AI知识库和传统知识库软件有什么不同?
AI知识库与传统知识库的区别,并非简单的技术升级,而是数据处理、交互模式与价值产出三个核心层面的范式革新——传统知识库是被动的“文档仓库”,聚焦存储与定位;AI知识库则是主动的“智能中枢”,聚焦解析、应用与价值转化。
一、 本质定义:从文档仓库到认知中枢
传统知识库本质上是结构化的文档仓库。其核心逻辑是存储,依赖于严格的人工录入、分类和标签化管理。它类似于一个庞大的在线档案馆,资料虽然齐全,但缺乏理解力,需要人类自行检索并消化内容。
AI知识库则进化为具备推理能力的智能中枢。其核心逻辑是理解与应用。通过自然语言处理(NLP)和深度学习技术,它不仅存储数据,更能对数据进行语义层面的解析,将孤立的信息点连接成网,主动为用户提供决策支持。
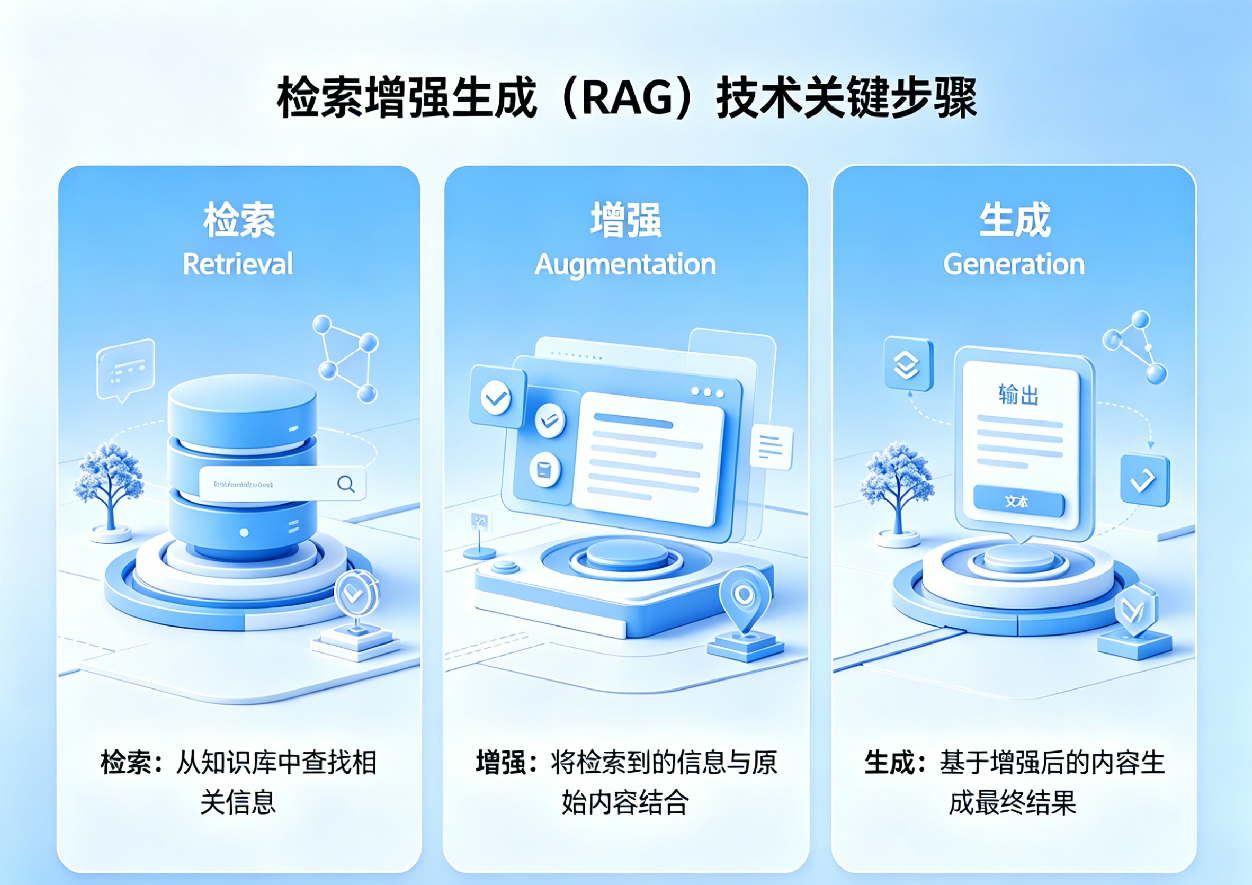
二、 核心技术差异对比
|
维度 |
传统知识库 |
AI知识库 |
|
数据处理 |
结构化主导:擅长处理表单、数据库等规整数据,对非结构化文本(如长文、聊天记录)处理能力弱 |
非结构化解析:利用向量嵌入(Vector Embedding)技术,将文档转化为语义向量,自动建立关联,无需繁琐的前置清洗 |
|
检索逻辑 |
关键词匹配:基于字符匹配,容错率低。同义词、近义词或表述偏差都会导致检索失败(高漏报/误报率) |
语义理解:基于意图识别。即便提问措辞与文档不一致,也能通过上下文理解用户需求,实现“所问即所得” |
|
交互模式 |
人找资料:用户主动搜索,系统返回链接列表。用户需自行下载、阅读、筛选,认知负荷高 |
对话式交互:支持自然语言提问与多轮追问。系统扮演专家角色,直接生成答案,并可追溯原文依据 |
|
维护成本 |
高运维成本:知识更新依赖人工手动修改或重新上传,分类体系僵化,极易随时间推移沦为数字废墟 |
动态自进化:文档即插即用,模型自动解析。通过用户反馈机制,系统能反向优化知识图谱,持续保鲜 |
三、 深度解析:三大维度的重构
1. 数据接入:从人工清洗到原生理解
传统知识库受限于技术架构,往往要求数据必须高度结构化才能被有效利用,这导致大量隐藏在非结构化文本(如会议纪要、项目复盘、邮件往来)中的隐性知识被浪费。AI知识库通过Transformer架构,能够直接“阅读”原始文档,自动提取实体、关系与事件,极大地降低了知识入库的门槛。
2. 检索体验:从大海捞针到精准投喂
在传统模式下,用户常常面临搜不到或太多看不完的困境。AI知识库改变了这一局面:它不再返回一堆链接让你去读,而是直接给出经过整合的结论。例如,询问“上个季度华东区的销售策略是什么”,AI能直接总结核心战术,并附上相关文档的引用链接,将信息获取时间从小时级缩短至秒级。
3. 价值产出:从被动备查到主动赋能
传统知识库的价值上限是有据可查,防止知识随人员流失而流失。而AI知识库的价值在于辅助创造。它能够基于现有知识进行推理、组合与创新,例如自动生成培训材料、辅助编写代码或起草商业计划,真正实现了知识资产的生产力转化。
四、 结语
传统知识库解决的是知识存在哪的问题,而 AI 知识库解决的是知识是什么、怎么用的问题。前者是图书馆的索引卡,后者更像是一个读过所有书并能随时答疑的图书管理员。
企业引入AI知识库,并非仅仅是为了替换掉旧的软件系统,而是要打破数据孤岛,激活沉睡的数据资产。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)