GB/T 42131——2022 知识图谱
实体:独立存在的对象
实体类型:一组具有相同属性的实体集合的抽象
知识图谱:以结构化形式描述的知识元素及其联系的集合
本体:表示实体类型以及实体类型之间关系、实体类型属性类型及其之间关联的一种模型
包含三个维度:
1.实体类型:领域中具有共同特征的抽象事物集合,是本体最基本的分类单元。例如在医疗本体中,"患者"、"医生"、"药品" 都是实体类型。
2.实体类型之间的关系:明确定义类与类之间的语义连接,如 "是一种"(继承关系)、"治疗"、"包含" 等。
3.属性类型:描述类的固有特征
属性:一类对象中所有成员公共的特征
关系:实体,实体类型,实体组合或实体类型组合间的联系
注意:属性与关系的联系
- 狭义上:属性≠关系。属性描述实体的内在特征,值是数据;关系描述实体间的外部连接,值是实体。
- 广义上:关系是属性的一种(对象属性),属性还包括数据属性。
知识表示:利用机器能够识别和处理的符号和方法描述人类的知识的活动。
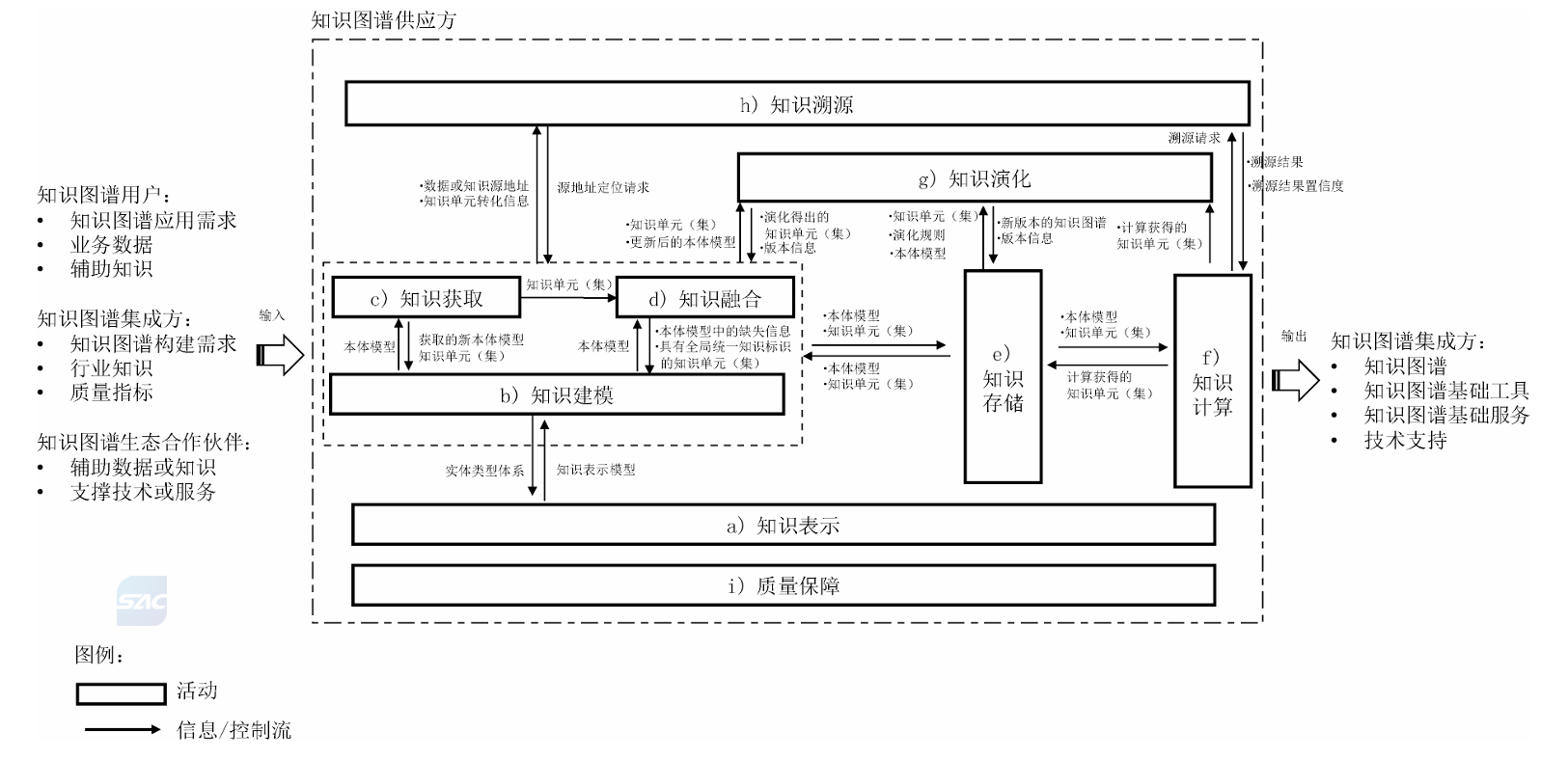
知识建模:构建知识图谱的本体及其形式化表达的活动。
本质是工程实践的过程,最终产物是本体模型
知识获取:从不同来源和结构的输入数据中提取知识的活动。 注:知识获取的数据源通常按数据组织结构的维度可分为结构化数据、半结构化数据、非结构化数据(如纯文本、音频和视频数据等)。
知识融合:整合和集成知识单元(集),并形成拥有全局统一知识标识的知识图谱的活动。
目标:实现全局统一,消除异构性。
实体对齐:识别出不同来来源中指向同一个真实世界实体的不同表示,并将它们合并为一个统一的实体
关系融合:将同一个实体对之间来自不同来源的多个关系进行合并和去重
冲突检测与消解:检测并解决不同来源知识之间的矛盾和冲突
eg:
- 来源 A:iPhone 16 的售价为 5999 元
- 来源 B:iPhone 16 的售价为 6999 元
知识计算:基于已构建的知识图谱和算法,发现 / 获得隐含知识并对外提供知识服务能力的活动。 注:知识计算可分为统计分析、推理计算等。知识的统计分析是对知识图谱蕴含知识结构及其特征的统计与归纳;知识的推理计算是从已有的事实或关系推断出知识图谱隐性知识的发现与挖掘。
知识的统计分析:
- 节点中心性分析:计算节点的度、介数、紧密度等中心性指标,识别图谱中的核心枢纽、桥梁节点或战略要地。
- 频繁子图挖掘:在海量图数据中,寻找反复出现的特定子结构模式。经典案例是电商领域的“购物篮分析”,发现“购买了A和B的客户,大概率也会购买C”这种关联规则,用于推荐系统。
属性分布概览:对特定类型实体的属性值进行统计。例如,对知识图谱中所有“公司”实体的“成立年份”和“所属行业”进行分布统计,从而快速获得产业的时间与领域格局全貌。
知识的推理计算:
于符号逻辑的推理:利用预定义的或者从数据中挖掘的规则(如“X 位于 Y,Y 位于 Z” → “X 位于 Z”)进行演绎。这是一种白盒的、可解释的推理。
基于图嵌入与表示学习的推理:将图中的实体和关系转化为低维、稠密的向量表示,使得语义上相近的实体/关系在向量空间中的距离也近。推理任务转而通过向量间的代数运算完成。
基于路径与神经网络的推理:重点分析两个实体间的连接路径序列,利用神经网络学习哪些路径模式对推断特定关系有效。
知识演化:随本体模型、数据资源等变化产生的新知识对原有知识的补充、更新或重组的活动。 注:通过知识计算得出的补全知识也可触发知识演化。
补充:即知识增添。在不改变原有结构的基础上,增加新实体、新关系或新属性。比如图谱中新增了一个人物实体和他的毕业院校关系。这是“从无到有”的演化。
更新:即知识修正。对图谱中已存在的、过时或错误的知识进行修改。比如某公司的CEO发生了变更,需要将旧关系置为历史态,并添加新关系。这是“从此到彼”的演化,往往涉及版本管理。
重组:即知识重构。这是最深层的演化,通常由本体模型变化触发。它涉及对已有知识的结构性调整,如实体合并、关系重定义、层级重构等。例如,将原本独立的“疾病”和“症状”两个概念,统一归入新创建的“医学现象”父类下。这是“从此形到彼形”的演化。
(真阳性):系统识别出,且与真实标准一致的实体 / 关系 / 属性
(假阳性):系统识别出,但和真实标准不符的内容
(假阴性):真实存在,但系统没识别出来的内容
精确率:
抽出来的所有结果里,正确的占比,衡量不抽错的能力。
召回率:
真实存在的全部知识里,被系统成功识别的占比,衡量不漏抽的能力。
F1值:
精确率和召回率的调和平均数,综合衡量抽取效果,兼顾准确性与完整性。
符号主义范式:
- 代表:逻辑、规则、本体、知识图谱
- 特点:显式表示知识、可解释性强、推理精确
- 问题:知识获取瓶颈、覆盖范围有限、泛化能力差
连接主义范式:
- 代表:词向量、预训练大模型
- 特点:隐式表示知识、泛化能力强、构建成本低
- 问题:可解释性差、推理不可靠、容易产生幻觉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)