用于目标检测,而是作为策略模型的视觉输入。模型需要从图像中理解物体位置、夹爪位置、桌面环境以及机械臂当前状态。
 图片3:S0100主从机械臂和操作平台
图片3:S0100主从机械臂和操作平台
数据采集流程
- 示教方式:主从臂映射控制,每条demonstration包含完整抓取轨迹。
- 数据内容:每帧记录640×480 RGB图像、关节角度(rad)、夹爪状态(0/1)、动作指令(Δ关节角度、夹爪目标)。规模:50条轨迹,共7642个样本。
- 规模:50条轨迹,共7642个样本。
模仿学习项目的核心是 demonstration 数据。本项目通过主从臂示教方式采集数据。操作者移动主臂完成抓取动作,从臂同步执行对应动作,同时系统记录相机图像、机械臂关节状态、夹爪状态、动作指令和时间戳。每一条 demonstration 都是一段完整的操作轨迹,从机械臂初始状态开始,到完成抓取或放置任务结束。
| 数据类型 |
含义 |
| 图像 observation | 相机看到的物体、夹爪、桌面和机械臂 |
| 机器人状态 state | 当前关节角、夹爪状态等自身信息 |
| 动作 action | 专家在当前状态下执行的动作 |
| 时间戳 timestamp | 用于对齐图像和机器人状态 |
demonstration 的质量会直接影响模型最终的真机表现。如果示教过程中存在夹爪没有对准物体、动作突然抖动、抓取点偏离中心、夹爪闭合时机错误等问题,我在项目初期存在的不同质量的示教情况如下:
- 示教抓取失败,不要继续微调机械臂和夹爪实现抓取
情况1视频如下:
质量低的施教-1
情况2视频如下:
质量低的示教-2
情况3视频如下:
质量低的示教视频-3
- 高质量示教,动作连贯,同时保证抓取成功率,不要有多余的小动作,这样机械臂会“学进去”
视频如下:
优质示教视频
LeRobot数据集构建
数据按LeRobot标准组织:
- episodes:可以理解为一次完整的机器人操作轨迹。例如,一次抓取任务从机械臂初始状态开始,到夹爪抓住物体并完成放置结束,这整个过程就是一个 episode。每个 episode 中包含连续时间步上的 observation 和 action。
- videos:保存相机采集到的视觉数据。视觉信息对抓取任务非常关键,因为机器人仅靠自身关节状态并不知道物体在哪里
- metadata:统计分布(如关节角度范围±π)、数据维度(图像resize为256×256)、保存数据集的统计信息和配置,例如 episode 数量、采样频率、状态范围、动作维度等。它不仅用于训练程序读取数据,也方便后续分析数据质量。
so100_pick_place_lerobot_dataset/
├── data/
│ └── chunk-000/
│ └── file-000.parquet
│
├── videos/
│ └── observation.images.main/
│ └── chunk-000/
│ └── file-000.mp4
│
├── meta/
│ ├── info.json
│ ├── stats.json
│ ├── tasks.parquet
│ └── episodes/
│ └── chunk-000/
│ └── file-000.parquet
│
└── README.md图像与机器人状态同步
在真实机器人数据采集中,一个非常容易被忽视的问题是图像和机器人状态的时间同步。
相机和机械臂状态的频率通常不同。例如,相机可能以 30 FPS 采集图像,而机械臂状态可能以更高频率更新。如果简单按照顺序把第 n 帧图像和第 n 个机器人状态配对,就可能出现图像和状态不属于同一时刻的问题。
这会直接影响模型训练。模型看到的是某一时刻的图像,但动作标签却对应另一个时刻的机械臂状态。这样会让模型学习到错误的对应关系,最终表现为训练 loss 下降,但真机部署效果很差。
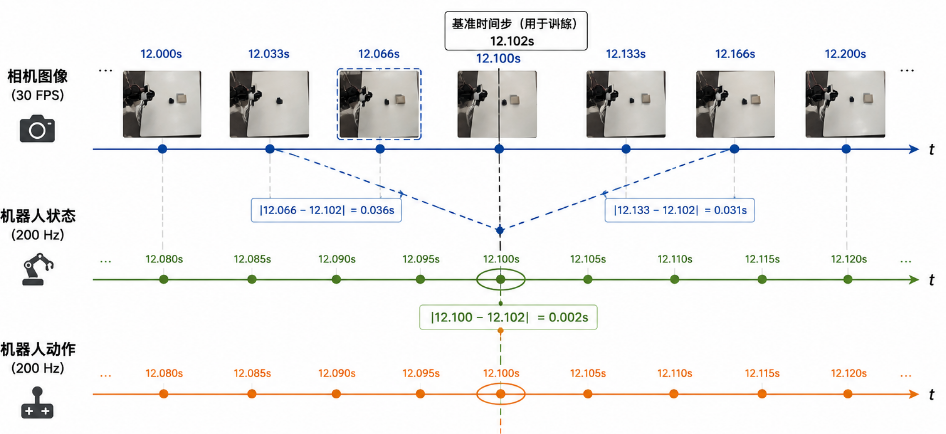
图4: 时间戳对齐示意图
为了解决这个问题,我在数据记录中保留时间戳,并根据时间戳对齐 image、state 和 action。具体做法是以某个时间步为基准,寻找时间上最接近的图像帧和机器人状态,使模型输入和动作标签尽可能对应同一时刻。
ACT策略模型训练
- 输入:
- 当前帧图像
- 关节状态(6维)+夹爪状态(1维)
- 历史动作窗口(10步)
- 输出:未来5步动作序列
- 训练细节:
- 模型参数量52M,8层Transformer,学习率3e-4
- Loss(MSE)从84.128降至0.825(8000 steps)
- 数据增强:随机裁剪
真机部署与Rollout测试结果
模型训练完成后,我将 ACT policy 部署到 SO100 从臂上进行真机 rollout 测试。和数据采集阶段不同,部署阶段的机械臂不再由人类主臂控制,而是由模型根据当前相机图像和机械臂状态直接输出动作。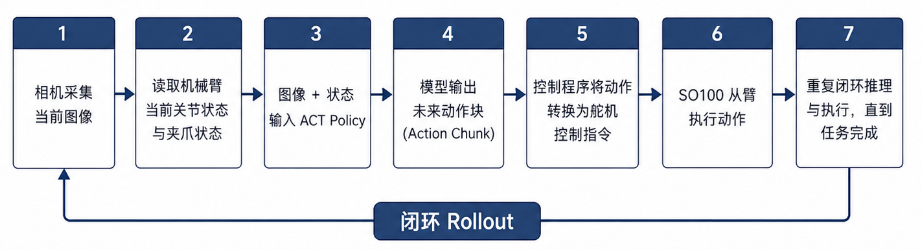
图5: 真机部署与Rollout测试图
同时本项目需要配合使用对应的指令来进行真机的评估,评估指令如下,可根据实际情况进行修改。
python lerobot/scripts/control_robot.py record \
--robot-path lerobot/configs/robot/so100.yaml \
--fps 30 \
--root data \
--repo-id pick/eval_so100_test \
--tags pickbottle \
--warmup-time-s 5 \
--episode-time-s 300 \
--reset-time-s 10 \
--num-episodes 2 \
-p outputs/train/act_so100_test/checkpoints/last/pretrained_model参数说明:
-
--robot-path lerobot/configs/robot/so100.yaml:指定机器人的配置文件路径。
-
--fps 30:设置数据采集的帧率为每秒 30 帧。
-
--root data:指定数据存储的根目录为 data 文件夹。
-
--repo-id pick/eval_so100_test:设置评估数据集的标识符为 pick/eval_so100_test。
-
--tags pickbottle:为评估数据集添加标签 pickbottle,便于分类和检索。
-
--warmup-time-s 5:在每个回合开始前有 5 秒的预热时间。
-
--episode-time-s 300:每个回合的持续时间为 300 秒(5 分钟)。
-
--reset-time-s 10:每个回合之间的重置时间为 10 秒。
-
--num-episodes 2:总共记录 2 个回合的评估数据。
-
-p outputs/train/act_so100_test/checkpoints/last/pretrained_model:指定使用训练好的策略模型,该模型位于 outputs/train/act_so100_test/checkpoints/last/pretrained_model
详情可阅读:https://gitee.com/huahuaze/genkiarm/blob/master/%E6%93%8D%E4%BD%9C%E6%96%87%E6%A1%A3.md
初始测试时,我遇到了一个典型问题:虽然训练 loss 已经下降,但真机动作仍然异常,机械臂会出现高频抖动,甚至出现类似“啄桌面”的动作。这说明机器人模仿学习中,loss 下降并不等于真机一定成功。真机效果还会受到相机视角、图像与状态同步、舵机响应、动作平滑和环境变化等因素影响。
视频如下:
抓取失败二次案例
在后续 rollout 测试中,我将白色桌面划分为 9 个区域,用来评估模型在不同物体位置下的泛化能力。其中,区域 1–6 作为训练数据中覆盖过的位置,属于分布内场景;区域 7–9 作为训练时没有重点覆盖或未覆盖的位置,属于分布外场景。

图6:划分操作平台区域图
测试结果显示,模型在分布内区域 1–6 的成功率约为 85%,说明模型已经能够在训练数据接近的物体位置、相机视角和光照条件下完成一部分抓取任务。但当目标物体移动到分布外区域 7–9 时,成功率下降到约 65%。这说明当前模型虽然学习到了一定的抓取策略,但对未见过的位置变化仍然比较敏感。
| 位置 | 成功率 |
| 分布内区域(1-6) | 85% |
| 分布外区域(7-9) | 65% |
这个结果也反映出当前 demonstration 数量和空间覆盖范围还不够充分。后续需要在 9 个区域内采集更多不同位置、不同角度和不同光照条件下的示教数据,提升模型对物体位置变化的泛化能力
遇到的问题与解决方案
-
相机视角不一致
问题:在早期实验中,我发现训练和测试时的相机位置存在轻微偏差。这种偏差对人眼不明显,但对直接从图像学习动作策略的ACT policy影响很大。相机角度或高度变化会导致图像中的物体位置、夹爪位置发生偏移,模型输入偏离训练分布。这在真机rollout中表现为模型训练看似收敛,部署时夹爪却对不准目标物体。
解决:固定相机支架,确保训练与测试时相机位置、角度、高度一致; 统一光照条件,减少曝光、阴影、反光变化
-
图像与机器人状态不同步
| 设备 | 频率 |
| 相机 | 30FPS |
| 机械臂 | 200HZ |
问题:相机通常以较低频率采集图像,而机械臂关节状态和动作指令更新频率更高。如果直接按照顺序把第 n 帧图像和第 n 个状态配对,就可能出现图像和状态不属于同一时刻的问题,这种不同步会直接影响训练质量。模型看到的是某一时刻的画面,但动作标签可能来自另一个时刻的机械臂状态。最终模型学到的就是错误的 image-state-action 对应关系。训练 loss 可能仍然下降,但真机部署时会出现动作不稳定、夹爪提前闭合、接近物体位置错误等问题。
视频如下:
抓取失败三次案例
解决:以图像帧时间为基准,在机械臂状态序列中寻找时间最接近的一帧状态和动作,将它们组合成一个训练样本。
-
USB摄像头断连
问题:在第二轮数据采集过程中,我遇到了 USB 摄像头断连和设备编号变化的问题。Ubuntu 中多个 USB 摄像头或 USB 视频设备重新插拔、重启后,系统分配的 /dev/video0、/dev/video1 编号可能发生变化。如果程序中写死了 /dev/video0,那么设备编号变化后,程序可能会读取到错误的摄像头。
解决:使用 udev rule 给摄像头绑定一个稳定的设备名。这样程序不再直接读取 /dev/video0,而是读取固定的符号链接,例如 /dev/camera_main。
SUBSYSTEM=="video4linux", ATTRS{idVendor}=="046d", ATTRS{idProduct}=="0825", SYMLINK+="camera_main"
配置完成后,重新加载udev规则:
sudo udevadm control --reload-rules
sudo udevadm trigger-
舵机通信异常
问题:我还遇到过 USB 带宽竞争导致的通信异常。USB 摄像头的视频流对带宽和实时性要求比较高,如果摄像头和机械臂通信模块接在同一个 USB HUB 或同一个 USB 控制器下面,当摄像头占用带宽较高或发生重连时,可能会影响同一 USB 链路下的其他设备。在项目中,这类问题表现为:相机采集脚本卡死、视频帧丢失、机械臂状态读取异常、舵机同步读写不稳定,甚至从臂动作突然异常。对于模仿学习来说,这会直接破坏数据采集质量,因为 state 和 action 可能不再稳定对应。
解决:减少 USB 带宽冲突:将摄像头与舵机通信分接不同 USB 控制器,避免高带宽摄像头共用 HUB,适当降低摄像头分辨率/帧率及不必要的舵机状态查询频率,并检查夹爪舵机在高频读写下的状态包稳定性。
-
PID参数导致机械臂抖动
问题:在早期测试中,SO100 从臂在执行模型输出动作时出现过明显高频抖动。这个问题会进一步影响模型输入,因为机械臂抖动会导致相机画面中的夹爪位置不断变化,使模型看到的状态偏离训练数据分布。最终可能造成动作越来越不稳定
解决:通过飞特调试工具调整STS3215参数,修改P参数为5,参考数据为5-10即可。
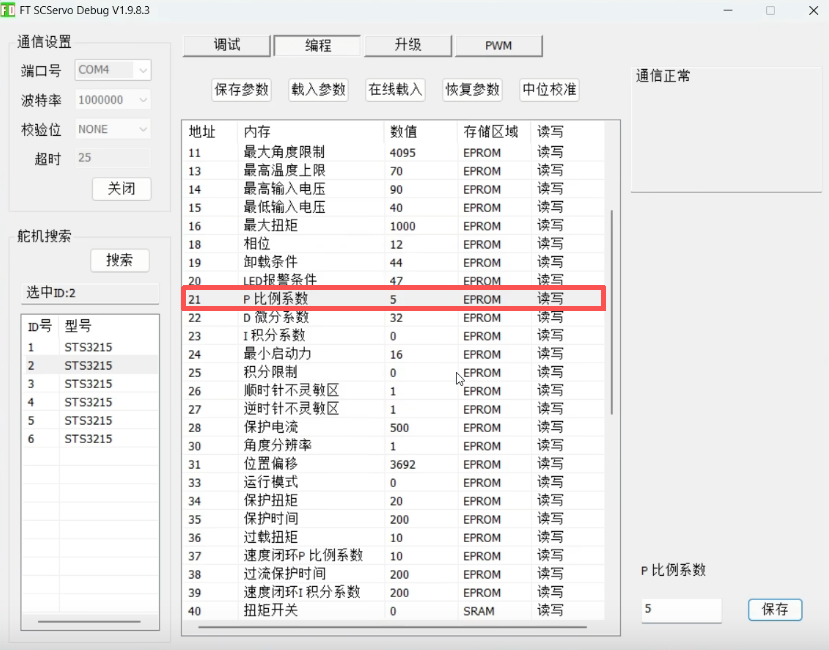
图7:飞特调试工具面板
实验结果与不足
- 优势:验证了模仿学习在简单抓取任务中的可行性,LeRobot简化了数据处理流程。
- 不足:
- 数据多样性不足(仅1种物体位置变体)。
- 未处理动态扰动(如移动目标)。
后续优化方向
- 增加 demonstration 数量和多样性
当前数据规模较小,物体位置和角度变化有限。后续可以将抓取区域划分为多个网格,在不同位置、不同角度、不同光照条件下采集更多 demonstration,提高模型对环境变化的鲁棒性。
- 引入 DAgger 减少分布偏移
模仿学习容易遇到分布偏移问题:训练时模型看到的是专家示教状态,但真机执行时一旦产生小误差,就会进入训练数据中没有覆盖过的状态。DAgger 的思路是让模型先在真实机械臂上执行任务,收集模型自己会遇到的状态,然后由人类专家对这些状态重新标注正确动作,再加入训练集继续训练。
- 优化视觉输入稳定性
后续可以继续优化相机固定结构,统一曝光、白平衡和光照条件,或者使用更稳定的工业相机,减少 USB 摄像头带来的带宽和设备编号问题。
- 增加动作平滑和安全约束
模型输出动作可以加入低通滤波、滑动平均或速度/加速度限制,避免机械臂出现突变动作。同时加入关节限位和安全区域限制,防止机械臂撞击桌面或超过关节范围。
- 扩展更多任务类型
当前任务主要集中在简单抓取和放置。后续可以扩展到多物体抓取、按颜色分类、堆叠、移动目标抓取等任务,让模型学习更复杂的操作策略。
附件
- 成功抓取案例1:https://live.csdn.net/v/527452
- 成功抓取案例2:https://live.csdn.net/v/527445

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)