YOLOv11 改进实战:Focal Loss 解决工业缺陷检测中的类别不平衡,结果却没我想的那么简单
前言
最近在做一个风机叶片表面缺陷检测的项目,数据集不大(862张训练图),3个类别:腐蚀(Corrosion)、裂纹(Crack)、凹陷(Dent)。直接用 YOLOv11n 从零训练(无预训练权重)跑了个 baseline,发现 Crack(裂纹)类别的 mAP50 只有 0.293,远低于 Dent 的 0.85 和 Corrosion 的 0.507。
一看数据分布就明白了——Crack 只有 189 个标注框,Dent 有 679 个,Corrosion 也有 516 个。
类别分布(训练集):
├── Dent: 679 (49%) ← 占一半
├── Corrosion: 516 (37%)
└── Crack: 189 (14%) ← 严重少数类
类别不平衡,Focal Loss 不是专门解决这个的吗?那就试试吧。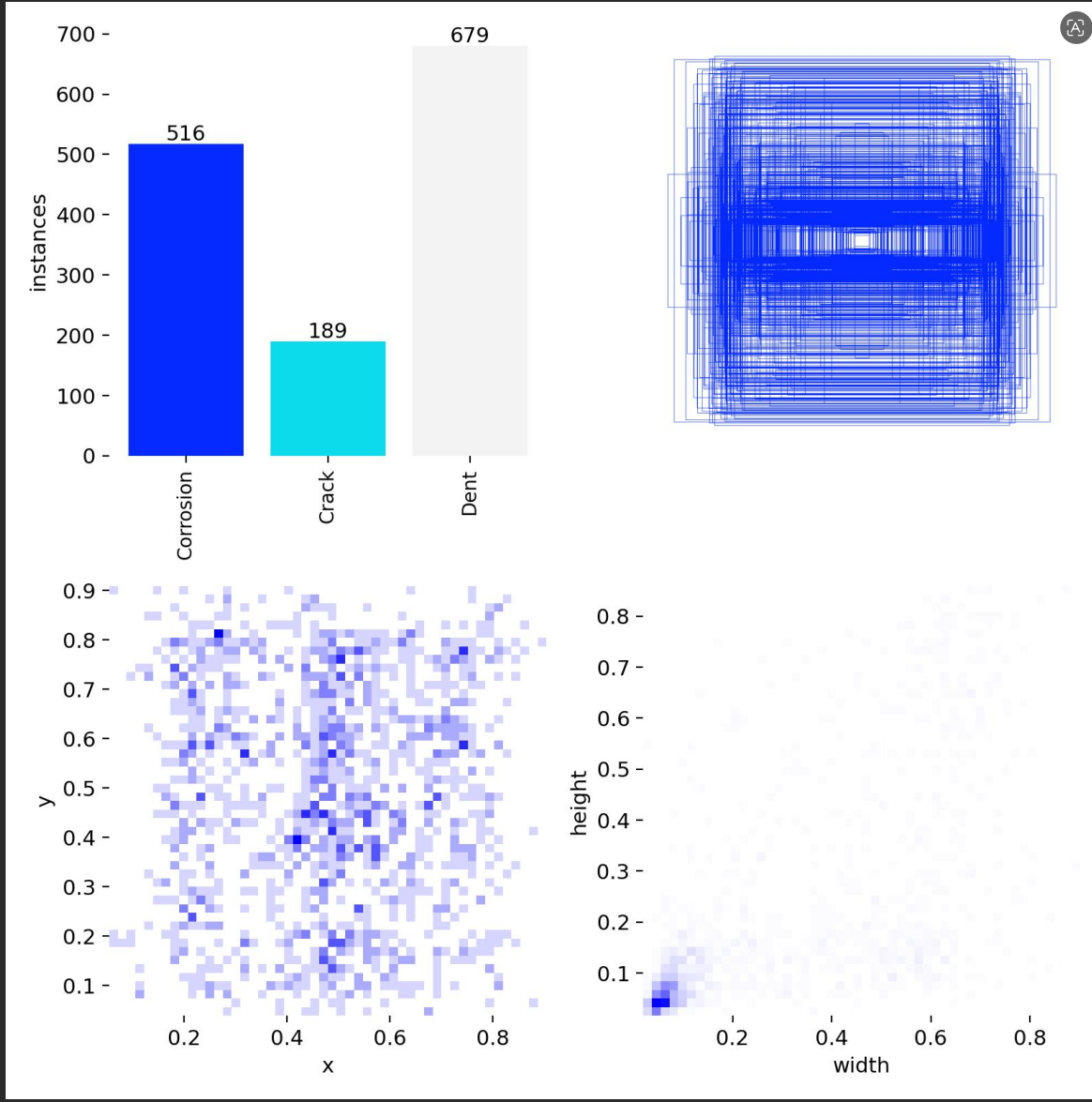
第一版:标准 Focal Loss + 类别 alpha
Focal Loss 的原始公式长这样:
FL = -α_t · (1 - p_t)^γ · log(p_t)
其中:
- p_t = y·p + (1-y)·(1-p) (模型对真实类别的预测概率)
- α_t = y·α + (1-y)·(1-α) (类别平衡因子)
- γ = 2.0 (聚焦参数,关注难样本)
α 的作用是对少数类给更高权重。我给 Crack 设了 α=0.8,Corrosion α=0.5,Dent α=0.3。
cls_alpha = [0.5, 0.8, 0.3]
focal_gamma = 1.5
结果
| 类别 | Baseline mAP50 | Focal v1 mAP50 |
|---|---|---|
| Corrosion | 0.507 | 0.429 (-15%) |
| Crack | 0.293 | 0.145 (-51%) 😱 |
| Dent | 0.850 | 0.742 (-13%) |
| ALL | 0.550 | 0.439 (-20%) |
全部下降,Crack 直接腰斩。 翻车了。
为什么会翻车?Focal Loss 的 α 陷阱
回头看公式,问题出在 α_t 上:
α_t = target × α + (1-target) × (1-α)
对于 Crack 类别(α=0.8):
正样本 (target=1): α_t = 0.8 ✅ 权重 OK
负样本 (target=0): α_t = 1-0.8 = 0.2 ❌ 问题在这!
Crack 类别的 α=0.8,意味着所有 anchor 上 “不是 Crack” 的预测,损失权重只有 0.2。
模型预测一个背景区域是 Crack(假阳性)时,惩罚只有原来的 1/5。这相当于鼓励模型瞎猜 Crack。Precision 从 0.404 断崖式跌到 0.237 就很好理解了。
Crack 的 P-R 变化:
Baseline: P=0.404 R=0.324
Focal v1: P=0.237 R=0.304 ← Precision 暴跌
第二版:修正 α,只加权正样本
把 α_t 改成只作用于正样本:
# 修复前(有问题)
alpha_factor = target * alpha + (1-target) * (1-alpha)
# 修复后
pos_mask = (target > 0).float()
cls_weight = [1.0, 3.0, 1.0] # Crack 正样本 3x 权重
cls_factor = 1.0 + pos_mask * (cls_weight - 1.0)
# 正样本: cls_factor = 3.0(Crack)
# 负样本: cls_factor = 1.0(不变)
结果
| 类别 | Baseline | Focal v1 | Focal v2 |
|---|---|---|---|
| Crack mAP50 | 0.293 | 0.145 | 0.239 |
| Crack P | 0.404 | 0.237 | 0.215 |
| Crack R | 0.324 | 0.304 | 0.391 ↑ |
| ALL mAP50 | 0.550 | 0.439 | 0.478 |
- Crack Recall 确实提升了 (0.324 → 0.391),说明 3x 正样本权重让模型更关注 Crack
- 但 Precision 仍然很低 (0.215),假阳性问题没完全解决
- 整体 mAP50 还是没回到 baseline 水平
第三版:弃用 Focal,只用类别加权(γ=0)
仔细想想,Focal Loss 的 (1-p_t)^γ 因子在小数据集上可能是个问题。862 张训练图 + 软标签(TaskAlignedAssigner 的 IoU 分数当 target,不是 0/1),难样本聚焦机制反而干扰了收敛。
干脆设 γ=0,退化成纯类别加权 BCE:
focal_gamma = 0.0 # 不用 focal
cls_alpha = [1.0, 3.0, 1.0] # 只给 Crack 正样本 3x 权重
结果
| 类别 | Baseline | Focal v1 (bug) | Focal v2 (γ=1.5) | v3 (γ=0) |
|---|---|---|---|---|
| Corrosion mAP50 | 0.507 | 0.429 | 0.439 | 0.510 |
| Crack mAP50 | 0.293 | 0.145 | 0.239 | 0.271 |
| Dent mAP50 | 0.850 | 0.742 | 0.757 | 0.844 |
| ALL mAP50 | 0.550 | 0.439 | 0.478 | 0.542 |
γ=0 后指标基本回到 baseline 水平(整体 mAP50 0.542 vs baseline 0.550),说明纯类别加权不会伤模型,但也没有带来明显提升。
三版实验完整对比
Crack mAP50 变化曲线:
Baseline: ████████████████████ 0.293
Focal v1: █████████ 0.145 ← α 打低压垮了负样本
Focal v2: ███████████████ 0.239 ← 修复 α,但 γ=1.5 过强
v3 γ=0: ██████████████████ 0.271 ← 回到接近 baseline
v3(γ=0,纯类别加权)是最干净的结果——没有破坏模型,但也没有提升。这说明问题的根因不在分类 loss 上。
复盘:Focal Loss 在目标检测中容易踩的坑
坑 1:α 对负样本的副作用
这是最容易犯的错误。Focal Loss 是为二分类设计 α 的(α 和 1-α 分布到正负样本),但 YOLO 的多类 BCE 下,每个类别都有独立的正负样本。直接把单类 α 映射回去,就会打压该类的负样本权重。
正确做法:α 只作用于 target>0(正样本)的位置,负样本权重保持 1.0。
坑 2:小数据集 + Soft Label 不适合过强的 γ
YOLOv8/v11 的分类 target 不是 0/1 硬标签,而是 IoU 分数(0~1 之间的软标签)。Focal 的 p_t 计算在软标签下含义变了,γ 过大时 (1-p_t)^γ 会过度压缩训练信号。
建议:小数据集从 γ=0 开始,确认类别权重有效后再逐步加。
坑 3:Loss 不是万能药
Crack 只有 189 个样本(训练集),R 只有 0.3 左右。光靠调 loss 很难突破数据量的天花板。更有效的方向可能是:
- 数据增强:CopyPaste 把 Crack 样本复制到更多图中
- 模型结构:加 P2 检测层(Crack 面积分布宽,多尺度特征有帮助)
- 过采样:训练时对含 Crack 的图提高采样概率
核心代码
在 ultralytics/utils/loss.py 新增 v8DetectionLossFocal 类,关键只有分类 loss 那几行:
class v8DetectionLossFocal(v8DetectionLoss):
def get_assigned_targets_and_loss(self, preds, batch):
# ... 前面和父类完全一样 ...
# 分类 loss:
bce_loss = self.bce(pred_scores, target_scores) # [B, A, NC]
# Focal 调制
pred_prob = pred_scores.sigmoid()
p_t = target * pred_prob + (1-target) * (1-pred_prob)
focal_weight = (1.0 - p_t).pow(self.focal_gamma)
# 正样本类别权重(关键:只作用于 target > 0)
pos_mask = (target > 0).float()
cls_factor = 1.0 + pos_mask * (cls_weight - 1.0)
loss_cls = (bce_loss * focal_weight * cls_factor).sum()
# Box loss / DFL loss 不变
训练脚本通过 monkey-patch DetectionModel.init_criterion 注入:
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils.loss import v8DetectionLossFocal
original = DetectionModel.init_criterion
DetectionModel.init_criterion = lambda self: v8DetectionLossFocal(
self, focal_gamma=0.0, cls_alpha=[1.0, 3.0, 1.0]
)
model = YOLO("yolo11n.yaml")
model.train(data="VOC_YOLO/data.yaml", ...)
DetectionModel.init_criterion = original # 恢复
总结
这次实验的收获:
- Focal Loss α 在多类 BCE 下要小心使用——α 只给正样本加权,别动负样本权重
- 小数据集(<1000 张)加软标签,γ 从 0 开始更稳妥——难样本聚焦容易反噬
- Loss 不是万能药——189 个 Crack 样本的瓶颈很难靠调 loss 突破,后续尝试数据结构或模型层面的改进会更有效
- baseline 本身不差——3 个版本改下来都没超过 baseline,说明 YOLOv11 默认的 BCE loss 在这个场景已经是合理的选择
完整代码和实验记录在项目 VOC_YOLO/ 目录下,私信可一起学习学习。接下来打算从数据增强(CopyPaste Crack 区域)或模型结构(加 P2 检测层)入手——敬请关注后续文章。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)