这篇论文最狠的地方,不是让模型更强,而是它开始认真解决一件更现实的事!
怎么让一群不同的大模型,像一个真正的团队那样协同干活。

📌 今天想讲的论文
论文标题:Learning to Orchestrate Agents in Natural Language with the Conductor 机构:Sakana AI 等 时间:ICLR 2026 / arXiv 2025.12.04388 v5
先说结论:
这篇论文的重点,不是“再造一个更大的模型”。
它做的是另一件事: 训练一个 7B 的“小指挥”,专门负责拆任务、选模型、分配上下文、安排协作顺序,让一组更强的大模型一起干活。
说白了,它不自己下场解题。 它像个调度员,负责指挥别人怎么配合。
这件事为什么值得看?
因为很多人现在聊 Agent,还停在“多拉几个角色进群”。 但这篇论文已经往前走了一步:
不是简单多加几个 Agent,而是开始训练“谁先做、谁后做、谁看谁的结果、什么时候复核”这套协作策略本身。
🧠 它到底做了什么
作者设计了一个叫 Conductor 的模型。
它的任务不是直接回答问题,而是先输出一套“工作流”:
-
第一步,把问题拆成几个子任务
-
第二步,给每个子任务分配合适的 worker model
-
第三步,决定每个 worker 能看到哪些前置结果
-
第四步,必要时增加验证、复核、再修改
看这张图就很好懂:

这就不是普通的 prompt engineering 了。
这更像是在训练一个 会动态编排 Agent 工作流的调度层。
🚀 这篇论文真正厉害的点,不只是分数
论文里最容易被转发的,肯定是成绩。
作者说这个 7B 的 Conductor,配合一组 worker models 后,在一些高难 benchmark 上,能打到比单个强模型更高的结果。
比如这张图: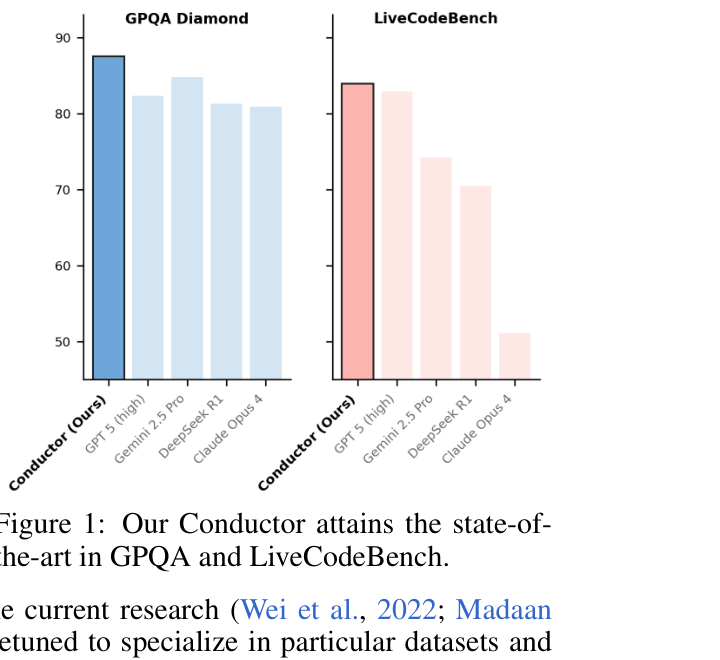
图 2:在 GPQA 和 LiveCodeBench 上,Conductor + worker 的组合超过了若干单模型结果。
但如果你只看到“它又赢了几个 benchmark”,那就看浅了。
这篇论文真正有价值的地方是:
1. 它把“协作策略”本身变成了可训练对象
以前大家做多 Agent,很多是人工写死流程:
-
先让 A 规划
-
再让 B 执行
-
再让 C 检查
这种方式能跑,但很硬。
一换任务,一换模型,一换成本约束,整套流程就可能失效。
Conductor 的思路是:
别把流程写死,直接训练一个模型来学会怎么编排。
这一步很关键。
因为它意味着,未来多 Agent 的核心竞争力,可能不只是“你接了几个模型”,而是:
你有没有一个足够聪明的调度层,知道什么时候拆、怎么拆、拆给谁、谁该看到什么。
2. 它开始逼近“真实团队协作”而不是“模型轮流说话”
论文里有张很有意思的图,展示了训练前后协作策略的变化:
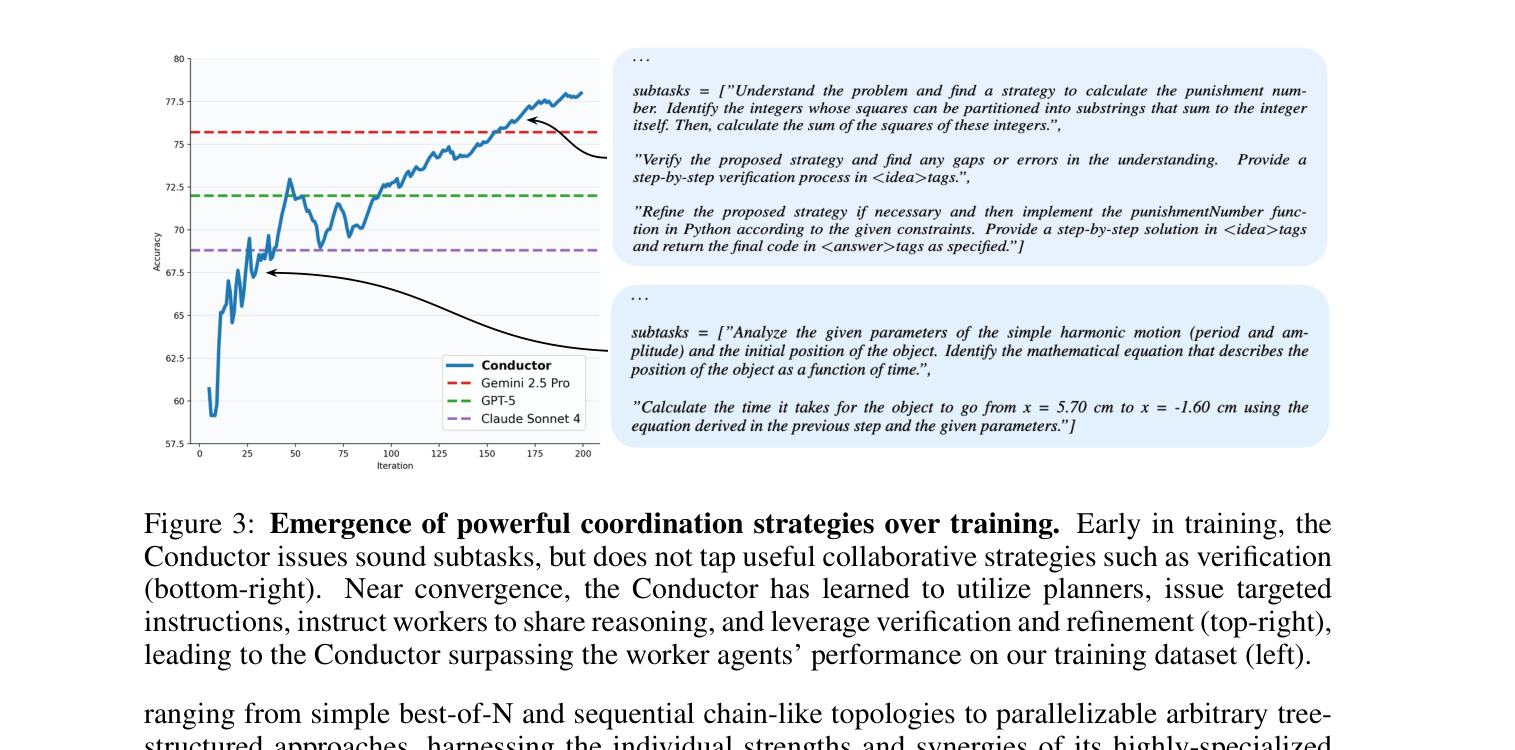
图 3:早期只是简单分任务,后期开始出现验证、复核、定向指令这些更像真实协作的动作。
作者观察到,Conductor 早期只是“分工”。
训练到后面,它开始学会一些更高级的动作:
-
先让某个模型做规划
-
再让另一个模型只做验证
-
再让第三个模型基于前两步做修正
这就比“大家都来回答一遍,然后投票”高级多了。
因为真正有用的协作,不是多几张嘴。 而是能不能减少瞎忙,减少重复,减少错误扩散。
3. 它提醒我们,Agent 的上限可能卡在“组织方式”
很多人默认觉得,模型越来越强,Agent 自然会越来越强。
但这篇论文在提醒另一件事:
单个模型变强当然重要,但怎么组织多个模型,可能同样重要。
这有点像团队管理。
一个公司不是招来 5 个高手就自动赢。 如果协作顺序不对、信息流不对、责任分配不对,高手也会相互抵消。
多模型系统也是一样。
🪤 但这篇论文也不是“多 Agent 万能论”
这里也得泼点冷水。
这篇论文很强,但你不能直接理解成:
以后所有 AI 应用都应该上多 Agent。
不对。
更准确的理解是:
1. 它证明了“训练协作层”很有价值
不是证明“所有场景都该堆更多模型调用”。
很多业务里,一个模型 + 一个明确流程,已经够了。
如果任务很短、成本敏感、延迟要求高,多 Agent 反而可能拖后腿。
2. 论文里的强结果,离生产还有一层系统工程
论文解决的是“怎么更聪明地编排”。
但真到线上,后面还有很多现实问题:
-
模型调用成本怎么控
-
不同模型怎么路由
-
某个 provider 抖了怎么办
-
链路怎么观测
-
多步执行失败了怎么重试
-
企业权限和审计怎么做
所以这篇论文很前沿,但它解决的主要还是 策略层 的问题。
而从 demo 走到生产,后面还有 执行层、治理层、成本层 要补。
👨💻 对开发者意味着什么
如果你是做 Agent、AI workflow、Copilot、自动化系统的,这篇论文最值得带走的,不是论文里的某个数字。
而是这三个判断:
1. 少迷信固定工作流,多重视动态编排
以前最常见的做法,是把流程写死。
但随着模型数量变多、任务类型变复杂,固定流程会越来越脆。
以后更值钱的能力,可能是:
-
动态拆任务
-
动态选模型
-
动态分配上下文
-
动态决定什么时候验证、什么时候递归
2. 不要只优化 prompt,要开始优化“协作协议”
很多团队现在还在卷提示词。
但再往前走,你会发现真正拉开差距的,是下面这些东西:
-
哪个角色先说
-
哪个角色只做审查
-
哪些中间结果应该共享
-
哪些结果反而不该共享,避免错误污染
这已经不是一句 prompt 的问题了。
这是系统设计问题。
3. 多 Agent 的关键,不是更多,而是更会分工
“再加一个 Agent 试试”这件事,短期内可能有效。
但长期看,真正值钱的是:
让每一步调用都更有明确职责。
会规划的去规划,会验证的去验证,会执行的去执行。 而不是每个模型都被拉来“都想一遍”。
🏢 对企业意味着什么
如果你站在企业侧,这篇论文的价值其实更直接。
它在说明一件事:
未来企业买到的,不只是某个模型能力,而是一整套多模型协作能力。
这背后至少有三层变化:
1. 单模型时代的选型逻辑,会慢慢不够用
以前企业问的是:
“我到底选 GPT、Claude、Gemini 还是 Qwen?”
以后更现实的问题会变成:
“哪类任务给哪个模型最合适?” “哪些任务要串行,哪些适合并行?” “哪些步骤要复核?” “高成本模型应该用在最关键的哪一步?”
这套问题,本质上就是调度问题。
2. 企业真正缺的,可能不是模型,而是编排和治理层
一旦业务真的开始跑起来,你会很快遇到:
-
模型太多,不好统一接
-
成本越来越高,不好归因
-
效果波动大,不好排查
-
多步流程长,不好观测
-
合规要求高,不好审计
所以很多企业后面补的,不会只是“再买一个更强模型”。 而是补一层把这些能力统一起来的系统。
3. 多模型协同会越来越像基础设施,而不是技巧
今天很多人还把多 Agent 当成一种玩法。
但如果 Conductor 这类方向继续往前走,多模型协同迟早会变成基础设施的一部分。
到那时,大家比的就不是“会不会搭个 demo”。 而是“能不能稳定、可控、低成本地持续跑”。
✍️ 我的判断
这篇论文最值得重视的,不是它证明了“多 Agent 很厉害”。
而是它往前推了一步:
开始把 AI 系统里的“组织能力”本身,变成一个可以训练、可以优化、可以扩展的对象。
这件事一旦继续成立,后面会改写很多产品和工程设计:
-
Agent 不再只是角色堆叠
-
workflow 不再只是人工脚手架
-
多模型系统不再只是路由到最强模型
而是会慢慢走向:
一个真正有调度层、有验证层、有执行层的 AI 生产系统。
🔚 最后一句现实话
如果你今天就在做 AI 应用、Agent 或企业级智能体,这篇论文最值得你马上反思的一点是:
你现在优化的,到底只是某一步调用效果,还是整套协作链路的组织方式?
前者会带来局部提升。 后者才可能真正把系统拉开差距。
顺着这个方向再往下走,后面拼的也不会只是 prompt 了,更多会落到路由、执行、观测、成本和治理这些系统层能力上。
这也是胜算云这类平台真正有价值的地方: 不是替你发一条 prompt,而是帮你把多模型和多步骤能力,接进一个能长期跑的生产体系里。
更多 AI 生产化观察,可继续看胜算云。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)