Hermes Agent Agent Loop 深度解析:一次任务到底是怎么执行的?
一、先说结论:Agent Loop 是 Hermes Agent 的“发动机”
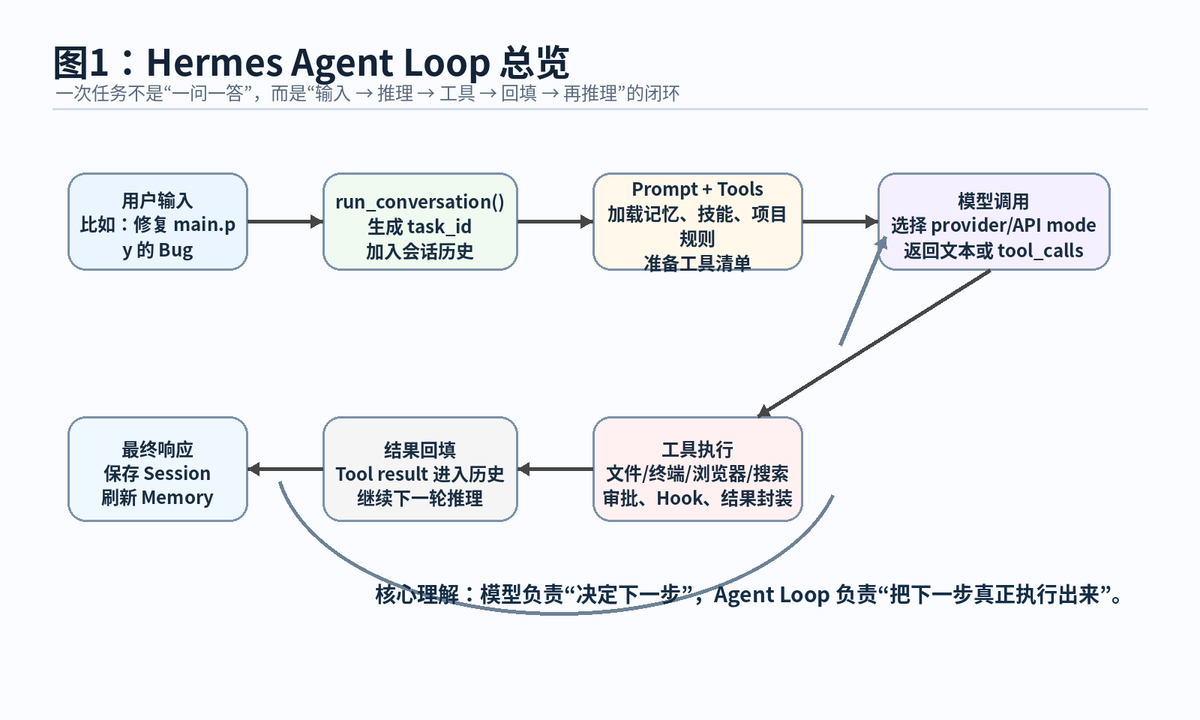
理解 Hermes Agent,不能只看它能接多少模型、能用多少工具,也不能只看它有没有 Memory 和 Skills。真正把这些能力串起来的,是 Agent Loop。所谓 Agent Loop,就是一次任务进入系统后,Hermes 如何不断整理上下文、调用模型、执行工具、把结果塞回历史,再继续下一轮判断,直到任务完成。
如果把普通聊天机器人比作“会回答问题的人”,那么 Hermes Agent 更像“能接任务、能查资料、能改文件、能跑命令、能保存经验的执行者”。它不是模型单独在工作,而是模型、上下文、工具系统、会话系统、记忆系统、技能系统一起协作。
官方文档把 AIAgent 的职责说得非常清楚:它负责组装系统提示词和工具 schema、选择 provider 和 API mode、发起可中断模型调用、执行工具调用、维护对话历史、处理压缩、重试、fallback、预算控制,并在上下文丢失前刷新持久化记忆。
二、为什么普通问答不是 Agent,真正的 Agent 要有 Loop
2.1 普通问答:模型想完就答
普通大模型问答通常是这样的:用户问一句,系统把问题发给模型,模型生成一段文本,然后结束。它不一定真的去看文件,不一定真的运行命令,也不一定知道任务完成到哪一步。
2.2 Agent Loop:边想、边做、边验证、边修正
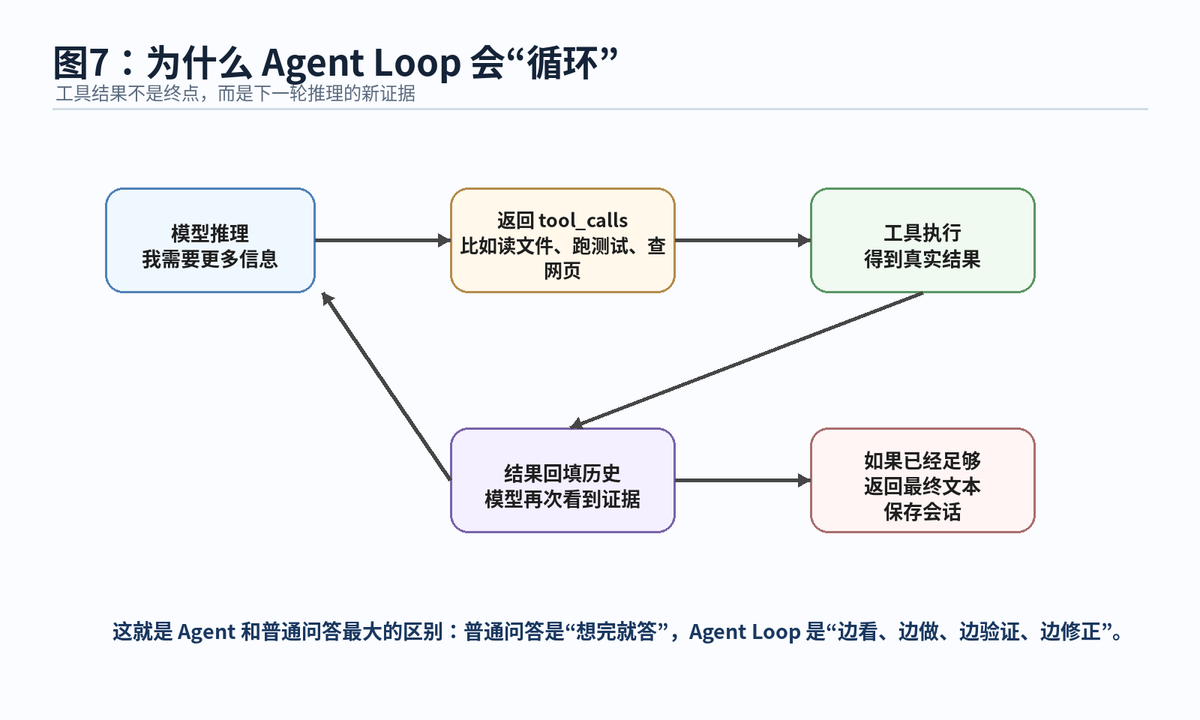
Hermes Agent 这种 Agent 的关键不是“能说”,而是“能行动”。当模型觉得自己需要更多信息时,它不会直接编答案,而是返回 tool_calls。Hermes 接到 tool_calls 后,会找到对应工具,进行权限检查,执行工具,再把工具结果以 tool 消息的形式放回会话历史。随后模型会基于真实结果继续判断下一步。
这就形成一个闭环:模型提出下一步,工具执行下一步,结果变成新证据,模型再继续判断。这个闭环就是 Agent Loop。
三、官方链路拆解:一次任务的 9 个关键步骤
按照官方 Agent Loop 文档,一次 run_conversation() 的循环大致可以拆成 9 个步骤。它不是一次性把任务扔给模型,而是每轮都要重新检查上下文、准备消息、调用模型、判断返回结果。
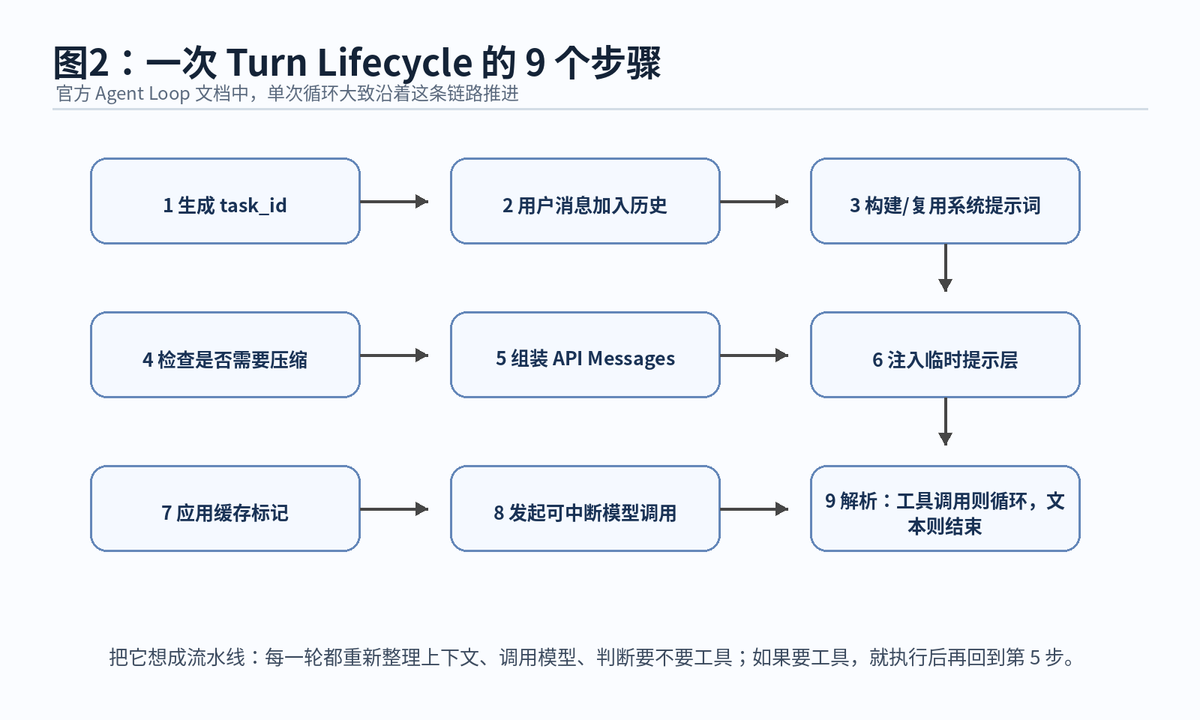
3.1 第一步:生成 task_id,让任务有身份证
当用户输入任务后,如果外部没有传入 task_id,Hermes 会生成一个任务 ID。这个 ID 的意义是给后续工具执行、日志记录、回调和会话追踪提供统一标识。通俗说,就是这次任务从一开始就被登记在案。
3.2 第二步:用户消息加入会话历史
用户输入不会被孤立处理,而是会追加进 conversation history。这样模型后续看到的不只是当前一句话,还能看到任务前后文、之前的工具结果和中间推理痕迹。
3.3 第三步:构建或复用系统提示词
Hermes 会通过 prompt_builder.py 构建有效的系统提示词。这里面不只是“你是一个助手”这么简单,还包括 Agent 身份、工具使用规则、Memory 快照、User Profile、Skills 索引、项目上下文文件、时间戳、平台提示等。
3.4 第四步:检查是否需要上下文压缩
如果会话已经很长,模型上下文空间被大量占用,Hermes 会在 API 调用前检查是否需要压缩。官方文档提到,preflight 压缩会在超过模型上下文 50% 时触发。这样做是为了避免模型调用失败,也避免重要上下文被挤掉。
3.5 第五步:构建 API Messages
Hermes 内部维护统一消息格式,但不同供应商接口并不完全一样。因此在真正发起模型调用前,系统会根据 API mode 把内部消息转换成对应供应商需要的格式。OpenAI 兼容接口、Codex Responses、Anthropic Messages 都会在这一层被适配。
3.6 第六步:注入临时提示层
有些提示只适合当前这一轮,比如预算快用完、上下文压力变大、平台临时状态等。这些临时信息不会永久写进稳定系统提示词,而是在调用前临时注入,既保证模型知道当前压力,也不污染长期缓存。
3.7 第七步:应用提示词缓存标记
对于支持提示词缓存的模型,Hermes 会尽量保持稳定前缀不变,并应用缓存标记。这样长任务中的重复系统提示词可以更容易命中缓存,降低重复成本。
3.8 第八步:发起可中断模型调用
模型调用不是不可打断的黑盒。官方文档中提到,Hermes 会用 _interruptible_api_call() 包装请求,让 HTTP 调用在后台线程里运行,主线程可以监听中断事件、超时或新输入。用户发出 /stop 或平台收到新消息时,Agent 可以更干净地停止当前调用。
3.9 第九步:解析结果,决定继续还是结束
模型返回后,Hermes 会判断结果类型:如果返回的是文本,就保存会话、刷新 Memory,然后返回最终响应;如果返回的是 tool_calls,就进入工具执行,再把工具结果写回历史,然后回到消息构建和模型调用步骤继续循环。
四、Prompt Builder:模型调用前,Hermes 先把“上下文饭菜”备好
很多人以为 Agent 的提示词就是几句 prompt。实际上,Hermes 的 Prompt Assembly 是一套很讲究的分层系统。官方文档明确强调,它有意区分缓存系统提示词状态和 API 调用时的临时追加内容,这关系到 token 使用、缓存效果、会话连续性和记忆正确性。
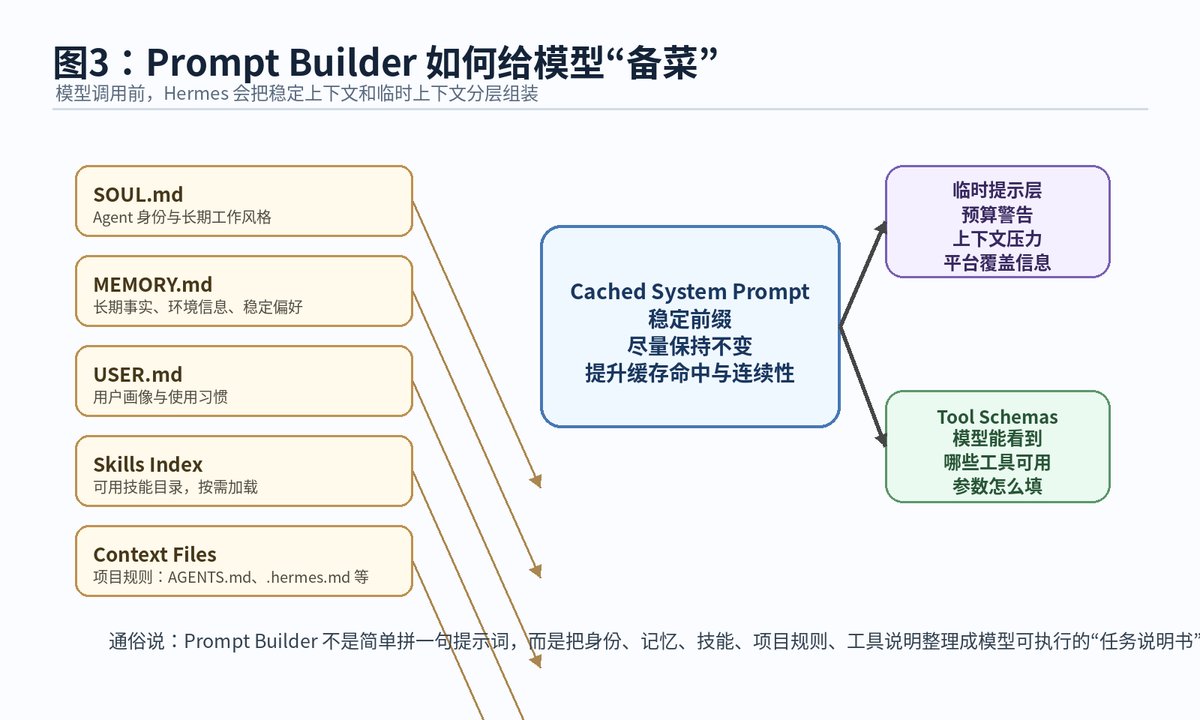
4.1 稳定层:尽量保持不变,方便缓存
稳定层包括 Agent 身份、工具行为规则、Memory 快照、User Profile 快照、Skills 索引、项目上下文文件、时间戳、平台提示等。这里的关键词是“稳定”。稳定的前缀越稳定,提示词缓存越容易生效,模型在长任务中也更容易保持一致行为。
4.2 记忆层:Memory 和 User Profile 是快照,不是每秒动态变
官方 Prompt Assembly 文档说明,本地 Memory 和用户画像会在 session 开始时以 frozen snapshot 的方式注入。中途写入 Memory 会更新磁盘状态,但不会立刻改变已经构建好的系统提示词,除非开启新 session 或强制重建。这样做的好处是记忆语义更清楚,也避免同一轮会话里系统提示词不断变化。
4.3 项目规则层:AGENTS.md、.hermes.md 等文件让 Agent 知道项目规矩
如果用户让 Hermes 修复一个项目里的 Bug,Agent 不能只看当前一句话。它还需要知道项目技术栈、测试命令、目录结构、代码规范、禁止事项等。这些信息可以来自 .hermes.md、HERMES.md、AGENTS.md、CLAUDE.md、.cursorrules 等上下文文件。
4.4 Skills 层:不是每次重新教,而是按需加载经验
Skills Index 会把可用技能目录放进提示词,让模型知道当前有哪些技能可以调用。真正需要某个技能时,再通过 skill_view 读取完整技能内容。这样既保留了经验沉淀,又不会把所有技能全文都塞进上下文。
五、Provider 与 API Mode:同一个 Agent Loop,适配不同模型后端
Hermes 支持多个模型供应商。不同供应商接口格式不同,但 Agent Loop 希望内部处理逻辑保持统一。因此 Hermes 会先解析 provider、model、base_url、凭证、API mode,再把外部差异收敛到统一内部消息格式。
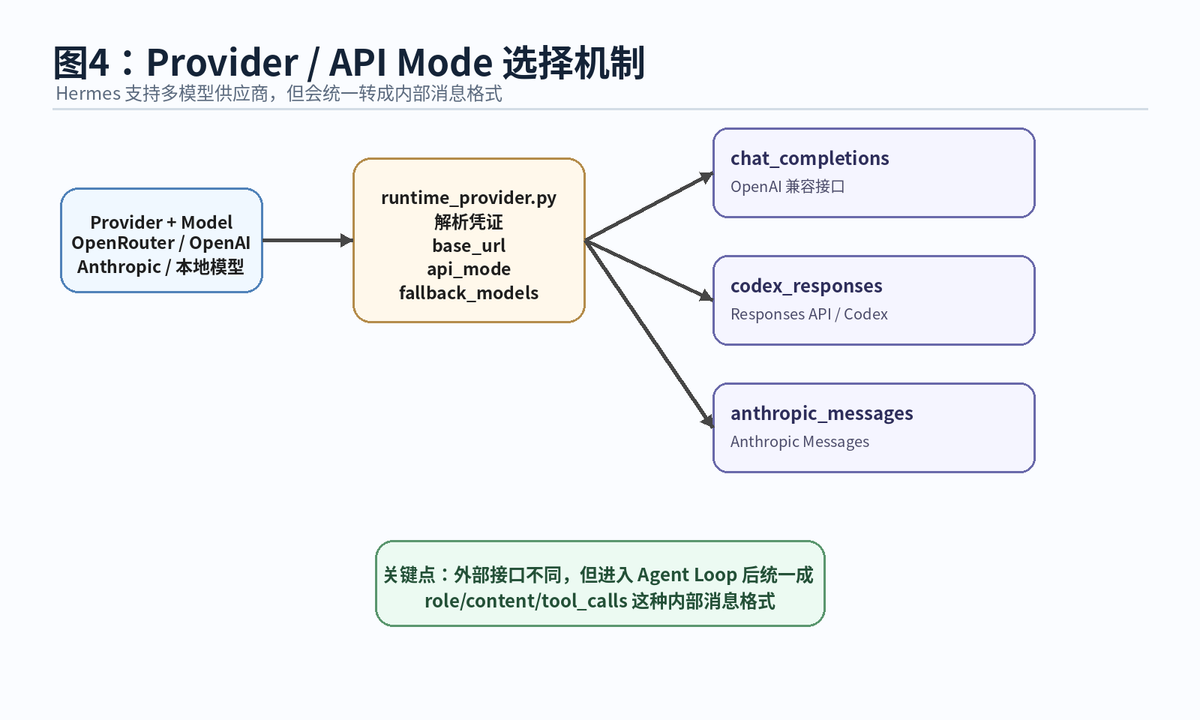
官方文档列出三种主要 API mode:chat_completions、codex_responses、anthropic_messages。它们分别对应 OpenAI 兼容接口、OpenAI Codex/Responses 格式、Anthropic Messages API。mode 会影响消息如何格式化、工具调用如何结构化、响应如何解析,以及缓存和流式输出如何工作。
这层设计的价值很大:Agent 的核心逻辑不需要为每个供应商重写一遍。只要 provider runtime 解析出正确的 API mode 和连接信息,后面都可以回到统一 Agent Loop。
六、消息格式:Agent Loop 的“账本”必须严格清楚
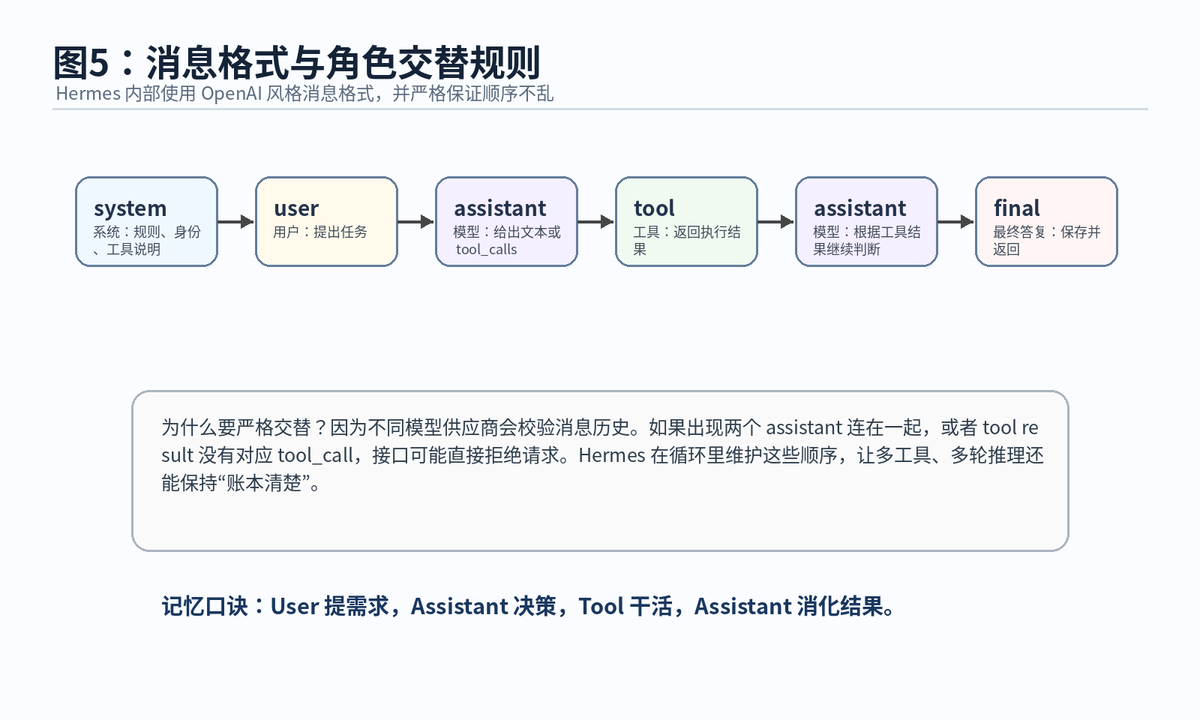
工具调用型 Agent 最怕历史消息乱掉。比如模型说“我要调用 terminal”,结果历史里没有对应的 tool result;或者两个 assistant 消息连续出现;或者 tool 消息没有对应 tool_call。这些都会让供应商接口报错,甚至让模型误解任务状态。
6.1 四类核心消息角色
|
角色 |
含义 |
在 Agent Loop 中的作用 |
|
system |
系统提示词 |
提供身份、规则、工具说明、记忆、技能和项目上下文 |
|
user |
用户输入 |
任务起点,也是每轮对话的显式需求 |
|
assistant |
模型输出 |
可能是普通文本,也可能包含 tool_calls |
|
tool |
工具结果 |
真实执行后的返回内容,作为下一轮推理证据 |
官方文档说明,Hermes 内部使用 OpenAI 兼容消息格式,比如 system、user、assistant、tool。即使外部供应商是 Anthropic 或 Responses API,进入和离开 API 调用前也会收敛到统一内部结构。
6.2 为什么 tool result 要回填历史
因为模型本身并不知道工具执行结果。比如模型要求读取 main.py,真正读取文件的是工具系统。只有把工具返回内容写回 conversation history,模型下一轮才能看到真实文件内容,进而判断下一步是修改、运行测试,还是继续搜索。
七、Tool Execution:模型提出动作,Hermes 负责真正执行
在 Agent Loop 里,模型不是直接访问你的文件系统,也不是直接跑 shell 命令。模型只是返回一个结构化的 tool_call,里面说明想调用哪个工具、参数是什么。Hermes 会接管后续执行过程。
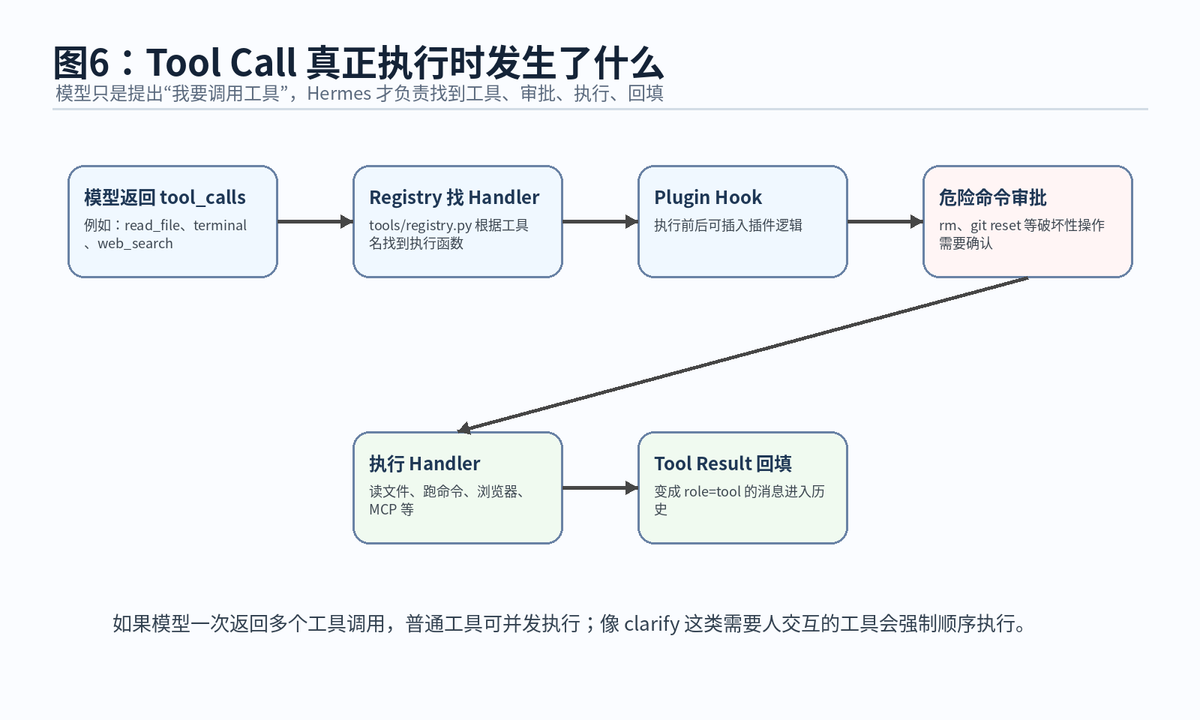
7.1 工具不是散落的函数,而是注册到 Registry 的能力
官方 Tools Runtime 文档说明,Hermes 的工具是自注册函数,按 toolsets 分组,并通过中心 registry/dispatch 系统执行。每个工具模块在导入时调用 registry.register(),声明工具名、所属工具集、schema、handler、可用性检查、环境变量需求等信息。
7.2 model_tools.py 负责发现工具和构建 schema
model_tools.py 会导入和发现工具模块,并构建模型可见的工具 schema。通俗说,schema 就是告诉模型:你现在有哪些工具可以用,每个工具叫什么,需要传哪些参数,返回结果大概是什么。
7.3 执行前后会经过 Hook 和安全检查
工具执行不是直接放行。Hermes 在执行前会触发 pre_tool_call plugin hook,执行后会触发 post_tool_call plugin hook。对于危险命令,还会进入审批流程。官方安全文档说明,Hermes 有防御纵深安全模型,其中包括用户授权、危险命令审批、容器隔离、MCP 凭证过滤、上下文文件扫描、跨 session 隔离和输入净化。
7.4 单工具直接执行,多工具可以并发执行
当模型一次只返回一个工具调用时,Hermes 会在主线程直接执行。当模型一次返回多个工具调用时,普通工具可以通过 ThreadPoolExecutor 并发执行,提高效率。但像 clarify 这类需要用户交互的工具会强制顺序执行,避免并发交互把上下文搞乱。
八、Agent-Level Tools:有些工具会被 run_agent.py 直接拦截
不是所有工具都会走普通 registry 派发。官方 Agent Loop 文档提到,一些 Agent 级工具会在 run_agent.py 中被拦截,因为它们直接改变 Agent 本地状态。
|
工具 |
为什么特殊 |
通俗理解 |
|
todo |
读写 Agent 本地任务状态 |
任务清单,不只是普通函数 |
|
memory |
写入持久化记忆文件,并有字符限制 |
长期记忆,影响后续会话 |
|
session_search |
查询历史会话数据库 |
跨会话找以前聊过什么 |
|
delegate_task |
生成子 Agent,并隔离上下文 |
把复杂任务拆出去并行处理 |
这些工具之所以特殊,是因为它们不只是“拿输入返回输出”,还会改变 Agent 的内部状态、会话状态或任务组织方式。把它们放在 run_agent.py 层面处理,可以让状态管理更集中。
九、一个例子:用户说“修复 main.py 的 Bug”,Agent Loop 怎么跑
为了让链路更直观,我们用一个简单场景说明:用户输入“帮我修复 main.py 的 Bug,并跑一下测试”。
|
阶段 |
发生了什么 |
|
第一轮 |
Hermes 把用户请求加入会话历史,加载系统提示词、Memory、Skills、项目上下文和工具 schema。 |
|
第二轮 |
模型判断需要先查看项目文件,于是返回 read_file 或 terminal ls 之类的 tool_call。 |
|
第三轮 |
Hermes 执行工具,读取文件或列目录,把结果作为 tool 消息写回历史。 |
|
第四轮 |
模型看到文件内容后,判断问题位置,返回 patch 或 write_file 类工具调用。 |
|
第五轮 |
Hermes 检查修改是否危险,必要时走审批,然后执行文件修改。 |
|
第六轮 |
模型要求运行测试,Hermes 调用 terminal 执行测试命令。 |
|
第七轮 |
测试结果回填历史。如果失败,模型继续修改;如果通过,模型生成最终说明。 |
|
结束 |
Hermes 保存 Session,必要时刷新 Memory,把最终结果返回给用户。 |
这个例子能看出,Agent Loop 不是为了“炫技”,而是为了让模型不要空想。每一步都尽量基于真实文件、真实命令输出、真实测试结果推进。
十、压缩与持久化:长任务为什么不会轻易跑崩
长任务最大的敌人是上下文膨胀。Agent 读文件、跑命令、查资料、改代码,消息历史会越来越长。如果不处理,模型上下文窗口迟早被填满。Hermes 在 Agent Loop 中加入了压缩和持久化机制。
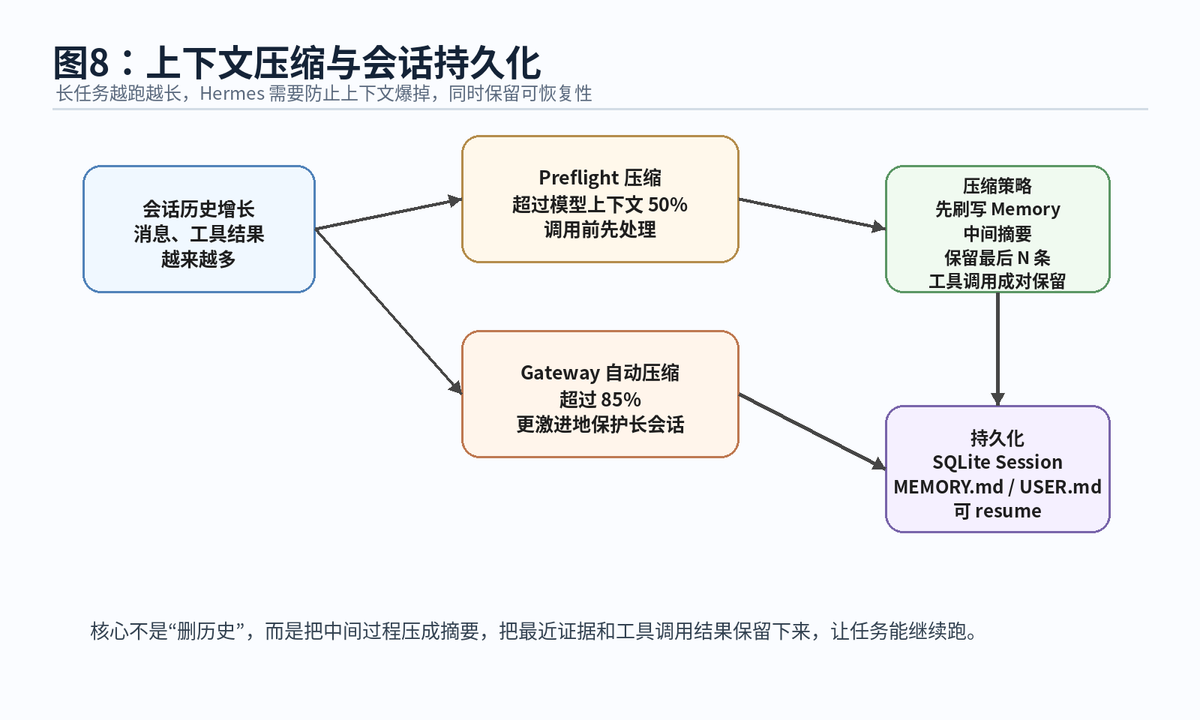
10.1 什么时候触发压缩
官方文档给了两个关键触发点:第一,API 调用前如果会话超过模型上下文窗口 50%,会触发 preflight 压缩;第二,Gateway 自动压缩会在超过 85% 时更积极触发。前者保证模型调用前不爆,后者保证长期网关任务更稳。
10.2 压缩不是简单删除,而是保留关键证据
压缩时,Hermes 会先把 Memory 刷写到磁盘,防止数据丢失;然后把中间对话压成紧凑摘要;最后保留最近 N 条消息,并保证工具调用和工具结果成对保留。这个“成对保留”非常重要,因为模型必须知道某个 tool result 对应哪个 tool_call。
10.3 会话持久化让任务可以恢复
每轮结束后,消息会保存到 session store,Memory 变化会刷新到 MEMORY.md / USER.md。用户后续可以通过 resume 机制恢复任务。对于长期运行的 Agent,这个能力非常关键:任务不是浏览器刷新就消失,而是有状态、有历史、有恢复入口。
十一、预算与 Fallback:Agent 不能无限跑,也不能一失败就崩
一个能自动执行工具的 Agent,如果没有预算限制,就可能陷入无限循环;如果没有备用模型,就可能因为一次 429、5xx 或鉴权问题直接失败。Hermes 在 Agent Loop 中加入了预算和 Fallback。
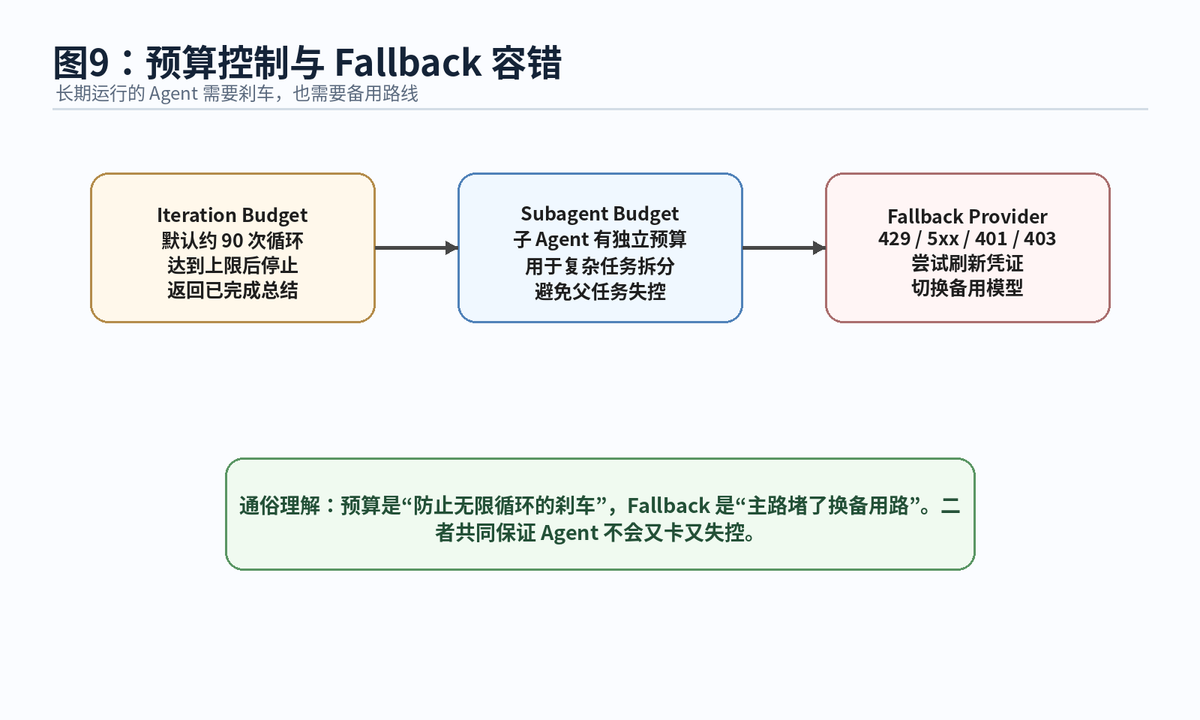
11.1 Iteration Budget:给循环加刹车
官方文档提到,Hermes 通过 IterationBudget 跟踪循环次数,默认大约 90 次,可通过 agent.max_turns 配置。每个 Agent 都有自己的预算;子 Agent 也有独立预算,并受 delegation.max_iterations 限制。到达 100% 后,Agent 会停止,并返回已经完成工作的总结。
11.2 Fallback Provider:主模型失败后换备用路线
当主模型遇到 429 限流、5xx 服务错误、401/403 鉴权错误时,Hermes 会检查 fallback_providers 列表,按顺序尝试备用 provider;对于 401/403,还会先尝试刷新凭证。视觉、压缩、网页抽取等辅助任务也可以有独立 fallback 链。
这两点体现了生产化思维:Agent 不只是能跑 Demo,还要能在真实环境里防止失控、降级运行、保留结果。
十二、Callback:为什么 CLI、Gateway、ACP 都能看到进度
Hermes 的 Agent Loop 支持多种回调,用于把内部状态暴露给不同入口。比如 CLI 可以显示 thinking 状态和工具执行 spinner,Gateway 可以发送进度消息,ACP 可以更新状态。
|
Callback |
触发时机 |
典型用途 |
|
tool_progress_callback |
工具执行前后 |
CLI spinner、网关进度消息 |
|
thinking_callback |
模型开始/停止思考 |
显示 thinking 状态 |
|
reasoning_callback |
模型返回 reasoning 内容 |
展示推理块或调试信息 |
|
clarify_callback |
clarify 工具被调用 |
交互式追问用户 |
|
step_callback |
每个完整 Agent turn 后 |
Gateway/ACP 跟踪步骤 |
|
stream_delta_callback |
流式 token 到达时 |
实时输出 |
|
status_callback |
状态变化时 |
ACP 状态更新 |
这些 callback 的意义是:同一个 Agent Loop 可以跑在不同入口里。无论是 CLI、消息网关、IDE 协议还是 API Server,底层都可以共享一套执行引擎,只是把进度展示给用户的方式不同。
十三、安全边界:能执行工具的 Agent,必须先学会克制
Agent Loop 的能力越强,安全越重要。Hermes 可以读文件、写文件、执行命令、连接外部工具,如果完全不设边界,就可能误删文件、泄露凭证或被项目文件中的恶意提示词影响。
官方安全文档把安全模型拆成七层:用户授权、危险命令审批、容器隔离、MCP 凭证过滤、上下文文件扫描、跨 session 隔离、输入净化。对开发者来说,这说明 Agent 工程不是“给模型开工具”这么简单,而是要围绕工具执行设计完整的防护栏。
|
安全层 |
解决的问题 |
|
用户授权 |
谁可以和 Agent 对话,尤其是消息平台入口 |
|
危险命令审批 |
rm、git reset 等破坏性命令不能无脑执行 |
|
容器隔离 |
把命令放到 Docker、Singularity、Modal 等隔离环境 |
|
MCP 凭证过滤 |
外部工具子进程不能随便拿到全部环境变量 |
|
上下文文件扫描 |
检测项目文件中的 prompt injection 风险 |
|
跨 session 隔离 |
不同会话不能互相串状态 |
|
输入净化 |
防止工作目录等参数造成命令注入 |
十四、源码阅读路线:想看懂 Agent Loop,先看这些文件

建议源码阅读顺序如下:第一看 run_agent.py,抓住 AIAgent 主循环;第二看 agent/prompt_builder.py,理解系统提示词怎么组装;第三看 model_tools.py 和 tools/registry.py,理解工具如何被模型看到、如何被执行;第四看 agent/context_compressor.py,理解长会话如何压缩;第五看 runtime_provider.py,理解模型供应商和 API mode 如何解析。
不要一开始就试图把所有工具、所有插件、所有平台入口看完。Agent Loop 是主干,工具、MCP、Gateway、Cron、Skills、Memory 都是围绕这条主干展开的分支。
十五、把 Hermes Agent Loop 放到企业 AI 应用里看
很多企业做 AI 应用时,只停留在“用户问题 + RAG 检索 + 模型回答”这个阶段。但 Hermes Agent Loop 提供了更完整的参考:一个真正能落地的 Agent,至少要有上下文管理、工具执行、结果回填、状态持久化、长任务压缩、安全审批和失败降级。
15.1 智能客服场景
客服 Agent 不能只回答 FAQ,还可能需要查订单、查工单、查物流、发起退款、记录用户偏好。这就需要工具系统、权限审批、会话持久化和跨会话记忆。
15.2 代码助手场景
代码 Agent 不能只解释代码,还要能读文件、改文件、跑测试、看报错、继续修复。Hermes Agent Loop 里的 tool_calls、结果回填、压缩和 session resume,正好对应代码任务的真实流程。
15.3 数据分析场景
数据分析 Agent 需要读数据、执行脚本、生成图表、解释结果、保存报告。Agent Loop 可以把每一步执行结果回填给模型,让模型基于真实数据继续判断,而不是凭空生成结论。
十六、总结:Agent Loop 才是 Hermes Agent 的真正主线
Hermes Agent 的 Agent Loop 可以浓缩成一句话:把用户任务变成一轮又一轮的“上下文整理、模型决策、工具执行、结果回填、状态保存”。模型负责判断下一步,工具负责真实行动,Session 负责记住过程,Memory 和 Skills 负责沉淀长期经验,压缩、预算、Fallback 和安全机制负责让系统稳定可控。
所以学习 Hermes Agent,不要只问“它用了什么模型”,更要问“它如何组织一次任务”。只要你看懂 Agent Loop,就能理解为什么 Hermes 不只是聊天壳,而是一个面向长期运行任务的 Agent Runtime。
对普通读者来说,可以记住这个口诀:先装上下文,再问模型;模型要工具,系统来执行;结果回历史,继续下一轮;任务完成后,保存、压缩、沉淀经验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)