Qwen3.5-LiveTranslate,可能是同传模型最该有的样子
语音翻译这件事,最怕的不是翻不出来,而是翻得像一个没在现场的人。
这句话听着有点绕,但你稍微想一下就懂了。
一个人在泰国餐厅点菜,服务员指着菜单说了一串泰语。你如果只拿到声音,当然也能翻译。但菜单上写着什么,服务员手指着哪一道菜,桌上到底摆着什么,这些东西都会影响翻译。
再比如电商直播,主播嘴里说的是一个型号,手里拿的是另一个商品,屏幕上还有一串参数。你只听音频,很容易把数字、规格、品牌名搞混。
所以我看完阿里 Qwen 团队新发的 Qwen3.5-LiveTranslate 之后,脑子里第一个冒出来的词不是「翻译」。
而是「临场感」。
它让我觉得,同传模型终于开始从一个只戴耳机的人,变成一个坐在现场的人。
这次最有意思的,不是它会翻译
Qwen3.5-LiveTranslate-Flash 是 Qwen 家族最新的同声传译模型,基于 Qwen3.5-Omni 构建。官方博客给它的描述很直接,实时、多模态翻译,不仅能听懂语音,还能看见视觉上下文。
这句话里最关键的不是「实时」,也不是「多语言」。
是「看见」。
以前我们讲语音翻译,大部分时候脑子里想的是一条流水线,先把声音识别成文字,再把文字翻译成另一种语言,最后再合成语音。这个流程当然能工作,而且工程上很成熟。
但问题是,它太像一个坐在隔壁房间里的翻译。
他能听见你说话,但他没看见现场。
Qwen3.5-LiveTranslate 这次真正有意思的地方,就是它把音频和视频一起喂给模型。官方架构里,Thinker 接收交错编排的视觉和音频输入,先生成译文。Talker 再基于译文和源音频生成目标语言语音,并尽可能保留原说话人的音色。
也就是说,它不是单纯把一句话从中文搬到英文。
它在尝试理解,说这句话的人是谁,现场发生了什么,屏幕和物体给了哪些上下文,然后再决定该怎么翻。

官方给了五个演示,我觉得顺序挺有意思
第一个是跨国会议。
多语言商务会议里,参会者用不同语言发言,中间还可能自由切换语言。这个场景对同传模型很折磨,因为它不是标准考试音频,而是真实会议。有人口音重,有人语速快,有人夹杂术语,有人一句话里混两种语言。
这类场景里,翻译模型最容易暴露两个问题。
一个是反应慢,话题都过去了,翻译还在追赶上一句。另一个是术语不稳,同一个词前后翻译不一致,会议听着就会很累。
第二个是出境旅游。
这个 demo 我反而更喜欢,因为它没有那么「发布会」。它就是一个中国游客在泰国餐厅点餐,设备结合菜单视觉信息和对话语音,把泰语翻成中文。
说真的,这才是多模态同传最该出现的地方。
你在国外旅行时,很多时候不是听不懂一句话,而是不知道这句话指向现实里的哪个东西。菜单、招牌、商品、路牌、屏幕,这些视觉信息本来就是语境的一部分。
一个只能听声音的翻译模型,就像你让一个人闭着眼睛帮你点菜。
当然能点。
但总感觉不踏实。
第三个是电商直播。
这类场景的难点不是日常口语,而是数字和参数。商品规格、容量、价格、型号,一旦翻错,不只是尴尬,甚至会直接影响交易。
这也是为什么官方把热词能力单独拎出来讲。它支持最多一千个热词,可以按场景动态配置。人名、地名、品牌名、产品型号、行业术语,都可以被优先识别和翻译。
我自己的感受是,这个功能比很多人想象得重要。
因为真实世界里的翻译,最容易翻车的不是「你好」「谢谢」这种句子,而是那些你以为模型应该懂,但它偏偏会乱猜的专有名词。
语言覆盖和延迟,都是硬指标
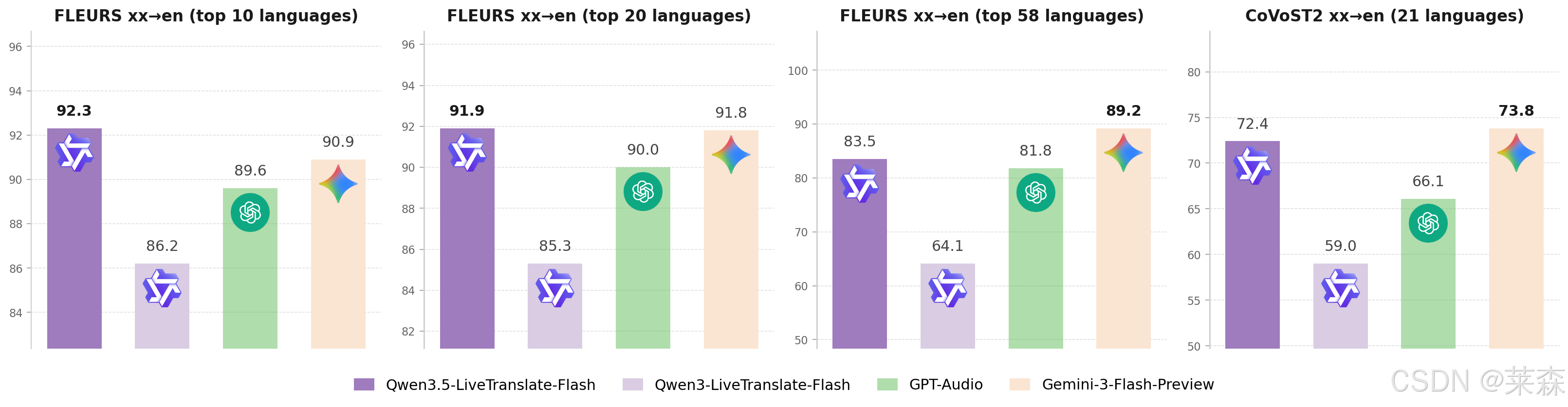
官方这次给了几个很硬的数字。
Qwen3-LiveTranslate 的输入音频和输出文本支持 18 种语言,到了 Qwen3.5-LiveTranslate,变成了 60 种。输出音频语言从 10 种变成了 29 种。
这个提升不是小修小补。
它直接决定一个同传系统能不能从 demo 走向更多真实场景。国际会议、跨境直播、在线课堂、商务谈判,这些场景里,语言不是整齐划一的。你以为是中英互译,现场可能突然来一句泰语、日语、西语、阿语。
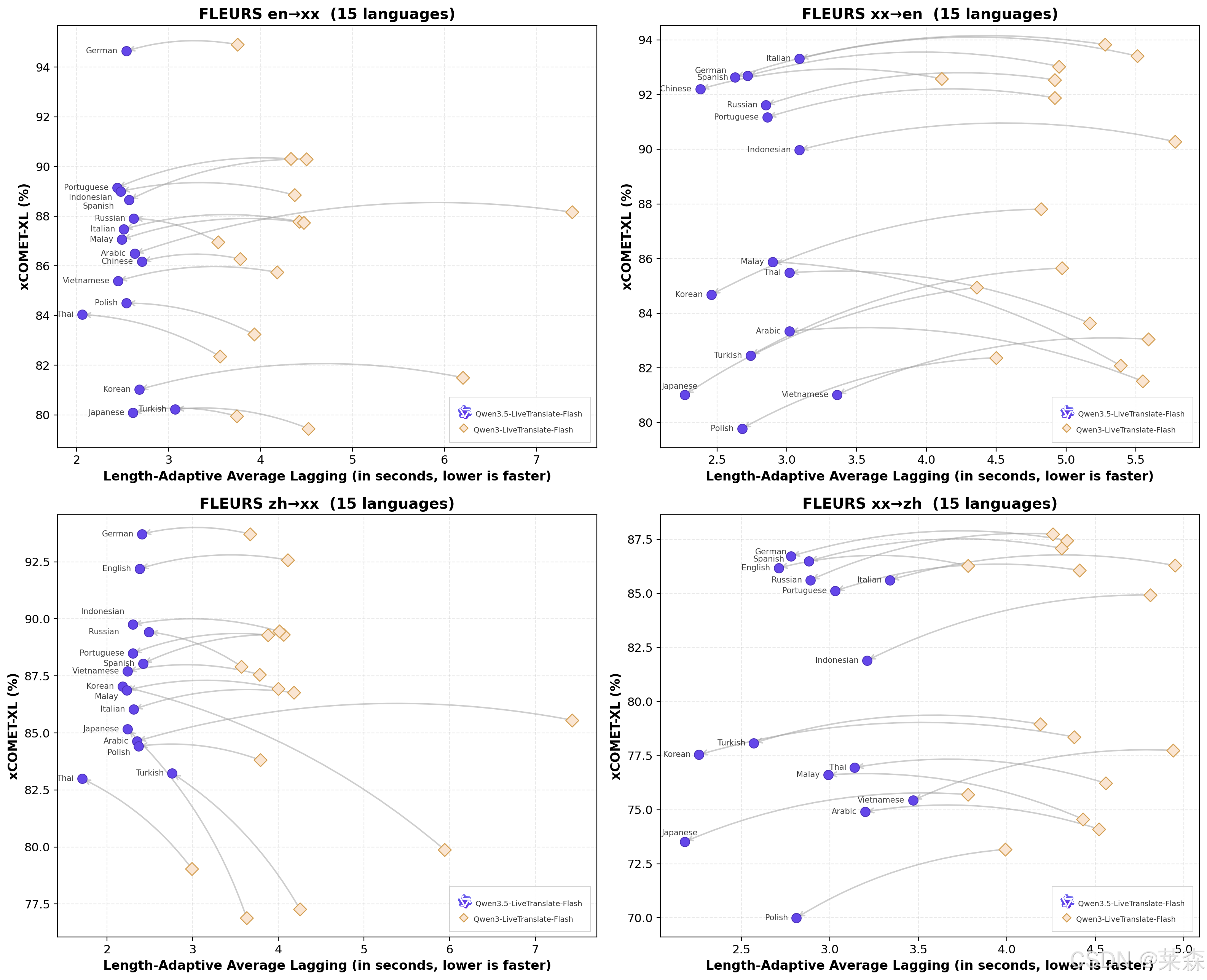
延迟更关键。
官方说,借助可读单元,也就是 Readable Unit 的流式策略,Qwen3.5-LiveTranslate-Flash 相比前代把首字延迟降低了 3.45 秒,字均延迟降低了 1.88 秒,最终端到端字均延迟做到 2.8 秒。
同传这东西,2.8 秒是什么概念?
它当然还不是科幻电影里那种完全同步,但已经接近一个人类同传可以接受的跟随节奏。尤其在直播和会议里,真正让人难受的不是延迟存在,而是延迟忽长忽短,听感断断续续。
所以 Readable Unit 这个点很有意思。
它不是简单地追求越早吐字越好,而是在「早点说」和「说出来还能读」之间找平衡。太早输出,可能语义没收完整,后面还要改。太晚输出,实时性就没了。
这里面其实就是同传的老问题,听到多少才敢开口。
声音克隆,让翻译不再像另一个人插话
还有一个我觉得很容易被低估的能力,实时音色克隆。
官方说,同传过程中模型可以自动复刻说话人的音色特征,让译文语音在不同语言之间保持「同一个人」的声音质感。
如果只是看技术参数,你可能会觉得这只是一个加分项。
但放到真实场景里,它很可能是体验差异最大的地方。
想象一下,一个主播在直播间里讲中文,系统把他的声音翻成英语。如果输出声音是一个完全陌生的播音腔,观众会知道这是翻译,但身份感断了。可如果输出的英文仍然像这个主播本人在说,哪怕不是百分百复刻,沉浸感都会完全不一样。
这对主播、嘉宾、主持人、老师都很重要。
因为他们卖的不只是信息,还有个人表达。
我有时候觉得,AI 翻译未来真正要解决的,不是把一句话翻成另一句话,而是把一个人翻到另一种语言里。
这就不只是文本问题了。

视觉消歧,是这个方向最值得期待的地方
官方最后给了一个视觉消歧 demo。
这个词有点技术,但其实很生活。
同一个词在不同场景下可能有不同意思。人类为什么能选对?因为我们不只听一句话,我们还看现场。屏幕上有什么,桌子上有什么,对方指着什么,这些信息会自动进入我们的理解。
AI 同传如果也能看见,就能少犯很多「语法没错但语境错了」的错误。
这让我想到一个很普通的场景。
你在国外便利店问店员,这个能不能加热。店员回答里可能有一个词,单看音频有几种理解。但如果模型看见你手里拿的是饭团,不是饮料,它就更容易选对译法。
这就是我说的,翻译开始看见世界了。
当然,它还不是万能翻译官
这里也得冷静一下。
Qwen3.5-LiveTranslate 现在看起来很漂亮,但从官方博客也能看到,它未来还要继续解决几件事。比如更低延迟,更多语言和方言,更长上下文,更强的一致性,更高保真的音色复刻,以及更丰富的交互模式。
这些都不是小问题。
尤其是长时间会议里,术语、人名、上下文能不能稳定保持,是非常难的。一个模型前十分钟翻得很好,不代表四十分钟后还能不乱。多人说话、打断、重叠语音、现场噪声,也会继续折磨系统。
所以如果你问我,它是不是已经可以替代专业同传?
我觉得还不能这么讲。
但它已经把方向摆得很清楚了。
未来的同传模型,不会只是一个更快的字幕机。它会同时处理声音、画面、术语、上下文、说话人身份,甚至语气和现场氛围。
这件事一旦做成,影响会比「翻译更准」大得多。
它会改变跨语言沟通的默认体验。
我真正被打动的地方
说实话,最打动我的不是 60 种语言,也不是 2.8 秒延迟。
这些当然很重要。
但我更在意的是,它把「现场」放回了翻译里。
过去很多 AI 翻译像是在处理一句孤零零的文本。可是人类说话从来不是孤零零的。我们说话时有表情,有手势,有屏幕,有物体,有身份,有语气,有一大堆没说出口但在现场的人都能看懂的东西。
如果 AI 只听声音,它永远只能猜。
如果 AI 开始看见,它就有机会理解。
Qwen3.5-LiveTranslate 这次让我看到的,就是这个方向。
同传翻译开始不只是把语言搬运过去。
它开始试着把一个现场,搬到另一种语言里。
这才是让我觉得兴奋的地方。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)