AI 写后端:如何让 AI 守住 Controller、Service、Mapper 的边界
如果你已经把 AI 用到了真实后端项目,大概率很快会遇到一个问题:# AI 写后端:如何让 AI 守住 Controller、Service、Mapper 的边界
摘要:本文基于 Sourcelin Blog 项目实践,分享如何让 AI 在参与后端开发时保持清晰的分层边界。核心观点是:AI 写后端的关键不是"写得多快",而是"分层不乱"。文章通过真实 Controller 代码示例,展示了如何通过明确的约束提示词,让 AI 遵守 Controller 只收参调 Service、Service 处理业务规则、Mapper 负责 SQL、DTO/VO 按输入输出分开的分层原则。同时提供了可直接复用的提示词模板,帮助开发者在实际项目中有效引导 AI 产出符合规范的后端代码。
它不是写不出来,而是特别容易把 Controller、Service、Mapper、DTO/VO 的边界做乱。
Sourcelin Blog 这套博客服务我后面越整理越清楚,AI 参与后端开发时,最重要的不是“帮我快点写”,而是“别把分层打散”。
如果你拿一个后端服务直接扔给 AI,让它“帮我加个接口”,它通常不是做不出来,而是很容易把分层做乱。
项目入口:
- 在线演示:http://sourcelin.cn
- Gitee:https://gitee.com/my_lyq/sourcelin-cloud-blog
- GitHub:https://github.com/SourceLin/sourcelin-cloud-blog
Sourcelin Blog 这个项目里,后端最重要的边界其实已经写得很清楚:
- Controller 只收参、校验、权限注解、调 Service
- Service 负责业务规则、事务、状态流转
- Mapper 负责 SQL
- DTO/VO 按输入输出分开
这件事如果不先说清楚,AI 很容易在 Controller 里塞太多东西。
先看这个项目里一段真实的 Controller
博客后台文章管理就在:
sourcelin-modules/sourcelin-blog/src/main/java/com/sourcelin/blog/controller/admin/ArticleController.java
里面的列表接口其实很典型:
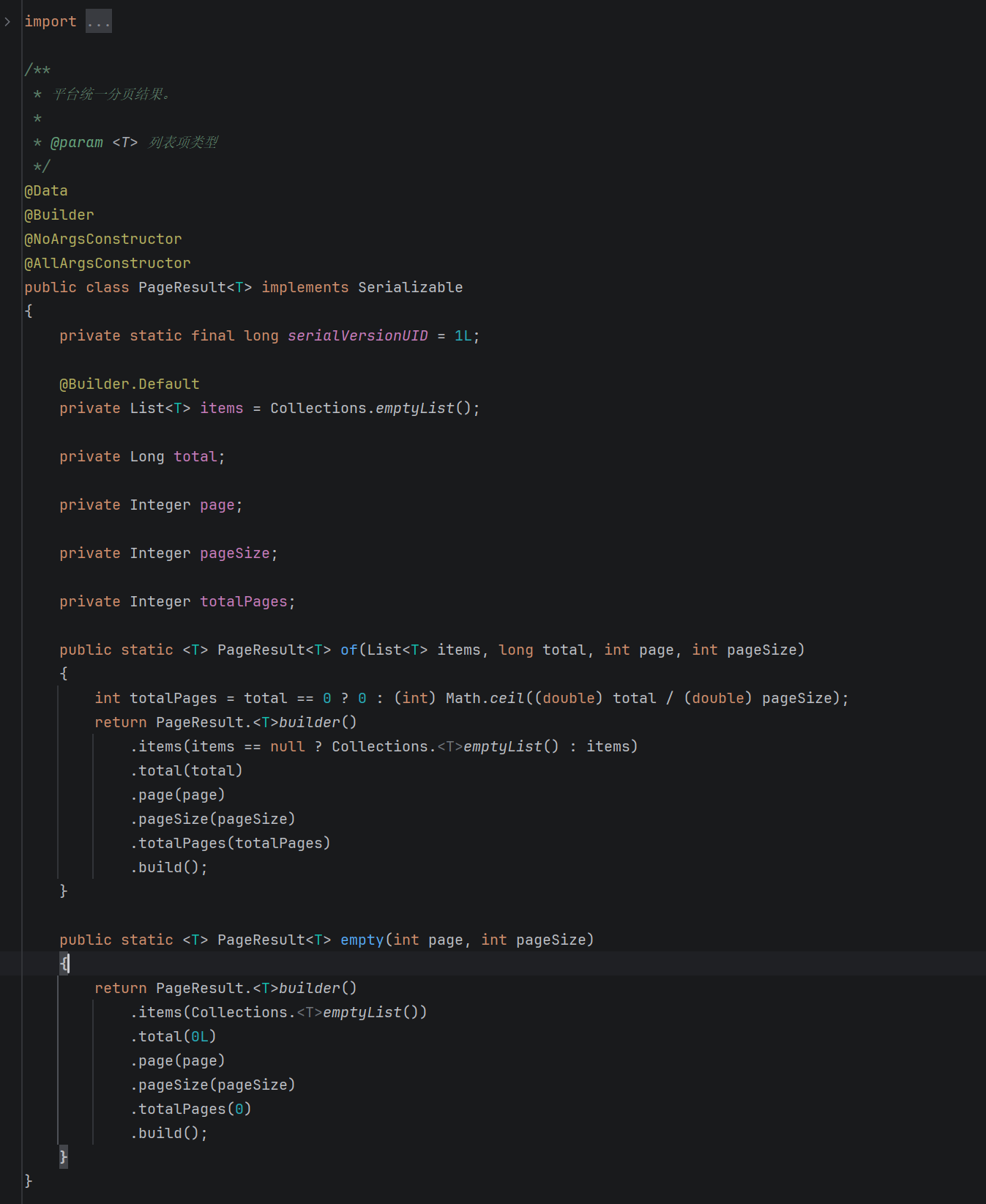
@GetMapping("/list")
public PageResult<ArticleVO> list(Article article) {
PageDomain pageDomain = TableSupport.buildPageRequest();
PageHelper.startPage(pageDomain.getPage(), pageDomain.getPageSize());
List<ArticleVO> list = articleService.selectArticleVoList(article);
PageInfo<ArticleVO> pageInfo = new PageInfo<>(list);
return BlogPageResults.of(list, pageInfo);
}
这段代码最值得学的不是语法,而是边界:
- Controller 没有直接写 SQL
- Controller 没有自己拼返回结构
- 分页最终收口到
PageResult<ArticleVO>
这类任务我一般怎么交给 AI
我会先把边界说死,而不是让它“自由发挥”:
请在 sourcelin-blog 模块中实现一个后端能力。
要求:
1. Controller 只做参数接收、权限和 Service 调用
2. Service 处理业务规则和 BusinessException
3. Mapper XML 继续放在 resources/mapper
4. 对外接口返回 PageResult、业务对象或 Void
5. 不允许返回 AjaxResult、TableDataInfo、Map
有了这层约束,AI 写后端会稳很多。
前台文章接口也是一个很好的参考
前台文章详情控制器在:
sourcelin-modules/sourcelin-blog/src/main/java/com/sourcelin/blog/controller/front/FrontArticleController.java
比如详情接口就体现了“先查、再校验、再拼展示态”的过程:
@GetMapping("/{id}")
public FrontArticleDetailVO detail(@PathVariable("id") Long id) {
Article article = articleService.selectArticleById(id);
if (article == null || isDeleted(article)) {
throw new BusinessException(ResultCode.NOT_FOUND, "文章不存在");
}
// ...
return detail;
}
这里有两个点我觉得很适合交给 AI 学:
- 业务失败统一抛
BusinessException - 对外返回的是明确的
VO,不是随手拼的Map
我自己现在更喜欢怎么拆后端任务
第一步:先定输入和输出
这一轮新增的是:
- 新建接口
- 列表接口
- 详情接口
- 审核或状态流转接口
不同接口,DTO/VO 的边界不一样。
第二步:再定放在哪个模块
这个项目里最常见的边界是:
- 公共能力放
sourcelin-common/* - 业务逻辑放
sourcelin-modules/* - Feign 和跨服务 DTO 放
sourcelin-api/*
第三步:最后才让 AI 写代码
这一步很多人会反过来做。
但后端一旦模块位置放错,后面再收就麻烦很多。
可以直接复用的提示词
请基于 Sourcelin Blog 的后端规则完成一个博客模块需求。
先阅读 AGENTS.md、rules/backend.md、rules/api-contract.md。
要求:
1. 明确这个能力属于 common、api 还是 modules
2. Controller 不直接写业务编排
3. 业务失败抛 BusinessException
4. 对外接口统一遵守 ApiResponse/PageResult 契约
5. 最后给出受影响模块的 Maven 验证命令
展示


这类任务里 AI 最容易跑偏的点
- 把业务逻辑塞进 Controller
- 返回旧协议字段
- 直接在公共模块里写业务规则
- 只给出代码,不给验证命令
我现在对 AI 写后端最看重的已经不是“快”,而是能不能长期保持分层稳定。
后端只要边界稳,后面很多功能都能接着做,文章也更有机会写成一套长期可复用的方法论。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)