hot100——动态规划
动态规划
动态规划(dynamic programming)是一个重要的算法范式,它将一个问题分解为一系列更小的子问题,并通过存储子问题的解来避免重复计算,从而大幅提升时间效率。
动态规划是属于自底而上的算法。与回溯算法一样,动态规划也使用“状态”概念来表示问题求解的特定阶段,每个状态都对应一个子问题以及相应的局部最优解。
同时由于动态规划的状态值依赖于某些局部状态,因此我们可以优化原有算法,消除dp的一个维度来达到降低空间复杂度的目的。
在动态规划问题中,当前状态往往仅与前面有限个状态有关,这时我们可以只保留必要的状态,通过“降维”来节省内存空间。这种空间优化技巧被称为“滚动变量”或“滚动数组”。


解题步骤:
第一步:思考每轮的决策,定义状态,从而得到 dp 表;
第二步:找出最优子结构,进而推导出状态转移方程
第三步:确定边界条件和状态转移顺序。
0-1背包问题

定义状态变量
我们可以将 0-1 背包问题看作一个由 n 轮决策组成的过程,对于每个物体都有不放入和放入两种决策,因此该问题满足决策树模型。
每一个物品可以选择放入背包或者不放入背包,假设当前的物品编号是i,以及此时的背包容量是c,那么[i, c]表示当前物品编号是i,背包容量是c,那么定义状态dp[i, c]是前i个物品在容量为c的背包下的最大价值。
那么需要求解的是dp[n, cap]。
状态转移方程
当我们做出第i个物品的决策时,那么剩余的就是前i-1个物品的子问题,那么对于第i个物品:
· 不选,价值不变,容量不变[i-1, c];
· 选,容量减小,c - wgt[i-1],价值增加val[i-1],状态变为[i-1, c-wgt[i-1]]。但是这里得注意,如果当前的物品的重量是大于此时的背包容量的时候,这时候也是不能放入背包的。
那么整个状态转移方程是:
dp[i, c] = max(dp[i-1, c], dp[i-1, c- wgt[i-1]] + val[i-1])
初始条件以及计算顺序
当没有物品或者背包容量为0时,dp[0,c] 以及dp[i, 0] == 0,也就是首行和首列都是0。计算顺序从小到大,经过2层循环遍历。
n = len(wgts)
dp = [[0] * (cap+1) for _ in range(n+1)]
for i in range(1, n+1):
for c in range(1, cap+1):
# 还要讨论当前选择物品的重要是否超过了背包容量,超过了,依旧不选
if wgts[i-1] > c:
dp[i][c] = dp[i-1, c]
else:
dp[i][c] = max(dp[i-1][c], dp[i-1][c- wgts[i-1]] + val[i-1])
return dp[n][cap]空间优化
从上述状态转移方程可以看出:
当前状态只和上一个状态有关,因此我们其实只需要一个一维数组就可以。因为i代表的是每一行,也就是每一行的状态都是由上一行的状态转移过来的,那么我们可以采用一个一维数组,当遍历第i行的时候,存储的其实是第i-1行的数据。
- 如果采取正序遍历,那么遍历到d[i, j]时,左上方d[i-1, 1] ~ d[i-1, j-1]值可能已经被覆盖,此时就无法得到正确的状态转移结果。
- 如果采取倒序遍历,则不会发生覆盖问题,状态转移可以正确进行。
n = len(wgts)
dp = [0] * (cap+1)
for i in range(1, n+1):
for c in range(cap, 0, -1):
# 还要讨论当前选择物品的重要是否超过了背包容量,超过了,依旧不选
if wgts[i-1] > c:
dp[c] = dp[c]
else:
dp[c] = max(dp[c], dp[c- wgts[i-1]] + val[i-1])
return dp[cap]可以继续改进
n = len(wgts)
dp = [0] * (cap+1)
for i in range(1, n+1):
# 如果当前物品的重量大于背包容量,那么该物品也是不选,dp数组保持不变
# 所以要使得当前dp数组状态转移,那么当前物品的重量必须要小于当前的背包容量c
# 所以此时的背包容量满足以下关系:
# wgts[i-1] <= c <= cap
for c in range(cap, wgts[i-1]-1, -1):
dp[c] = max(dp[c], dp[c- wgts[i-1]] + val[i-1])
return dp[cap]完全背包问题

定义状态变量
dp[i,c]:前i个物品在容量为c的背包下所能产生的最大价值。
状态转移方程
对于第i个物品,依旧是可选可不选:
不选的话,和之前一样,由前i-1个物品决定,状态转移至dp[i-1,c];
选的话,容量变小,c-wgts[i-1],并且由于选了第i个物品之后还可以继续选第i个物品,所以状态转移至dp[i, c-wgts[i-1]]。
由此状态转移方程是:
dp[i,c] = max(dp[i-1, c], dp[i,c-wgts[i-1]])
初始条件以及计算顺序
当没有物品或者背包容量为0时,dp[0,c] 以及dp[i, 0] == 0,也就是首行和首列都是0。因为每个物品都可以重复抽取,那么对应的状态值是可以更新的,这样后面用的时候也说明了这个元素是被多次利用,符合题目要求,计算顺序从小到大,经过2层循环遍历。
def unbounded_knapsack_dp(wgt: list[int], val: list[int], cap: int) -> int:
"""完全背包:动态规划"""
n = len(wgt)
dp = [[0] * (cap + 1) for _ in range(n+1)]
for i in range(1, n+1):
for c in range(1, cap+1):
# 如果当前物品质量超过背包容量,则不选当前物品,那么价值由前i-1个物品决定
if wgt[i-1] > c:
dp[i][c] = dp[i-1][c]
else:
dp[i][c] = max(dp[i-1][c], dp[i][c-wgt[i-1]] + val[i-1])
return dp[n][cap]空间优化
由上述状态可知,当前状态值,是由上边的,以及左边的值转移的,因此空间优化的话,需要从正序入手。因为这样的话,已经更新的状态是可以被重复利用的话,说明元素可以被重复利用,因此选正序。
def unbounded_knapsack_dp(wgt: list[int], val: list[int], cap: int) -> int:
"""完全背包:动态规划"""
n = len(wgt)
dp = [0] * (cap + 1)
for i in range(1, n+1):
for c in range(1, cap+1):
# 如果当前物品质量超过背包容量,则不选当前物品,那么价值由前i-1个物品决定
if wght[i-1] > c:
dp[c] = dp[c]
else:
dp[c] = max(dp[c], dp[c-wgt[i-1]] + val[i-1])
return dp[cap]继续优化
def unbounded_knapsack_dp(wgt: list[int], val: list[int], cap: int) -> int:
"""完全背包:动态规划"""
n = len(wgt)
dp = [0] * (cap + 1)
for i in range(1, n+1):
for c in range(wght[i-1], cap+1):
dp[c] = max(dp[c], dp[c-wgt[i-1]] + val[i-1])
return dp[cap]“空间优化需要从正序入手,因为已经更新的状态可以被重复利用,说明元素可以被重复利用”,这是完全正确的。正序允许 dp[c-wgt[i]] 可能是本轮已经更新过的,从而支持同一物品多次选取。这与0-1背包的逆序形成鲜明对比。
正序/逆序的讨论,只出现在空间优化的一维 DP 中。在原始的二维 DP 里,我们只是老老实实地按物品顺序、按容量从小到大计算,不需要特意区分正序逆序,因为状态 dp[i][c] 只依赖于上一行 dp[i-1][...](或同一行左边 dp[i][c-wgt] 对于完全背包),二维数组天然隔离了层次,不会发生覆盖问题。
因此,你的这个补充非常到位,抓住了背包问题优化的关键点:
-
二维 DP:清晰直观,无遍历顺序困扰。
-
一维 DP:必须根据物品类型选择正序(完全背包)或逆序(0‑1 背包),以避免状态覆盖导致错误。
总结
-
0-1背包(物品只能选一次):内层容量必须逆序(从大到小),这样才能保证
dp[c - w[i]]使用的是上一轮(未选当前物品)的状态,避免同一个物品被重复使用。 -
完全背包(物品可以选无限次):内层容量必须正序(从小到大),这样
dp[c - w[i]]可能是本轮已经更新过的状态,从而允许物品被多次选取。
编辑距离问题
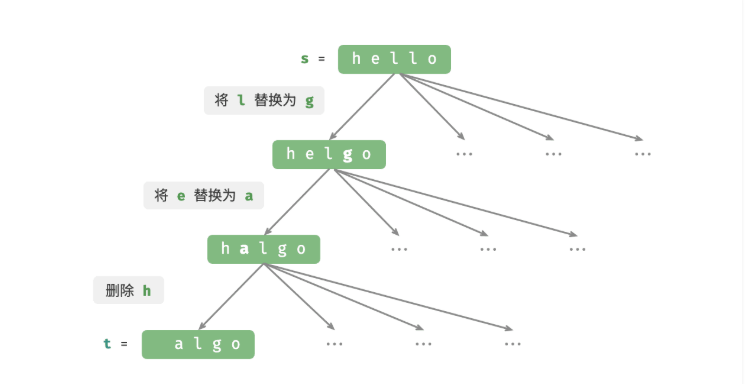
编辑距离,也称 Levenshtein 距离,指两个字符串之间互相转换的最少修改次数,通常用于在信息检索和自然语言处理中度量两个序列的相似度。


编辑距离问题可以很自然地用决策树模型来解释。字符串对应树节点,一轮决策(一次编辑操作)对应树的一条边。
如图 14-28 所示,在不限制操作的情况下,每个节点都可以派生出许多条边,每条边对应一种操作,这意味着从 hello 转换到 algo 有许多种可能的路径。
从决策树的角度看,本题的目标是求解节点 hello 和节点 algo 之间的最短路径。
第一步:思考每轮的决策,定义状态,从而得到 dp 表
每一轮的决策都是对s进行一次编辑,题目中是要我们找到最少编辑数。那么就是我们在编辑过程中,希望问题的规模越来越小,这样有利于构建子问题。假设字符串s和字符串t的大小分别是n和m,先考虑2字符串的最后一个元素s[n-1]和t[m-1]:
如果这俩相等,则直接跳过这俩,看s[n-1]和t[m-2];
如果这俩不相等,则我们需要对s进行一次编辑(替换、删除、添加),使得俩字符尾部元素相等,从而可以跳过它们,考虑更小规模的问题;
那么就是,我们在s中的每一个决策,都会使得s和t中剩余待匹配字符发生变化,因此状态为当前考虑的s中的第i个字符,和t中的第j个字符,记作[i, j]。
那么状态[i, j] 为将s前i个字符转变为t的前j个字符所需要的最小的编辑数目。
第二步:找出最优子结构,进而推导出状态转移方程
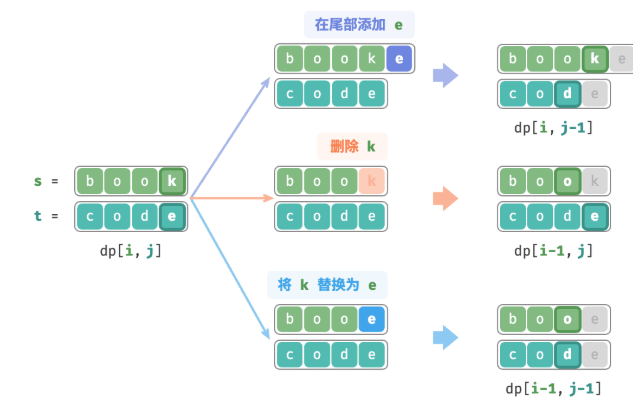
对于子问题dp[i, j],对应的是s[i-1]和t[j-1],当s[i-1]和t[j-1]不同的时候,根据不同的编辑操作,分为以下三种:
①在s[i-1]之后添加t[j-1],那么剩下的子问题就是dp[i, j-1];
②删除s[i-1],那么剩余的子问题就是dp[i-1, j];
③替换s[i-1]为t[j-1],那么剩余的子问题就是dp[i-1, j-1]
那么可以直到最少编辑数dp[i,j] 等于上面3个操作的最小值,再加上当前的编辑这一步:
dp[i,j] = min(dp[i,j-1], dp[i-1, j], dp[i-1, j-1])+ 1
如果s[i-1]和t[j-1]相同的话,不需要编辑当前字符,那么直接进入到dp[i-1, j-1],也就是dp[i,j]=dp[i-1,j-1]。
第三步:确定边界条件和状态转移顺序
当2个字符串都是为空的时候,dp[0, 0] = 0,当s为空的时候,dp[0, j] = j;
当t为空的时候,dp[i,0] = i;
由状态方程可知,当前状态是由左,上,左上决定的,因此需要两层循环正序遍历才能得到当前结果。
代码
def edit_distance_dp_comp(s: str, t: str) -> int:
"""编辑距离:空间优化后的动态规划"""
n = len(s)
m = len(t)
dp = [[0] * (m+1) for _ in range(n+1)]
# s不为空,t为空,需要的编辑数目等于s的长度
for i in range(1, n+1):
dp[i][0] = i
# t不为空,s为空,需要的编辑数目等于t的长度
for j in range(1, m+1):
dp[0][j] = j
for i in range(1, n+1):
for j in range(1, m+1):
# 如果最后一个元素相同,跳过
if s[i-1] == t[j-1]:
dp[i][j] = dp[i-1][j-1]
else:
dp[i][j] = min(min(dp[i][j-1],dp[i-1][j]), dp[i-1][j-1]) + 1
return dp[n][m]空间优化
由上述状态转移方程可知:当前状态依赖其正上方、正左方、左上方的状态,因此空间优化后正序或倒序遍历都无法正确地进行状态转移。为此,我们利用一个变量暂存左上方状态,从而转化到与完全背包问题等价的情况,可以在空间优化后进行正序遍历。
def edit_distance_dp_comp(s: str, t: str) -> int:
"""编辑距离:空间优化后的动态规划"""
m = len(t)
n = len(s)
dp = [0] * (m+1)
# t不为空,s为空,需要的编辑数目等于t的长度(插入)
for j in range(1, m+1):
dp[j] = j
# 此时的dp存储的是上一轮的遍历结果,也就是上一行的结果
for i in range(1, n+1):
# 保存上一行的左上,即dp[i-1][0]
leftUp = dp[0]
# dp[0]要累加是因为相当于当t为空,s不为空的时候,s匹配要多少次,编辑距离等于 i(删除操作)
dp[0] += 1
for j in range(1, m+1):
## 保存上一行的 dp[j](即 dp[i-1][j]),作为下一轮的左上角
temp = dp[j]
# 如果最后一个元素相同,跳过
if s[i-1] == t[j-1]:
dp[j] = leftUp
else:
dp[j] = min(min(dp[j-1], dp[j]), leftUp) + 1
# 更新左上角为上一行的当前列值
leftUp = temp
return dp[m]贪心



分数背包问题

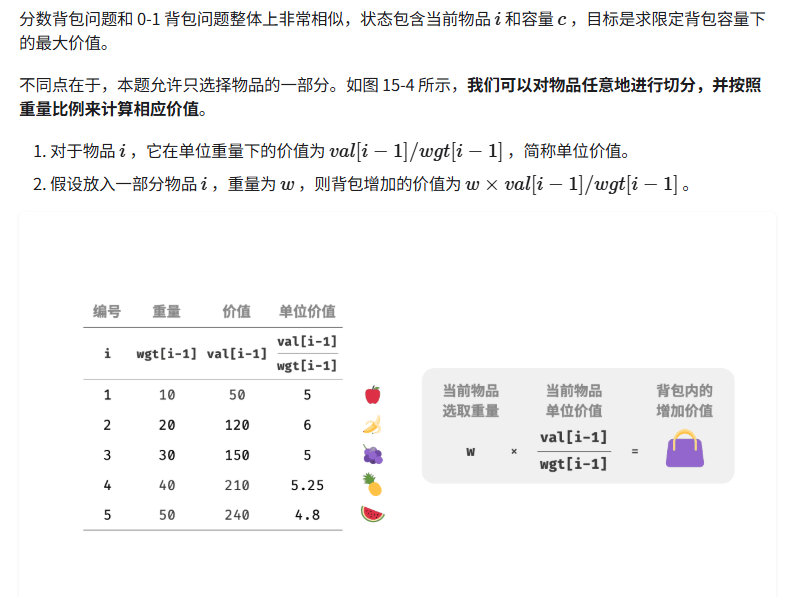

class Item:
"""物品"""
def __init__(self, w: int, v: int):
self.w = w # 物品重量
self.v = v # 物品价值
def fractional_knapsack(wgt: list[int], val: list[int], cap: int) -> int:
"""分数背包:贪心"""
# 创建物品列表,包含两个属性:重量、价值
items = [Item(w, v) for w, v in zip(wgt, val)]
# 按照单位价值 item.v / item.w 从高到低进行排序
items.sort(key=lambda item: item.v / item.w, reverse=True)
# 循环贪心选择
res = 0
for item in items:
if item.w <= cap:
# 若剩余容量充足,则将当前物品整个装进背包
res += item.v
cap -= item.w
else:
# 若剩余容量不足,则将当前物品的一部分装进背包
res += (item.v / item.w) * cap
# 已无剩余容量,因此跳出循环
break
return res-
[](Item &a, Item &b) { ... }是一个 lambda 表达式,定义了一个比较函数。 -
参数
a和b是待比较的两个物品。 -
返回值是
bool:如果a应该排在b前面,则返回true;否则返回false。 -
这里比较的是 单位价值(价值/重量),使用
>表示降序(单位价值高的在前)。 -
(double)强制转换,避免整数除法截断。
所以,排序后 items 中单位价值最高的物品会排在最前面。
sort(items.begin(), items.end(),
[](Item &a, Item &b) {
return (double)a.v / a.w > (double)b.v / b.w;
});也可以用下面2种方式进行替换
// 方式1:普通函数
bool cmp(const Item &a, const Item &b) {
return (double)a.v / a.w > (double)b.v / b.w;
}
sort(items.begin(), items.end(), cmp);
// 方式2:先定义 lambda 变量
auto cmp = [](const Item &a, const Item &b) {
return (double)a.v / a.w > (double)b.v / b.w;
};
sort(items.begin(), items.end(), cmp);class Item
{
public:
int w;
int v;
Item(int w, int v):w(w), v(v)
{
}
};
/* 分数背包:贪心 */
double fractionalKnapsack(vector<int> &wgt, vector<int> &val, int cap) {
// 创建物品列表,包含两个属性:重量、价值
vector<Item> items;
for(int i=0;i<wgt.size();i++)
{
items.push_back(Item(wgt[i], val[i]));
}
// 按照单位价值从高到低排列,
sort(items.begim(), items.end(), [](Item &a, Item&b){return (double)a.v/a.w > (double)b.v / b.w};
// 返回价值
double res = 0;
for(auto item :items)
{
if(item.w < cap)
{
res += item.v;
cap -= item.w;
}
else
{
res += cap*(item.v/item.w);
break;
}
}
return res;
最大容量问题

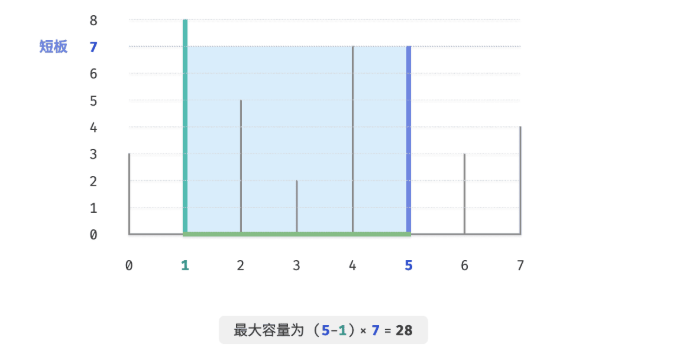
容器由任意2个隔板围成,而高是由较短的隔板决定,那么对应的容器面积是:
d[i, j] = min(h[i], h[j]) * (j-i)
如果是穷举n个隔板中任意2个的情况,那么时间复杂度将会达到O()
那么贪心策略是:
使用双指针来进行操作,首先分别让双指针指向容器的两端,计算当前的容器容量,并更新最大容量,比较i,j对应的高度,然后移动短板向内一格,直至i、j相遇。
为什么是移动短板?
因为如果一开始就是移动长板的话,那么容量一定是减小的,因为隔板的高度在减小,两个隔板之间的宽度也在减小,所以移动长板,虽然宽度在减小,但是高度在增加,可能会使得容量增大,而移动长板一定使得容量减小或者不变。
代码
/* 最大容量:贪心 */
int maxCapacity(vector<int> &ht) {
# 双指针,一个指向头,一个指向尾
int i = 0;
int j = ht.size()-1;
# 最大容量
int maxcap = 0;
# 知道2个指针相遇才结束遍历
while(i<j)
{
# 计算当前的容量
int temp = min(ht[i], ht[j]) * (j-i);
maxcap = max(temp,maxcap);
# 判断短板,并移动短板
if(ht[i]<=ht[j])
{
i++;
}
else
j--;
}
return maxcap;
}最大切分乘积问题




/* 最大切分乘积:贪心 */
int maxProductCutting(int n) {
// 当 n <= 3 时,必须切分出一个 1
if (n <= 3) {
return 1 * (n - 1);
}
// 贪心地切分出 3 ,a 为 3 的个数,b 为余数
int a = n / 3;
int b = n % 3;
if (b == 1) {
// 当余数为 1 时,将一对 1 * 3 转化为 2 * 2
return (int)pow(3, a - 1) * 2 * 2;
}
if (b == 2) {
// 当余数为 2 时,不做处理
return (int)pow(3, a) * 2;
}
// 当余数为 0 时,不做处理
return (int)pow(3, a);
}/* 最大切分乘积:贪心 */
def maxProductCutting(n):
# 任何一个大于3的数都可以写作
# n = 3q + r(r=0,1,2)
if n<=3:
return n-1
# q是商,r是余数
q,r = divmod(n, 3)
# 3*1 不如 2*2,所以将最后一个3换位2*2
if r==1:
return 3**(q-1)*4
elif r==2:
return 3**q*2
# r==0的情况
else:
return 3**q
单调栈

10.正则表达式匹配

解题思路
本题考虑用动态规划来实现:
假设s的长度为m,p的长度为n,s的前i个字符记作s[:i],p的前j个字符记作p[:j],那么这道题就可以转换为判断s[:i]和s[:j]是否匹配,从第一个字符串开始查看s[:1]和p[:1]是否匹配,然后逐个增加元素查看是否匹配直至添加到整个字符串。
本题中共有mxn种状态,设置状态矩阵dp,其中dp[i][j]表示s的前i个字符和p的前j个字符是否匹配:
dp[i][j]对应的添加的字符是s[i-1]和p[j-1],其中dp[0,0] = True,空字符是可以匹配的。
首先对于空字符串如何匹配呢?只有如同a*a*……这种形式才可以匹配完成:
当s为空字符串的时候,状态矩阵需要初始化:每当奇数下标时对应的p的字符为*,并且只有当p中字符个数为偶数的时候才可以匹配s。
而对于d[i][j]而言,此时对应比较的元素是s[i-1]以及p[j-1],而此时的p[j-1]就要分为*的情况和不为*的情况:
当p[j-1]不是*的时候,那么p[j-1]就必须要和s[i-1]相等或者说p[j-1]==".",不论这2种情况的哪一种,先决条件都是d[i-1][j-1]要是True;
当p[j-1]是*的时候,这个时候又分为了*代表前面出现的字符次数是0以及多次的情况:
当前面的字符出现为0次的时候,也就是此时是p[j-2]*,但是*表示这里匹配0次p[j-2],“匹配0次前一元素”就是指忽略掉 x* 这一组合,即模式向前跳两个字符(跳过 p[j-2] 和 p[j-1]),字符串保持不变。这样,dp[i][j] 就直接等于 dp[i][j-2],不需要考虑字符串的当前字符。
当*表示一次或者多次的时候,那么要比较s[i-1]要和p[j-2]是否匹配,或者p[j-2]是否等于".",那么这样的先决条件是d[i-1][j]要是True(比如说s“aaa”,p“aa*”,s[i-1] == p[j-2] == a,但是我们还要比较s[:i-1]和p[:j]是否匹配,因为*可以代表和p[j-2]多次出现,所以s[:i-1]还是要和p[:j]进行匹配,不能说s往左移一位,p也要往移一位,那么就直接得到不匹配的结果但是实际上s和p其实是匹配的)
代码
python
class Solution(object):
def isMatch(self, s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
m, n = len(s) + 1, len(p) + 1
# dp size:mxn
dp = [[False] * n for _ in range(m)]
dp[0][0] = True
# 那些模式可以匹配空字符串: (字符/. + *)这种才可以,并且要是偶数字符个数
# 只对偶数下标进行赋值,奇数下标默认Fasle
for j in range(2, n, 2):
dp[0][j] = dp[0][j-2] and p[j-1] == '*'
# 考虑p[j-1]是否为*,分情况讨论
for i in range(1, m):
for j in range(1, n):
dp[i][j] = dp[i][j-2] or dp[i-1][j] and (s[i-1] == p[j-2] or p[j-2] == '.') \
if p[j-1] == '*' else \
dp[i-1][j-1] and (p[j-1] == '.' or s[i-1] == p[j-1])
return dp[-1][-1]
C++
class Solution {
public:
bool isMatch(string s, string p) {
// 这里必须加1,因为dp[i][j]代表s的前i个元素和p的前j个元素是否相等
// 之后循环遍历的时候是要取到s/p的长度,代表s/p的整体
int m = s.size() + 1;
int n = p.size() + 1;
vector<vector<bool>> dp(m, vector<bool>(n, false));
// 初始化s为空字符串的情况,p得为a*a*a*a*……这种情况,奇数下标都是*
// 每次步进2个单位,因为p为奇数的话不可能和s匹配
dp[0][0] = true;
for(int j = 2;j<n;j+=2)
{
dp[0][j] = dp[0][j-2] && p[j-1] == '*';
}
// 状态变化
for(int i = 1;i<m;i++)
{
for(int j = 1;j<n;j++)
{
if(p[j-1] == '*')
{
// *为0 + *为一或者多次前一元素的情况
dp[i][j] = dp[i][j-2] || (dp[i-1][j] && (s[i-1]==p[j-2] || p[j-2] == '.'));
}
else
{
dp[i][j] = dp[i-1][j-1] && (s[i-1]==p[j-1] || p[j-1]=='.');
}
}
}
// 返回最后一个元素,就是代码s整个和p整个是否匹配
return dp[m-1][n-1];
}
};32.最长有效括号

解题思路
对于这种最值型问题,我们尝试用动态规划来处理:
动态规划问题分为以下4个步骤:
1.确定状态
研究最优策略的最后一步
化为子问题
2.转移方程
根据子问题定义得到
3.初始条件和边界条件
4.计算顺序
首先,我们定义一个dp数组,其中第i个元素代表的是以i为下标结尾的最长有效子字符串的长度。
研究状态:
确定最优策略的最后一步:
字符串最后一个元素是s[i],需要判断s[i]的情况
情况1:s[i]=='(',那么d[i] ==0,因此此时不会有和s[i]匹配的右括号,所以dp[i] ==0;
情况2:s[i]==')',但是这样的话也是需要分情况考虑的:
s[i-1]=='(',这样的话,那么d[i] = d[i-2] + 2;因此此时s[i-1]和s[i]是配对的,然后我们还要加上前i-2个字符的dp情况;
s[i-1]==')',这样的话,那么我需要先判定以s[i-1]==')'结尾的最长有效子字符串的长度dp[i-1],此时对应的字符串中的序列就是s[i-dp[i-1]].....s[i-1],那么此时我们需要判定s[i-dp[i-1]-1]是否是'(',来和s[i]进行配对,以构成有效的括号对,同时还需要判断dp[i-[dp[i-1]-2]也就是以s[i-dp[i-1]-2]结尾的字符串的最长有效子字符串的长度,因此
d[i] = dp[i-1] + 2 + dp[i-dp[i-1]-2];
子问题:
从上述分析可知,我们要得到dp[i]就必须要知道dp[i-1]、dp[i-2]、dp[i-dp[i-1]-2],所以原问题就变成了求dp[i-1]、dp[i-2]、dp[i-dp[i-1]-2]的子问题。
那么此时的状态就是:
设 dp 数组,其中第 i 个元素表示以下标为 i 的字符结尾的最长有效子字符串的长度。
转移方程:
if s[i] == '(':
dp[i] == 0
elif s[i] == ')':
if s[i-1] == '(':
dp[i] = dp[i-2] + 2 # 得保证i-2>=0
elif s[i-1] == ')' and s[i-dp[i-1]-1] == '(':
dp[i] = dp[i-1] + 2 + dp[i-dp[i-1]-2] # 得保证 i-dp[i-1]-2>=0初始条件和边界条件:
初始条件:dp[i] = 0;
边界条件:在计算过程中:i-2>=0 以及 i -dp[i-1]-2>=0
计算顺序:
无论第一个字符是什么第一个数dp[0] = 0;而后计算dp[i]/dp[1]/dp[2]/……dp[n-1],最后取max(dp[i]) 。
代码
python
class Solution(object):
def longestValidParentheses(self, s):
"""
:type s: str
:rtype: int
"""
m = len(s)
dp = [0] * m
maxVal = 0
# 遍历字符串s
for i in range(1, m):
if s[i] == ')':
# s[i-1] == '('的情况
if s[i-1] == '(':
dp[i] = 2
# 边界条件
if i-2>=0:
dp[i] = dp[i-2] + 2
# s[i-1] == ')'的情况
# 先判定dp[i-1]>0, 因为这是后面的基础
# 如果dp[i-1] == 0,那么下面的判断条件其实就是无效了,i-1>=0 and s[i-1]=='('
# 因为这个时候s[i-1]==')',我们是要在0~i-2这个区间内,找到有没有和i-1/i位置对应的左括号
elif dp[i-1]>0:
# dp[i-1]代表以i-1下标结尾的子字符串的最长有效括号的长度,这个之前的下标是i-dp[i-1]-1
# 我们要判断这个下标对应的符号是不是和s[i]对应的右括号对应,同时的得注意到i-dp[i-1]-2以这个下标
# 结尾的子字符串中是不是存在最长有效括号
if i-dp[i-1]-1 >=0 and s[i-dp[i-1]-1] == '(':
dp[i] = dp[i-1] + 2
if i-dp[i-1]-2 >=0:
dp[i] = dp[i-1] + 2 + dp[i-dp[i-1]-2]
maxVal = max(maxVal,dp[i])
return maxVal
C++
class Solution {
public:
int longestValidParentheses(string s) {
int size = s.length();
vector<int> dp(size, 0);
int maxVal = 0;
for(int i = 1; i<size;i++)
{
if(s[i]==')')
{
if(s[i-1]=='(')
{
dp[i] = 2;
if(i-2>=0)
dp[i] = dp[i-2] + dp[i];
}
else if(dp[i-1] >0)
{
if((i-dp[i-1]-1)>=0 && s[i-dp[i-1]-1] == '(')
{
dp[i] = dp[i-1]+2;
if(i-dp[i-1]-2>=0)
dp[i] = dp[i-1] + dp[i-dp[i-1]-2] + 2;
}
}
}
maxVal = max(maxVal, dp[i]);
}
return maxVal;
}
};53.最大子数组和

解题思路
本题依旧采用动态规划的方法来解决:
取状态数组dp[i],其中第i个数值代表以nums[i]结尾的最大连续子数组和。其中dp[i]必须包括了nums[i]这个元素。
1.确定状态
对于dp[i],它是由dp[i-1]以及nums[i]共同决定,需要作如下判断:
如果dp[i-1]<=0,那对于dp[i]而言,dp[i-1]的贡献是负值,这只会使得dp[i]的值越来越小,所以此时dp[i]就取值nums[i];
如果dp[i-1]>0,那么对于dp[i]而言,dp[i-1]对dp[i]是由贡献的,这样会使得当前的dp[i]值可能变得更大,使得连续子数组和可以由更大的值。
2.转移方程
3.初始条件
初始条件:dp[0] = nums[0],以nums[0]结尾的数组中的最大值其实就是自身;
4.计算顺序
要得到dp[i]就需要知道dp[i-1],所以从0开始一致计算到n-1,也即从dp[0]一致到dp[n-1],而后取max(dp[i])返回即可。
优化:
因为我们状态数组dp[i]只和dp[i-1]与nums[i]有关,所以我们可以直接在nums[i]上进行操作,这样可以节省额外的dp数组的空间开销,使得空间复杂度降为O(1)。
代码
python
class Solution(object):
def maxSubArray(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
for i in range(1, len(nums)):
nums[i] = max(nums[i-1], 0) + nums[i]
return max(nums)C++
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int ans = nums[0];
for(int i=1;i<nums.size();i++)
{
// 在nums上直接修改
// nums[i-1]>0,nums[i] = nums[i-1] + nums[i]
// 反之nums[i]保持不变
if(nums[i-1] >0)
nums[i] = nums[i-1] + nums[i];
if(ans < nums[i])
ans = nums[i];
}
return ans;
}
};62.不同路径

解题思路
本题还是使用动态规划,其中题目中要求的是从起点到终点之间的路径由多少条,而从起点出发每次只能往右走或者往下走,那么我们取状态变量dp[i][j],代表从起点到(i.j)位置的路径的数目。
初始条件以及边界条件:
在第一行以及第一列,由于上面或者左边都是处于边界,所以dp[0][j] == dp[i][0] == 1;
确定状态:
dp[i][j]代表起点到(i,j)的路径数目,那么到达(i.j)位置的话,只能从(i-1,j)往下或者是(i,j-1)往右走,那么dp[i][j] = dp[i-1][j] + dp[i][j-1];
转移方程:
计算顺序:
由上述转移方程可知,要想计算dp[i][j],就得知道dp[i-1][j]和dp[i][j-1],所以计算顺序就是从dp[0][0]一行行遍历一直计算到dp[m-1][n-1]。
返回值:
返回dp[n-1]即可。
优化:
要想得到当前位置(i,j)的路径数目,需要得到其左边位置的路径数目和上边位置的路径数目,而我们是逐行遍历的,并且第一行和第一列的值都是初始化好了的,那么我们可以用一个一维数组进行优化:
在循环遍历中,dp开始是上一行的遍历结果,对于当前行,我们的循环都是从1开始,因为0位置已经在初始化的时候定义好了,那么在当前行,dp[1] = dp[0] + 上一行的dp[1],以此类推,其他也是一样的。
举例说明:
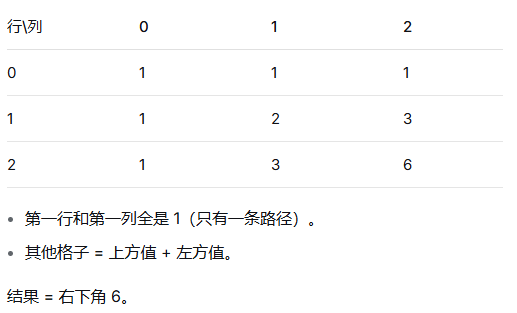
初始化时第一行都是1,从第二行开始遍历,dp[1]需要上方的dp[1]以及左边的dp[0],而此时我们的dp还是上一行的遍历结果[1 1 1],所以dp[1] = dp[0] + dp[1] = 2
对于第一行第二列一样,dp[2]需要上方的dp[2]以及左边的dp[1],dp[1]的值已经更新,而此时我们的dp[1 2 1],所以dp[2] = dp[1] + dp[2] = 3
下一行同理。
代码
python
class Solution(object):
def uniquePaths(self, m, n):
"""
:type m: int
:type n: int
:rtype: int
"""
dp = [1] * n
for i in range(1, m):
for j in range(1, n):
dp[j] += dp[j-1]
return dp[-1]C++
class Solution {
public:
int uniquePaths(int m, int n) {
vector<int> dp(n, 1);
for(int i = 1;i<m;i++)
{
for(int j=1;j<n;j++)
{
// dp[j-1]保存的是d[j]左边的dp结果
// dp[j]是由上边的结果加上左边的结果
// 开始d[j]保存的是上一次循环的结果,也就是上一行的结果
dp[j] += dp[j-1];
}
}
return dp[n-1];
}
};64.最小路径和

解题思路
本题依旧采用动态规划来做:
首先题中要求的是求的从左上角到右下角的最小路径和,我们取dp[i][j]代表从左上角到(i,j)的最小路径和,其中dp[i][j]是由左边以及上边二者的最小值加上当前位置的权值。
初始化以及边界条件:
当i==j==0的时候,这时候在起点,dp[i][j] == grod[i][j];
当处在第0行时,这个时候dp[i][j]只能由左边来提供路径和,也即dp[i][j] = dp[i][j-1] + grid[i][j];
当处在第0列的时候,dp[i][j]只能由上边来提供路径和,也即dp[i][j] = dp[i-1][j] + grid[i][j];
当不是上述情况的时候:
确定状态:
如上所述
计算顺序:
还是从dp[0][0]依次从左到右从上到下逐行逐列遍历到dp[m-1][n-1].
返回值:
dp[m-1][n-1]
优化:
其实我们可以直接在原grid数组上直接进行操作,这样就可以节省额外的空间开销。因为我们是逐个遍历,那么grid数组的值只会在计算当前的值的时候用到,之后用不上:
代码
python
class Solution(object):
def minPathSum(self, grid):
"""
:type grid: List[List[int]]
:rtype: int
"""
for i in range(len(grid)):
for j in range(len(grid[0])):
# 起点
if i==j==0:
continue
# 上边界,只能从左边来
elif i==0:
grid[i][j] += grid[i][j-1]
# 左边界,只能从上面来
elif j==0:
grid[i][j] += grid[i-1][j]
else:
grid[i][j] += min(grid[i-1][j], grid[i][j-1])
return grid[-1][-1]C++
class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
for(int i=0;i<m;i++)
{
for(int j=0;j<n;j++)
{
// 起点值保持不变
if(i==0 && j==0)
continue;
// 第0行,只能由左边的数值已经路径和
else if(i==0)
grid[i][j] += grid[i][j-1];
// 第0列,只能由上边的数值已经路径和
else if(j==0)
grid[i][j] += grid[i-1][j];
// 处于grid数组中的其他值,路径和是由从左边走的以及从上面走的二者的最小值加上当前值
else
grid[i][j] += min(grid[i-1][j], grid[i][j-1]);
}
}
return grid[m-1][n-1];
}
};70.爬楼梯

解题思路
这道题其实思路很简单,我最后一级楼梯可以是从倒数第一级爬一个台阶,也可以是倒数第二级爬2个台阶,那么可以得到状态转移方程:
初始以及边界条件
当n==1的时候,直接返回1,因为1级台阶只有1种方法
确定状态
dp[i]表示爬到第i级台阶共有多少种方法
计算顺序
从第一级台阶开始逐个计算
返回dp[-1]或者dp[n]即可。
优化
由于dp[i] = dp[i-1] + dp[i-2]
当前状态值之和上一个以及上上一个状态值有关,所以我们只需要处理这三个值即可。空间复杂度由O(N)降为O(1)。
代码
python
class Solution(object):
def climbStairs(self, n):
"""
:type n: int
:rtype: int
"""
if n==1:
return 1
dp = [1] * n
dp[1] = 2
for i in range(2,n):
dp[i] = dp[i-1] + dp[i-2]
return dp[-1]优化后的代码
class Solution(object):
def climbStairs(self, n):
"""
:type n: int
:rtype: int
"""
"""
if n==1:
return 1
dp = [1] * n
dp[1] = 2
for i in range(2,n):
dp[i] = dp[i-1] + dp[i-2]
return dp[-1]
"""
if n==1:
return 1
a = 1
b = 2
for i in range(3, n+1):
c = a+b
a = b
b = c
return bC++
空间复杂度为O(N)
class Solution {
public:
int climbStairs(int n) {
// 处理边界条件
if(n==1)
return 1;
vector<int> fn(n);
fn[0] = 1;
fn[1] = 2;
for(int i=2; i<n;i++)
{
fn[i] = fn[i-1] + fn[i-2];
}
return fn.back();
}
};优化后的代码
class Solution {
public:
int climbStairs(int n) {
// 处理边界条件
/*
if(n==1)
return 1;
vector<int> fn(n);
fn[0] = 1;
fn[1] = 2;
for(int i=2; i<n;i++)
{
fn[i] = fn[i-1] + fn[i-2];
}
return fn.back();
*/
if(n==1)
return 1;
// 因为dp[i] = dp[i-1] + dp[i-2]
// 所以只要知道i-1,i-2的值,就知道i的值,所以只需要从0遍历到i-2,共i-1个数即可
int a = 1;
int b = 2;
int sum = 0;
for(int i=3;i<=n;i++)
{
sum = a + b;
a = b;
b = sum;
}
return b;
}
};72.编辑距离

解题思路
本题解题思路依旧是采用动态规划,其中本题要求给定两个单词如何经过最少的操作可以让2个单词相同。
取word1为s,word2为t,在编辑过程中,我们希望问题的规模越来越小,这样才能构建子问题,设s和t的长度分别为m,n,从最后一个元素开始做对比s[m-1]与t[n-1],如果s[m-1]!=t[n-1],则需要经过编辑(插入、删除、替换),使得二者相等;如果s[m-1]==t[n-1],则跳过当前元素,两个字符串都往前移动一位,重复此操作。
因此状态为当前在s中考虑第i个字符,t中的第j个字符:
状态[i,j]定义为s的前i个字符转变为t的前j个字符之间最少的操作数;
dp[i,j]对应的是s[i-1]和t[j-1],此时对于s[i-1]和t[j-1]之间的匹配存在以下情况:
在s[i-1]之后添加t[j-1],之后处理的问题是dp[i, j-1];
删除s[i-1],之后处理的问题是dp[i-1,j];
替换s[i-1],使之和t[j-1]相同,之后处理的问题是dp[i-1, j-1]。
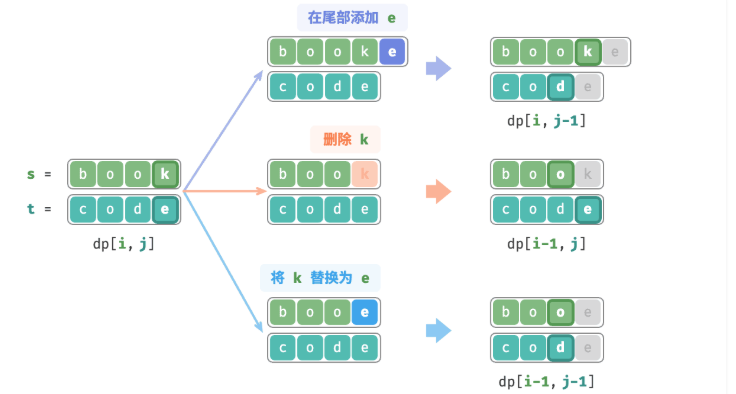
由上述分析可知,dp[i,j]的状态值是由dp[i, j-1]、dp[i-1, j]、dp[i-1][j-1]共同决定的:
上述分析针对的是s[i-1]与t[j-1]不相同的情况,如果s[i-1]==t[j-1]的话,那么则不考虑这两个字符,直接都往前走一个字符,也即:
确定边界条件和初始条件:
当字符串都为空的时候,dp[0,0] = 0;
当s为空,t不为空的时候,dp[0, j] = j,也就是说这时候最少的编辑数目等于t中字符的长度;
当s不为空,t为空的时候,dp[i, 0] = i,也就是说这个时候最少的编辑数目等于s中字符的长度。
由状态转移公式可以知道,dp[i, j]的值依赖左、上、左上这三个值。
优化:
上述复杂度是O(m*n),但是其实因为dp[i, j]的值依赖左、上、左上这三个值,因此我们可以用一个一维数组来替代上述二维数组,以此减少空间开销。
而对于左上的元素,需要保存起来,从而只考虑左和上的这2元素。
代码
python
class Solution(object):
def minDistance(self, word1, word2):
"""
:type word1: str
:type word2: str
:rtype: int
"""
m = len(word1)
n = len(word2)
dp = [[0]*(n+1) for _ in range(m+1)]
# 初始条件
# word1不为空,word2为空的情况
for i in range(m+1):
dp[i][0] = i
# word1为空,word2不为空的情况
for j in range(n+1):
dp[0][j] = j
for i in range(1, m+1):
for j in range(1, n+1):
if word1[i-1] == word2[j-1]:
dp[i][j] = dp[i-1][j-1]
else:
dp[i][j] = min(min(dp[i-1][j], dp[i][j-1]), dp[i-1][j-1]) + 1
return dp[m][n]优化
class Solution(object):
def minDistance(self, word1, word2):
"""
:type word1: str
:type word2: str
:rtype: int
"""
"""
m = len(word1)
n = len(word2)
dp = [[0]*(n+1) for _ in range(m+1)]
# 初始条件
# word1不为空,word2为空的情况
for i in range(m+1):
dp[i][0] = i
# word1为空,word2不为空的情况
for j in range(n+1):
dp[0][j] = j
for i in range(1, m+1):
for j in range(1, n+1):
if word1[i-1] == word2[j-1]:
dp[i][j] = dp[i-1][j-1]
else:
dp[i][j] = min(min(dp[i-1][j], dp[i][j-1]), dp[i-1][j-1]) + 1
return dp[m][n]
"""
m = len(word1)
n = len(word2)
dp = [0]*(n+1)
# 初始条件
# word1为空,word2不为空的情况
for j in range(n+1):
dp[j] = j
# 其余行
for i in range(1, m+1):
# 取出上一行的dp数组的第一个数用leftup保存
leftup = dp[0]
# 当前行的第一个元素是i(dp[i] = i),需要对应好
dp[0] = i
for j in range(1, n+1):
# 保存上一轮的dp[j],也就是当前行当前值的上一行的对应值
temp = dp[j]
if word1[i-1] == word2[j-1]:
dp[j] = leftup
else:
dp[j] = min(min(dp[j-1], dp[j]), leftup) + 1
leftup = temp
return dp[n]C++
class Solution {
public:
int minDistance(string word1, string word2) {
int m = word1.size();
int n = word2.size();
vector<vector<int>> dp(m + 1, vector<int>(n+1, 0));
// 边界条件
// 1.word1不为空,而word2为空的情况
for(int i = 1;i<=m;i++)
dp[i][0] = i;
// 2.word1为空,而word2不为空的情况
for(int j =1;j<=n;j++)
dp[0][j] = j;
for(int i =1;i<=m;i++)
{
for(int j =1;j<=n;j++)
{
// 两字符相同,则word1和word2跳过当前字符
if(word1[i-1]==word2[j-1])
dp[i][j] = dp[i-1][j-1];
else
dp[i][j] = min(min(dp[i][j-1], dp[i-1][j]), dp[i-1][j-1]) + 1;
}
}
return dp[m][n];
}
};优化后的代码
class Solution {
public:
int minDistance(string word1, string word2) {
/*
int m = word1.size();
int n = word2.size();
vector<vector<int>> dp(m + 1, vector<int>(n+1, 0));
// 边界条件
// 1.word1不为空,而word2为空的情况
for(int i = 1;i<=m;i++)
dp[i][0] = i;
// 2.word1为空,而word2不为空的情况
for(int j =1;j<=n;j++)
dp[0][j] = j;
for(int i =1;i<=m;i++)
{
for(int j =1;j<=n;j++)
{
// 两字符相同,则word1和word2跳过当前字符
if(word1[i-1]==word2[j-1])
dp[i][j] = dp[i-1][j-1];
else
dp[i][j] = min(min(dp[i][j-1], dp[i-1][j]), dp[i-1][j-1]) + 1;
}
}
return dp[m][n];
*/
int m = word1.size();
int n = word2.size();
vector<int> dp(n + 1, 0);
// 边界条件
// 首行
for(int i = 1;i<=n;i++)
dp[i] = i;
// 其余行
for(int i =1;i<=m;i++)
{
// 取leftup等于上一行的0位置的值,也即左上
int lefup = dp[0];
dp[0] = i;
for(int j =1;j<=n;j++)
{
// 先将上一轮的结果保存,之后再改变当前值
int temp = dp[j];
// 两字符相同,则word1和word2跳过当前字符
if(word1[i-1]==word2[j-1])
dp[j] = lefup;
else
dp[j] = min(min(dp[j], dp[j-1]), lefup) + 1;
lefup = temp;
}
}
return dp[n];
}
};参考
121.买卖股票的最佳时机

解题思路
本题的话,其实思路很简单,因为题目中要求我们得到最大利润,而最大利润又是需要我们买入的时候,成本要是最低的,然后卖出的时候价格应该是最高的,这样得到的利润才会是最大的。
因此我们取cost作为成本,profit作为当天卖出利润。
初始化cost为极大值,profit为0。
遍历整个prices数组,通过不断比较当天的price和cost的大小不断更新cost的值(取二者较小值),通过比较当天卖出price-cost和profit的值(取二者最大值),来得到可以获得的最大值。
总的来说,就是对于第i天而言,如果第i天卖出股票,那么第i天获得的利润的最大值等于第i天的股票价格-前i天中股票的最低价,然后与已知的最大利润之间作比较,大于已知的最大利润则更新该利润profit的值。
代码
python
class Solution(object):
def maxProfit(self, prices):
"""
:type prices: List[int]
:rtype: int
"""
cost, profit = float('inf'), 0
for price in prices:
# 成本是前i天的价格的最小值,不断更新
cost = min(price, cost)
# 利润是前i天的最高利润,用上面得到的最小买入成本,用当天的价格减去该最小成本,比较得到的利润值
profit = max(profit, price - cost)
return profitC++
class Solution {
public:
int maxProfit(vector<int>& prices) {
int cost = INT_MAX;
int profit = 0;
for(int price : prices)
{
cost = min(price, cost);
profit = max(profit, price - cost);
}
return profit;
}
};139.单词拆分

解题思路
本题依旧使用动态规划,题目中要求我们能够判断s中的单词是由wordDict中的几个单词拼接而成,就返回True。
那么本题定义状态数组dp[i],其中i表示s的前i个字符能否被wordDict中的单词表示;
初始化:
dp = [False] * (n+1);
其中dp[0] = True,表示空字符也可以被表示
执行流程:
①遍历s,for i in range(n),也就是遍历s的所有子串
②边界结束索引j,取值区间是[i+1, n+1)
③判断条件,如果dp[i]是True,并且s[i:j)在wordDict中的话,则把dp[j]置为True。这里需要注意一点,dp的大小是n+1,因为dp中包括了0,0代表空字符,所以dp中1~n才是和字符s中一一对应的,这里也就是说明了为什么是dp[j] = True,此时的j在s中因为左闭右开,j的取值在子串中是取不到的,对应的是s中下一个子串的起始,但是在dp中j的位置恰好对应的s[i:j)子串的末尾,也就是能够用wordDict中某一可以表示的单词结尾。
举个例子,
输入: s = "leetcode", wordDict = ["leet", "code"]
dp和s的对应关系:
| s[0] | s[1] | s[2] | s[3] | s[4] | s[5] | s[6] | s[7] | ||
| "" | l | e | e | t | c | o | d | e | |
| dp[0] | dp[1] | dp[2] | dp[3] | dp[4] | dp[5] | dp[6] | dp[7] | dp[8] | |
| dp | True | False | False | False | True | False | False | False | True |
dp[0] = True
s[0:4] in wordDict,此时的j==4,s中是左闭右开,dp中这个4正好对应一个单词的结尾,将结尾设置为True,等待下一次遍历的时候,i从j位置开始,查询s[i:j]是否和wordDict中某一单词对应。
④返回值:dp[-1]。
代码
python
class Solution(object):
def wordBreak(self, s, wordDict):
"""
:type s: str
:type wordDict: List[str]
:rtype: bool
"""
n = len(s)
dp = [False] * (n+1)
# 空字符可以被表示
dp[0] = True
for i in range(n):
for j in range(i+1, n+1):
# 注意dp中0代表空字符,1代表的s的第0个字符
if (dp[i] and s[i:j] in wordDict):
dp[j] = True
return dp[-1]C++
substr(pos, count)返回从pos开始长度为count的子串,索引是左闭的,即包含pos位置的字符,连续取count个字符。因为是从pos位置开始取,包括了pos,所以等同于python的左闭右开。
find
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
int n = s.size();
unordered_set<string> dict(wordDict.begin(), wordDict.end());
vector<bool> dp(n+1, false);
dp[0] = true;
for(int i=0;i<n;i++)
{
for(int j = i+1;j<=n;j++)
{
string sub = s.substr(i,j-i);
if(dp[i] && dict.find(sub)!=dict.end())
dp[j] = true;
}
}
return dp[n];
}
};count
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
int n = s.size();
unordered_set<string> dict(wordDict.begin(), wordDict.end());
vector<bool> dp(n+1, false);
dp[0] = true;
for(int i=0;i<n;i++)
{
for(int j = i+1;j<=n;j++)
{
string sub = s.substr(i,j-i);
if(dp[i] && dict.count(sub))
dp[j] = true;
}
}
return dp[n];
}
};152.乘积最大子数组
解题思路
本题是53.最大子数组和的变式。
本题中要求一个乘积最大的非空连续子数组,要求非空和连续,并且乘积最大,那么对于nums[i]而言,到下标i的时候,乘积最大有如下情况:
1.当前nums[i] == x为正值,那么对于以nums[i]为右端点的子数组的最大乘积有如下情形:
①nums[i]既是最大;
②需要在[0:i-1]这个区间内找到以nums[i-1]为右端点的最大的乘积,之后再乘以nums[i]也就是x;
2.当前nums[i] == x为负值,那么对于以nums[i]为右端点的子数组的最大乘积有如下情形:
①nums[i]既是最大;
②因为是负值,根据负负得正,需要在[0:i-1]这个区间内找到以nums[i-1]为右端点的最小的乘积,之后再乘以nums[i]也就是x;
那么根据上述情况,我们可以知道,再nums的遍历中,我们需要维护下面2个值:
①以nums[i]为右端点的子数组的最大乘积,记作;
②以nums[i]为右端点的子数组的最小乘积,记作;
对于x=nums[i]:
要么是x自己是最大乘积;
要么就是,x和前面的子数组的最大乘积的结合才是最大乘积,而这个时候前面子数组的最大乘积又有2种,要么是当x>0的时候, ;要么是当x<0的时候,
。
那么在遍历中我们把这些都考虑进去,就不需要单独对每一个nums[i]进行判断了。
与此同时,我们注意到:
这些起始每个只和当前值与前一个状态值有关,因此我们可以优化空间。只用以及
来滚动计算即可,那么状态转移方程可以改写为:
那么对于第一个数而言,以nums[0]为右端点的子数组,最大值和最小值都是自己,所以这个时候我们取以及
。这样的话,代码内部就可以从第0个开始进行遍历。
这里需要注意的是,上面2个式子需要同时计算,不然在计算的时候,
已经是更新之后的值,而不是上一级的值了。
代码
python
class Solution(object):
def maxProduct(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
ans = -float('inf')
fmax = 1
fmin = 1
for x in nums:
fmax, fmin = max(fmax * x, fmin * x, x), \
min(fmax * x, fmin * x, x)
ans = max(ans, fmax)
return ansC++
class Solution {
public:
int maxProduct(vector<int>& nums) {
int ans = INT_MIN;
int fmax = 1;
int fmin = 1;
for(int x: nums)
{
// 用一个中间变量保存fmax,在后面计算fmin的时候,
// 应该用上一级的fmax,不然用到的是更新之后fmax,结果不对
int temp = fmax;
fmax = max(max(fmax * x, fmin * x), x);
fmin = min(min(temp * x, fmin * x), x);
ans = max(ans, fmax);
}
return ans;
}
};221.最大正方形
本题在之前的专题中已经做过,此处不再重复。
279.完全平方数
解题思路
在本题中,要求我们返回和为n的完全平方数的最少数量。
我们把问题分解为一个完全平方数+剩余部分,要使得整体数最少,那么剩余部分的数要最小。这就是原问题与子问题之间的关系。
这里我们用状态变量dp[i]来表示,和为i最少需要多少个完全平方数。
初始化dp,各个位置都为0;
遍历数字n,对于当前位置i,每次都将当前位置赋给dp[i],表示当前最坏的结果就是一直都是1相加,由i个i相加之后得到。
在i中,一定存在一个完全平方数j*j被用到了,取值i-j*j,那么剩下的数值就是i-j*j,那么我们就要判断如何使得i-j*j中完全平方数最少,最优,也就是dp[i-j*j],那么所有的完全平方数就是dp[i-j*j] + 1(其中1代表的是j*j这个平方数,dp[i-j*j]中没有包括整个,只有j*j + i -j *j 才等于此时的i)。
所以需要遍历j,判定条件是i-j*j>=0。
而后比较dp[i],和dp[i-j*j] + 1之间哪个更小,说明对应的完全平方数更少。
最后返回dp[n]即可。
代码
python
class Solution(object):
def numSquares(self, n):
"""
:type n: int
:rtype: int
"""
dp = [0] * (n+1)
for i in range(1, n+1):
dp[i] = i
j = 1
while i - j*j >= 0:
dp[i] = min(dp[i], dp[i-j*j] + 1)
j += 1
return dp[-1]C++
class Solution {
public:
int numSquares(int n) {
// dp[i]表示值为i最少需要多少个完全平方数
vector<int> dp(n+1, 0);
for(int i=1;i<=n;i++)
{
// 代表最差情况,i个1相加得到结果
dp[i] = i;
for(int j = 1;i-j*j>=0;j++)
{
// 取较小值
// 在i中一定存在某个数的完全平方,这里取作j*j
// 那么要使得最少的完全平方数的话,就是i-j*j中要得到的完全平方数要最少
// 因为这里dp[i-j*j]是没有把j这个数的完全平方放进来的,所以需要+1
dp[i] = min(dp[i], dp[i-j*j]+1);
}
}
return dp[n];
}
};300.最长递增子序列

解题思路
本题中所要求的是,在一个给定的整数数组中,找到其中最长的严格单调递增的子序列的长度,但是:
①这个严格单调递增子序列不一定是连续的;
②子序列的最后一个元素未必一定是数组的末尾元素。
那么状态数组的定义:
定义dp[i]是以nums[i]结尾的最长严格单调递增的子序列的长度;
转移方程:
遍历nums,当遍历到nums[i]的时候,这个时候在遍历j,其中j∈[0,i),观察nums[i]和nums[i]之间的大小:
如果nums[i]>nums[j],说明nums[i]是可以放到nums[j]之后,并且也不改变原有数组元素的顺序,所以dp[j]+1,因为nums[i]可以接到以nums[j]结尾的最长子序列的后面(dp[j]),组成新的最长子序列,长度自然就是dp[j]+1。
当nums[i]<=nums[j],此时不满足严格单调递增的情形,所以直接跳过就行;
为什么是 dp[j] + 1 而不是 dp[i] + 1?
因为 dp[j] 是已经计算好的、以 nums[j] 结尾的最长递增子序列长度。
当 nums[i] > nums[j] 时,我们可以把 nums[i] 接到那个子序列的末尾,形成一个新的、更长的子序列。这个新子序列的长度就是 dp[j](原来的长度)加上 1(这个新元素 nums[i]),所以是 dp[j] + 1。
而 dp[i] 本身正是我们正在计算的目标(以 nums[i] 结尾的最长长度),它还没有被确定,因此不能用来作为加数。实际上,我们要从所有可能的 j 中找到最大的 dp[j] + 1,然后把这个最大值赋给 dp[i]。
简单来说:j 是过去的结尾,i 是现在的结尾。把现在的元素接到过去的后面,长度 = 过去长度 + 1。
因为j∈[0,i),对于在这个区间内的j,每遍历一次,我们需要更新dp[i]的值,使得最终dp[i]的值为最大:
初始条件:因为nums中的每一个元素都可以单独组成最长递增子序列,所以给dp中的所有值都赋值为1。
返回值:返回dp数组中的最大值,不是返回dp[n]即可,因为未必是以最后一个元素结尾的序列是最长严格递增的子序列。
上述代码的时间复杂度是O(N^2);题目要求降到o(nlogN);看到对数时间复杂度就想到二分法。
优化
使用贪心+二分,因为题目中的进阶要求是需要时间复杂度是O(nlogn),由此我们想到用二分法:
上面的算法中,我们每一次循环中nums[i]都要和之前nums[j]做比较,因此我们想到的是,能不能避免每次都要回头比较呢?而是维护一个结构,只需要比较一次就可以知道新数应该放在哪个位置:
-
贪心+二分:
tails直接维护每个长度的最小末尾,新数只需二分定位,不需要回头比较所有前面的数。
tails[i] 表示长度为 i+1 的递增子序列的最小末尾值。
例如,对于nums,遍历nums,对于nums[i],在tail中查询是否由比nums[i]大的数,如果有,则在找到的第一个答案中,将该值添加到对应位置的末尾,一次说明,这个长度的递增子序列的最小末尾值应该是nums[i];
反之,如果没有找到任何大于nums[i]的数,那么则在tails中最后新开辟一个位置给nums[i];
最终tails的长度就是题目中所要求的最长的严格递增的子序列长度。因为tails中的元素其实是单调递增的,因为新加入的数nums[i]要和tails中已有的数做比较,如果大于tails中已有的数,则在tails的末尾添加nums[i],如果小于tails中已有的数,则找到第一个小于tails中的数,将其覆盖为nums[i],说明长度为i+1的递增子序列的最小末尾值应该是nums[i]。
例如:nums = [10, 9, 2, 5, 3, 7, 101, 18]
tails初始化为[];
x=10,tails中为空,新建一堆,顶部为10,直接tails = [10];
x=9,其中10>9,9将10覆盖,于是,tails = [9](意义就是长度为1的子序列中,最小末尾值可以是9,而不是10)
x=2,其中9>2,2将9覆盖,于是tails = [2](意义就是长度为1的子序列中,最小末尾值可以是2,而不是9)
x=5,tails中没有大于5的数,因此新开一个堆,于是tails = [2, 5]
x=3,5>3,于是3将5覆盖,tails = [2, 3](意义就是长度为2的子序列中,最小末尾值可以是3,而不是5)
x=7,tails中没有大于7的数,因此新开一个堆。tails = [2, 3, 7]
x=101,tails中没有大于101的数,因此新开一个堆,tails = [2, 3, 7 101]
x=18,tails中101>18,所以18将101覆盖,tails = [2, 3, 7, 18]
最终返回tails的长度,tails.size()即为最长单调递增子序列的长度。
代码
python
class Solution(object):
def lengthOfLIS(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
dp = [1] * len(nums)
for i in range(len(nums)):
for j in range(i):
if nums[i] > nums[j]:
dp[i] = max(dp[i], dp[j] + 1)
return max(dp)C++
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n, 1);
int maxvalue = 0;
for(int i=0;i<n;i++)
{
for(int j =0;j<i;j++)
{
if(nums[i]>nums[j])
{
dp[i] = max(dp[i], dp[j]+1);
}
}
maxvalue = max(maxvalue, dp[i]);
}
return maxvalue;
}
};class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n, 1);
int maxvalue = 1;
for(int i=0;i<n;i++)
{
for(int j =0;j<i;j++)
{
if(nums[i]>nums[j])
{
dp[i] = max(dp[i], dp[j]+1);
maxvalue = max(maxvalue, dp[i]);
}
}
}
return maxvalue;
}
};优化
python(bisect_left实现二分,返回查找到的大于等于x的下标,如果没有找到大于x的数,则返回序列长度,即len(tails))
class Solution(object):
def lengthOfLIS(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
'''
dp = [1] * len(nums)
for i in range(len(nums)):
for j in range(i):
if nums[i] > nums[j]:
dp[i] = max(dp[i], dp[j] + 1)
return max(dp)
'''
# tails维护的是长度为i+1的子序列的最小末尾数
tails = []
for x in nums:
i = bisect_left(tails, x)
# 说明在tails中没有找到大于等于x的数
if i == len(tails):
tails.append(x)
else:
tails[i] = x
return len(tails)
C++(通过lower_bound实现二分,返回迭代器,如果没有大于x的数,则返回end()迭代器)
vector<int> tails;
for(int x:nums)
{
// 找到tails中小于x的第一个数
auto it = lower_bound(tails.begin(), tails.end(), x);
if(it == tails.end())
{
// 没找到比x小的数,另开一个堆
tails.push_back(x);
}
// 反之,则将找到的哪个堆顶元素置为x
else
*it = x;
}
// 最后返回tails的长度就是题中所需要的最长严格单调递增的子序列的长度了
return tails.size();198.打家劫舍

解题思路
题目中要求如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警,那么就是说相邻的房间不能一起偷。
我们取状态变量:dp[i],表示在满足条件下偷前i个房屋能够获得的最大金额。
对于前i个房间:
| 0 | 1 | 2 | 3 | …… | i-4 | i-3 | i-2 | i-1 |
有如下2种情况:
第i-1间房屋,我们偷的话,那么第i-2间房就不能偷,那么此时可以获得的最大金额就是前i-2间房能得到的最大金额加上第i-1间房的金额;
不偷第i-1间房的话,那么此时可以获得的最大金额就是前i-1间房可以获得的最大金额。
最终可以得到的最大金额就是上面2种情况中的较大值,具体转移方程如下:
初始条件:
前0个房间能够偷到的最大金额是0;
前1个房间能够偷到的最大金额是第一个房间的金额;
计算顺序:
要得到dp[i]就要得到dp[i-1]、dp[i-2],所以是自底而上的。
优化,因为dp[i]只和dp[i-1]以及dp[i-2]有关,所以我们可以只维护这2个值。
代码
python
class Solution(object):
def rob(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
# 原始版本
n = len(nums)
dp = [0] * (n+1)
dp[1] = nums[0]
for i in range(2, n+1):
dp[i] = max(dp[i-1], dp[i-2]+nums[i-1])
return dp[n]C++
class Solution {
public:
int rob(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n+1,0);
dp[1] = nums[0];
for(int i=2;i<=n;i++)
{
dp[i] = max(dp[i-1], dp[i-2]+nums[i-1]);
}
return dp[n];
}
};优化
python
class Solution(object):
def rob(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
"""
# 原始版本
n = len(nums)
dp = [0] * (n+1)
dp[1] = nums[0]
for i in range(2, n+1):
dp[i] = max(dp[i-1], dp[i-2]+nums[i-1])
return dp[n]
"""
n = len(nums)
cur, pre = 0, 0
for x in nums:
cur, pre = max(cur, x + pre), cur
return curC++
class Solution {
public:
int rob(vector<int>& nums) {
/*
int n = nums.size();
vector<int> dp(n+1,0);
dp[1] = nums[0];
for(int i=2;i<=n;i++)
{
dp[i] = max(dp[i-1], dp[i-2]+nums[i-1]);
}
return dp[n];
*/
int n = nums.size();
int cur = 0;
int pre = 0;
int temp = 0;
for(int num:nums)
{
temp = cur;
cur = max(cur, pre+num);
pre = temp;
}
return cur;
}
};309.买卖股票的最佳时机含冷冻期

解题思路
题目中的要求就是在卖出股票之后,第二天不能立即买入。要有一个至少要间隔一天的时间才能继续买入股票,也就是所谓的冷冻期。
那么本题中第i天结束的时候你有如下状态:
状态0:持有股票(host)——今天结束的时候手里还有股票(可能昨天就有这股票,今天没有卖出;也可能是你今天刚买入);
状态1:刚卖出(sold)——今天卖出股票;
状态2:观望/冷冻期(rest)——今天结束的时候手里没有股票(可能昨天刚卖出,可能一直没有股票)
三种状态之间的关系:
状态0:
昨天是已经持有,今天选择继续持有;
昨天是观望/冷冻期(状态2),今天选择买入,那么此时的利润要减去今天股票的价格
状态1:
昨天是持有股票(状态0),今天选择卖出,利润要加上今天的股票价格
状态2:
昨天是观望/冷冻期(状态2),今天选择继续观望;
或者是昨天卖出股票(状态1),今天进入冷冻期。
用hold[i]、sold[i]、rest[i] 三个变量表示在第 i 天结束时进入该状态时,我们能获得的最大利润。
由上述分析可知:
边界条件:
最后题目要求的最大利润应该是在sold[i]和rest[i]里面了。
代码
python
class Solution(object):
def maxProfit(self, prices):
"""
:type prices: List[int]
:rtype: int
"""
n = len(prices)
if n==0:
return 0
# 定义状态数组
hold = [0] * n
sold = [0] * n
rest = [0] * n
hold[0] = -prices[0]
for i in range(1, n):
# 状态转移方程
hold[i] = max(hold[i-1], rest[i-1]-prices[i])
sold[i] = hold[i-1] + prices[i]
rest[i] = max(rest[i-1], sold[i-1])
# 最终的最大利润在rest和sold之间
return max(rest[n-1], sold[n-1])C++
class Solution {
public:
int maxProfit(vector<int>& prices) {
int n = prices.size();
if(n==0)
return 0;
// 三种状态的初始化
vector<int> hold(n, 0);
vector<int> sold(n, 0);
vector<int> rest(n, 0);
hold[0] = -prices[0];
for(int i=1;i<n;i++)
{
// 状态转移方程
hold[i] = max(hold[i-1], rest[i-1] - prices[i]);
sold[i] = hold[i-1] + prices[i];
rest[i] = max(rest[i-1], sold[i-1]);
}
// 最终的利润最大值在rest和sold之间
return max(sold[n-1], rest[n-1]);
}
};312.戳气球

解题思路
本题如果是从正向思考的话,一个一个去戳破气球,那么因为每戳破一个气球,余下气球之间的相邻关系就改变了,比如戳破第i个气球,那么原本不相邻的i-1和i+1的气球就是相邻的了,那么这些气球之间就会存在依赖,不利于构建子问题。
因此我们反向思考,从最后一个气球反过来看:
我们先延申整个数组,给它加上左右边界,值都是1,
定义状态数组:状态数组dp[i][j],表示在开区间(i,j)中可以获得的最大硬币数目。当j=i+1时,dp[i][j] = 0;那么对于最后一个气球k,它可以获得的硬币数目是vals[k]*vals[i]*vals[j],因为此时的k处在(i,j)区间内,区间内只有k这一个气球,而区间(1,k)以及(k,j)中的气球都已经被戳破了,所以需要关注在区间(i,k)和(k,j)中可以获得的最大硬币数目,也就是dp[i][k]和dp[k][j],由此原问题和子问题就由此构建出来了,那么可以获得的最大硬币数目就是:
那么最终题目要求的最大硬币数目其实就是dp[0][n+1]。
初始条件:
dp[0][0] = 0;
dp[0][1] = 0;(区间内没有气球,所以置零)
原数组需要加上左右边界,值都是1,也即vals[0] =1, vals[n+1] = 1,中间[1,n]就是原数组的值。
计算顺序
这里需要从小到大计算区间长度len(也就是j-i),由于大区间(i,j),依赖于更小的区间(i,k)和(k.j),所以(i,j)之间必须可以放气球的话,那么区间长度len就得从2开始(i=0,j=2,k=1),一直到len=n+1,得到最终结果,这也是确保,在计算dp[i][j]时更小的依赖已经计算完毕。
len的区间长度从2(i=0, j=2,区间内只有一个气球),到len=n+1(i=0,j=n+1,区间内就是原数组的所有值),所以len的遍历顺序是j-i的长度,从2~n+2(这个区间内才会有真气球)。
代码
python
class Solution(object):
def maxCoins(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
n = len(nums)
# 扩充边界,得到n+2长度的数组
vals = [1] + nums + [1]
# 构建状态数组
dp = [[0] * (n+2) for _ in range(n+2)]
for length in range(2, n+2):
for i in range(0, n+2-length):
j = i+length
for k in range(i+1,j):
# 状态转移方程
dp[i][j] = max(dp[i][j], dp[i][k]+dp[k][j]+vals[i]*vals[k]*vals[j])
return dp[0][n+1]
C++
class Solution {
public:
int maxCoins(vector<int>& nums) {
int n = nums.size();
// 扩充边界
vector<int> vals(n+2, 1);
for(int i=0;i<n;i++)
vals[i+1] = nums[i];
// 定义状态数组dp
// dp[i][j]表示在开区间(i,j)中可以获得的最大硬币数目
vector<vector<int>> dp(n+2, vector<int>(n+2, 0));
// 逻辑处理
for(int len=2;len<n+2;len++)
{
for(int i=0;i<n+2-len;i++)
{
int j = i+len;
for(int k=i+1;k<j;k++)
{
dp[i][j] = max(dp[i][j], dp[i][k]+dp[k][j]+vals[i]*vals[k]*vals[j]);
}
}
}
// 返回dp[0][n+1]就是题目要求的整个nums中的最大硬币数目
return dp[0][n+1];
}
};322.零钱兑换

解题思路
本题的解题思路如下:
题目中要求在给定的整数数组中,计算并返回可以凑成总金额的所需的最小的硬币个数;
那么我们取状态数组dp[i]表示凑成金额i所需要的最少的硬币个数。
那么对于dp[i],要凑i元的金额,我们需要遍历整个coins数组,在数组中进行枚举,然后返回其中的最小的个数。也就是外层循环是遍历i从0(1也可以)到amount,内层循环是遍历coins数组:
对于金额i,我们在coins数组中先取处coin,那么余下的i-coin金额一定是比i要小的,那么也就是说dp[i-coin]所需要的最少的硬币个数在前面是已经确定了的,因此dp[i] = dp[i-coin] +1(+1是因为我们取出了coin这个硬币,所以+1)。
因此状态转移方程就是:
初始条件:
因为这里是取最小值,那么dp中的原始值都要是最大值float('inf'),而dp[0]表示金额0的最少硬币数==0,也即dp[0] = 0。
返回值:
比较dp[amount]与float('inf)之间的关系,相等返回-1,说明没有任何一种硬币组合能组成总金额;反之则返回dp[amount]。
计算顺序:
从上面的分析可以知道,计算顺序就是从1元一直计算到amount元,顺序进行。
代码
python
class Solution(object):
def coinChange(self, coins, amount):
"""
:type coins: List[int]
:type amount: int
:rtype: int
"""
# dp[i]表示凑i元所需要最少的硬币个数(需要遍历整个coins数组,取最小的个数)
# dp[i] = min(dp[i], dp[i-coin]+1)
# 其中dp[i-coin]+1是,我先取出coin,那么余下的金额就是
# i-coin,肯定比i小,在之前就已经被确定下来了,也就是dp[i-coin]的值
# 初始化
dp = [float('inf')]*(amount+1)
dp[0] = 0
for i in range(amount+1):
for coin in coins:
if i>= coin:
dp[i] = min(dp[i], dp[i-coin]+1)
# 返回dp[amount],如果不等于float('inf),说明找到了最小值
# 反之则说明没有任何一种硬币可以组成amount
return dp[amount] if dp[amount]!=float('inf') else -1
class Solution(object):
def coinChange(self, coins, amount):
"""
:type coins: List[int]
:type amount: int
:rtype: int
"""
# dp[i]表示凑i元所需要最少的硬币个数(需要遍历整个coins数组,取最小的个数)
# dp[i] = min(dp[i], dp[i-coin]+1)
# 其中dp[i-coin]+1是,我先取出coin,那么余下的金额就是
# i-coin,肯定比i小,在之前就已经被确定下来了,也就是dp[i-coin]的值
"""
# 初始化
dp = [float('inf')]*(amount+1)
dp[0] = 0
for i in range(amount+1):
for coin in coins:
if i>= coin:
dp[i] = min(dp[i], dp[i-coin]+1)
# 返回dp[amount],如果不等于float('inf),说明找到了最小值
# 反之则说明没有任何一种硬币可以组成amount
return dp[amount] if dp[amount]!=float('inf') else -1
"""
# 初始化
dp = [float('inf')]*(amount+1)
dp[0] = 0
for coin in coins:
for i in range(coin, amount+1):
dp[i] = min(dp[i], dp[i-coin]+1)
# 返回dp[amount],如果不等于float('inf),说明找到了最小值
# 反之则说明没有任何一种硬币可以组成amount
return dp[amount] if dp[amount]!=float('inf') else -1
C++(注意数据溢出,初始设置最大值设置INT_MAX/2,不然后面dp[i-coin]+1会溢出)
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
// 初始化状态变量
vector<int> dp(amount+1, INT_MAX/2);
dp[0] = 0;
for(int i=0;i<=amount;i++)
{
for(int coin:coins)
{
// 保证数组下标索引的有效性
if(i>=coin)
{
// 状态转移方程
dp[i] = min(dp[i], dp[i-coin]+1);
}
}
}
return dp[amount]==INT_MAX/2?-1:dp[amount];
}
};class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
// 初始化状态变量
/*
vector<int> dp(amount+1, INT_MAX/2);
dp[0] = 0;
for(int i=0;i<=amount;i++)
{
for(int coin:coins)
{
// 保证数组下标索引的有效性
if(i>=coin)
{
// 状态转移方程
dp[i] = min(dp[i], dp[i-coin]+1);
}
}
}
return dp[amount]==INT_MAX/2?-1:dp[amount];
*/
vector<int> dp(amount+1, INT_MAX/2);
dp[0] = 0;
for(int coin:coins)
{
for(int i=coin;i<=amount;i++)
{
// 状态转移方程
dp[i] = min(dp[i], dp[i-coin]+1);
}
}
return dp[amount]==INT_MAX/2?-1:dp[amount];
}
};416.分割等和子集

解题思路
本题中定义状态变量dp[i],表示能否选出若干数使得和为j。
状态转移:
如何判断是否可以把整个nums分成2个子集,首先我们取子集的和为target,接着遍历nums数组,而后倒序遍历j从target倒序到num,在这个过程中,观察dp[j-num]是否为True,也就是j-num这个数值是不是可以被凑到,如果可以那么j-num+num = j也是可以凑到的,那么将其置为True。
for num in nums:
for j in range(target, num-1,-1):
if dp[j-num]:
dp[j] = True初始条件:
首先题目中要求的是给定的数组要将它分割成2个子集,使得这两个子集的元素和相等,那么这也就是说明这个给定的数组nums的和得是偶数,因为分成两个等和的子集的值不能是小数。
对于状态数组,其中第0个数,也就是能否选出若干个数使得和为0,这个设置为True;
而其余数则初始化为False。
dp数组大小为target+1,因为要加上0这个值。
返回值:
dp[target]
至于为什么要倒序遍历
如果我们正序遍历的话:
for num in nums:
for j in range(num, target+1):
if dp[j-num]:
dp[j] = True那么dp[j]的更新是从小到达进行的,dp[j-num]可能在之前已经被遍历更新过,而之后又在更大的j的时候又再次使用了它。而题目中说明了一个数只能被使用一次,那么就说明出现了重复使用的情况。比如nums=[2],target = 4
显然一个数是凑不出来4的,结果为False;
从正序来看:
num = 2:
j=2, dp[2-2] = dp[0] = True;
j=3, dp[3-2] = dp[1] = False;
j=4, dp[4-2] = dp[2](之前更新过的值)= True
但是明显一个2凑不出4来,所以结果有问题,这是因为我们更新j=4的时候,用到了先前在j=2时更新中已经使用过的dp[2],这相当于把2用了2次,不满足题意。
从倒序来看:
num = 2:
j=4, dp[4-2] = dp[2] = False;
j=3, dp[3-2] = dp[1] = False;
j=2, dp[2-2] = dp[0] = True'
结果dp[target] = False;正确。
倒序保证了每个物品最多被使用一次:当更新dp[j]时,它依赖的dp[j-num]还没有被本轮更新过,仍然是旧的(还没加入当前物品)状态。
正序则会让小金额先被更新,然后大金额用到了刚更新的小金额,从而导致同一个物品被多次使用。
2种理解:
-
第一种理解:“原来用
num可以凑出j,现在对于更大的j,我必须再凑一个num才能凑出这个更大的j,说明num用到了两次。”
这直接描述了重复使用的过程:先凑出j(这里j=2),再加一个num凑出j+num(即 4)。自然就是用两次。 -
第二种理解:“在判断
dp[4-num]时,因为4-num和先前遍历更新的一个dp[j]相同,说明了num用到了两次。”
这里的“先前遍历更新的一个dp[j]”就是指dp[2],而dp[2]正是由本轮num刚刚更新得到的。因此dp[4]依赖了一个已经“用过一次”的状态,相当于再次使用num。
所以,无论是从“递推过程”还是“依赖状态来源”来看,核心都是:正序更新使得小状态被当前物品更新后,大状态又利用了这个已更新的小状态,从而导致同一物品被多次使用。
代码
python
class Solution(object):
def canPartition(self, nums):
"""
:type nums: List[int]
:rtype: bool
"""
# target的先决条件
target = sum(nums)
if target%2 == 1:
return False
target /= 2
# 初始化
dp = [False] * (target + 1)
dp[0] = True
# 状态转移
for num in nums:
for j in range(target, num-1, -1):
if dp[j-num]:
dp[j] = True
# 返回值
return dp[target]
C++
class Solution {
public:
bool canPartition(vector<int>& nums) {
// target的确定
// nums的和只能为偶数
int n = nums.size();
int total = accumulate(nums.begin(), nums.end(), 0);
if(total%2==1)
return false;
int target = total /2;
// 定义状态数组
vector<bool> dp(target+1, false);
dp[0] = true;
// 状态转移
for(int num :nums)
{
for(int j = target;j>=num;j--)
{
if(dp[j-num])
dp[j] = true;
}
}
// 返回值
return dp[target];
}
};494.目标和

解题思路
本题的解题思路如下:
首先nums数组的总和为sum,设其中添加了+号的部分的总和为add,其中添加了-号部分的总和的绝对值是sub,存在如下关系:
由上可知:
由此可知,sum+target必须要是偶数,add也不可能超过sum,target的值也不可能超过sum。
题目中要求通过构造找到运算结果等于target的不同表达式的数目,实际上add确定了,sub也随之确定,所以我们只需要找到满足子集的和为add的数目,也就是说在nums中存在多少种方案使得某些子集的和为add。
状态变量:
dp[j]:表示,组成和为j的子集共有多少种方案或者选法;
转移方程:
在组成和为add的子集中,数组中的一个数只能被选择一次,或者说不被选择,那么对于dp[j]而言,对于数组中的每个数num,存在以下2种情况:
不选择num,那么dp[j]不变,继承之前的方案数;
选择num,那么余下的部分的总和就是j-num,对应的方案数目就是dp[j-num];
上述2种情况合并,得到总的方案数:
初始条件:
dp[0] = 1(对于总和为0的方案,就是什么都不选这一种情形)
其余的初始化都初始化为0。
sum+target必须要是偶数,add也不可能超过sum,target的值也不可能超过sum。
需要判断(sum+target)%2==1?,以及abs(target)>sum这两个判定条件。
遍历顺序:
因为如果是正序的话,dp[j]会用到之前已经更新或者使用过的dp[j-num],这就造成了一个数被多次使用,并不符合题目中一个数只能被使用1次或者0次的可能,故本题需要逆序。
返回值:
dp[add]。
代码
python
class Solution(object):
def findTargetSumWays(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: int
"""
# 初始化,判定合理性
total = sum(nums)
if (total + target) % 2 == 1:
return 0
if abs(target) > total:
return 0
# target <= add < total
add = (total + target) / 2
# 状态数组
# dp[j],表示组成子集和为j共有多少种方案
dp = [0] *(add +1)
dp[0] = 1
# 转移方程
for num in nums:
for j in range(add, num-1, -1):
dp[j] += dp[j-num]
return dp[add]C++
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
// 初始化add
int add = 0;
int sum = accumulate(nums.begin(), nums.end(), 0);
// 判断合理性
// target的数值不可能大于sum,题中说明了nums是非负正整数
// sum+target的值必须得是偶数,add是nums中子集的和,不可能为小数之类的
if(abs(target) > sum)
return 0;
if((sum + target) % 2 == 1)
return 0;
add = (sum + target) / 2;
// 初始化dp
vector<int> dp(add+1, 0);
dp[0] = 1;
// 状态转移
for(int num :nums)
{
for(int j = add; j>=num;j--)
{
dp[j] += dp[j-num];
}
}
// 返回值
return dp[add];
}
};55.跳跃游戏

解题思路
本题中需要我们判断是否能够到达最后一个下标,其中数组中的每个元素代表在该位置可以跳跃的最大值,那么假设我们在当前位置可以跳跃的最大下标是maxreach,遍历整个nums数组,
对于某一个下标i>maxreach,说明当前位置无法到达这个i下标所在的位置,则直接返回False;
反之则说明当前位置是可以达到i的,而i下标位置可以跳跃的最大长度是nums[i],那就说明maxreach可以达到的最大长度是i+nums[i],更新maxreach为i+nums[i],也即是maxreach = max(maxreach, i+nums[i]);
如果maxreach>=n-1,说明当前位置的最大下标超过了数组的最大下标,说明可以达到最后一个下标,返回True。
代码
python
class Solution(object):
def canJump(self, nums):
"""
:type nums: List[int]
:rtype: bool
"""
# 维护当前位置可以跳跃到的最大下标
maxreach = 0
for i in range(len(nums)):
# 如果当前下标i是我们maxreach达不到的,所以我们当前位置是到达不了这个i下标,直接返回false
if i>maxreach:
return False
# 反之说明可以到达,那么就直接更新maxreach的值,maxreach可以到达的最大下标是i
# 到了位置i,可以跳跃的长度又是nums[i],所以maxreach = i+nums[i]
maxreach = max(maxreach, i+nums[i])
# 当maxreach超过了数组的最大下标,说明可以跳跃到数组的最大下标的,直接返回true即可
if maxreach >=len(nums) -1:
return True
return TrueC++
class Solution {
public:
bool canJump(vector<int>& nums) {
// maxreach是我们维护的当前位置可以到达的最大下标
int maxreach = 0;
for(int i=0;i<nums.size();i++)
{
// 如果nums[i]所在的下标是大于maxreach的,说明我们当前位置是达到不了i的,而i又是在数组下标[0~n-1]之间
// 说明当前位置是到达不了数组的最后一个下标
if(i>maxreach)
return false;
// 反之说明当前位置到达的最大距离是i,而下标i上可以跳跃的最大长度是nums[i],
// 说明可以条约的最大长度是i+nums[i],更新maxreach
maxreach = max(maxreach, i+nums[i]);
// 如果maxreach大于数组的最后一个下标,说明了从第一个下标是可以到达最后一个下标的,返回true
if(maxreach>=nums.size()-1)
return true;
}
return true;
}
};56.合并区间

解题思路
本题的解题思路如下:
本题中要求我们要把所有的重叠的区间合并,对于[1, 3] [2, 6]这样的区间得合并,对于[1, 4] [4, 5]这样的区间也得合并,我们不难发现,可以合并的基本上都满足,当前子区间的左端点要小于等于上一个子区间的右端点的值,那么具体做法如下:
初始化最后结果列表为ans=[]
首先我们把intervals中的所有区间的左端点进行排序,而后遍历intervals数组,观察其中子区间p的左端点和上一个子区间的右端点大小,如果满足左端点的值小于等于上一个子区间的右端点的值,
即:
或者
则合并这两个区间,因为左端点是从小到大排序了的,左端点还是上一个子区间的左端点,但是右端点得是当前子区间和上一个子区间的右端点的最大值,比如[1, 4] [2, 3]合并后的子区间就是[1,4];再比如[1, 3] [2, 4]合并后的子区间就是[1 , 4] 。
或者
反之不满足就直接在ans最后添加就行。
最后返回ans即可。
代码
python
class Solution(object):
def merge(self, intervals):
"""
:type intervals: List[List[int]]
:rtype: List[List[int]]
"""
# 把intervals左端点按照从小到大进行排列
intervals.sort(key = lambda p:p[0])
ans = []
for p in intervals:
# 当前intervals中的区间的左端点小于ans中最后一个区间的右端点
# 则可以合并区间
# 此时更新右端点为ans中最后一个区间的右端点和p区间右端点的最大值
if ans and p[0] <=ans[-1][1]:
ans[-1][1] = max(ans[-1][1], p[1])
# 反之,说明这两个区间不相交
else:
ans.append(p)
return ansC++
在 C++ 中,sort(intervals.begin(), intervals.end()) 默认使用 vector<int> 的 operator<,它会按照 字典序 比较两个 vector<int>:即先比较第一个元素,如果相等再比较第二个元素,依此类推。
因此,对于形如 [[1,3],[2,6],[2,4]] 的二维数组,默认排序的结果是:
-
先按每个区间的左端点升序排列
-
左端点相同时,再按右端点升序排列(因为
vector的第二元素也会参与比较)
在合并区间问题中,这样排序是可以接受的,因为:
-
左端点相同时,右端点小的排在前面,不影响合并逻辑(合并时会取最大右端点)
-
如果显式只按左端点排序(忽略右端点),也完全可以,但默认排序实际上更细致。
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
// 让intervals中的每个子区间的左端点按照从小到大排列
sort(intervals.begin(),intervals.end());
vector<vector<int>> ans;
for(auto &p:intervals)
{
// 满足p的左端点的值要小于等于ans的最后一区间的右端点的值,则可以合并区间
if(!ans.empty() && p[0]<=ans.back()[1])
// 合并区间的右端点为and最后区间的右端点的值与p的右端点的值的最大值
ans.back()[1] = max(p[1], ans.back()[1]);
else
// 反之压入ans中
ans.push_back(p);
}
return ans;
}
};406.根据身高重建队列

解题思路
本题的我们对身高先进行降序排列,对身高相同的对k进行升序排列,那么为什么这么做呢?
首先为什么要先对身高降序排列呢?
对身高先进行降序排列,在结果队列当中,当前处理的是p,已经存放在数组中的都是身高大于等于p的,而p要求前面要有k个大于等于它身高的元素,那我们把p插入到当前队列的k索引下标处,那么此时队列的前面(0,k-1)就是存在k个大于等于p身高的数,满足条件。
如果后面有比p的身高要小的元素,但是k值很小,会插入到当前p的前面,会增加p前面人的数量,但是对于p而言,前面身高大于等于它的人数并没有改变,不会改变k的计数,不会破坏原来的k的大小。
为什么要对身高相同的对k进行升序排列呢?
倘若我们对身高相同不进行升序排列呢?比如存在一个[6, 4] [6,5],如果说k大的先放到队列中,那么[6, 5]先放到队列当中,队列当中身高大于等于6的有5个,而后再放入[6,4],[6, 4]得插入到[6, 5]之前,那么[6, 5]之前所保持的队列前面有5个大于等于6的就不对了,因为此时[6, 4]的加入,使得这个5不满足了,此时是6,所以不能降序排列。
应当先往队列当中放k较小的[6,4],之后再放[6,5],这样k值之间关系才得以满足,不会被打乱。
代码
python
python中的lambda表达式
lambda 参数列表: 表达式people.sort(key=lambda x: (-x[0], x[1]))
or
people = sorted(people, key = lambda x:(-x[0], x[1]))
lambda x: (-x[0], x[1]) 接收一个元素 x(即 [h, k]),返回一个元组 (-h, k)。
排序时,Python 会先比较元组的第一个元素(即 -h),如果相等再比较第二个元素(即 k)。
由于 -h 是负的,所以 h 大的(即身高高的)对应的 -h 小,会排在前面,实现了降序。
当 -h 相同时(即身高相同),比较 k 值,k 小的排在前面,实现了升序。class Solution(object):
def reconstructQueue(self, people):
"""
:type people: List[List[int]]
:rtype: List[List[int]]
"""
# 构造结果数组
res = []
# 对people队列中h进行降序排列,k进行升序排列
people = sorted(people, key = lambda x:(-x[0], x[1]))
for p in people:
# res元素长度小于当前p的k索引,也就是说明当前res队列的元素,大于等于p的元素个数不满足k
# 直接再res末尾加上p
if len(res) <= p[1]:
res.append(p)
# 反之就是说res的长度已经是大于当前p的k值,说明队列中元素的数目是大于当前p中的k值
# 那么我们直接再res的索引p[1]处,插入p即可
else:
res.insert(p[1],p)
return resC++
注意这里需要自定义排序的比较函数
还有就是在插入到时候,插入到索引为k的位置,就是ans.begin()+p[1],就是索引为k的位置。
sort(people.begini(), people.end(), [](const vector<int>&a, const vecor<int>&b)
{
return a[0] > b[0] ; // 降序排列
};
sort(people.begini(), people.end(), [](auto&a, auto&b)
{
return a[0] > b[0] ; // 降序排列
};class Solution {
public:
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
vector<vector<int>> ans;
// 这里需要自己重构这个排序
sort(people.begin(), people.end(), [](const vector<int>& u, const vector<int>&v)
{
return u[0] > v[0] || (u[0] == v[0] && u[1] < v[1]);
});
// 逻辑处理
for(auto& p:people)
{
// ans中元素长度不满足p[1],直接在ans末尾添加p
if(ans.size()<=p[1])
ans.push_back(p);
// 满足的话,就在p[1]==k的位置插入p
else
ans.insert(ans.begin()+p[1], p);
}
return ans;
}
};621.任务调度器

解题思路
本题的解题思路如下:
题目中要求的是,每2个相同种类的任务之间必须要有长度为n的冷却时间,在这个冷却时间内,我们可以取填充别的任务,来达到这个n的冷却时间;
那么假设tasks中出现次数最多的任务,次数是maxExec,可能有1个,也可能有多个都出现了maxExec次。
而count_maxExec 是任务次数也达到最大值 maxExec 的任务种类数。
而假设首先我们取出其中的一个任务A,然后把它排列在一块,每2个A之间空出n的冷却时间,用来填充n个不相同的任务,最后一个A之后接上其余的maxExec-1个任务,因为这些任务不相同,没有所谓的冷去时间。
而其余的maxExec个任务都一起穿插在这些n中,会有如下情况(假设tasks = ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C'] n=3:
①这些任务填不满n的冷却时间:
A _ _ _ A _ _ _ A
那么最终的填充情况就是:
A B C _ A B C _ A B
总共所需的时间是total_time = (maxExec -1 ) * (n+1) + count_maxExec,这个地方等于10;
②这些任务可以填满n的冷却时间,甚至是超过了冷却时间假设tasks = ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C'] n=2:
A _ _ A _ _ A ====> A B C A B C A B
此时最终所需要的最短时间间隔是8,就是tasks的任务总数len(tasks)。
如果n=1:
A B A B A B ,2个C可以穿插在任意位置,只要不相邻即可,举一种例子:A B A C B A B C
此时最终所需要的最短时间间隔是8,同样是tasks的任务总数len(tasks)。
所以最终的最短时间间隔是取上述2种情况的最大值:
如果total_time要大于len(tasks),说明冷却时间内部有空闲;
如果total_time小于len(tasks),说明任务多到可以填满所有空闲,那么实际时间就由任务总数决定。
在上述例子中,情况1,任务总数len(tasks) = 8,但是实际需要的时间是10,所以是取最大值;
在情况2中,任务总数是8,按照公式计算(3-1)*(2+1)+ 2 = 8;
如果是n=1的情况,公式得到的是(3-1)*(1+1)+ 2 = 6,但是实际需要8次才可以。
综上所述,最终的最短时间间隔就是取max(total_time, len(tasks)).
代码
python
class Solution(object):
def leastInterval(self, tasks, n):
"""
:type tasks: List[str]
:type n: int
:rtype: int
"""
# 统计每个字符出现的次数
freq = [0] * 26
for task in tasks:
freq[ord(task) - ord('A')] += 1
# 找到最大出现次数
max_freq = max(freq)
# 计算有多少个任务的次数等于最大出现次数
max_count = freq.count(max_freq)
# 计算桶时间
total_time = (max_freq - 1)*(n + 1) + max_count
# 取最大值
return max(total_time, len(tasks))C++
*max_element
在 C++ 中,max_element 是标准库 <algorithm> 里的一个函数,用于在指定范围内找到最大元素的位置(迭代器)。
int max_freq = *max_element(freq.begin(), freq.end());-
freq.begin()和freq.end()分别是 vector 的起始迭代器和结束迭代器,表示整个freq数组的范围。 -
max_element会遍历这个范围,返回一个迭代器(可以理解为指向该元素的指针/索引),它指向找到的最大元素。 -
由于我们需要的是元素的值而不是位置,所以前面加
*(解引用操作符)来取得该位置上的值。
也就是说:*max_element(...) 就等于 freq 数组中的最大值。
class Solution {
public:
int leastInterval(vector<char>& tasks, int n) {
// 统计每个任务的出现次数
vector<int> freq(26,0);
for(char task:tasks)
{
freq[task-'A']++;
}
// 计算最大出现次数,最大出现次数对应的任务的个数
int max_freq = *max_element(freq.begin(), freq.end());
int max_count = 0;
for(int f:freq)
{
if(f==max_freq)
max_count++;
}
// 计算桶时间
int total_time = (max_freq-1)*(n+1) + max_count;
// 返回比较最大值
return max(total_time, (int)tasks.size());
}
};581.最短无需连续子数组

解题思路
本题使用的方法如下:
对整个数组采取从左往右,以及从右往左2次遍历,分别找到出现乱序的右边界和左边界;
因为整个数组是要求升序排列,只是某些部分数字的顺序被打乱了,因此我们要找出这部分打乱的最短的数组,使得它按照升序排列之后,整个数组都是升序。
从左往右遍历:对于升序排列,每个数 >= 左边所有数的最大值。如果存在某个数 nums[i] < max_left(即比左边的最大值还小),说明它需要排序,更新right = i。;
从右往左遍历:对于升序排列,每个数 ≤ 右边所有数的最小值。如果存在某个数 nums[i] > min_right(即比右边的最小值还大),说明它需要排序,更新 left = i。
对于right和left值,如果right<=left,说明不存在这个区间,原数组就是升序排列的,返回0;
反之,则返回right - left +1即可。
为什么[left , right]就是所要求的最短子数组:
因为数组要求是升序排列的,那么[0,left-1]是升序的,[right+1, n-1]是升序的,而[left, right]中是因为我们发现了在这个区间存在不满足升序的数,任何更短的不能使得整个数组升序,再往外延申会包括本身就是升序的元素,所以[left, right]区间就是最短子数组区间。
初始化:
left= n
right = -1
因为从左往右遍历是找right,right一开始的值就得比原数组的所有下标都要小,取-1,而后不断遍历更新更大的值;
而从右往左遍历是找left,left一开始的值就得比原数组所有的下标都要大,取n,而后不断遍历更新更小的值;
其实取left = n-1和right=0也可以,因为最后的判定条件是left<right,满足才返回right - left+1,即使是数组中只有一个元素,left = 0,right= 0,同样不满足left<right,依旧返回0;
而取left = n,right = -1,是为了防止最后的判定条件是left<=right的情形,这样当遇到只有一个元素的数组的时候,如果是上述情况会返回1,但是实际应该返回0,而在这种情况下left = n,right = -1,即使是left<=right这个条件,也不会被满足,直接返回0。
所以说left取n,right取-1是一种更为保险的做法。
代码
python
class Solution(object):
def findUnsortedSubarray(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
n = len(nums)
left = n
right = -1
# 从左往右遍历
max_left = nums[0]
for i in range(1, n):
if nums[i] < max_left:
right = i
else:
max_left = nums[i]
# 从右往左遍历
min_right = nums[-1]
for i in range(n-1, -1, -1):
if nums[i] > min_right:
left = i
else:
min_right = nums[i]
return right-left+1 if left < right else 0
C++
class Solution {
public:
int findUnsortedSubarray(vector<int>& nums) {
int n = nums.size();
int left = n;
int right = -1;
// 从左往右遍历
int max_left = nums[0];
for(int i=1;i<n;i++)
{
if(nums[i]<max_left)
right = i;
else
max_left = nums[i];
}
// 从右往左遍历
int min_right = nums[n-1];
for(int j=n-2;j>=0;j--)
{
if(nums[j] >min_right)
left = j;
else
min_right = nums[j];
}
return left<right?right - left +1:0;
}
};253.会议室II

解题思路
用双指针模拟事件顺序
本题我们使用双指针来表示会议的开始和结束时间,在intervals中,我们遍历每一个元素,将起始时间和结束时间都按顺序保存在starts和ends数组中,然后比较这两个数组中的元素:
假设i代表下一个事件的开始时间,j代表下一个事件的结束时间。
关键在于:比较starts[i]和ends[j]之间的大小关系
如果starts[i]< ends[j] ,说明下一个未处理的开始时间是小于下一个未处理的结束时间,说明接下来要发生的是会议开始,而上一个会议还没有结束,所以我们应该新开一个会议室;
如果starts[i] >= ends[j],说明下一个未处理的开始时间是大于下一个未处理的结束时间,说明接下来要发生的是会议结束,会有会议室空出来复用,此时会议室的数量保持不变。
举例说明:
假设有三个会议:
-
A: [0, 30]
-
B: [5, 10]
-
C: [15, 20]
starts = [0, 5, 15] ends = [10, 20, 30] room代表需要的会议室数目
按照常理[0, 30]分配一个会议室,而[5, 10]分配一个会议室,时间结束后[15, 20]继续利用这个会议室进行会议。所以总共是2个。
i= 0,starts[i] = 0 , ends[j] = 10
starts[i] < ends[i],那么就是说明下一个事件是开始,那么就需要新开一个会议室,room+1,room =1。
i= 1, starts[i] = 5, ends[j] = 10
starts[i] < ends[j],那么就是说明下一个事件是开始,但是此时已经有一个会议在进行[0, 30],没有任何会议结束,因此需要新开一个会议室,room+1,room = 2。
i = 2, starts[i] = 15, ends[j] = 10
starts[i] > ends[j],说明下一个事件是结束,意味这我们可以空出一间会议室出来复用,所以room的数量保持不变,继续找下一个j。
最终返回room=2即可。
如果不太好理解的话,可以把开始时间记作+1,而后结束时间记作-1,那么上面的内容升序排列之后:
0 +1
5 +1
10 -1
15 +1
20 -1
30 -1
这个过程中右边计数的最大值是2,表示在整个会议时间内,需要新开2间会一直供整个会议时间内使用。其实和上面的例子是一个道理。
至于为什么不用考虑时间配对问题,就是说每一个会议的开始和结束时间不应该是一一对应的么?上面那样做就是打乱了所有的开始和结束时间,这样不会有影响的么?
其实这样做没有影响,因为存在开始时间就说明有会议要进行,而一碰到结束时间,说明有会议结束,对应的会议室可以复用,这样不必追求每个时间都要一一匹配。
代码
python
class Solution:
def minMeetingRooms(self, intervals):
# 判定异常
if not intervals:
return 0
# 升序得到开始时间和结束时间
starts = sorted(i[0] for i in intervals)
ends = sorted(i[1] for i in intervals)
# 初始化
rooms = 0
j = 0
for i in range(len(intervals)):
# 下一个事件是开始,所以会议室数量+1
if starts[i] < ends[j]:
rooms +=1
# 反之说明下一个事件是结束,有会议室空出,可以复用,会议室数量保持不变,j往后移
else:
j += 1
return roomsC++
class Solution{
public:
int minMeetingRooms(vector<vector<int>> & intervals)
{
// 判断intervals是否为空
if(intervals.empty())
return 0;
// 初始化
vector<int> starts, ends;
// 按升序存储起始时间、结束时间
for(auto &inv:intervals)
{
starts.push_back(inv[0]);
ends.push_back(inv[1]);
}
int j = 0;
int room = 0;
for(int i =0;i<intervals.size();i++)
{
// 未处理事件的开始时间大于结束时间,得新开一个会议室
if(starts[i] < ends[j])
room++;
// 反之,有会议结束,空出来的会议室可以复用,继续比较下一个结束时间,当前结束时间已完成,说明上一个会议已经结束
else
j++;
}
return room;
}
}39.组合总和(回溯专题漏了这题)

解题思路
回溯的基本做法,这个地方我们只用选或者不选这种方法来做。
初始化path=[], ans = []
终止条件:
当left == 0相等时,此时path数组内的值满足target了,直接取出即可;
判定条件:
如果遍历到了candidates的末尾,说明在candidates中没有满足target的组合或者说最后left的值小于0,同样说明凑不到满足target的组合;
选:
对于数组中第i个元素,此时我们目前组合的和是left,如果我们选择了candidates[i],那么余下的数的和是left- nums[i],而后还是可以继续选择nums[i],因为题目中说明了同一个数字可以无限制重复被选取;选择了nums[i[],将其放入path数组中
不选:
对于数组中第i个元素,此时我们目前组合的和是left,如果我们不选择nums[i],那么余下的数的和是left不变,而后走到第i+1个数;
返回值:
返回ans数组即可。
优化:
对candidates进行升序排列,在判定无效的时候,如果left小于cadidates[i],那么不应继续递归了,因为后面的candidates[i+1]……都是大于left的,凑不到left==0,我们要找到满足使得left==0的组合是不可能的,所以这样直接剪枝,不用继续后面的判断。
代码
python
class Solution(object):
def combinationSum(self, candidates, target):
"""
:type candidates: List[int]
:type target: int
:rtype: List[List[int]]
"""
# 初始化
candidates.sort()
ans = []
path = []
# 回溯
# i代表candidates中的下标
# left代表剩余元素的和,起始是target
def dfs(i, left):
# 终止条件
if left == 0:
ans.append(path[:])
return
# 判定条件
if i == len(candidates) or left < 0:
return
# 优化
if i == len(candidates) or left < candidates[i]:
return
# 不选
dfs(i+1, left)
# 选
path.append(candidates[i])
# 继续i是因为题目中说明了元素可以无限利用
dfs(i, left - candidates[i])
path.pop()
dfs(0, target)
return ansC++
class Solution {
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
// 对candidates进行升序排列
sort(candidates.begin(), candidates.end());
vector<int> path;
vector<vector<int>> ans;
// left是凑成target组合还需要多大
auto dfs = [&](this auto &&dfs, int i, int left)
{
// 终止条件
if(left == 0)
{
ans.push_back(path);
return;
}
// 判定边界
if(i==candidates.size() || left < candidates[i])
return;
// 不选
dfs(i+1, left);
// 选, 还是遍历i,因为一个元素可以多次利用
// 先压入path中,再继续往下递归
path.push_back(candidates[i]);
dfs(i, left - candidates[i]);
// 恢复现场
path.pop_back();
};
dfs(0, target);
return ans;
}
};42.接雨水

解题思路
本题还是使用单调栈,对于能够形成水坑,来接雨水的坑,满足一下情况:
left是当前坑底元素(栈顶元素)弹栈之后的栈顶元素,在文中我们把它当作栈顶元素的下一个元素。
①坑底的左边一定有元素,并且是高度比它搞得元素,从左到坑底这块是单调递减的,在坑底右边的柱子的高度是必须大于坑底的,也就是右边的柱子不满足左边的单调递减规律;
②能够装雨水的区域的面积:
假设坑的形状、左右是这个样子:left bottom i(i是当前遍历到的索引)
那么坑的宽度是right-left-1,高度是min(height[left], height[right]) - height[bottom]
能够接水的面积是:宽度* 高度 = (right - left -1) * (min(height[left], height[i]) - height[bottom])
那么就有如下问题:
①这个bottom怎么求呢?
首先我们知道,bottom是一个坑的坑底,那么从左到坑底是单调递减的,在遍历这个height数组的时候,我们用一个单调栈来维护,栈中元素自底向上是单调递减的,如果在遍历的时候发现当前元素height[i]大于栈顶元素,说明当前元素高度大于栈底,并且栈底元素左边有存在比它高的元素,那么就可以组成一个坑来接雨水。
故,bottom就是在遍历的过程中,按照单调递减存入栈中,而遍历到大于栈顶的元素时,此时的栈顶元素。
②这个left怎么求呢?
因为要想组成坑来接雨水,那么左右边界都必须要比坑底要高,并且都得存在,当我们在上面知道了bottom的时候,其实right也就是当前遍历的元素i,那么left就得是bottom左边且比它要高的元素,也就是left是栈顶元素的下一个元素。当栈中弹出栈顶元素bottom之后,栈为空,说明了bottom左边没有比它高的柱子,因此形成不了接雨水的坑,直接跳出当前循环。
③对于存在多个相同的坑底元素该怎么办呢?
例如:height = [3, 2, 1, 1, 2]
情况一:如果栈是严格单调递减的话,那么
i=0, 开始st= [0]
i=1, 2<3,st=[0, 1]
i=2, 1<2,st=[0, 1, 2]
i=3, 1==1,此时进入while循环中,i=3,bottom = 2,bottom_hd = 1,left = 1, height[left] =2,hd = min(height[i], height[left]) - bottom_hd = min(1, 2) - 1 = 0,所以能接水的区域是0;
此时的栈st=[0,1],height[st[-1]] = 2 height[i] = 1,不满足height[st[-1]] <=h,所以不满足,继续往后遍历。
由上可知,对于严格单调递减,栈中只会存储一个相同的坑底元素。
情况二:如果是栈是非严格单调递增的话,那么
i=0, st = [0]
i=1, 2<3,st=[0, 1]
i=2, 1<2,st=[0, 1, 2]
i=3, 1=1,st=[0, 1, 2, 3]
i=4, 1<2,此时进入while循环中,i=4, bottom = 3, bottom_hd = 1, left = 2, height[left] = 1,hd = min(height[i], height[left]) - bottom_hd = min(2, 1) - 1 = 0,所以能接水的区域是0;
此时栈st=[0, 1, 2],这个情况和情况1一致,后续不具体分析。
总之,对于上述情况,不论坑底是否有多个相同的坑底元素,最终都能找到正确的答案。
代码
python
class Solution(object):
def trap(self, height):
"""
:type height: List[int]
:rtype: int
"""
# 初始化
ans = 0
# 栈中维护的是下标
st = []
# 遍历height数组
for i, h in enumerate(height):
# st按照自底向上,单调递减排列
# 一旦出现不满足单调递减的,可能会形成坑,要在此处做更进一步的判断
while st and height[st[-1]] <= h:
# 此时坑底元素就是栈顶元素
# 将其弹出栈
bottom_h = height[st.pop()]
# 将bottom弹出后,判断栈是否为空
# 栈为空,形成可以接水的坑的左边界是不存在的,因此无法接水
if not st:
break
# 栈不为空,此时形成坑的左边界就是此时的栈顶元素
left = st[-1]
width = i - left - 1
hd = min(h, height[left]) - bottom_h
ans += width * hd
# 此时元素不满足上述关系,也就是栈顶元素大于当前遍历的height数组元素值
# 满足递减,存入栈中
st.append(i)
return ansC++
class Solution {
public:
int trap(vector<int>& height) {
// 初始化
stack<int> st;
int ans = 0;
int n = height.size();
for(int i =0;i<n;i++)
{
// st不为空,且st遵循严格单调递减
// 不满足进入循环,求解可行区域
while(!st.empty() && height[st.top()] <= height[i])
{
int bottom = st.top();
int bottom_hd = height[bottom];
st.pop();
// 判断弹出栈顶元素后,栈左边还有没有数,没有形成不了可以接水的区域
if(st.empty())
break;
int left = st.top();
int width = i - left - 1;
int hd = min(height[i], height[left]) - bottom_hd;
ans += width * hd;
}
// st单调递减
st.push(i);
}
return ans;
}
};84.柱形图中最大的矩形
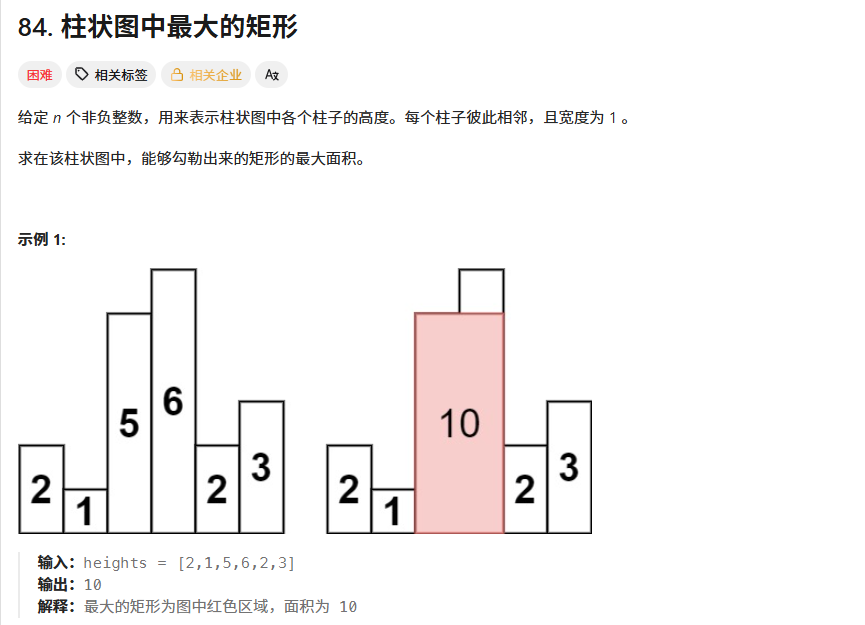
解题思路
本题要求柱形图中面积最大的矩形,其实要求面积最大的矩形,就是遍历整个heights数组,然后以heights[i]为中心,各找到左右第一个比heights[i]小的左右边界left,right,而后这样的话,矩形的宽就是right-left-1,高就是height[i],不断更新这个面积的最大值。
而在这个过程中,我们选择维护一个单调递增栈,也就是栈自底向上是单调递增的,假设当前遍历到的元素是heights[i],栈顶元素的大小比当前元素要大,那么就以此时栈顶元素为高(栈pop()出来),原始栈中栈顶元素的下一个位置,因为是单调递增栈,该位置比栈顶元素小,也就是得到的左边界left,此时的i就是右边界,计算可以形成的区域面积:
area = (i - left - 1) * heights[st.pop()]
随后,如果此时的栈不为空,且栈顶元素依旧是大于heights[i],则继续更新area,直到栈顶元素此时小于等于height[i]。
为什么要在heights左右都加上0?
在整个过程中,为了使得所有的柱子都经过计算,我们在heights数组中左右两边界都补上了0,这样在遍历到最后的0的时候,会把所有柱子都计算。
因为我们考虑极端情况,当heights是单调递增的情况下,那么栈中存储也是单调递增的,就不会有计算面积这一步,但是即使是严格单调递增,依旧需要计算面积,因此为了让栈中的所有元素都计算面积,我们在最后加入了0,以及最前面加入了0,保证了左右边界,也就是left和right,它会强制栈中所有剩余柱子依次弹出并计算面积。
总之:
前面加0,保证栈不为空;
最后加0,保证栈中所有元素都弹出并计算面积。
代码
python
class Solution(object):
def largestRectangleArea(self, heights):
"""
:type heights: List[int]
:rtype: int
"""
# 矩形的计算:
# 以heights[i]为高,左右两边出现的第一个小于heights[i]的元素作为left和right
# wd = right - left -1
# hd = heights[i]
# area = wd * hd
# 左右边界补0
heights = [0] + heights + [0]
# 构建单调递增栈,自底向上单调递增
st = []
area = 0
for i, h in enumerate(heights):
# 栈不为空,且此时的栈顶元素大于当前元素
while st and heights[st[-1]] > h:
# 此时栈顶元素作为高,弹出
hd = heights[st.pop()]
# 此时的栈顶元素作为左边界
left = st[-1]
# i为右边界,计算宽度
w_d = i - left - 1
# 计算面积
area = max(area, hd * w_d)
st.append(i)
return areaC++
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
// 在heights前后加入0
heights.push_back(0);
heights.insert(heights.begin(), 0);
// 单调递增栈,自底向上,单调递增
// 存的是下标
stack<int> st;
int area = 0;
int n = heights.size();
for(int i=0;i<n;i++)
{
// 当前栈不为空,并且栈顶元素大于heights[i],找到左右边界
while(!st.empty() && heights[st.top()] > heights[i])
{
// 此时栈顶元素作为高
int hd = heights[st.top()];
st.pop();
// 弹出后,此时栈顶元素是左边界
int left = st.top();
int wd = i - left -1;
area = max(area, hd * wd);
}
st.push(i);
}
return area;
}
};85.最大矩形

解题思路
本题的做法其实和84题基本一致,只不过本题是在一个矩阵上,但是我们是可以以每行为一个基准,对每行进行84题一样的操作,计算每行的最大的矩形,然后逐行累加,计算最大矩形。
对于矩阵中的元素如果是0,那么高度就是0,如果是1,那么对应列的height+1。对于每一行的元素,有1则在上一层的基础上+1。
其实矩形的话,把其中每一列为一的结果累加之后,组成的图形就是84的柱形图,不是么?只不过我们在这里计算了矩形每一列的结果。
代码
python
class Solution(object):
def largestRectangleArea(self, heights):
# 单调栈,自底向上单调递增
st = []
# 内部添加0,保证栈中所有原本元素都弹出并计算面积
heights = [0] + heights + [0]
n = len(heights)
area = 0
for i, h in enumerate(heights):
while st and heights[st[-1]] > h:
hd = heights[st.pop()]
left = st[-1]
wd = i - left - 1
area = max(area, hd * wd)
st.append(i)
return area
def maximalRectangle(self, matrix):
"""
:type matrix: List[List[str]]
:rtype: int
"""
ans = 0
n = len(matrix[0])
heights = [0] * n
for row in matrix:
for j, c in enumerate(row):
if c=='0':
heights[j] = 0
else:
heights[j] += 1
ans = max(ans, self.largestRectangleArea(heights))
return ans
C++
class Solution {
public:
int largeRectangleArea(vector<int> heights)
{
heights.push_back(0);
heights.insert(heights.begin(), 0);
int n = heights.size();
stack<int> st;
int area = 0;
for(int i=0;i<n;i++)
{
while(!st.empty() && heights[st.top()] > heights[i])
{
int hd = heights[st.top()];
st.pop();
int left = st.top();
int wd = i - left - 1;
area = max(area, hd * wd);
}
st.push(i);
}
return area;
}
int maximalRectangle(vector<vector<char>>& matrix) {
int n = matrix[0].size();
vector<int> heights(n);
int ans = 0;
for(auto& row :matrix)
{
for(int i=0;i<n;i++)
{
if(row[i] == '0')
heights[i] = 0;
else
heights[i] += 1;
}
// 将每行的结果送给上面的函数计算面积
ans = max(ans, largeRectangleArea(heights));
}
return ans;
}
};739.每日温度
解题思路
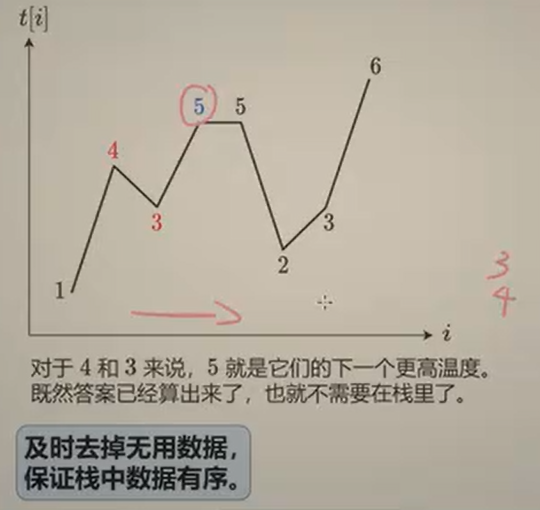
我们用单调栈来解决这个问题,首先本题的单调栈自底向上是降序排列。
每次遍历的时候,如果当前元素t[i]大于栈顶元素,则弹出栈顶元素,同时记录对应的下标差值,即为出现下一个更高温度出现在第几天。
因此栈中维护的其实是下标。
具体算法流程:
初始化结果数组ans,栈st
当栈不为空并且当前元素大于栈顶元素的时候,栈顶元素出栈,并记录对应的下标索引差值存在结果数组ans中,如此一直循环,直到当前元素不大于栈顶元素;
反之,如果不满足上述条件:栈不为空并且当前元素大于栈顶元素,则将当前元素的下标压入栈中,而后继续遍历t中其余元素。
最终返回ans。
代码
python
class Solution(object):
def dailyTemperatures(self, temperatures):
"""
:type temperatures: List[int]
:rtype: List[int]
"""
n = len(temperatures)
# 栈中存储的是下标
st = []
ans = [0] * n
for i, t in enumerate(temperatures):
# 如果栈不为空,并且当前元素大于栈顶元素,那么栈顶元素一直要被弹出,
# 直到当前元素小于等于栈顶元素
while st and t > temperatures[st[-1]]:
# 取出栈顶元素的索引
index = st.pop()
# i-index就是题中要求的下一个更高温度出现在几天后
ans[index] = i - index
# 当不满足上述条件,将当前元素下标压入栈中
st.append(i)
return ans
C++
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
// 初始化
int n = temperatures.size();
vector<int> ans(n, 0);
// 栈中存储的是下标值
stack<int> st;
for(int i=0;i<n;i++)
{
// 当栈不为空,并且当前元素大于栈顶元素
while(!st.empty() && temperatures[i]>temperatures[st.top()])
{
// 取出栈顶元素的下标
int j = st.top();
st.pop();
ans[j] = i - j;
}
// 不满足条件的话,那么把当前元素的下标压入栈中
st.push(i);
}
return ans;
}
};
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)