《面向深度学习的高效安全推理研究综述》学习笔记
一、核心问题与目标
1、核心问题
在“深度学习即服务(DLaaS)”模式下,用户数据与模型参数分离,存在严重的隐私泄露风险。采用同态加密(HE)、安全多方计算(MPC)等密码技术实现安全推理,虽然能保护隐私,但会带来巨大的计算和通信开销,导致推理速度极慢,难以实际应用。
2、研究目标
本文的目标是:系统梳理和对比现有面向高效安全推理的研究成果,从全局视角分析如何加速安全推理。具体包括:
-
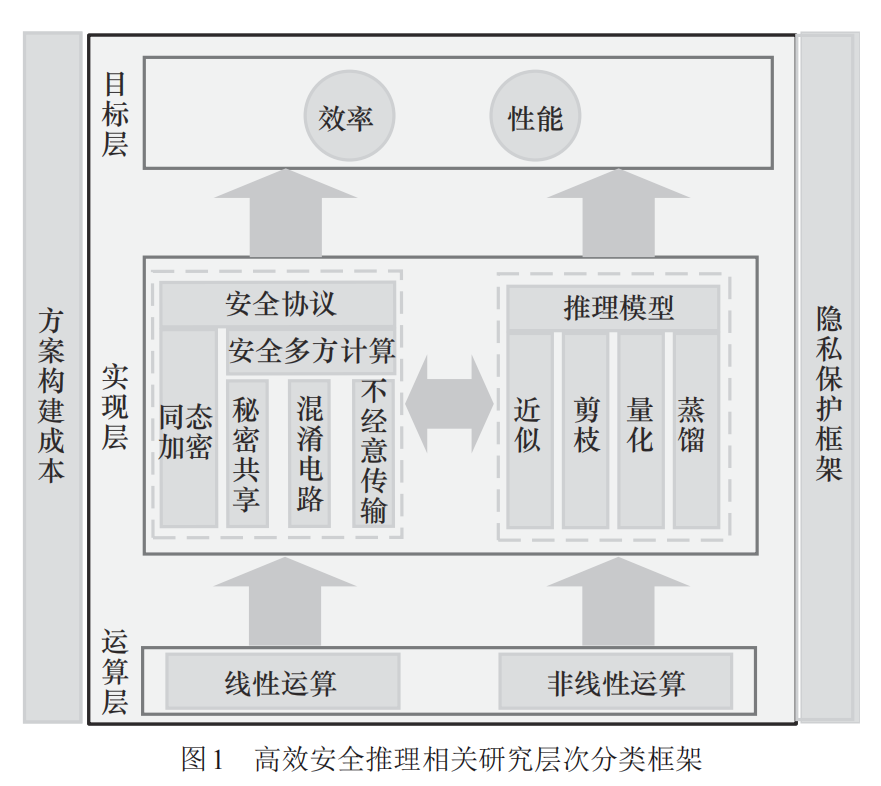
构建一个统一的层次分类框架(运算层-实现层-目标层);
-
区分线性运算与非线性运算,分别对比不同密码原语(HE、SS、GC、OT等)和模型优化方法的效率;
-
补充讨论方案构建成本和隐私保护框架这两个常被忽略的实践因素;
二、研究难点
-
密码学开销的“两难”
-
同态加密(HE):密文计算极慢,尤其是旋转(rotation)、自举(bootstrapping)等操作;密文尺寸大,存储和传输开销高。
-
安全多方计算(MPC):线性运算中秘密共享(SS)需要频繁交互通信;非线性运算(如ReLU、Softmax)需借助混淆电路(GC)或函数秘密共享(FSS),通信或计算开销依然很大。
-
-
非线性运算难以高效实现
-
HE天然不支持非线性函数,必须用多项式近似,但低次多项式精度不足,高次多项式开销大。
-
MPC可实现精确非线性运算,但电路复杂、通信轮次多。
-
如何在精度、效率、安全性之间取得平衡是核心难点。
-
-
模型优化与安全推理的兼容性问题
-
现有模型优化方法(剪枝、近似、蒸馏)大多针对明文推理设计,迁移到安全推理后,开销分布发生变化(非线性运算占比极高),原有优化效果可能不佳。
-
许多优化需要重新训练模型,在大模型时代成本极高,但已有研究常忽略这一构建成本。
-
-
缺少统一、实用的评价体系
-
不同方案采用不同的基准、硬件、协议,难以横向对比。
-
评价指标多限于推理时延和模型精度,忽略了安全强度灵活性、构建成本、易用性等实际问题。
-
三、关键技术
(一)安全协议优化
1. 线性运算的安全协议
问题:线性运算(卷积、全连接、矩阵乘法)是神经网络的基础计算,但在隐私保护场景下面临两难选择:
-
采用同态加密(HE):密文计算开销巨大(尤其是旋转、重线性化等操作),导致推理时延极高。
-
采用秘密共享(SS):乘法运算需要多方交换份额,通信开销成为主要瓶颈。
目标:在保护数据隐私的前提下,高效实现安全推理中的线性运算,尽可能降低密文计算开销或通信开销,使安全推理的时延接近明文推理水平。
核心思路:
基于HE的线性协议(以计算换通信):
-
CryptoNets:首次将HE与神经网络结合,通过SIMD批处理将多个数据打包进一个密文并行计算,摊销单次运算开销。
-
Gazelle:为卷积和矩阵乘法设计专门的同态运算内核,优化底层计算效率。
-
FALCON:利用傅里叶变换在频域加速卷积,减少旋转操作。
-
Cheetah:通过精心设计多项式编码方式,完全避免昂贵的旋转操作。
-
BOLT / Iron:针对Transformer的矩阵乘法,提出紧凑打包技术和大小步策略,降低密文运算和通信开销。
基于MPC(秘密共享)的线性协议(以离线换在线):
-
SecureML:首创离线预生成Beaver三元组技术,将大部分交互移到离线阶段,大幅降低在线推理时延。
-
ABY3:在三方场景中采用复制秘密共享,进一步减少通信轮次。
-
BumbleBee:针对大模型中的矩阵乘法,通过多项式编码和密文打包技术,高效实现两方安全矩阵乘法,平衡计算与通信。
2. 非线性运算的安全协议
问题:非线性运算(ReLU、Softmax、GeLU、LayerNorm等)是安全推理中开销最大、技术难度最高的部分。核心矛盾在于:
-
HE原生不支持非线性函数(无法直接比较、取指数、除法等)。
-
MPC可实现精确非线性,但电路复杂、通信开销巨大。
-
需要在精度、效率和安全性三者之间找到平衡。
目标:在保证可用精度的前提下,高效实现安全推理中的非线性运算,使非线性层的开销不再成为安全推理的主要瓶颈。
核心思路:
基于HE的近似方法(以精度换效率):
-
多项式近似:用低次多项式逼近非线性函数。早期(CryptoNets):平方函数替代ReLU,精度低但计算快。后续用三次多项式、优化的10次多项式逼近ReLU,在输入范围内达到10位精度,有效提升精度。
-
客户端辅助:服务器将密文发回客户端,客户端解密后计算明文非线性函数再加密返回。优点:明文计算极快。缺点:增加通信轮次,且客户端参与计算存在隐私风险。
基于MPC的原生实现(以通信换精确):
-
混淆电路(GC):将非线性函数转化为布尔电路,适合实现比较、ReLU等操作,虽然通信轮数与电路深度无关,但复杂非线性函数对应的电路规模庞大,通信开销依然很高。XONN(基于XNOR的不经意深度神经网络推理框架)通过模型参数二值化来缩小电路规模。
-
函数秘密共享(FSS):以极少通信轮次实现比较协议。
-
AriaNN:基于函数秘密共享的低交互隐私保护深度学习框架,首次用FSS设计ReLU、最大池化、批归一化协议,通信量极大减少。
-
SIGMA:基于函数秘密共享的安全GPT推理系统,将FSS扩展到Transformer的Softmax和GeLU,效率提升一个数量级以上。
-
-
混合协议:结合多种密码原语取长补短。
-
SS + OT:设计低交互的比较、指数、除法协议。
-
SS + GC:利用查表法实现非线性函数。
-
(二)推理模型优化
推理模型优化:在不显著降低模型精度的前提下,通过修改模型结构或替换算子,减少安全推理时的计算量或通信量,从而降低推理时延。
模型侧的优化主要针对非线性运算,因为无论是CNN还是Transformer,非线性部分都占据了安全推理的大部分开销。主要方法包括剪枝、近似和蒸馏。
1. 剪枝:通过移除模型中不重要的非线性算子来降低模型整体运算开销;
- 结构化剪枝:以层或通道为单位进行整体移除,操作简单但粗粒度,对模型精度影响较大,如DeepReduce基于ReLU重要性进行结构化剪枝。
- 非结构化剪枝:在神经元级别进行精细剪枝,如Selective Network Linearization基于梯度选择要移除的ReLU。
- 重新设计神经网络架构:直接构建低ReLU数量的模型,如CryptoNAS通过神经架构搜索在给定ReLU预算下寻找最优网络结构。
- 综合性方法:DReP提出了一种结合结构化和非结构化的剪枝方法,基于神经元输出状态进行剪枝,能够在无需重训练的情况下实现深度剪枝,较好平衡了模型性能和效率。
2. 近似:使用对于安全推理计算开销更小的算子替代模型中的非线性算子。基本思路是用对安全推理友好的简单函数(如低次多项式)替换原非线性激活函数。
- 固定多项式近似:使用固定形式的多项式替代非线性激活函数,如CryptoNets直接使用平方函数替代ReLU,后续研究逐步将多项式次数提升到三次乃至优化的十次,在特定输入范围内获得更高精度。
- 通道级自适应近似:允许网络中的不同通道选择不同阶数的多项式,如SafeNet引入了通道级的多项式近似,从而更灵活地平衡精度与效率。
- 随机化近似:通过随机化ReLU测试并引入新的截断方法实现近似,如Circa。
- Transformer专用近似:针对注意力机制中的Softmax设计近似函数,如MPCFormer提出2Quad-Softmax;SAL-ViT进一步提出可学习的2Quad-Softmax,通过训练调整近似参数。
- 自动化近似搜索:实现完全自动化的ReLU替换,如AutoReP利用分布感知的多项式近似搜索最优替代函数,无需人工设计。
- 精度补偿机制:近似方法在显著提升效率的同时往往导致模型精度下降,因此许多研究同时配合知识蒸馏来恢复性能。
3. 蒸馏:通过将复杂模型中的知识转移到简单模型,实现保持性能的同时大幅减少计算复杂度。
通常不作为独立的优化方法,而是配合剪枝或近似使用,用于在模型精度下降后快速恢复性能。例如在MPCFormer和MPCViT等工作中,先用近似方法简化非线性函数,再通过知识蒸馏将原始大模型的知识迁移到轻量安全模型中,从而在保持较高精度的同时大幅降低推理时延。不过,论文也指出目前蒸馏在安全推理中的应用仍较初步,缺乏针对安全场景的参数和策略优化,蒸馏过程本身的开销也需要进一步控制。
(三)构建成本控制
论文特别指出,许多安全推理优化方案在追求推理效率的同时,引入了巨大的方案构建成本,尤其是需要重新训练模型或进行神经网络架构搜索(NAS),在大模型时代这些成本可能高得难以接受。针对这一问题,现有研究主要从两个方向探索降低成本:一是在NAS过程中压缩搜索空间,例如通过参数复用或搜索过程解耦来减少开销;二是设计避免或降低重训练开销的安全推理方案,如DReP基于神经元输出状态直接剪枝,或基于ReLU重要性分布进行快速近似。这些低成本构建方案目前主要集中在CNN中的ReLU剪枝和近似上,应用范围有限,但为未来在大模型上实现高效安全推理提供了重要思路。
(四)隐私保护框架
为了降低安全推理的开发门槛,研究者构建了多个隐私保护框架,封装底层密码协议,提供类似PyTorch、TensorFlow的高级接口。其中,CrypTen仿照PyTorch的接口设计,底层采用算数秘密共享和布尔秘密共享及其转换,用户只需少量修改代码即可将明文模型转为安全推理模型。SecretFlow-SPU则更进一步,不限定前端框架,用户可以用任何主流深度学习框架编写模型,再通过少量代码修改迁移到安全推理,它底层支持ABY3、Cheetah、semi2K等多种高效安全协议,且推理速度比传统框架快数倍。这些框架已被大量后续研究采用,尤其是在模型优化方向,研究者可以专注于策略本身而无需从头实现密码协议。
四、主要结论与贡献
-
提出了统一的层次分类框架(运算层 → 实现层 → 目标层),为后续研究提供了清晰的结构化视角,能容纳不同技术路线并进行公平对比。
-
系统对比了HE和MPC在线性与非线性运算中的效率-性能权衡
-
线性运算:HE密文计算慢但无交互;MPC(SS)交互通信是瓶颈,但离线预计算可大幅提速。
-
非线性运算:多项式近似(HE路线)简单但深层网络精度下降;MPC(GC/FSS)精确但通信或计算开销大。
-
不存在绝对最优方案,应依赖场景选择。
-
-
首次在综述中强调方案构建成本和隐私保护框架
-
指出许多高效方案需要重训练,成本被忽视;
-
总结了CrypTen、SecretFlow-SPU等框架,推动研究更贴近工程实践。
-
-
总结了现有研究的不足与未来方向
-
安全假设单一(大多半诚实),缺乏灵活的安全强度配置。
-
模型优化多依赖经验调参,缺乏可解释性。
-
缺少包含成本、易用性的综合评价指标。
-
五、知识体系
1. 隐私保护密码基础
1.1 同态加密(HE)
-
基本概念:允许在密文上直接进行计算,解密后结果与明文计算一致。
-
分类:
-
部分同态:仅支持加法(如Paillier)或仅支持乘法(如RSA)。
-
全同态加密(FHE):同时支持加法和乘法,但存在噪声增长问题,需自举(bootstrapping)操作,计算成本高。
-
层次型全同态加密(LFHE):根据预期电路深度预设参数,在有限深度内无需自举。
-
-
代表性方案:
-
BFV:适合整数运算,在数据量较大时效率高于CKKS。
-
CKKS:支持浮点数运算,适用于需要近似计算的场景。
-
-
关键技术:
-
SIMD批处理:将多个数据打包进一个密文,实现并行计算,摊销单次运算开销。
-
打包编码:通过精心设计多项式编码方式,减少昂贵操作(如旋转、重线性化)。
-
NTT/FFT:利用数论变换或快速傅里叶变换加速多项式乘法。
-
-
开销来源:密文计算(尤其是旋转操作)、加解密过程、噪声控制与自举、密文尺寸大导致的存储与传输开销。
1.2 安全多方计算(MPC)
-
定义:一组互不信任的参与方在保持输入隐私的同时协同完成计算。
-
核心密码原语:
-
秘密共享(SS):将秘密拆分为多个份额,需达到门限数量才能恢复。加法可在本地完成,乘法需交换份额(如Beaver三元组)。常见形式:Shamir秘密共享、复制秘密共享(2-out-of-3)。
-
混淆电路(GC):将函数表示为布尔电路,一方生成混淆表,另一方评估。适用于任意函数,通信轮数为常数,但通信量大。典型协议:姚氏GC、GMW。
-
不经意传输(OT):发送方有多个消息,接收方选择性获取其中一个,发送方不知接收方选了哪个。常用于MPC中的基础构建块,可通过OT扩展技术减少调用次数。
-
函数秘密共享(FSS):较新的原语,可将函数(如比较、ReLU)拆分为份额,评估时通信极低。已被用于高效实现ReLU、最大池化、Softmax等非线性运算。
-
-
通信开销:主要来源于份额交换和电路传输。离线预计算(如Beaver三元组)可将大部分交互移到预处理阶段,降低在线时延。
1.3 威胁模型
-
半诚实模型(SH, semi-honest):参与方严格遵循协议,但会尝试从接收到的数据中推断额外信息。安全性较弱,但可实现更高效率,目前大多数安全推理方案采用此假设。
-
恶意模型(MA, malicious):参与方可任意偏离协议行为(如发送错误数据、提前终止)。安全性强,但协议设计复杂、开销大,研究相对较少。
2. 深度学习基础
2.1 CNN(卷积神经网络)
CNN的核心思想是通过卷积算子对输入数据进行局部处理,并通过池化操作逐步提取高级特征,最后通过全连接网络对图像的特征表达进行分类。
- 线性算子:
卷积:卷积是卷积神经网络(CNN)中最核心的线性运算,用于从输入数据(如图像)中提取局部特征。
全连接:全连接层通常位于CNN的末端,用于将卷积层提取的高维特征映射到样本标签空间(如分类任务的各类别得分)。
平均池化:平均池化是一种下采样操作,用于缩小特征图的空间尺寸,减少计算量并增强特征的平移不变性。它在一个局部窗口(如 2×2)内计算所有元素的平均值,并将该平均值作为输出。
批归一化(BatchNorm,可转化为线性):批归一化是一种用于加速神经网络训练并提高稳定性的技术。它对每个小批量(batch)的数据进行标准化,使其均值接近0、方差接近1,然后再用可学习的缩放参数 γ 和平移参数 β 进行变换。。
- 非线性算子:神经网络中非线性特性的实现主要通过激活函数来完成
ReLU():深度神经网络中的激活函数。它的作用就是:把负数变成0,正数保持不变。
Sigmoid:用于二分类任务的输出层,将输出压缩到 (0,1)(0,1) 区间,可解释为概率。
Tanh:与Sigmoid类似,但输出范围为 (−1,1)(−1,1),均值为0,在某些场景下比Sigmoid更优。
最大池化:最大池化是一种下采样操作,主要用于CNN中减小特征图的空间尺寸,增强平移不变性并降低计算量。
2.2 Transformer:
- 线性算子:全连接、矩阵乘法(自注意力机制中的QK^T、与V相乘)。
-
非线性算子:Softmax(注意力权重归一化)、GeLU(前馈网络激活函数)、层归一化(LayerNorm,方差计算引入非线性)。
2.3 模型压缩与优化方法(面向安全推理)
-
剪枝:移除不重要的非线性单元(主要是ReLU)。分为结构化剪枝(层/通道级别)、非结构化剪枝(神经元级别)以及重新设计低ReLU网络架构。可在设定预算下自动搜索最佳剪枝对象。
-
近似:用计算开销更小的函数替代原非线性函数。例如:用低次多项式近似ReLU、用2Quad-Softmax近似Softmax、用ReLU或二次多项式替代GeLU。近年趋向自动化搜索最佳近似形式。
-
量化:降低数值精度(如浮点转定点),减少存储和计算开销。在MPC场景中可将量化位数作为可训练参数。
-
知识蒸馏:将大模型(教师)的知识迁移到小模型(学生),常用于剪枝或近似后的精度恢复,也可用于保护训练数据隐私。
2.3 神经网络架构搜索(NAS)
-
定义:利用算法自动设计神经网络结构,替代传统的人工设计。其核心目标是:在保证模型准确率(性能)的前提下,搜索出那些更适合进行加密计算(如包含更少的非线性运算、更利于并行处理)的模型结构。
-
在安全推理中的应用:解决非线性运算的优化问题。搜索低 ReLU 结构:搜索最优架构,以减少ReLU的使用次数;结构化剪枝:自动识别并移除网络中不重要的层或通道,从而降低计算复杂度。设计低 ReLU 数量的网络:在设定的ReLU预算下,自动寻找最优的剪枝对象,以平衡速度和精度。
-
挑战:虽然NAS能找到高效的模型,但它通常需要巨大的重训练开销
3. 安全推理核心技术
3.1 隐私保护线性运算协议
-
基于HE的线性协议:
-
利用HE同态加法与乘法直接实现卷积、矩阵乘。
-
优化方向:SIMD打包减少密文数量、精心编码消除旋转操作、频域FFT加速、分块处理大矩阵、层融合减少交互。
-
代表方案:CryptoNets(首次HE+CNN)、Gazelle(优化内核)、Cheetah(无旋转编码)、Iron/BOLT(Transformer矩阵乘法优化)。
-
①Gazelle:将同态加密(HE)与混淆电路(GC)两种密码技术“混合”使用,在线性层使用HE,非线性层使用GC,以此来同时确保安全性和较低的延迟。
-
单纯HE:在CNN的非线性层(如ReLU)效率极低。
-
单纯GC:在线性层(如卷积)通信开销巨大。
②CryptoNets:将HE与神经网络结合,并引入SIMD批处理技术,将多个数据打包进一个密文并行计算,摊销了单次运算开销。
-
基于MPC的线性协议:
-
主要采用秘密共享(SS),加法本地完成,乘法需份额交换。
-
优化方向:离线预生成Beaver三元组、使用复制秘密共享减少通信轮次、设计高效矩阵乘法协议(多项式编码+密文打包)、引入半诚实第三方辅助。
-
代表方案:SecureML(离线三元组)、ABY3(三方复制秘密共享)、BumbleBee(两方大矩阵乘法)。
-
3.2 隐私保护非线性运算协议
-
基于HE的近似方案:
-
用多项式(平方、三次、十次等)近似ReLU、Sigmoid等。
-
客户端辅助:密文发回客户端明文计算后返回(增加通信,降低安全强度)。
-
精度与效率权衡:低次多项式快但精度差,高次多项式开销大。
-
-
基于MPC的原生方案:
-
混淆电路(GC):实现任意非线性函数,但电路规模大。优化:模型二值化、缩小电路。
-
函数秘密共享(FSS):极低通信实现比较、ReLU、MaxPool、Softmax等。代表方案:AriaNN、SIGMA。
-
混合协议:SS+GC(查表法)、SS+OT(指数/除法协议),取各原语所长。
-
3.3 混合密码协议设计
-
动机:没有单一密码原语在所有运算上最优。HE适合线性但非线性弱,SS适合线性但交互多,GC/OT/FSS适合非线性但开销大。
-
典型混合策略:
-
线性层用HE或SS,非线性层用GC/FSS。
-
离线阶段生成Beaver三元组(SS),在线阶段执行线性运算。
-
结合SS与OT实现低交互比较。
-
多层协议栈:如CrypTen底层使用算术SS和布尔SS及其转换。
-
-
优势:平衡计算与通信开销,适应不同安全假设和场景需求。
3.4 安全感知模型优化
-
核心思想:将安全计算的约束(如特定算子开销、通信轮次)纳入模型设计和训练过程,而非事后优化。
-
具体方法:
-
将实际安全推理时延加入损失函数,训练出MPC感知的模型(如MPCViT)。
-
设计HE/MPC友好的激活函数(如可学习多项式、低次近似)。
-
利用NAS搜索针对特定安全协议的最优网络架构。
-
知识蒸馏将大模型能力迁移到轻量安全模型,避免大模型效率瓶颈。
-
-
优化目标:在保持可接受精度的前提下,最小化推理时延和通信开销,同时控制构建成本(如重训练开销)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)