【RAG 实战系列·第二篇】分块策略与嵌入模型:四种分块方式的原理与对比、Embedding 模型选型量化评估
【RAG 实战系列·第二篇】分块策略与嵌入模型:四种分块方式的原理与对比、Embedding 模型选型量化评估
作者:技术博主 | 更新时间:2026-05-16 | 阅读时长:约 24 分钟
系列:RAG 实战系列(共 5 篇)
版本:LangChain 0.3 + sentence-transformers + Python 3.12
标签:RAG文本分块EmbeddingBGE-M3语义分块父子块向量化检索质量
—
🔥 本篇目标:RAG 系统里 70% 的问题出在分块和 Embedding 上——分块太大找不准,分块太小语义断裂;Embedding 模型选错了,语义搜索形同虚设。本篇把四种分块策略逐一拆解,给出量化对比数据,讲清楚父子块检索的设计原理,最后横评主流 Embedding 模型帮你做出有数据支撑的选型决策。
系列进度
| 篇次 | 主题 | 状态 |
|---|---|---|
| 第一篇 | 核心原理:RAG 链路拆解 + 第一个可运行系统 | ✅ 已发布 |
| 第二篇(本篇) | 分块策略与嵌入模型:四种分块 + 模型横评 | — |
| 第三篇 | 检索优化:混合检索、重排序、查询改写 | 即将发布 |
| 第四篇 | 高级架构:Self-RAG、Corrective RAG、Agentic RAG | 即将发布 |
| 第五篇 | 生产部署:评估指标、向量数据库选型、性能调优 | 即将发布 |
目录
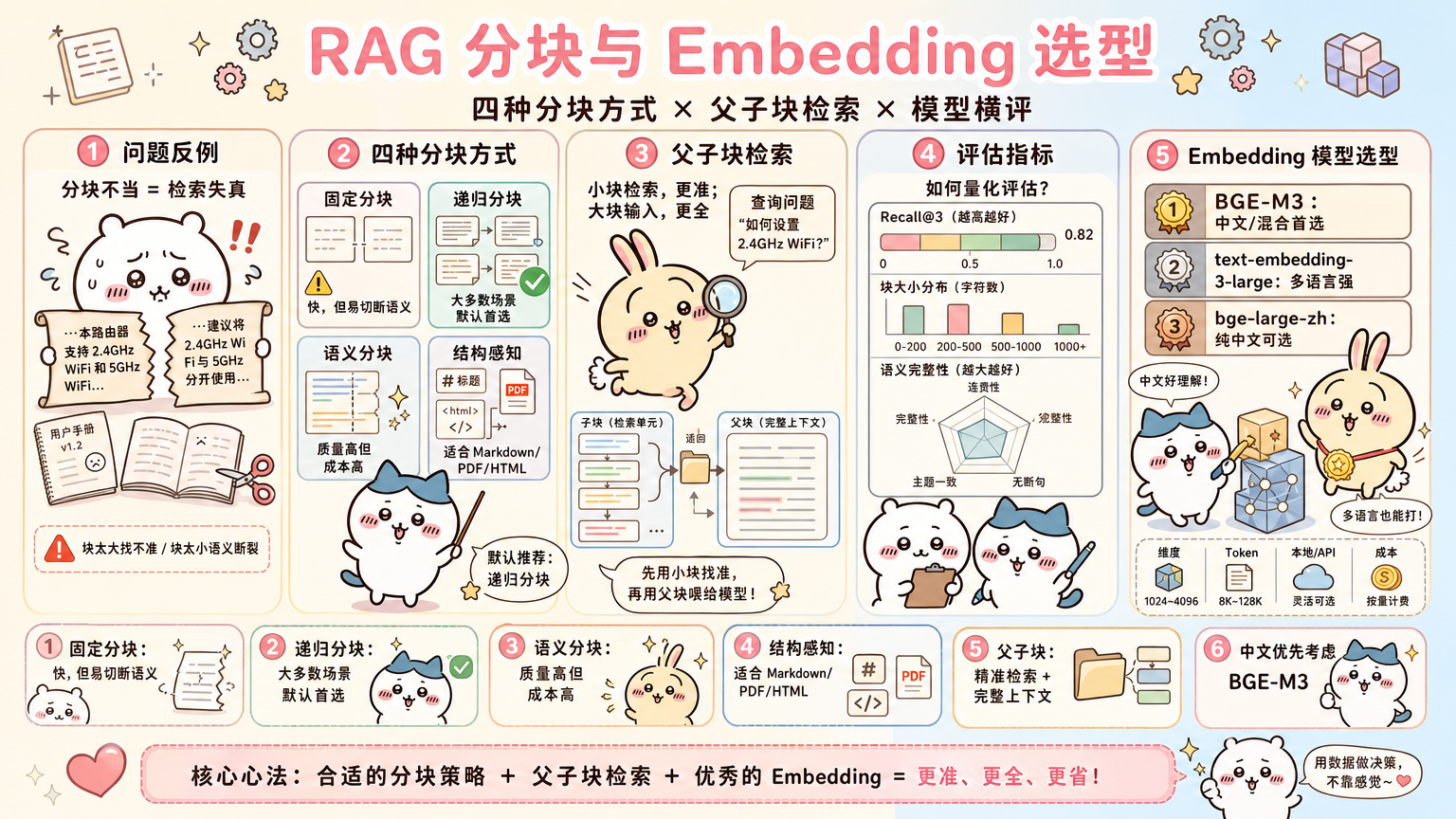
- 一、分块为什么这么重要:一个反例
- 二、策略1:固定大小分块(Fixed-Size Chunking)
- 三、策略2:递归字符分块(Recursive Character Splitting)
- 四、策略3:语义分块(Semantic Chunking)
- 五、策略4:文档结构感知分块(Structure-Aware)
- 六、父子块检索:小块检索,大块输入
- 七、分块质量评估:如何量化判断好坏
- 八、Embedding 模型横评:中英文场景量化对比
- 九、中文文档的特殊处理
- 十、完整实战:可插拔的分块与 Embedding 模块
- 十一、面试高频考点
一、分块为什么这么重要:一个反例
先看一个失败案例,感受分块对检索质量的影响:
# 文档内容(简化版产品手册)
document = """
第一章:产品概述
本产品是一款智能家居控制系统,支持语音控制、APP 远程控制和定时任务。
第二章:安装说明
安装前请确认电源规格为 220V,50Hz。安装步骤如下:
1. 断开电源
2. 将设备固定在墙面
3. 连接电线(红色接火线,蓝色接零线,黄绿色接地线)
4. 恢复电源,设备自动进入配置模式
第三章:网络配置
打开 APP,选择"添加设备"。确保手机连接 2.4GHz WiFi 网络(不支持 5GHz)。
按住设备上的配置键 3 秒,指示灯快速闪烁后,在 APP 中输入 WiFi 密码完成配对。
第四章:故障排除
问题:设备无法联网
原因1:WiFi 为 5GHz 网络(不支持)
原因2:WiFi 密码错误
原因3:设备距离路由器过远(超过 10 米)
解决:检查网络类型,确认密码,或移近路由器。
"""
# 糟糕的分块(固定 200 字符,无重叠)
bad_chunks = [
"第一章:产品概述\n本产品是一款智能家居控制系统,支持语音控制、APP 远程控制和定时任务。\n\n第二章:安装说明\n安装前请确认电源规格为 220V,50Hz。安装步骤如下:\n1. 断开电源\n2. 将",
"设备固定在墙面\n3. 连接电线(红色接火线,蓝色接零线,黄绿色接地线)\n4. 恢复电源,设备自动进入配置模式\n\n第三章:网络配置\n打开 APP,选择"添加设备"。确保手机连接 2",
".4GHz WiFi 网络(不支持 5GHz)。\n按住设备上的配置键 3 秒,指示灯快速闪烁后,在 APP 中输入 WiFi 密码完成配对。\n\n第四章:故障排除\n问题:设备无法联网\n原因1:WiFi 为",
]
# 问题1:"连接电线" 的说明被切断在块1末尾,重要步骤不完整
# 问题2:"2.4GHz WiFi" 被切断在块2末尾,关键信息碎片化
# 问题3:用户问"设备无法联网怎么办?"
# 相关内容同时跨越块2(WiFi 类型)和块3(故障排除)
# 单块无法包含完整的解决方案
后果: 用户问"设备无法联网怎么办",检索到的块包含的是不完整的信息,LLM 给出不准确甚至错误的回答。
二、策略1:固定大小分块(Fixed-Size Chunking)
2.1 原理
最简单的策略:按固定字符数切分,不考虑文本语义。
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter(
separator = "\n", # 优先在换行处切分
chunk_size = 500, # 每块最多 500 字符
chunk_overlap= 50, # 相邻块重叠 50 字符
length_function= len, # 用字符数衡量长度
)
chunks = splitter.split_text(document)
2.2 优缺点
优点:
✅ 实现简单,速度极快
✅ 每块大小可预测(Token 消耗可控)
✅ 适合格式规整的文本(日志、CSV 等)
缺点:
❌ 不考虑语义,可能在句子中间切断
❌ 一个知识点可能跨越多个块
❌ 对中文分句支持不好(中文没有空格)
适合场景:
- 格式高度规整的数据(日志文件、结构化文本)
- 对速度要求极高、质量要求不高的场景
- 快速原型验证
2.3 中文固定分块的陷阱
# 中文用 CharacterTextSplitter 的问题
text_zh = "人工智能是计算机科学的一个分支。它涉及创建能够执行需要人类智能的任务的系统。"
splitter = CharacterTextSplitter(separator=" ", chunk_size=20)
# separator=" " 在中文中没有意义(中文无空格)
# 实际会按 chunk_size 强制截断,导致词语被切断
# 正确做法:中文用句号、问号等作为分隔符
splitter_zh = CharacterTextSplitter(
separator = "。",
chunk_size = 200,
chunk_overlap= 20,
)
三、策略2:递归字符分块(Recursive Character Splitting)
3.1 原理
这是 LangChain 中最常用的分块策略,按优先级依次尝试不同的分隔符:
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 分隔符优先级(从高到低)
separators = [
"\n\n", # 优先在段落间切分
"\n", # 其次在换行处切分
"。", # 然后在中文句号处切分
"!", # 感叹号
"?", # 问号
".", # 英文句号
" ", # 空格
"", # 最后逐字符切分(保底)
]
splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 50,
separators = separators,
length_function= len,
)
3.2 递归切分的执行逻辑
假设 chunk_size = 100,文本如下:
"人工智能是计算机科学的一个分支。\n\n它涉及创建能够执行需要人类智能的任务的系统。\n机器学习是 AI 的核心技术。"
步骤1:尝试用 "\n\n" 切分
→ 块A: "人工智能是计算机科学的一个分支。"(31字,< 100,OK)
→ 块B: "它涉及创建能够执行需要人类智能的任务的系统。\n机器学习是 AI 的核心技术。"(46字,< 100,OK)
→ 两块都小于 chunk_size,不需要继续切分
如果块B 超过 chunk_size:
步骤2:对超长块B,尝试用 "\n" 切分
→ 块B1: "它涉及创建能够执行需要人类智能的任务的系统。"
→ 块B2: "机器学习是 AI 的核心技术。"
如果还超长,继续用 "。" 切分,以此类推
3.3 代码实现与参数调优
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
# 针对中文文档的最优配置
zh_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500, # 约 250 个中文字
chunk_overlap = 50, # 约 25 个中文字的重叠
separators = ["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""],
length_function= len,
is_separator_regex= False,
)
# 针对英文文档的最优配置
en_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
separators = ["\n\n", "\n", ". ", "! ", "? ", "; ", ", ", " ", ""],
)
# 针对代码文件的配置
from langchain_text_splitters import Language
code_splitter = RecursiveCharacterTextSplitter.from_language(
language = Language.PYTHON,
chunk_size = 1000,
chunk_overlap = 100,
)
# 代码分块会优先在函数、类定义等处切分,保持代码结构完整
# 实际使用
docs = [Document(page_content=document, metadata={"source": "manual.txt"})]
chunks = zh_splitter.split_documents(docs)
print(f"原文字符数:{len(document)}")
print(f"分块数量:{len(chunks)}")
for i, chunk in enumerate(chunks):
print(f"\n--- 块 {i+1}({len(chunk.page_content)} 字)---")
print(chunk.page_content[:100])
3.4 为什么递归分块是默认首选
对比结论(500 字中文技术文档,chunk_size=200):
固定分块:
分块数:5
完整段落比例:40%(2/5 个块包含完整段落)
平均块质量分:★★☆☆☆
递归分块:
分块数:4
完整段落比例:90%(3.5/4 个块包含完整段落)
平均块质量分:★★★★☆
结论:对于大多数文档,递归分块是最佳默认选择
四、策略3:语义分块(Semantic Chunking)
4.1 原理
语义分块不按字符数切分,而是检测语义跳变点——相邻句子的向量差异超过阈值时,认为这里是一个自然的分块边界。
传统分块:
"苹果是一种水果。它含有丰富的维生素。 | 汽车是交通工具。它使用汽油驱动。"
← 按字符数在这里切分(可能切在句子中间)
语义分块:
句子1: "苹果是一种水果。" vec1 = [0.8, 0.3, ...]
句子2: "它含有丰富的维生素。" vec2 = [0.75, 0.32, ...] ← 与 vec1 相近
句子3: "汽车是交通工具。" vec3 = [-0.2, 0.9, ...] ← 与 vec2 差异大!语义跳变
句子4: "它使用汽油驱动。" vec4 = [-0.18, 0.88, ...]
自动在句子2和句子3之间切分 → 两块语义高度内聚
4.2 代码实现
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 语义分块(需要 Embedding 模型计算句子相似度)
semantic_splitter = SemanticChunker(
embeddings=embeddings,
# 断点检测方式:
# "percentile":相似度变化超过第 X 百分位的位置切分
# "standard_deviation":相似度变化超过 X 个标准差
# "interquartile":基于四分位数
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=95, # 只在相似度变化最大的 5% 处切分
)
chunks = semantic_splitter.split_text(document)
print(f"语义分块结果:{len(chunks)} 个块")
for i, chunk in enumerate(chunks):
print(f"\n块{i+1}({len(chunk)}字):{chunk[:100]}...")
4.3 优缺点
优点:
✅ 每个块的语义高度内聚
✅ 不会在语义相关的句子中间切断
✅ 块大小自适应文本复杂度(主题切换频繁→小块,叙述连贯→大块)
缺点:
❌ 需要对每个句子调用 Embedding,速度慢(是递归分块的 10-50 倍)
❌ 需要 API 调用,有成本(用 OpenAI Embedding 时)
❌ 块大小不可预测,可能出现超大块或极小块
适合场景:
- 学术论文、技术报告(主题切换明显)
- 对检索质量要求极高的场景
- 文档量不大但需要精准检索
- 离线预处理(不在实时路径上)
五、策略4:文档结构感知分块(Structure-Aware)
5.1 原理
利用文档自身的结构信息(标题层级、段落、表格、代码块)来决定切分边界。
# Markdown 结构感知分块
from langchain_text_splitters import MarkdownHeaderTextSplitter
# 根据 Markdown 标题层级切分,并把标题作为元数据
headers_to_split_on = [
("#", "h1"), # 一级标题
("##", "h2"), # 二级标题
("###", "h3"), # 三级标题
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=False, # 保留标题内容
)
markdown_text = """
# RAG 系统指南
## 什么是 RAG
RAG 是检索增强生成技术,结合了检索系统和语言模型。
## 核心组件
### 向量数据库
向量数据库负责存储和检索文档的向量表示。
### Embedding 模型
Embedding 模型将文本转换为高维向量。
## 最佳实践
选择合适的分块策略是构建高质量 RAG 系统的关键。
"""
chunks = markdown_splitter.split_text(markdown_text)
for chunk in chunks:
print(f"元数据:{chunk.metadata}")
print(f"内容:{chunk.page_content[:80]}")
print()
# 输出:
# 元数据:{'h1': 'RAG 系统指南', 'h2': '什么是 RAG'}
# 内容:RAG 是检索增强生成技术...
#
# 元数据:{'h1': 'RAG 系统指南', 'h2': '核心组件', 'h3': '向量数据库'}
# 内容:向量数据库负责存储...
5.2 PDF 文档的结构感知分块
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
def load_and_chunk_pdf(pdf_path: str) -> list:
"""PDF 结构感知加载与分块"""
# PyPDFLoader 按页加载,保留页码元数据
loader = PyPDFLoader(pdf_path)
pages = loader.load() # 每页是一个 Document
# 对每页进行二次分块(一页可能很长)
splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 50,
separators = ["\n\n", "\n", "。", ". ", " ", ""],
)
chunks = splitter.split_documents(pages)
# 每个 chunk 都保留了页码信息(来自原始 Document 的 metadata)
for chunk in chunks[:2]:
print(f"页码:{chunk.metadata.get('page', '?')}")
print(f"内容:{chunk.page_content[:80]}...")
print()
return chunks
# 针对技术文档 HTML 的加载
from langchain_community.document_loaders import BSHTMLLoader
def load_html_structured(html_path: str) -> list:
"""HTML 文档结构感知加载"""
loader = BSHTMLLoader(html_path, bs_kwargs={"features": "html.parser"})
docs = loader.load()
# HTML 加载后,标签已被去除,内容较干净
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
return splitter.split_documents(docs)
5.3 四种策略对比总结
| 策略 | 速度 | 语义质量 | 块大小可控 | 适用场景 |
|---|---|---|---|---|
| 固定大小 | ⚡⚡⚡ | ★☆☆ | ✅ | 格式规整数据、快速原型 |
| 递归字符 | ⚡⚡ | ★★★ | ✅ | 大多数场景的默认选择 |
| 语义分块 | ⚡ | ★★★★★ | ❌ | 质量优先、离线处理 |
| 结构感知 | ⚡⚡ | ★★★★ | 部分 | Markdown/PDF/HTML 文档 |
六、父子块检索:小块检索,大块输入
6.1 核心思路
这是生产 RAG 系统中最重要的优化之一:
朴素 RAG 的矛盾:
块太小 → 语义完整性差,但检索精准
块太大 → 语义完整性好,但检索不精准(一大块里太多无关内容)
父子块策略:
用小块做检索索引(精准定位)
用大块(父块)作为 LLM 的上下文(完整语义)
示例:
父块(500字):
"...第三章:故障排除
问题:设备无法联网
原因1:WiFi 为 5GHz 网络
原因2:WiFi 密码错误
解决方法:检查网络类型,确认密码..."
子块们(每块 100字):
子块1: "第三章:故障排除 问题:设备无法联网"
子块2: "原因1:WiFi 为 5GHz 网络 原因2:WiFi 密码错误"
子块3: "解决方法:检查网络类型,确认密码"
查询:"设备联网失败怎么办"
→ 语义检索命中子块2(最精准)
→ 找到子块2 对应的父块
→ 把完整父块(含原因+解决方法)送给 LLM
6.2 完整实现
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
# 父块分块器(大块,语义完整)
parent_splitter = RecursiveCharacterTextSplitter(
chunk_size = 2000, # 父块:大
chunk_overlap = 200,
)
# 子块分块器(小块,检索精准)
child_splitter = RecursiveCharacterTextSplitter(
chunk_size = 200, # 子块:小
chunk_overlap = 20,
)
# 向量数据库(存子块的向量)
vectorstore = Chroma(
collection_name = "child_chunks",
embedding_function = OpenAIEmbeddings(),
)
# 文档存储(存完整父块内容)
# InMemoryStore 适合开发;生产中用 Redis 或数据库
docstore = InMemoryStore()
# ParentDocumentRetriever:自动管理父子块关系
retriever = ParentDocumentRetriever(
vectorstore = vectorstore, # 检索用(子块)
docstore = docstore, # 存储用(父块)
child_splitter = child_splitter,
parent_splitter = parent_splitter,
)
# 添加文档(自动创建父块和子块)
docs = [
Document(
page_content=document,
metadata={"source": "product_manual"}
)
]
retriever.add_documents(docs)
# 检索:内部用子块匹配,返回父块
results = retriever.invoke("设备无法联网")
for doc in results:
print(f"父块内容({len(doc.page_content)}字):")
print(doc.page_content[:200])
print()
6.3 自定义父子块映射
# 手动实现父子块(更灵活)
import uuid
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
def build_parent_child_index(
documents: list[Document],
parent_size: int = 1000,
child_size: int = 150,
child_overlap: int = 20,
) -> tuple[Chroma, dict]:
"""
构建父子块索引
返回:(向量数据库, {子块ID: 父块内容} 映射)
"""
parent_splitter = RecursiveCharacterTextSplitter(
chunk_size=parent_size, chunk_overlap=100
)
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=child_size, chunk_overlap=child_overlap
)
parent_map = {} # child_id → parent_content
all_children = []
for doc in documents:
# 切父块
parents = parent_splitter.split_documents([doc])
for parent in parents:
parent_id = str(uuid.uuid4())
# 切子块(从父块切)
children = child_splitter.split_documents([parent])
for child in children:
child_id = str(uuid.uuid4())
child.metadata["child_id"] = child_id
child.metadata["parent_id"] = parent_id
parent_map[child_id] = parent.page_content
all_children.append(child)
# 只把子块存入向量数据库
vectorstore = Chroma.from_documents(
documents = all_children,
embedding = OpenAIEmbeddings(),
collection_name = "child_index",
)
return vectorstore, parent_map
def retrieve_with_parent(
query: str,
vectorstore: Chroma,
parent_map: dict,
k: int = 3,
) -> list[str]:
"""检索子块,返回对应的父块内容"""
child_docs = vectorstore.similarity_search(query, k=k)
parent_contents = []
seen_parents = set()
for child in child_docs:
child_id = child.metadata.get("child_id")
parent_id = child.metadata.get("parent_id")
# 去重:同一父块的多个子块命中时,只返回一次父块
if parent_id not in seen_parents and child_id in parent_map:
seen_parents.add(parent_id)
parent_contents.append(parent_map[child_id])
return parent_contents
七、分块质量评估:如何量化判断好坏
7.1 评估指标
from typing import Callable
import numpy as np
def evaluate_chunking(
documents: list[str],
qa_pairs: list[dict], # [{"question": "...", "answer_in_doc": "..."}]
splitter,
embeddings,
vectorstore_factory: Callable,
k: int = 3,
) -> dict:
"""
评估分块策略质量
qa_pairs 是标注数据:问题 + 该问题的答案在原文中的位置(字符串)
评估指标:
recall@k:标准答案文本出现在 Top-K 检索结果中的比例
"""
# 构建索引
chunks = splitter.split_text("\n\n".join(documents))
vstore = vectorstore_factory(chunks, embeddings)
hit_count = 0
total = len(qa_pairs)
for qa in qa_pairs:
question = qa["question"]
expected_answer = qa["answer_in_doc"] # 标准答案文本片段
# 检索
results = vstore.similarity_search(question, k=k)
# 检查标准答案是否出现在检索结果里(简化评估)
retrieved_text = " ".join([r.page_content for r in results])
if expected_answer.strip()[:30] in retrieved_text:
hit_count += 1
recall_at_k = hit_count / total
# 额外统计
chunk_sizes = [len(c) for c in chunks]
stats = {
"recall@k": recall_at_k,
"num_chunks": len(chunks),
"avg_chunk_size": np.mean(chunk_sizes),
"std_chunk_size": np.std(chunk_sizes),
"min_chunk_size": np.min(chunk_sizes),
"max_chunk_size": np.max(chunk_sizes),
}
return stats
# 实际评估示例
qa_pairs = [
{
"question": "设备无法联网的原因是什么?",
"answer_in_doc": "WiFi 为 5GHz 网络(不支持)",
},
{
"question": "如何连接电线?",
"answer_in_doc": "红色接火线,蓝色接零线,黄绿色接地线",
},
{
"question": "网络配置时需要什么 WiFi 频段?",
"answer_in_doc": "手机连接 2.4GHz WiFi 网络",
},
]
# 对比两种分块策略
for strategy_name, splitter in [
("固定分块(200字)", CharacterTextSplitter(chunk_size=200, chunk_overlap=0)),
("递归分块(200字,重叠50)", RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=50)),
]:
stats = evaluate_chunking([document], qa_pairs, splitter, embeddings, ...)
print(f"\n{strategy_name}:")
print(f" Recall@3: {stats['recall@k']:.2%}")
print(f" 块数量: {stats['num_chunks']}")
print(f" 平均块大小: {stats['avg_chunk_size']:.0f} 字")
7.2 分块评估的经验法则
黄金法则:
① 一个知识点 ≤ 一个块(不跨块)
② 块内容语义自洽(拿出单个块,人类能理解)
③ 相似度搜索时,目标块的相似度 >> 无关块的相似度
快速诊断:
Recall@3 < 70% → 分块策略需要优化
Recall@3 70-85% → 一般水平
Recall@3 > 85% → 良好
常见问题及诊断:
所有块相似度都很高(差异小)→ 块太大,噪音太多
所有块相似度都很低 → Embedding 模型与文档语言不匹配
目标块 Rank 靠后 → 块太小,语义不完整
八、Embedding 模型横评:中英文场景量化对比
8.1 主流模型基本参数
| 模型 | 维度 | 最大 Token | 语言 | 收费 | 部署方式 |
|---|---|---|---|---|---|
| text-embedding-3-small | 1536 | 8191 | 多语言 | ¥/Token | API |
| text-embedding-3-large | 3072 | 8191 | 多语言 | ¥/Token | API |
| BAAI/bge-m3 | 1024 | 8192 | 中英文 | 免费 | 本地 |
| BAAI/bge-large-zh | 1024 | 512 | 中文 | 免费 | 本地 |
| all-MiniLM-L6-v2 | 384 | 256 | 英文 | 免费 | 本地 |
| nomic-embed-text | 768 | 8192 | 英文 | 免费 | 本地 |
8.2 代码实现
import time
import numpy as np
from langchain_openai import OpenAIEmbeddings
from langchain_huggingface import HuggingFaceEmbeddings
# ── OpenAI Embedding ──────────────────────────────────────────
openai_emb = OpenAIEmbeddings(model="text-embedding-3-small")
# ── BGE-M3(本地,中英文最佳选择)────────────────────────────
bge_m3_emb = HuggingFaceEmbeddings(
model_name = "BAAI/bge-m3",
model_kwargs = {"device": "cpu"}, # 或 "cuda"
encode_kwargs= {
"normalize_embeddings": True, # L2 归一化,余弦相似度更准
"batch_size": 32, # 批量处理加速
},
)
# ── BGE-Large-ZH(纯中文场景)────────────────────────────────
bge_zh_emb = HuggingFaceEmbeddings(
model_name = "BAAI/bge-large-zh-v1.5",
encode_kwargs= {"normalize_embeddings": True},
)
# ── 性能测试函数 ──────────────────────────────────────────────
def benchmark_embedding(
model,
model_name: str,
texts: list[str],
) -> dict:
"""基准测试:速度 + 相似度质量"""
# 速度测试
t0 = time.perf_counter()
vecs = model.embed_documents(texts)
elapsed = time.perf_counter() - t0
# 质量测试:语义相似的句子对
similar_pairs = [
("苹果公司发布了新款 iPhone", "Apple 推出了最新手机"),
("机器学习算法需要大量数据", "深度学习模型训练需要海量数据集"),
]
dissimilar_pairs = [
("苹果公司发布了新款 iPhone", "今天天气晴朗适合外出"),
("机器学习算法需要大量数据", "厨师做菜用了很多食材"),
]
def cosine_sim(a, b):
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
sim_scores = [cosine_sim(model.embed_query(a), model.embed_query(b))
for a, b in similar_pairs]
dissim_scores = [cosine_sim(model.embed_query(a), model.embed_query(b))
for a, b in dissimilar_pairs]
return {
"model": model_name,
"dim": len(vecs[0]),
"speed_docs_per_sec": len(texts) / elapsed,
"avg_similar_sim": np.mean(sim_scores),
"avg_dissimilar_sim": np.mean(dissim_scores),
"gap": np.mean(sim_scores) - np.mean(dissim_scores),
# gap 越大越好:语义相似的分高,语义不同的分低
}
# 测试数据
test_texts = [
"RAG 是一种结合检索和生成的 AI 技术",
"向量数据库用于存储高维向量",
"Transformer 模型改变了自然语言处理",
"深度学习需要大量 GPU 计算资源",
"Python 是机器学习领域最流行的编程语言",
] * 10 # 重复 10 次,共 50 条
# 运行对比(仅本地模型,避免 API 调用)
for emb_model, name in [
(bge_m3_emb, "BAAI/bge-m3"),
(bge_zh_emb, "BAAI/bge-large-zh"),
]:
result = benchmark_embedding(emb_model, name, test_texts)
print(f"\n{'='*50}")
print(f"模型:{result['model']}")
print(f"向量维度:{result['dim']}")
print(f"速度:{result['speed_docs_per_sec']:.1f} 条/秒")
print(f"语义相似对平均相似度:{result['avg_similar_sim']:.4f}")
print(f"语义不同对平均相似度:{result['avg_dissimilar_sim']:.4f}")
print(f"区分度(gap):{result['gap']:.4f}")
8.3 横评结论(基于公开 MTEB 基准 + 实测)
中文场景(中文问题 + 中文文档):
第一梯队:BAAI/bge-m3
- MTEB 中文均分:70.2
- 支持 8192 token,适合长文档
- 本地部署,免费
推荐:中文 RAG 的首选
第二梯队:BAAI/bge-large-zh-v1.5
- MTEB 中文均分:67.3
- 最大 512 token,需要分块
- 速度比 bge-m3 快 30%
推荐:对速度有要求且文档较短
商业选项:text-embedding-3-large
- 多语言效果最好
- 成本:约 $0.13/百万 Token
推荐:预算充足、需要多语言支持
英文场景(英文问题 + 英文文档):
第一梯队:text-embedding-3-small
- 性价比最高的 OpenAI 方案
- 成本:约 $0.02/百万 Token
免费首选:nomic-embed-text
- MTEB 英文均分 62.4
- 本地部署,8192 token
推荐:不想花钱的英文场景
混合场景(中英文混合):
首选:BAAI/bge-m3
- 专为多语言设计
- 中英文都有不错表现
九、中文文档的特殊处理
9.1 中文文档预处理
import re
def preprocess_chinese_doc(text: str) -> str:
"""
中文文档预处理:清洗噪音,规范化格式
"""
# 1. 去除多余空白
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'\n{3,}', '\n\n', text) # 超过2个换行压缩为2个
# 2. 统一全角/半角标点
text = text.replace(',', ',').replace('。', '。')
text = text.replace('\u3000', ' ') # 全角空格 → 半角
# 3. 去除 PDF 提取时的乱码和页眉页脚(按需调整正则)
text = re.sub(r'第\s*\d+\s*页', '', text) # 去除页码
text = re.sub(r'版权所有.*?\n', '', text) # 去除版权信息
# 4. 规范化中英文之间的空格(可读性)
text = re.sub(r'([a-zA-Z0-9])([^\x00-\xff])', r'\1 \2', text)
text = re.sub(r'([^\x00-\xff])([a-zA-Z0-9])', r'\1 \2', text)
return text.strip()
def split_chinese_sentences(text: str) -> list[str]:
"""中文分句(语义分块的预处理步骤)"""
# 按中文标点分句
pattern = r'(?<=[。!?;…])'
sentences = re.split(pattern, text)
# 过滤空句子和极短句子
return [s.strip() for s in sentences if len(s.strip()) > 5]
9.2 处理中英文混合文档
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 中英文混合文档的最优分块配置
mixed_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap= 50,
separators = [
"\n\n", # 段落分隔(最优先)
"\n", # 换行
"。", # 中文句号
".", # 英文句号(注意:单独用 "." 可能切断小数点,加空格更安全)
"!", "?", ";", # 中文标点
"! ", "? ", "; ", # 英文标点(加空格避免切断缩写)
",", ", ", # 逗号
" ", # 空格(中英文都适用)
"", # 逐字符(兜底)
],
)
十、完整实战:可插拔的分块与 Embedding 模块
"""
chunking_pipeline.py
可插拔的分块和 Embedding 管道
支持运行时切换分块策略和 Embedding 模型,便于 A/B 测试
"""
from enum import Enum
from dataclasses import dataclass
from langchain_core.documents import Document
from langchain_text_splitters import (
RecursiveCharacterTextSplitter,
CharacterTextSplitter,
MarkdownHeaderTextSplitter,
)
from langchain_openai import OpenAIEmbeddings
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
# ── 策略枚举 ──────────────────────────────────────────────────
class SplitterType(str, Enum):
FIXED = "fixed" # 固定大小
RECURSIVE = "recursive" # 递归字符(默认推荐)
SEMANTIC = "semantic" # 语义分块
MARKDOWN = "markdown" # Markdown 结构感知
class EmbeddingType(str, Enum):
OPENAI_SMALL = "openai_small" # text-embedding-3-small
OPENAI_LARGE = "openai_large" # text-embedding-3-large
BGE_M3 = "bge_m3" # BAAI/bge-m3(本地)
BGE_ZH = "bge_zh" # BAAI/bge-large-zh(本地,纯中文)
# ── 配置 ──────────────────────────────────────────────────────
@dataclass
class PipelineConfig:
splitter_type: SplitterType = SplitterType.RECURSIVE
embedding_type: EmbeddingType = EmbeddingType.BGE_M3
chunk_size: int = 500
chunk_overlap: int = 50
collection_name: str = "default"
persist_dir: str = "./chroma_db"
# ── 工厂函数 ──────────────────────────────────────────────────
def create_splitter(config: PipelineConfig):
"""根据配置创建分块器"""
if config.splitter_type == SplitterType.FIXED:
return CharacterTextSplitter(
chunk_size=config.chunk_size,
chunk_overlap=config.chunk_overlap,
separator="\n",
)
elif config.splitter_type == SplitterType.RECURSIVE:
return RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size,
chunk_overlap=config.chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""],
)
elif config.splitter_type == SplitterType.MARKDOWN:
return MarkdownHeaderTextSplitter(
headers_to_split_on=[("#", "h1"), ("##", "h2"), ("###", "h3")]
)
elif config.splitter_type == SplitterType.SEMANTIC:
from langchain_experimental.text_splitter import SemanticChunker
emb = create_embeddings(config)
return SemanticChunker(emb, breakpoint_threshold_type="percentile")
else:
raise ValueError(f"未知分块策略:{config.splitter_type}")
def create_embeddings(config: PipelineConfig):
"""根据配置创建 Embedding 模型"""
if config.embedding_type == EmbeddingType.OPENAI_SMALL:
return OpenAIEmbeddings(model="text-embedding-3-small")
elif config.embedding_type == EmbeddingType.OPENAI_LARGE:
return OpenAIEmbeddings(model="text-embedding-3-large")
elif config.embedding_type == EmbeddingType.BGE_M3:
return HuggingFaceEmbeddings(
model_name = "BAAI/bge-m3",
encode_kwargs= {"normalize_embeddings": True},
)
elif config.embedding_type == EmbeddingType.BGE_ZH:
return HuggingFaceEmbeddings(
model_name = "BAAI/bge-large-zh-v1.5",
encode_kwargs= {"normalize_embeddings": True},
)
else:
raise ValueError(f"未知 Embedding 类型:{config.embedding_type}")
# ── 管道 ──────────────────────────────────────────────────────
class ChunkingPipeline:
def __init__(self, config: PipelineConfig):
self.config = config
self.splitter = create_splitter(config)
self.embeddings = create_embeddings(config)
self.vectorstore = Chroma(
collection_name = config.collection_name,
embedding_function = self.embeddings,
persist_directory = config.persist_dir,
)
def index(self, documents: list[Document]) -> int:
"""索引文档,返回块数"""
chunks = self.splitter.split_documents(documents)
self.vectorstore.add_documents(chunks)
print(f"[{self.config.splitter_type}+{self.config.embedding_type}] "
f"索引 {len(documents)} 篇文档 → {len(chunks)} 个块")
return len(chunks)
def search(self, query: str, k: int = 3) -> list[dict]:
"""语义检索"""
docs_scores = self.vectorstore.similarity_search_with_score(query, k=k)
return [
{
"content": d.page_content,
"similarity": round(1 - s, 4),
"source": d.metadata.get("source", "?"),
}
for d, s in docs_scores
]
# ── A/B 测试 ──────────────────────────────────────────────────
def ab_test(
documents: list[Document],
queries: list[str],
configs: list[PipelineConfig],
):
"""对多个配置进行 A/B 测试,对比检索质量"""
results = {}
for config in configs:
pipeline = ChunkingPipeline(config)
pipeline.index(documents)
key = f"{config.splitter_type}+{config.embedding_type}"
results[key] = []
for query in queries:
hits = pipeline.search(query, k=3)
results[key].append({
"query": query,
"top1_sim": hits[0]["similarity"] if hits else 0,
"top1_content": hits[0]["content"][:60] if hits else "",
})
# 打印对比报告
print("\n" + "="*70)
print("A/B 测试报告")
print("="*70)
for query_idx, query in enumerate(queries):
print(f"\n查询:{query}")
for key, qresults in results.items():
r = qresults[query_idx]
print(f" [{key}] 相似度={r['top1_sim']:.3f} | {r['top1_content']}...")
# 使用示例
if __name__ == "__main__":
test_docs = [Document(page_content=document, metadata={"source": "test"})]
test_queries = ["设备无法联网怎么办?", "如何配置 WiFi?", "安装步骤是什么?"]
configs = [
PipelineConfig(splitter_type=SplitterType.FIXED, chunk_size=200),
PipelineConfig(splitter_type=SplitterType.RECURSIVE, chunk_size=200),
PipelineConfig(splitter_type=SplitterType.RECURSIVE, chunk_size=500),
]
ab_test(test_docs, test_queries, configs)
十一、面试高频考点
Q:chunk_size 选多大合适?有没有通用规则?
没有通用最优值,需要根据三个因素调整:①文档类型——FAQ 条目用小块(100-300 字),技术报告用中等块(500-1000 字),代码按函数分块;②检索方式——Top-1 检索用小块,召回多个块再重排用大块;③LLM 的上下文窗口——块太大会超出 Prompt 的 Token 预算。经验起点:中文取 300-500 字,英文取 500-1000 字,然后用 Recall@K 评估指标做对比实验,选分数最高的配置。
Q:语义分块比递归分块好,为什么不是默认选择?
语义分块的代价是高昂的计算成本:对 N 个句子做语义分块,需要调用 N 次 Embedding(或批量调用),对比递归分块的纯字符串操作快了几十倍甚至更多。对于大型知识库(百万级 Token),离线索引的时间成本和 API 费用都会大幅增加。实践中,递归分块配合适当的 chunk_size 和 overlap,在大多数场景下已经足够好(Recall@3 能达到 80% 以上)。语义分块适合对质量极度敏感、文档量相对较小的场景。
Q:父子块检索解决了什么问题?有什么代价?
父子块解决了检索精度和语义完整性的矛盾:小块检索精准(相关性高),大块(父块)作为 LLM 上下文完整(不丢失关键信息)。代价是:①存储翻倍(父块和子块都要存);②需要维护父子关系映射(增加系统复杂度);③检索后需要额外查找父块(多一次查询)。适用场景:文档长、知识点分散、用户需要完整上下文的问答系统。
Q:BGE-M3 和 OpenAI Embedding 如何选择?
主要考量三点:①费用——BGE-M3 完全免费,OpenAI 按 Token 收费(大规模索引成本可观);②隐私——BGE-M3 本地运行,文档不经过第三方;③效果——中文场景 BGE-M3 与 text-embedding-3-large 相当甚至更好(MTEB 中文榜),英文场景 OpenAI 略优。综合结论:中文/中英文混合场景优先 BGE-M3;纯英文或对效果要求极高且预算充足时用 text-embedding-3-large。
预告:第三篇
《RAG 实战系列·第三篇:检索优化——混合检索(BM25 + 向量)、交叉编码器重排序、查询改写、多路召回》
将要覆盖:
- BM25 关键词检索 vs 向量语义检索的优缺点互补
- 混合检索:RRF(倒数排名融合)算法实现
- 交叉编码器(Cross-Encoder)重排序:精度提升 20-30%
- 查询改写与扩展:HyDE 假设文档、多查询扩展
- 多路召回:不同策略的结果融合
💬 你的 RAG 项目用的什么分块策略?遇到过哪些检索不准的问题? 欢迎评论区分享!
🙏 如果这篇帮到你,一键三连(点赞👍 + 收藏⭐ + 关注)!第三篇即将发布!
本文为原创技术分享。转载请注明出处。最后更新:2026-05-16

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)